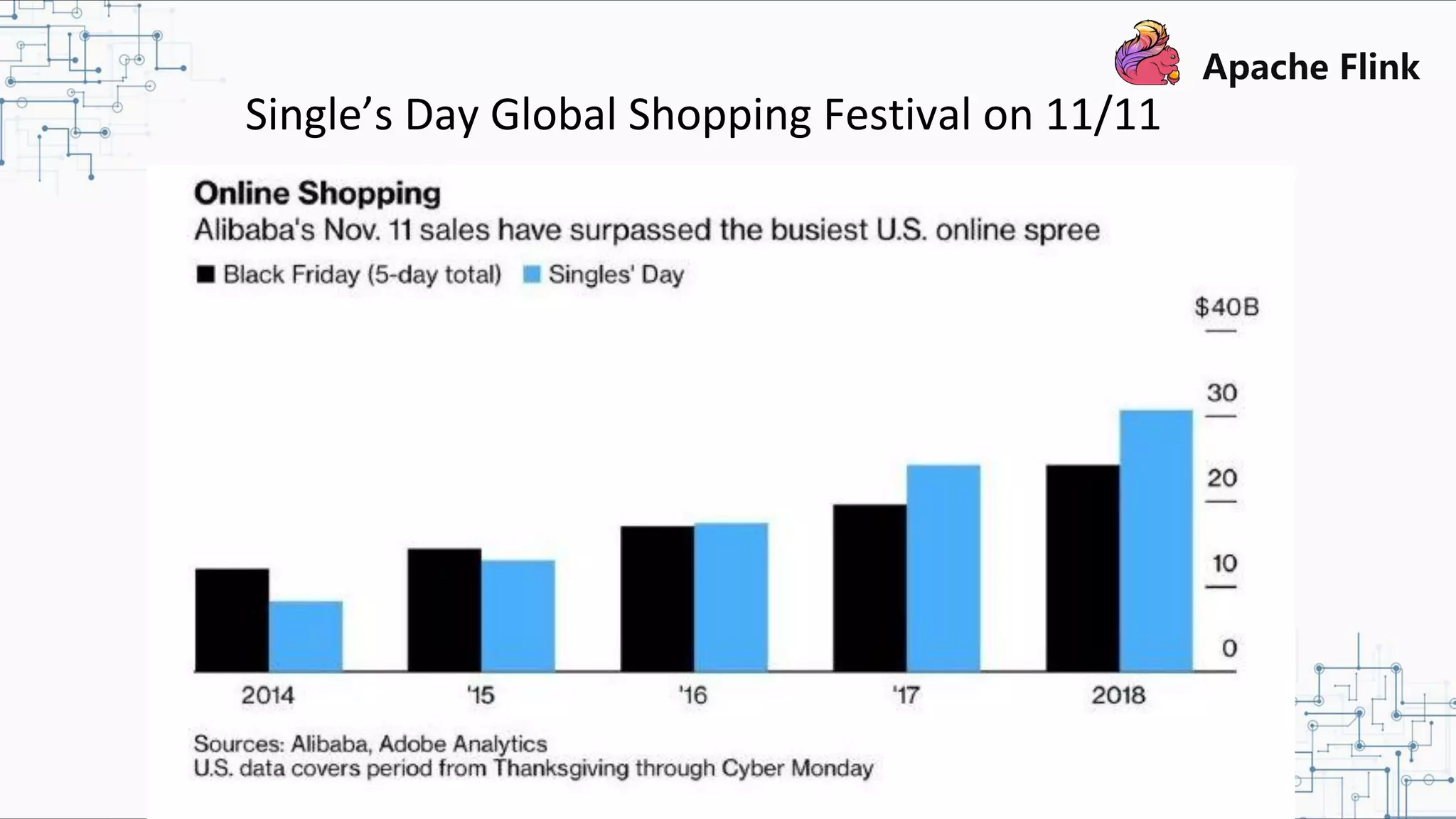
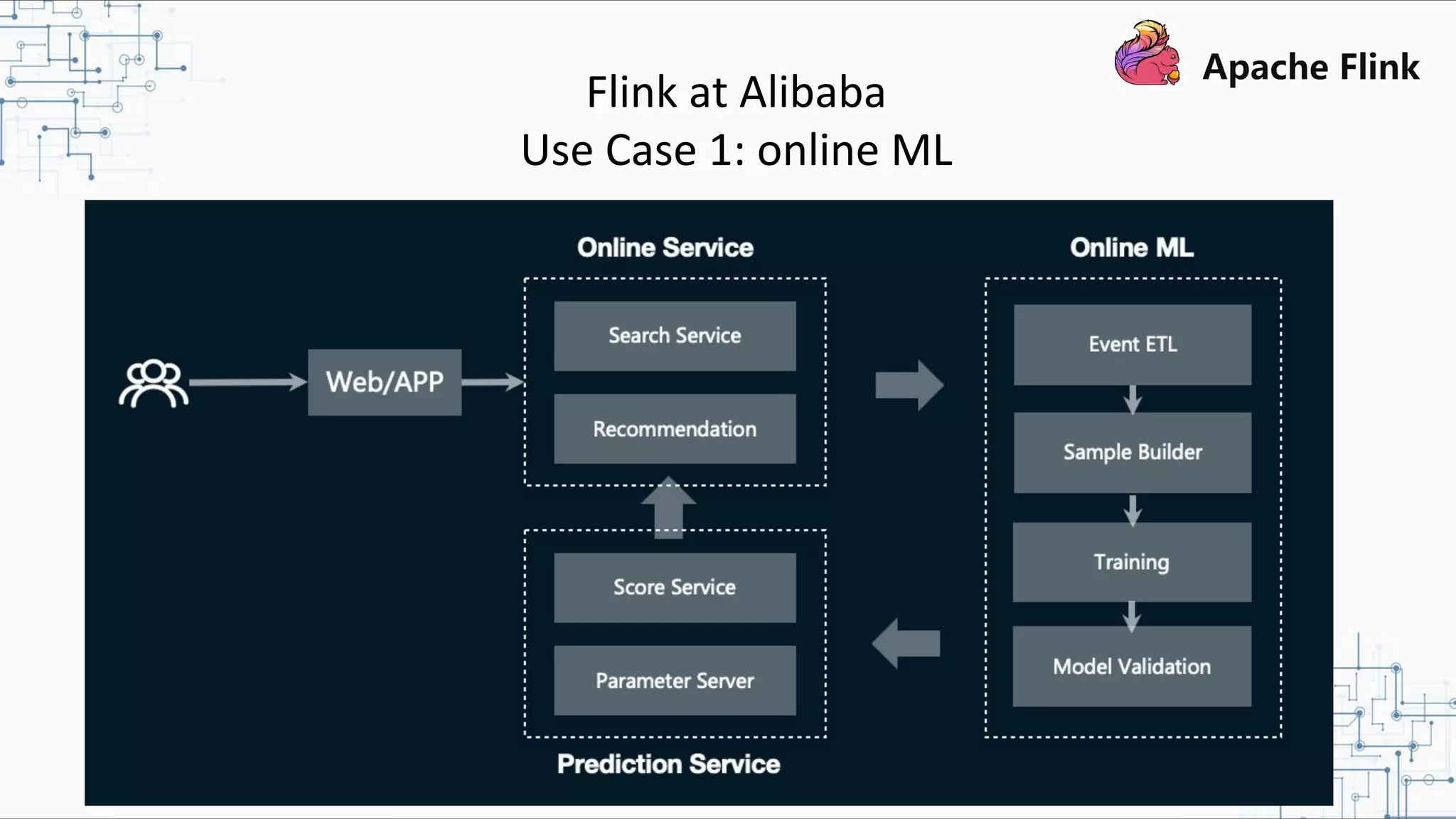
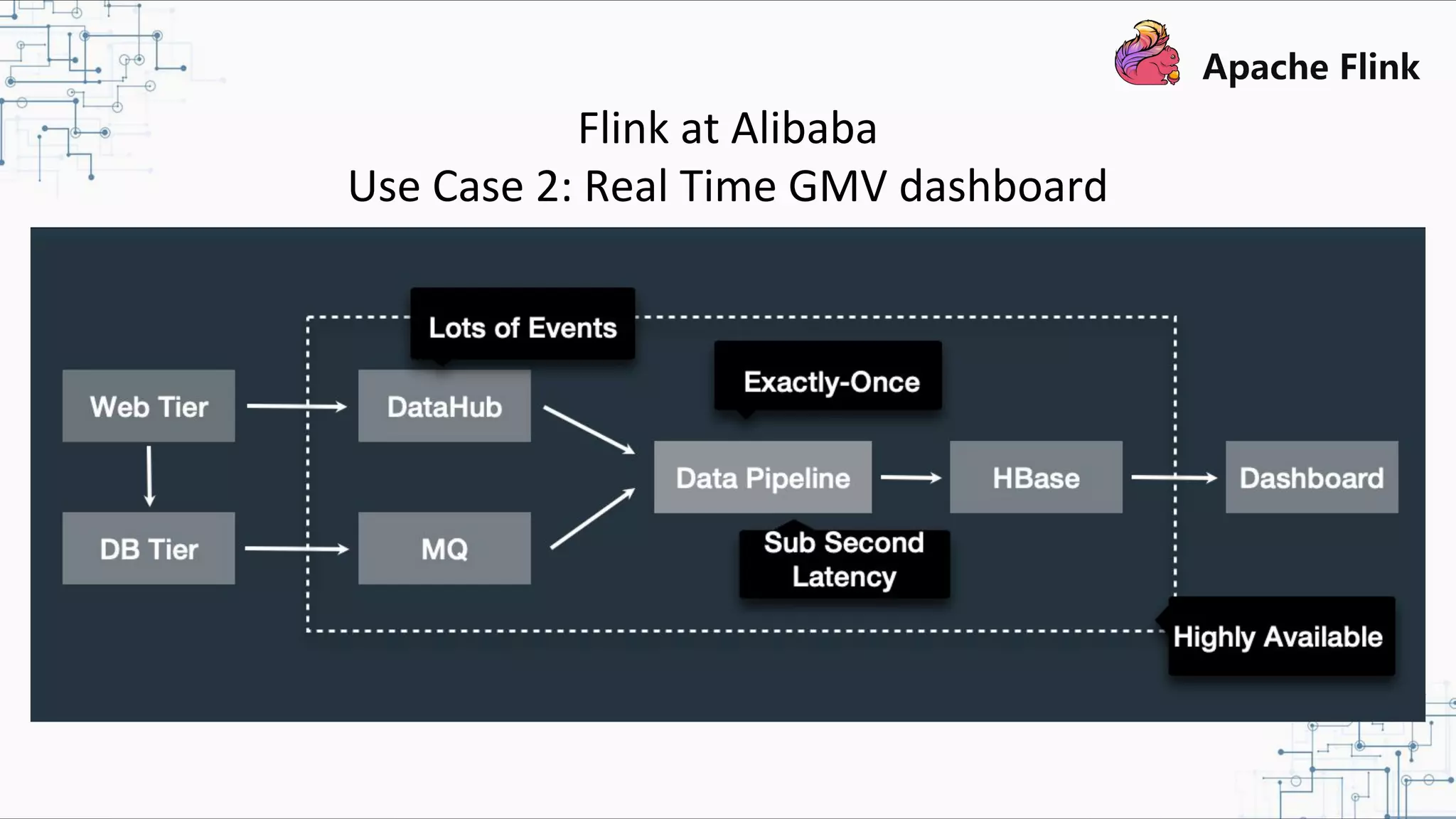
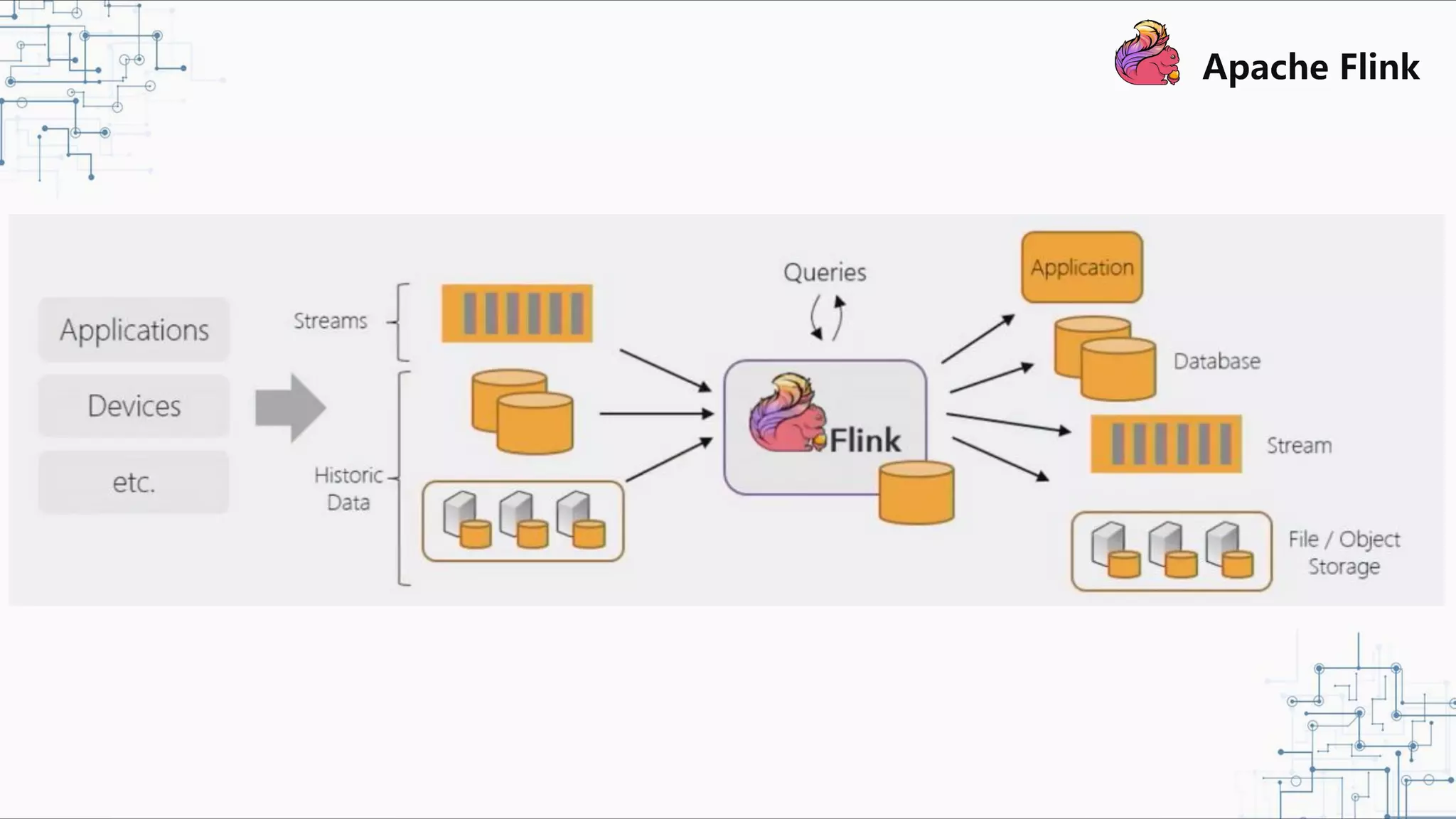
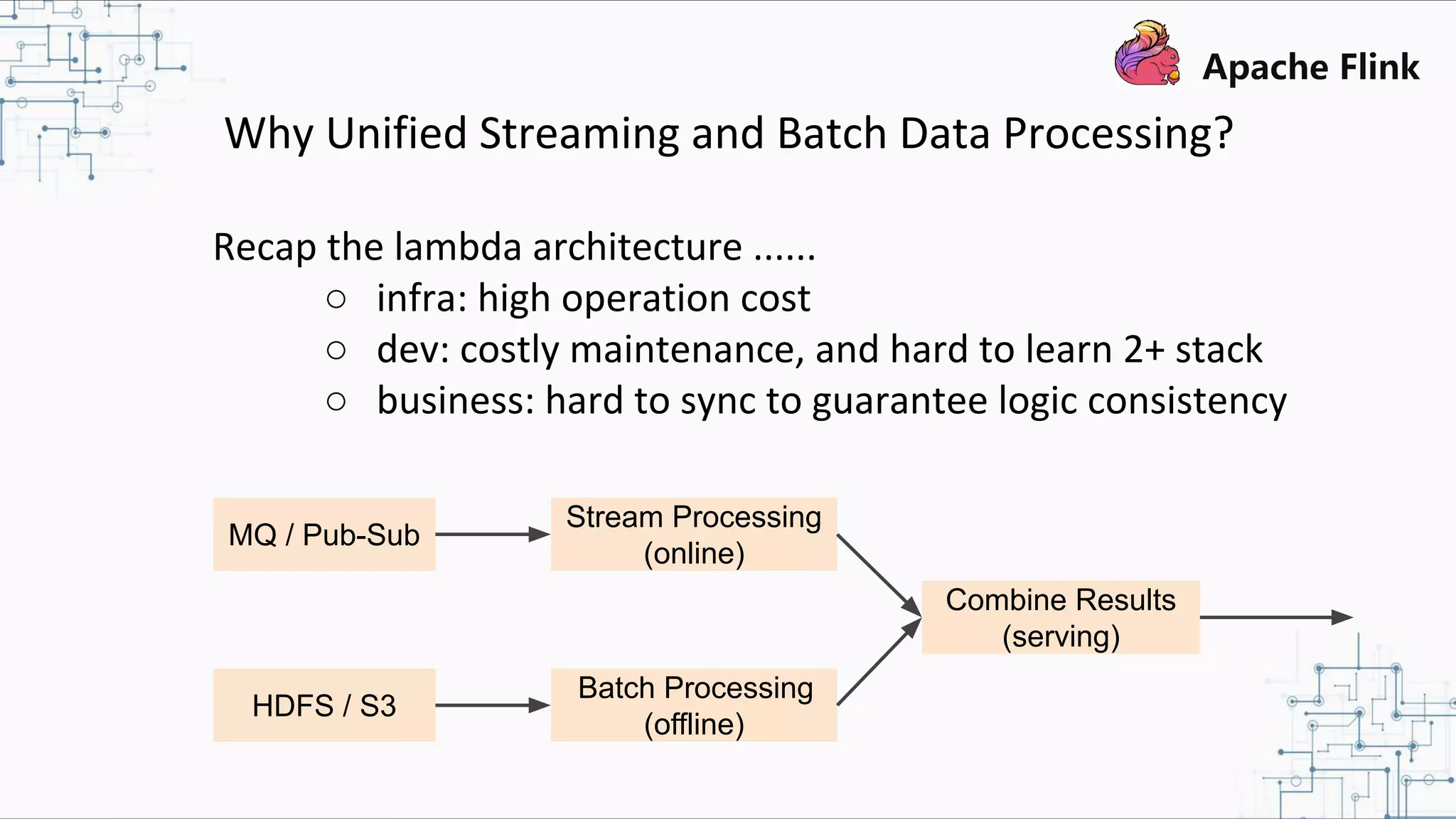
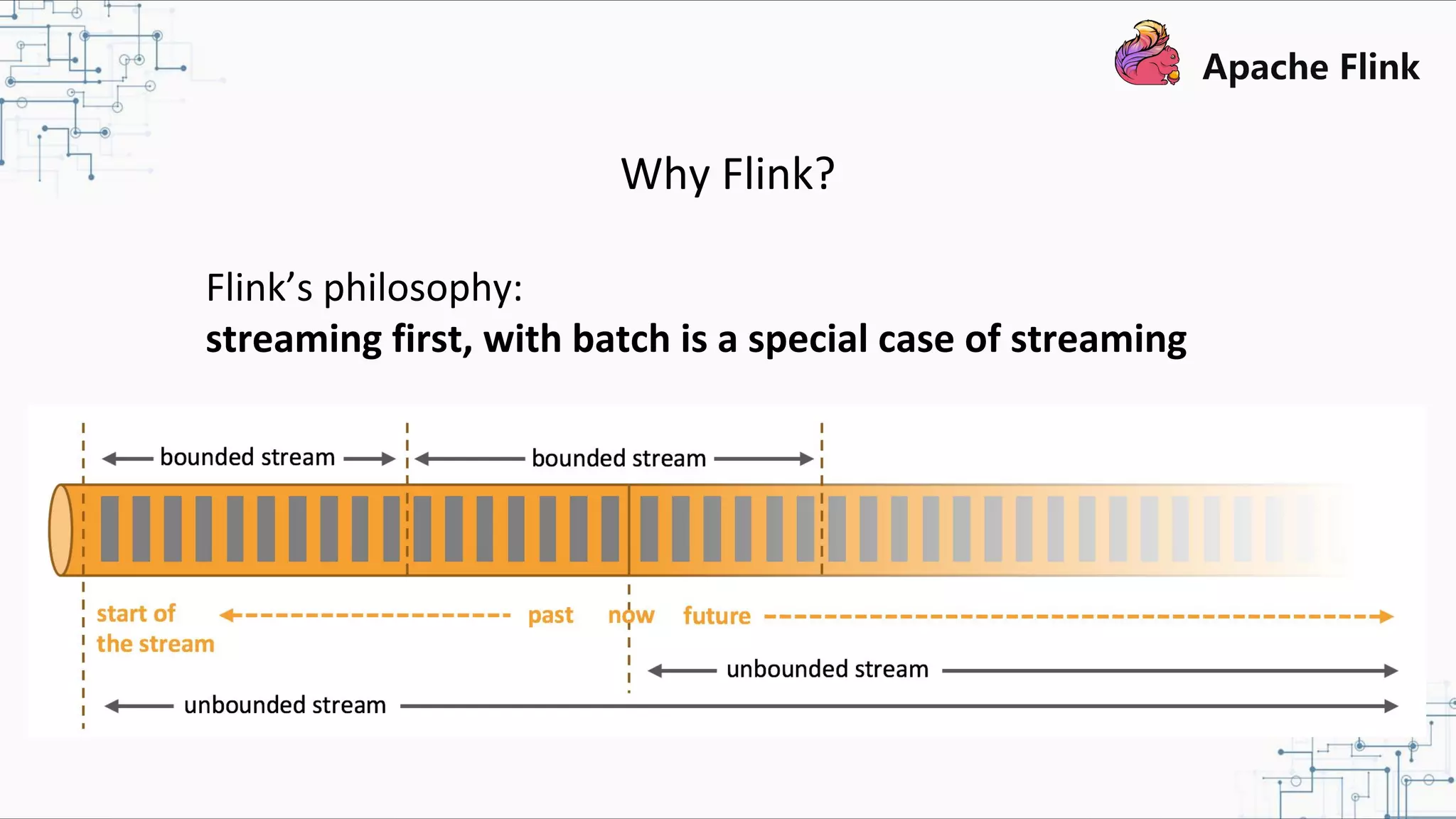
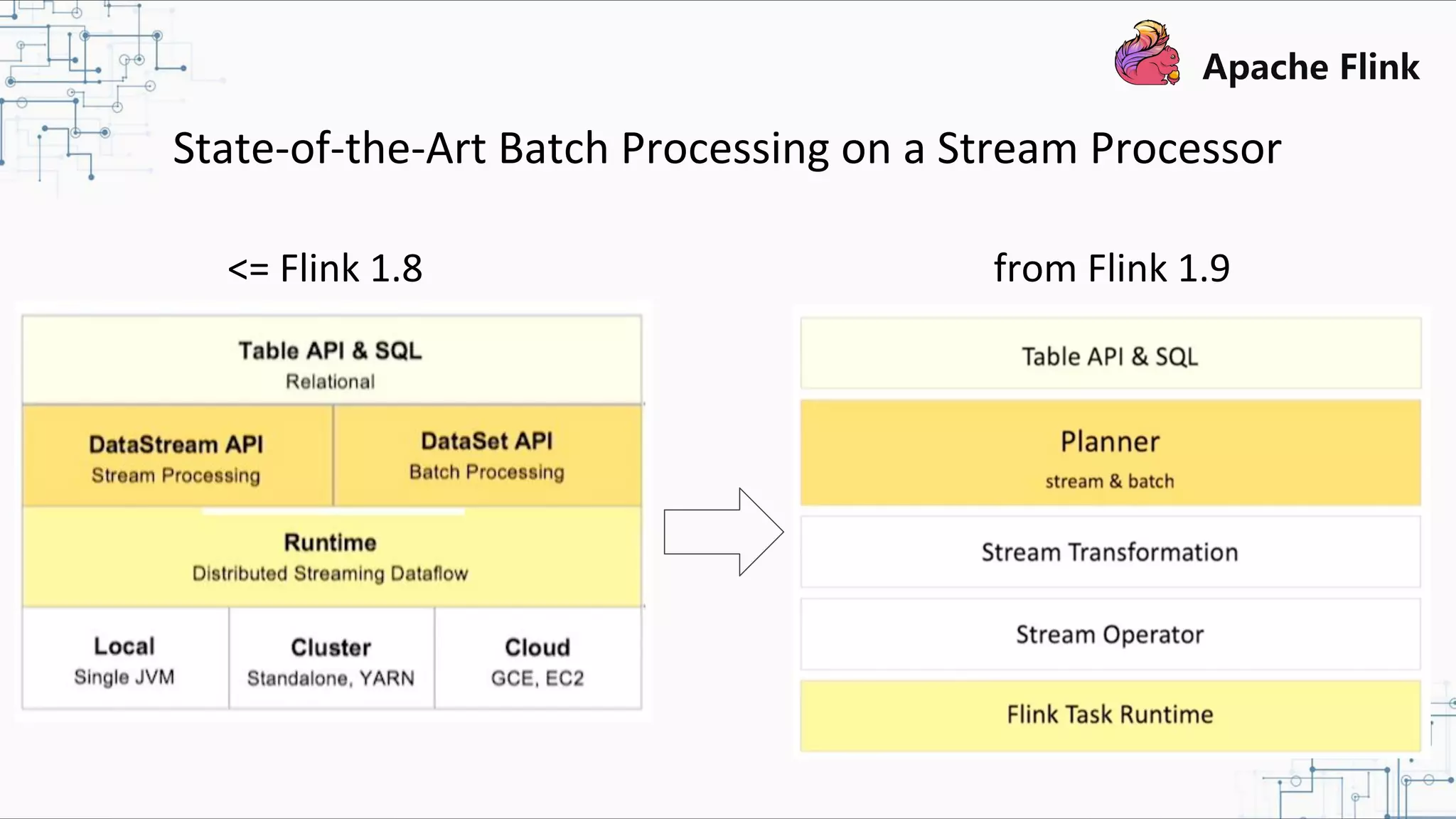
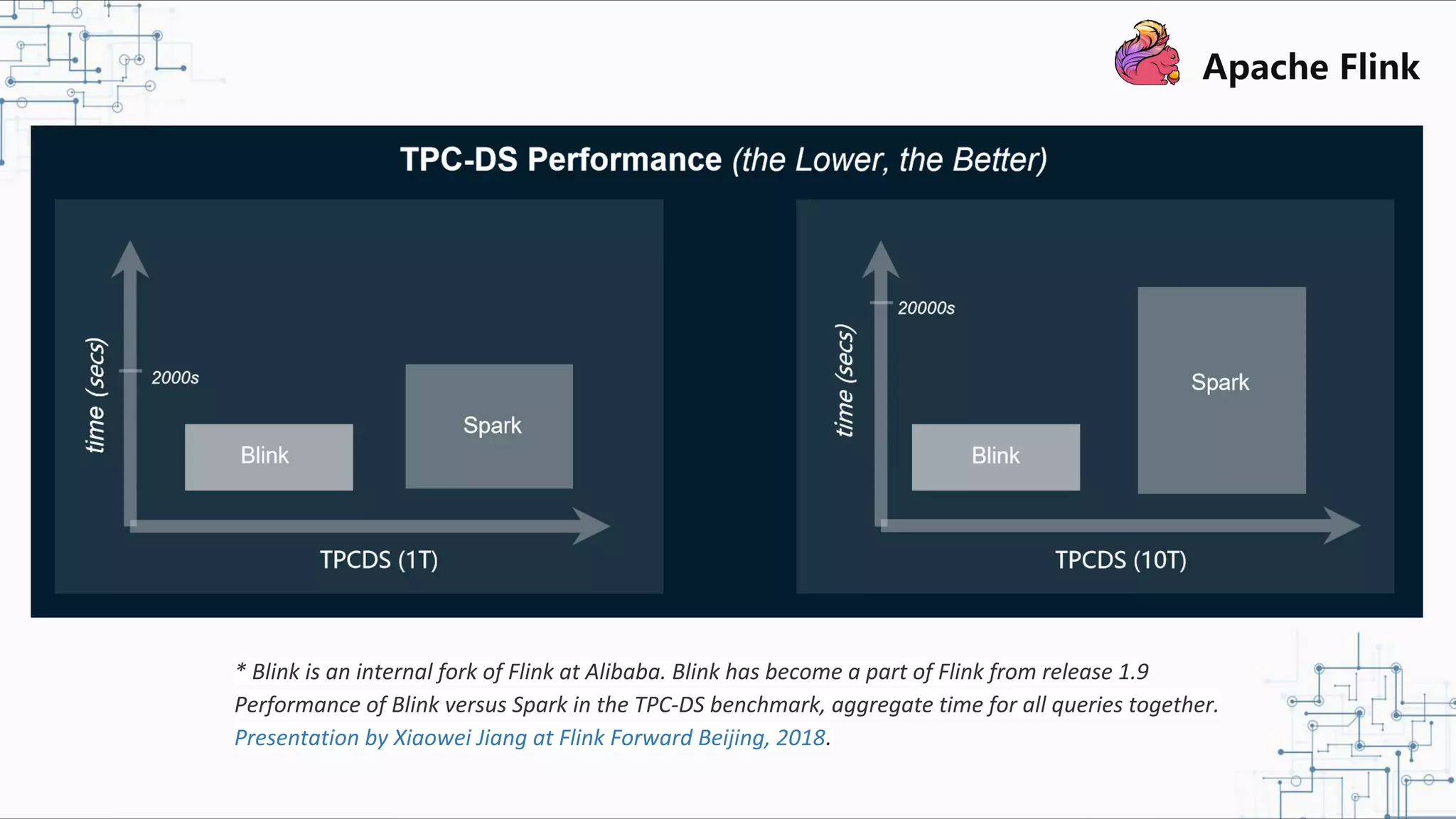
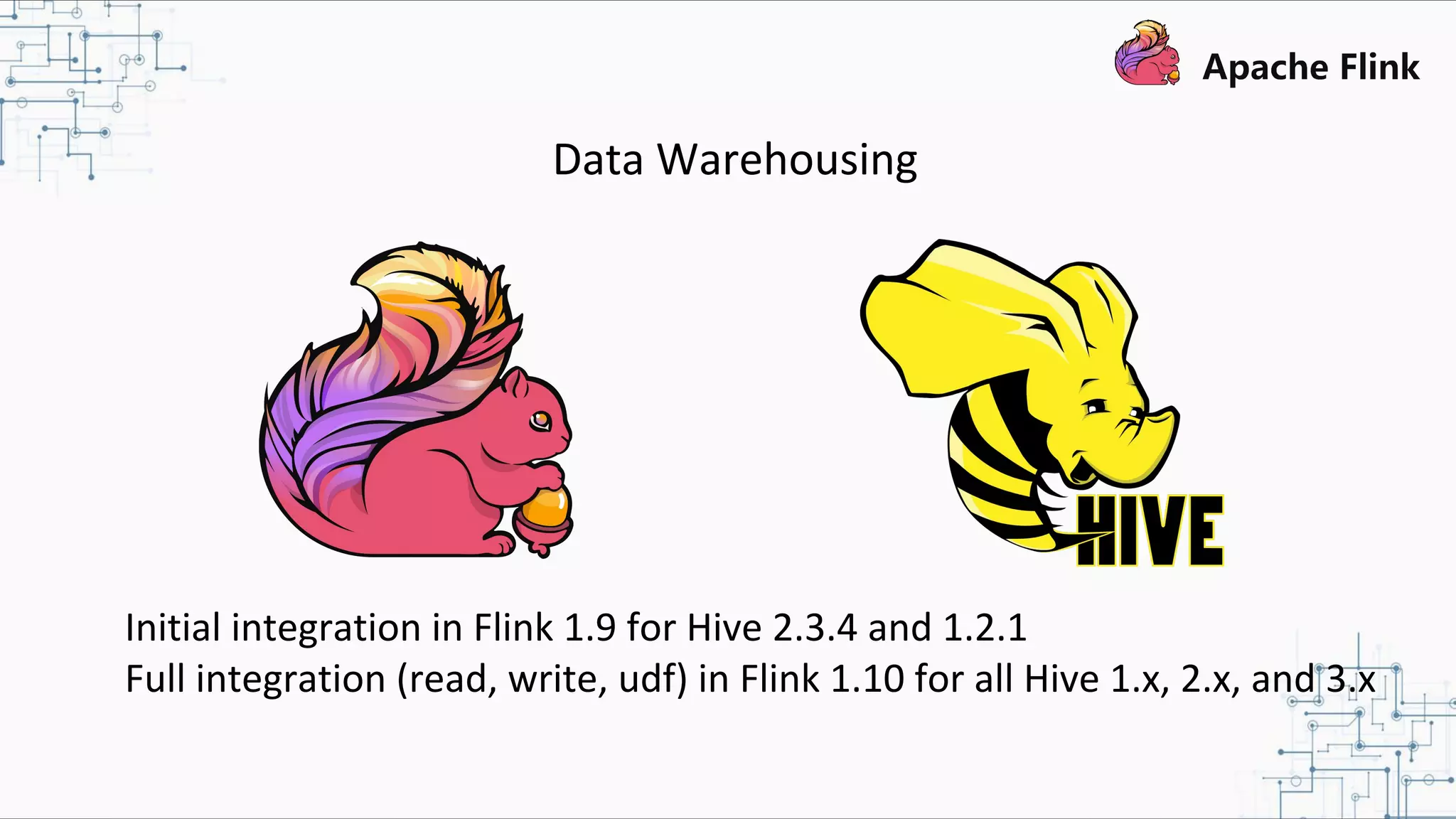
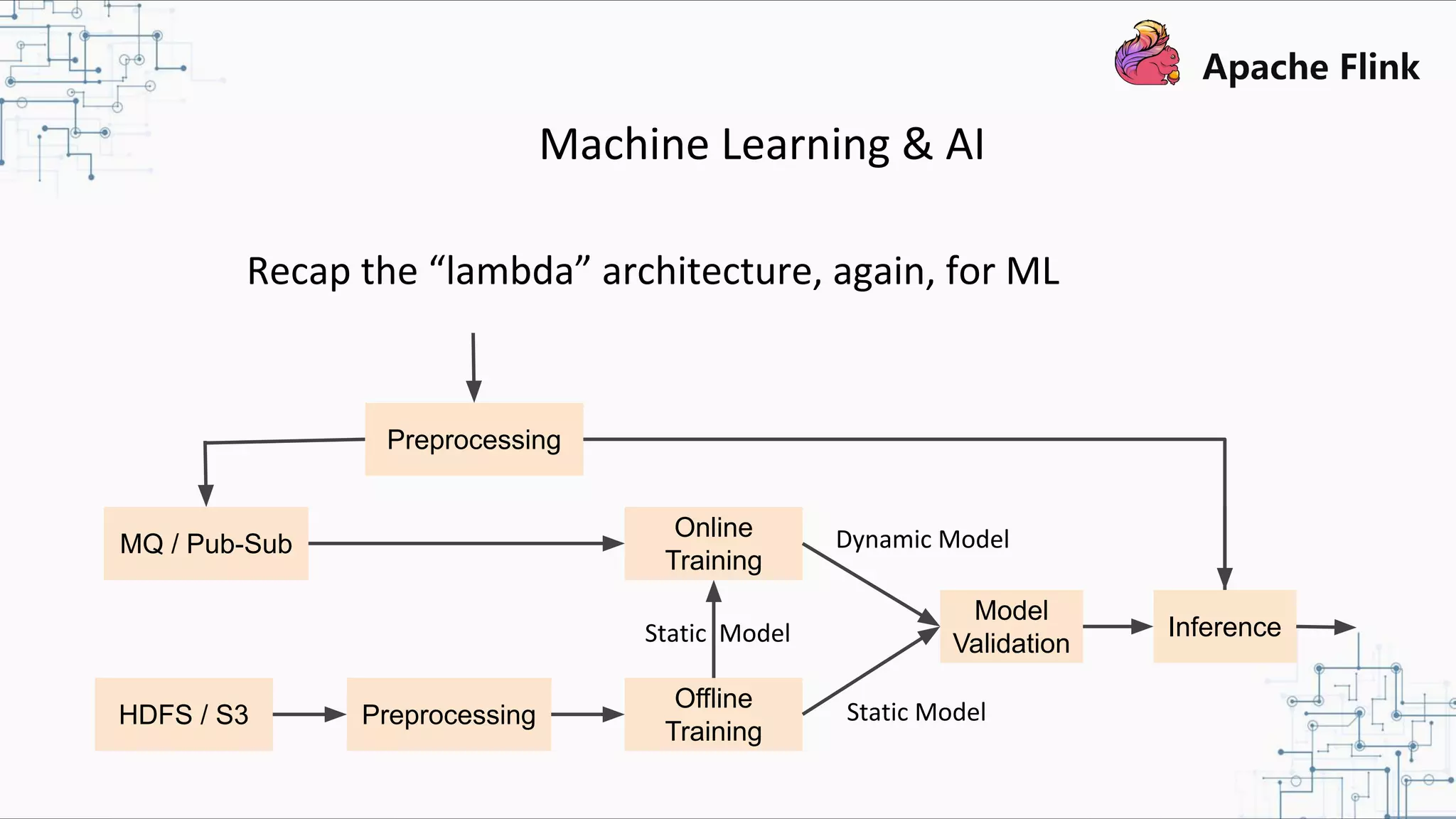
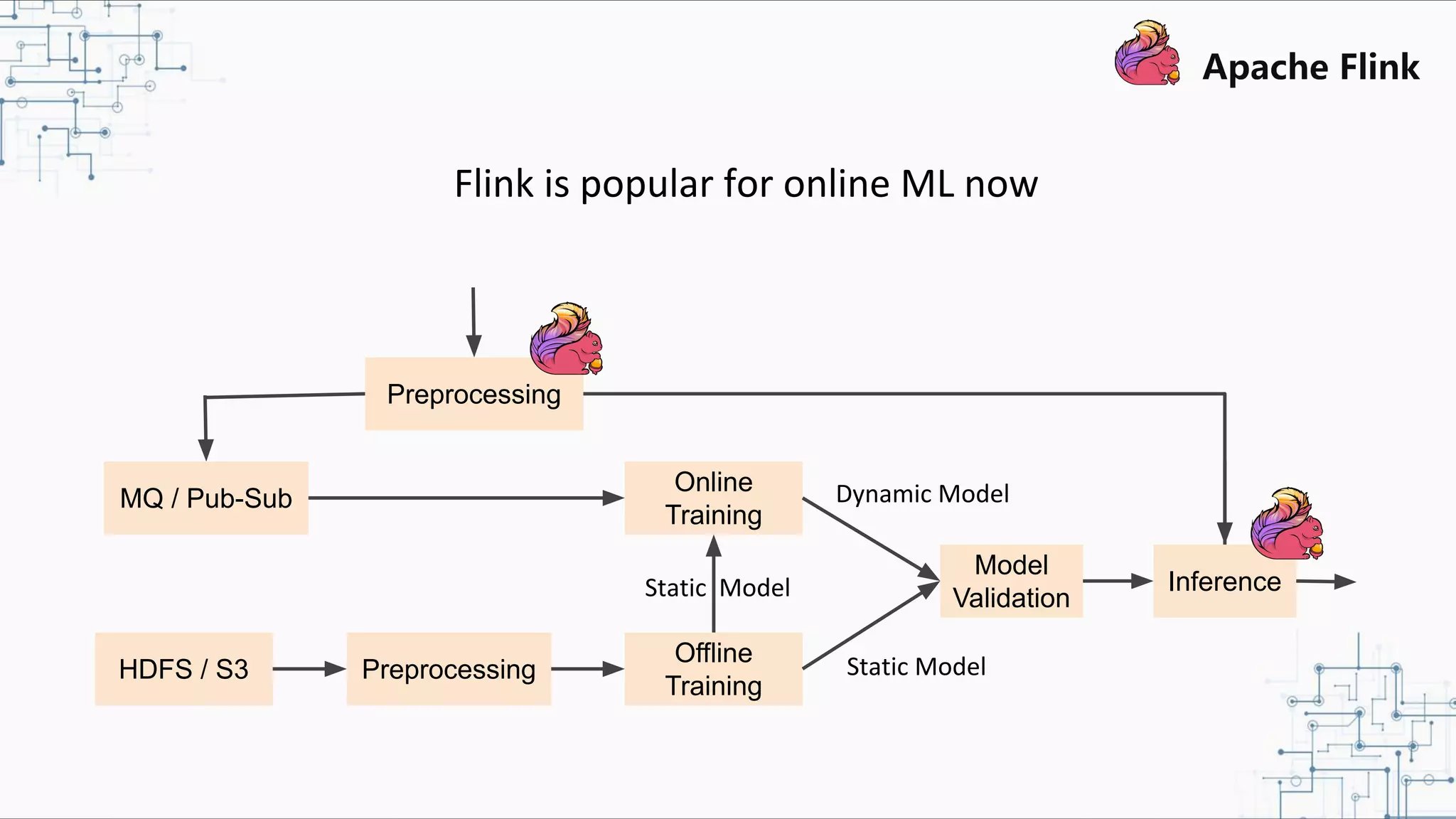
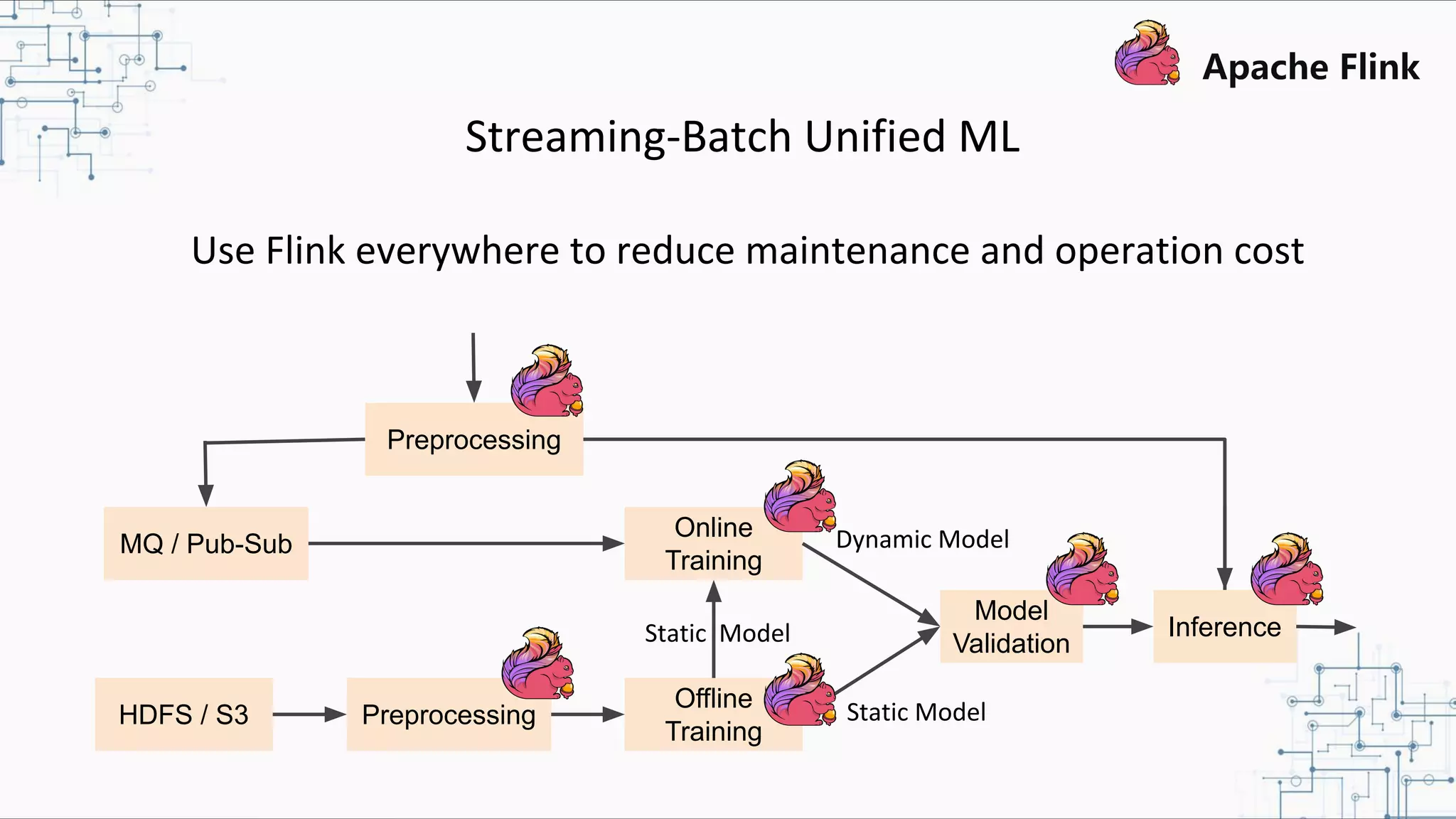
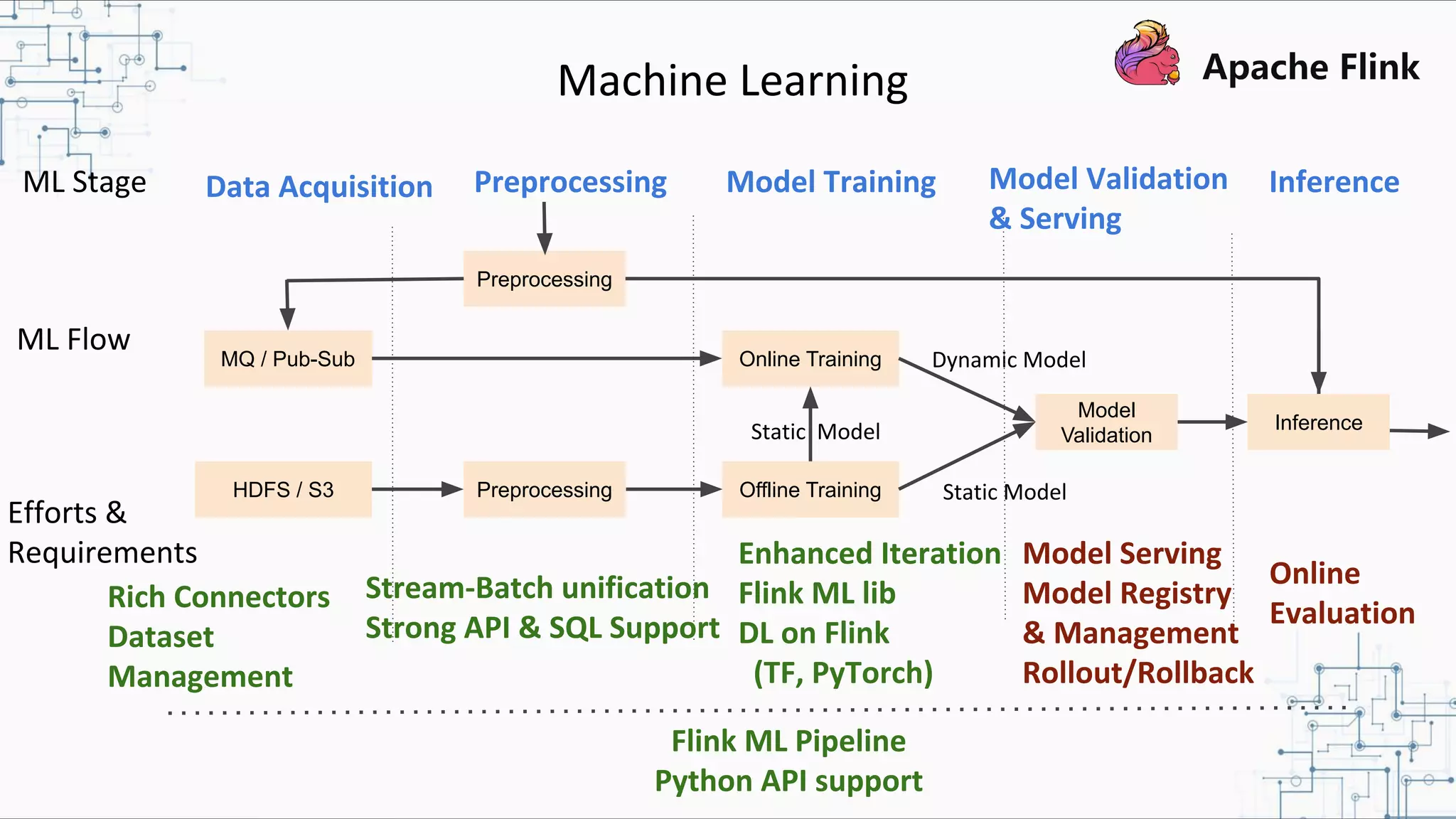
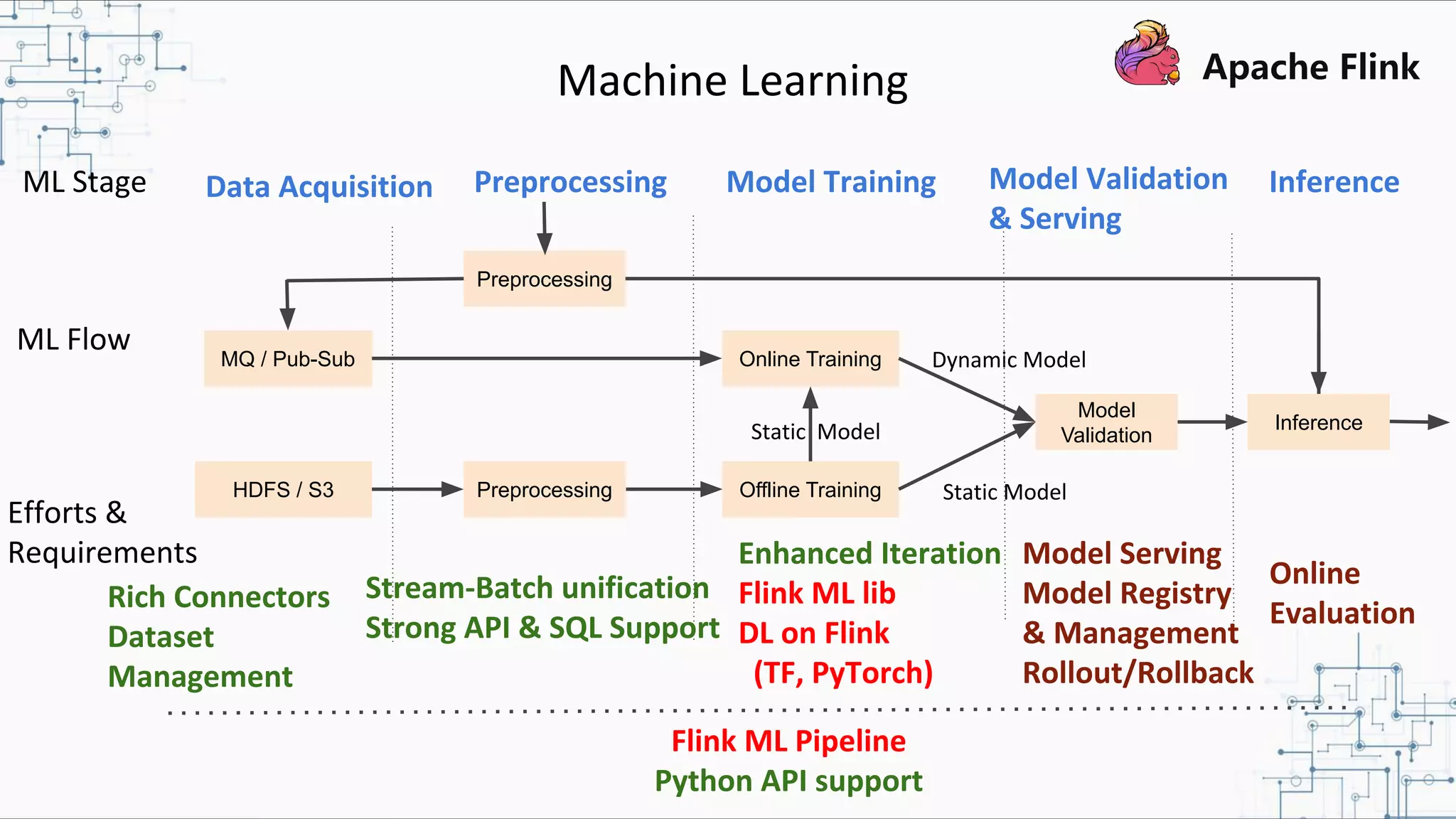
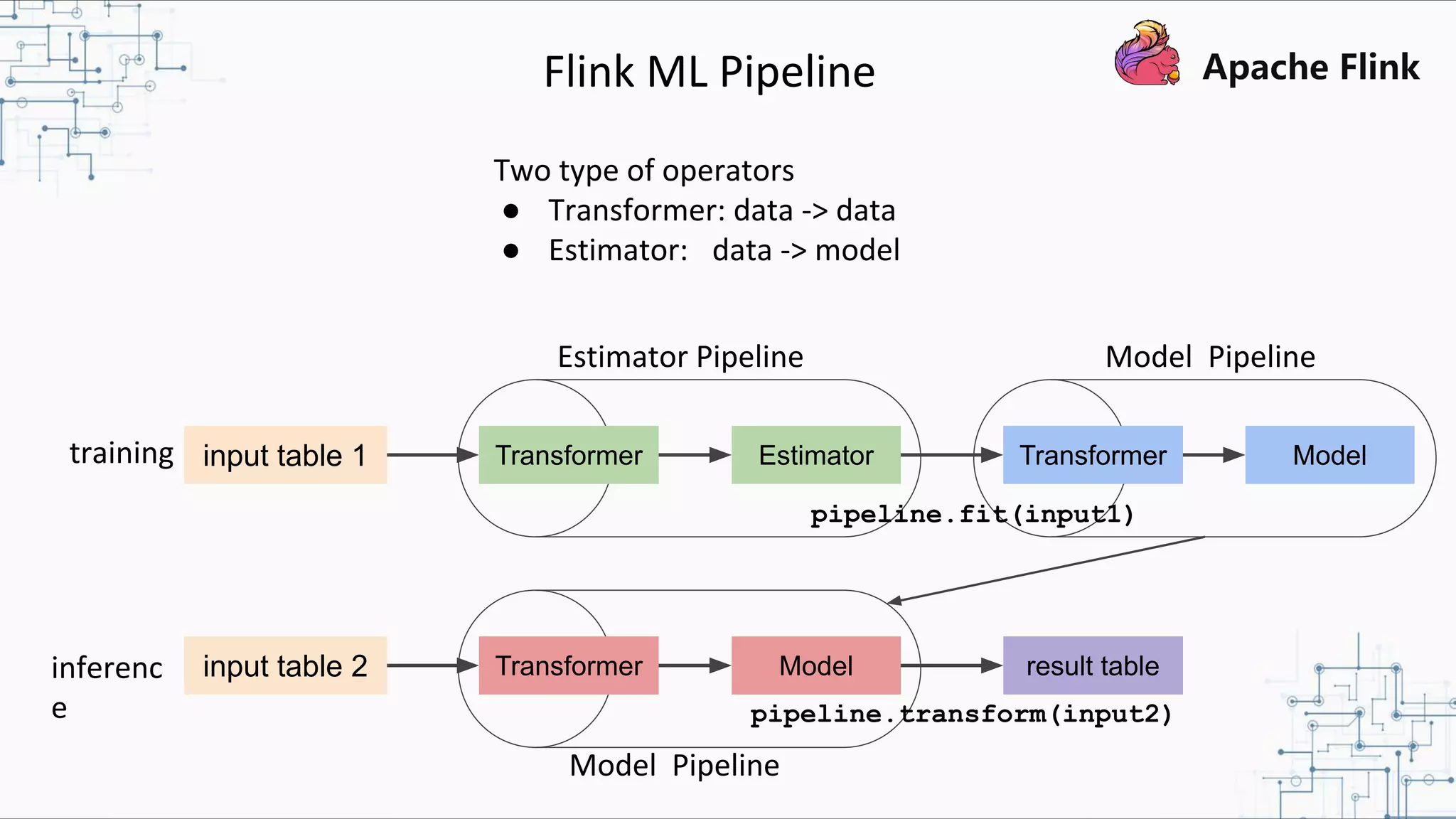
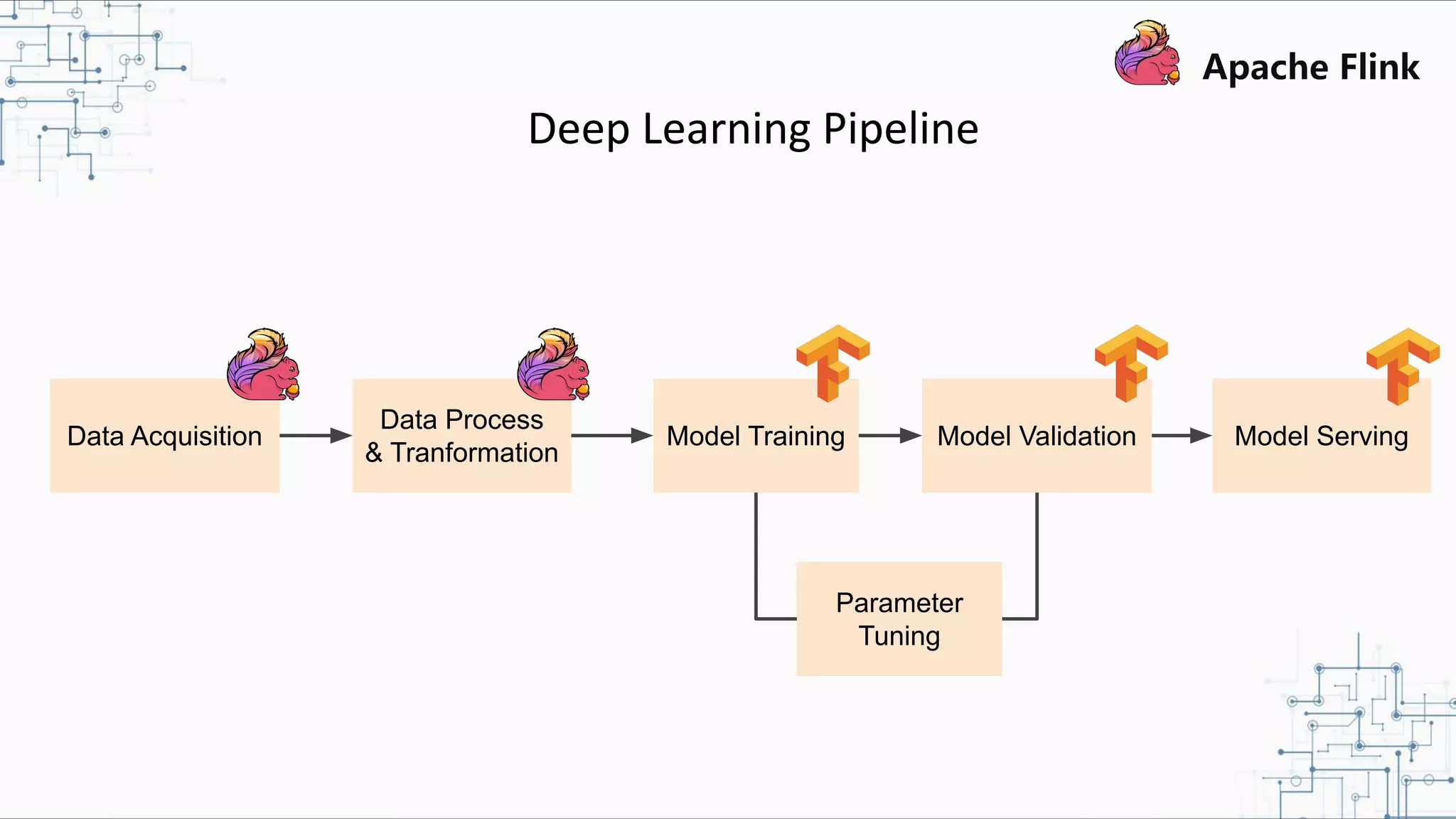
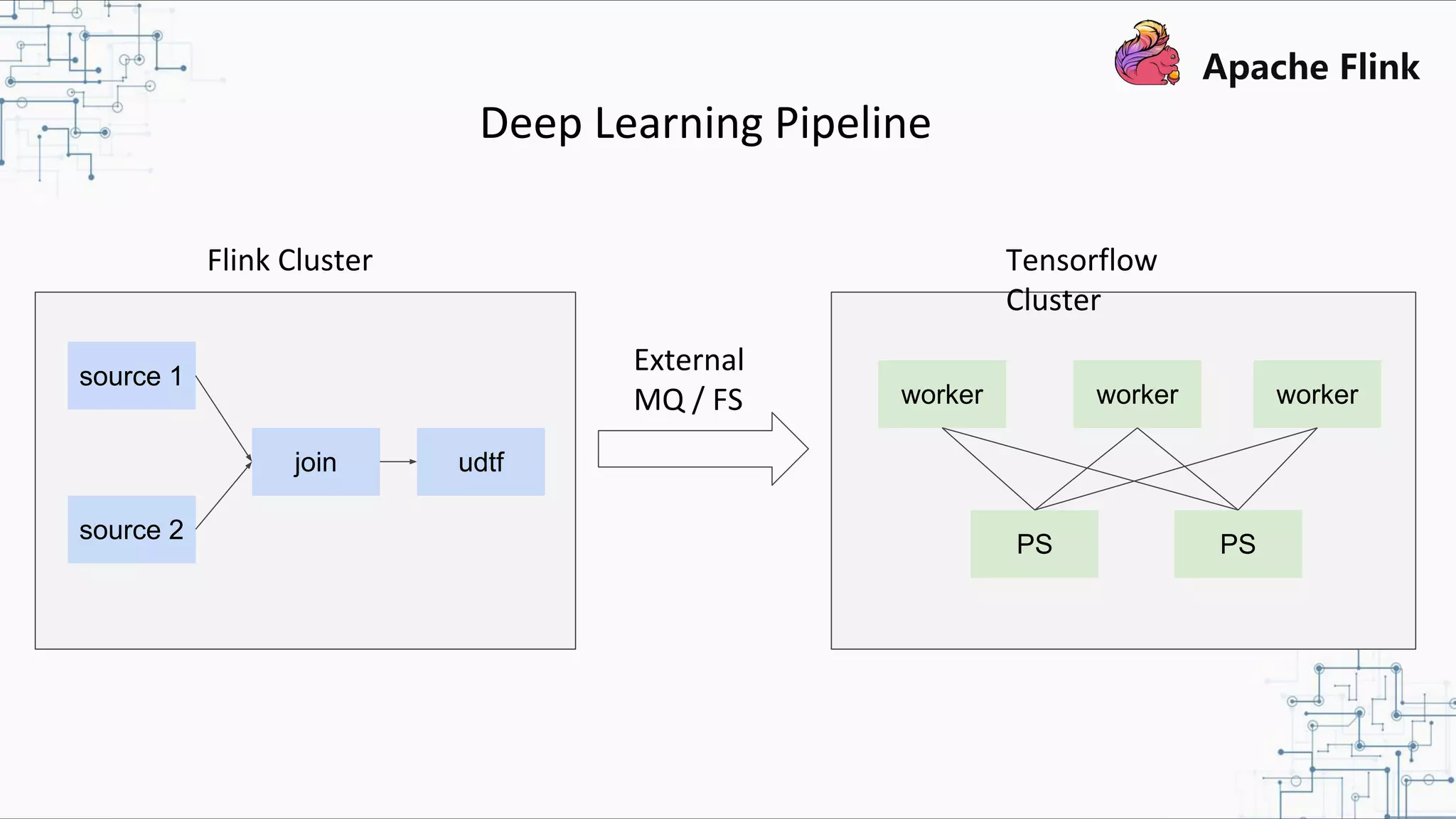
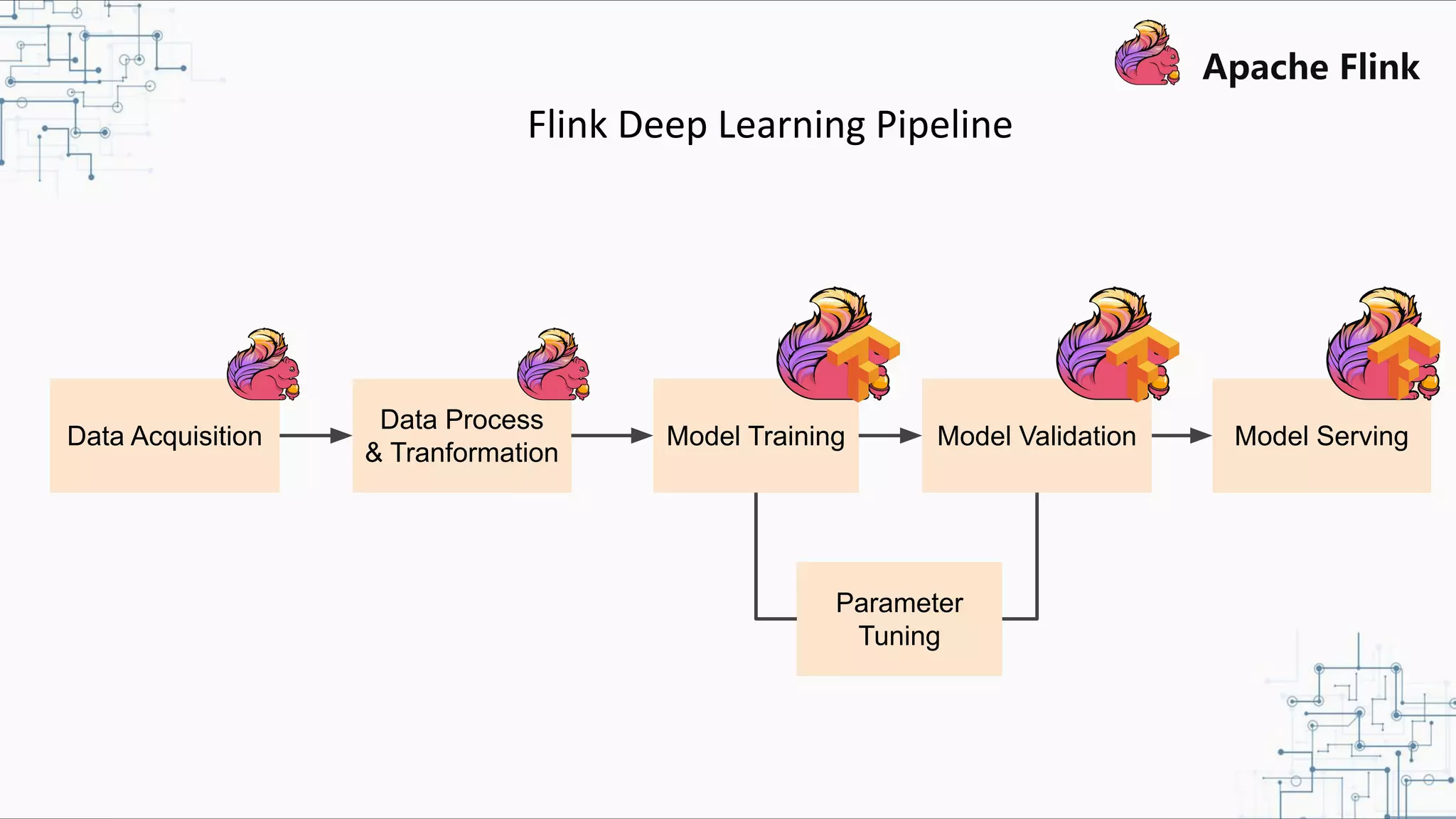
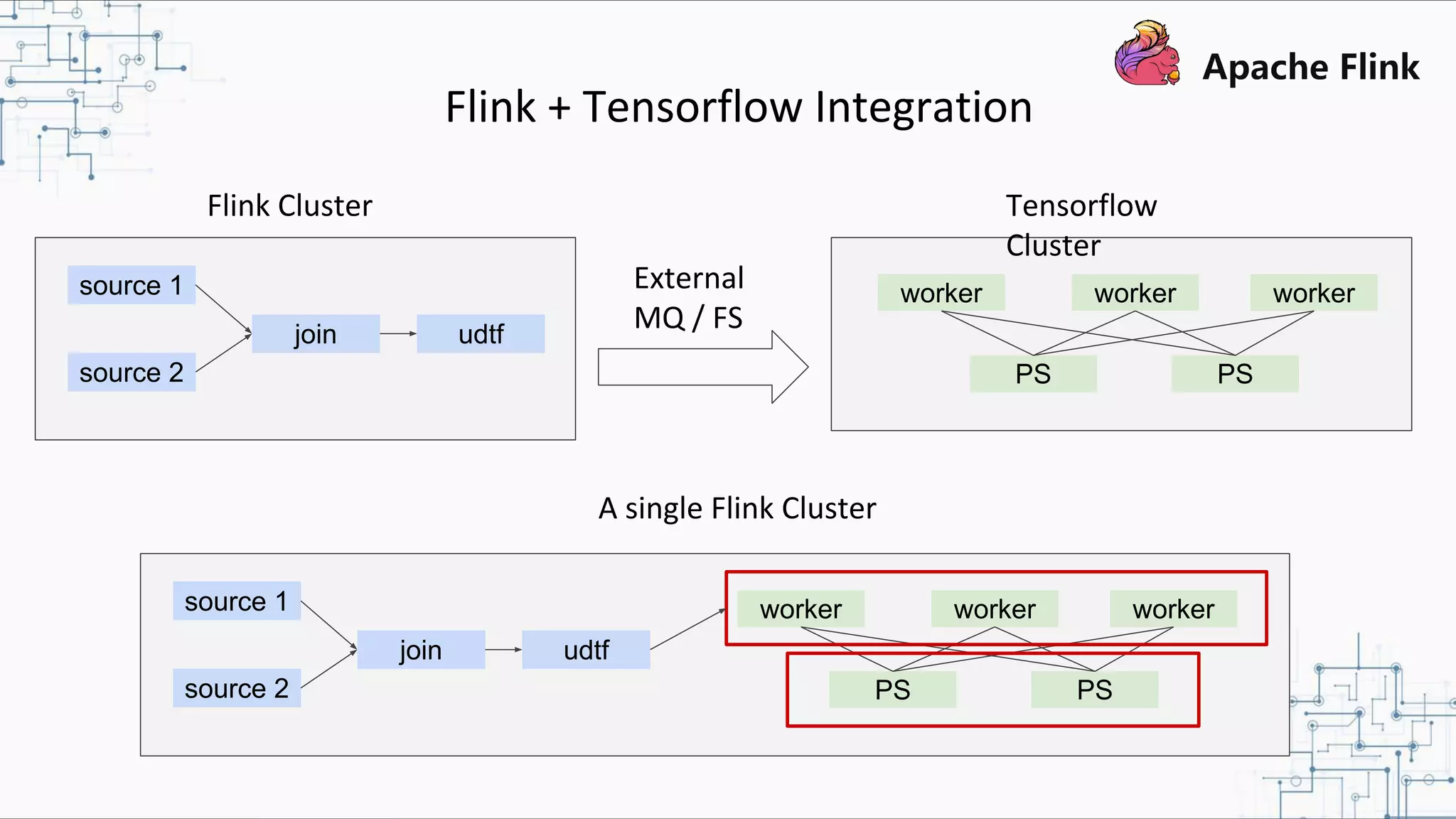
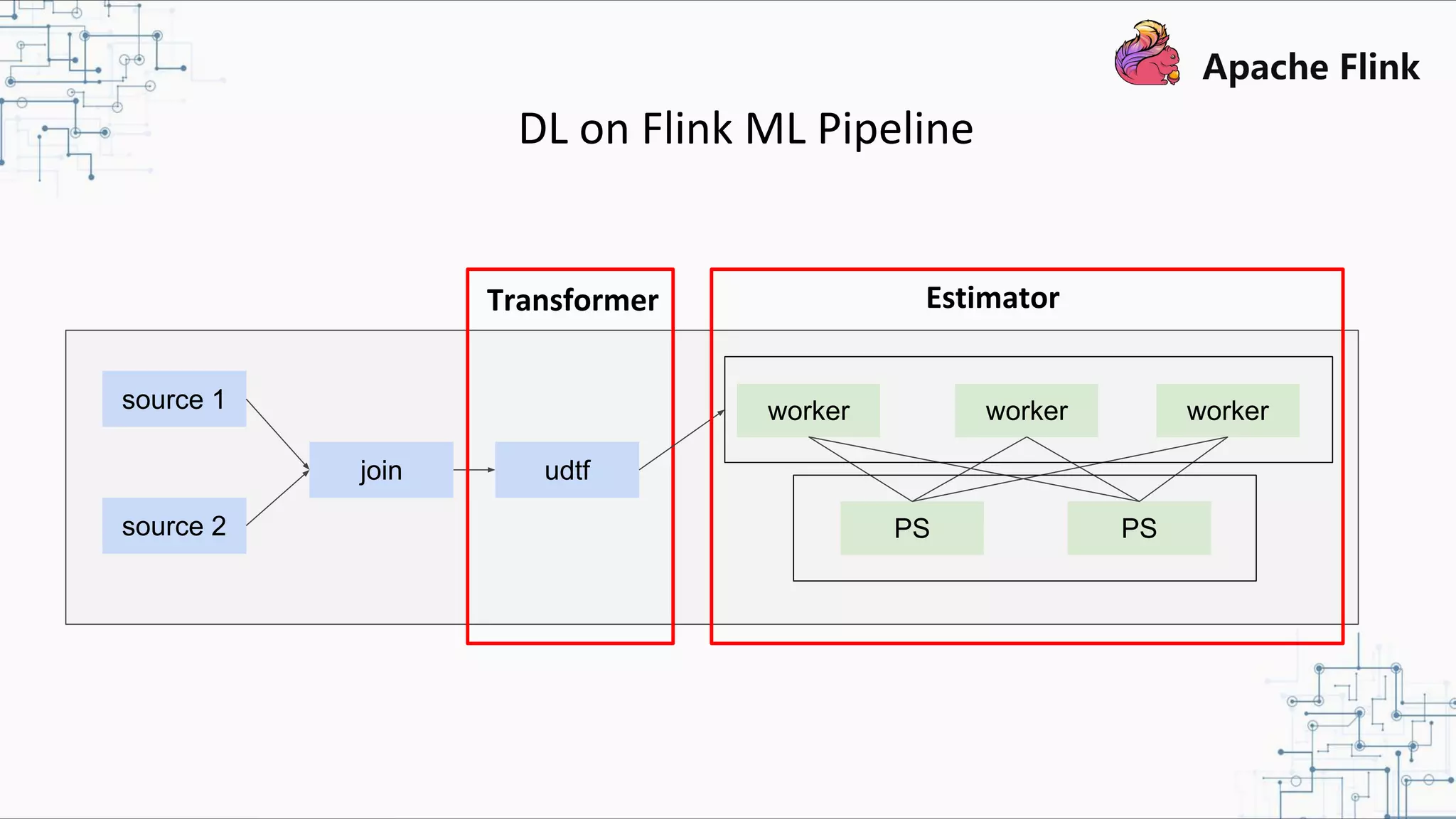
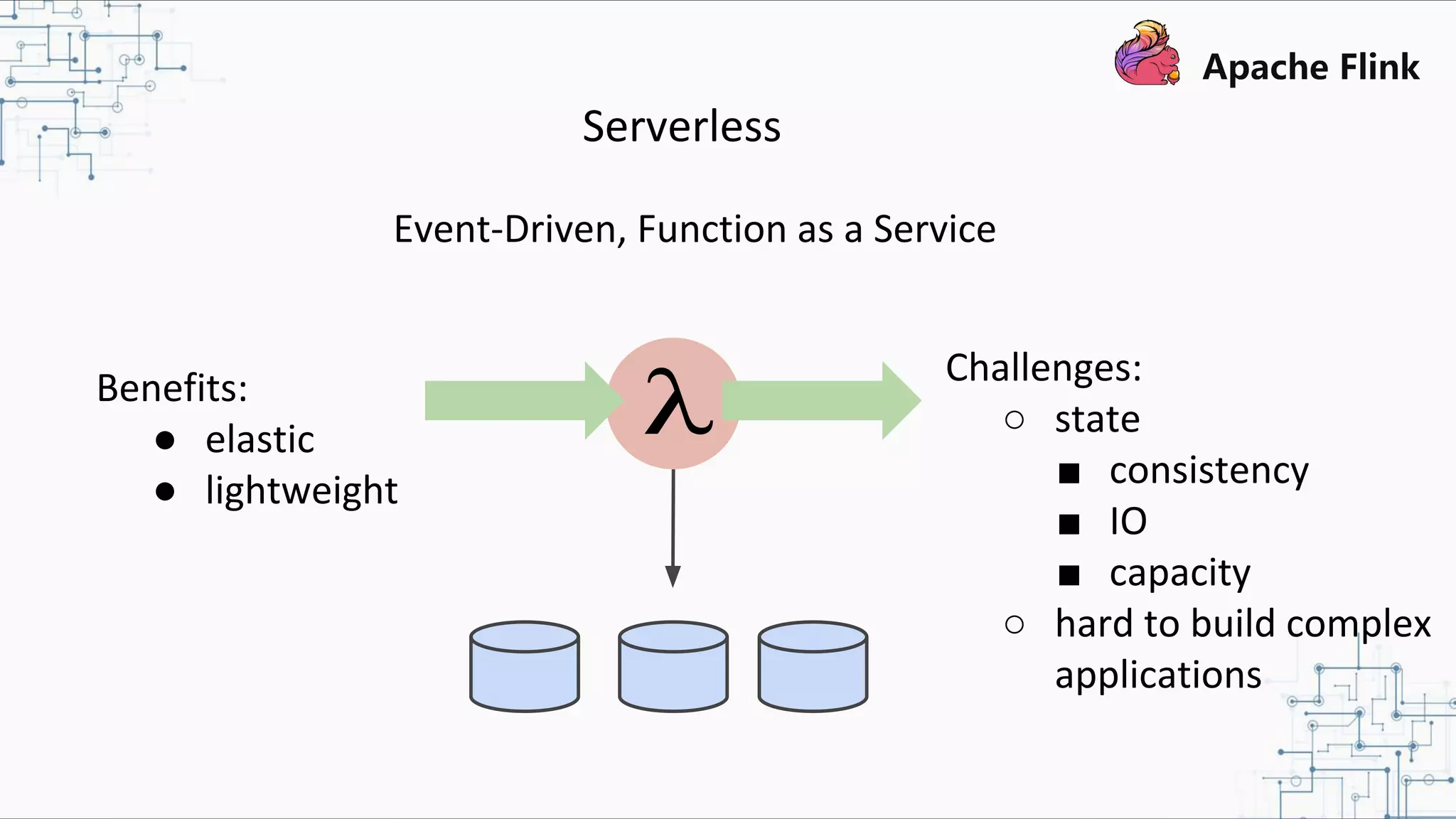
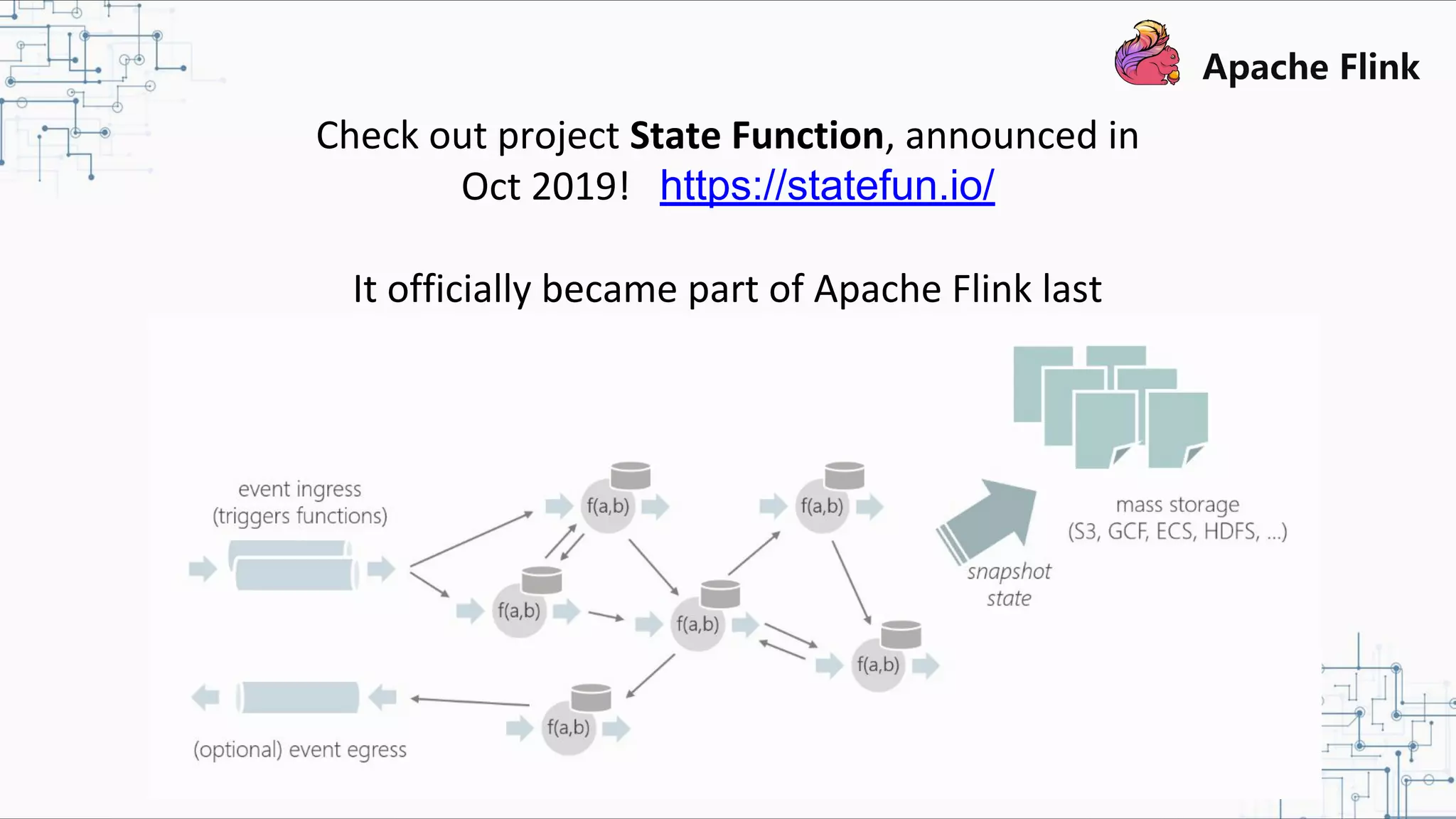
The document discusses Apache Flink 2.0, highlighting its capabilities in unified data processing, including stream and batch processing, and real-time analytics applications at Alibaba. It details how Flink supports various use cases such as online machine learning and real-time dashboards, emphasizing its stateful computations and fault-tolerant architecture. Additional insights cover the integration of Flink with machine learning frameworks and the potential of serverless event-driven functionalities.