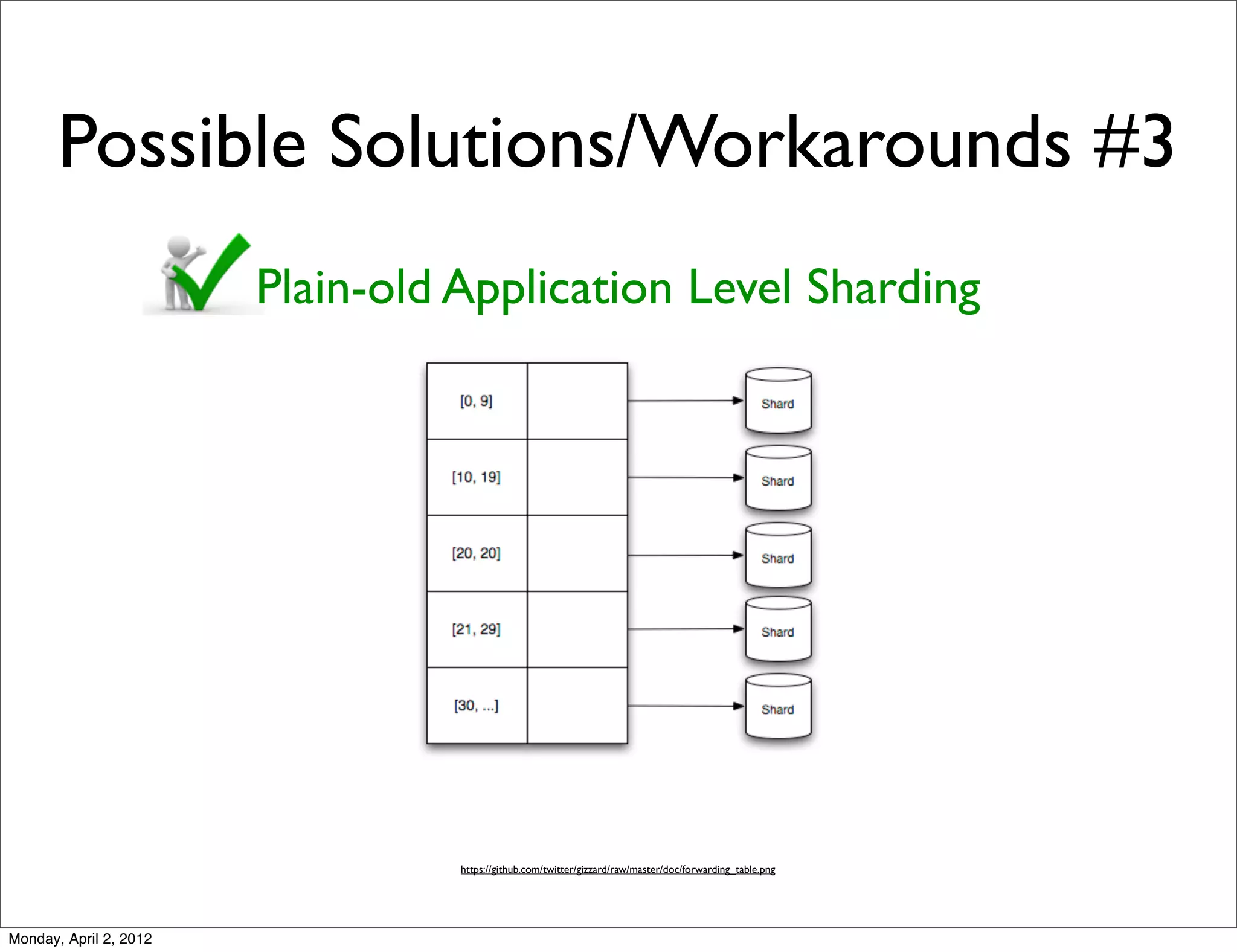
The document discusses several challenges with MongoDB, including: 1. MongoDB uses a global write lock, which can negatively impact write performance. 2. Auto-sharding in MongoDB is not always reliable, as the balancer can get into deadlocks and MongoDB has trouble determining the number of documents after sharding. 3. Being schema-less is overrated, as it means repeating the schema in each document, increasing storage size. Possible solutions discussed include using shorter key names to reduce document sizes.














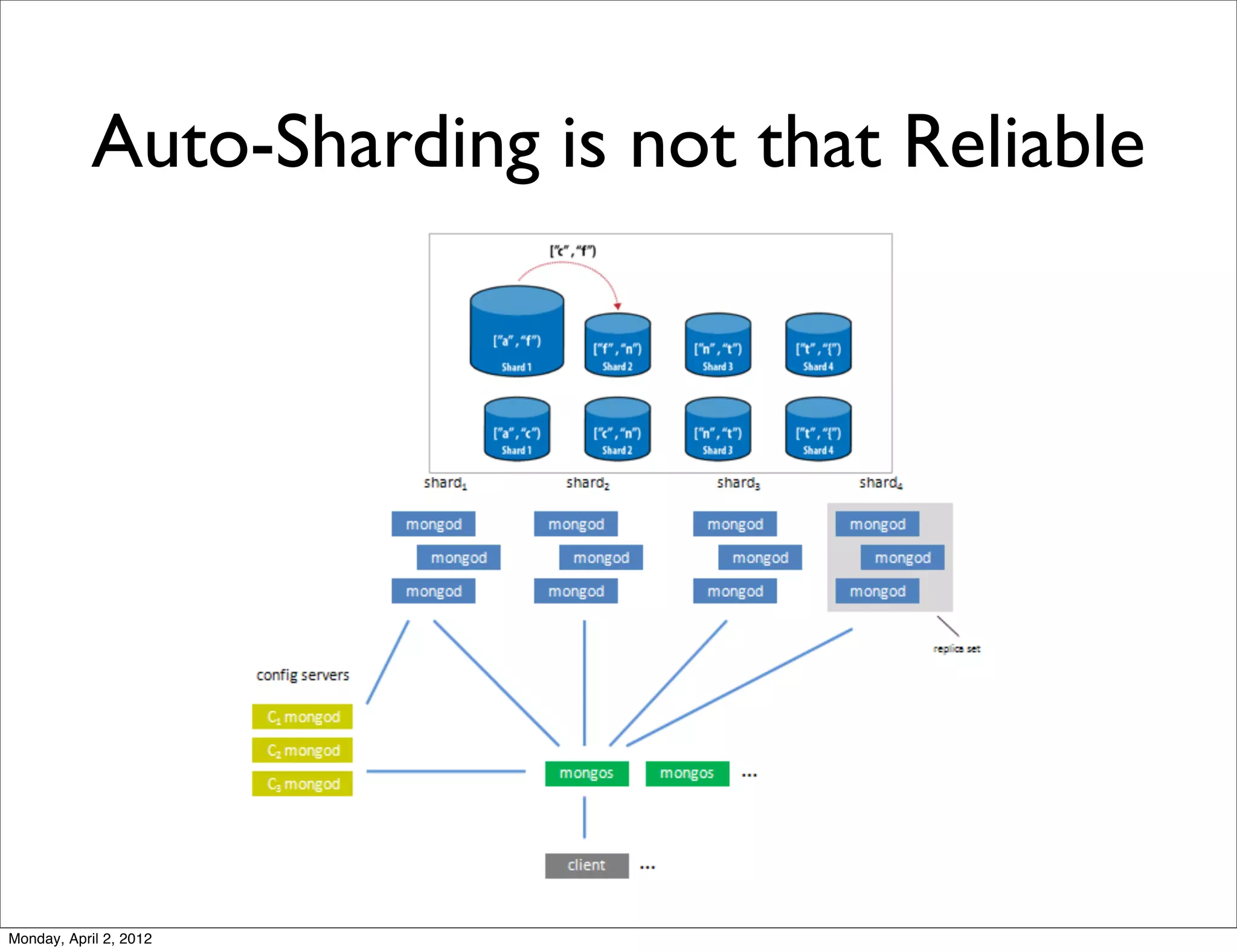
![Problems with Auto-Sharding • MongoDB can’t figure out how many docs in a collection after sharding • Balancer dead lock [Balancer] skipping balancing round during ongoing split or move activity.) [Balancer] dist_lock lock failed because taken by.... [Balancer] Assertion failure cm s/balance.cpp... • Uneven shard load distribution • ... (Note: I did the experiment before 2.0. So some of the issues might be fixed or improved in new versions of MongoDB coz it’s evolving very fast) Monday, April 2, 2012](https://image.slidesharecdn.com/challenges-with-mongodb-120405024454-phpapp01/75/Challenges-with-MongoDB-16-2048.jpg)