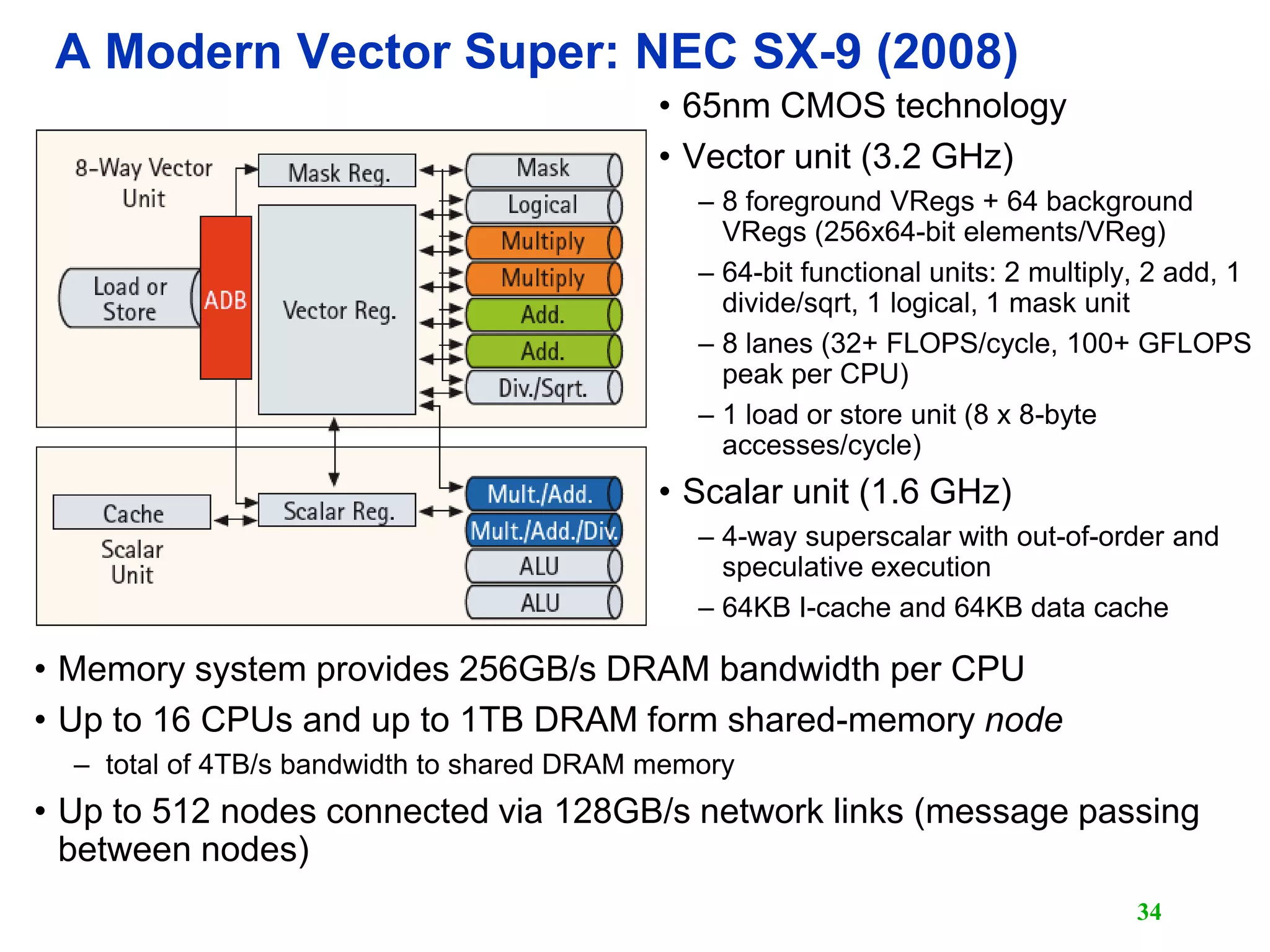
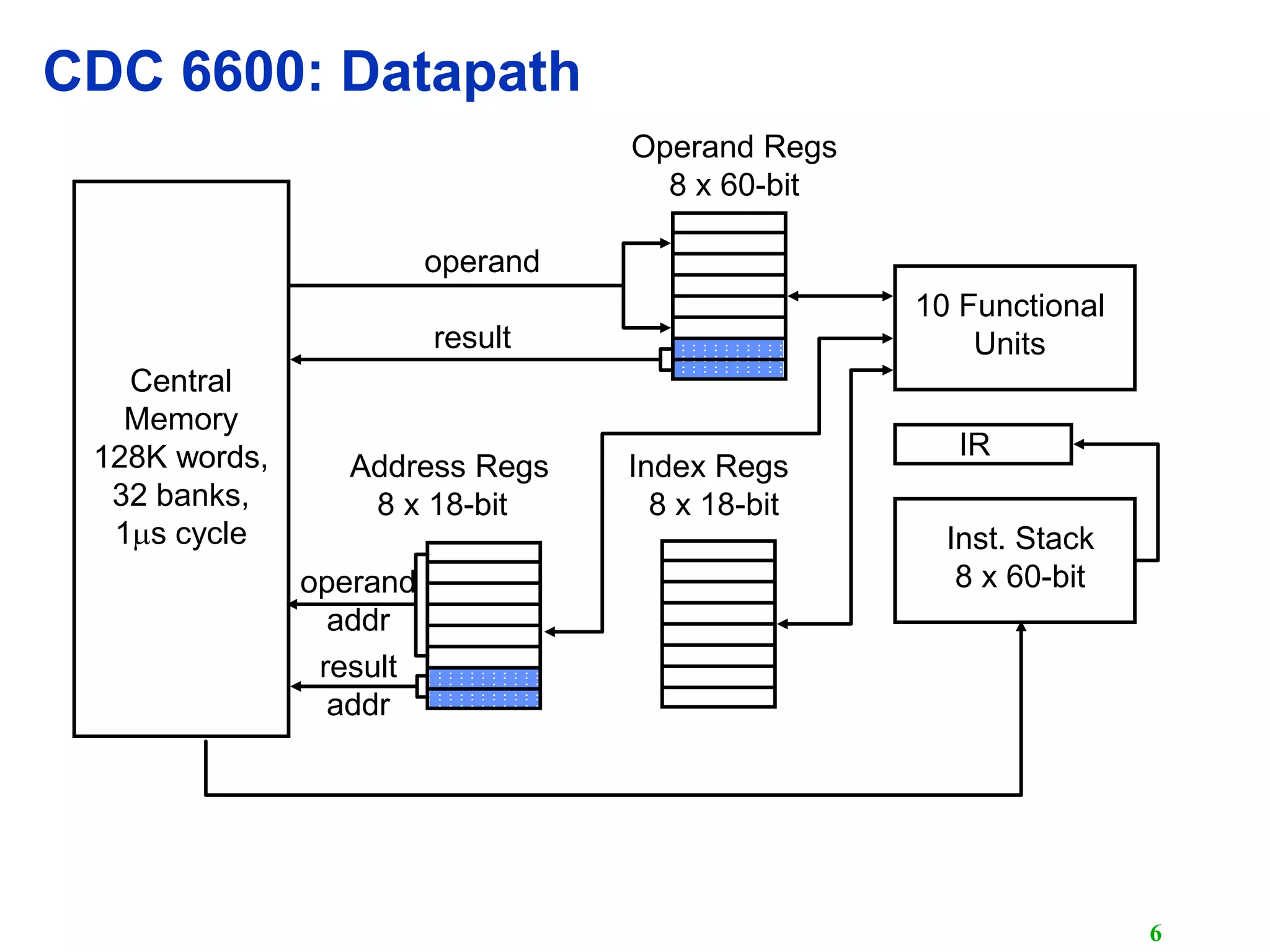
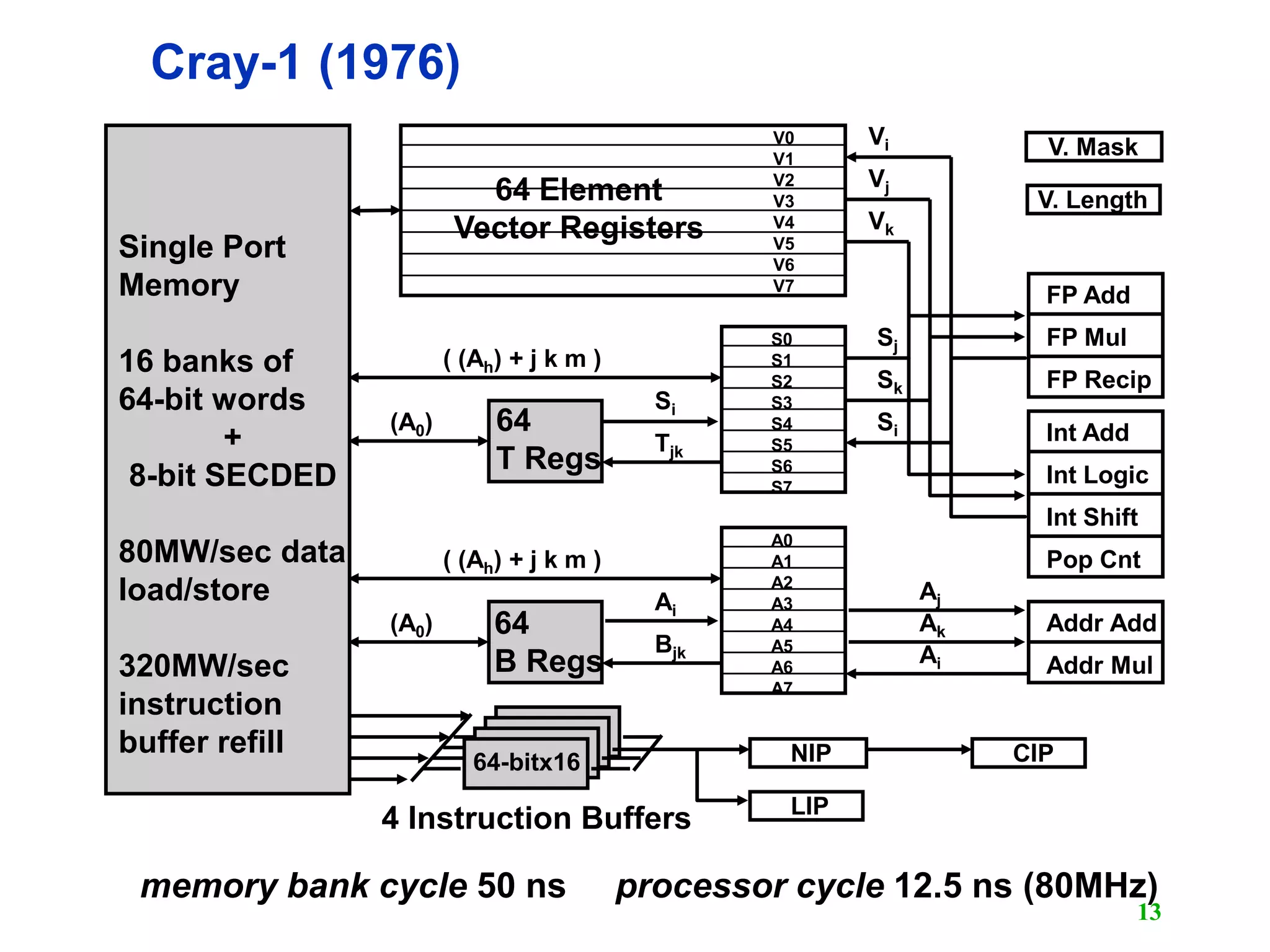
The document discusses vector computers and their instruction sets. It begins by defining supercomputers and describing the CDC 6600, one of the earliest supercomputers. It then covers vector instruction sets, how vector instructions are executed in parallel across functional units and memory banks, and techniques like vector chaining and stripmining that improve performance. Overall, the document provides an overview of the design of vector computers and their vector processing capabilities.




![5 • Separate instructions to manipulate three types of reg. 8 60-bit data registers (X) 8 18-bit address registers (A) 8 18-bit index registers (B) • All arithmetic and logic instructions are reg-to-reg • Only Load and Store instructions refer to memory! Touching address registers 1 to 5 initiates a load 6 to 7 initiates a store - very useful for vector operations opcode i j k Ri (Rj) op (Rk) CDC 6600: A Load/Store Architecture opcode i j disp Ri M[(Rj) + disp] 6 3 3 3 6 3 3 18](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-5-2048.jpg)



![Vector Programming Model 10 + + + + + + [0] [1] [VLR-1] Vector Arithmetic Instructions ADDV v3, v1, v2 v3 v2 v1 Scalar Registers r0 r15 Vector Registers v0 v15 [0] [1] [2] [VLRMAX-1] VLRVector Length Register v1 Vector Load and Store Instructions LV v1, r1, r2 Base, r1 Stride, r2 Memory Vector Register](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-10-2048.jpg)
![11 Vector Code Example # Scalar Code LI R4, 64 loop: L.D F0, 0(R1) L.D F2, 0(R2) ADD.D F4, F2, F0 S.D F4, 0(R3) DADDIU R1, 8 DADDIU R2, 8 DADDIU R3, 8 DSUBIU R4, 1 BNEZ R4, loop # Vector Code LI VLR, 64 LV V1, R1 LV V2, R2 ADDV.D V3, V1, V2 SV V3, R3 # C code for (i=0; i<64; i++) C[i] = A[i] + B[i];](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-11-2048.jpg)


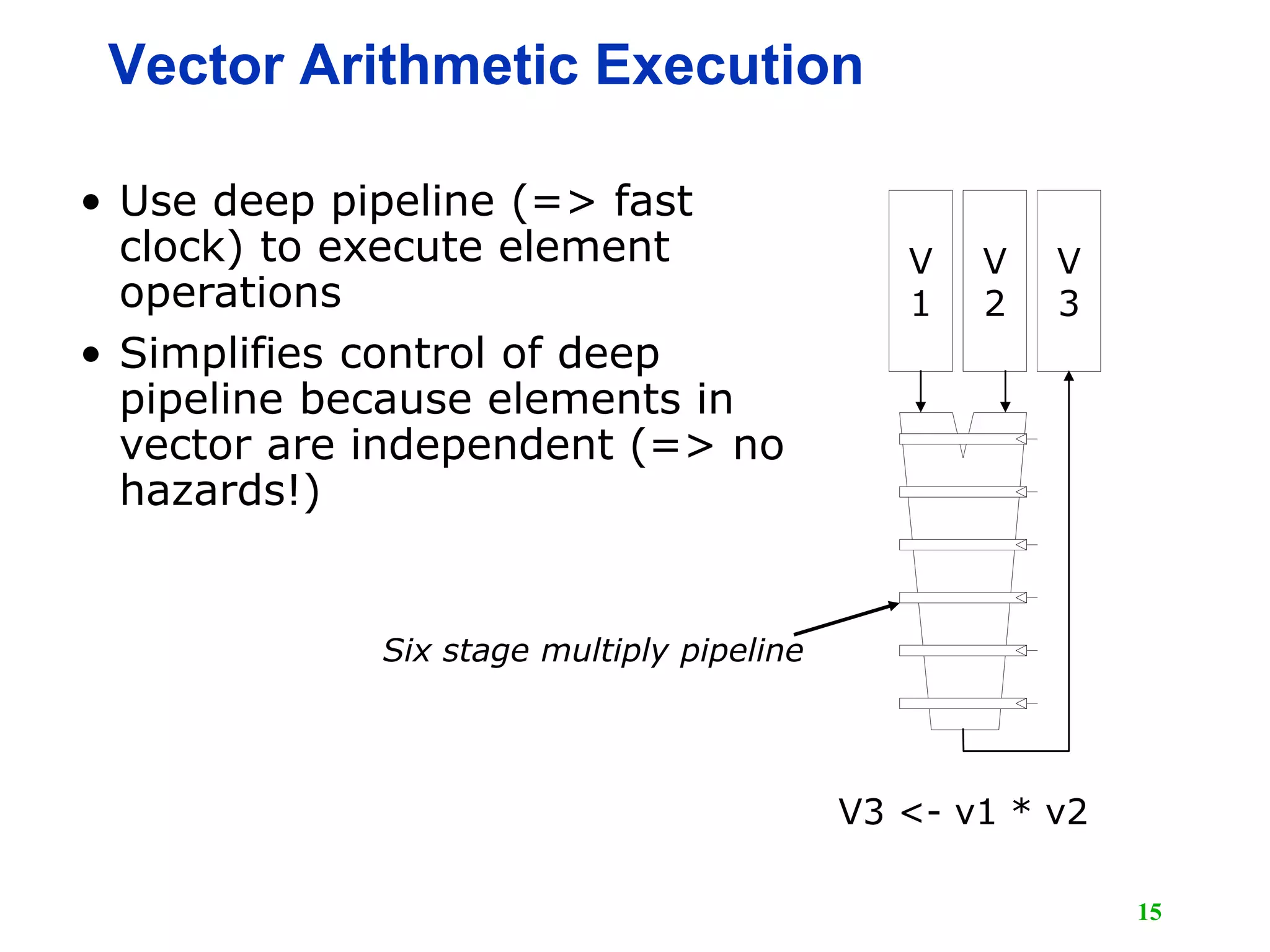
![16 Vector Instruction Execution ADDV C,A,B C[1] C[2] C[0] A[3] B[3] A[4] B[4] A[5] B[5] A[6] B[6] Execution using one pipelined functional unit C[4] C[8] C[0] A[12] B[12] A[16] B[16] A[20] B[20] A[24] B[24] C[5] C[9] C[1] A[13] B[13] A[17] B[17] A[21] B[21] A[25] B[25] C[6] C[10] C[2] A[14] B[14] A[18] B[18] A[22] B[22] A[26] B[26] C[7] C[11] C[3] A[15] B[15] A[19] B[19] A[23] B[23] A[27] B[27] Execution using four pipelined functional units](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-16-2048.jpg)
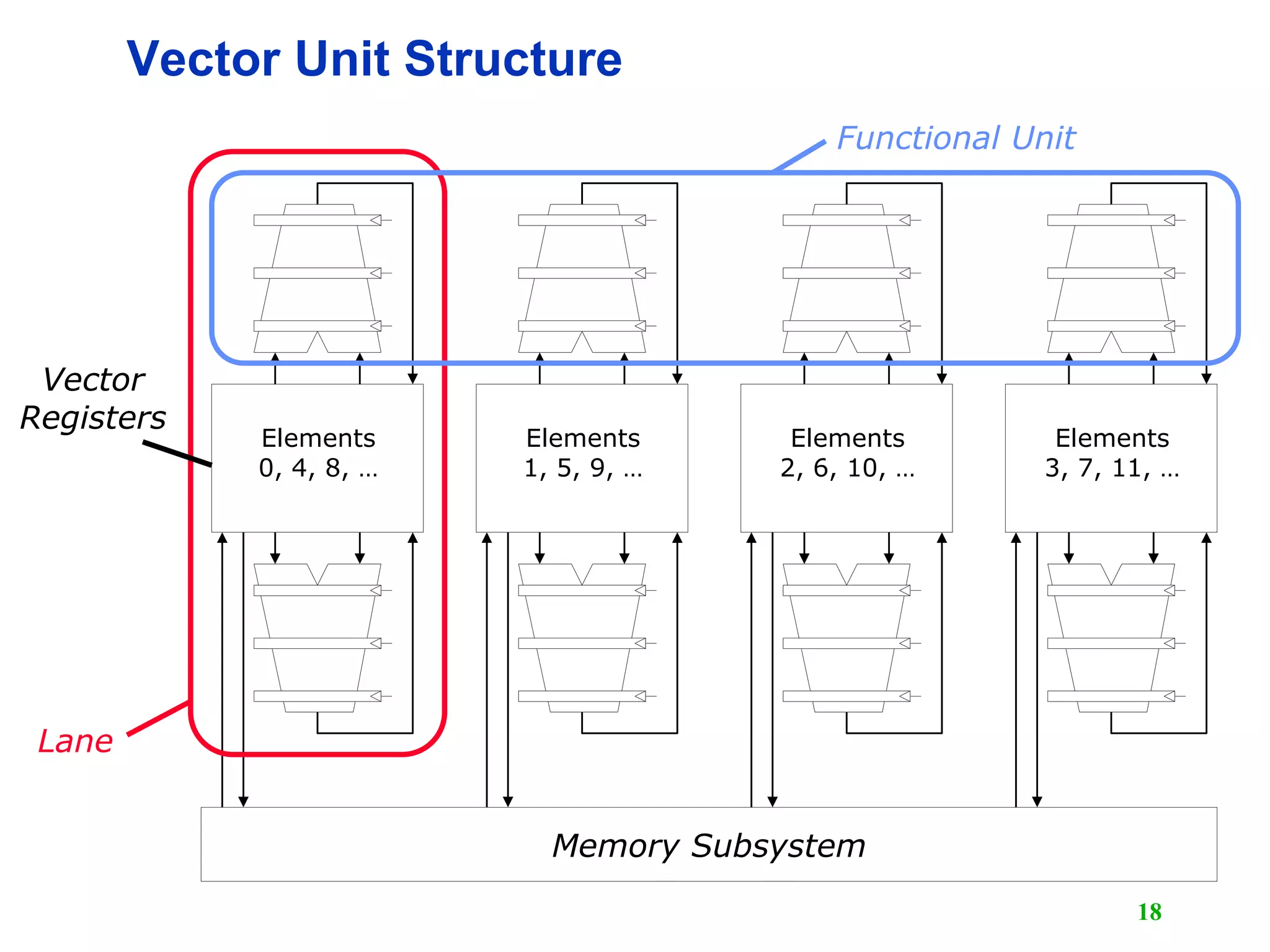
![19 T0 Vector Microprocessor (UCB/ICSI, 1995) LaneVector register elements striped over lanes [0] [8] [16] [24] [1] [9] [17] [25] [2] [10] [18] [26] [3] [11] [19] [27] [4] [12] [20] [28] [5] [13] [21] [29] [6] [14] [22] [30] [7] [15] [23] [31]](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-19-2048.jpg)
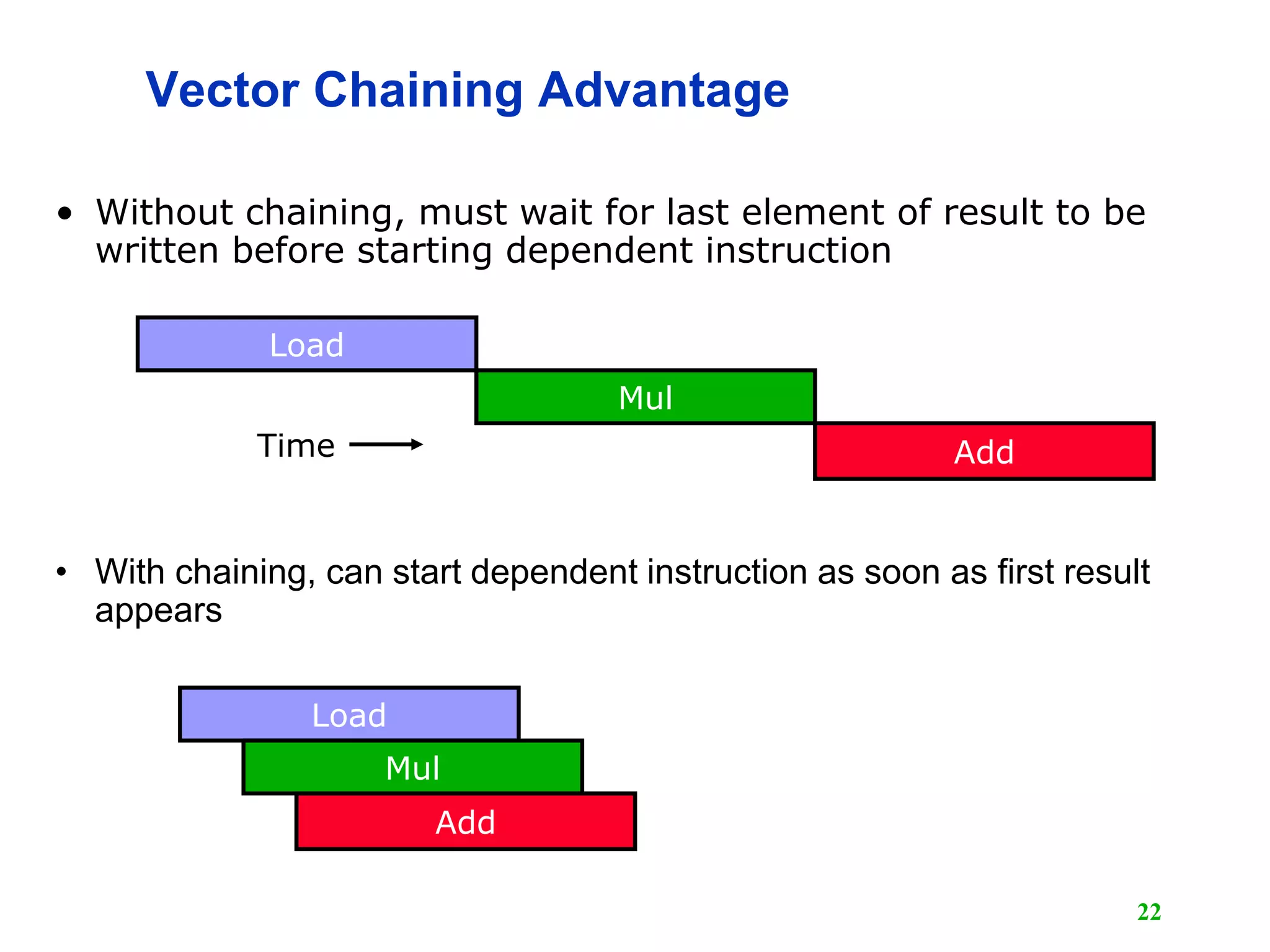
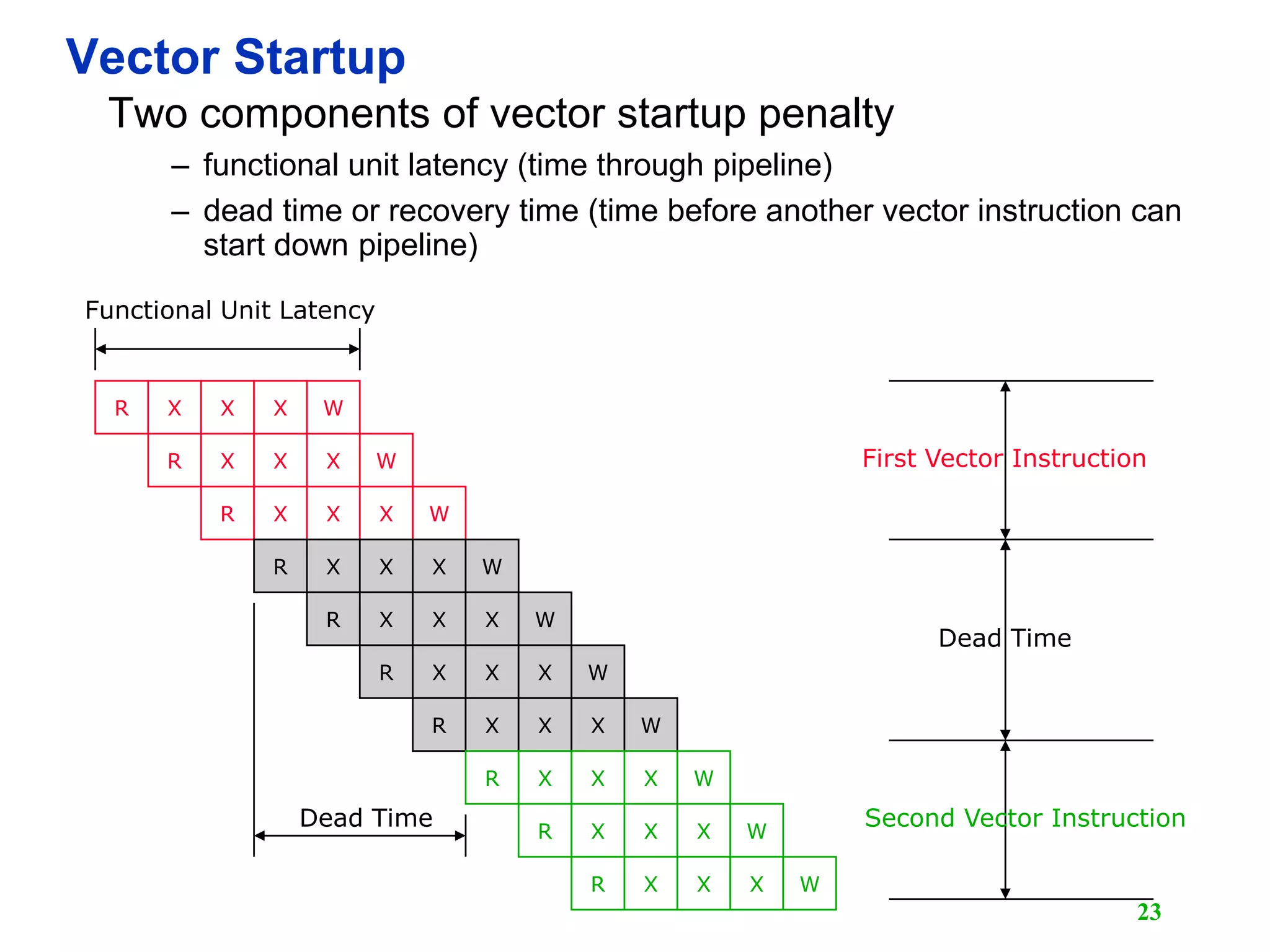
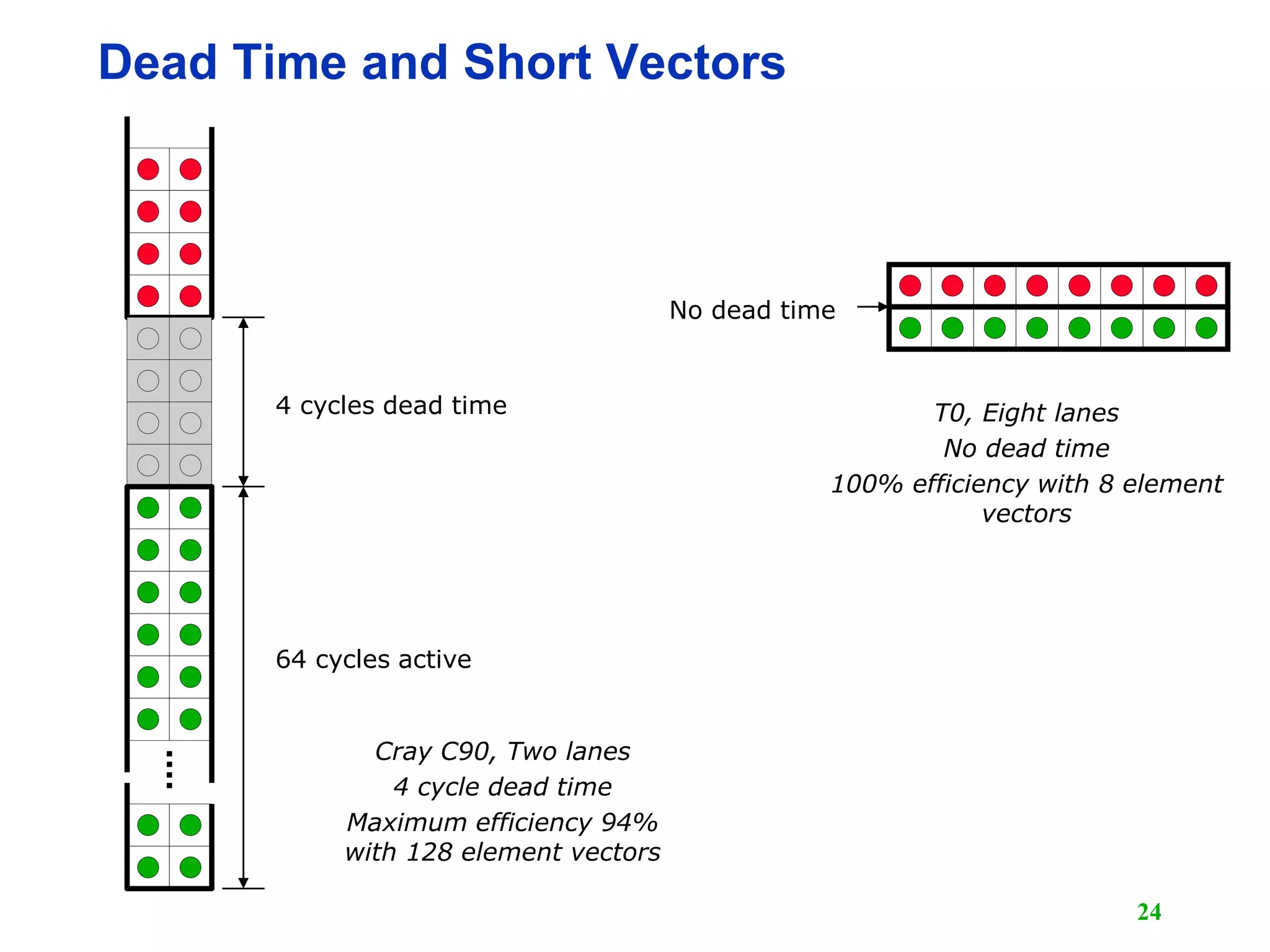
![25 Vector Memory-Memory versus Vector Register Machines • Vector memory-memory instructions hold all vector operands in main memory • The first vector machines, CDC Star-100 (‘73) and TI ASC (‘71), were memory-memory machines • Cray-1 (’76) was first vector register machine for (i=0; i<N; i++) { C[i] = A[i] + B[i]; D[i] = A[i] - B[i]; } Example Source Code ADDV C, A, B SUBV D, A, B Vector Memory-Memory Code LV V1, A LV V2, B ADDV V3, V1, V2 SV V3, C SUBV V4, V1, V2 SV V4, D Vector Register Code](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-25-2048.jpg)

![27 Automatic Code Vectorization for (i=0; i < N; i++) C[i] = A[i] + B[i]; load load add store load load add store Iter. 1 Iter. 2 Scalar Sequential Code Vectorization is a massive compile-time reordering of operation sequencing requires extensive loop dependence analysis Vector Instruction load load add store load load add store Iter. 1 Iter. 2 Vectorized Code Time](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-27-2048.jpg)
![28 Vector Stripmining Problem: Vector registers have finite length Solution: Break loops into pieces that fit in registers, “Stripmining” ANDI R1, N, 63 # N mod 64 MTC1 VLR, R1 # Do remainder loop: LV V1, RA DSLL R2, R1, 3 # Multiply by 8 DADDU RA, RA, R2 # Bump pointer LV V2, RB DADDU RB, RB, R2 ADDV.D V3, V1, V2 SV V3, RC DADDU RC, RC, R2 DSUBU N, N, R1 # Subtract elements LI R1, 64 MTC1 VLR, R1 # Reset full length BGTZ N, loop # Any more to do? for (i=0; i<N; i++) C[i] = A[i]+B[i]; + + + A B C 64 elements Remainder](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-28-2048.jpg)
![29 Vector Conditional Execution Problem: Want to vectorize loops with conditional code: for (i=0; i<N; i++) if (A[i]>0) then A[i] = B[i]; Solution: Add vector mask (or flag) registers – vector version of predicate registers, 1 bit per element …and maskable vector instructions – vector operation becomes NOP at elements where mask bit is clear Code example: CVM # Turn on all elements LV vA, rA # Load entire A vector SGTVS.D vA, F0 # Set bits in mask register where A>0 LV vA, rB # Load B vector into A under mask SV vA, rA # Store A back to memory under mask](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-29-2048.jpg)
![30 Masked Vector Instructions C[4] C[5] C[1] Write data port A[7] B[7] M[3]=0 M[4]=1 M[5]=1 M[6]=0 M[2]=0 M[1]=1 M[0]=0 M[7]=1 Density-Time Implementation – scan mask vector and only execute elements with non-zero masks C[1] C[2] C[0] A[3] B[3] A[4] B[4] A[5] B[5] A[6] B[6] M[3]=0 M[4]=1 M[5]=1 M[6]=0 M[2]=0 M[1]=1 M[0]=0 Write data portWrite Enable A[7] B[7]M[7]=1 Simple Implementation – execute all N operations, turn off result writeback according to mask](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-30-2048.jpg)
![31 Vector Reductions Problem: Loop-carried dependence on reduction variables sum = 0; for (i=0; i<N; i++) sum += A[i]; # Loop-carried dependence on sum Solution: Re-associate operations if possible, use binary tree to perform reduction # Rearrange as: sum[0:VL-1] = 0 # Vector of VL partial sums for(i=0; i<N; i+=VL) # Stripmine VL-sized chunks sum[0:VL-1] += A[i:i+VL-1]; # Vector sum # Now have VL partial sums in one vector register do { VL = VL/2; # Halve vector length sum[0:VL-1] += sum[VL:2*VL-1] # Halve no. of partials } while (VL>1)](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-31-2048.jpg)
![32 Vector Scatter/Gather Want to vectorize loops with indirect accesses: for (i=0; i<N; i++) A[i] = B[i] + C[D[i]] Indexed load instruction (Gather) LV vD, rD # Load indices in D vector LVI vC, rC, vD # Load indirect from rC base LV vB, rB # Load B vector ADDV.D vA,vB,vC # Do add SV vA, rA # Store result](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-32-2048.jpg)
![33 Vector Scatter/Gather Histogram example: for (i=0; i<N; i++) A[B[i]]++; Is following a correct translation? LV vB, rB # Load indices in B vector LVI vA, rA, vB # Gather initial A values ADDV vA, vA, 1 # Increment SVI vA, rA, vB # Scatter incremented values](https://image.slidesharecdn.com/l15-vectorprocessor1-190105115203/75/Computer-Architecture-Vector-Computer-33-2048.jpg)