Downloaded 119 times












![Words as vectors (Embeddings) list → [human, cow] → int list [0, 1] → embeddings [(2,2), (4,0)]](https://image.slidesharecdn.com/deeplearningwithtensorflowunderstandingtensorscomputationsgraphsimagesandtext-160614151136/75/Deep-Learning-with-TensorFlow-Understanding-Tensors-Computations-Graphs-Images-and-Text-28-2048.jpg)
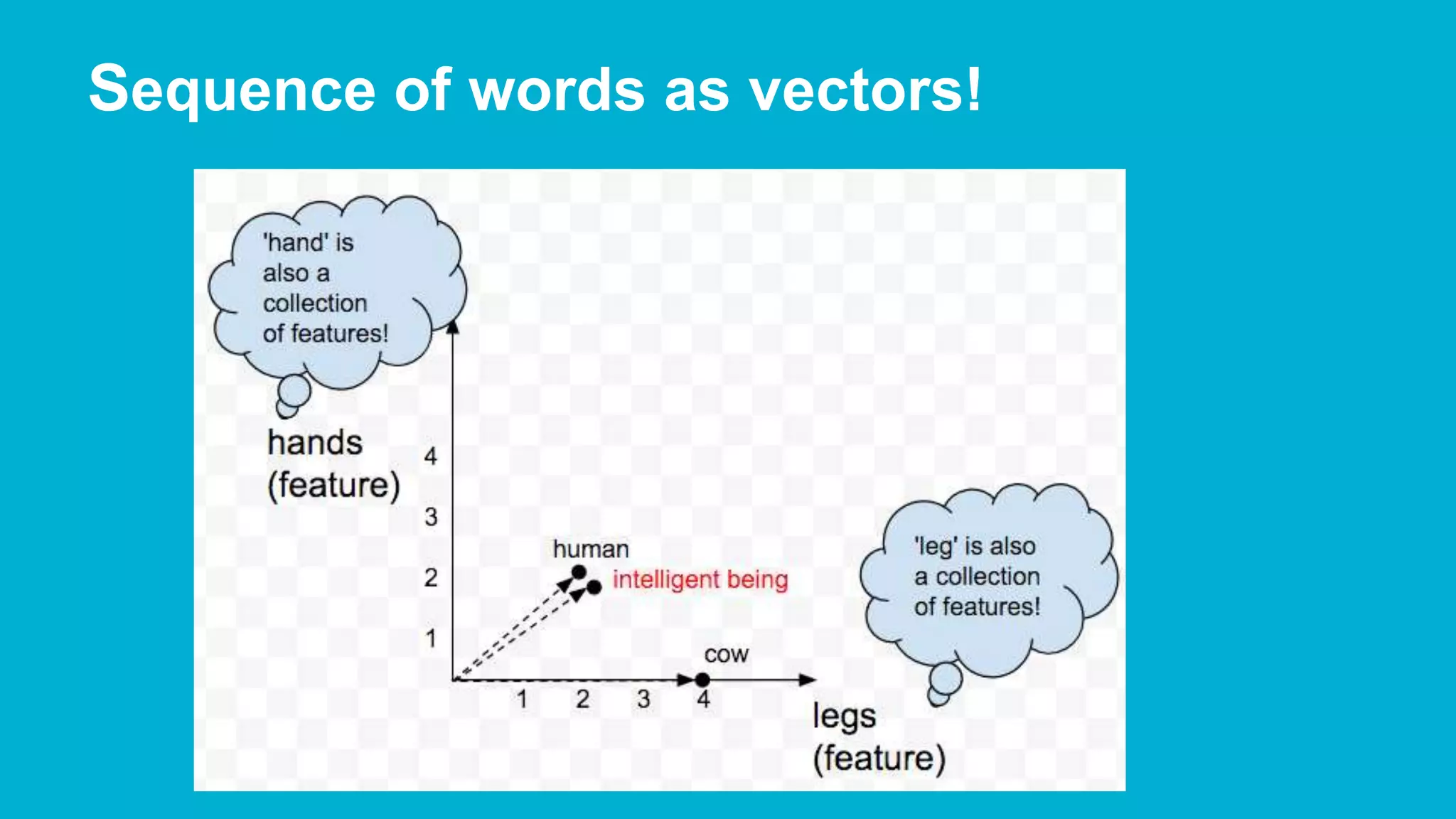





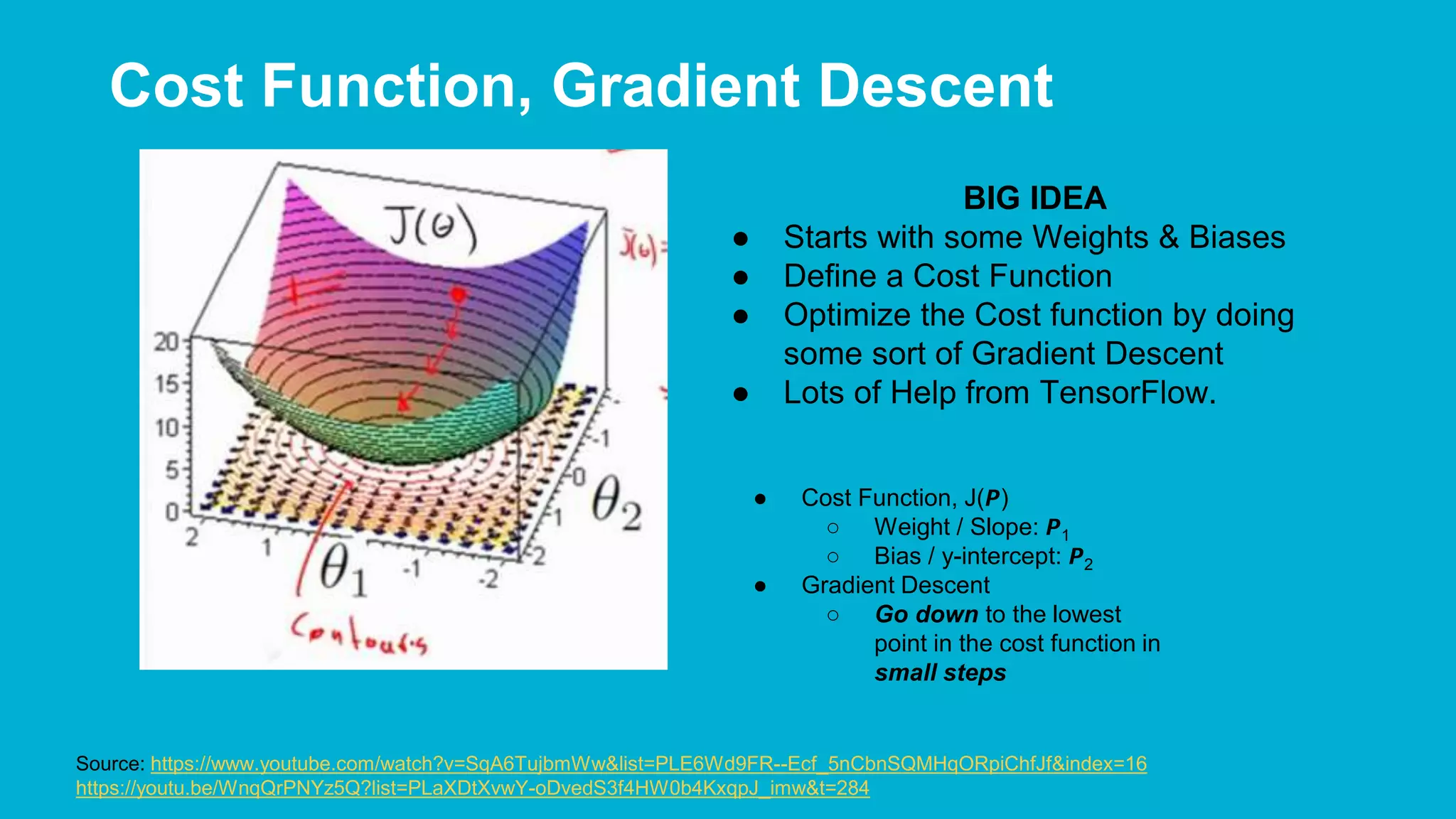
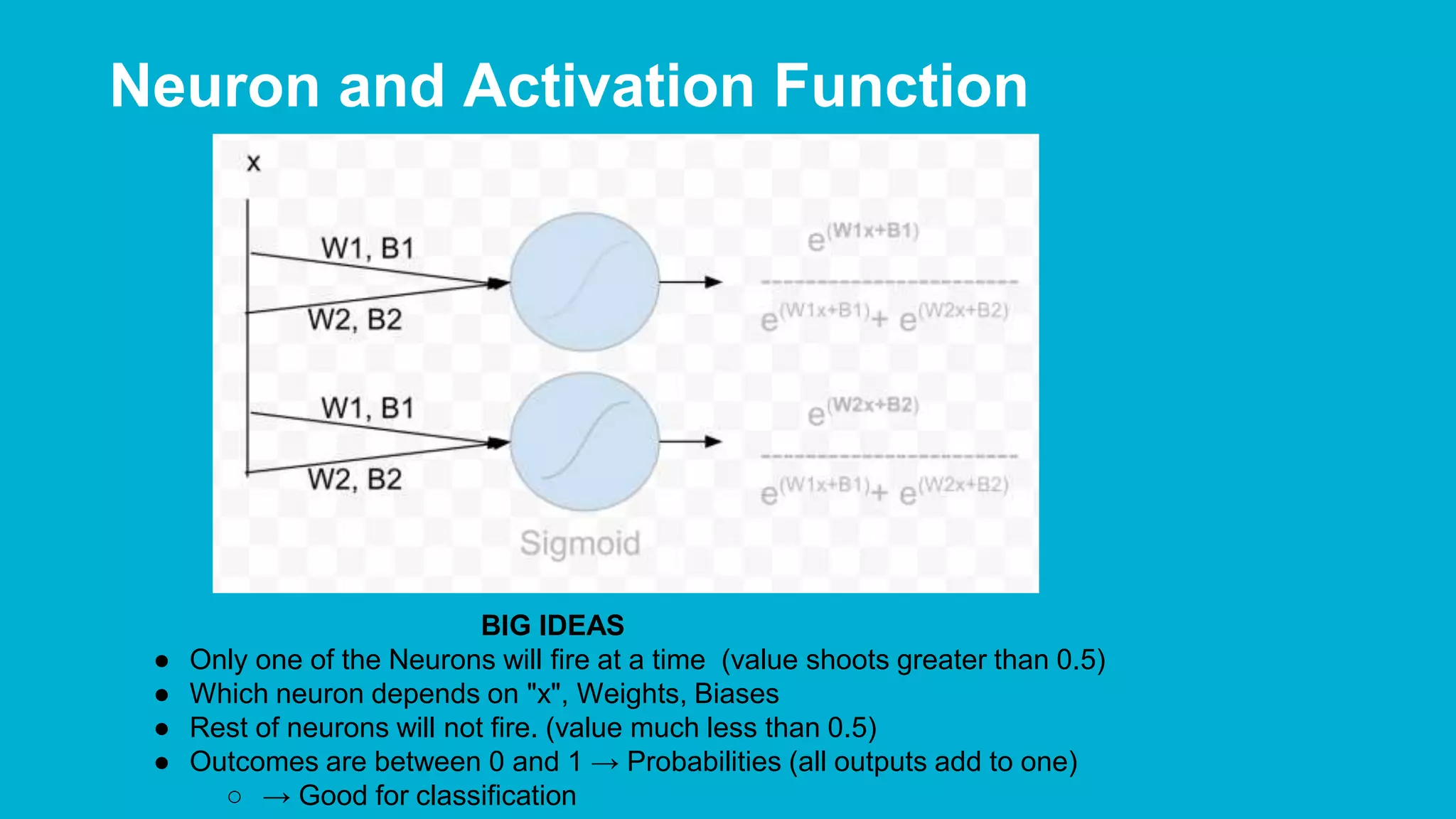
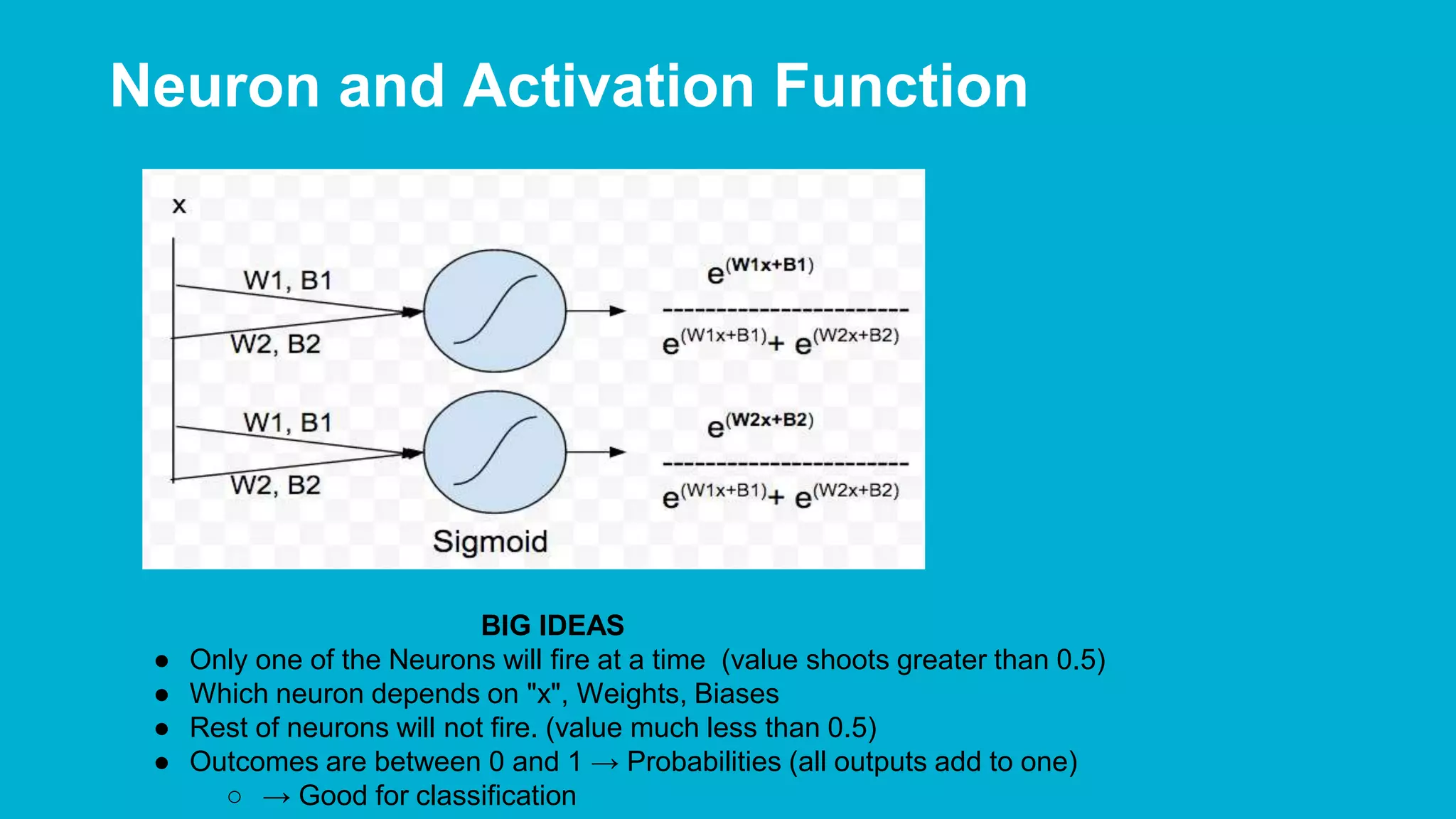
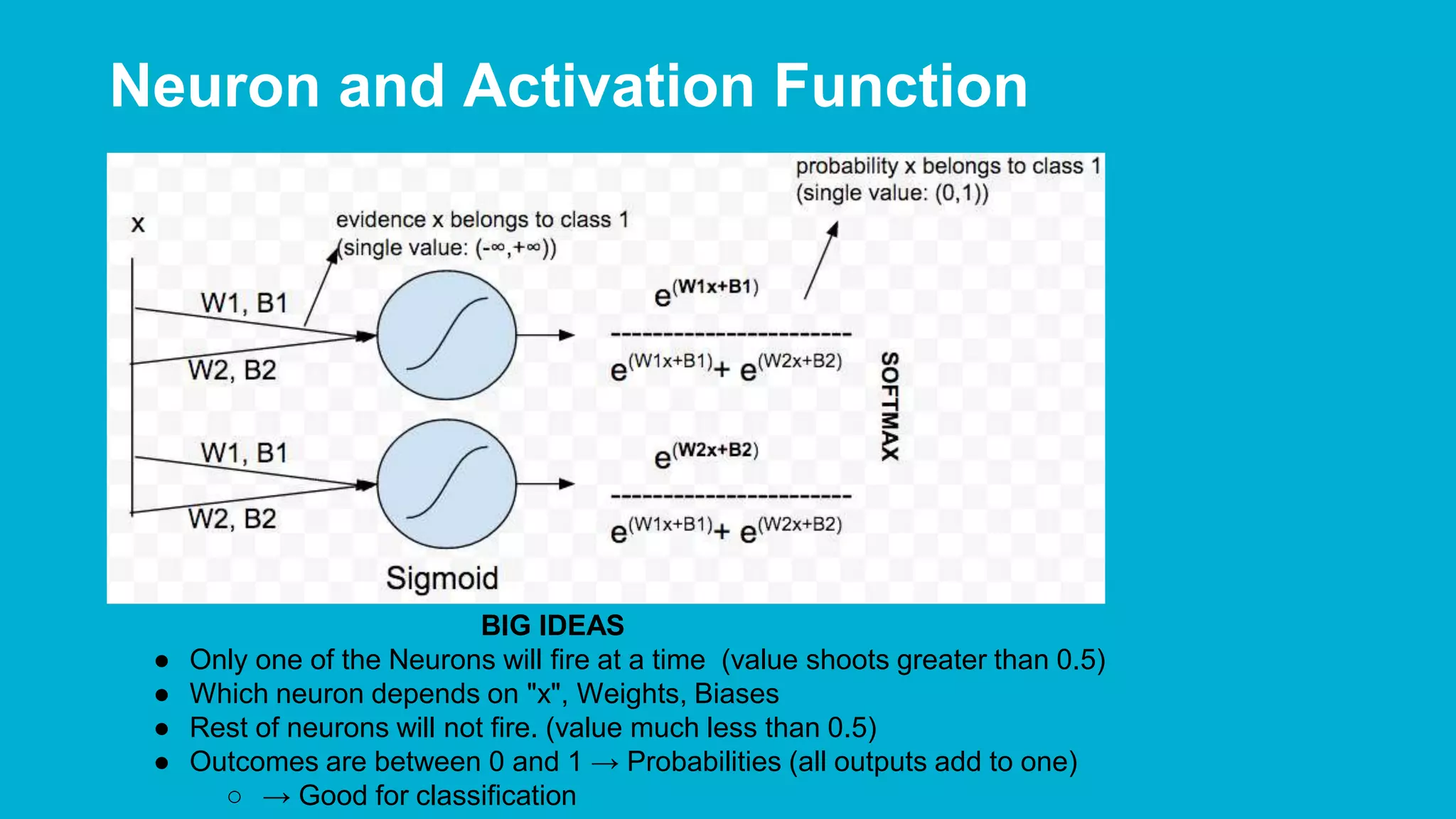
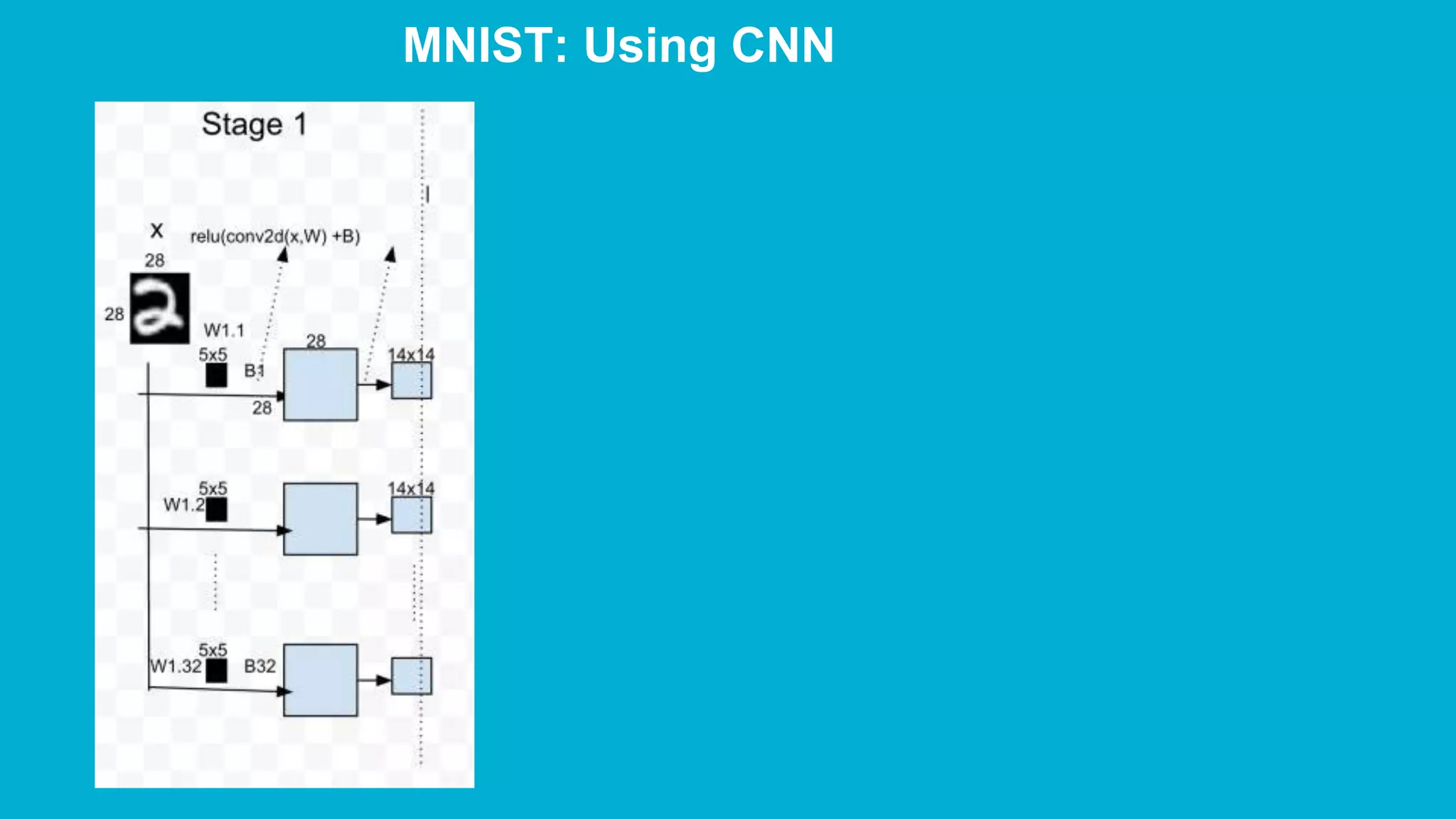
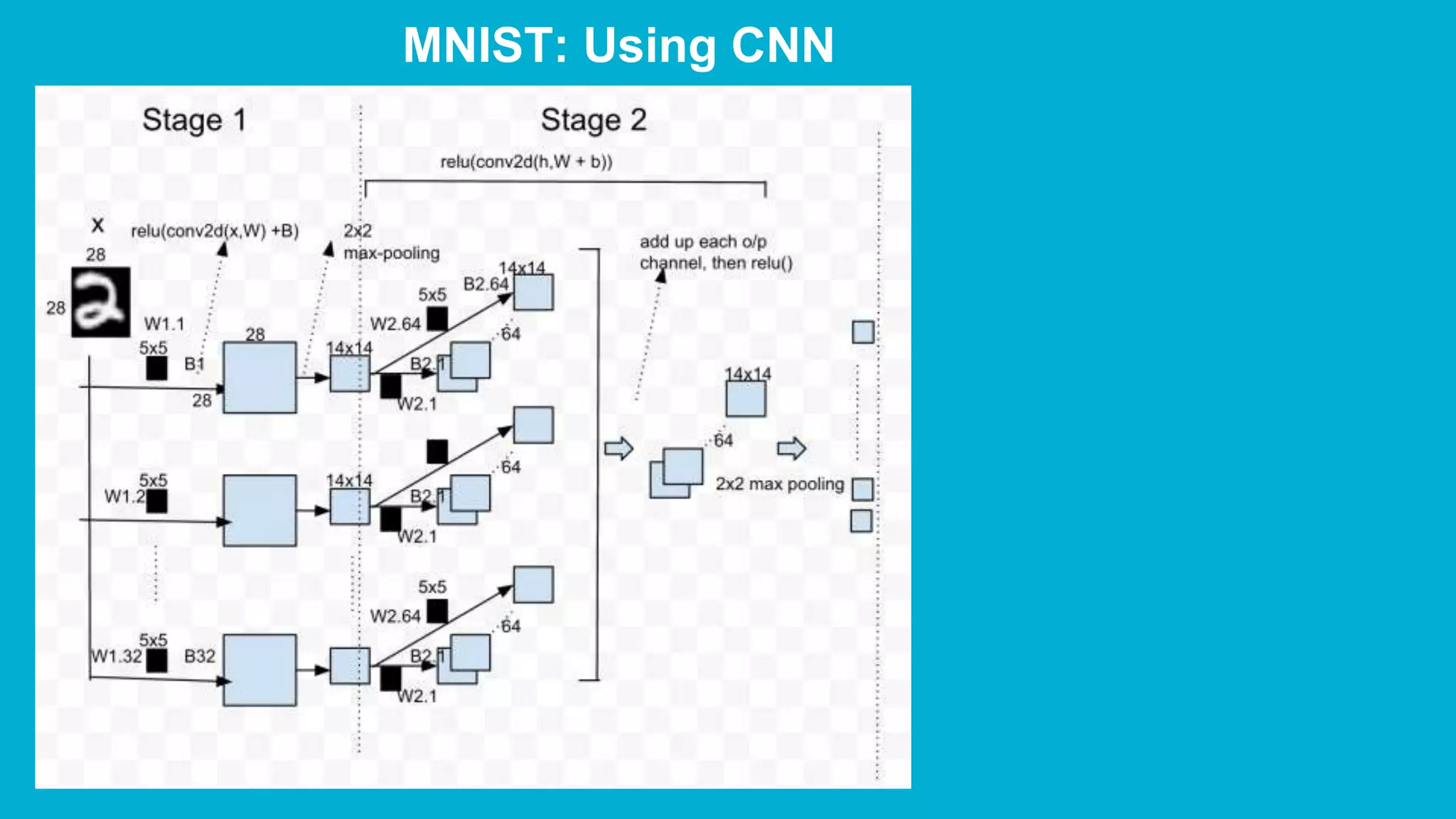
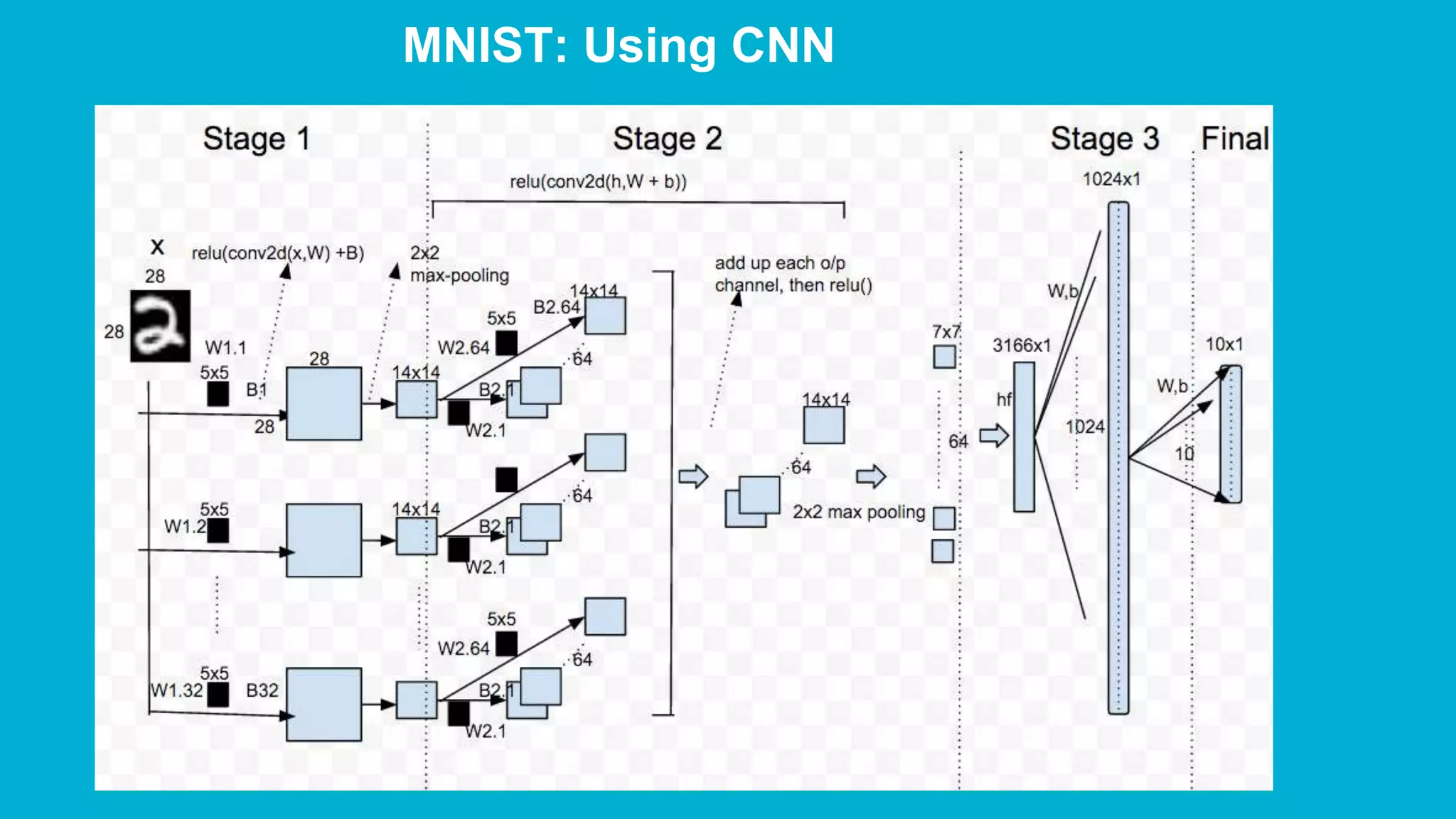
The document covers deep learning concepts using TensorFlow, focusing on neural networks, tensors, and various machine learning techniques including linear regression and word2vec. It discusses the importance of understanding the operations of neural networks, the gradient descent optimization process, and the implementation of basic models for image and text analytics. Key ideas include the representation of weights and biases in neural networks, the application of convolutional neural networks, and understanding relationships between words through vectorization.