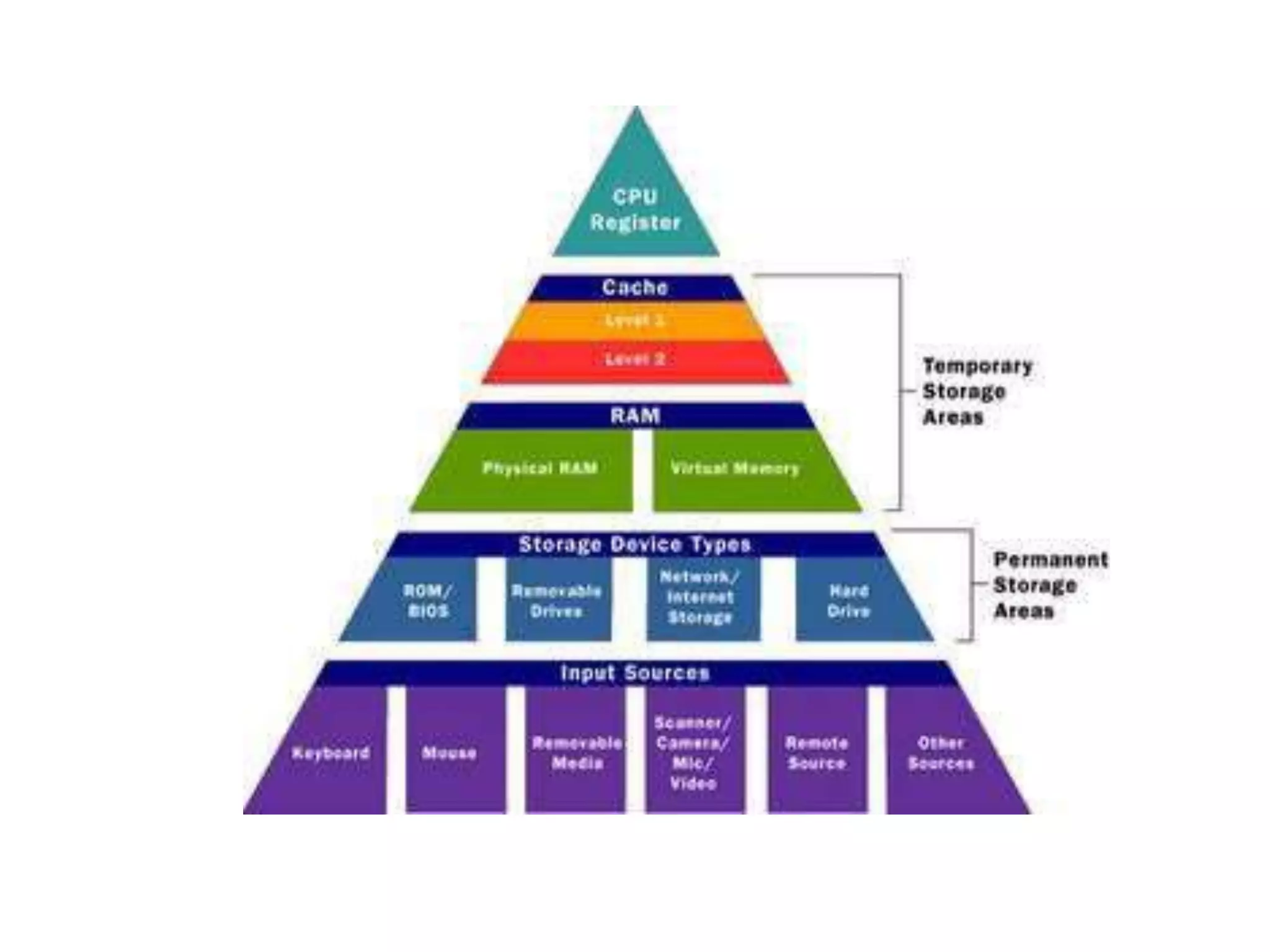
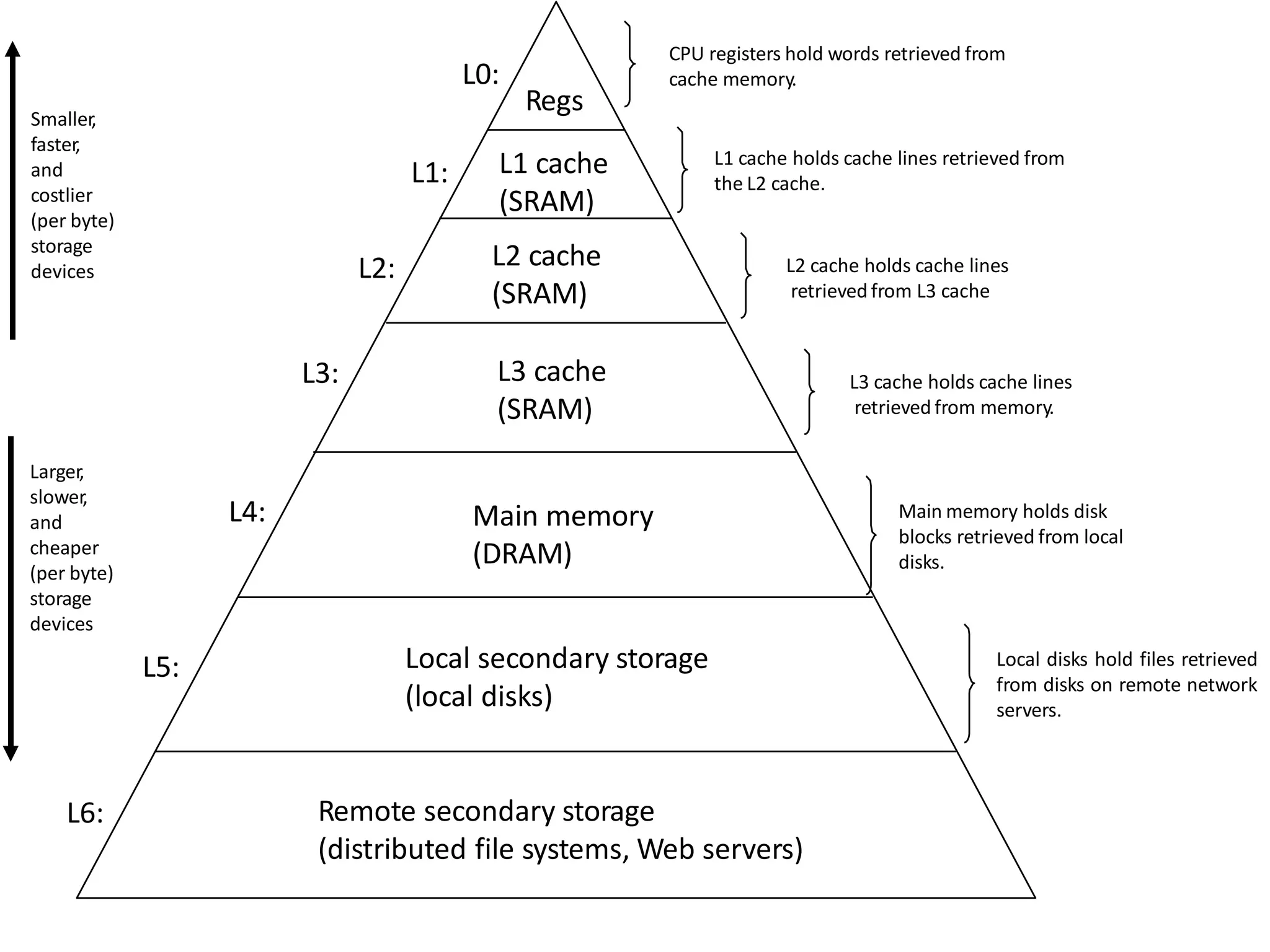
The document discusses computer memory hierarchy and cache organization. It begins by outlining the memory pyramid from fastest and smallest registers to largest but slowest hard disks. It then discusses cache organization including direct mapped, set associative and fully associative caches. The key points are: Caches aim to bridge the speed gap between fast processors and slow main memory. Caches exploit temporal and spatial locality to reduce average memory access time. Caches are organized into blocks and sets to store recently accessed data from main memory.
Overview of computer architecture, including memory hierarchy and pyramid structure. Topics include cache organization and locality of reference.
Discusses ideal memory characteristics as per programmers' needs; emphasizes faster, larger, and cheaper memory.
Detailed explanation of memory hierarchy including registers, various cache levels, main memory, and storage devices.
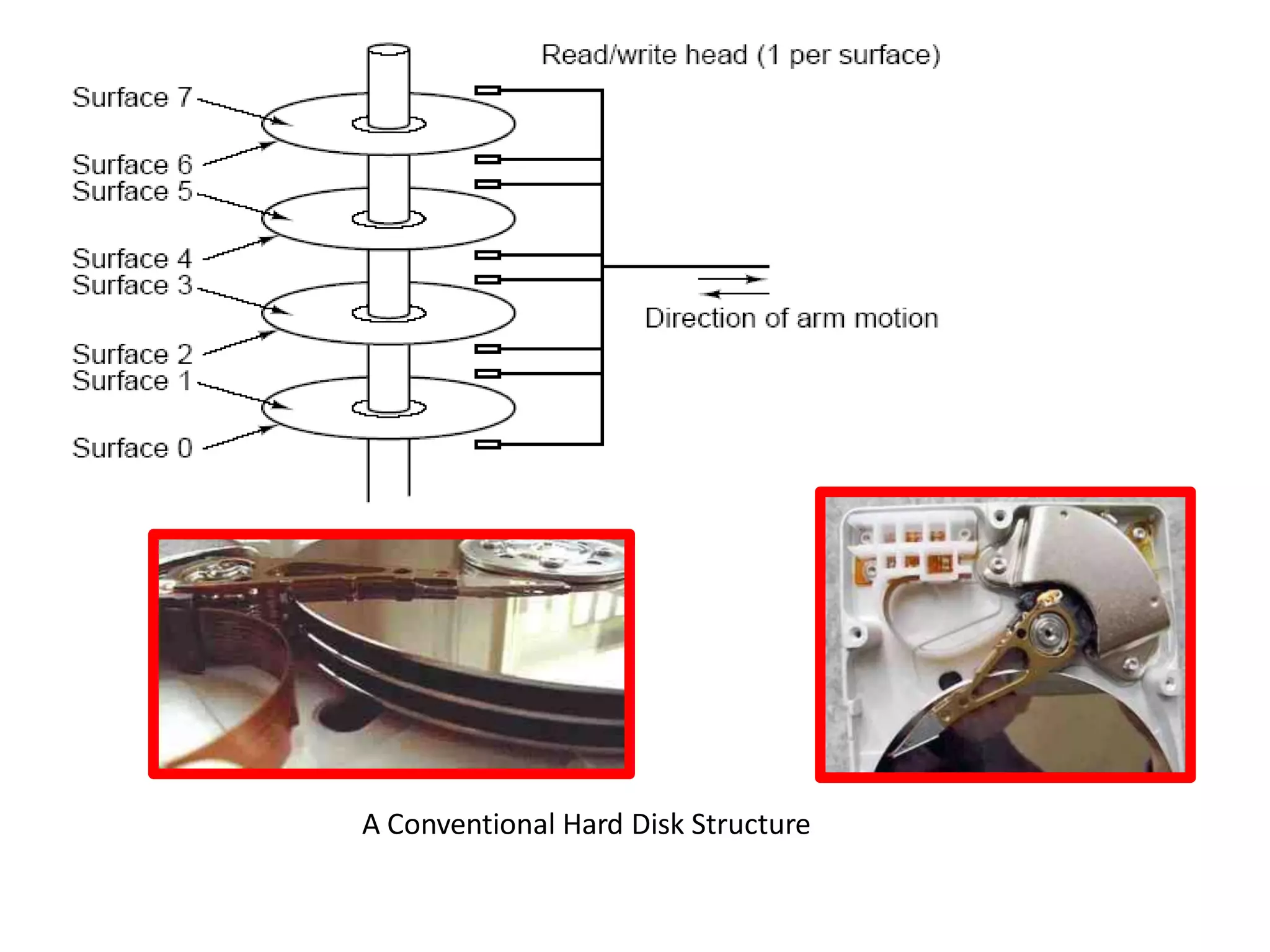
History and structure of hard disks, including data access mechanics and performance improvements over time.
Describes hard disk structure, tracks, sectors, and performance metrics such as seek time and transfer time.
Comparison of flash storage types (NOR vs NAND), performance, usage, and longevity in electronic storage.
Examines DRAM technology, packaging, and specifics related to data transfer and memory modules.
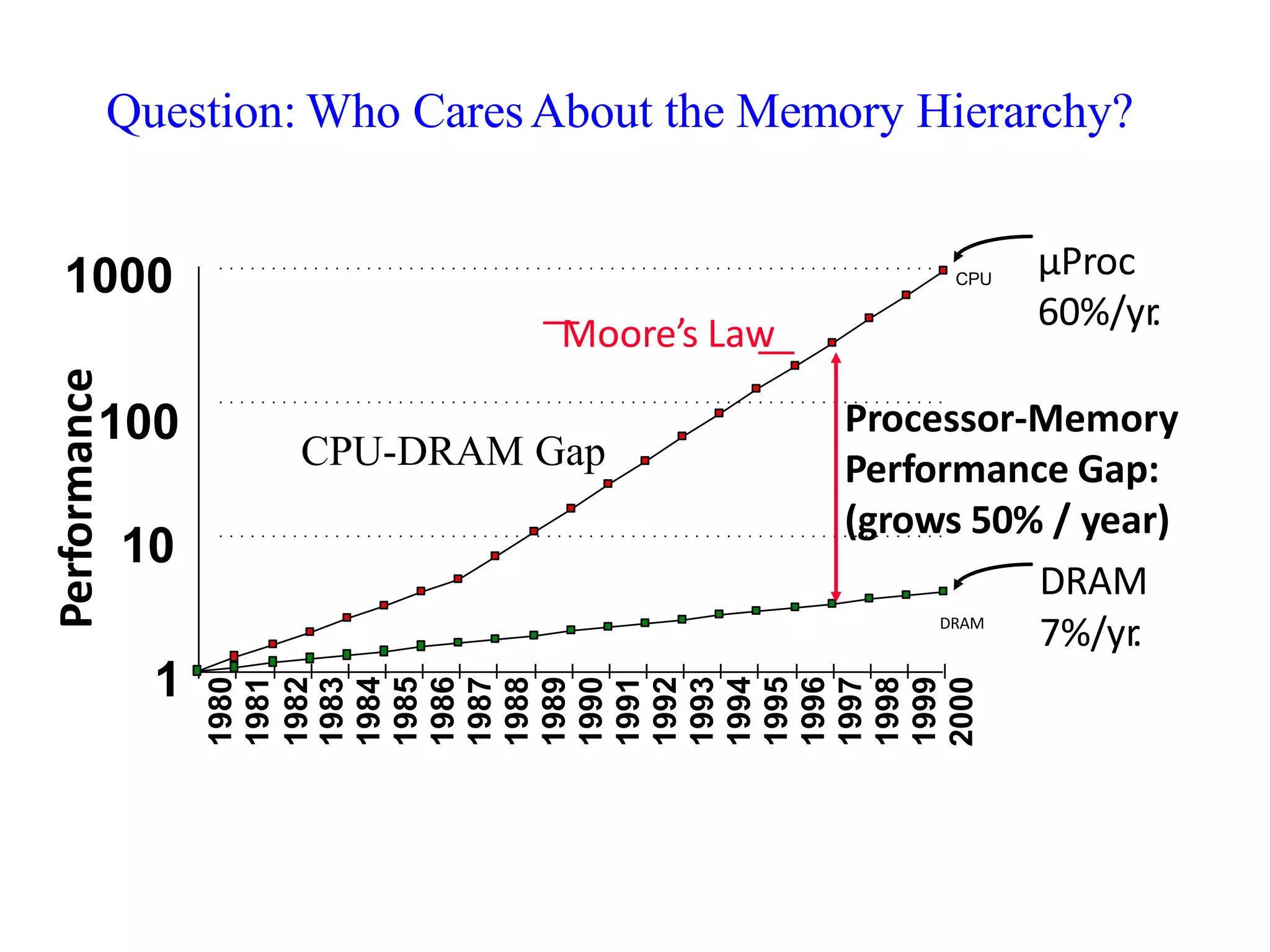
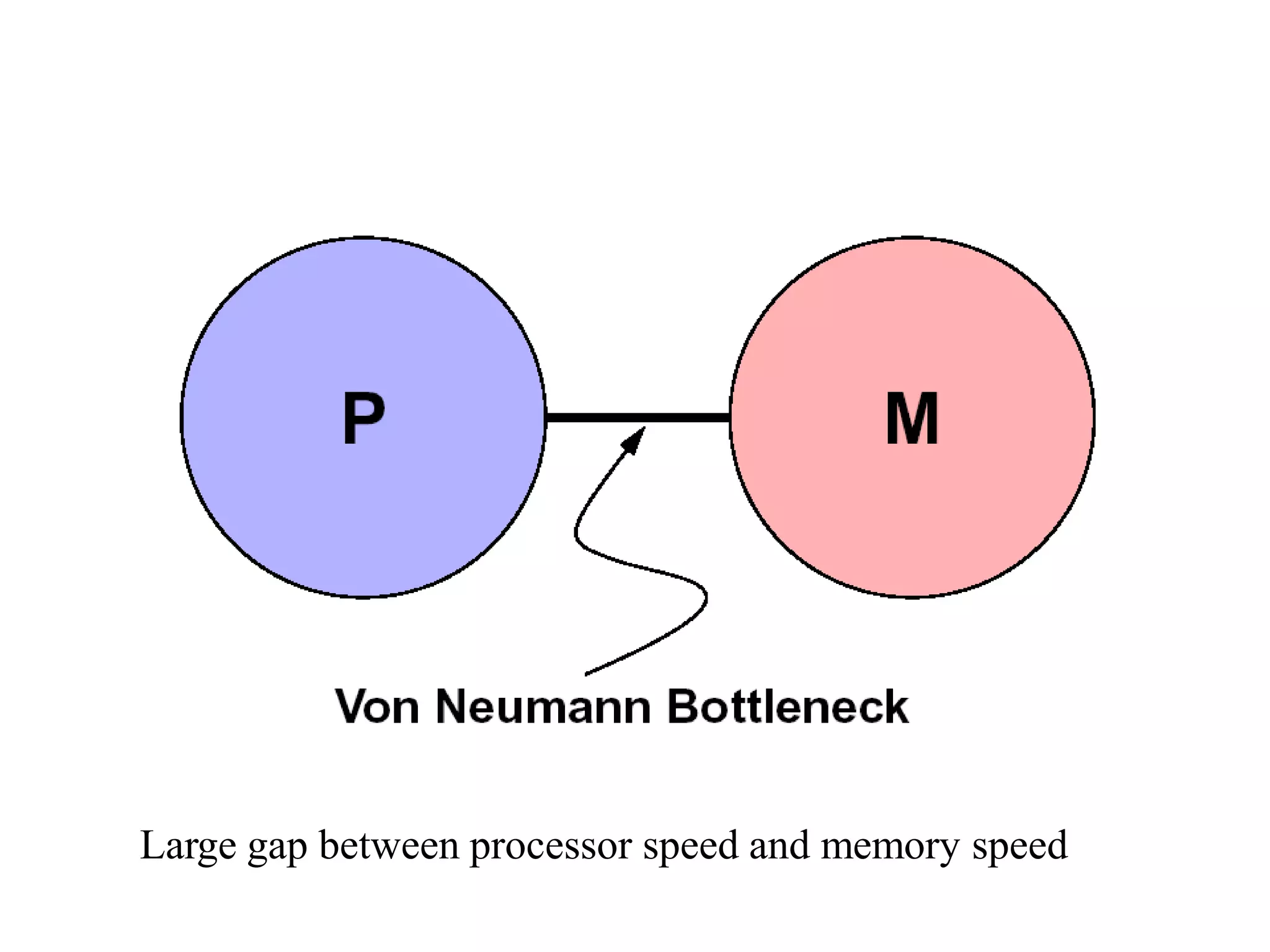
Explores cache memory, the gap between CPU and memory speeds, and the importance of locality in programming.Detailed methods for cache organization, including direct mapping and the role of locality in cache efficiency.
Instructions for analyzing cache configurations, breakdowns utilizing associativity, and block sizes.
Strategies to improve cache performance including usage of write-back policies and multilevel caches.
Examples illustrating cache operations, hits, misses, and cache-friendly code practices in real application.
Summarizes the importance of memory hierarchy organization aiming for speed, cost, and programming locality.
IBM Disk 350,size 5MB, circa 50s source: http://royal.pingdom.com/2010/02/18/amazing-facts-and-figures-about-the-evolution-of-hard-disk-drives/ Funny facts: • It took 51 years to reach 1TB and 2 years to reach 2TB! • IBM introduced the first hard disk drive to break the 1 GB barrier in 1980.
10.
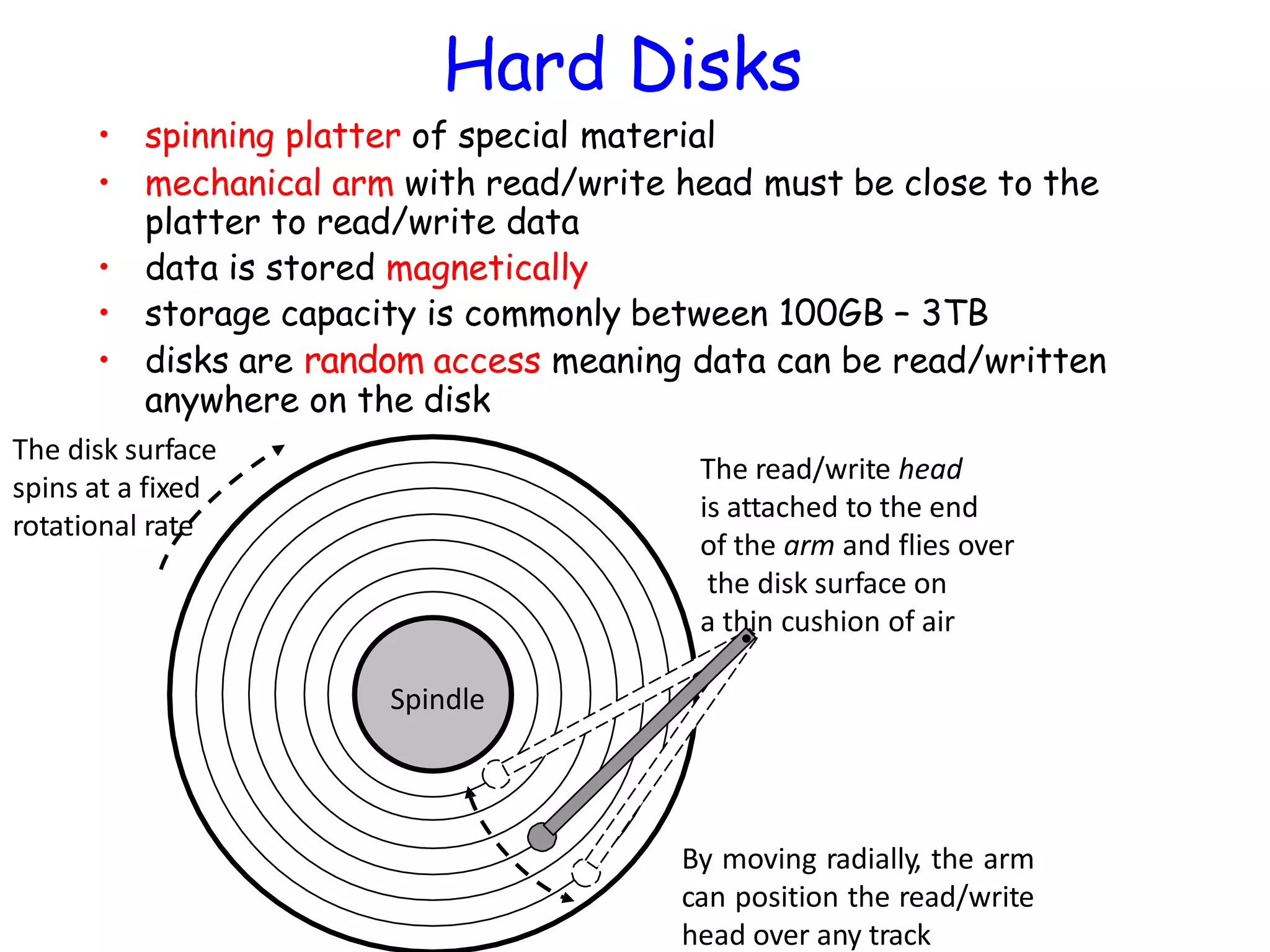
Hard Disks • spinningplatter of special material • mechanical arm with read/write head must be close to the platter to read/write data • data is stored magnetically • storage capacity is commonly between 100GB – 3TB • disks are random access meaning data can be read/written anywhere on the disk By moving radially, the arm can position the read/write head over any track Spindle The disk surface spins at a fixed rotational rate The read/write head is attached to the end of the arm and flies over the disk surface on a thin cushion of air
11.
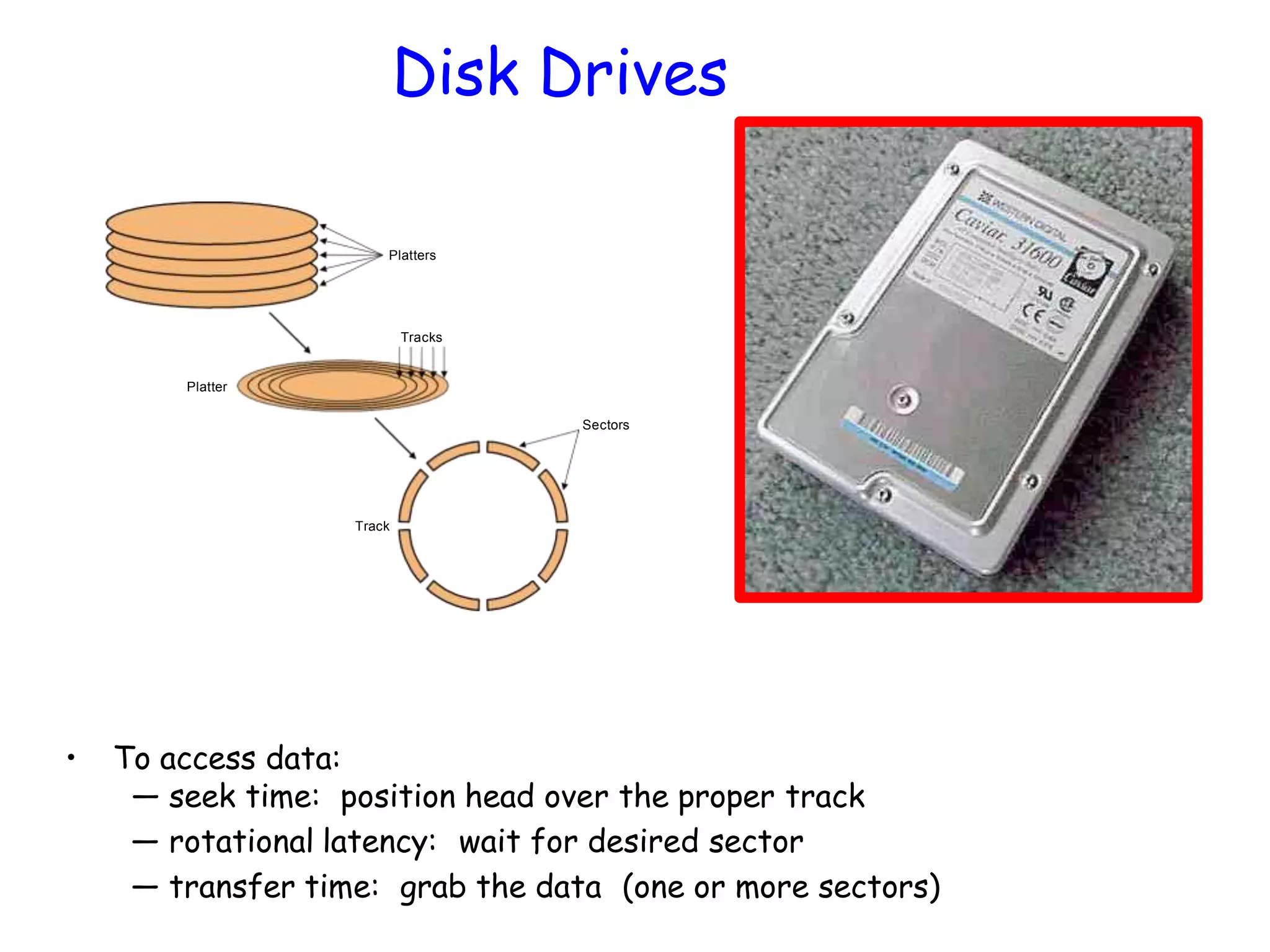
Disk Drives • Toaccess data: — seek time: position head over the proper track — rotational latency: wait for desired sector — transfer time: grab the data (one or more sectors) Tracks Platter Sectors Track Platters
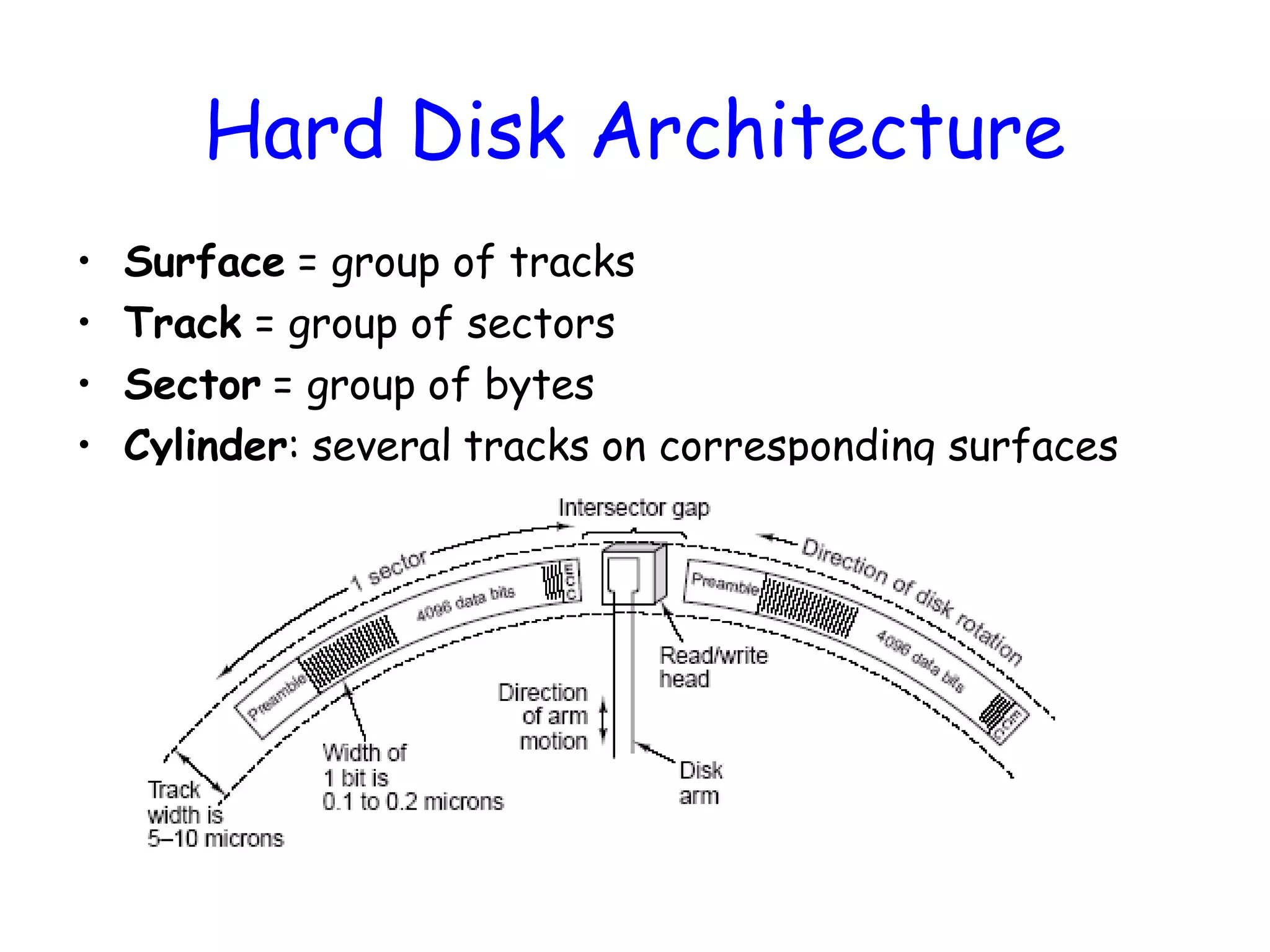
Hard Disk Architecture •Surface = group of tracks • Track = group of sectors • Sector = group of bytes • Cylinder: several tracks on corresponding surfaces
15.
Disk Sectors andAccess • Each sector records – Sector ID – Data (512 bytes, 4096 bytes proposed) – Error correcting code (ECC) • Used to hide defects and recording errors – Synchronization fields and gaps • Access to a sector involves – Queuing delay if other accesses are pending – Seek: move the heads – Rotational latency – Data transfer – Controller overhead
16.
Example of aReal Disk • Seagate Cheetah 15k.4 – 4 platters, 8 surfaces – Surface diameter: 3.5” – Formatted capacity is 146.8 GB – Rotational speed 15,000 RPM – Avg seek time: 4ms – Bytes per sector: 512 – Cylinders: 50,864
17.
Disks: Other Issues •Average seek and rotation times are helped by locality. • Disk performance improves about 10%/year • Capacity increases about 60%/year • Example of disk controllers: • SCSI, ATA, SATA
18.
Flash Storage • Nonvolatilesemiconductor storage – 100× – 1000× faster than disk – Smaller, lower power, more robust – But more $/GB (between disk and DRAM)
19.
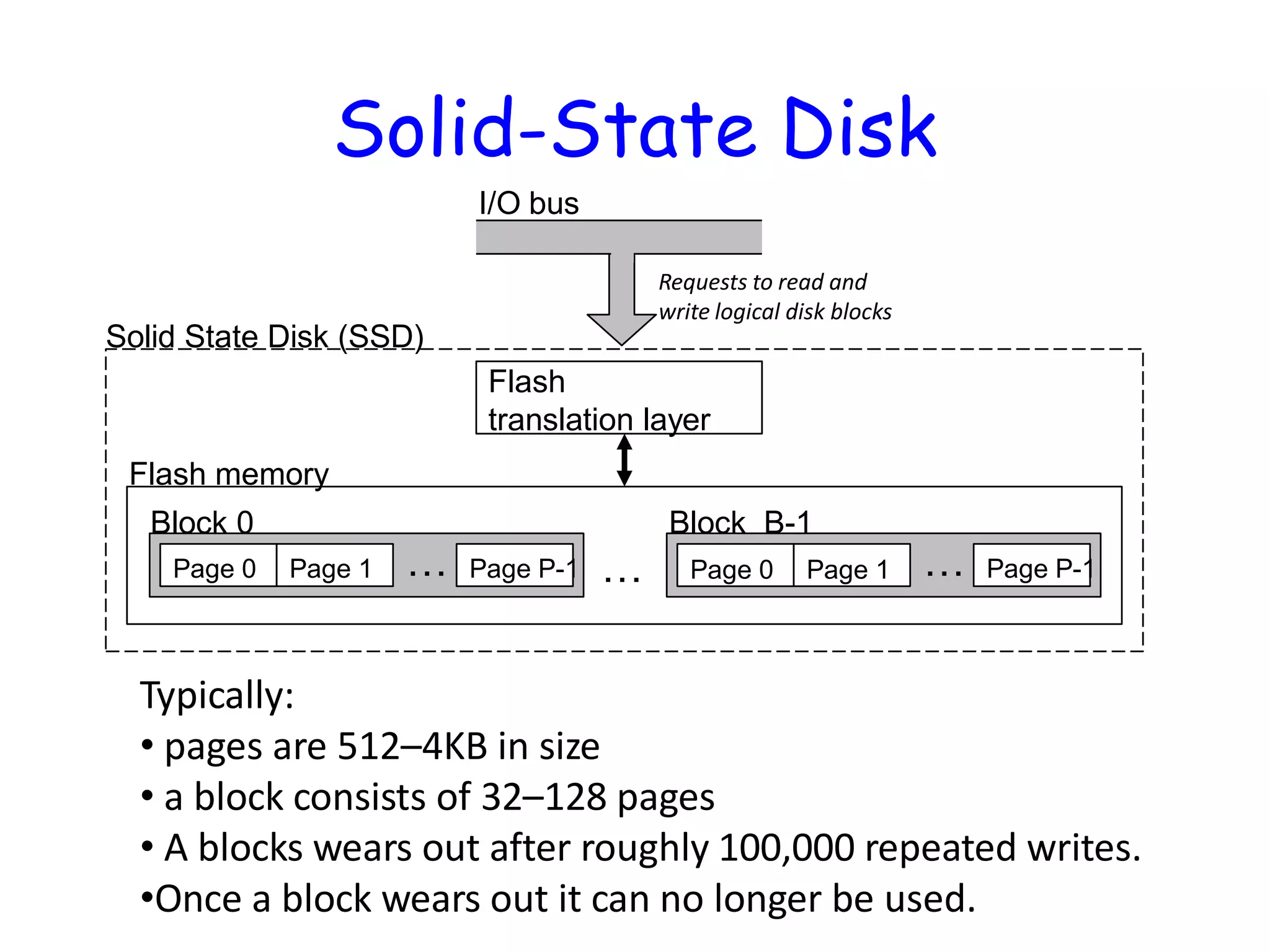
Flash Types • NORflash: bit cell like a NOR gate – Random read/write access – Used for instruction memory in embedded systems • NAND flash: bit cell like a NAND gate – Denser (bits/area), but block-at-a-time access – Cheaper per GB – Used for USB keys, media storage, … • Flash bits wears out after 1000’s of accesses – Not suitable for direct RAM or disk replacement – Wear leveling: remap data to less used blocks
20.
Flash translation layer I/O bus Page0 Page 1 Page P-1… Block 0 … Block B-1 Page 0 Page 1 Page P-1… Flash memory Solid State Disk (SSD) Requests to read and write logical disk blocks Solid-State Disk Typically: • pages are 512–4KB in size • a block consists of 32–128 pages • A blocks wears out after roughly 100,000 repeated writes. •Once a block wears out it can no longer be used.
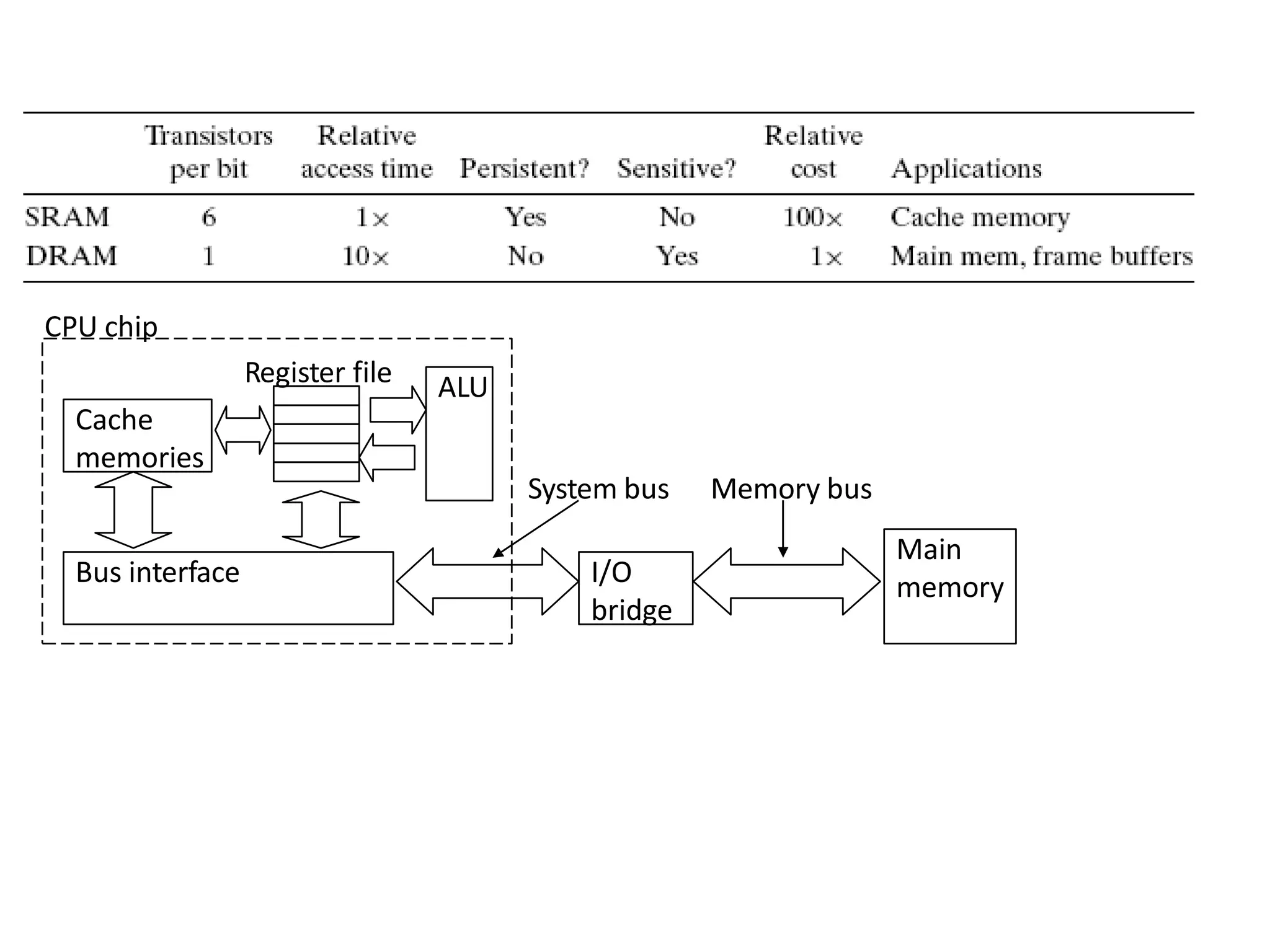
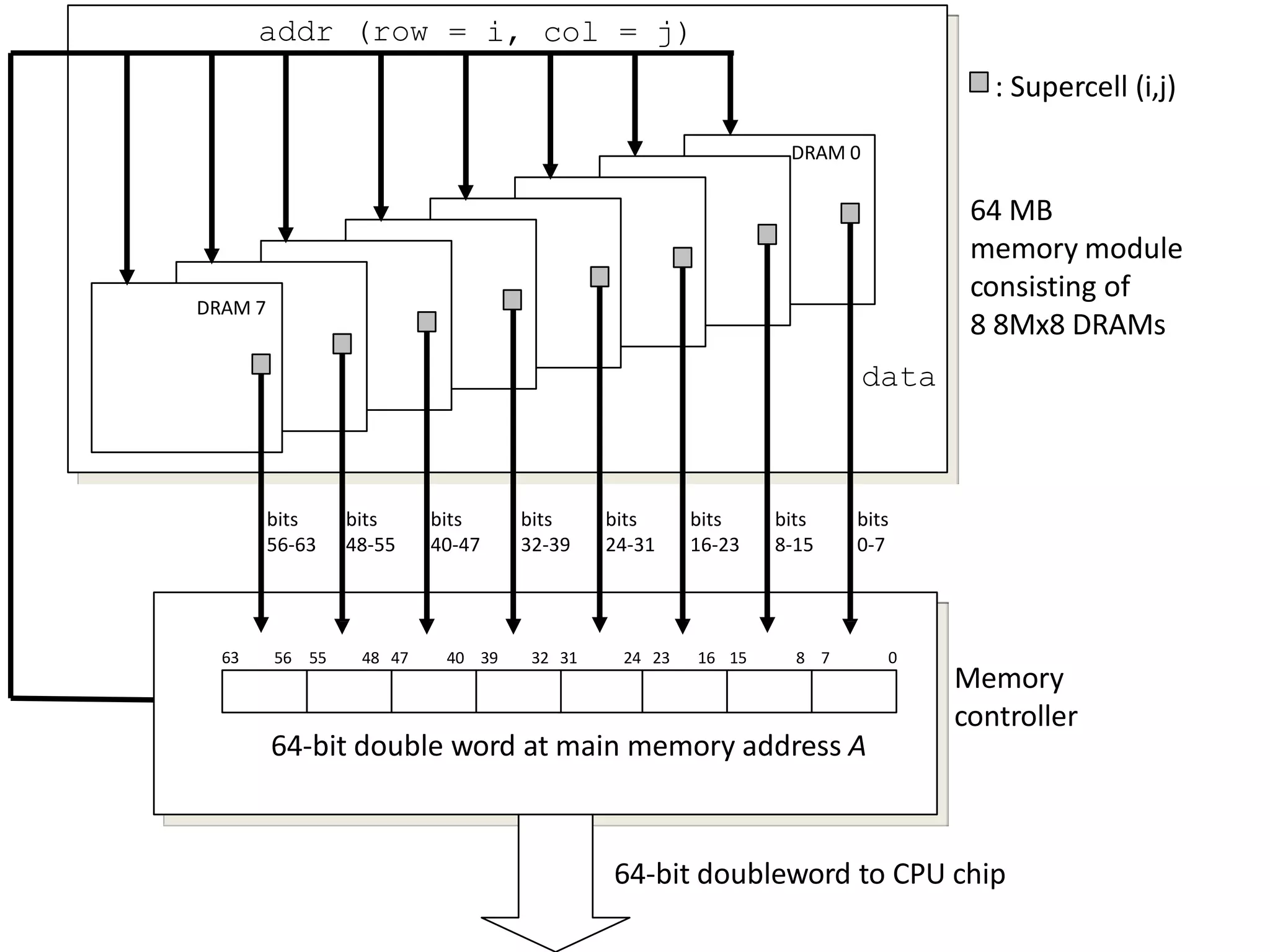
DRAM • packaged inmemory modules that plug into expansion slots on the main system board (motherboard) • Example package: 168-pin dual inline memory module (DIMM) – transfers data to and from the memory controller in 64-bit chunks
23.
: Supercell (i,j) 03231 8 716 1524 2363 40 3948 4756 55 64-bit double word at main memory address A 64-bit doubleword to CPU chip addr (row = i, col = j) data 64 MB memory module consisting of 8 8Mx8 DRAMs Memory controller bits 0-7 DRAM 7 DRAM 0 bits 8-15 bits 16-23 bits 24-31 bits 32-39 bits 40-47 bits 48-55 bits 56-63
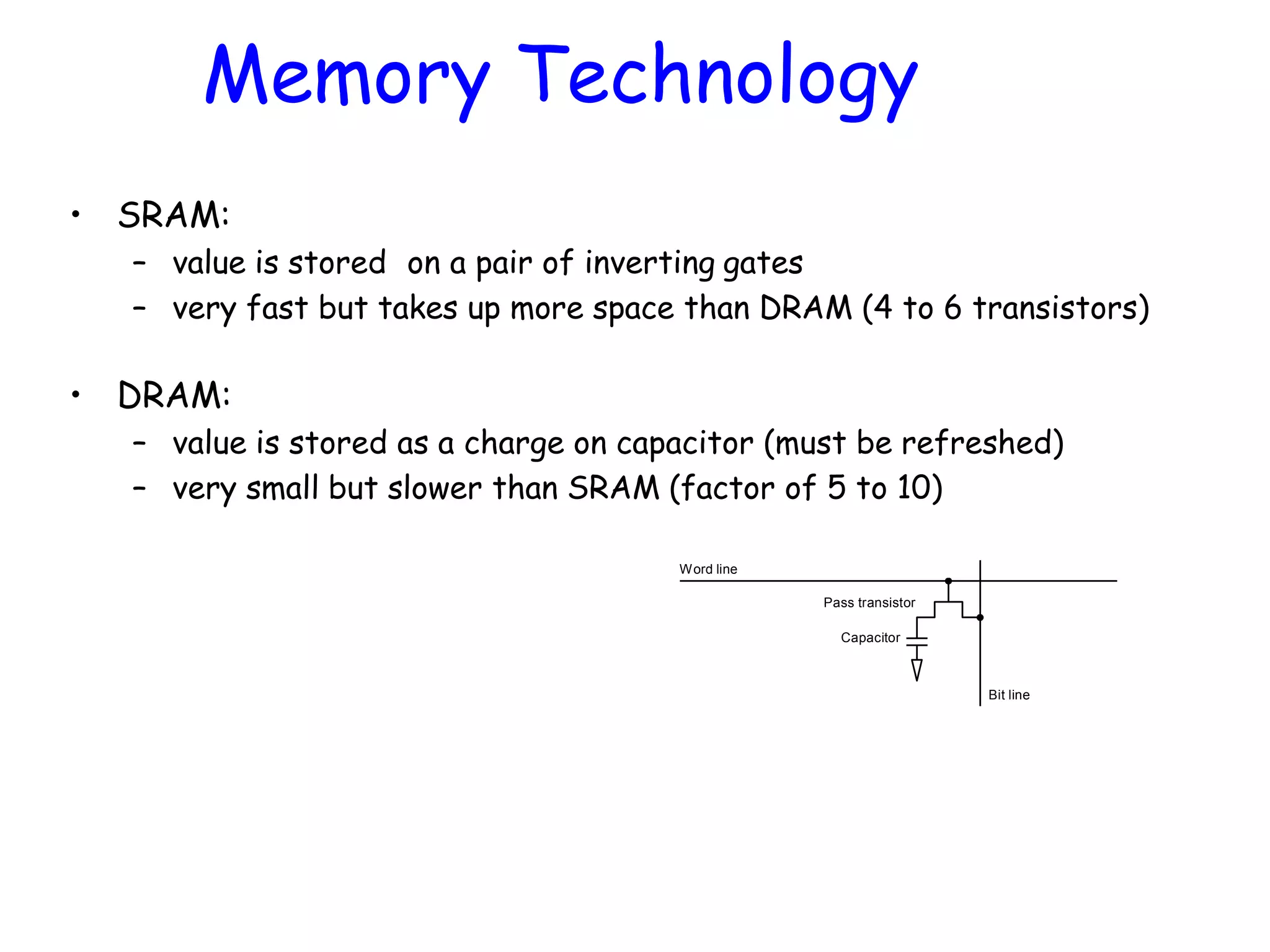
• SRAM: – valueis stored on a pair of inverting gates – very fast but takes up more space than DRAM (4 to 6 transistors) • DRAM: – value is stored as a charge on capacitor (must be refreshed) – very small but slower than SRAM (factor of 5 to 10) Memory Technology Word line Pass transistor Capacitor Bit line
28.
Memory Technology • StaticRAM (SRAM) – 0.5ns – 2.5ns, $500 – $1000 per GB • Dynamic RAM (DRAM) – 50ns – 70ns, $10 – $20 per GB • Magnetic disk – 5ms – 20ms, $0.01 – $0.1 per GB • Ideal memory – Access time of SRAM – Capacity and cost/GB of disk
29.
Cache Analogy • Hungry!must eat! – Option 1: go to refrigerator • Found eat! • Latency = 1 minute – Option 2: go to store • Found purchase, take home, eat! • Latency = 20-30 minutes – Option 3: grow food! • Plant, wait … wait … wait … , harvest, eat! • Latency = ~250,000 minutes (~ 6 months)
30.
What Do WeGain? Let m = cache access time, M: main memory access time p = probability that we find the data in the cache Average access time = p*m + (1-p)(m+M) = m + (1-p) M We need to increase p
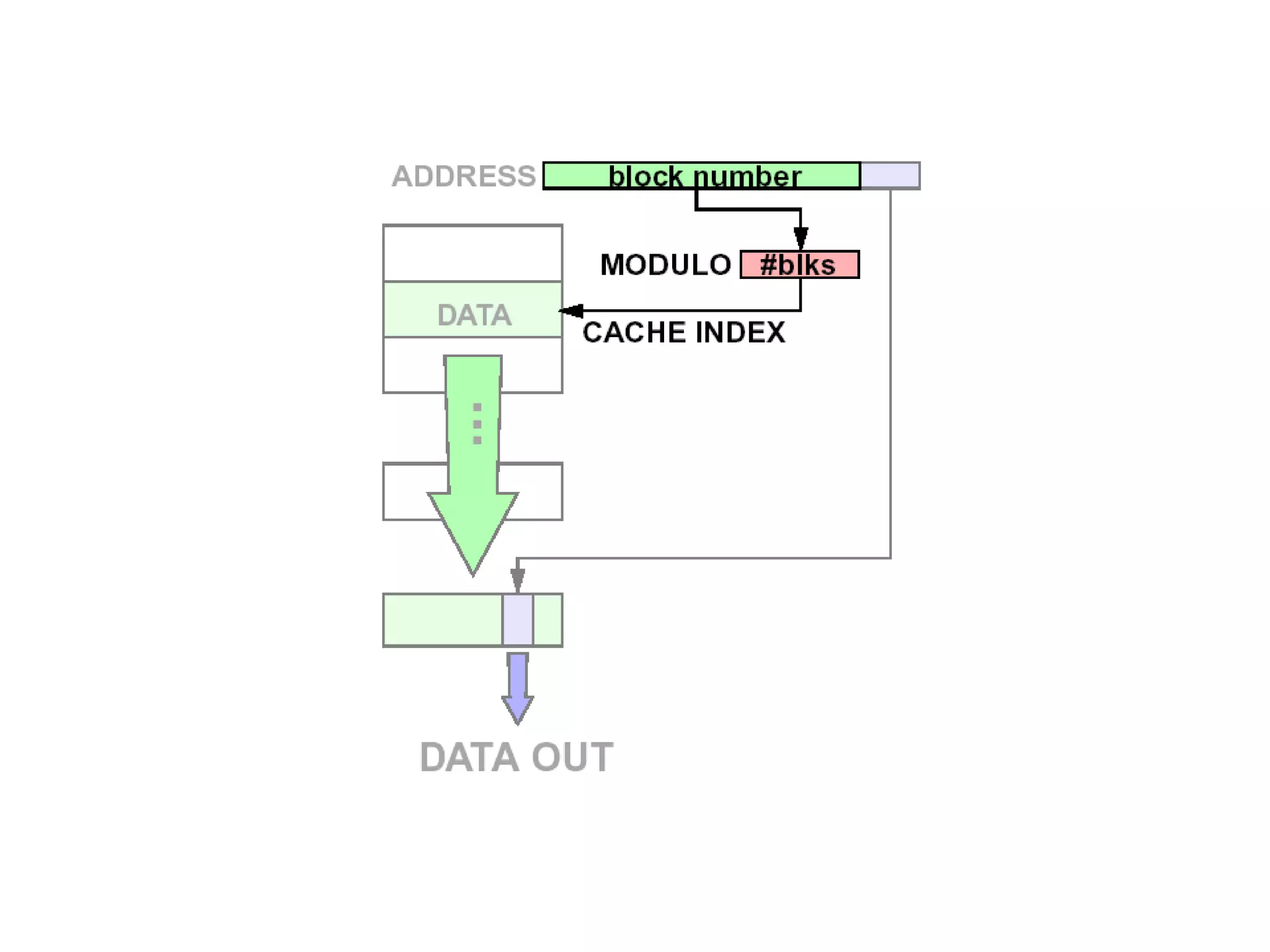
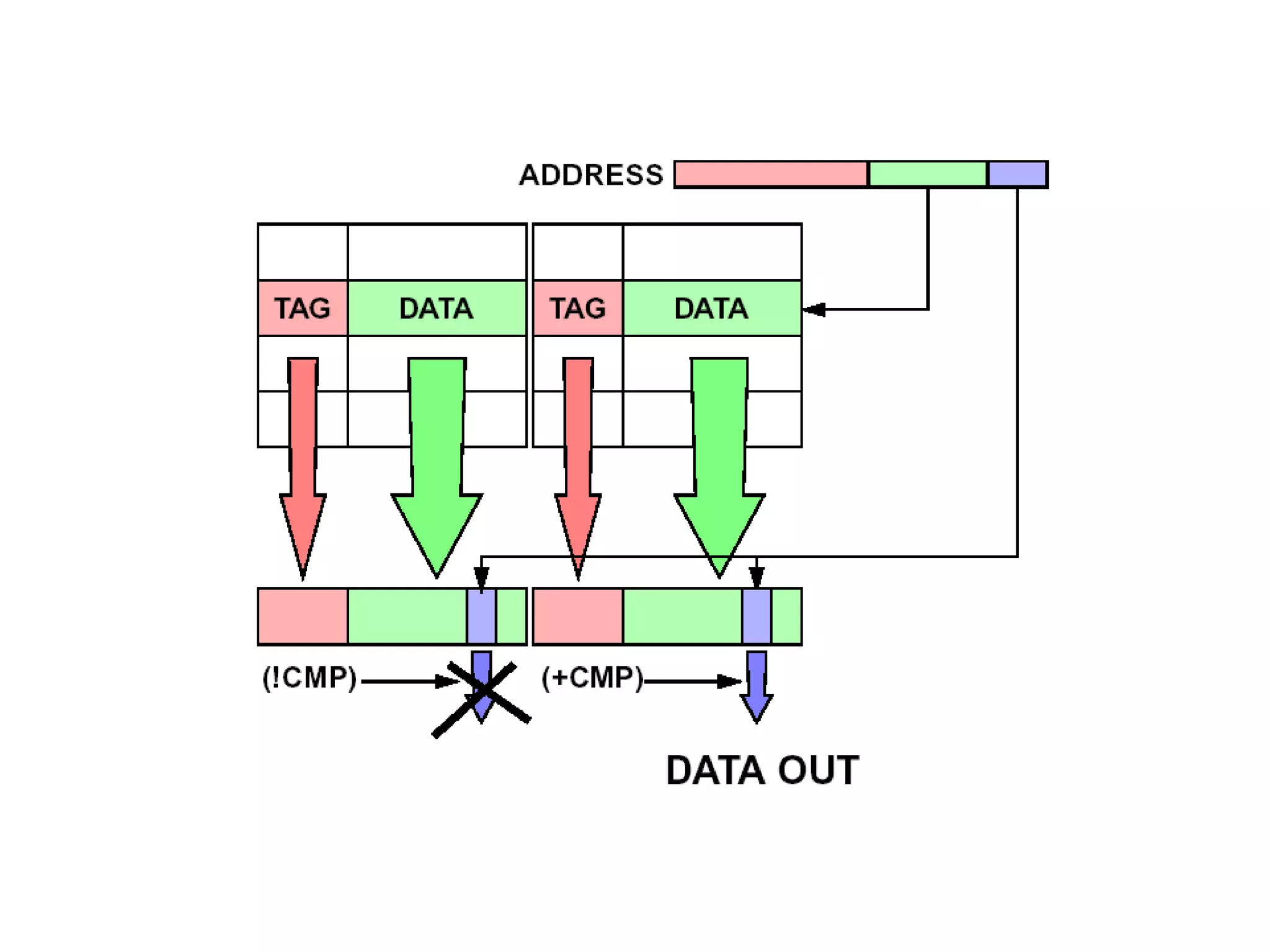
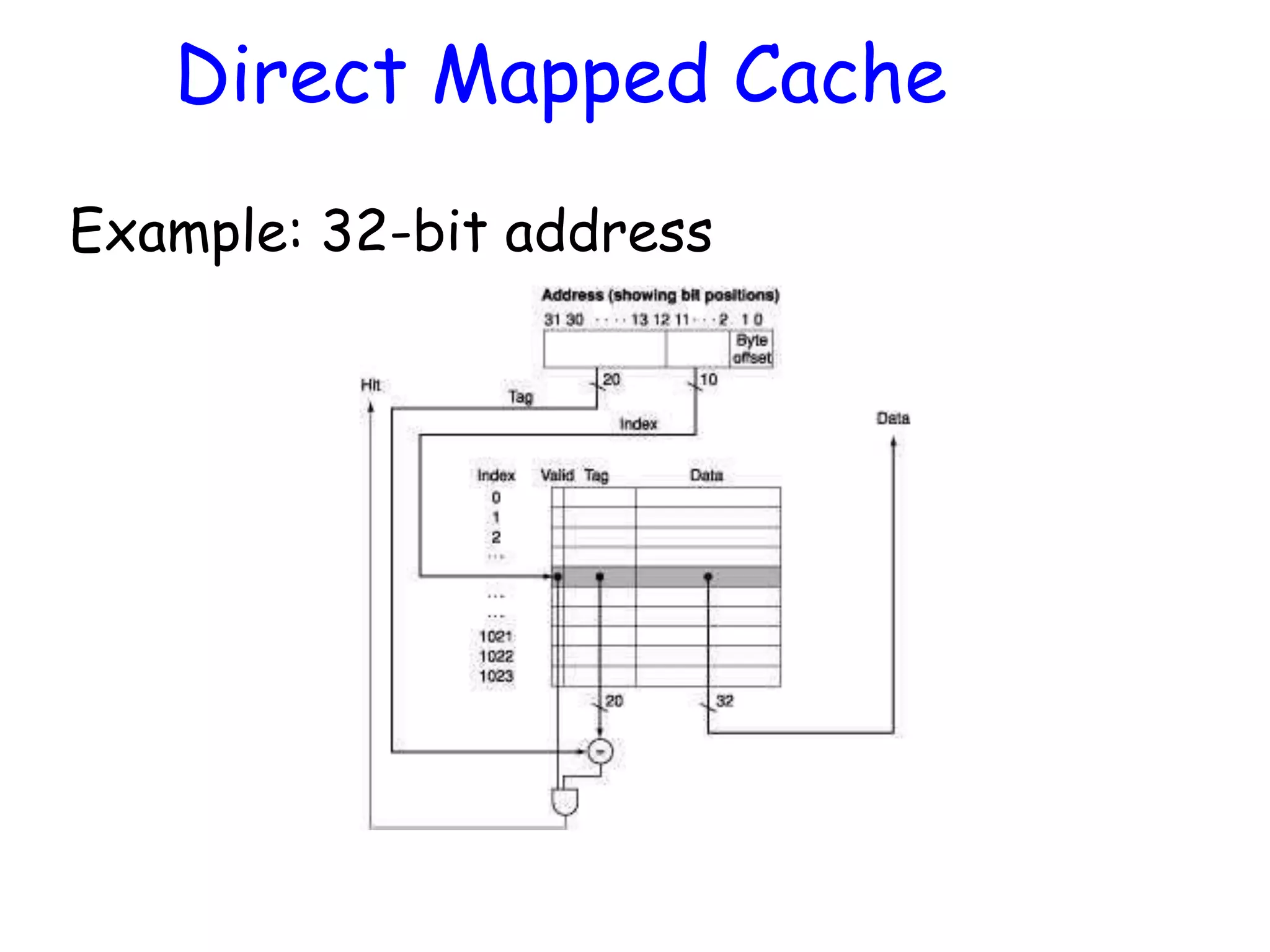
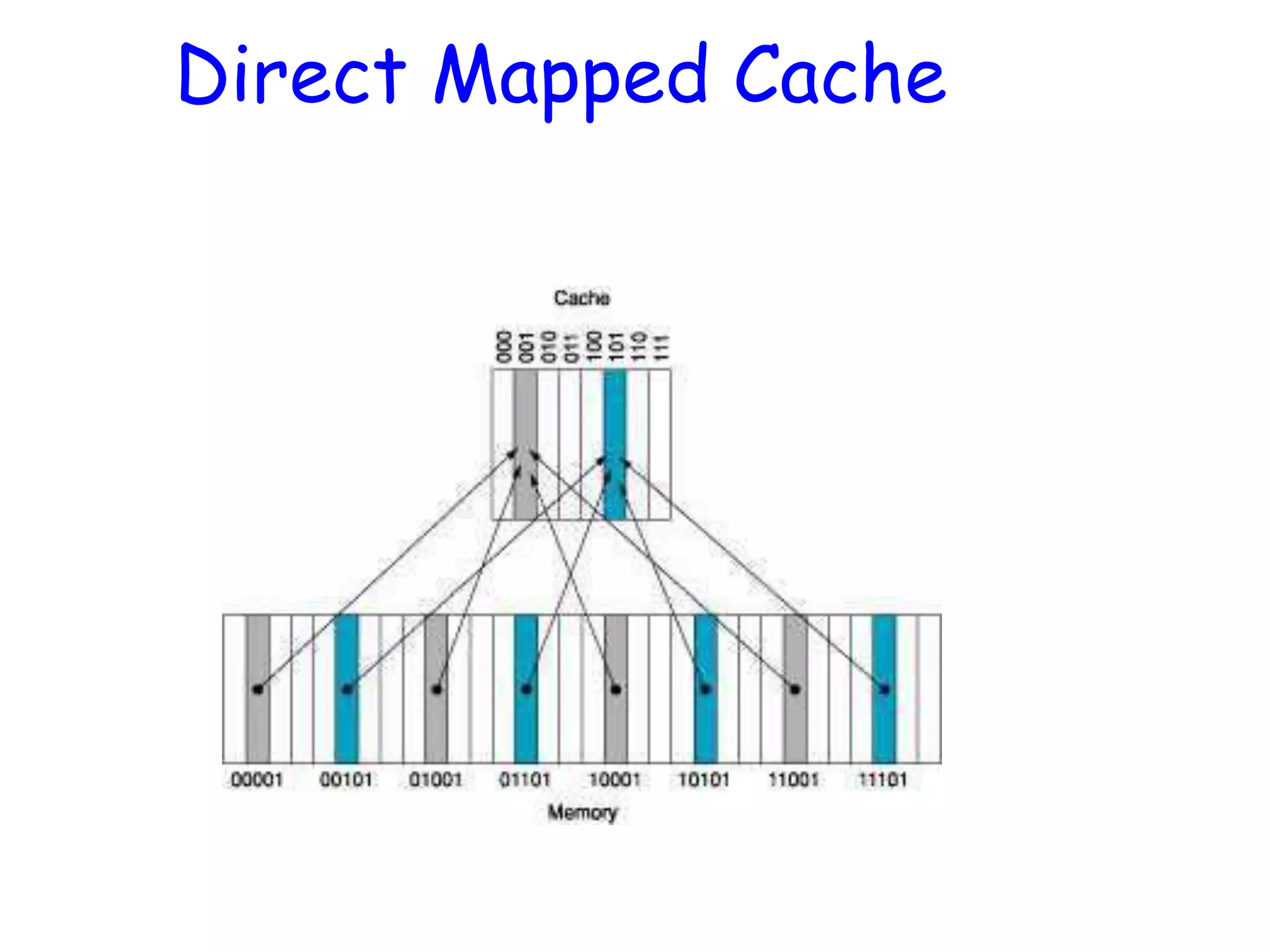
Basic Cache Design •Cache memory can copy data from any part of main memory – It has 2 parts: • The TAG (CAM) holds the memory address • The BLOCK (SRAM) holds the memory data • Accessing the cache: – Compare the reference address with the tag • If they match, get the data from the cache block • If they don’t match, get the data from main memory
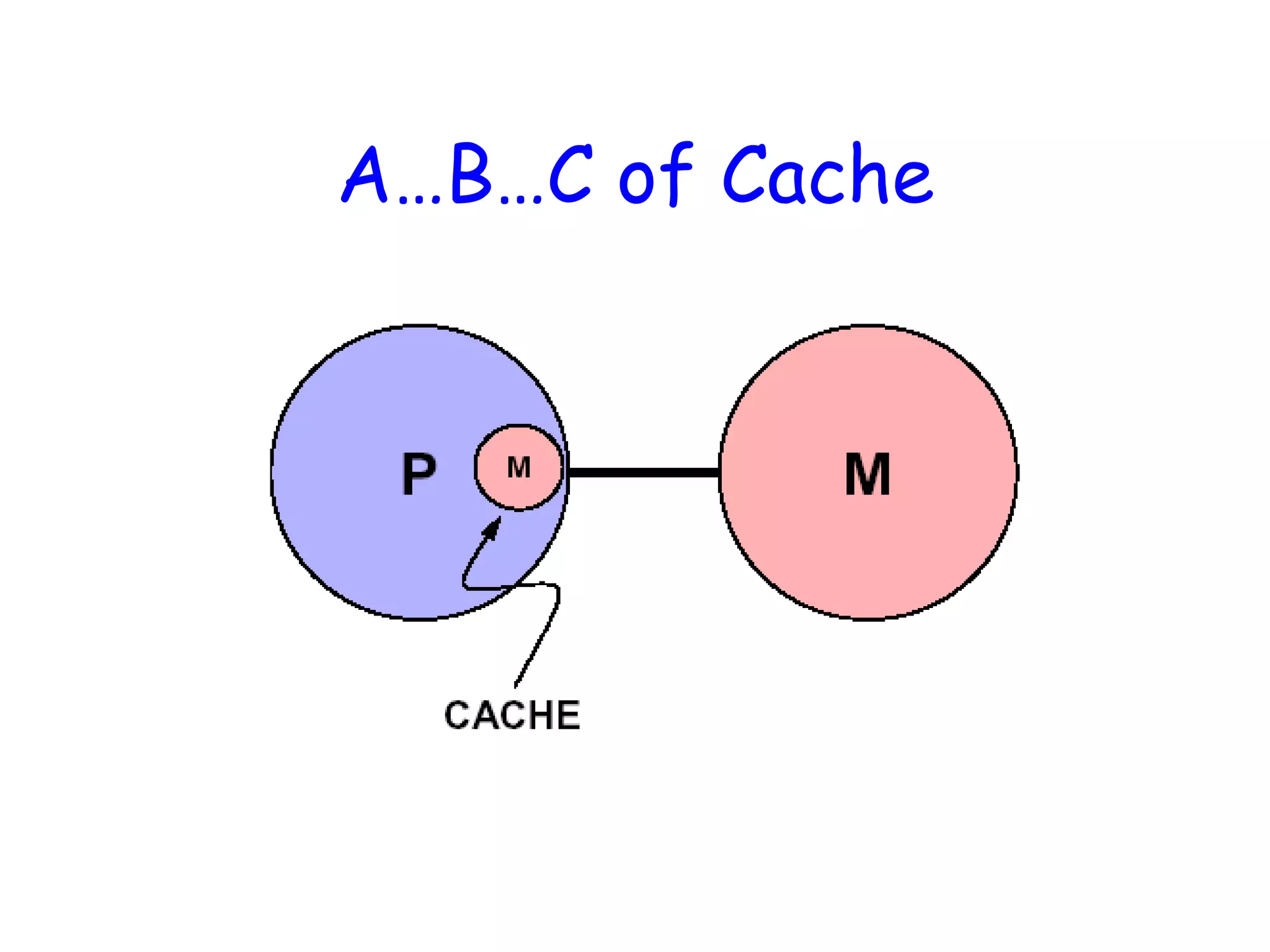
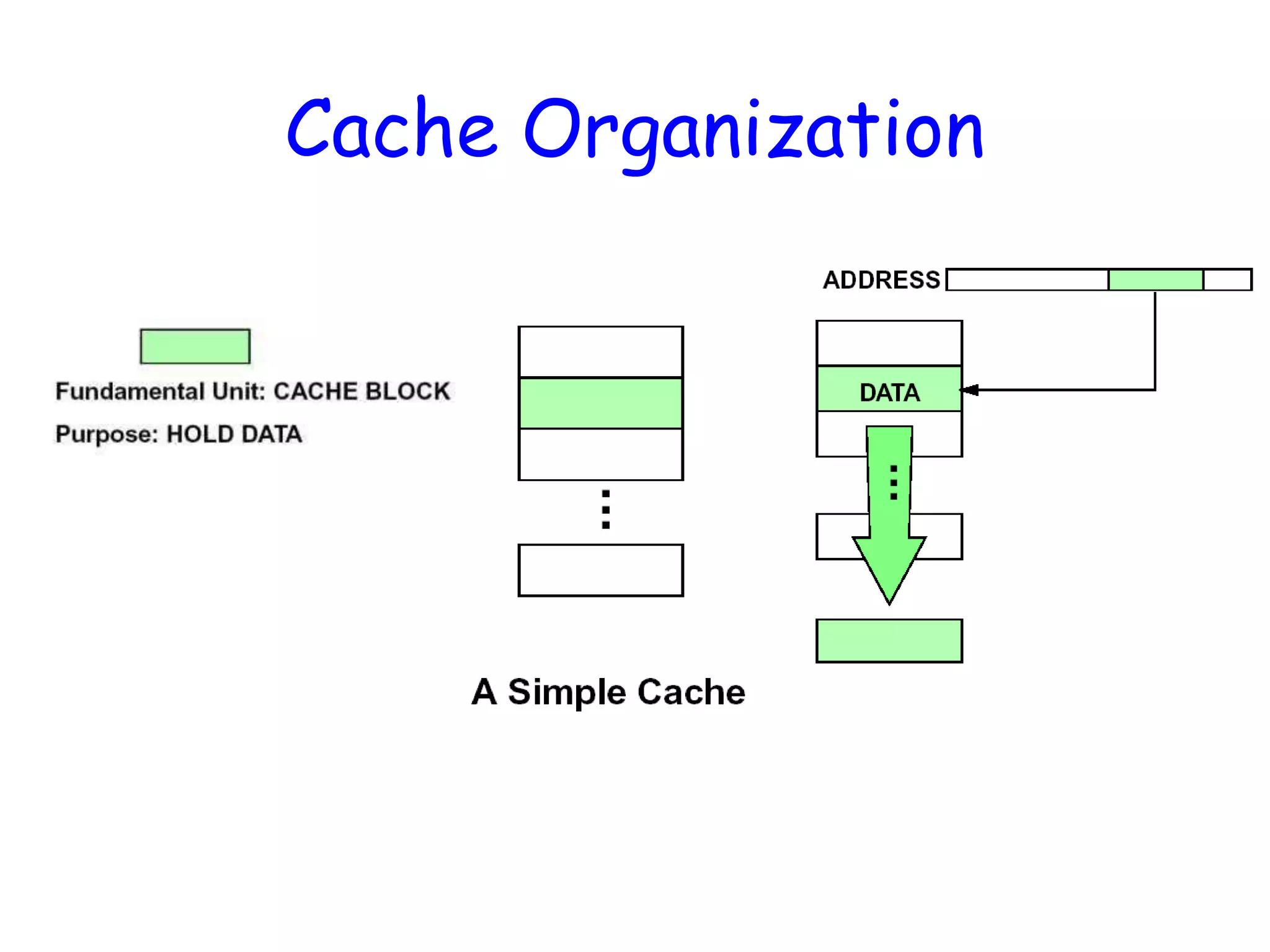
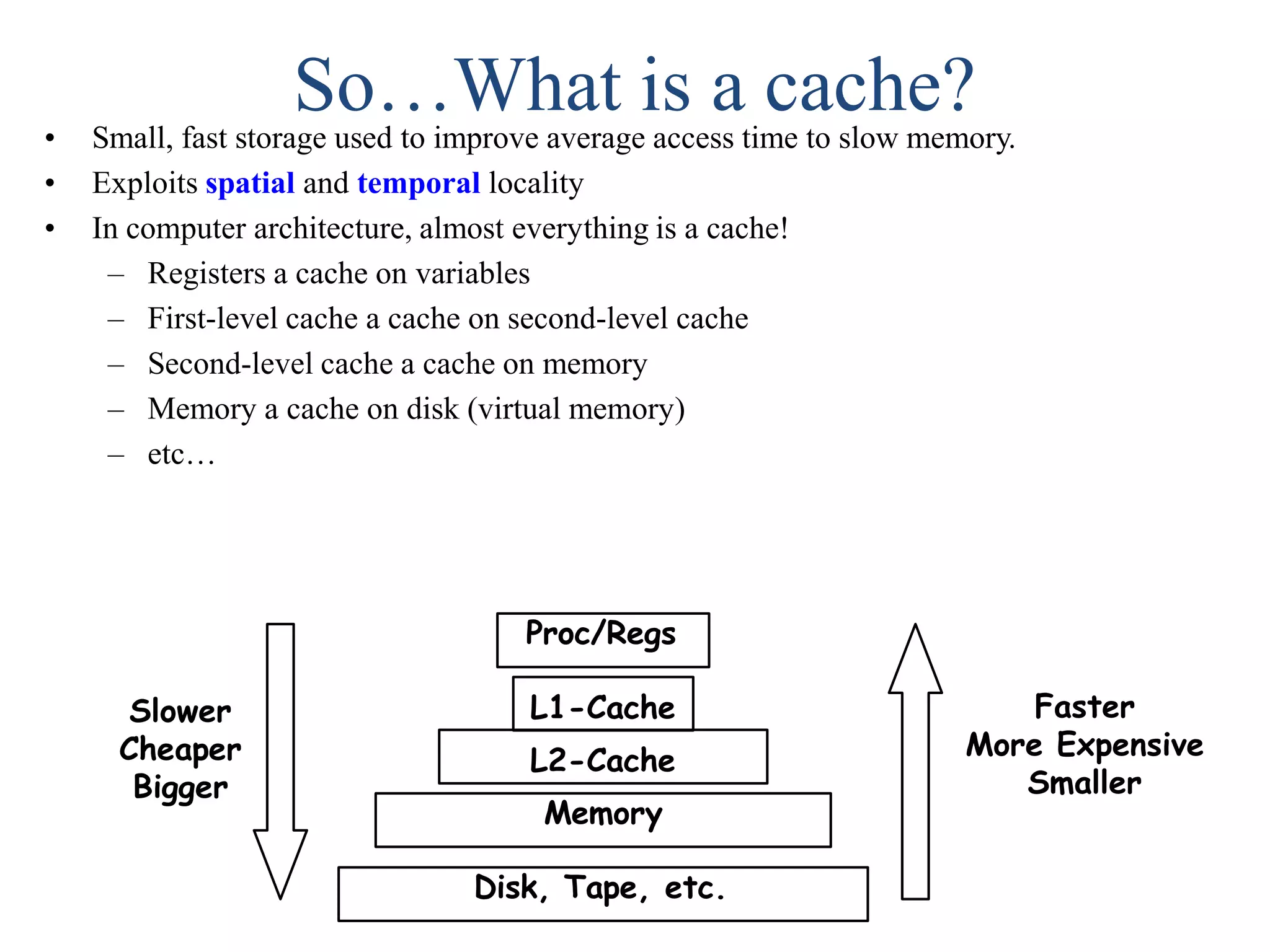
So…What is acache?• Small, fast storage used to improve average access time to slow memory. • Exploits spatial and temporal locality • In computer architecture, almost everything is a cache! – Registers a cache on variables – First-level cache a cache on second-level cache – Second-level cache a cache on memory – Memory a cache on disk (virtual memory) – etc… Proc/Regs L1-Cache L2-Cache Memory Disk, Tape, etc. Slower Cheaper Bigger Faster More Expensive Smaller
42.
Localities: Why Cache Isa Good Idea? • Spatial locality: If block k is accessed, it is likely that block k+1 will be accessed • Temporal locality: If block k is accessed, it is likely that it will be accessed again
43.
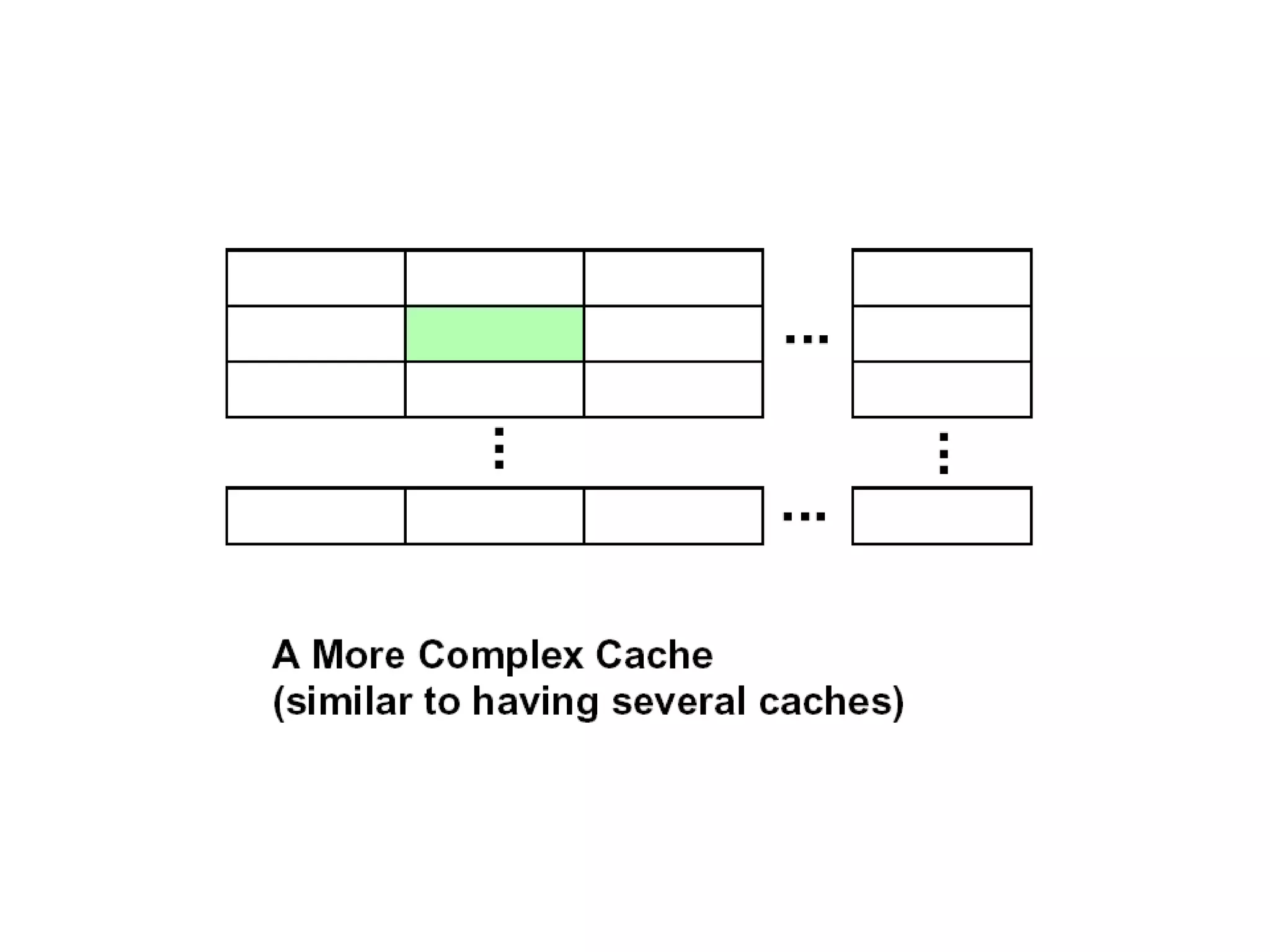
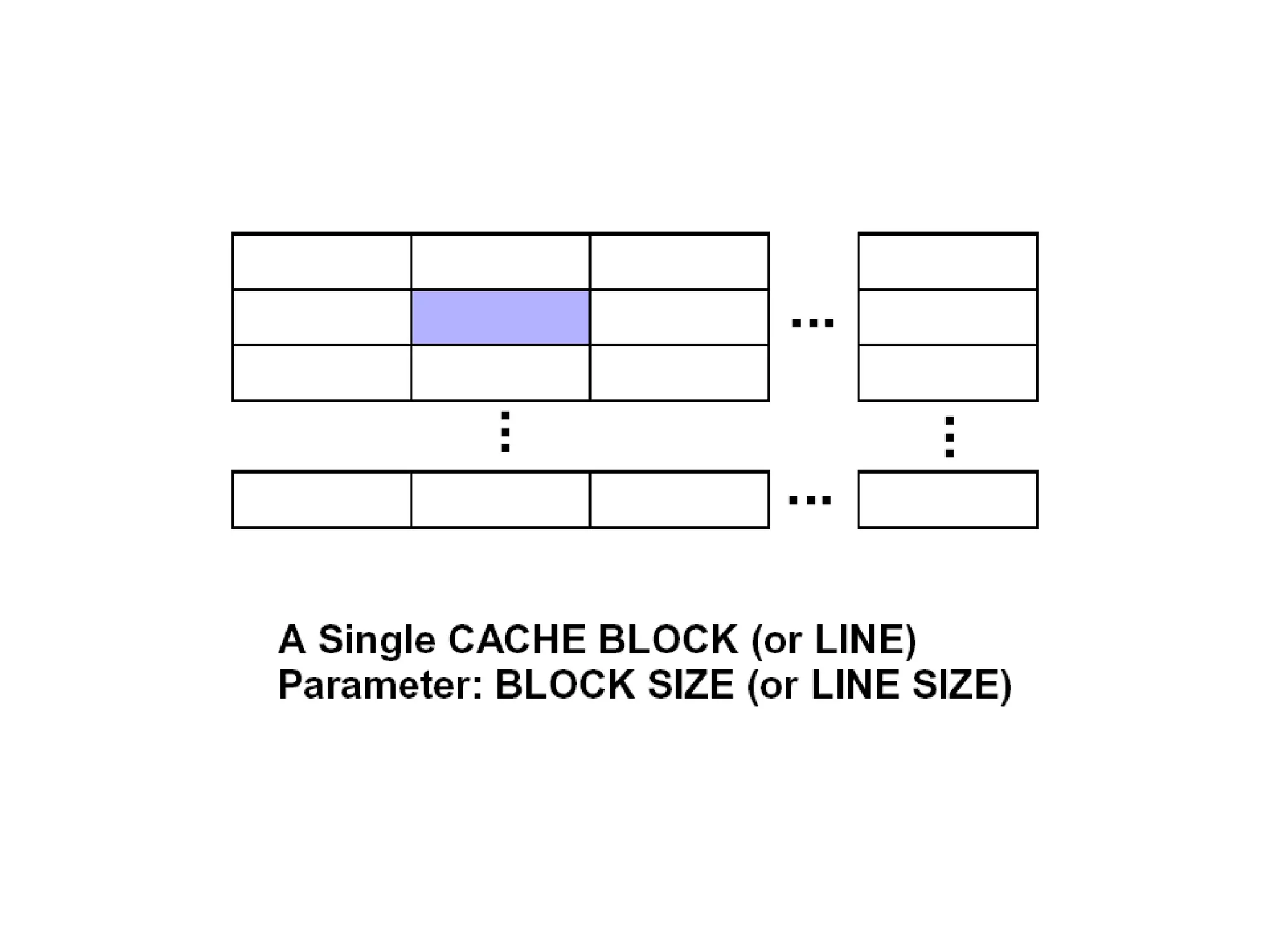
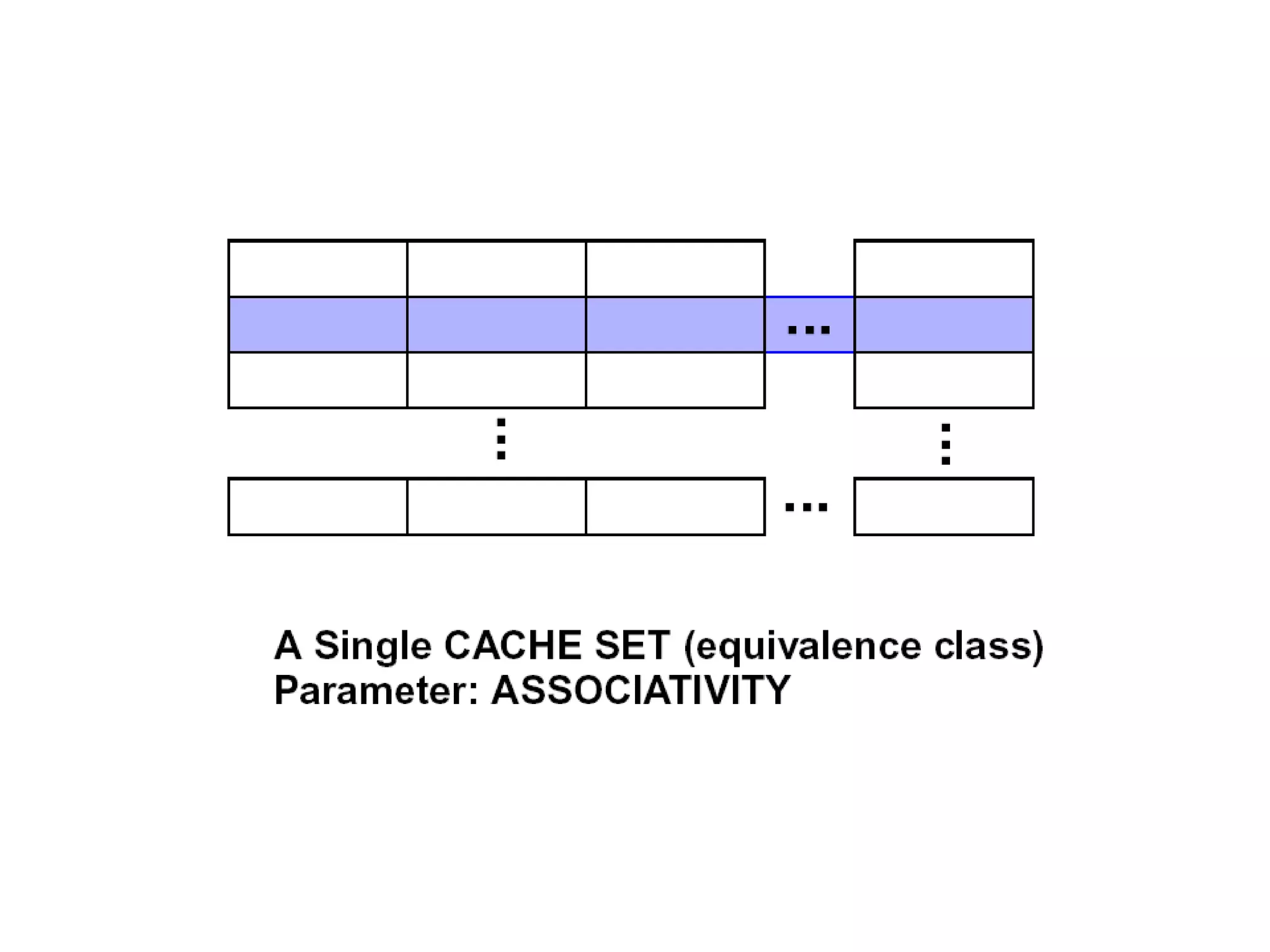
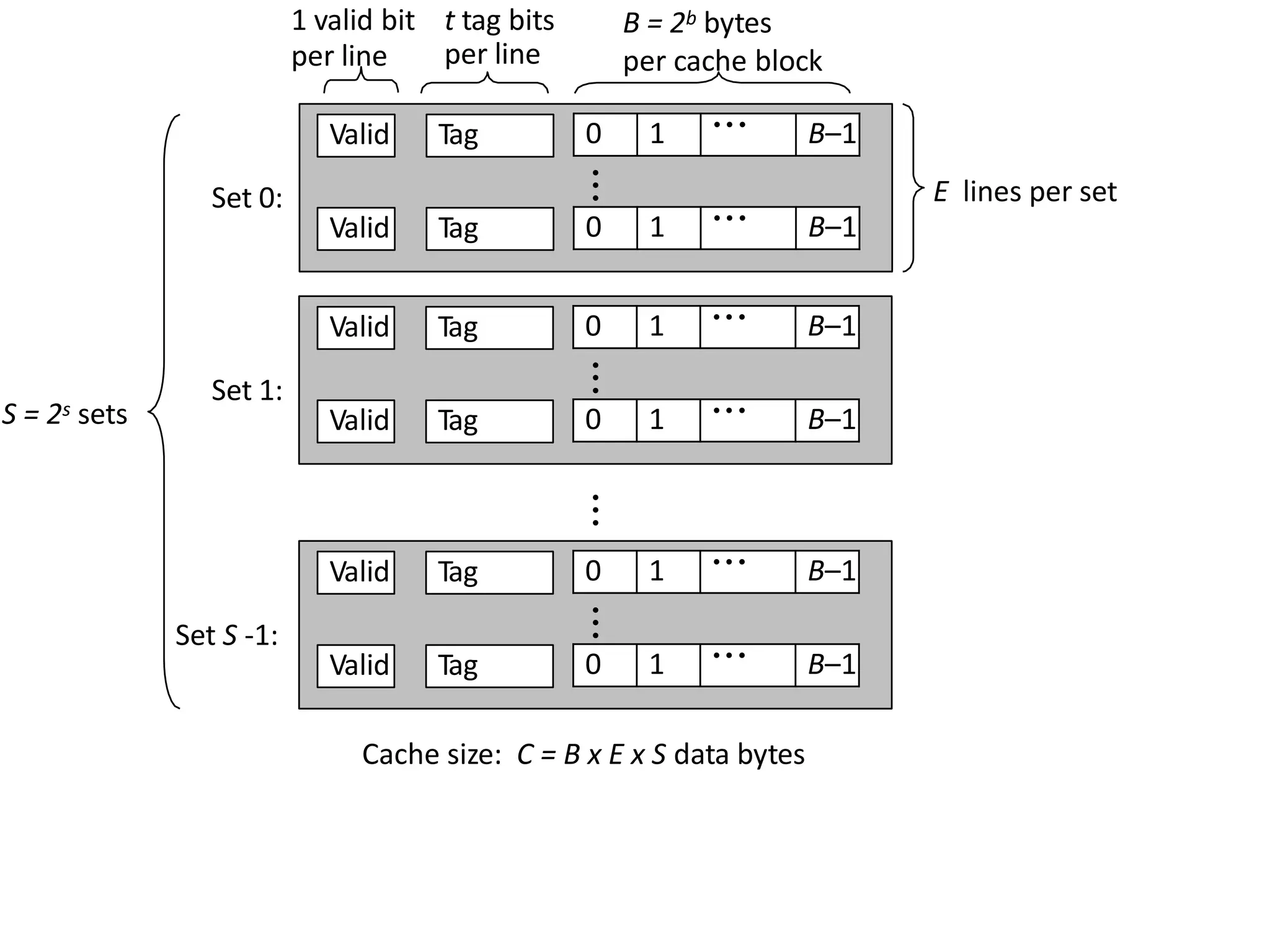
Valid Valid Tag Tag Set 0: B =2b bytes per cache block E lines per set S = 2s sets t tag bits per line 1 valid bit per line Cache size: C = B x E x S data bytes ••• Valid Valid Tag Tag Set 1: •••Valid Valid Tag Tag Set S -1: •••••• 0 1 • • • B–1 0 1 • • • B–1 0 1 • • • B–1 0 1 • • • B–1 0 1 • • • B–1 0 1 • • • B–1
44.
Problem Show the breakdownof the address for the following cache configuration: 32 bit address 16K cache Direct-mapped cache 32-byte blocks tag set index block offset
45.
Problem Show the breakdownof the address for the following cache configuration: 32 bit address 32K cache 4-way set associative cache 32-byte blocks tag set index block offset
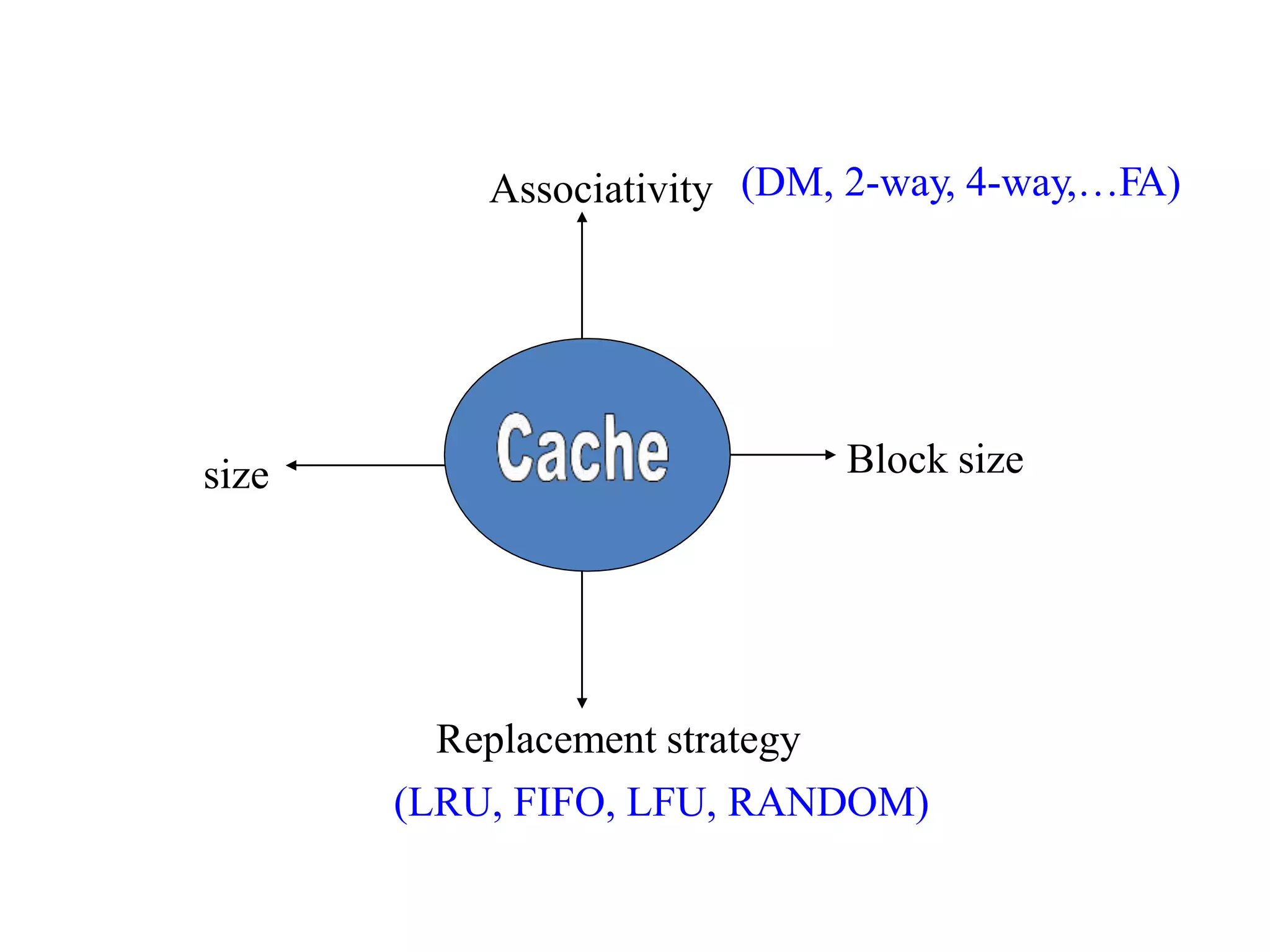
Design Issues • Whatto do in case of hit/miss? • Block size • Associativity • Replacement algorithm • Improving performance
48.
• Read hits –this is what we want! • Read misses – stall the CPU, fetch block from memory, deliver to cache, restart • Write hits: – can replace data in cache and memory (write-through) – write the data only into the cache (write-back the cache later) • Write misses: – read the entire block into the cache, then write the word Hits vs. Misses
49.
Improving Cache Performance 1.Reduce the miss rate, 2. Reduce the miss penalty, 3. Reduce power consumption (won’t be discussed here)
50.
Reducing Misses • ClassifyingMisses: 3 Cs – Compulsory—The first access to a block is not in the cache, so the block must be brought into the cache. Also called cold start misses or first reference misses. (Misses in even an Infinite Cache) – Capacity—If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being discarded and later retrieved. – Conflict—If block-placement strategy is set associative or direct mapped, conflict misses (in addition to compulsory & capacity misses) will occur because a block can be discarded and later retrieved if too many blocks map to its set. Also called collision misses or interference misses.
51.
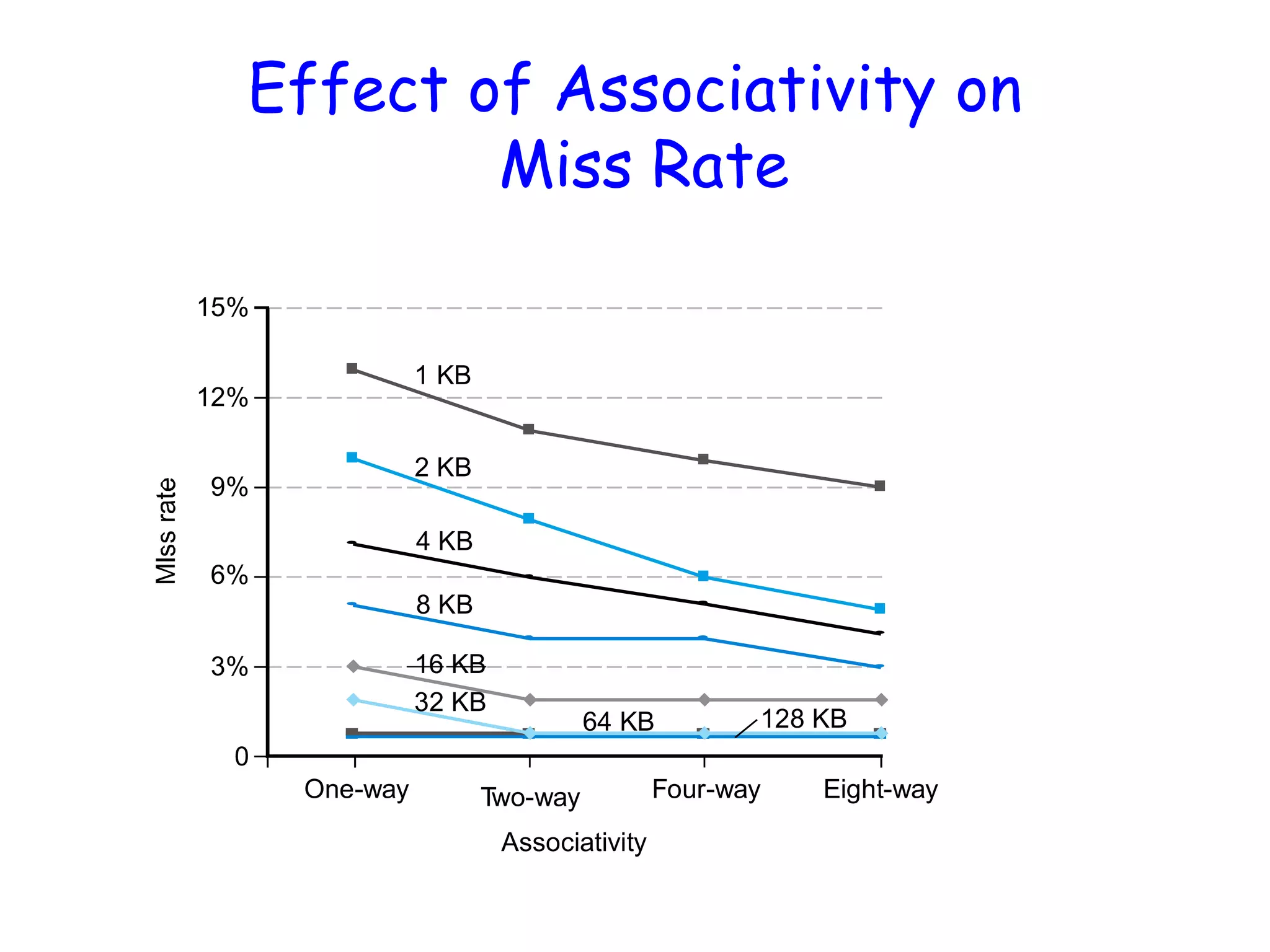
How Can WeReduce Misses? 1) Change Block Size: 2) ChangeAssociativity: 3) Increase Cache Size
52.
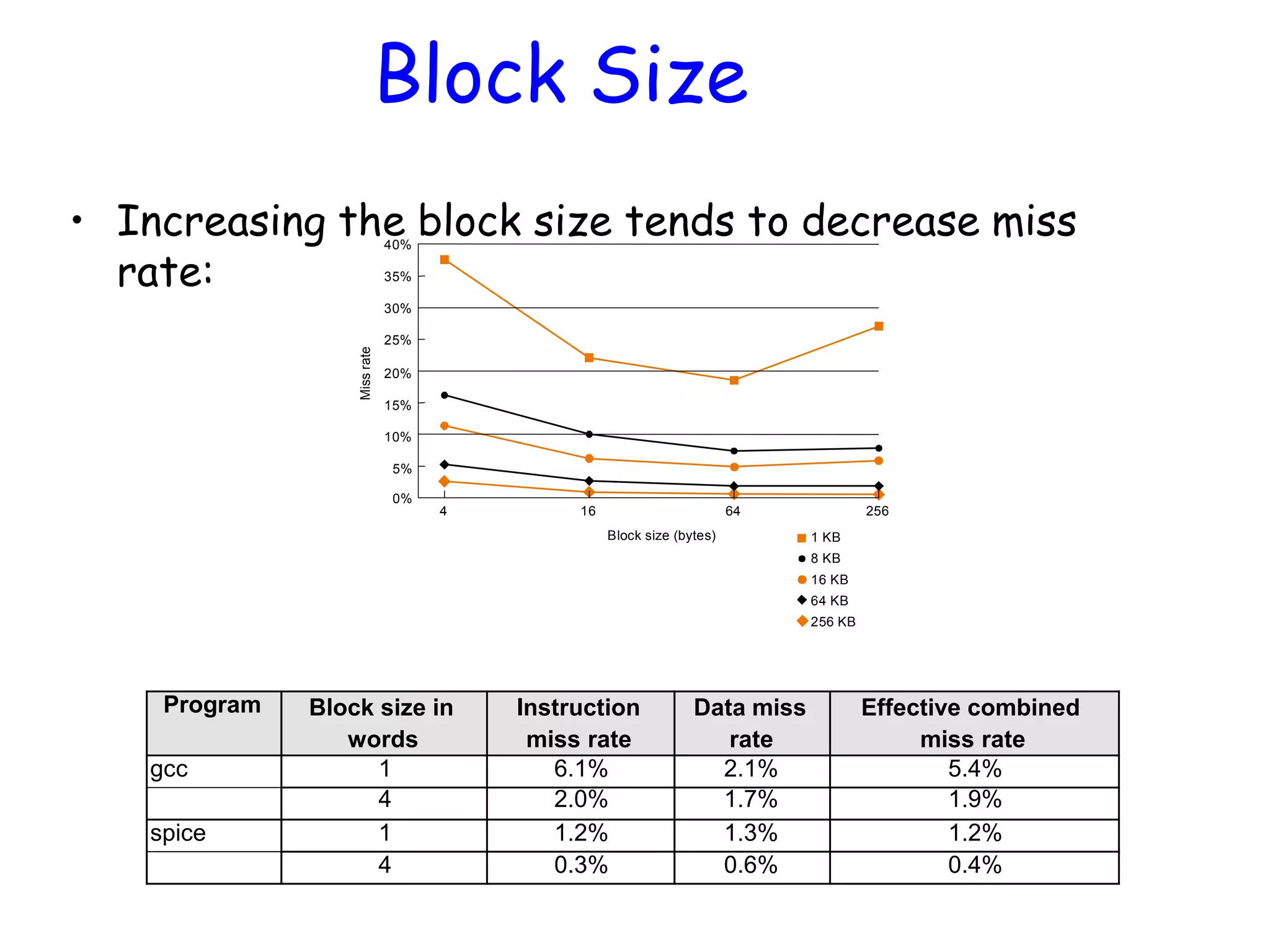
• Increasing theblock size tends to decrease miss rate: Block Size 1 KB 8 KB 16 KB 64 KB 256 KB 256 40% 35% 30% 25% 20% 15% 10% 5% 0% Missrate 64164 Block size (bytes) Program Block size in words Instruction miss rate Data miss rate Effective combined miss rate gcc 1 6.1% 2.1% 5.4% 4 2.0% 1.7% 1.9% spice 1 1.2% 1.3% 1.2% 4 0.3% 0.6% 0.4%
53.
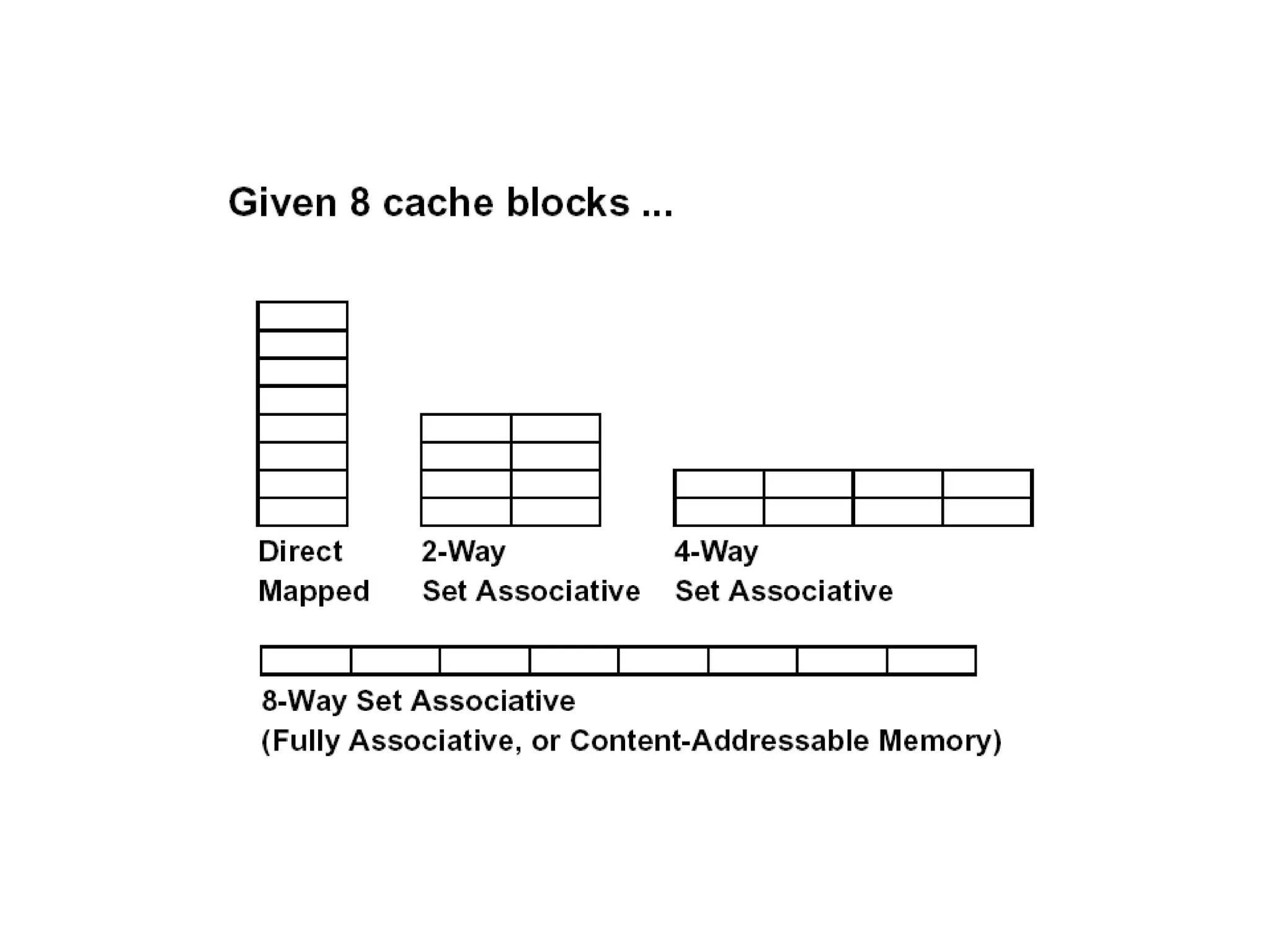
Decreasing miss ratiowith associativity Eight-way set associative (fully associative) Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Set Tag Data Tag Data Tag Data 0 1 Tag Data Four-way set associative Set Tag Data Tag Data 0 1 2 3 Two-way set associative Block Tag Data 0 1 2 3 4 5 6 7 One-way set associative (direct mapped)
54.
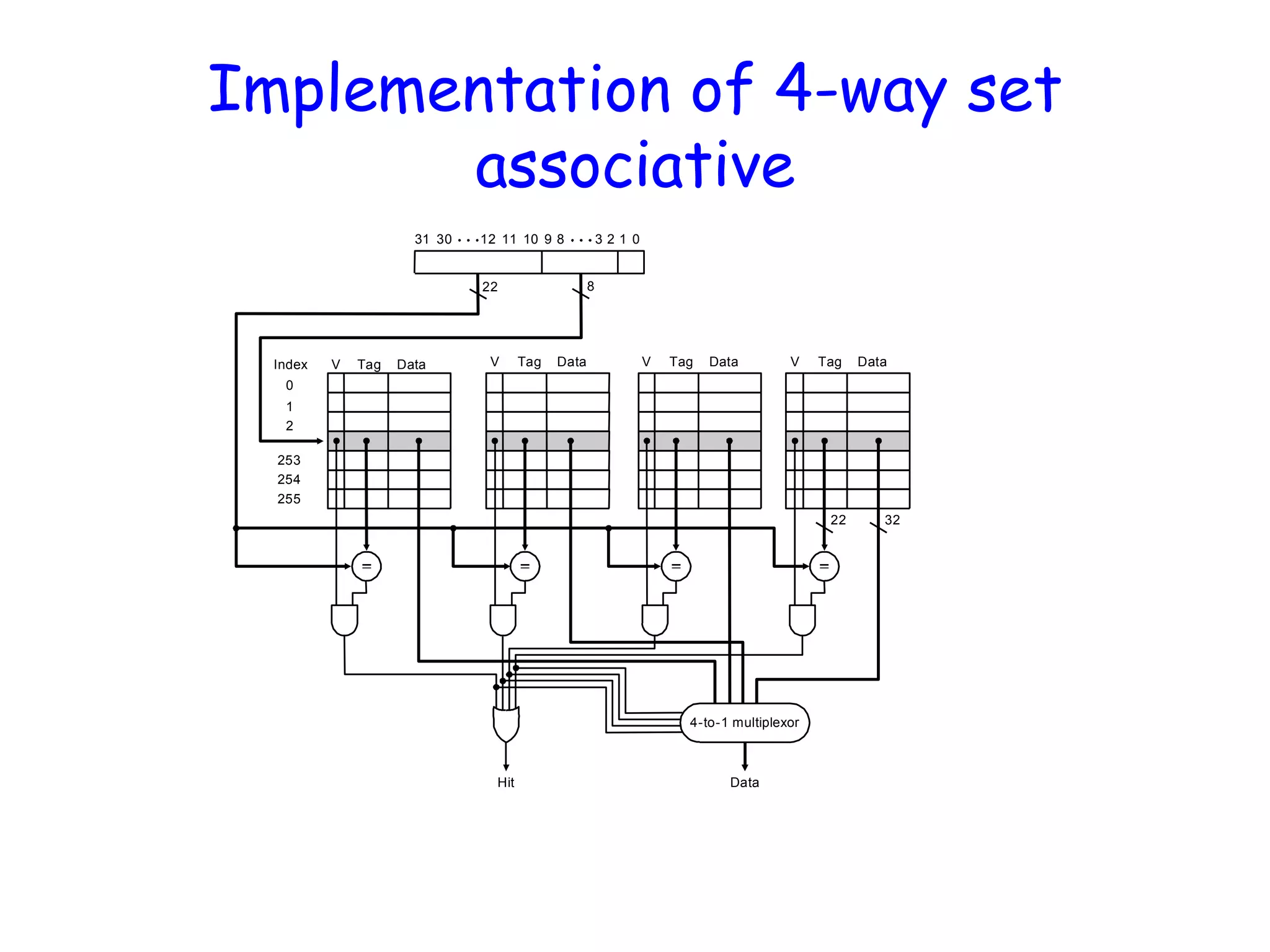
Implementation of 4-wayset associative 22 8 Index V Tag Data 0 1 2 253 254 255 V Tag Data V Tag Data V Tag Data 3222 4-to-1 multiplexor Hit Data 3 2 1 012 11 10 9 831 30
Reducing Miss Penalty WritePolicy 1: Write-Through vs Write-Back • Write-through: all writes update cache and underlying memory/cache – Can always discard cached data - most up-to-date data is in memory – Cache control bit: only a valid bit • Write-back: all writes simply update cache – Can’t just discard cached data - may have to write it back to memory – Cache control bits: both valid and dirty bits • Other Advantages: – Write-through: • memory (or other processors) always have latest data • Simpler management of cache – Write-back: • much lower bandwidth, since data often overwritten multiple times • Better tolerance to long-latency memory?
57.
Reducing Miss Penalty WritePolicy 2: Write Allocate vs Non-Allocate (What happens on write-miss) • Write allocate: allocate new cache line in cache – Usually means that you have to do a “read miss” to fill in rest of the cache-line! • Write non-allocate (or “write-around”): – Simply send write data through to underlying memory/cache - don’t allocate new cache line!
58.
Decreasing miss penaltywith multilevel caches • Add a second (and third) level cache: – often primary cache is on the same chip as the processor – use SRAMs to add another cache above primary memory (DRAM) – miss penalty goes down if data is in 2nd level cache • Using multilevel caches: – try and optimize the hit time on the 1st level cache – try and optimize the miss rate on the 2nd level cache
Conclusions • The computersystem’s storage is organized as a hierarchy. • The reason of this hierarchy is to try to get an memory that is very fast, cheap, and almost infinite. • A good programmer must try to make the code cache friendly make the common case cache friendly locality































![A Very Simple Memory System Processor Ld R1 M[ 1 ] Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] Cache 2 cache lines 4 bit tag field 1 byte block tag data Memory 0 1 2 3 4 5 6 7 8 9 10 R0 R1 R2 R3 11 12 13 14 15 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 V V](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-60-2048.jpg)
![A Very Simple Memory System 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Processor Cache Memory tag data This is a Cache miss R0 R1 R2 R3 Is it in the cache? No valid tags Allocate: address tag Mem[1] block 0 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 Ld R1 M[ 1 ] Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] 1 1 110 0](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-61-2048.jpg)
![A Very Simple Memory System 100 tag data R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Ld R1 M[ 1 ] Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] Processor Cache Memory lru Misses: 1 Hits: 0 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 1 1 110 0 110](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-62-2048.jpg)
![A Very Simple Memory System 100 tag data R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Processor Cache Memory Misses: 1 Hits: 0 lru Check tags: 5 1 Cache Miss 0 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 Ld R1 M[ 1 ] Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] 110 11 110 1 5150](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-63-2048.jpg)
![A Very Simple Memory System 100 tag data R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Ld R1 M[ 1 ] Processor Cache Memory Misses: 2 Hits: 0 lru 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] 1 1 110 1 5150 110 150](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-64-2048.jpg)
![A Very Simple Memory System 100 tag data R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Ld R1 M[ 1 ] Processor Cache Memory Misses: 2 Hits: 0 lru Check tags: 1 5, but 1 = 1 (HIT!) 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] 1 1 110 1 5150 110 150](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-65-2048.jpg)
![A Very Simple Memory System 100 tag data R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Ld R1 M[ 1 ] Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] Processor Cache Memory Misses: 2 Hits: 1 lru 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 1 1 110 1 5150 110 150 110](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-66-2048.jpg)
![A Very Simple Memory System 100 R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Ld R1 M[ 1 ] Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] Processor Cache Memory tag data Misses: 2 Hits: 1 lru 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 1 1 110 1 5150 110 150 110](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-67-2048.jpg)
![A Very Simple Memory System 100 5 6 7 8 9 10 11 12 13 14 15 Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] 5 tag data R0 R1 R2 R3 Processor Cache Memory 0 150 Misses: 2 Hits: 1 lru 110 7 5 and 7 1 1 (MISS!) 2 Ld R1 M[ 1 ] 3 Ld R2 M[ 5 ] 4 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 1 1110 1 7170 110 150 170](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-68-2048.jpg)
![A Very Simple Memory System 100 tag data R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Ld R1 M[ 1 ] Processor Cache Memory Misses: 3 Hits: 1 lru 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] 1 1 110 1 7170 110 150 170](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-69-2048.jpg)
![A Very Simple Memory System 100 Ld R1 M[ 1 ] tag data R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Processor Cache Memory Misses: 3 Hits: 1 150 lru 7 1 and 7 = 7 (HIT!) 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] 1 1 110 1 7170 110170 170](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-70-2048.jpg)
![A Very Simple Memory System 100 tag data R0 R1 R2 R3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Ld R1 M[ 1 ] Processor Cache Memory Misses: 3 Hits: 2 lru 74 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 Ld R2 M[ 5 ] Ld R3 M[ 1 ] Ld R3 M[ 7 ] Ld R2 M[ 7 ] 1 1 110 1 7170 110 170 170](https://image.slidesharecdn.com/calecture101-190105115153/75/Computer-Memory-Hierarchy-Computer-Architecture-71-2048.jpg)

