Downloaded 386 times






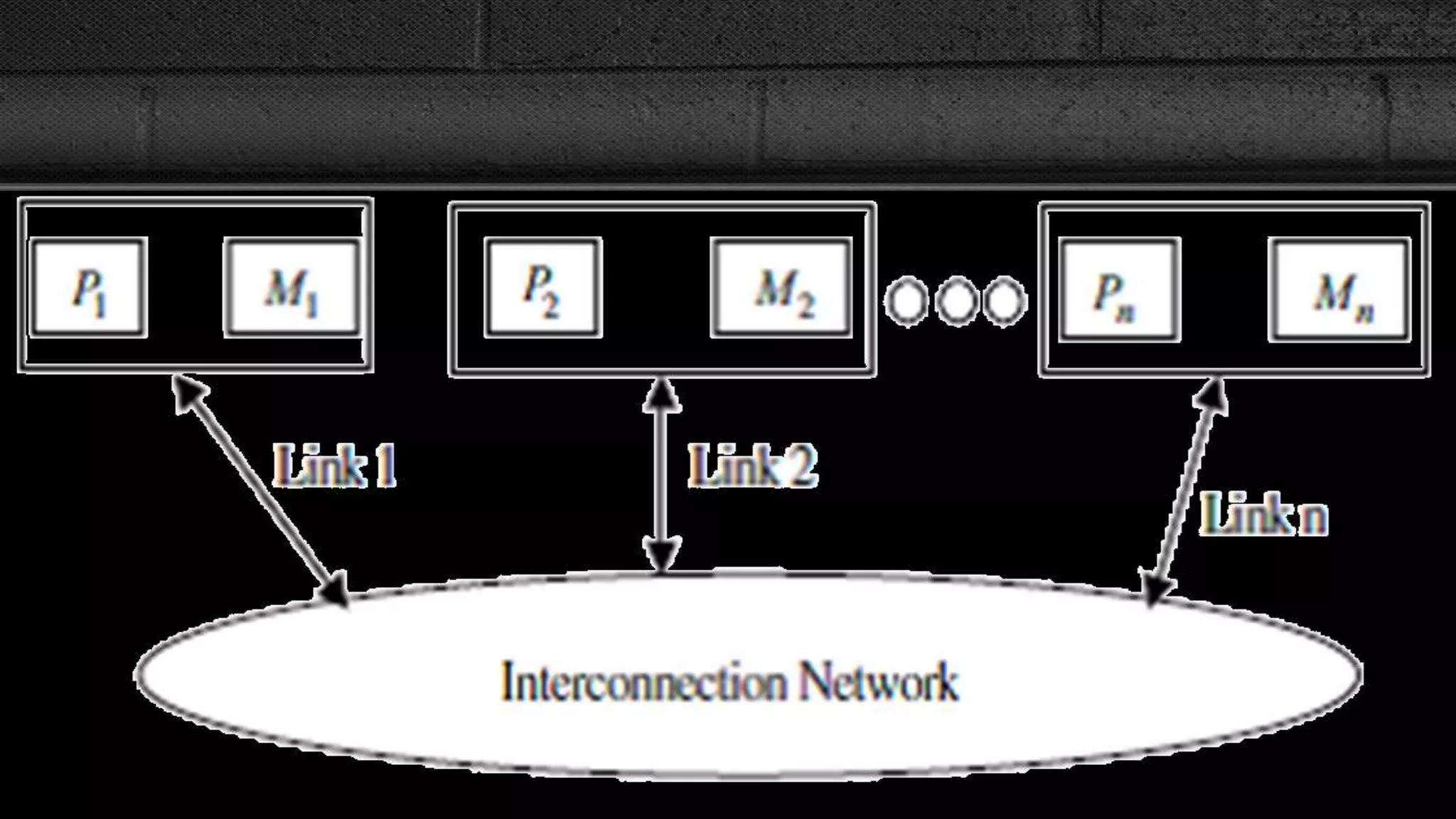








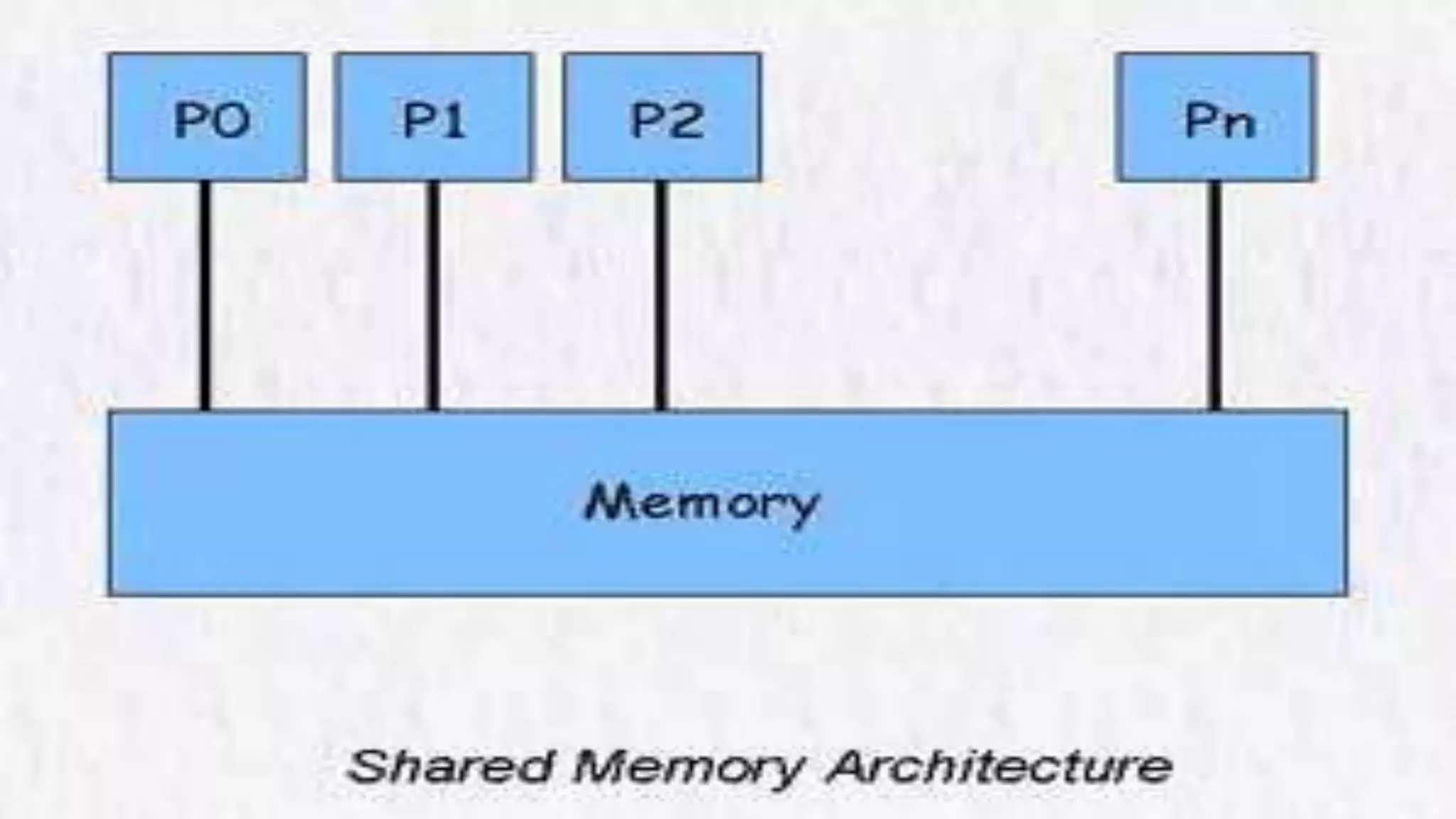



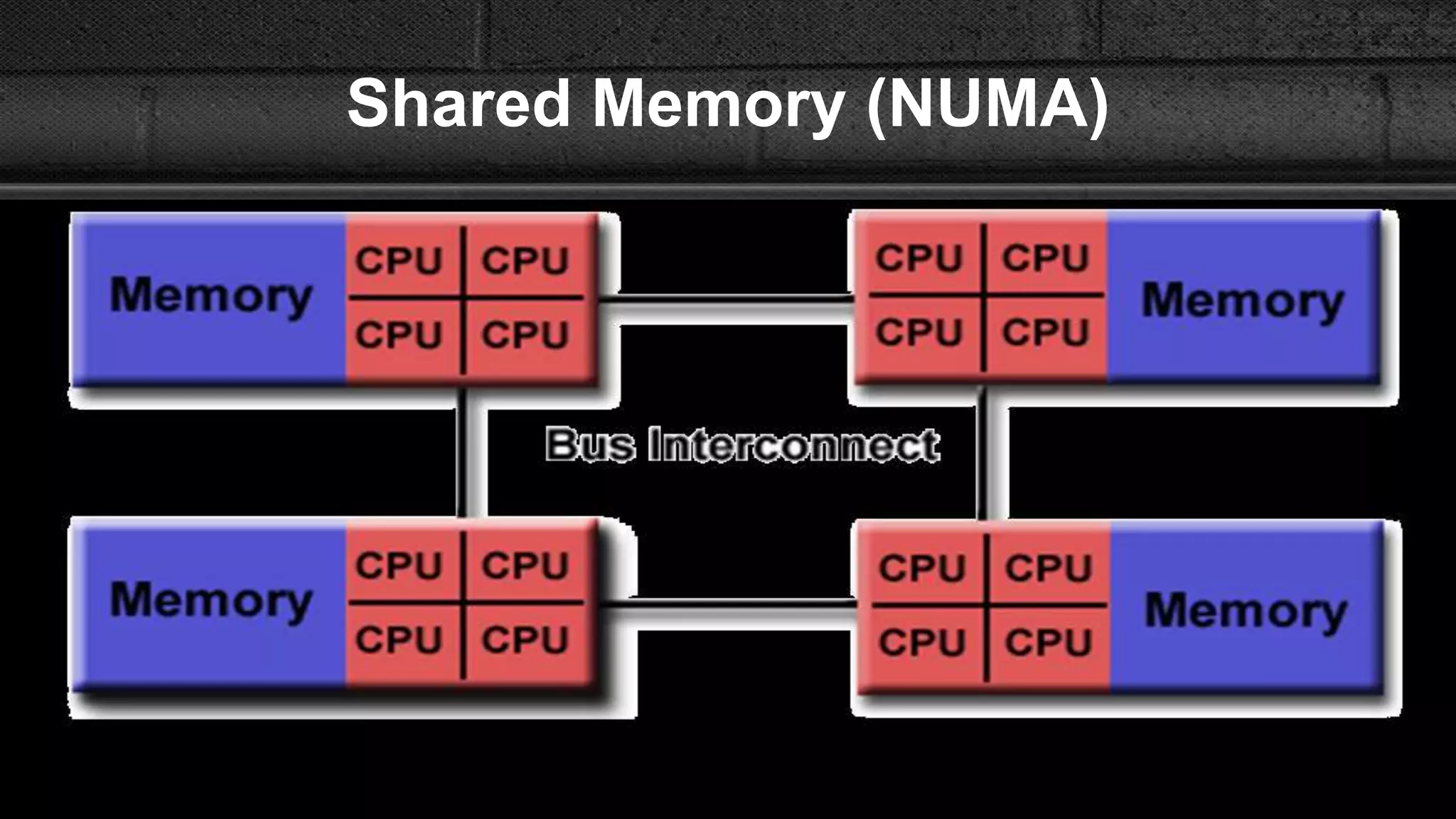










This document compares message passing and shared memory architectures for parallel computing. It defines message passing as processors communicating through sending and receiving messages without a global memory, while shared memory allows processors to communicate through a shared virtual address space. The key difference is that message passing uses explicit communication through messages, while shared memory uses implicit communication through memory operations. It also discusses how the programming model and hardware architecture can be separated, with message passing able to support shared memory and vice versa.