The document presents insights from Andrew Rollins on optimizing MongoDB, sharing practical tips on managing documents and indexes, handling fragmentation, and effective migrations, particularly in a cloud environment. Key strategies include using Bindata for identifiers, minimizing index entries, and optimizing shard keys for better locality. The discussion emphasizes the importance of hardware considerations and operational practices for maintaining high performance in MongoDB applications.
Me • Email: my first name @ localytics.com • twitter.com/andrew311 • andrewrollins.com • Founder, Chief Software Architect at Localytics
3.
Localytics • Real timeanalytics for mobile applications • Built on: – Scala – MongoDB – Amazon Web Services – Ruby on Rails – and more…
4.
Why I‟m here:brain dump! • To share tips, tricks, and gotchas about: – Documents – Indexes – Fragmentation – Migrations – Hardware – MongoDB on AWS • Basic to more advanced, a compliment to MongoDB Perf Tuning at MongoSF 2011
5.
MongoDB at Localytics •Use cases: – Anonymous loyalty information – De-duplication of incoming data • Requirements: – High throughput – Add capacity without long down-time • Scale today: – Over 1 billion events tracked in May – Thousands of MongoDB operations a second
6.
Why MongoDB? • Stability • Community • Support • Drivers • Ease of use • Feature rich • Scale out
Use BinData forUUIDs/hashes Bad: { u: “21EC2020-3AEA-1069-A2DD-08002B30309D”, // 36 bytes plus field overhead } Good: { u: BinData(0, “…”), // 16 bytes plus field overhead }
10.
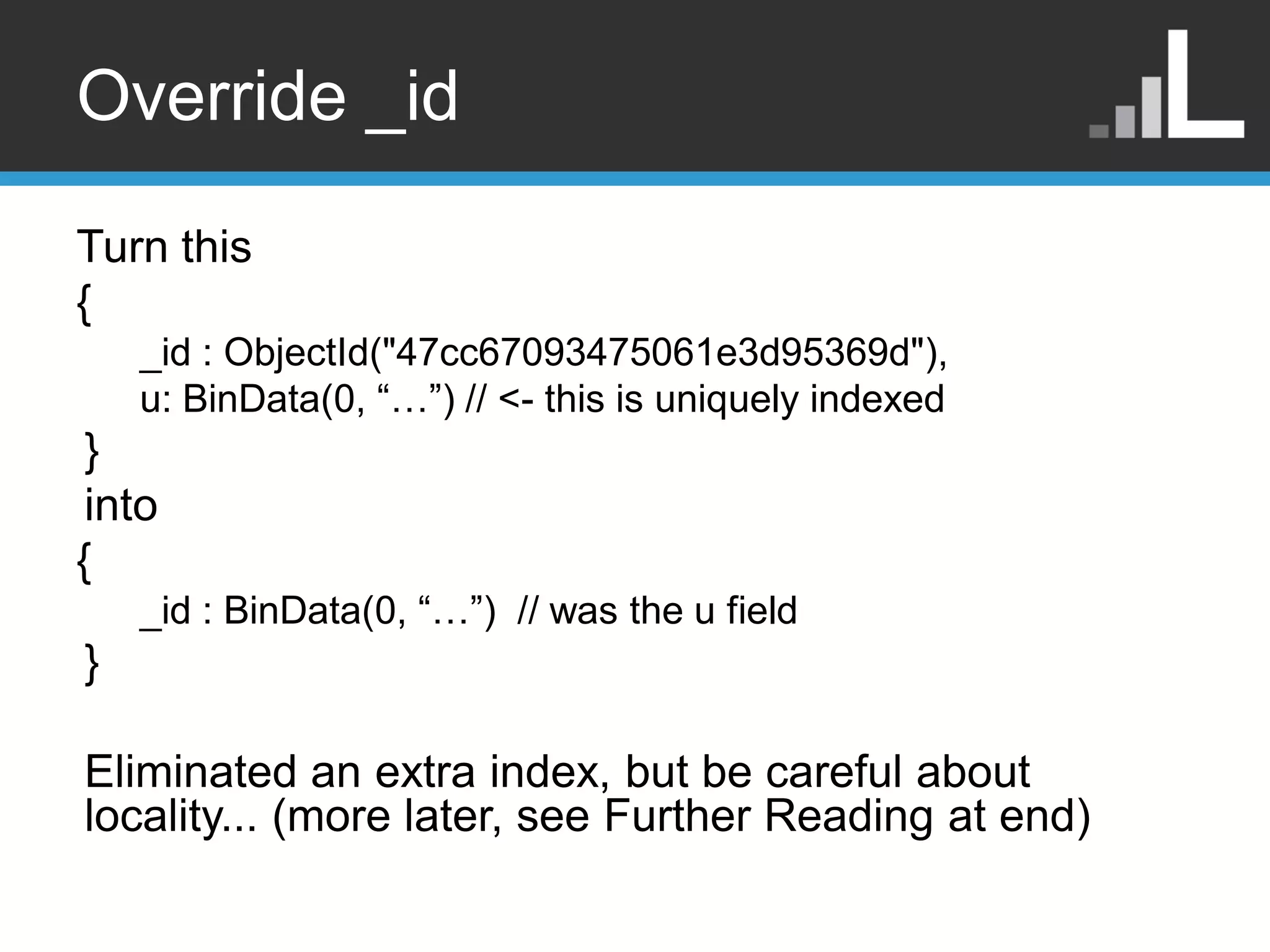
Override _id Turn this { _id : ObjectId("47cc67093475061e3d95369d"), u: BinData(0, “…”) // <- this is uniquely indexed } into { _id : BinData(0, “…”) // was the u field } Eliminated an extra index, but be careful about locality... (more later, see Further Reading at end)
11.
Pack „em in •Look for cases where you can squish multiple “records” into a single document. • Why? – Decreases number of index entries – Brings documents closer to the size of a page, alleviating potential fragmentation • Example: comments for a blog post.
12.
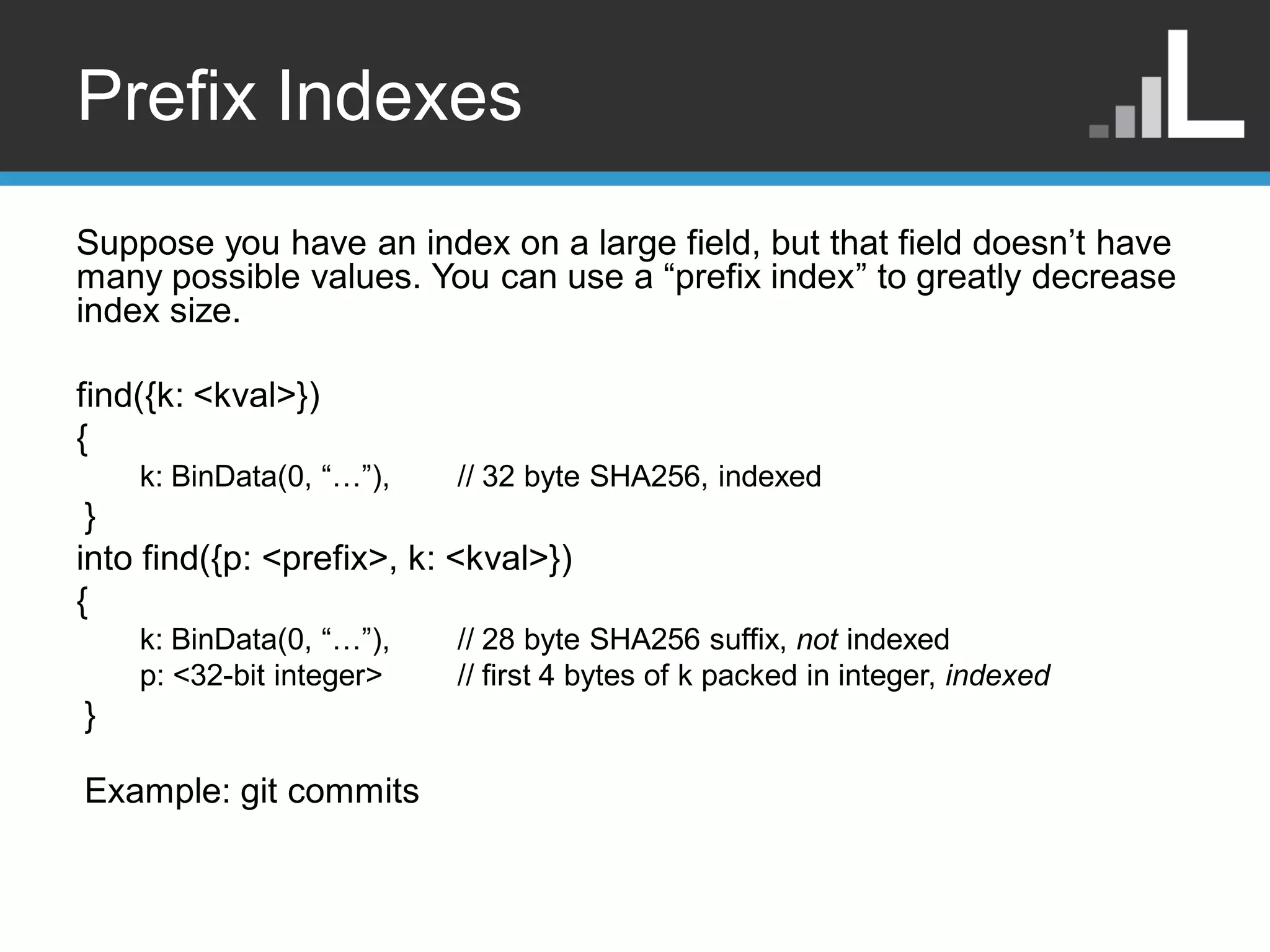
Prefix Indexes Suppose youhave an index on a large field, but that field doesn‟t have many possible values. You can use a “prefix index” to greatly decrease index size. find({k: <kval>}) { k: BinData(0, “…”), // 32 byte SHA256, indexed } into find({p: <prefix>, k: <kval>}) { k: BinData(0, “…”), // 28 byte SHA256 suffix, not indexed p: <32-bit integer> // first 4 bytes of k packed in integer, indexed } Example: git commits
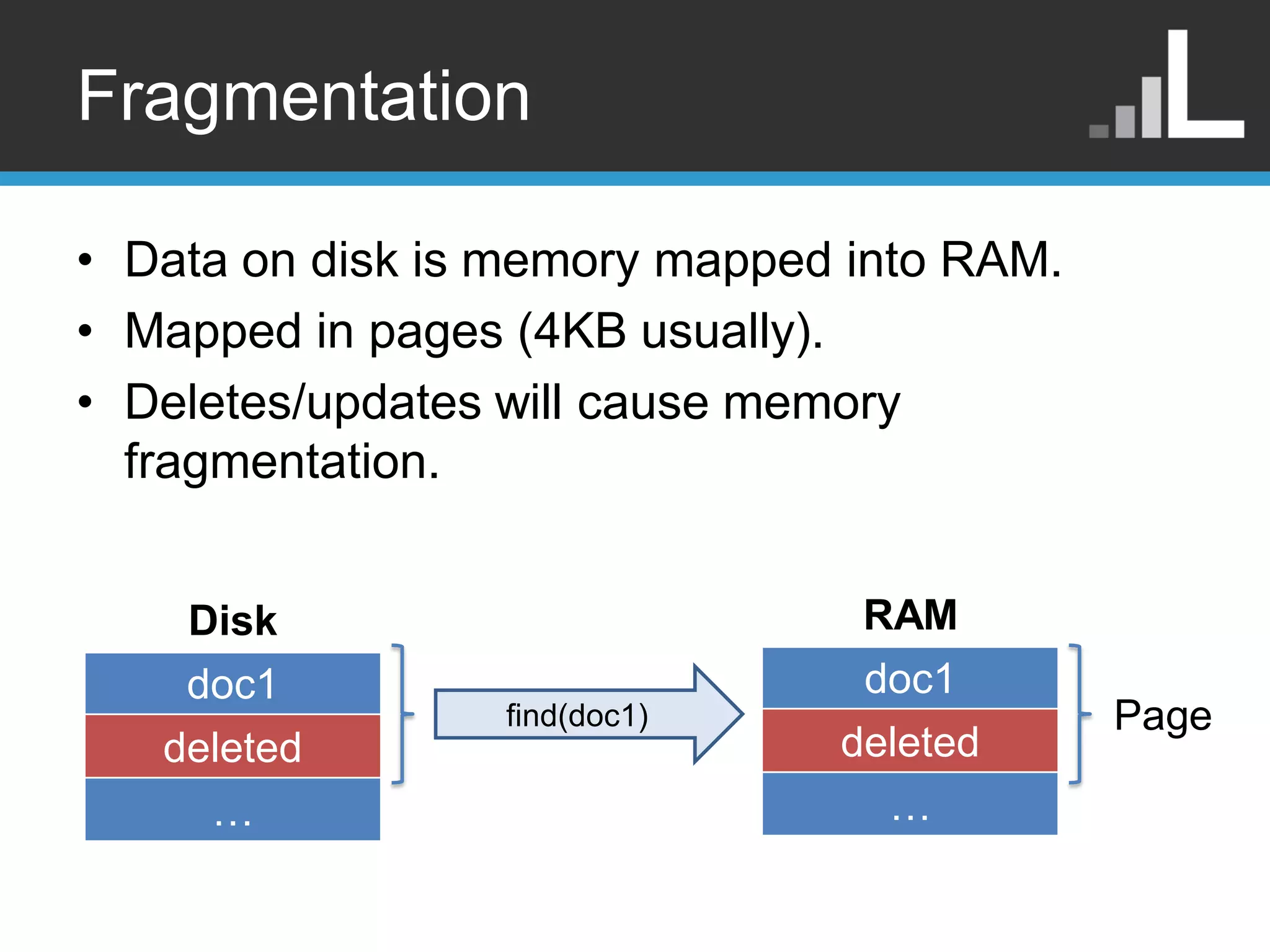
Fragmentation • Data ondisk is memory mapped into RAM. • Mapped in pages (4KB usually). • Deletes/updates will cause memory fragmentation. Disk RAM doc1 doc1 find(doc1) Page deleted deleted … …
15.
New writes minglewith old data Data doc1 Page Write docX docX doc3 doc4 Page doc5 find(docX) also pulls in old doc1, wasting RAM
16.
Dealing with fragmentation •“mongod --repair” on a secondary, swap with primary. • 1.9 has in-place compaction, but this still holds a write-lock. • MongoDB will auto-pad records. • Pad records yourself by including and then removing extra bytes on first insert. – Alternative offered in SERVER-1810.
17.
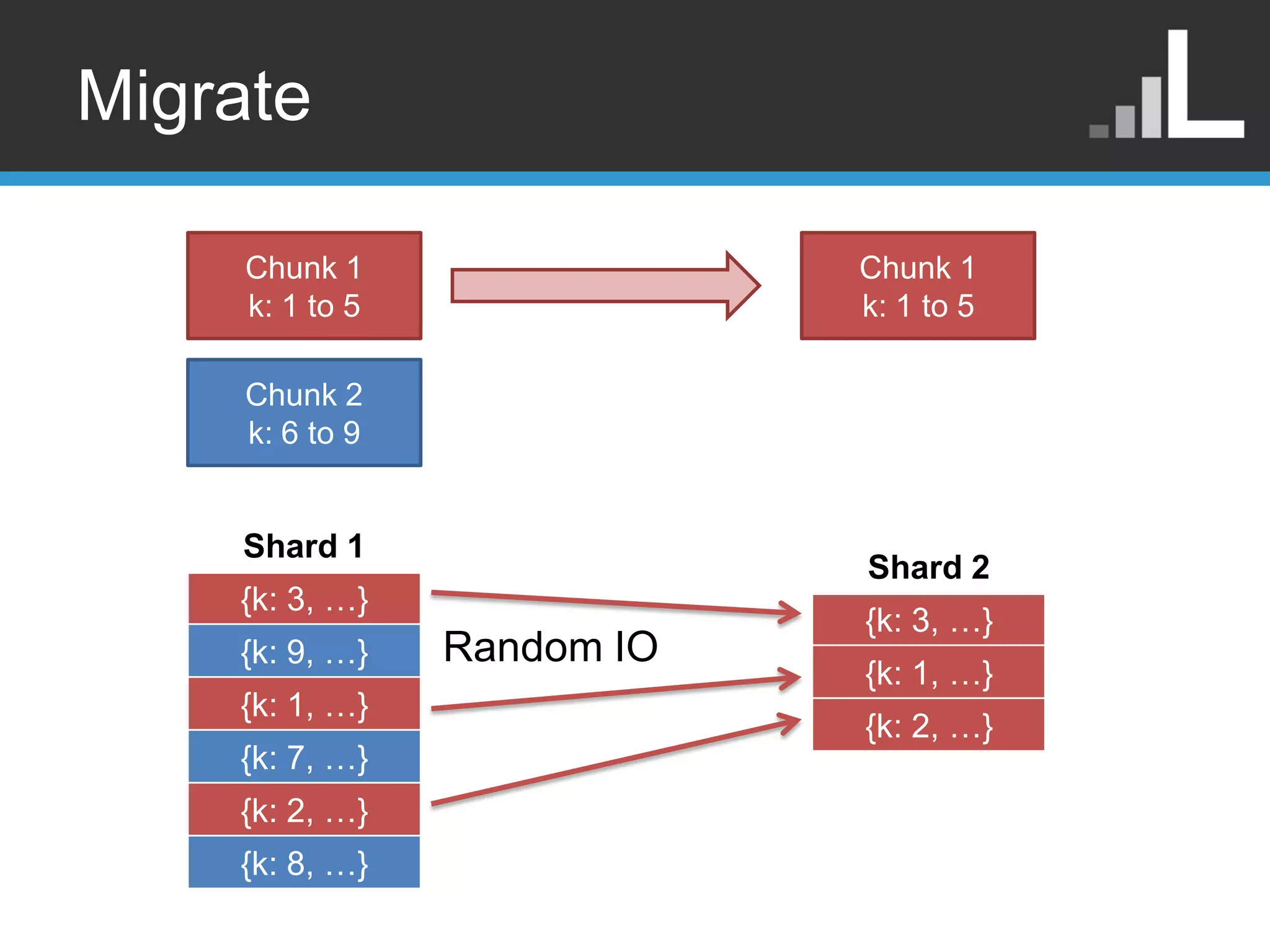
The Dark Sideof Migrations • Chunks are a logical construct, not physical. • Shard keys have serious implications. • What could go wrong? – Let‟s run through an example.
18.
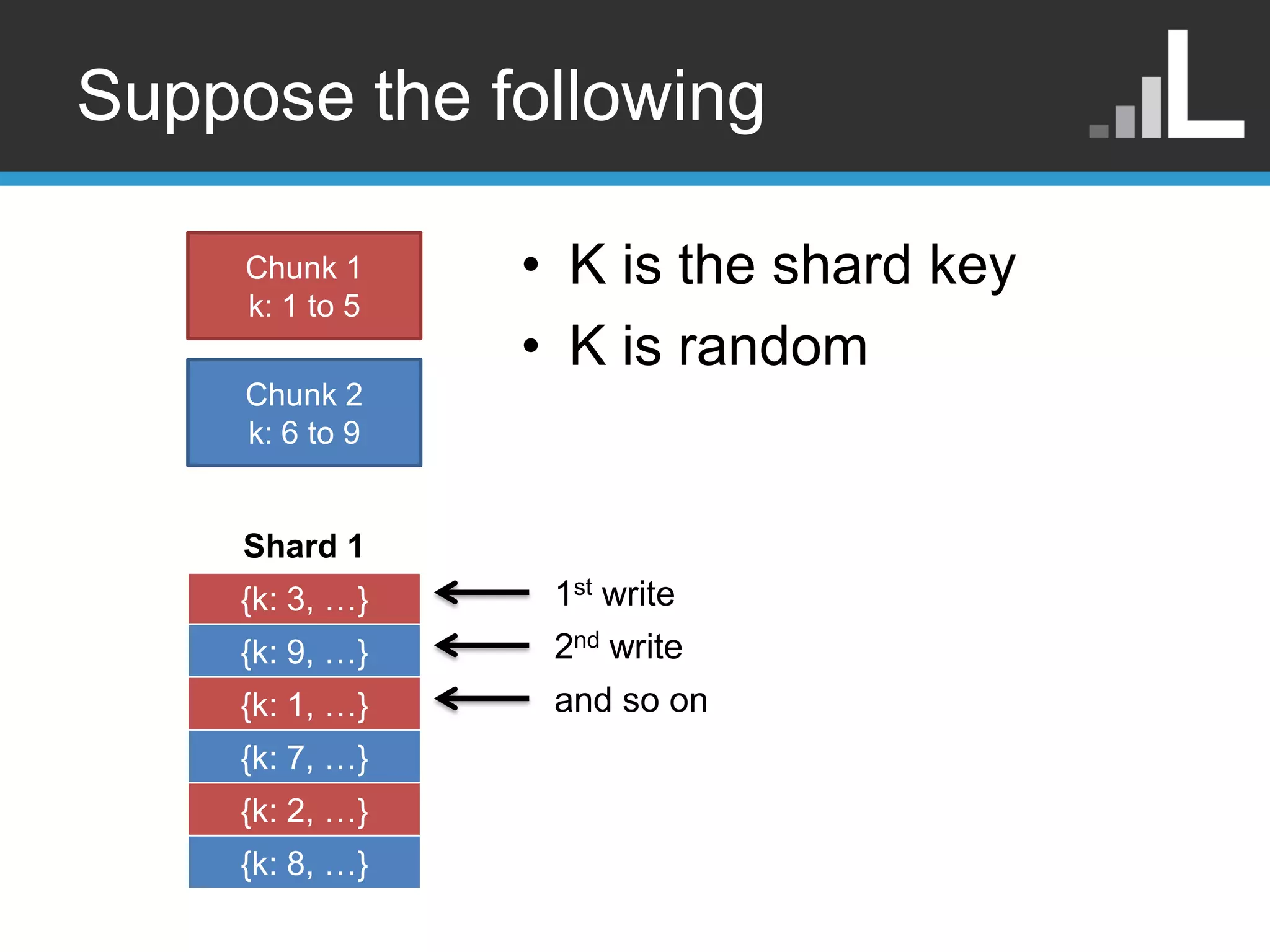
Suppose the following Chunk 1 • K is the shard key k: 1 to 5 • K is random Chunk 2 k: 6 to 9 Shard 1 {k: 3, …} 1st write {k: 9, …} 2nd write {k: 1, …} and so on {k: 7, …} {k: 2, …} {k: 8, …}
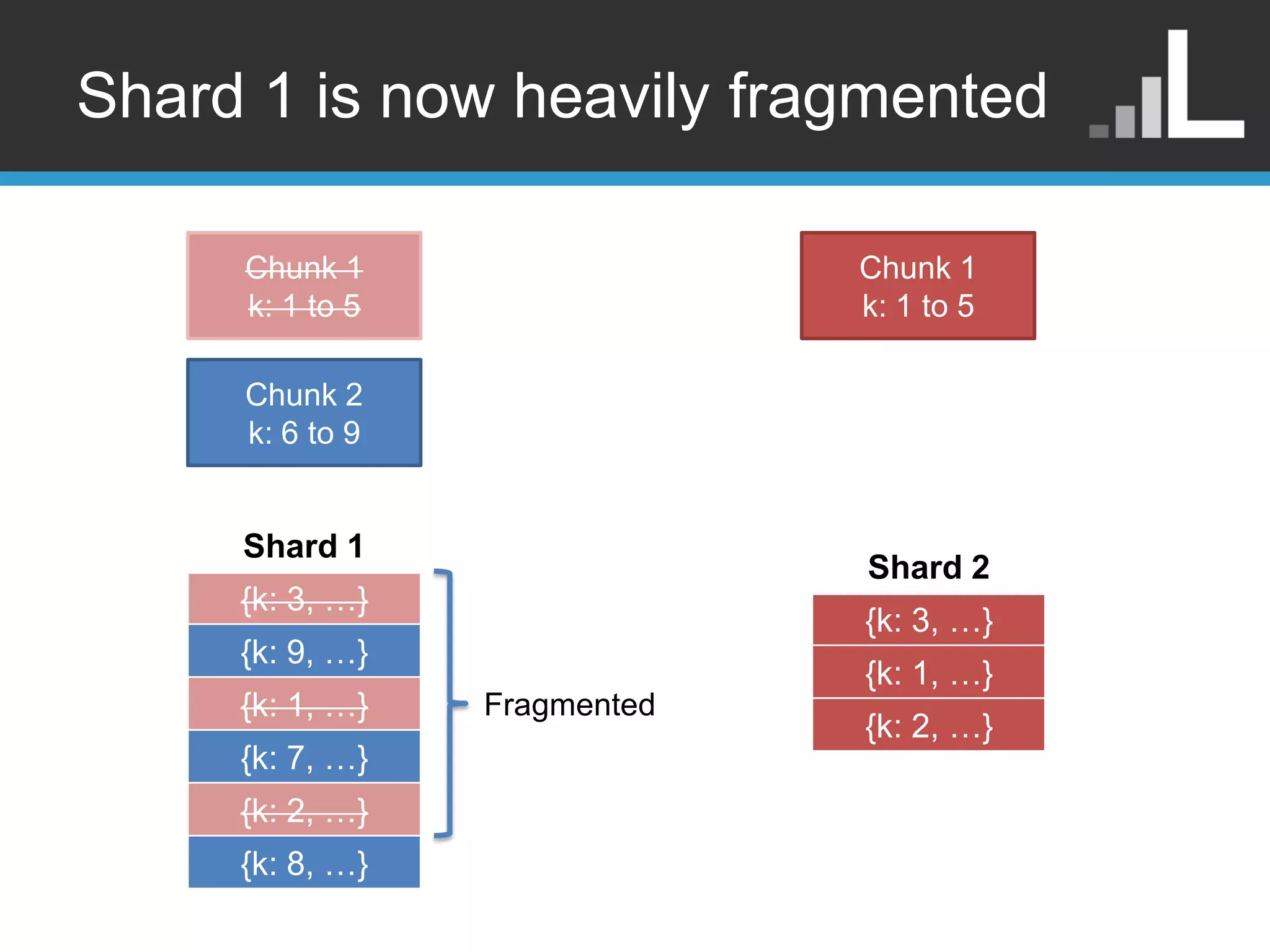
Why is thisscenario bad? • Random reads • Massive fragmentation • New writes mingle with old data
22.
How can weavoid bad migrations? • Pre-split, pre-chunk • Better shard keys for better locality – Ideally where data in the same chunk tends to be in the same region of disk
23.
Pre-split and move •If you know your key distribution, then pre-create your chunks and assign them. • See this: – http://blog.zawodny.com/2011/03/06/mongodb-pre- splitting-for-faster-data-loading-and-importing/
24.
Better shard keys •Usually means including a time prefix in your shard key (e.g., {day: 100, id: X}) • Beware of write hotspots • How to Choose a Shard Key – http://www.snailinaturtleneck.com/blog/2011/01/04/ho w-to-choose-a-shard-key-the-card-game/
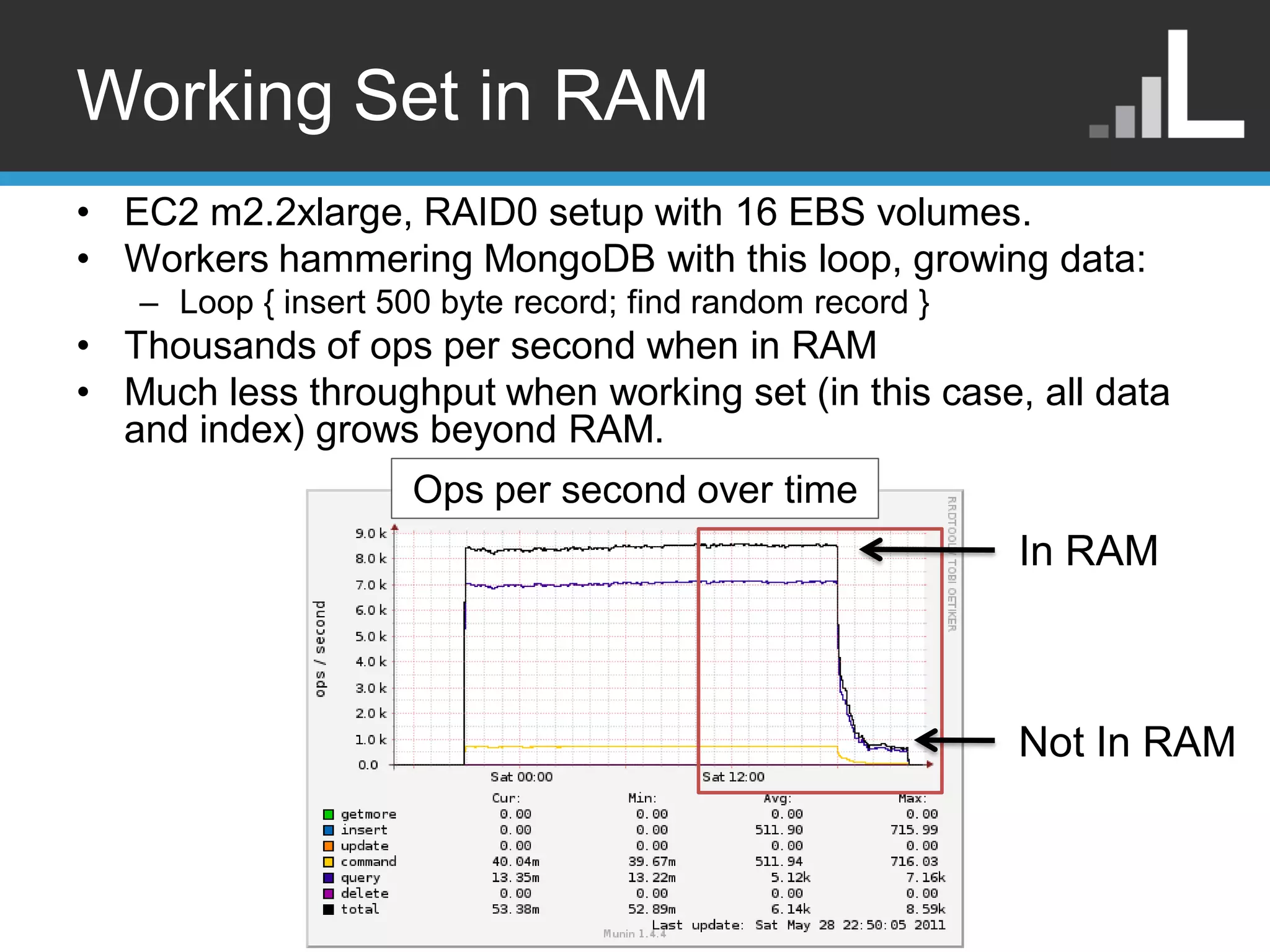
Working Set inRAM • EC2 m2.2xlarge, RAID0 setup with 16 EBS volumes. • Workers hammering MongoDB with this loop, growing data: – Loop { insert 500 byte record; find random record } • Thousands of ops per second when in RAM • Much less throughput when working set (in this case, all data and index) grows beyond RAM. Ops per second over time In RAM Not In RAM
27.
Pre-fetch • Updates holda lock while they fetch the original from disk. • Instead do a read to warm the doc in RAM under a shared read lock, then update.
28.
Shard per core •Instead of a shard per server, try a shard per core. • Use this strategy to overcome write locks when writes per second matter. • Why? Because MongoDB has one big write lock.
29.
Amazon EC2 • Highthroughput / small working set – RAM matters, go with high memory instances. • Low throughput / large working set – Ephemeral storage might be OK. – Remember that EBS IO goes over Ethernet. – Pay attention to IO wait time (iostat). – Your only shot at consistent perf: use the biggest instances in a family. • Read this: – http://perfcap.blogspot.com/2011/03/understanding- and-using-amazon-ebs.html
30.
Amazon EBS • ~200seeks per second per EBS on a good day • EBS has *much* better random IO perf than ephemeral, but adds a dependency • Use RAID0 • Check out this benchmark: – http://orion.heroku.com/past/2009/7/29/io_performanc e_on_ebs/ • To understand how to monitor EBS: – https://forums.aws.amazon.com/thread.jspa?messag eID=124044
31.
Further Reading • MongoDB Performance Tuning – http://www.scribd.com/doc/56271132/MongoDB-Performance-Tuning • Monitoring Tips – http://blog.boxedice.com/mongodb-monitoring/ • Markus‟ manual – http://www.markus-gattol.name/ws/mongodb.html • Helpful/interesting blog posts – http://nosql.mypopescu.com/tagged/mongodb/ • MongoDB on EC2 – http://www.slideshare.net/jrosoff/mongodb-on-ec2-and-ebs • EC2 and Ephemeral Storage – http://www.gabrielweinberg.com/blog/2011/05/raid0-ephemeral-storage-on-aws- ec2.html • MongoDB Strategies for the Disk Averse – http://engineering.foursquare.com/2011/02/09/mongodb-strategies-for-the-disk-averse/ • MongoDB Perf Tuning at MongoSF 2011 – http://www.scribd.com/doc/56271132/MongoDB-Performance-Tuning
32.
Thank you. • Checkout Localytics for mobile analytics! • Reach me at: – Email: my first name @ localytics.com – twitter.com/andrew311 – andrewrollins.com