Downloaded 191 times


















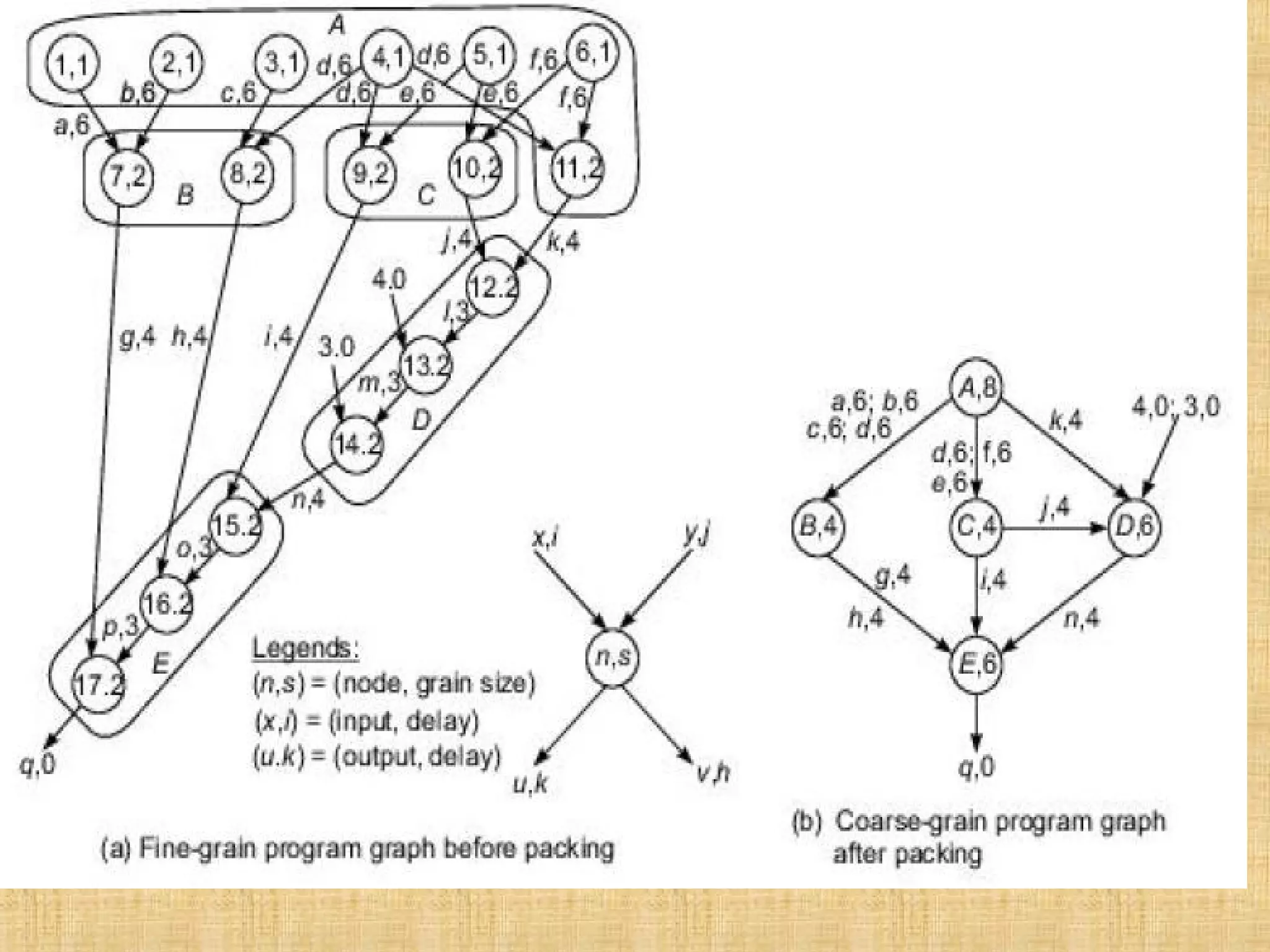
![The basic concept of program partitioning is introduced here . In Fig. we show an example program graph in two different grain sizes. A program graph shows the structure of a program. It is very similar to the dependence graph . Each node in the program graph corresponds to a computational unit in the program. The grain size is measured by the number of basic machine cycle[including both processor and memory cycles] needed to execute all the operations within the node. We denote each node in Fig. by a pair (n,s) , where n is the node name {id} and s is the grain size of the node. Thus grain size reflects the number of computations involved in a program segment. Fine-grain nodes have a smaller grain size. and coarse-grain nodes have a larger grain size.](https://image.slidesharecdn.com/unit-1-programpartitioningandscheduling1-190323083003/75/program-partitioning-and-scheduling-IN-Advanced-Computer-Architecture-20-2048.jpg)
![The edge label (v,d) between two end nodes specifies the output variable v from the source node or the input variable to the destination node , and the communication delay d between them. This delay includes all the path delays and memory latency involved. There are 17 nodes in the fine-grain program graph (Fig. a) and 5 in the coarse-grain program graph (Fig. b]. The coarse-grain node is obtained by combining {grouping} multiple fine-grain nodes. The fine grain corresponds to the following program:](https://image.slidesharecdn.com/unit-1-programpartitioningandscheduling1-190323083003/75/program-partitioning-and-scheduling-IN-Advanced-Computer-Architecture-21-2048.jpg)





The document discusses program partitioning and scheduling in advanced computer architecture, emphasizing the transformation of sequential programs into parallel forms. It details granularity levels (fine, medium, coarse) in parallel execution and the associated latencies, communication demands, and techniques like grain packing to optimize execution time and resource allocation. Furthermore, it illustrates the trade-offs between parallelism, scheduling overhead, and communication latency in the design of parallel computing systems.