


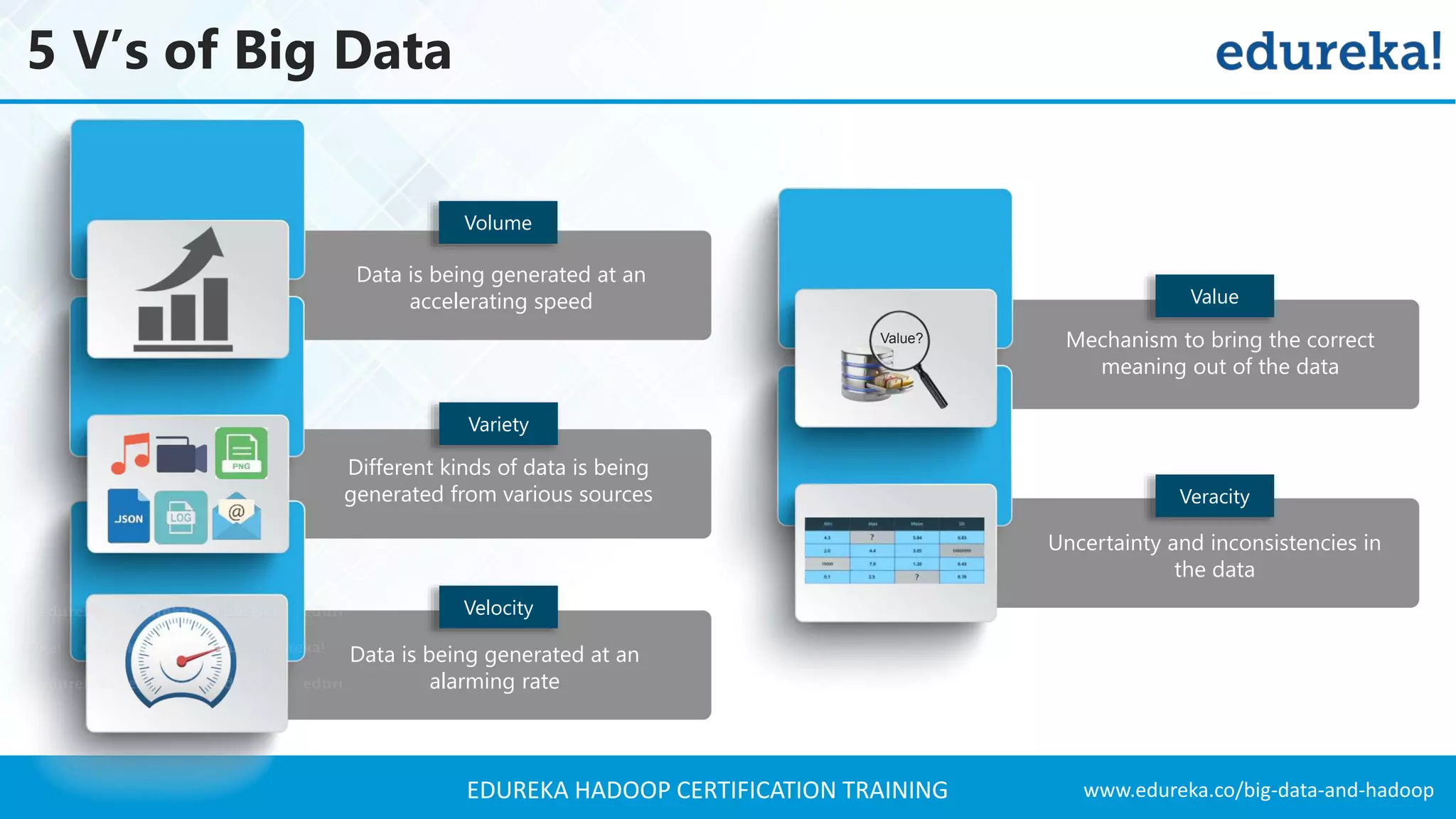

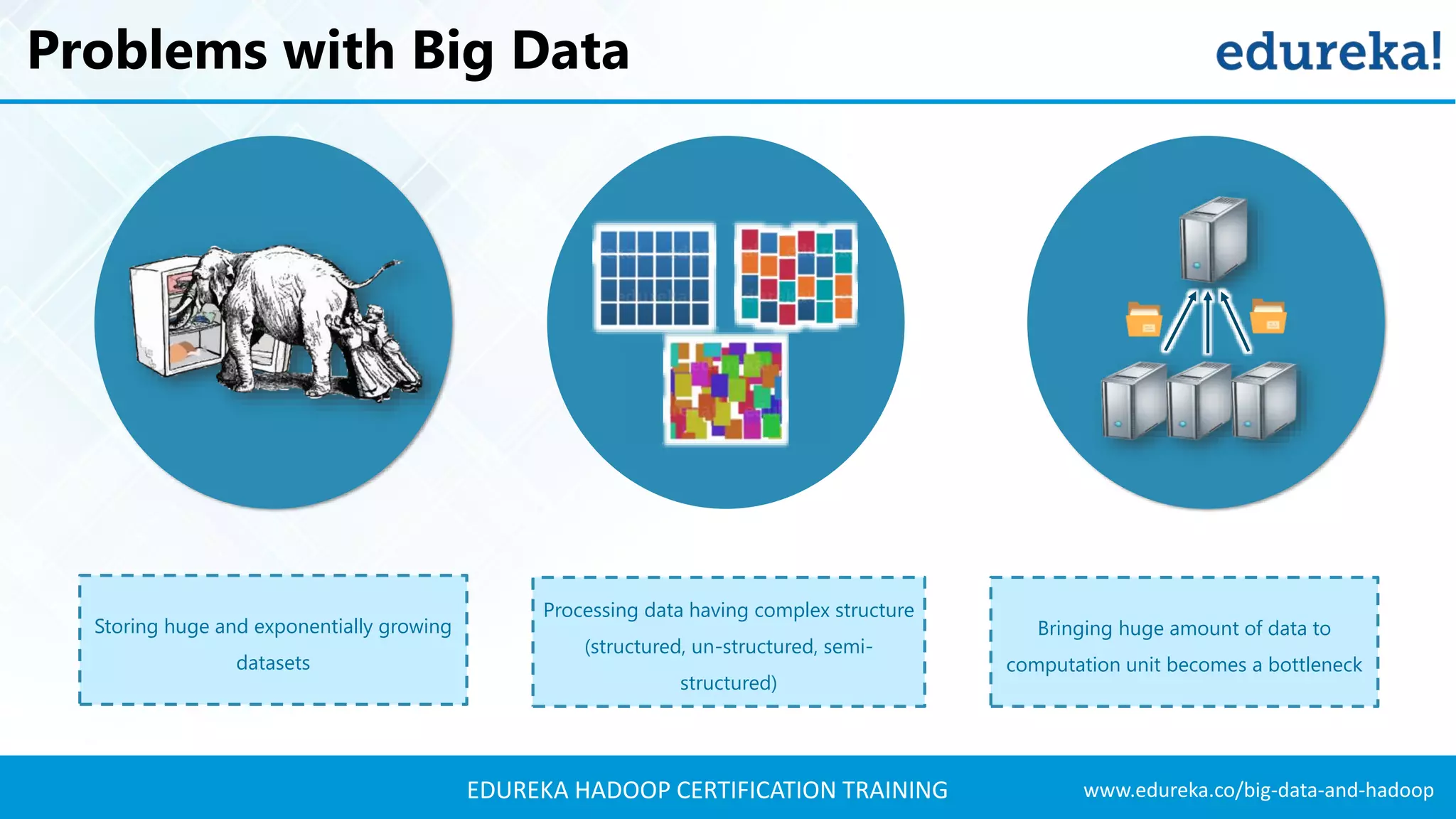

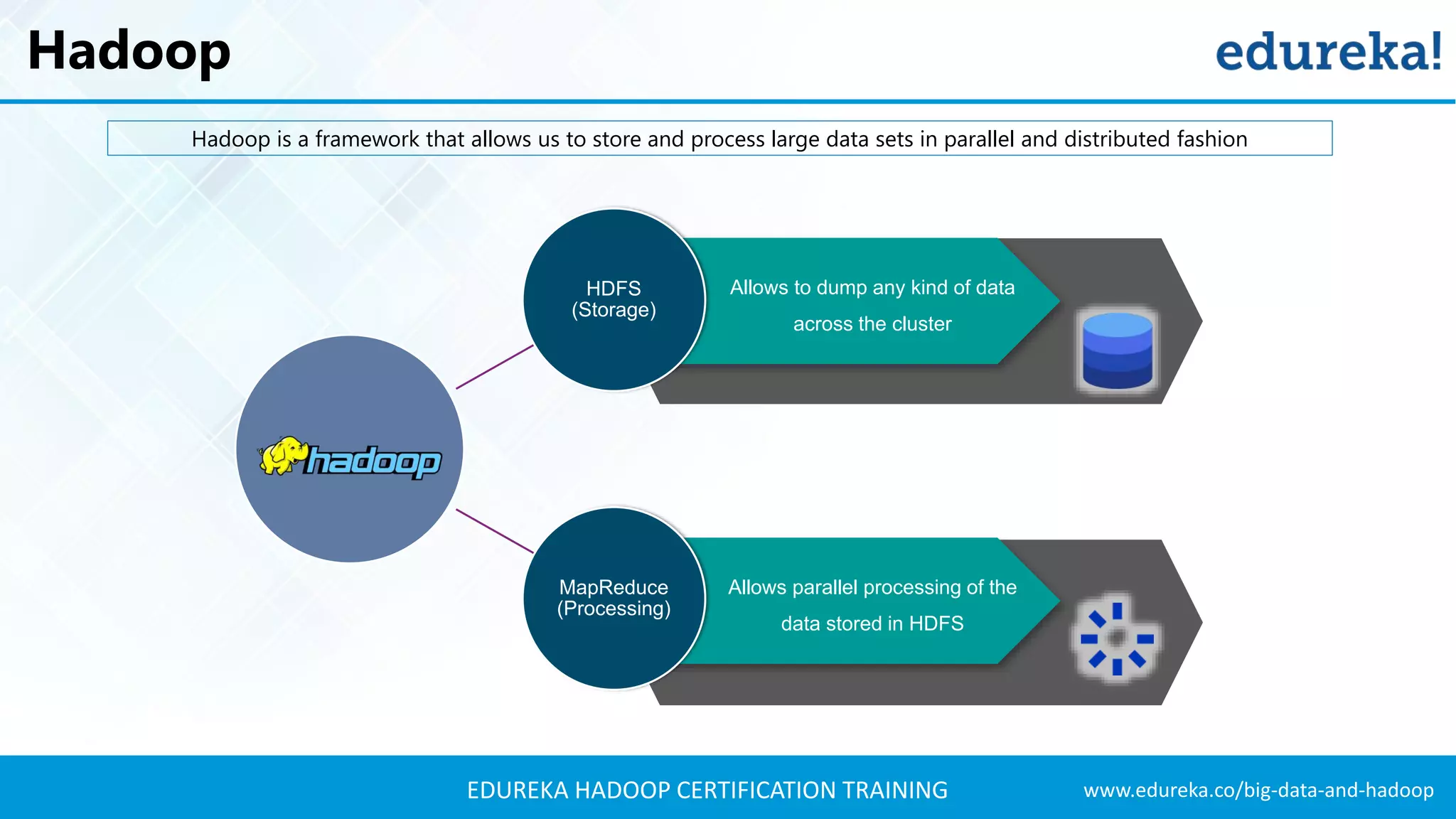
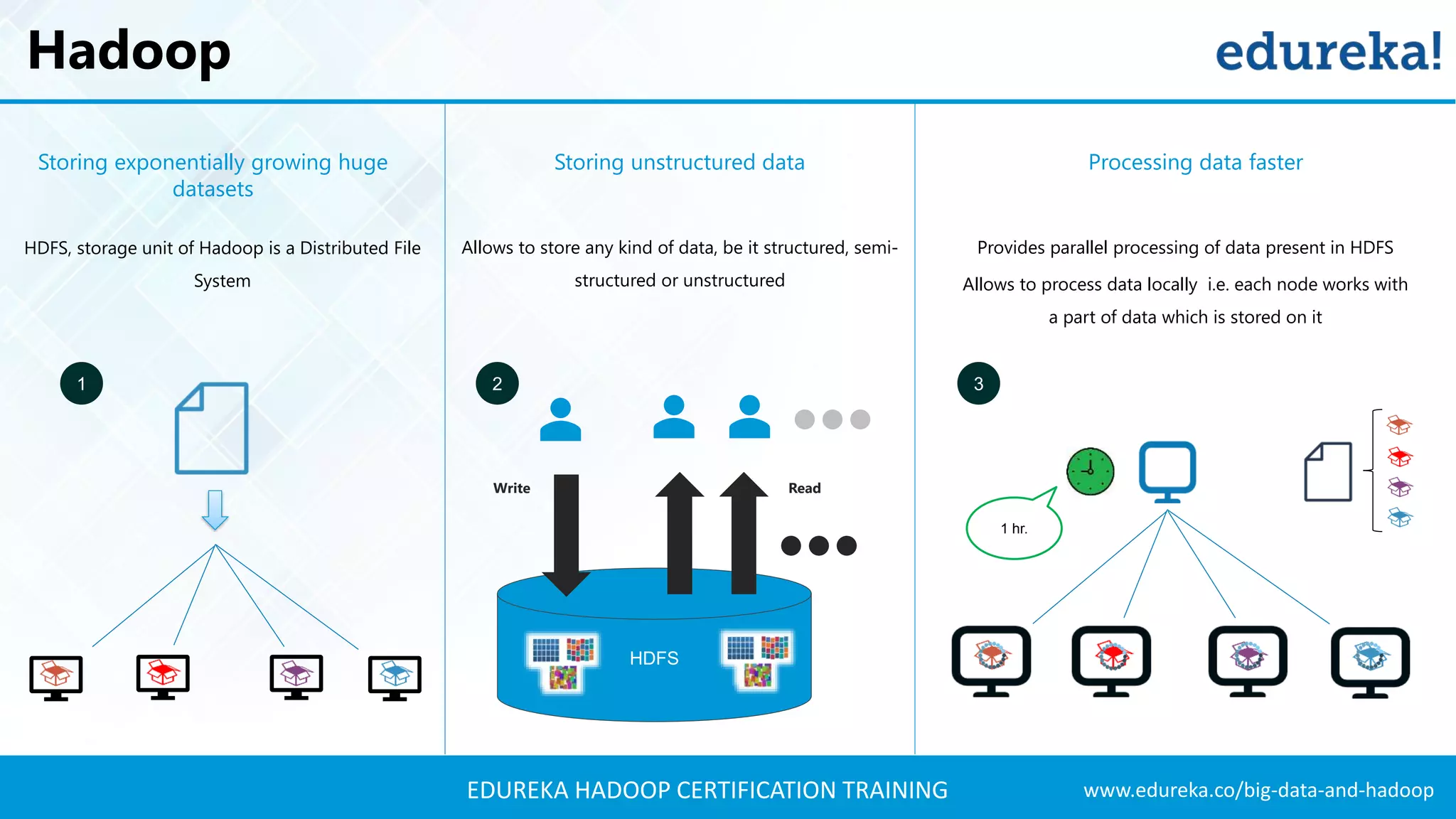

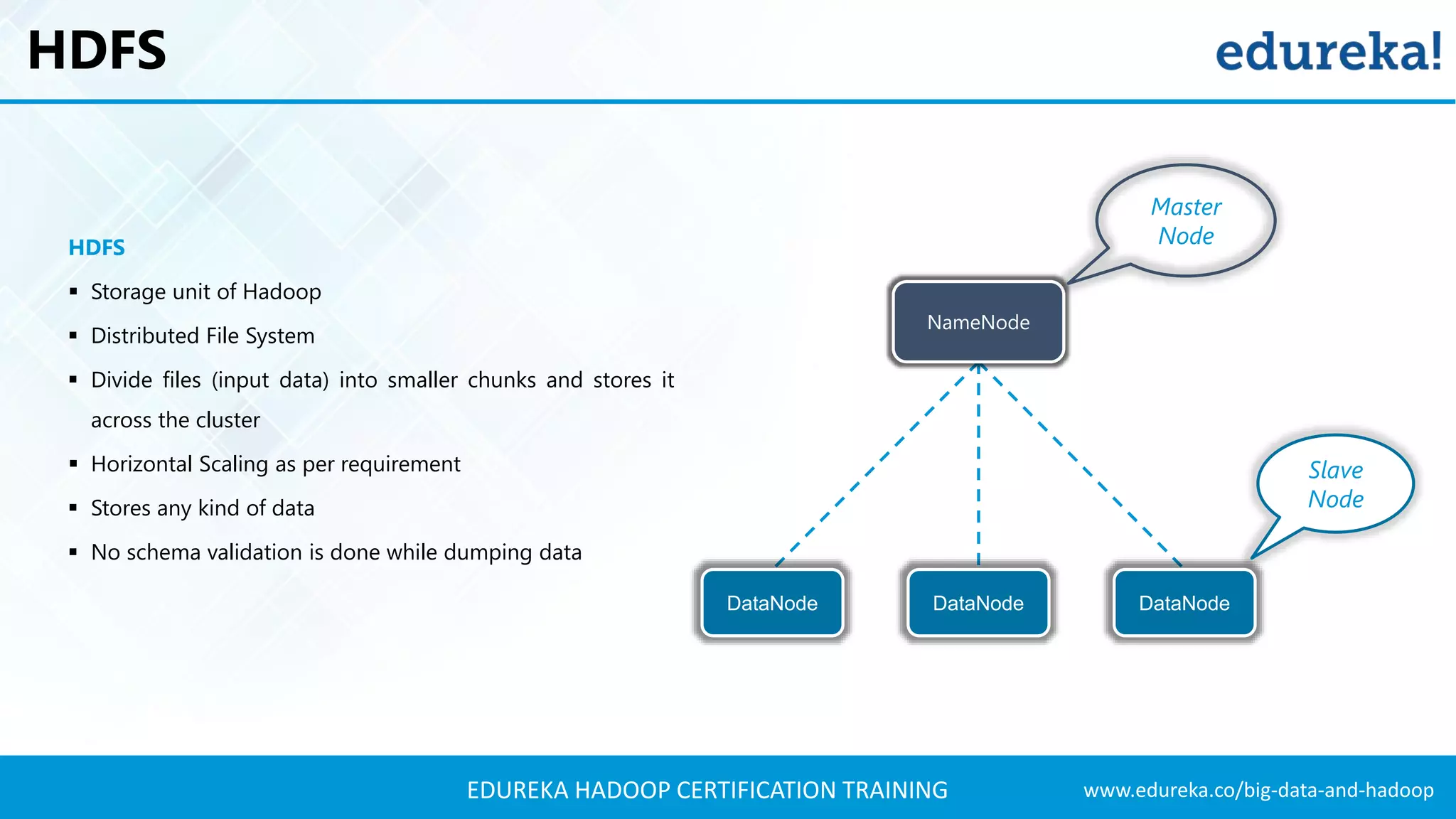
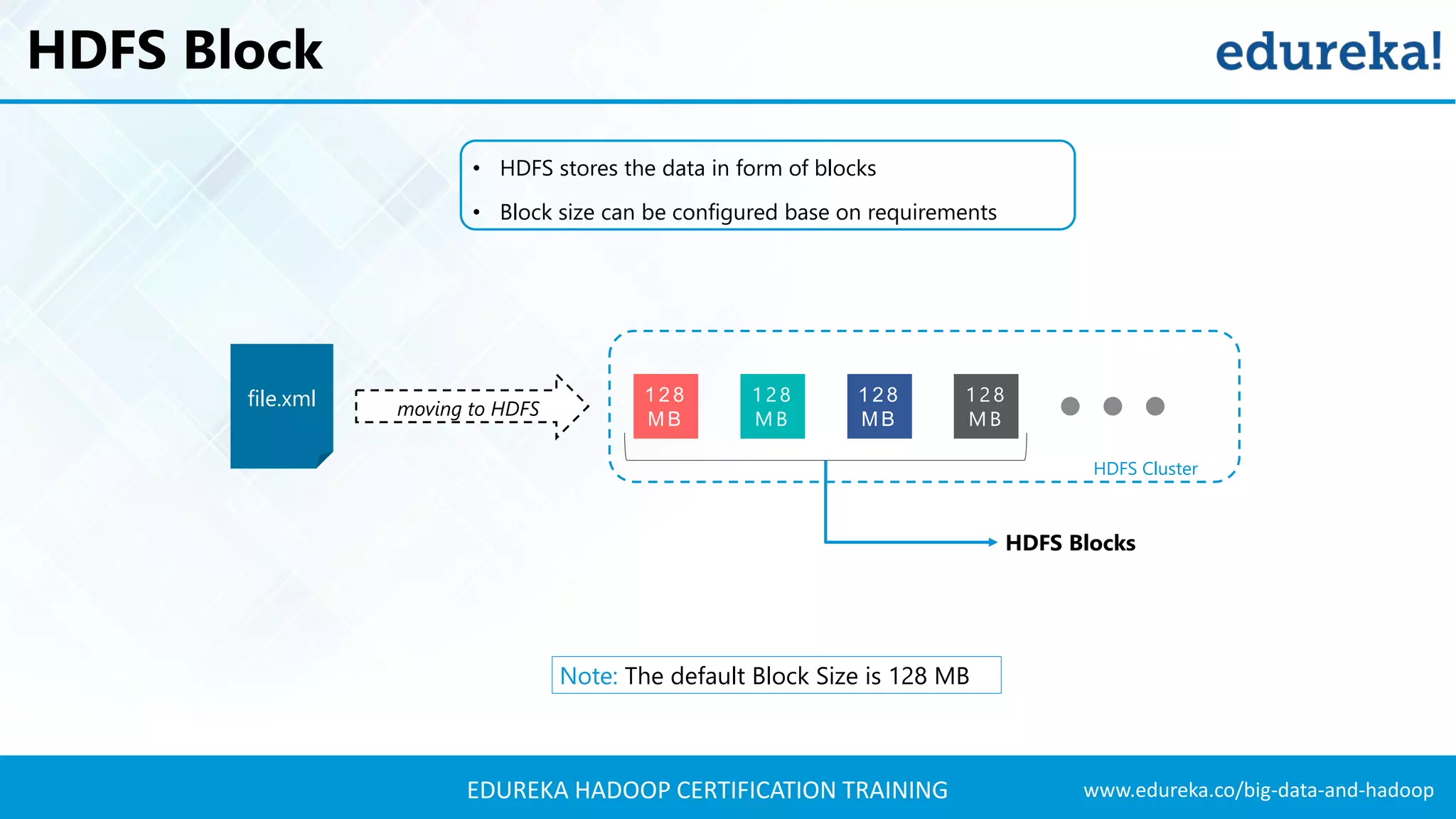
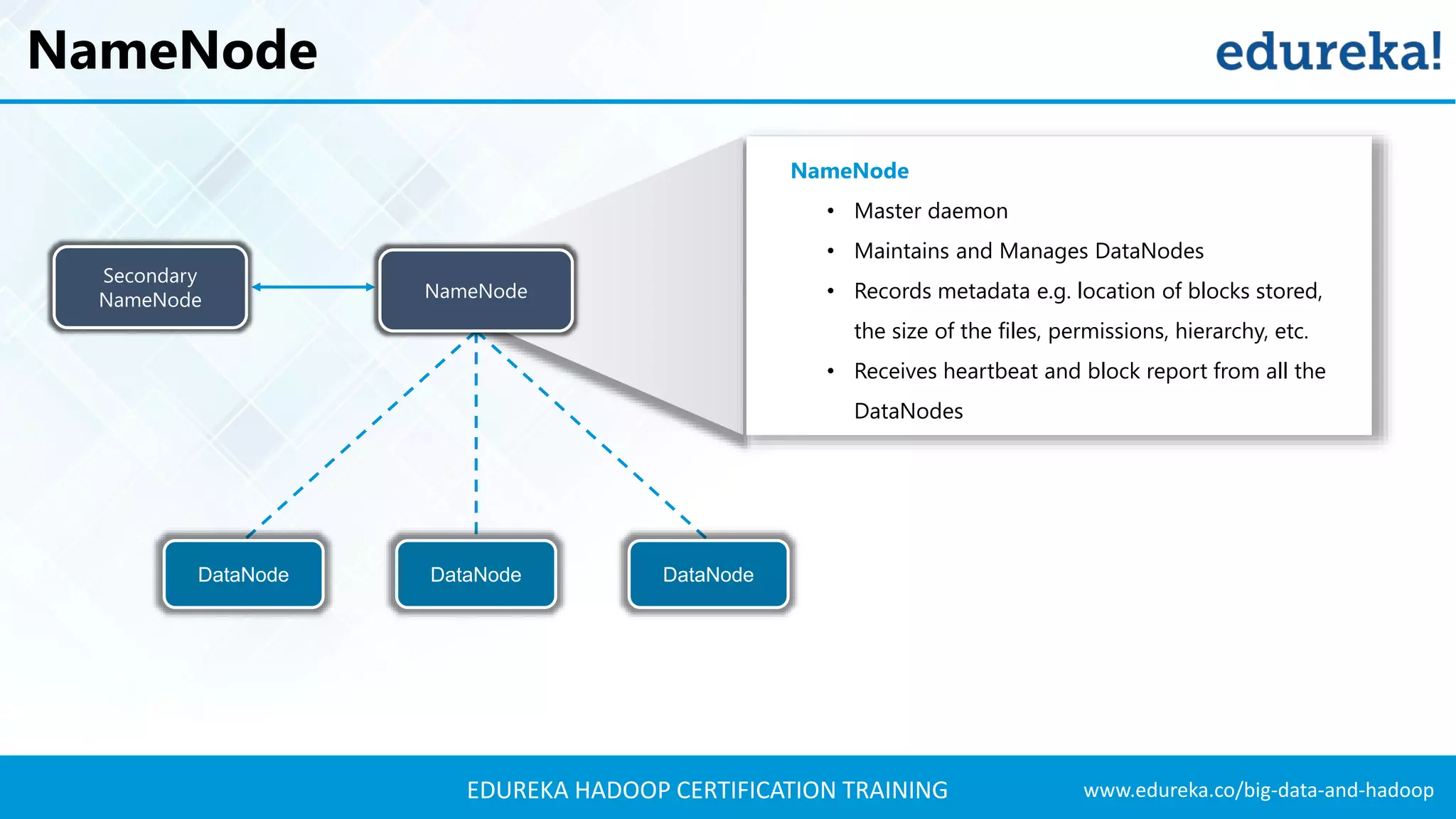
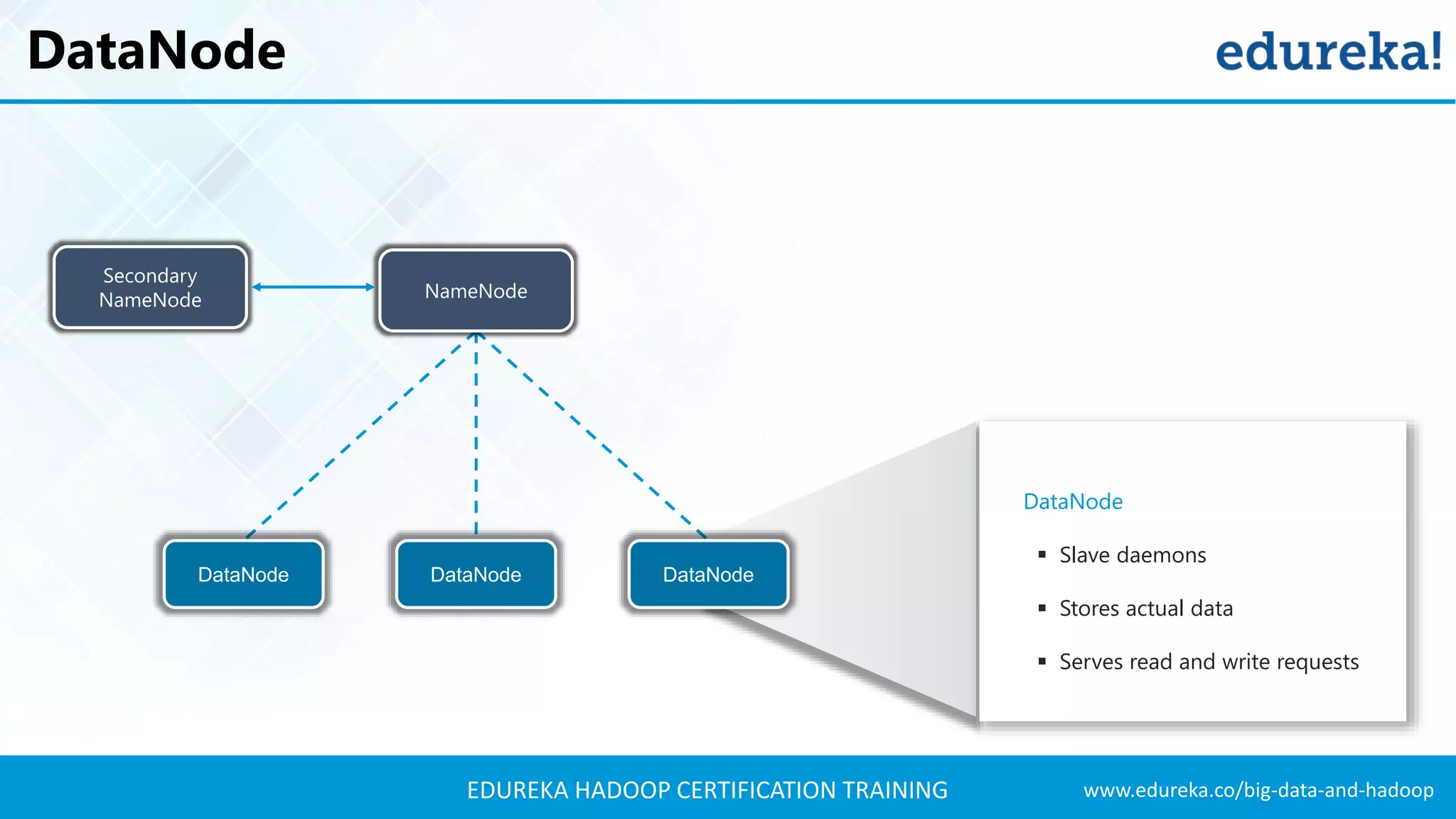
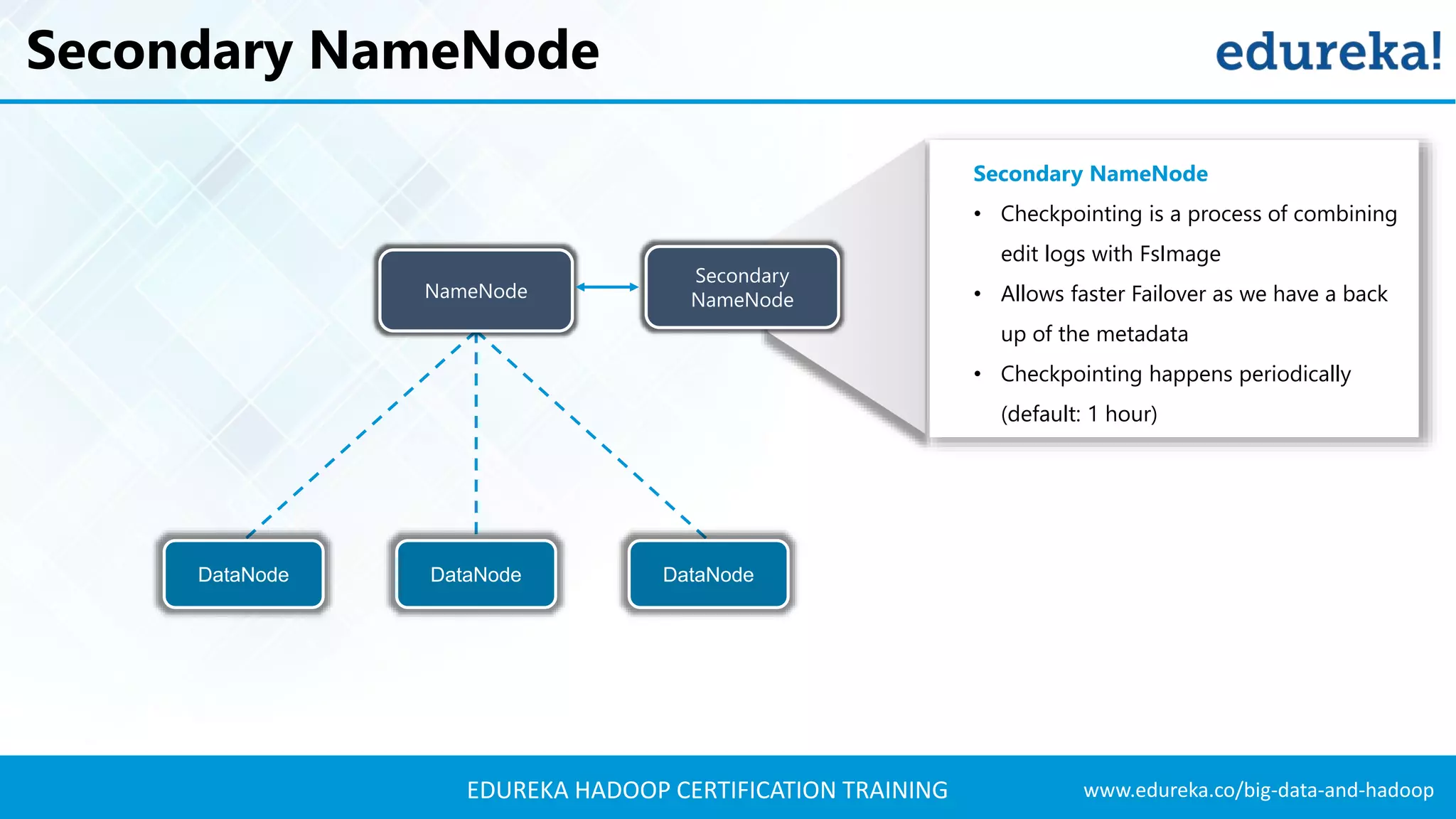
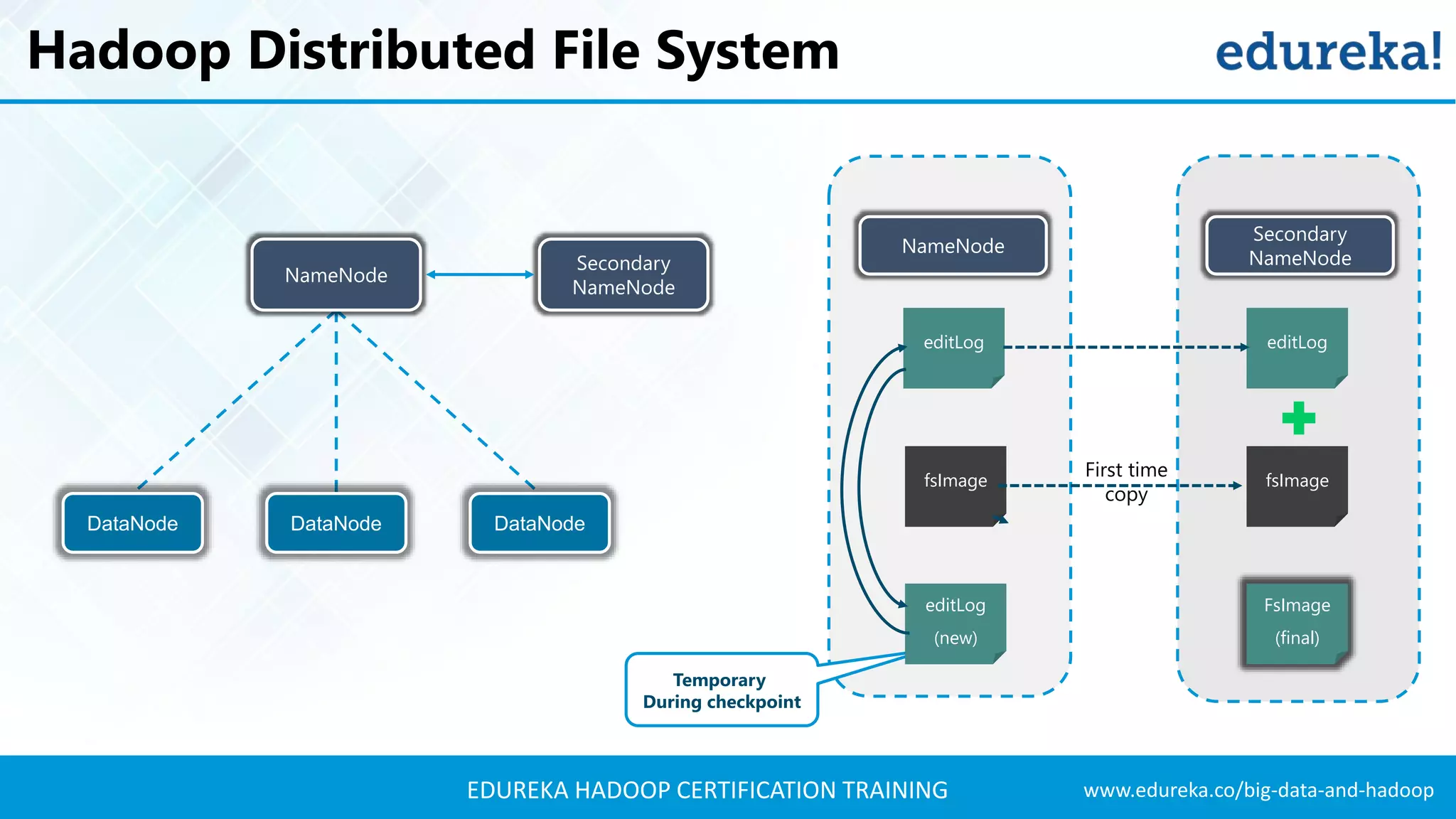

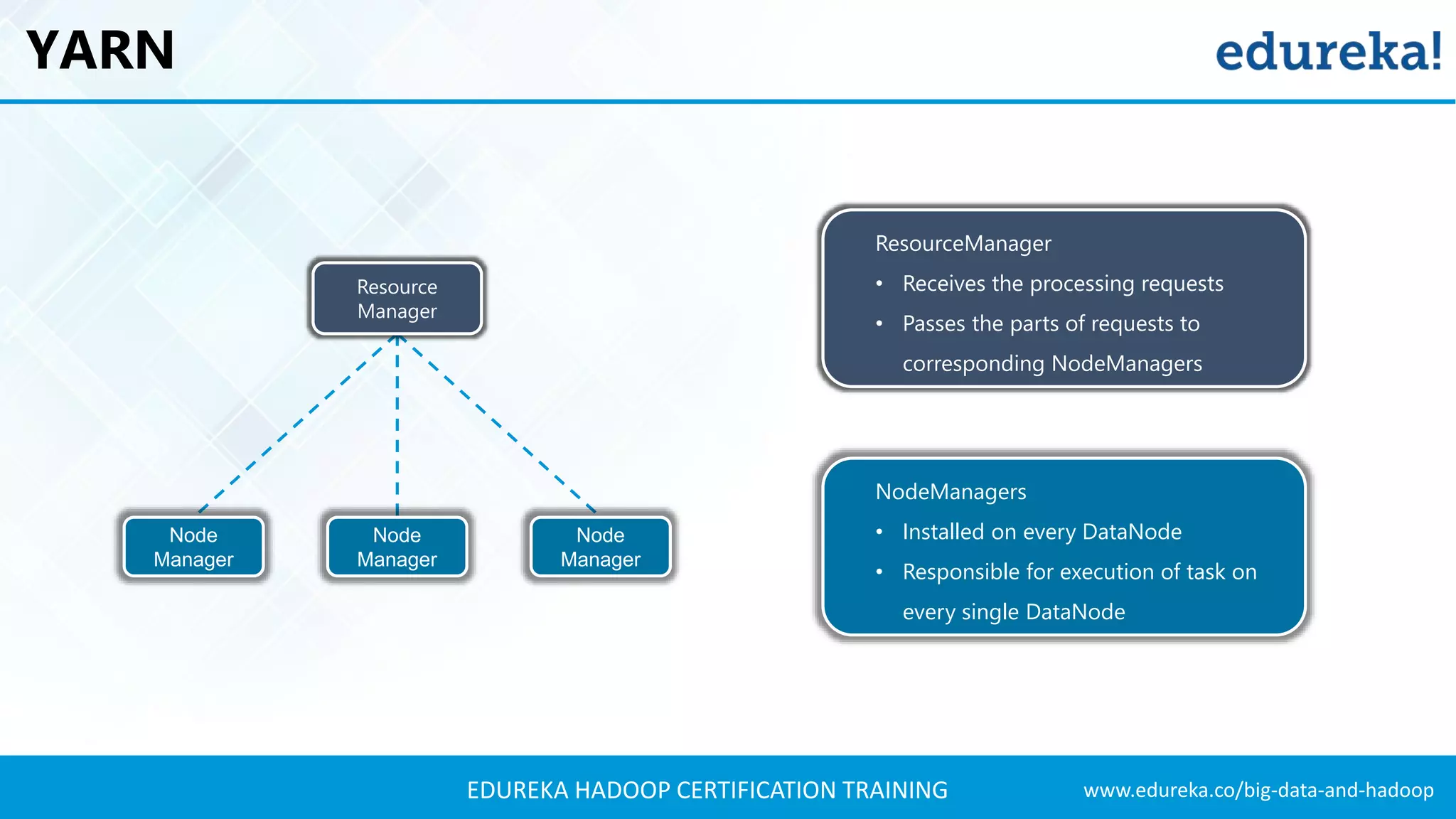
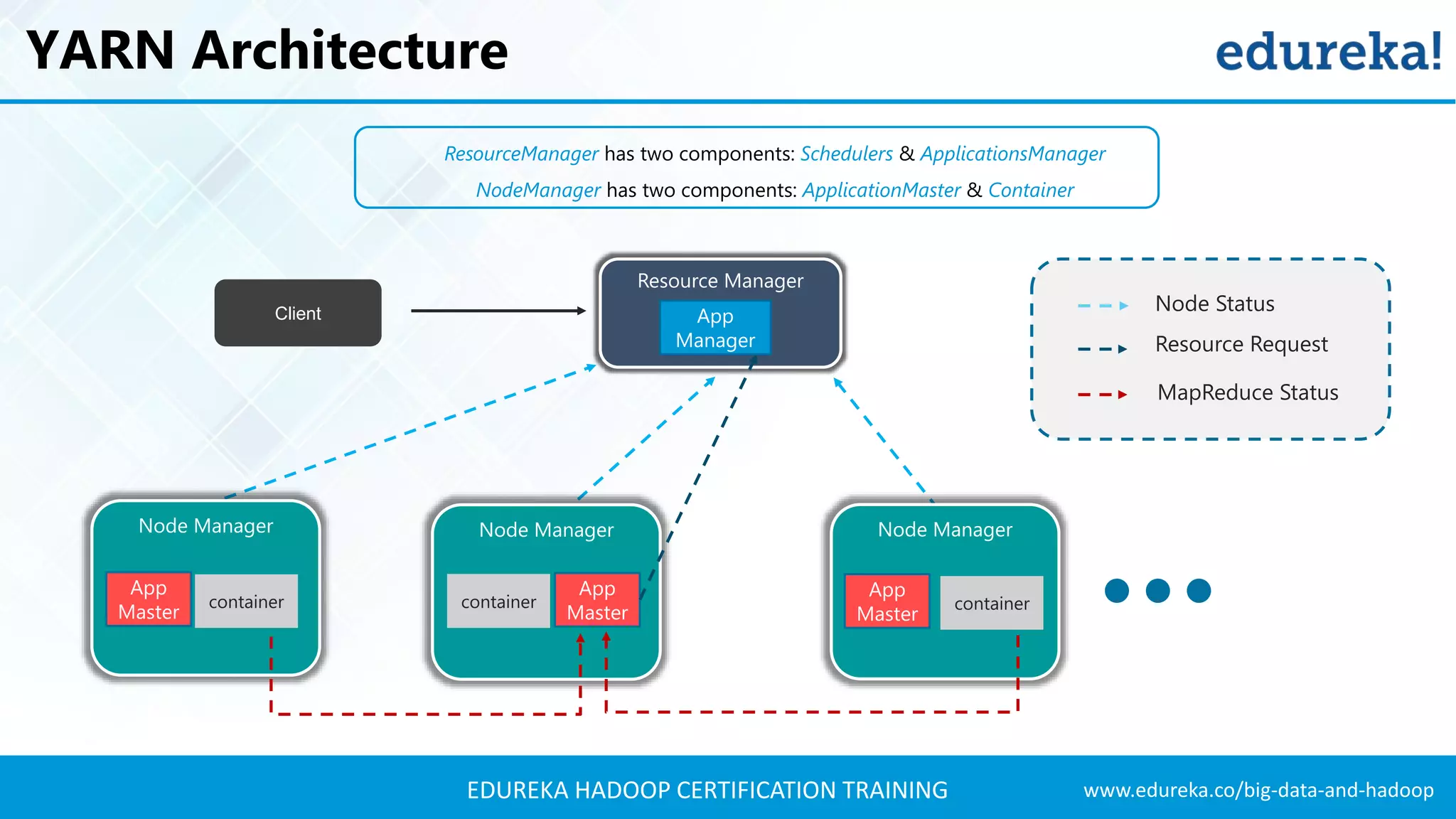
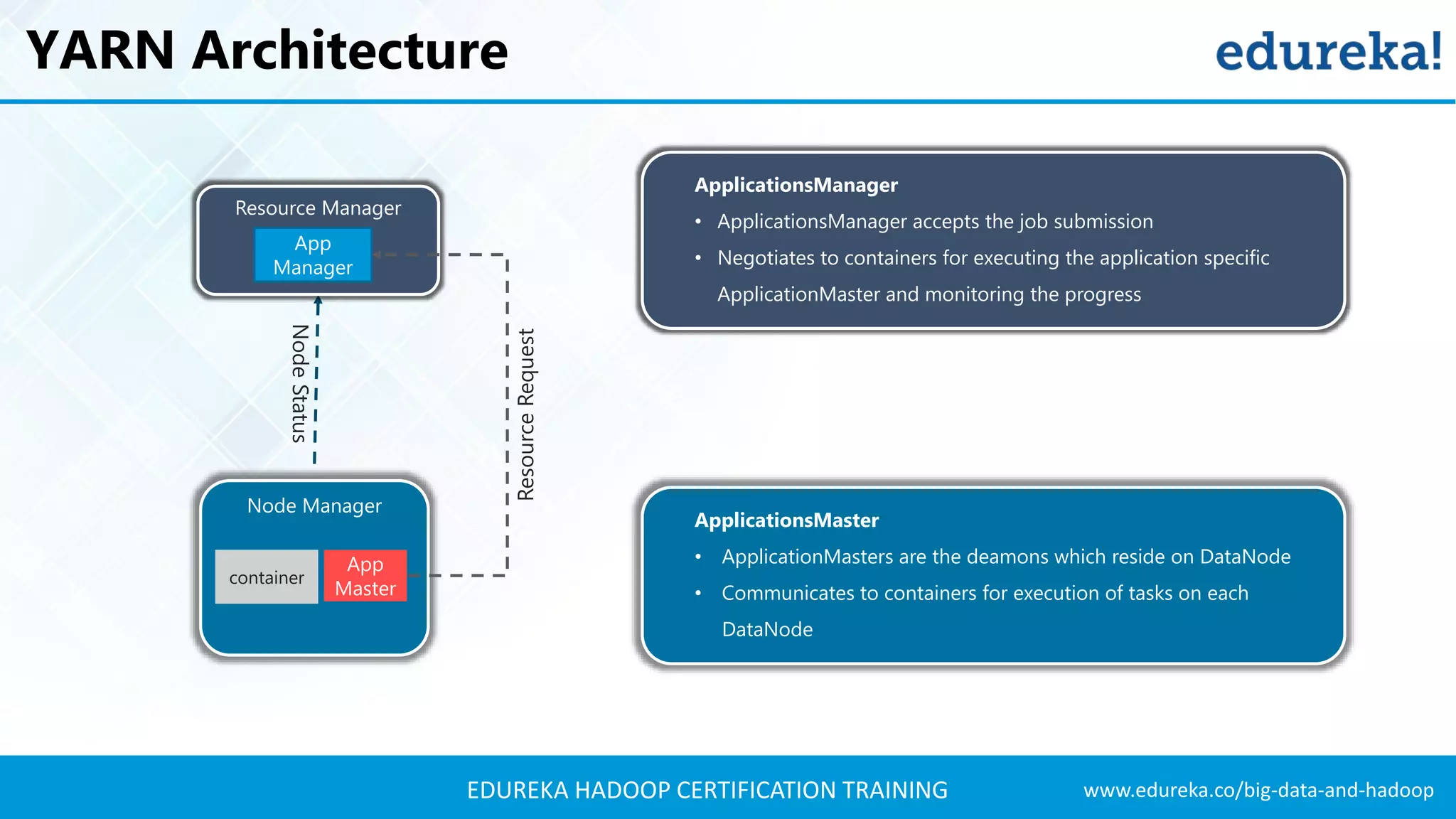

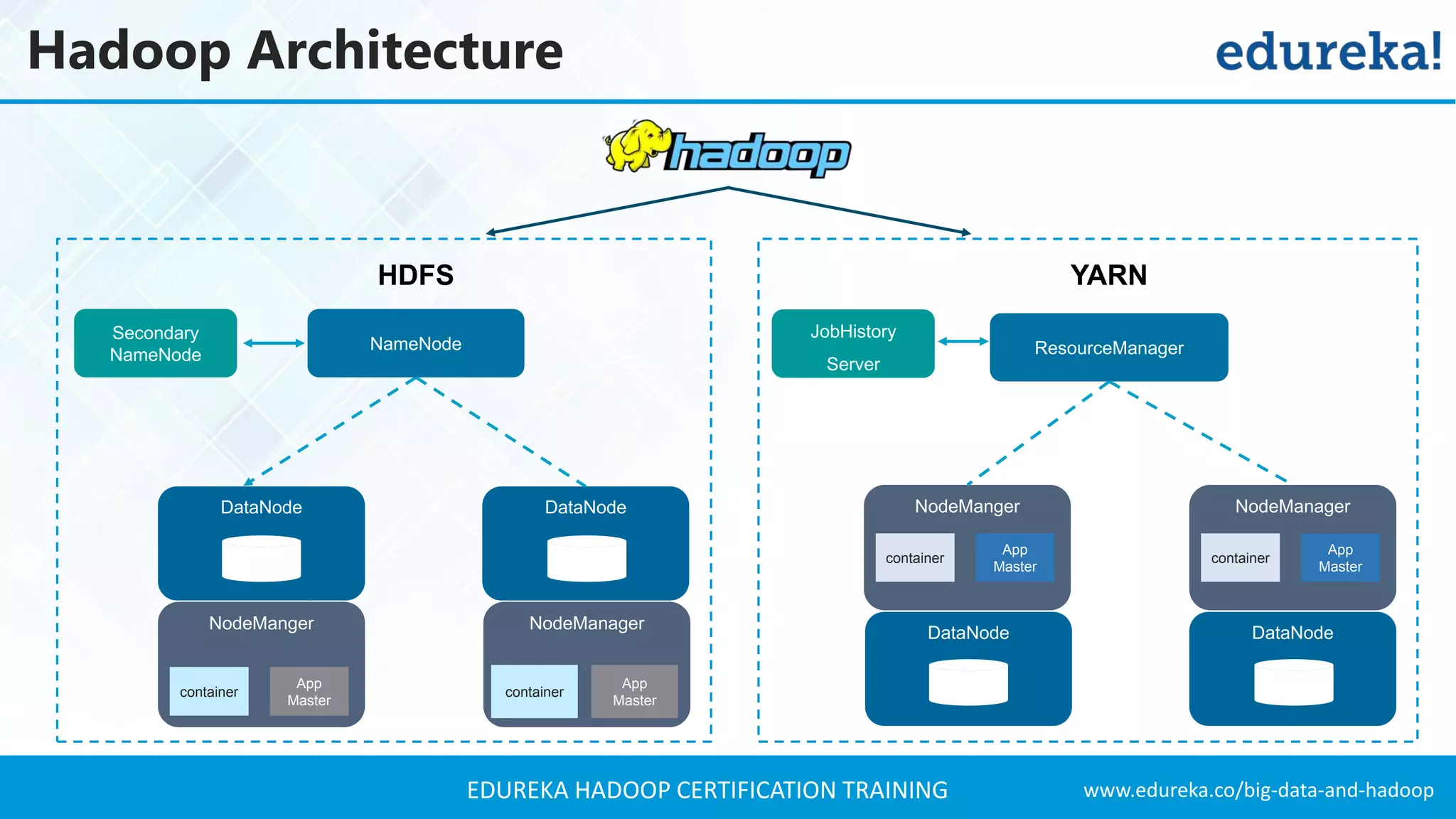

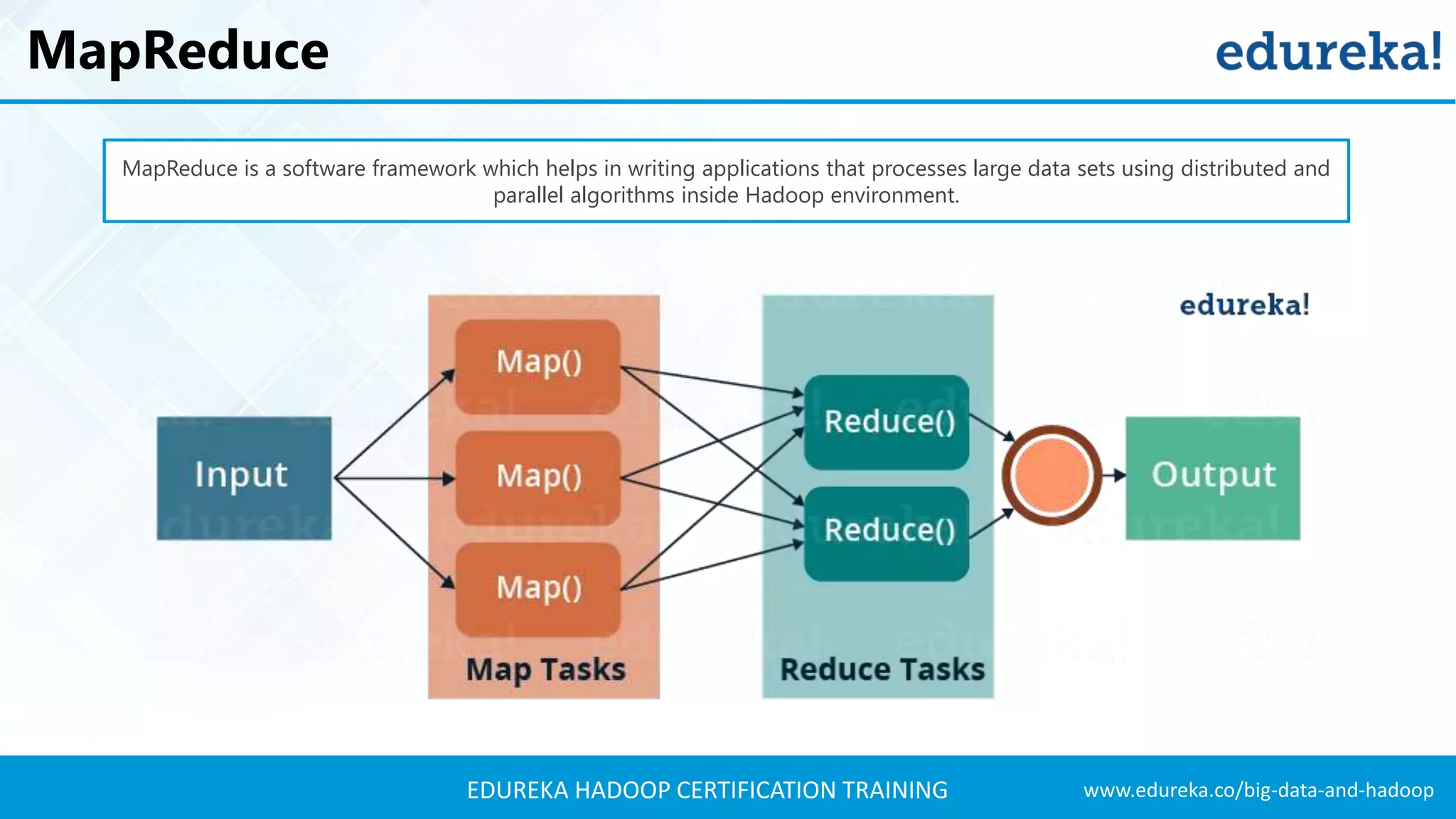
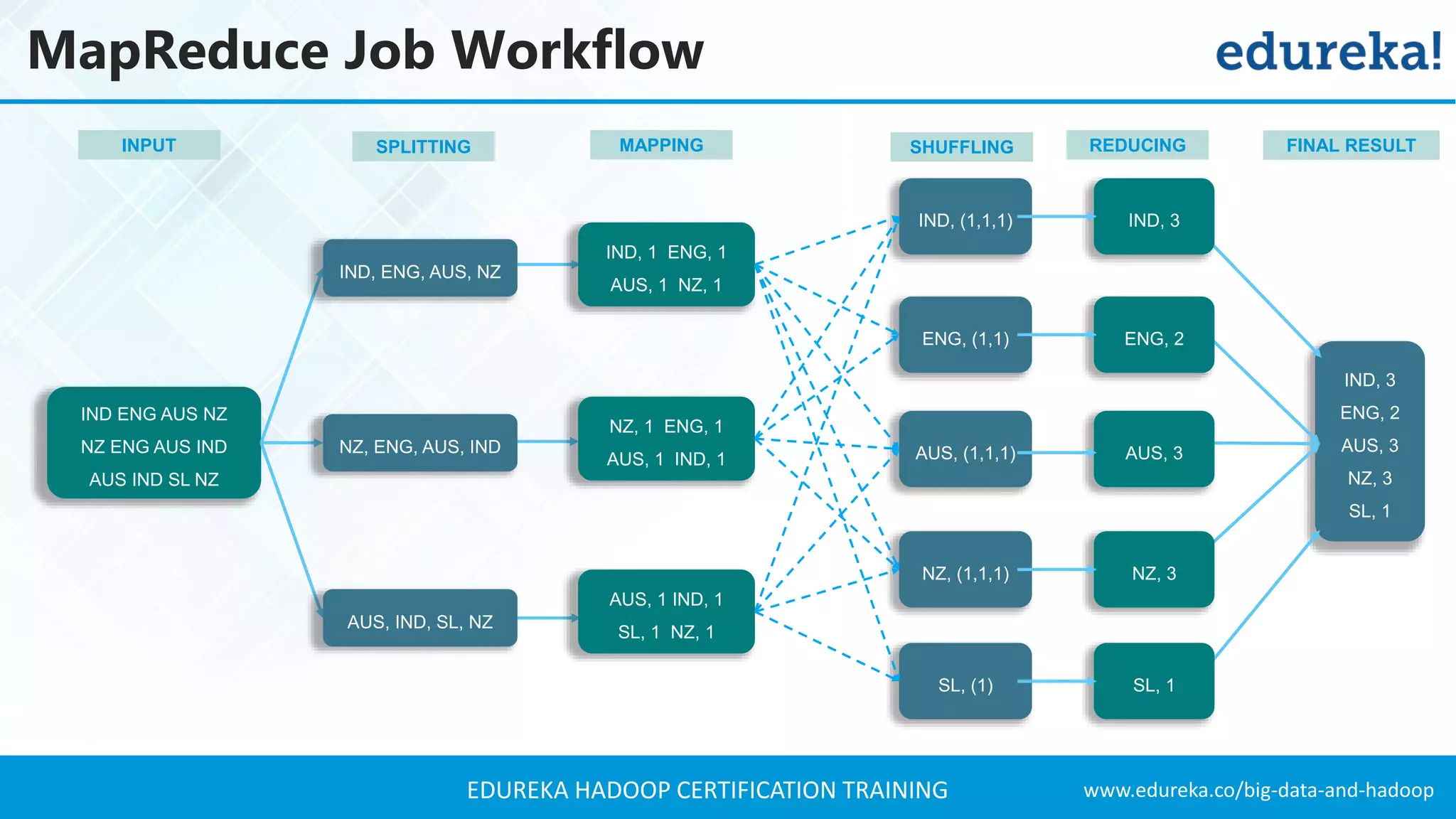

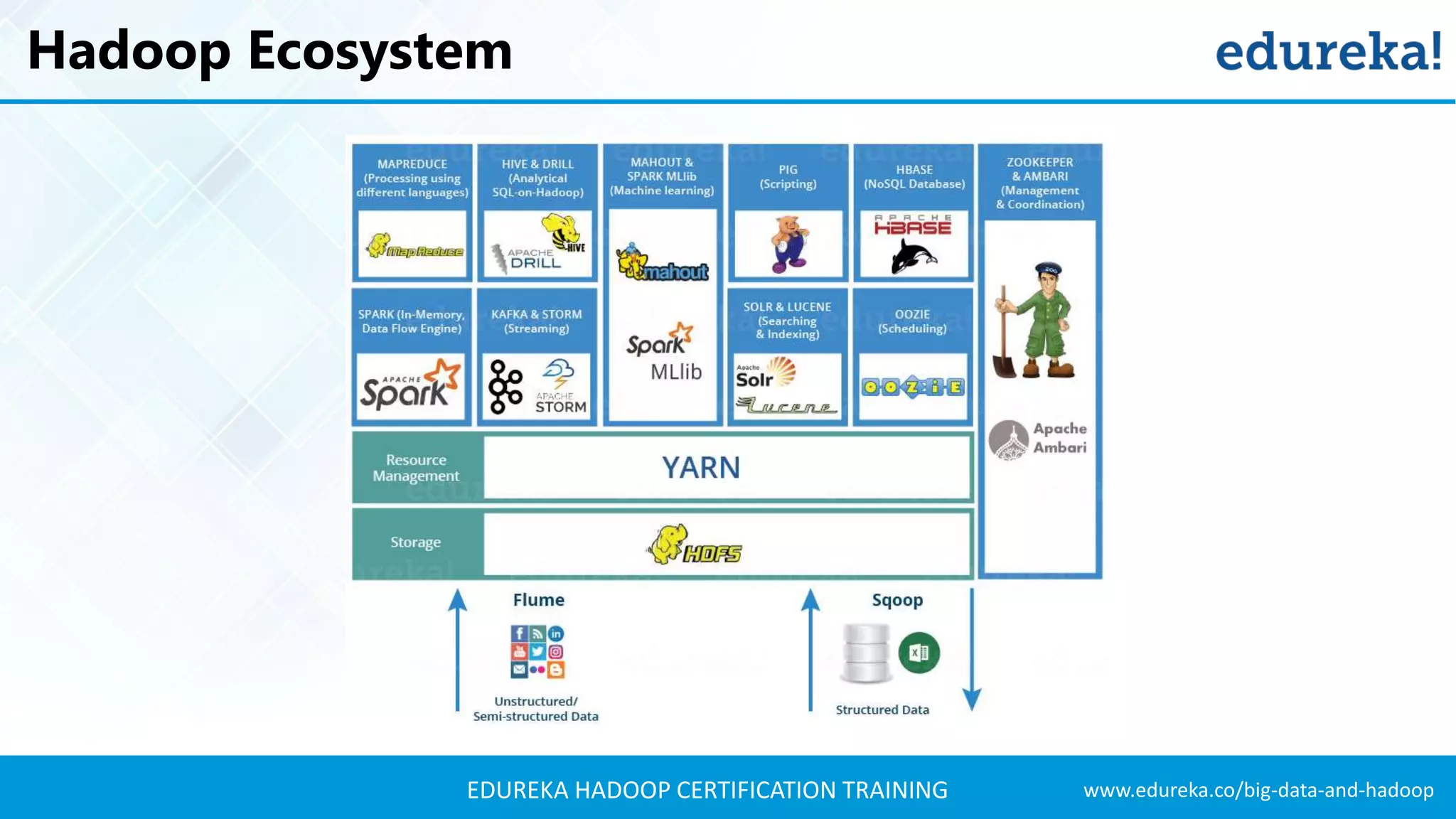


The document outlines the agenda for a Hadoop certification training, covering key concepts of big data, its problems, and Hadoop as a solution. It introduces Hadoop's architecture, including HDFS, YARN, and MapReduce, along with their functionalities for processing large datasets. Additionally, it details the Hadoop ecosystem, emphasizing the need for effective data management and processing in today's rapidly growing data landscape.