This document introduces HBase, an open-source, non-relational, distributed database modeled after Google's BigTable. It describes what HBase is, how it can be used, and when it is applicable. Key points include that HBase stores data in columns and rows accessed by row keys, integrates with Hadoop for MapReduce jobs, and is well-suited for large datasets, fast random access, and write-heavy applications. Common use cases involve log analytics, real-time analytics, and messages-centered systems.
Intro to HBase Alex Baranau, Sematext International, 2012 Monday, July 9, 12
2.
About Me Software Engineer at Sematext International http://blog.sematext.com/author/abaranau @abaranau http://github.com/sematext (abaranau) Monday, July 9, 12
3.
Agenda What is HBase? How to use HBase? When to use HBase? Monday, July 9, 12
What: HBase is... Open-source non-relational distributed column-oriented database modeled after Google’s BigTable. Think of it as a sparse, consistent, distributed, multidimensional, sorted map: labeled tables of rows row consist of key-value cells: (row key, column family, column, timestamp) -> value Monday, July 9, 12
6.
What HBase isNOT Not an SQL database Not relational No joins No fancy query language and no sophisticated query engine No transactions out-of-the box No secondary indices out-of-the box Not a drop-in replacement for your RDBMS Monday, July 9, 12
7.
What: Features-1 Linear scalability, capable of storing hundreds of terabytes of data Automatic and configurable sharding of tables Automatic failover support Strictly consistent reads and writes Monday, July 9, 12
8.
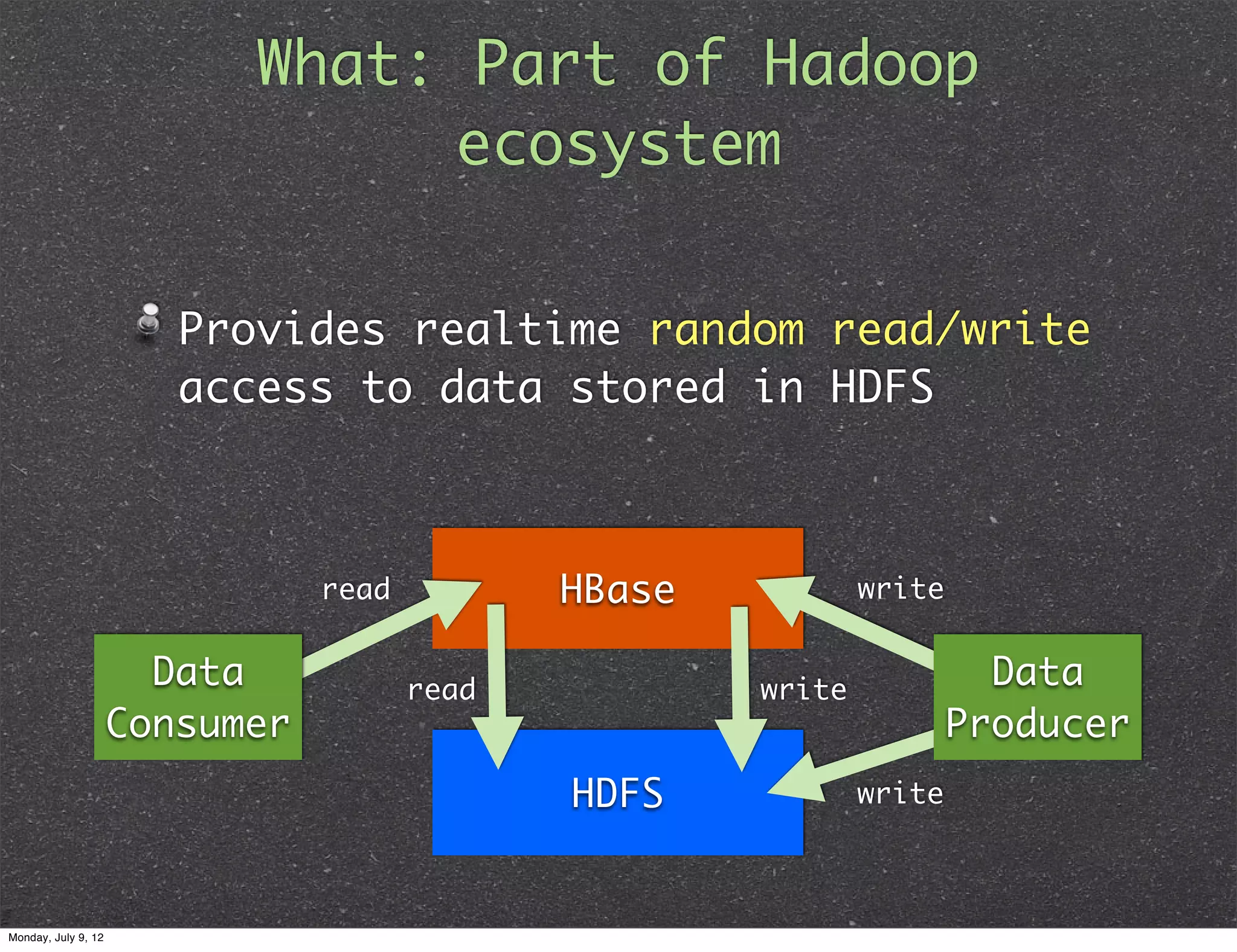
What: Part ofHadoop ecosystem Provides realtime random read/write access to data stored in HDFS read HBase write Data read write Data Consumer Producer HDFS write Monday, July 9, 12
9.
What: Features-2 Integrates nicely with Hadoop MapReduce (both as source and destination) Easy Java API for client access Thrift gateway and REST APIs Bulk import of large amount of data Replication across clusters & backup options Block cache and Bloom filters for real-time queries and many more... Monday, July 9, 12
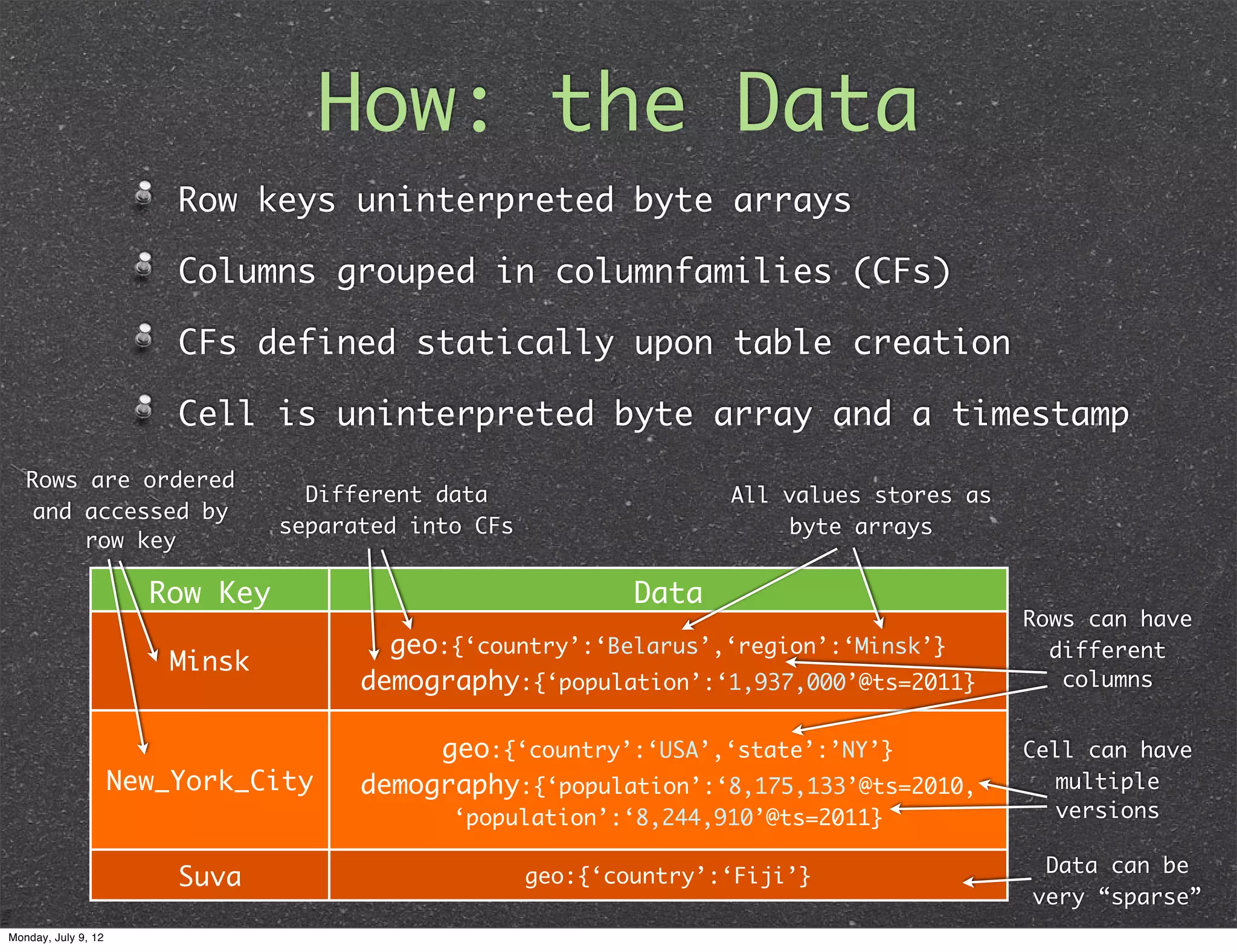
How: the Data Row keys uninterpreted byte arrays Columns grouped in columnfamilies (CFs) CFs defined statically upon table creation Cell is uninterpreted byte array and a timestamp Rows are ordered Different data All values stores as and accessed by separated into CFs byte arrays row key Row Key Data Rows can have geo:{‘country’:‘Belarus’,‘region’:‘Minsk’} different Minsk demography:{‘population’:‘1,937,000’@ts=2011} columns geo:{‘country’:‘USA’,‘state’:’NY’} Cell can have New_York_City demography:{‘population’:‘8,175,133’@ts=2010, multiple ‘population’:‘8,244,910’@ts=2011} versions Data can be Suva geo:{‘country’:‘Fiji’} very “sparse” Monday, July 9, 12
12.
How: Writing theData Row updates are atomic Updates across multiple rows are NOT atomic, no transaction support out of the box HBase stores N versions of a cell (default 3) Tables are usually “sparse”, not all columns populated in a row Monday, July 9, 12
13.
How: Reading theData Reader will always read the last written (and committed) values Reading single row: Get Reading multiple rows: Scan (very fast) Scan usually defines start key and stop key Rows are ordered, easy to do partial key scan Row Key Data ‘login_2012-03-01.00:09:17’ d:{‘user’:‘alex’} ... ... ‘login_2012-03-01.23:59:35’ d:{‘user’:‘otis’} ‘login_2012-03-02.00:00:21’ d:{‘user’:‘david’} Query predicate pushed down via server-side Filters Monday, July 9, 12
14.
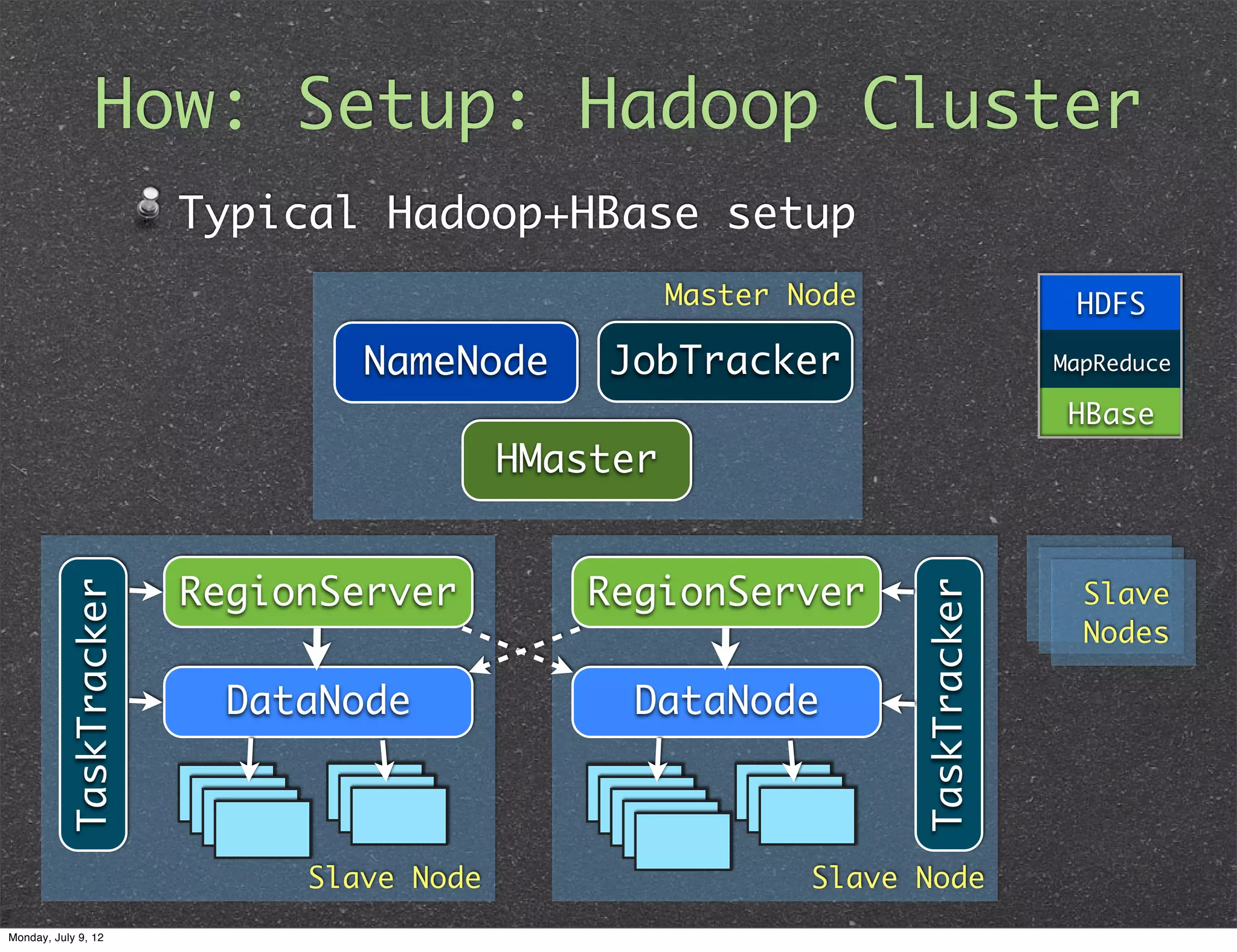
How: MapReduce Integration Out of the box integration with Hadoop MapReduce Data from HBase table can be source for MR job MR job can write data into HBase MR job can write data into HDFS directly and then output files can be very quickly loaded into HBase via “Bulk Loading” functionality Monday, July 9, 12
15.
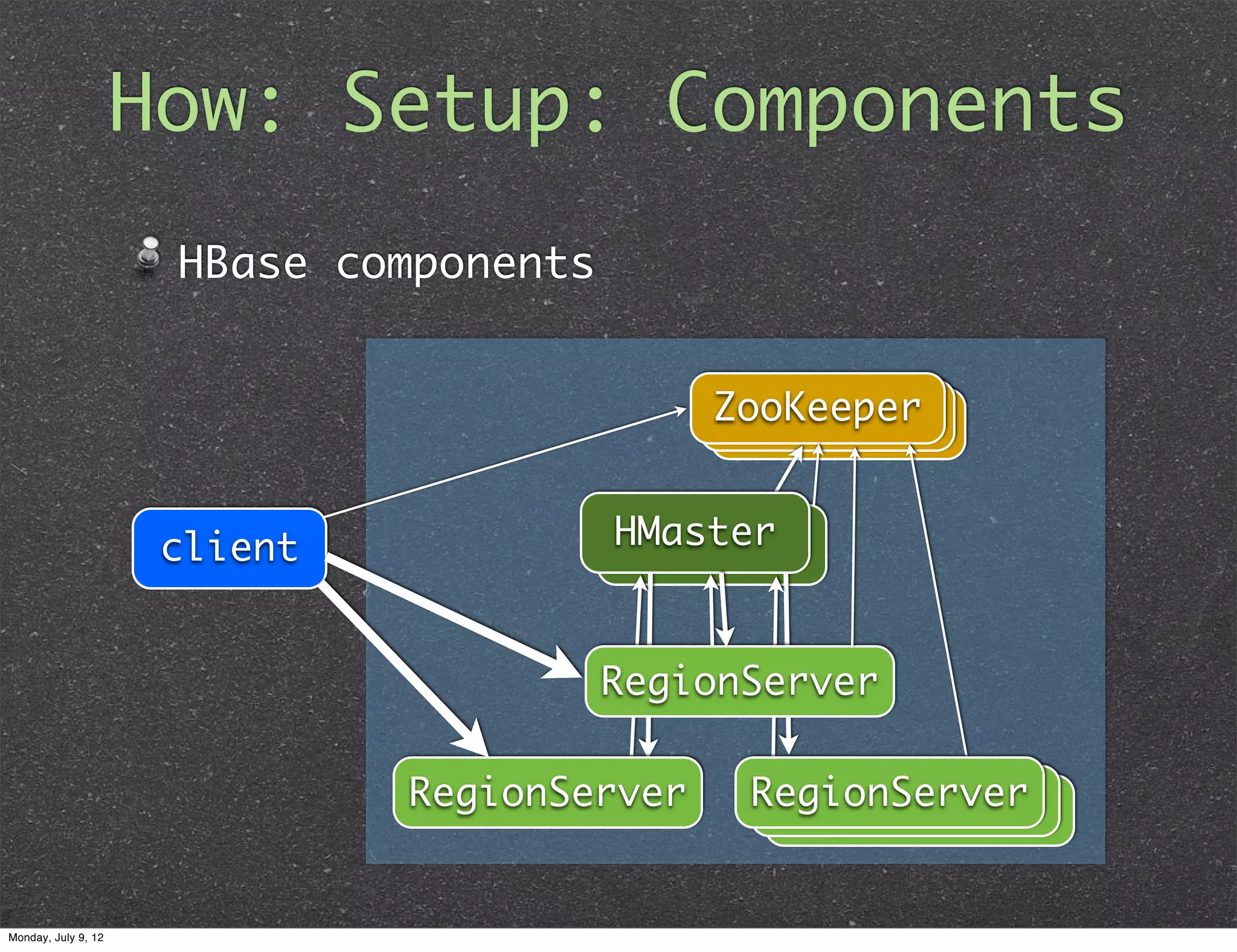
How: Sharding theData Automatic and configurable sharding of tables: Tables partitioned into Regions Region defined by start & end row keys Regions are the “atoms” of distribution Regions are assigned to RegionServers (HBase cluster slaves) Monday, July 9, 12
How: Setup: AutomaticFailover DataNode failures handled by HDFS (replication) RSs failures (incl. caused by whole server failure) handled automatically Master re-assignes Regions to available RSs HMaster failover: automatic with multiple HMasters Monday, July 9, 12
When: What HBaseis good at Serving large amount of data: built to scale from the get-go fast random access to the data Write-heavy applications* Append-style writing (inserting/ overwriting new data) rather than heavy read-modify-write operations** * clients should handle the loss of HTable client-side buffer ** see https://github.com/sematext/HBaseHUT Monday, July 9, 12
21.
When: HBase vs... Favors consistency over availability Part of a Hadoop ecosystem Great community; adopted by tech giants like Facebook, Twitter, Yahoo!, Adobe, etc. Monday, July 9, 12
22.
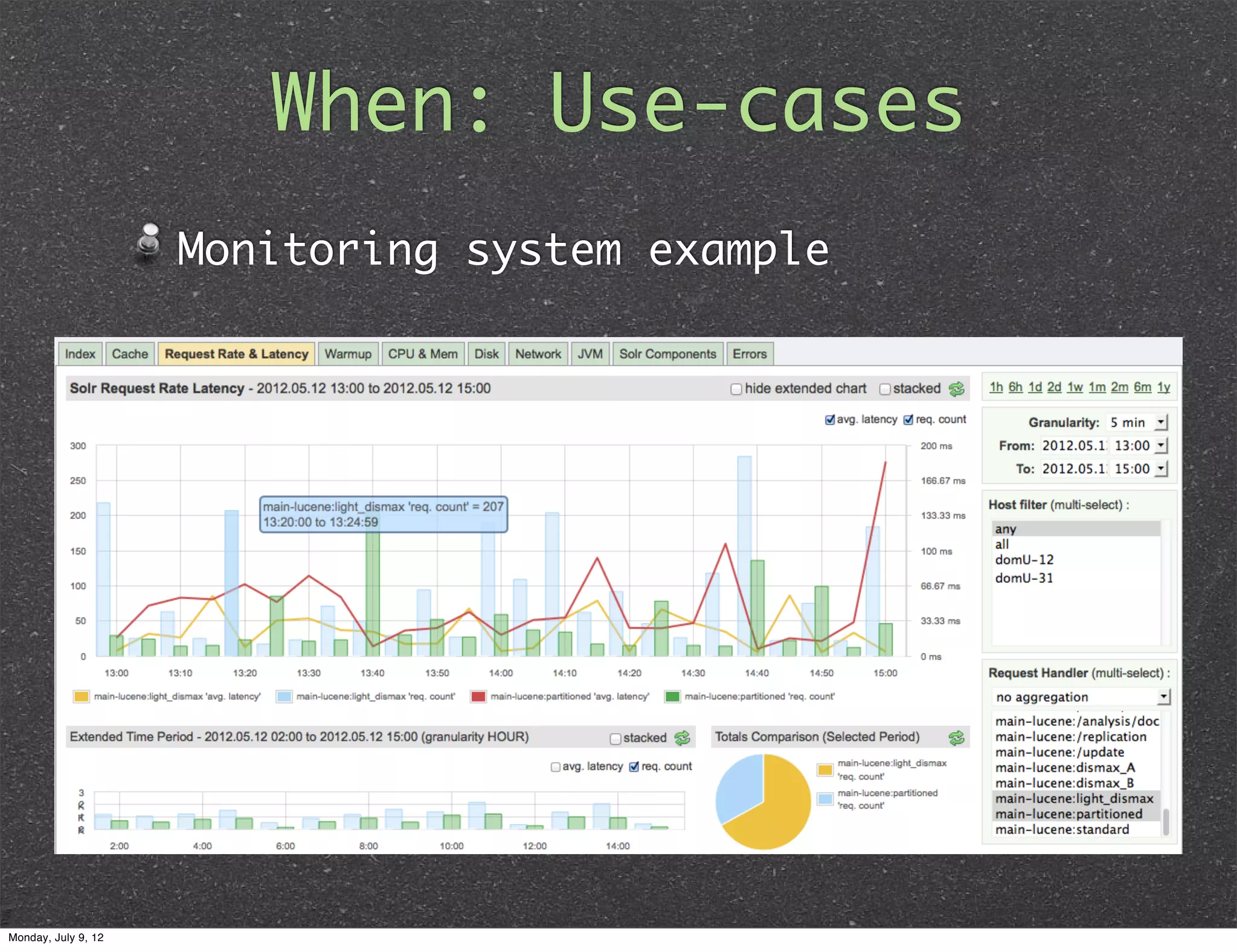
When: Use-cases Audit logging systems track user actions answer questions/queries like: what are the last 10 actions made by user? row key: userId_timestamp which users logged into system yesterday? row key: action_timestamp_userId Monday, July 9, 12
When: Use-cases Messages-centered systems twitter-like messages/statuses Content management systems serving content out of HBase Canonical use-case: webtable (pages stored during crawling the web) And others Monday, July 9, 12
26.
Future Making stable enough to substitute RDBMS in mission critical cases Easier system management Performance improvements Monday, July 9, 12
27.
Qs? (next: Intro into HBase Internals) Sematext is hiring! Monday, July 9, 12