Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
ssusered4546
PPTX, PDF
5 views
Chapter 4: Data-Level Parallelism in Vector, SIMD, and GPU Architectures
Data-Level Parallelism in Vector, SIMD, and GPU Architectures
Engineering
◦
Read more
0
Save
Share
Embed
Download
Download to read offline
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PPTX
Data-Level Parallelism in Vector, SIMD, and GPU Architectures.pptx
by
aliali240367
PPTX
Caqa5e ch4
by
Aravindharamanan S
PPTX
Data-Level Parallelism in Microprocessors
by
Dilum Bandara
PPT
chapter4.ppt
by
Rakesh Pogula
PPTX
Advanced computer architecture
by
krishnaviswambharan
PPTX
Computer Architecture Vector Computer
by
Haris456
PPT
Single instruction multiple data
by
Syed Zaid Irshad
PDF
Andes RISC-V vector extension demystified-tutorial
by
RISC-V International
Data-Level Parallelism in Vector, SIMD, and GPU Architectures.pptx
by
aliali240367
Caqa5e ch4
by
Aravindharamanan S
Data-Level Parallelism in Microprocessors
by
Dilum Bandara
chapter4.ppt
by
Rakesh Pogula
Advanced computer architecture
by
krishnaviswambharan
Computer Architecture Vector Computer
by
Haris456
Single instruction multiple data
by
Syed Zaid Irshad
Andes RISC-V vector extension demystified-tutorial
by
RISC-V International
Similar to Chapter 4: Data-Level Parallelism in Vector, SIMD, and GPU Architectures
PPTX
Ca unit v 27 9-2020
by
Thyagharajan K.K.
PPTX
lec2 - Modern Processors - SIMD.pptx
by
Rakesh Pogula
PDF
Vectorization on x86: all you need to know
by
Roberto Agostino Vitillo
PPT
Happy To Use SIMD
by
Wei-Ta Wang
PPTX
Vector computing
by
Safayet Hossain
PPTX
SIMD.pptx
by
dk03006
PPTX
Intrinsics: Low-level engine development with Burst - Unite Copenhagen 2019
by
Unity Technologies
PDF
Aca2 08 new
by
Sumit Mittu
PPTX
Parallel Processors (SIMD)
by
Ali Raza
PPTX
Parallel Processors (SIMD)
by
Ali Raza
PDF
Abstracting Vector Architectures in Library Generators: Case Study Convolutio...
by
ETH Zurich
PDF
Designing C++ portable SIMD support
by
Joel Falcou
PDF
Joel Falcou, Boost.SIMD
by
Sergey Platonov
PDF
Simd programming introduction
by
Champ Yen
PPTX
CSA unit5.pptx
by
AbcvDef
PDF
Vector processor : Notes
by
Subhajit Sahu
PDF
Vectorization with LMS: SIMD Intrinsics
by
ETH Zurich
PPT
Lec3 final
by
Gichelle Amon
PPTX
introduction to embedded-converted new one
by
DrVikasMahor
PDF
Advanced High-Performance Computing Features of the OpenPOWER ISA
by
Ganesan Narayanasamy
Ca unit v 27 9-2020
by
Thyagharajan K.K.
lec2 - Modern Processors - SIMD.pptx
by
Rakesh Pogula
Vectorization on x86: all you need to know
by
Roberto Agostino Vitillo
Happy To Use SIMD
by
Wei-Ta Wang
Vector computing
by
Safayet Hossain
SIMD.pptx
by
dk03006
Intrinsics: Low-level engine development with Burst - Unite Copenhagen 2019
by
Unity Technologies
Aca2 08 new
by
Sumit Mittu
Parallel Processors (SIMD)
by
Ali Raza
Parallel Processors (SIMD)
by
Ali Raza
Abstracting Vector Architectures in Library Generators: Case Study Convolutio...
by
ETH Zurich
Designing C++ portable SIMD support
by
Joel Falcou
Joel Falcou, Boost.SIMD
by
Sergey Platonov
Simd programming introduction
by
Champ Yen
CSA unit5.pptx
by
AbcvDef
Vector processor : Notes
by
Subhajit Sahu
Vectorization with LMS: SIMD Intrinsics
by
ETH Zurich
Lec3 final
by
Gichelle Amon
introduction to embedded-converted new one
by
DrVikasMahor
Advanced High-Performance Computing Features of the OpenPOWER ISA
by
Ganesan Narayanasamy
Recently uploaded
PPTX
Introduction of gdg and info session on study jam.pptx
by
DeepakkumarSingh415123
PPT
Design Flow of Analog IC Design - Presentation
by
RRaja Einstein
PDF
MCP, Functions and Security | Development with AI Tools
by
ShaBoncuku1
PDF
Design of a high frequency low voltage CMOS operational amplifier
by
VLSICS Design
PDF
Lagoon Liners and Baffle Curtains - v.23
by
Brian Gongol
PDF
Energias renovables estudio energias.pdf
by
CarlosPrezBuelga
PDF
The Electric Power Engineering Handbook - 12 - Power System Operation And Con...
by
islammuddinilsevar
PDF
Ingenieria offshore energias renovables.pdf
by
CarlosPrezBuelga
PPTX
an overview to software engineering.pptx
by
1111287
PDF
An architecture to build high performance infrastructures on cloud computing ...
by
TELKOMNIKA JOURNAL
PPTX
Advanced data security and confidentiality strategies Final Version --.pptx
by
FedralKha
PPTX
LNG Basics by Choi SPE Introductory Liquefaction Lecture
by
RobertWaters35
PDF
IS18591-2024 Geosynthetic Reinforced Soil Structures — Code of Practice
by
Rabindra Shrestha
PDF
Drone Supported by modular optical systems
by
mkevinfahlevi445
PDF
Request for Information - #10547 CBTC
by
mdrodriguez7
PDF
Evolution of MQ Messaging to Distributed Data Pipeline
by
Peerapat Asoktummarungsri
PPTX
Why Did The submarine Kursk Sink? What went wrong?
by
Bob Mayer
PPTX
INDUSTRIAL ERGONOMICS.pptx-MCN 401 -MODULE 3
by
VinayB68
PDF
SMT PCB Assembly Process -Manufacturing Ebook.pdf
by
sproworkstech
PDF
Dera Murad Jamali Bypass on National Highway N-65 – Tender Drawings
by
HabiburRehmanKhan5
Introduction of gdg and info session on study jam.pptx
by
DeepakkumarSingh415123
Design Flow of Analog IC Design - Presentation
by
RRaja Einstein
MCP, Functions and Security | Development with AI Tools
by
ShaBoncuku1
Design of a high frequency low voltage CMOS operational amplifier
by
VLSICS Design
Lagoon Liners and Baffle Curtains - v.23
by
Brian Gongol
Energias renovables estudio energias.pdf
by
CarlosPrezBuelga
The Electric Power Engineering Handbook - 12 - Power System Operation And Con...
by
islammuddinilsevar
Ingenieria offshore energias renovables.pdf
by
CarlosPrezBuelga
an overview to software engineering.pptx
by
1111287
An architecture to build high performance infrastructures on cloud computing ...
by
TELKOMNIKA JOURNAL
Advanced data security and confidentiality strategies Final Version --.pptx
by
FedralKha
LNG Basics by Choi SPE Introductory Liquefaction Lecture
by
RobertWaters35
IS18591-2024 Geosynthetic Reinforced Soil Structures — Code of Practice
by
Rabindra Shrestha
Drone Supported by modular optical systems
by
mkevinfahlevi445
Request for Information - #10547 CBTC
by
mdrodriguez7
Evolution of MQ Messaging to Distributed Data Pipeline
by
Peerapat Asoktummarungsri
Why Did The submarine Kursk Sink? What went wrong?
by
Bob Mayer
INDUSTRIAL ERGONOMICS.pptx-MCN 401 -MODULE 3
by
VinayB68
SMT PCB Assembly Process -Manufacturing Ebook.pdf
by
sproworkstech
Dera Murad Jamali Bypass on National Highway N-65 – Tender Drawings
by
HabiburRehmanKhan5
Chapter 4: Data-Level Parallelism in Vector, SIMD, and GPU Architectures
1.
Copyright © 2019,
Elsevier Inc. All rights Reserved 1 Chapter 4 Data-Level Parallelism in Vector, SIMD, and GPU Architectures Computer Architecture A Quantitative Approach, Sixth Edition
2.
2 Copyright © 2019,
Elsevier Inc. All rights Reserved Introduction SIMD architectures can exploit significant data- level parallelism for: Matrix-oriented scientific computing Media-oriented image and sound processors SIMD is more energy efficient than MIMD Only needs to fetch one instruction per data operation Makes SIMD attractive for personal mobile devices SIMD allows programmer to continue to think sequentially Introduction
3.
3 Copyright © 2019,
Elsevier Inc. All rights Reserved SIMD Parallelism Vector architectures SIMD extensions Graphics Processor Units (GPUs) For x86 processors: Expect two additional cores per chip per year SIMD width to double every four years Potential speedup from SIMD to be twice that from MIMD! Introduction
4.
4 Copyright © 2019,
Elsevier Inc. All rights Reserved Vector Architectures Basic idea: Read sets of data elements into “vector registers” Operate on those registers Disperse the results back into memory Registers are controlled by compiler Used to hide memory latency Leverage memory bandwidth Vector Architectures
5.
5 Copyright © 2019,
Elsevier Inc. All rights Reserved VMIPS Example architecture: RV64V Loosely based on Cray-1 32 62-bit vector registers Register file has 16 read ports and 8 write ports Vector functional units Fully pipelined Data and control hazards are detected Vector load-store unit Fully pipelined One word per clock cycle after initial latency Scalar registers 31 general-purpose registers 32 floating-point registers Vector Architectures
6.
6 Copyright © 2019,
Elsevier Inc. All rights Reserved VMIPS Instructions .vv: two vector operands .vs and .sv: vector and scalar operands LV/SV: vector load and vector store from address Example: DAXPY vsetdcfg 4*FP64 # Enable 4 DP FP vregs fld f0,a # Load scalar a vld v0,x5 # Load vector X vmul v1,v0,f0 # Vector-scalar mult vld v2,x6 # Load vector Y vadd v3,v1,v2 # Vector-vector add vst v3,x6 # Store the sum vdisable # Disable vector regs 8 instructions, 258 for RV64V (scalar code) Vector Architectures
7.
7 Copyright © 2019,
Elsevier Inc. All rights Reserved Vector Execution Time Execution time depends on three factors: Length of operand vectors Structural hazards Data dependencies RV64V functional units consume one element per clock cycle Execution time is approximately the vector length Convey Set of vector instructions that could potentially execute together Vector Architectures
8.
8 Copyright © 2019,
Elsevier Inc. All rights Reserved Chimes Sequences with read-after-write dependency hazards placed in same convey via chaining Chaining Allows a vector operation to start as soon as the individual elements of its vector source operand become available Chime Unit of time to execute one convey m conveys executes in m chimes for vector length n For vector length of n, requires m x n clock cycles Vector Architectures
9.
9 Copyright © 2019,
Elsevier Inc. All rights Reserved Example vld v0,x5 # Load vector X vmul v1,v0,f0 # Vector-scalar multiply vld v2,x6 # Load vector Y vadd v3,v1,v2 # Vector-vector add vst v3,x6 # Store the sum Convoys: 1 vld vmul 2 vld vadd 3 vst 3 chimes, 2 FP ops per result, cycles per FLOP = 1.5 For 64 element vectors, requires 32 x 3 = 96 clock cycles Vector Architectures
10.
10 Copyright © 2019,
Elsevier Inc. All rights Reserved Challenges Start up time Latency of vector functional unit Assume the same as Cray-1 Floating-point add => 6 clock cycles Floating-point multiply => 7 clock cycles Floating-point divide => 20 clock cycles Vector load => 12 clock cycles Improvements: > 1 element per clock cycle Non-64 wide vectors IF statements in vector code Memory system optimizations to support vector processors Multiple dimensional matrices Sparse matrices Programming a vector computer Vector Architectures
11.
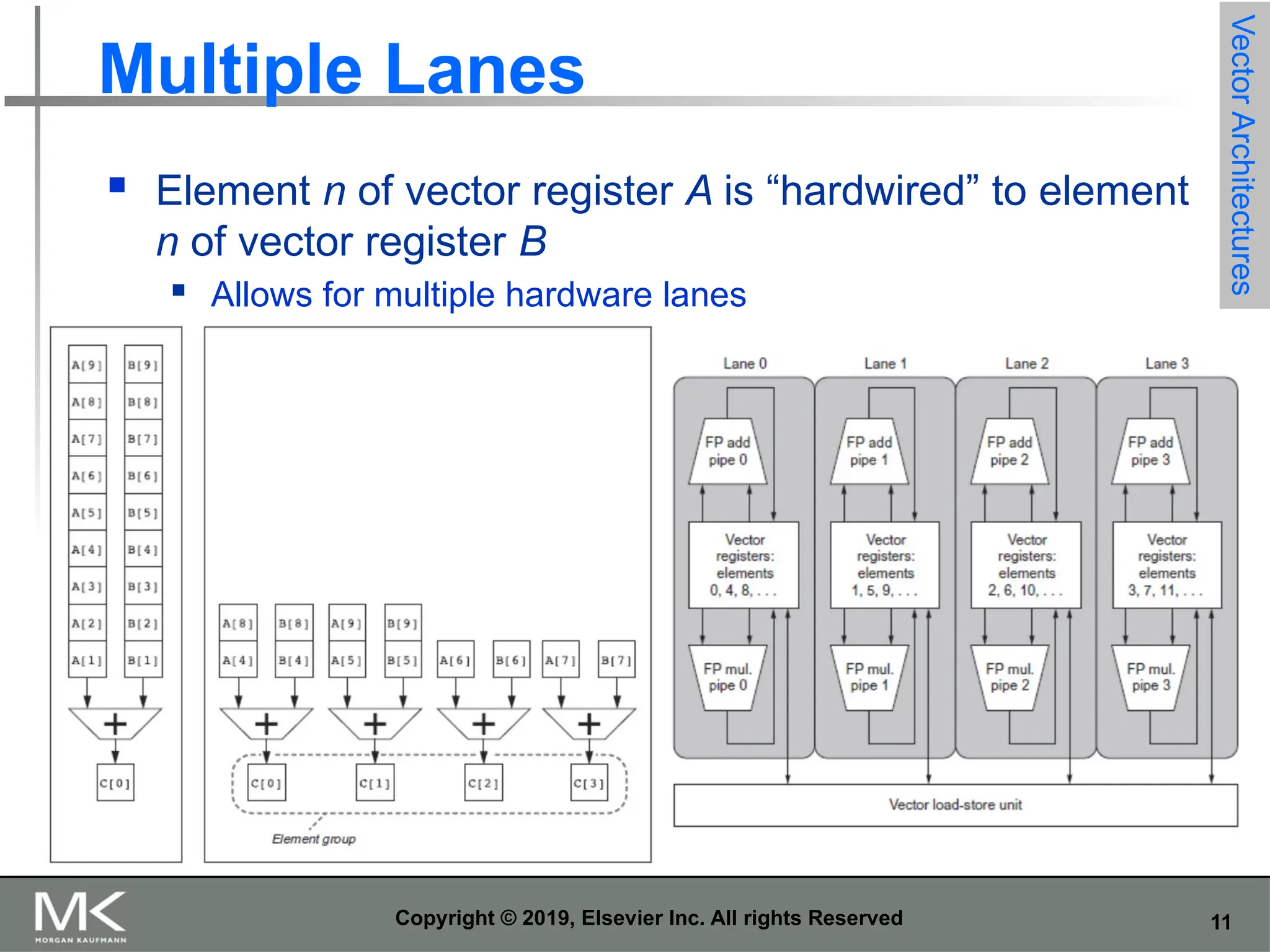
11 Copyright © 2019,
Elsevier Inc. All rights Reserved Multiple Lanes Element n of vector register A is “hardwired” to element n of vector register B Allows for multiple hardware lanes Vector Architectures
12.
12 Copyright © 2019,
Elsevier Inc. All rights Reserved Vector Length Register for (i=0; i <n; i=i+1) Y[i] = a * X[i] + Y[i]; vsetdcfg 2 DP FP # Enable 2 64b Fl.Pt. registers fld f0,a # Load scalar a loop: setvl t0,a0 # vl = t0 = min(mvl,n) vld v0,x5 # Load vector X slli t1,t0,3 # t1 = vl * 8 (in bytes) add x5,x5,t1 # Increment pointer to X by vl*8 vmul v0,v0,f0 # Vector-scalar mult vld v1,x6 # Load vector Y vadd v1,v0,v1 # Vector-vector add sub a0,a0,t0 # n -= vl (t0) vst v1,x6 # Store the sum into Y add x6,x6,t1 # Increment pointer to Y by vl*8 bnez a0,loop # Repeat if n != 0 vdisable # Disable vector regs} Vector Architectures
13.
13 Copyright © 2019,
Elsevier Inc. All rights Reserved Vector Mask Registers Consider: for (i = 0; i < 64; i=i+1) if (X[i] != 0) X[i] = X[i] – Y[i]; Use predicate register to “disable” elements: vsetdcfg 2*FP64 # Enable 2 64b FP vector regs vsetpcfgi 1 # Enable 1 predicate register vld v0,x5 # Load vector X into v0 vld v1,x6 # Load vector Y into v1 fmv.d.x f0,x0 # Put (FP) zero into f0 vpne p0,v0,f0 # Set p0(i) to 1 if v0(i)!=f0 vsub v0,v0,v1 # Subtract under vector mask vst v0,x5 # Store the result in X vdisable # Disable vector registers vpdisable # Disable predicate registers Vector Architectures
14.
14 Copyright © 2019,
Elsevier Inc. All rights Reserved Memory Banks Memory system must be designed to support high bandwidth for vector loads and stores Spread accesses across multiple banks Control bank addresses independently Load or store non sequential words (need independent bank addressing) Support multiple vector processors sharing the same memory Example: 32 processors, each generating 4 loads and 2 stores/cycle Processor cycle time is 2.167 ns, SRAM cycle time is 15 ns How many memory banks needed? 32x(4+2)x15/2.167 = ~1330 banks Vector Architectures
15.
15 Copyright © 2019,
Elsevier Inc. All rights Reserved Stride Consider: for (i = 0; i < 100; i=i+1) for (j = 0; j < 100; j=j+1) { A[i][j] = 0.0; for (k = 0; k < 100; k=k+1) A[i][j] = A[i][j] + B[i][k] * D[k][j]; } Must vectorize multiplication of rows of B with columns of D Use non-unit stride Bank conflict (stall) occurs when the same bank is hit faster than bank busy time: #banks / LCM(stride,#banks) < bank busy time Vector Architectures
16.
16 Copyright © 2019,
Elsevier Inc. All rights Reserved Scatter-Gather Consider: for (i = 0; i < n; i=i+1) A[K[i]] = A[K[i]] + C[M[i]]; Use index vector: vsetdcfg 4*FP64 # 4 64b FP vector registers vld v0, x7 # Load K[] vldx v1, x5, v0 # Load A[K[]] vld v2, x28 # Load M[] vldi v3, x6, v2 # Load C[M[]] vadd v1, v1, v3 # Add them vstx v1, x5, v0 # Store A[K[]] vdisable # Disable vector registers Vector Architectures
17.
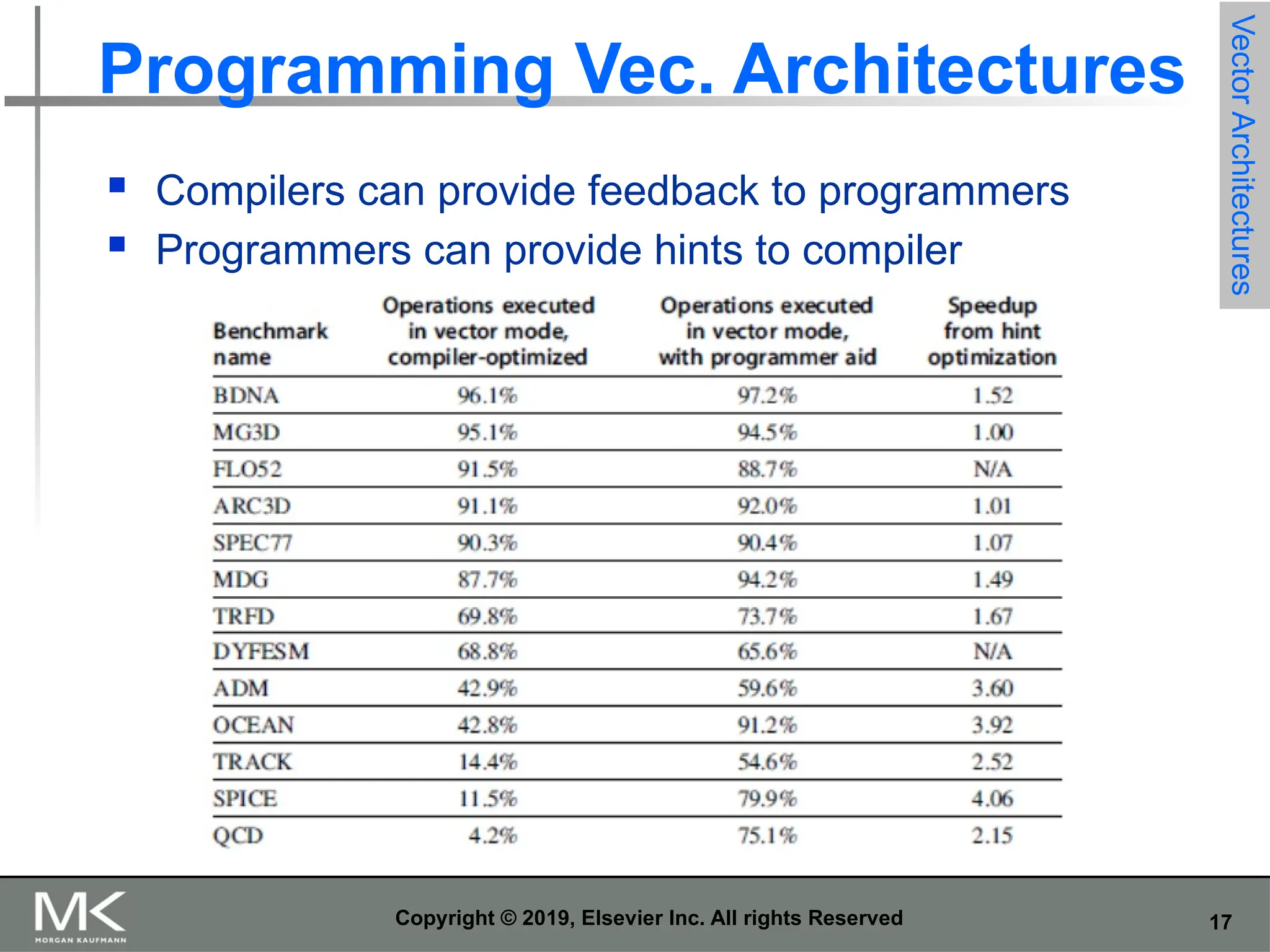
17 Copyright © 2019,
Elsevier Inc. All rights Reserved Programming Vec. Architectures Compilers can provide feedback to programmers Programmers can provide hints to compiler Vector Architectures
18.
18 Copyright © 2019,
Elsevier Inc. All rights Reserved SIMD Extensions Media applications operate on data types narrower than the native word size Example: disconnect carry chains to “partition” adder Limitations, compared to vector instructions: Number of data operands encoded into op code No sophisticated addressing modes (strided, scatter- gather) No mask registers SIMD Instruction Set Extensions for Multimedia
19.
19 Copyright © 2019,
Elsevier Inc. All rights Reserved SIMD Implementations Implementations: Intel MMX (1996) Eight 8-bit integer ops or four 16-bit integer ops Streaming SIMD Extensions (SSE) (1999) Eight 16-bit integer ops Four 32-bit integer/fp ops or two 64-bit integer/fp ops Advanced Vector Extensions (2010) Four 64-bit integer/fp ops AVX-512 (2017) Eight 64-bit integer/fp ops Operands must be consecutive and aligned memory locations SIMD Instruction Set Extensions for Multimedia
20.
20 Copyright © 2019,
Elsevier Inc. All rights Reserved Example SIMD Code Example DXPY: fld f0,a # Load scalar a splat.4D f0,f0 # Make 4 copies of a addi x28,x5,#256 # Last address to load Loop: fld.4D f1,0(x5) # Load X[i] ... X[i+3] fmul.4D f1,f1,f0 # a x X[i] ... a x X[i+3] fld.4D f2,0(x6) # Load Y[i] ... Y[i+3] fadd.4D f2,f2,f1 # a x X[i]+Y[i]... # a x X[i+3]+Y[i+3] fsd.4D f2,0(x6) # Store Y[i]... Y[i+3] addi x5,x5,#32 # Increment index to X addi x6,x6,#32 # Increment index to Y bne x28,x5,Loop # Check if done SIMD Instruction Set Extensions for Multimedia
21.
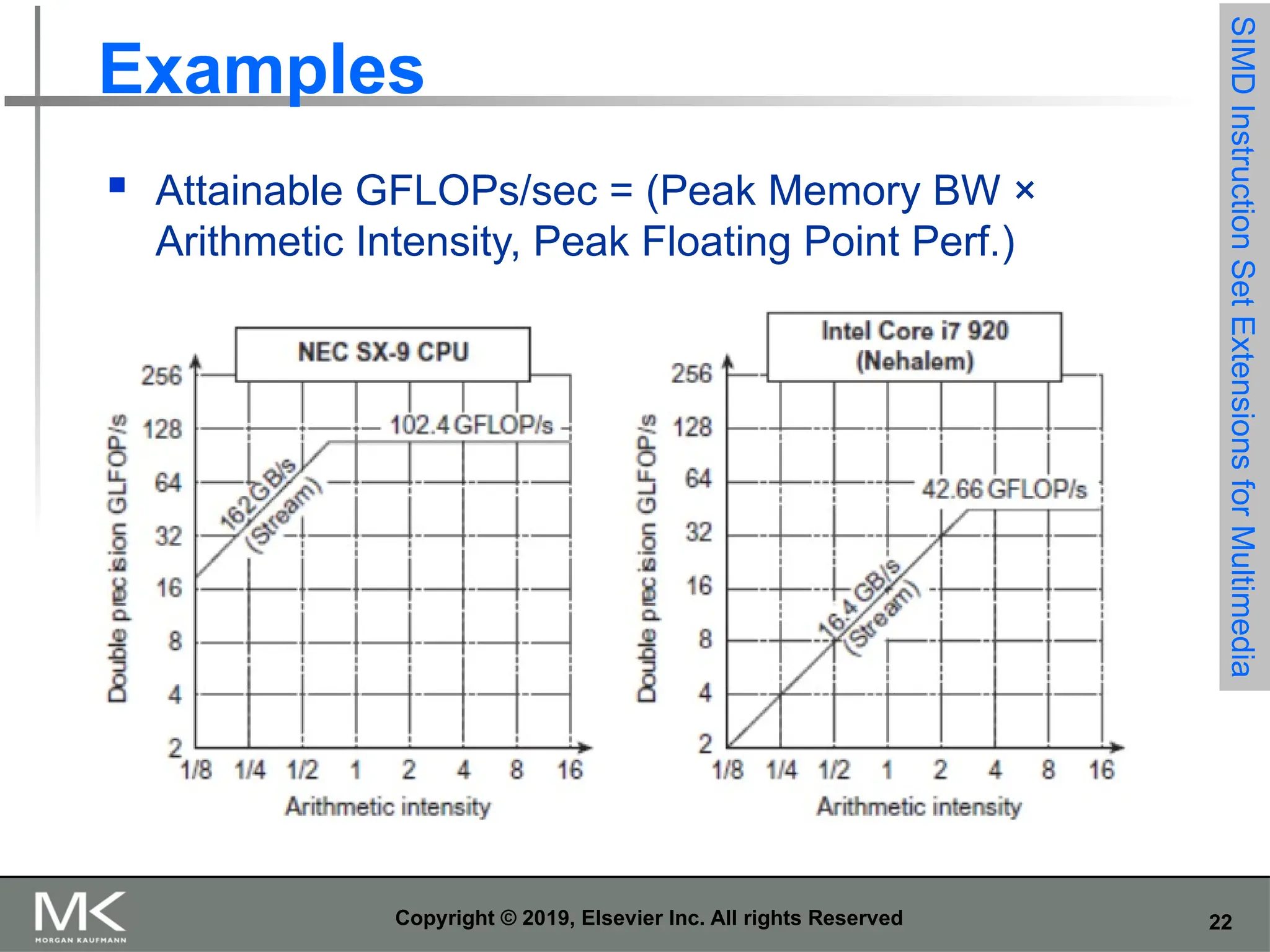
21 Copyright © 2019,
Elsevier Inc. All rights Reserved Roofline Performance Model Basic idea: Plot peak floating-point throughput as a function of arithmetic intensity Ties together floating-point performance and memory performance for a target machine Arithmetic intensity Floating-point operations per byte read SIMD Instruction Set Extensions for Multimedia
22.
22 Copyright © 2019,
Elsevier Inc. All rights Reserved Examples Attainable GFLOPs/sec = (Peak Memory BW × Arithmetic Intensity, Peak Floating Point Perf.) SIMD Instruction Set Extensions for Multimedia
23.
23 Copyright © 2019,
Elsevier Inc. All rights Reserved Graphical Processing Units Basic idea: Heterogeneous execution model CPU is the host, GPU is the device Develop a C-like programming language for GPU Unify all forms of GPU parallelism as CUDA thread Programming model is “Single Instruction Multiple Thread” Graphical Processing Units
24.
24 Copyright © 2019,
Elsevier Inc. All rights Reserved Threads and Blocks A thread is associated with each data element Threads are organized into blocks Blocks are organized into a grid GPU hardware handles thread management, not applications or OS Graphical Processing Units
25.
25 Copyright © 2019,
Elsevier Inc. All rights Reserved NVIDIA GPU Architecture Similarities to vector machines: Works well with data-level parallel problems Scatter-gather transfers Mask registers Large register files Differences: No scalar processor Uses multithreading to hide memory latency Has many functional units, as opposed to a few deeply pipelined units like a vector processor Graphical Processing Units
26.
26 Copyright © 2019,
Elsevier Inc. All rights Reserved Example Code that works over all elements is the grid Thread blocks break this down into manageable sizes 512 threads per block SIMD instruction executes 32 elements at a time Thus grid size = 16 blocks Block is analogous to a strip-mined vector loop with vector length of 32 Block is assigned to a multithreaded SIMD processor by the thread block scheduler Current-generation GPUs have 7-15 multithreaded SIMD processors Graphical Processing Units
27.
27 Copyright © 2019,
Elsevier Inc. All rights Reserved Terminology Each thread is limited to 64 registers Groups of 32 threads combined into a SIMD thread or “warp” Mapped to 16 physical lanes Up to 32 warps are scheduled on a single SIMD processor Each warp has its own PC Thread scheduler uses scoreboard to dispatch warps By definition, no data dependencies between warps Dispatch warps into pipeline, hide memory latency Thread block scheduler schedules blocks to SIMD processors Within each SIMD processor: 32 SIMD lanes Wide and shallow compared to vector processors Graphical Processing Units
28.
28 Copyright © 2019,
Elsevier Inc. All rights Reserved Example Graphical Processing Units
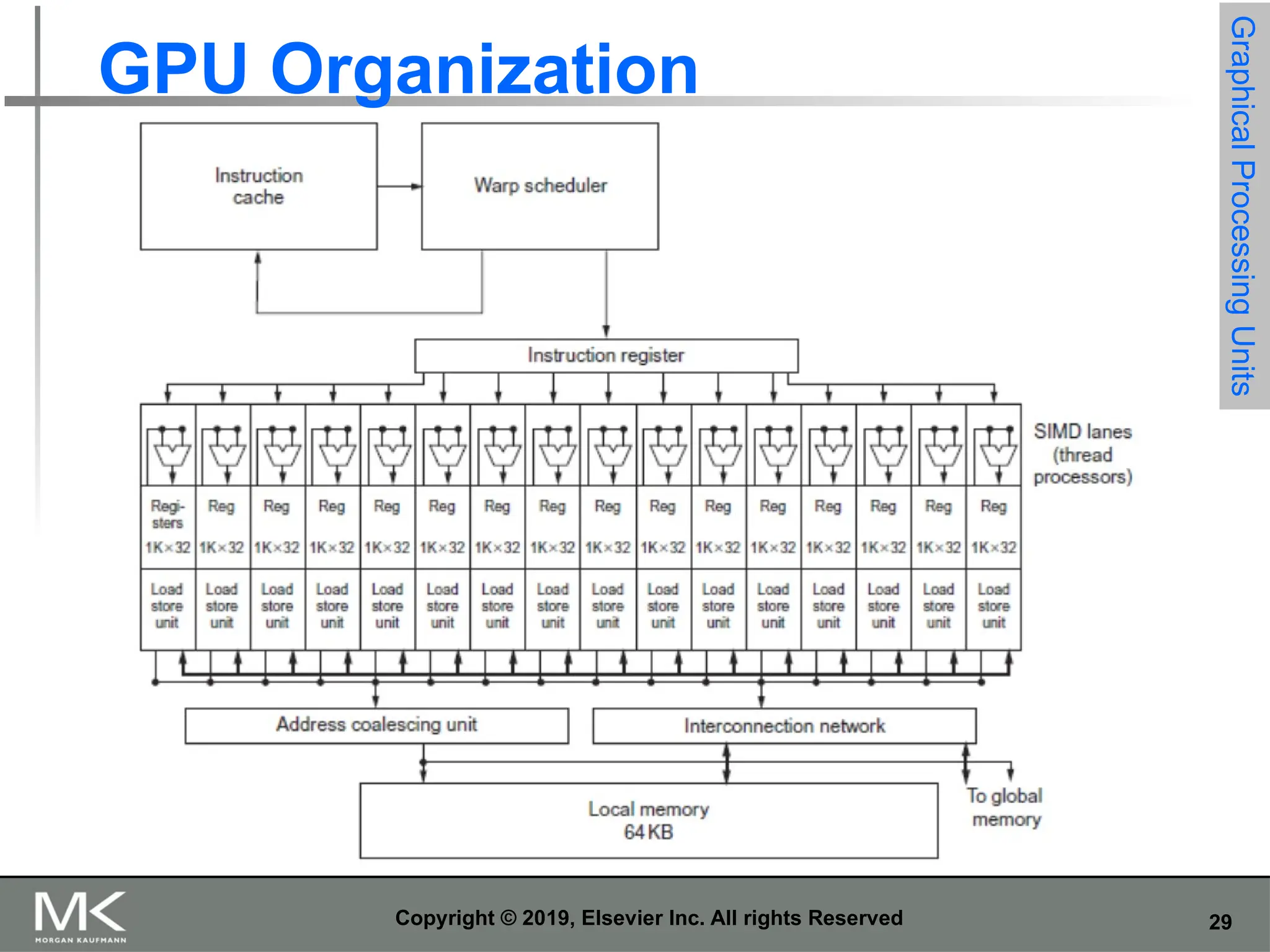
29.
29 Copyright © 2019,
Elsevier Inc. All rights Reserved GPU Organization Graphical Processing Units
30.
30 Copyright © 2019,
Elsevier Inc. All rights Reserved NVIDIA Instruction Set Arch. ISA is an abstraction of the hardware instruction set “Parallel Thread Execution (PTX)” opcode.type d,a,b,c; Uses virtual registers Translation to machine code is performed in software Example: shl.s32 R8, blockIdx, 9 ; Thread Block ID * Block size (512 or 29) add.s32 R8, R8, threadIdx ; R8 = i = my CUDA thread ID ld.global.f64 RD0, [X+R8] ; RD0 = X[i] ld.global.f64 RD2, [Y+R8] ; RD2 = Y[i] mul.f64 R0D, RD0, RD4 ; Product in RD0 = RD0 * RD4 (scalar a) add.f64 R0D, RD0, RD2 ; Sum in RD0 = RD0 + RD2 (Y[i]) st.global.f64 [Y+R8], RD0 ; Y[i] = sum (X[i]*a + Y[i]) Graphical Processing Units
31.
31 Copyright © 2019,
Elsevier Inc. All rights Reserved Conditional Branching Like vector architectures, GPU branch hardware uses internal masks Also uses Branch synchronization stack Entries consist of masks for each SIMD lane I.e. which threads commit their results (all threads execute) Instruction markers to manage when a branch diverges into multiple execution paths Push on divergent branch …and when paths converge Act as barriers Pops stack Per-thread-lane 1-bit predicate register, specified by programmer Graphical Processing Units
32.
32 Copyright © 2019,
Elsevier Inc. All rights Reserved Example if (X[i] != 0) X[i] = X[i] – Y[i]; else X[i] = Z[i]; ld.global.f64 RD0, [X+R8] ; RD0 = X[i] setp.neq.s32 P1, RD0, #0 ; P1 is predicate register 1 @!P1, bra ELSE1, *Push ; Push old mask, set new mask bits ; if P1 false, go to ELSE1 ld.global.f64 RD2, [Y+R8] ; RD2 = Y[i] sub.f64 RD0, RD0, RD2 ; Difference in RD0 st.global.f64 [X+R8], RD0 ; X[i] = RD0 @P1, bra ENDIF1, *Comp ; complement mask bits ; if P1 true, go to ENDIF1 ELSE1: ld.global.f64 RD0, [Z+R8] ; RD0 = Z[i] st.global.f64 [X+R8], RD0 ; X[i] = RD0 ENDIF1: <next instruction>, *Pop ; pop to restore old mask Graphical Processing Units
33.
33 Copyright © 2019,
Elsevier Inc. All rights Reserved NVIDIA GPU Memory Structures Each SIMD Lane has private section of off-chip DRAM “Private memory” Contains stack frame, spilling registers, and private variables Each multithreaded SIMD processor also has local memory Shared by SIMD lanes / threads within a block Memory shared by SIMD processors is GPU Memory Host can read and write GPU memory Graphical Processing Units
34.
34 Copyright © 2019,
Elsevier Inc. All rights Reserved Pascal Architecture Innovations Each SIMD processor has Two or four SIMD thread schedulers, two instruction dispatch units 16 SIMD lanes (SIMD width=32, chime=2 cycles), 16 load-store units, 4 special function units Two threads of SIMD instructions are scheduled every two clock cycles Fast single-, double-, and half-precision High Bandwith Memory 2 (HBM2) at 732 GB/s NVLink between multiple GPUs (20 GB/s in each direction) Unified virtual memory and paging support Graphical Processing Units
35.
35 Copyright © 2019,
Elsevier Inc. All rights Reserved Pascal Multithreaded SIMD Proc. Graphical Processing Units
36.
36 Copyright © 2019,
Elsevier Inc. All rights Reserved Vector Architectures vs GPUs SIMD processor analogous to vector processor, both have MIMD Registers RV64V register file holds entire vectors GPU distributes vectors across the registers of SIMD lanes RV64 has 32 vector registers of 32 elements (1024) GPU has 256 registers with 32 elements each (8K) RV64 has 2 to 8 lanes with vector length of 32, chime is 4 to 16 cycles SIMD processor chime is 2 to 4 cycles GPU vectorized loop is grid All GPU loads are gather instructions and all GPU stores are scatter instructions Graphical Processing Units
37.
37 Copyright © 2019,
Elsevier Inc. All rights Reserved SIMD Architectures vs GPUs GPUs have more SIMD lanes GPUs have hardware support for more threads Both have 2:1 ratio between double- and single-precision performance Both have 64-bit addresses, but GPUs have smaller memory SIMD architectures have no scatter-gather support Graphical Processing Units
38.
38 Copyright © 2019,
Elsevier Inc. All rights Reserved Loop-Level Parallelism Focuses on determining whether data accesses in later iterations are dependent on data values produced in earlier iterations Loop-carried dependence Example 1: for (i=999; i>=0; i=i-1) x[i] = x[i] + s; No loop-carried dependence Detecting and Enhancing Loop-Level Parallelism
39.
39 Copyright © 2019,
Elsevier Inc. All rights Reserved Loop-Level Parallelism Example 2: for (i=0; i<100; i=i+1) { A[i+1] = A[i] + C[i]; /* S1 */ B[i+1] = B[i] + A[i+1]; /* S2 */ } S1 and S2 use values computed by S1 in previous iteration S2 uses value computed by S1 in same iteration Detecting and Enhancing Loop-Level Parallelism
40.
40 Copyright © 2019,
Elsevier Inc. All rights Reserved Loop-Level Parallelism Example 3: for (i=0; i<100; i=i+1) { A[i] = A[i] + B[i]; /* S1 */ B[i+1] = C[i] + D[i]; /* S2 */ } S1 uses value computed by S2 in previous iteration but dependence is not circular so loop is parallel Transform to: A[0] = A[0] + B[0]; for (i=0; i<99; i=i+1) { B[i+1] = C[i] + D[i]; A[i+1] = A[i+1] + B[i+1]; } B[100] = C[99] + D[99]; Detecting and Enhancing Loop-Level Parallelism
41.
41 Copyright © 2019,
Elsevier Inc. All rights Reserved Loop-Level Parallelism Example 4: for (i=0;i<100;i=i+1) { A[i] = B[i] + C[i]; D[i] = A[i] * E[i]; } Example 5: for (i=1;i<100;i=i+1) { Y[i] = Y[i-1] + Y[i]; } Detecting and Enhancing Loop-Level Parallelism
42.
42 Copyright © 2019,
Elsevier Inc. All rights Reserved Finding dependencies Assume indices are affine: a x i + b (i is loop index) Assume: Store to a x i + b, then Load from c x i + d i runs from m to n Dependence exists if: Given j, k such that m ≤ j ≤ n, m ≤ k ≤ n Store to a x j + b, load from a x k + d, and a x j + b = c x k + d Detecting and Enhancing Loop-Level Parallelism
43.
43 Copyright © 2019,
Elsevier Inc. All rights Reserved Finding dependencies Generally cannot determine at compile time Test for absence of a dependence: GCD test: If a dependency exists, GCD(c,a) must evenly divide (d-b) Example: for (i=0; i<100; i=i+1) { X[2*i+3] = X[2*i] * 5.0; } Detecting and Enhancing Loop-Level Parallelism
44.
44 Copyright © 2019,
Elsevier Inc. All rights Reserved Finding dependencies Example 2: for (i=0; i<100; i=i+1) { Y[i] = X[i] / c; /* S1 */ X[i] = X[i] + c; /* S2 */ Z[i] = Y[i] + c; /* S3 */ Y[i] = c - Y[i]; /* S4 */ } Watch for antidependencies and output dependencies Detecting and Enhancing Loop-Level Parallelism
45.
45 Copyright © 2019,
Elsevier Inc. All rights Reserved Finding dependencies Example 2: for (i=0; i<100; i=i+1) { Y[i] = X[i] / c; /* S1 */ X[i] = X[i] + c; /* S2 */ Z[i] = Y[i] + c; /* S3 */ Y[i] = c - Y[i]; /* S4 */ } Watch for antidependencies and output dependencies Detecting and Enhancing Loop-Level Parallelism
46.
46 Copyright © 2019,
Elsevier Inc. All rights Reserved Reductions Reduction Operation: for (i=9999; i>=0; i=i-1) sum = sum + x[i] * y[i]; Transform to… for (i=9999; i>=0; i=i-1) sum [i] = x[i] * y[i]; for (i=9999; i>=0; i=i-1) finalsum = finalsum + sum[i]; Do on p processors: for (i=999; i>=0; i=i-1) finalsum[p] = finalsum[p] + sum[i+1000*p]; Note: assumes associativity! Detecting and Enhancing Loop-Level Parallelism
47.
47 Copyright © 2019,
Elsevier Inc. All rights Reserved Fallacies and Pitfalls GPUs suffer from being coprocessors GPUs have flexibility to change ISA Concentrating on peak performance in vector architectures and ignoring start-up overhead Overheads require long vector lengths to achieve speedup Increasing vector performance without comparable increases in scalar performance You can get good vector performance without providing memory bandwidth On GPUs, just add more threads if you don’t have enough memory performance Fallacies and Pitfalls
Download










![12 Copyright © 2019, Elsevier Inc. All rights Reserved Vector Length Register for (i=0; i <n; i=i+1) Y[i] = a * X[i] + Y[i]; vsetdcfg 2 DP FP # Enable 2 64b Fl.Pt. registers fld f0,a # Load scalar a loop: setvl t0,a0 # vl = t0 = min(mvl,n) vld v0,x5 # Load vector X slli t1,t0,3 # t1 = vl * 8 (in bytes) add x5,x5,t1 # Increment pointer to X by vl*8 vmul v0,v0,f0 # Vector-scalar mult vld v1,x6 # Load vector Y vadd v1,v0,v1 # Vector-vector add sub a0,a0,t0 # n -= vl (t0) vst v1,x6 # Store the sum into Y add x6,x6,t1 # Increment pointer to Y by vl*8 bnez a0,loop # Repeat if n != 0 vdisable # Disable vector regs} Vector Architectures](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-12-2048.jpg)
![13 Copyright © 2019, Elsevier Inc. All rights Reserved Vector Mask Registers Consider: for (i = 0; i < 64; i=i+1) if (X[i] != 0) X[i] = X[i] – Y[i]; Use predicate register to “disable” elements: vsetdcfg 2*FP64 # Enable 2 64b FP vector regs vsetpcfgi 1 # Enable 1 predicate register vld v0,x5 # Load vector X into v0 vld v1,x6 # Load vector Y into v1 fmv.d.x f0,x0 # Put (FP) zero into f0 vpne p0,v0,f0 # Set p0(i) to 1 if v0(i)!=f0 vsub v0,v0,v1 # Subtract under vector mask vst v0,x5 # Store the result in X vdisable # Disable vector registers vpdisable # Disable predicate registers Vector Architectures](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-13-2048.jpg)

![15 Copyright © 2019, Elsevier Inc. All rights Reserved Stride Consider: for (i = 0; i < 100; i=i+1) for (j = 0; j < 100; j=j+1) { A[i][j] = 0.0; for (k = 0; k < 100; k=k+1) A[i][j] = A[i][j] + B[i][k] * D[k][j]; } Must vectorize multiplication of rows of B with columns of D Use non-unit stride Bank conflict (stall) occurs when the same bank is hit faster than bank busy time: #banks / LCM(stride,#banks) < bank busy time Vector Architectures](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-15-2048.jpg)
![16 Copyright © 2019, Elsevier Inc. All rights Reserved Scatter-Gather Consider: for (i = 0; i < n; i=i+1) A[K[i]] = A[K[i]] + C[M[i]]; Use index vector: vsetdcfg 4*FP64 # 4 64b FP vector registers vld v0, x7 # Load K[] vldx v1, x5, v0 # Load A[K[]] vld v2, x28 # Load M[] vldi v3, x6, v2 # Load C[M[]] vadd v1, v1, v3 # Add them vstx v1, x5, v0 # Store A[K[]] vdisable # Disable vector registers Vector Architectures](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-16-2048.jpg)


![20 Copyright © 2019, Elsevier Inc. All rights Reserved Example SIMD Code Example DXPY: fld f0,a # Load scalar a splat.4D f0,f0 # Make 4 copies of a addi x28,x5,#256 # Last address to load Loop: fld.4D f1,0(x5) # Load X[i] ... X[i+3] fmul.4D f1,f1,f0 # a x X[i] ... a x X[i+3] fld.4D f2,0(x6) # Load Y[i] ... Y[i+3] fadd.4D f2,f2,f1 # a x X[i]+Y[i]... # a x X[i+3]+Y[i+3] fsd.4D f2,0(x6) # Store Y[i]... Y[i+3] addi x5,x5,#32 # Increment index to X addi x6,x6,#32 # Increment index to Y bne x28,x5,Loop # Check if done SIMD Instruction Set Extensions for Multimedia](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-20-2048.jpg)







![30 Copyright © 2019, Elsevier Inc. All rights Reserved NVIDIA Instruction Set Arch. ISA is an abstraction of the hardware instruction set “Parallel Thread Execution (PTX)” opcode.type d,a,b,c; Uses virtual registers Translation to machine code is performed in software Example: shl.s32 R8, blockIdx, 9 ; Thread Block ID * Block size (512 or 29) add.s32 R8, R8, threadIdx ; R8 = i = my CUDA thread ID ld.global.f64 RD0, [X+R8] ; RD0 = X[i] ld.global.f64 RD2, [Y+R8] ; RD2 = Y[i] mul.f64 R0D, RD0, RD4 ; Product in RD0 = RD0 * RD4 (scalar a) add.f64 R0D, RD0, RD2 ; Sum in RD0 = RD0 + RD2 (Y[i]) st.global.f64 [Y+R8], RD0 ; Y[i] = sum (X[i]*a + Y[i]) Graphical Processing Units](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-30-2048.jpg)

![32 Copyright © 2019, Elsevier Inc. All rights Reserved Example if (X[i] != 0) X[i] = X[i] – Y[i]; else X[i] = Z[i]; ld.global.f64 RD0, [X+R8] ; RD0 = X[i] setp.neq.s32 P1, RD0, #0 ; P1 is predicate register 1 @!P1, bra ELSE1, *Push ; Push old mask, set new mask bits ; if P1 false, go to ELSE1 ld.global.f64 RD2, [Y+R8] ; RD2 = Y[i] sub.f64 RD0, RD0, RD2 ; Difference in RD0 st.global.f64 [X+R8], RD0 ; X[i] = RD0 @P1, bra ENDIF1, *Comp ; complement mask bits ; if P1 true, go to ENDIF1 ELSE1: ld.global.f64 RD0, [Z+R8] ; RD0 = Z[i] st.global.f64 [X+R8], RD0 ; X[i] = RD0 ENDIF1: <next instruction>, *Pop ; pop to restore old mask Graphical Processing Units](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-32-2048.jpg)





![38 Copyright © 2019, Elsevier Inc. All rights Reserved Loop-Level Parallelism Focuses on determining whether data accesses in later iterations are dependent on data values produced in earlier iterations Loop-carried dependence Example 1: for (i=999; i>=0; i=i-1) x[i] = x[i] + s; No loop-carried dependence Detecting and Enhancing Loop-Level Parallelism](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-38-2048.jpg)
![39 Copyright © 2019, Elsevier Inc. All rights Reserved Loop-Level Parallelism Example 2: for (i=0; i<100; i=i+1) { A[i+1] = A[i] + C[i]; /* S1 */ B[i+1] = B[i] + A[i+1]; /* S2 */ } S1 and S2 use values computed by S1 in previous iteration S2 uses value computed by S1 in same iteration Detecting and Enhancing Loop-Level Parallelism](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-39-2048.jpg)
![40 Copyright © 2019, Elsevier Inc. All rights Reserved Loop-Level Parallelism Example 3: for (i=0; i<100; i=i+1) { A[i] = A[i] + B[i]; /* S1 */ B[i+1] = C[i] + D[i]; /* S2 */ } S1 uses value computed by S2 in previous iteration but dependence is not circular so loop is parallel Transform to: A[0] = A[0] + B[0]; for (i=0; i<99; i=i+1) { B[i+1] = C[i] + D[i]; A[i+1] = A[i+1] + B[i+1]; } B[100] = C[99] + D[99]; Detecting and Enhancing Loop-Level Parallelism](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-40-2048.jpg)
![41 Copyright © 2019, Elsevier Inc. All rights Reserved Loop-Level Parallelism Example 4: for (i=0;i<100;i=i+1) { A[i] = B[i] + C[i]; D[i] = A[i] * E[i]; } Example 5: for (i=1;i<100;i=i+1) { Y[i] = Y[i-1] + Y[i]; } Detecting and Enhancing Loop-Level Parallelism](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-41-2048.jpg)

![43 Copyright © 2019, Elsevier Inc. All rights Reserved Finding dependencies Generally cannot determine at compile time Test for absence of a dependence: GCD test: If a dependency exists, GCD(c,a) must evenly divide (d-b) Example: for (i=0; i<100; i=i+1) { X[2*i+3] = X[2*i] * 5.0; } Detecting and Enhancing Loop-Level Parallelism](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-43-2048.jpg)
![44 Copyright © 2019, Elsevier Inc. All rights Reserved Finding dependencies Example 2: for (i=0; i<100; i=i+1) { Y[i] = X[i] / c; /* S1 */ X[i] = X[i] + c; /* S2 */ Z[i] = Y[i] + c; /* S3 */ Y[i] = c - Y[i]; /* S4 */ } Watch for antidependencies and output dependencies Detecting and Enhancing Loop-Level Parallelism](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-44-2048.jpg)
![45 Copyright © 2019, Elsevier Inc. All rights Reserved Finding dependencies Example 2: for (i=0; i<100; i=i+1) { Y[i] = X[i] / c; /* S1 */ X[i] = X[i] + c; /* S2 */ Z[i] = Y[i] + c; /* S3 */ Y[i] = c - Y[i]; /* S4 */ } Watch for antidependencies and output dependencies Detecting and Enhancing Loop-Level Parallelism](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-45-2048.jpg)
![46 Copyright © 2019, Elsevier Inc. All rights Reserved Reductions Reduction Operation: for (i=9999; i>=0; i=i-1) sum = sum + x[i] * y[i]; Transform to… for (i=9999; i>=0; i=i-1) sum [i] = x[i] * y[i]; for (i=9999; i>=0; i=i-1) finalsum = finalsum + sum[i]; Do on p processors: for (i=999; i>=0; i=i-1) finalsum[p] = finalsum[p] + sum[i+1000*p]; Note: assumes associativity! Detecting and Enhancing Loop-Level Parallelism](https://image.slidesharecdn.com/ch4-250914033334-2f0ac2e5/75/Chapter-4-Data-Level-Parallelism-in-Vector-SIMD-and-GPU-Architectures-46-2048.jpg)
