Here's how OpenAI Token count is computed in Tiktokenizer - Part 3
In this article, we will review how OpenAI Token count is computed in Tiktokenizer — Part 3. We will look at:
- OpenSourceTokenizer class
For more context, read part 2.
OpenSourceTokenizer class
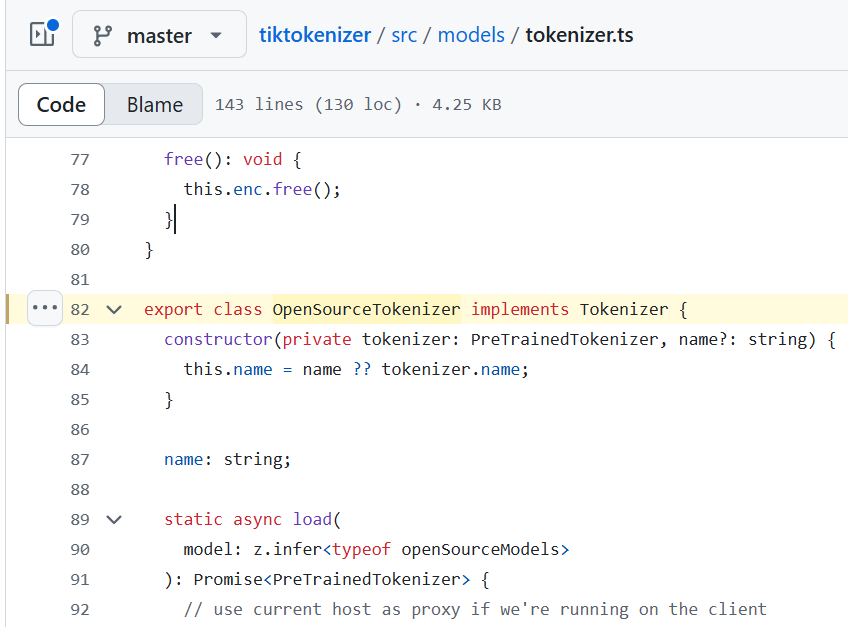
In tiktokenizer/src/models/tokenizer.ts, at line 82, you will find the following code:
export class OpenSourceTokenizer implements Tokenizer { constructor(private tokenizer: PreTrainedTokenizer, name?: string) { this.name = name ?? tokenizer.name; } name: string; static async load( model: z.infer<typeof openSourceModels> ): Promise<PreTrainedTokenizer> { // use current host as proxy if we're running on the client if (typeof window !== "undefined") { env.remoteHost = window.location.origin; } env.remotePathTemplate = "/hf/{model}"; // Set to false for testing! // env.useBrowserCache = false; const t = await PreTrainedTokenizer.from_pretrained(model, { progress_callback: (progress: any) => console.log(`loading "${model}"`, progress), }); console.log("loaded tokenizer", model, t.name); return t; } This class also implements tokenizer. Tokenizer is an interface defined in the same file
export interface Tokenizer { name: string; tokenize(text: string): TokenizerResult; free?(): void; } constructor
constructor had the following code
constructor(private tokenizer: PreTrainedTokenizer, name?: string) { this.name = name ?? tokenizer.name; } This constructor only sets this.name.
The type of tokenizer is PreTrainedTokenizer, it is imported as shown below:
import { PreTrainedTokenizer, env } from "@xenova/transformers"; static load
This OpenSourceTokenizer class has a static method named load and it contains the following code.
static async load( model: z.infer<typeof openSourceModels> ): Promise<PreTrainedTokenizer> { // use current host as proxy if we're running on the client if (typeof window !== "undefined") { env.remoteHost = window.location.origin; } env.remotePathTemplate = "/hf/{model}"; // Set to false for testing! // env.useBrowserCache = false; const t = await PreTrainedTokenizer.from_pretrained(model, { progress_callback: (progress: any) => console.log(`loading "${model}"`, progress), }); console.log("loaded tokenizer", model, t.name); return t; } This function returns a variable name t and this t is assigned a value returned by the PreTrainedTokenizer.from_pretrained as shown below
const t = await PreTrainedTokenizer.from_pretrained(model, { progress_callback: (progress: any) => console.log(`loading "${model}"`, progress), }); tokenize
tokenize has the following code.
tokenize(text: string): TokenizerResult { // const tokens = this.tokenizer(text); const tokens = this.tokenizer.encode(text); const removeFirstToken = ( hackModelsRemoveFirstToken.options as string[] ).includes(this.name); return { name: this.name, tokens, segments: getHuggingfaceSegments(this.tokenizer, text, removeFirstToken), count: tokens.length, }; } It returns the object that contains name, tokens, segments and count which is same as the object returned by the TiktokenTokenizer at line 26.
About me:
Hey, my name is Ramu Narasinga. I study codebase architecture in large open-source projects.
Email: ramu.narasinga@gmail.com
Want to learn from open-source projects? Solve challenges inspired by open-source projects.
References:
-
https://github.com/dqbd/tiktokenizer/blob/master/src/models/tokenizer.ts#L82
-
https://github.com/dqbd/tiktokenizer/blob/master/src/models/tokenizer.ts#L26