


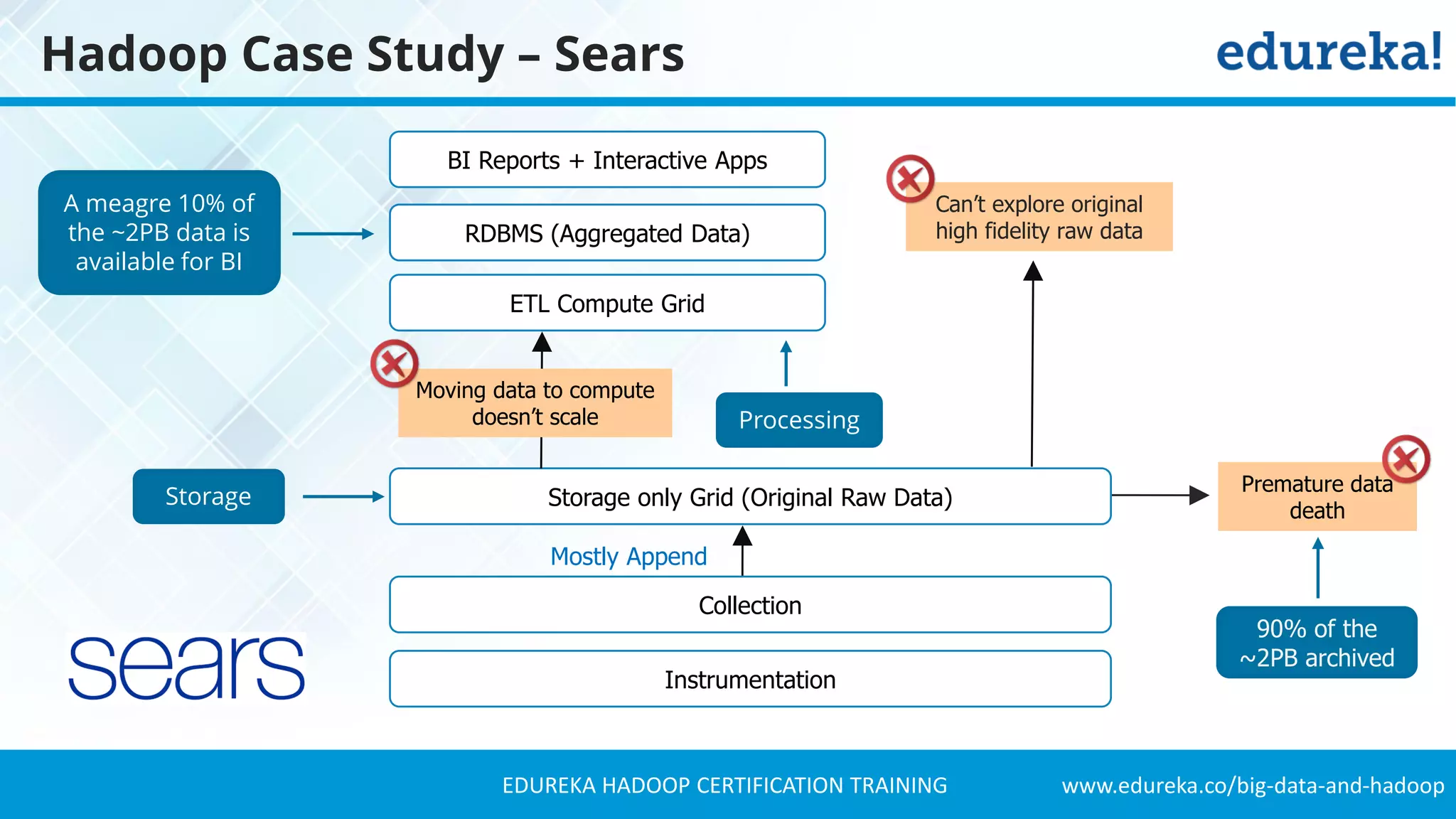
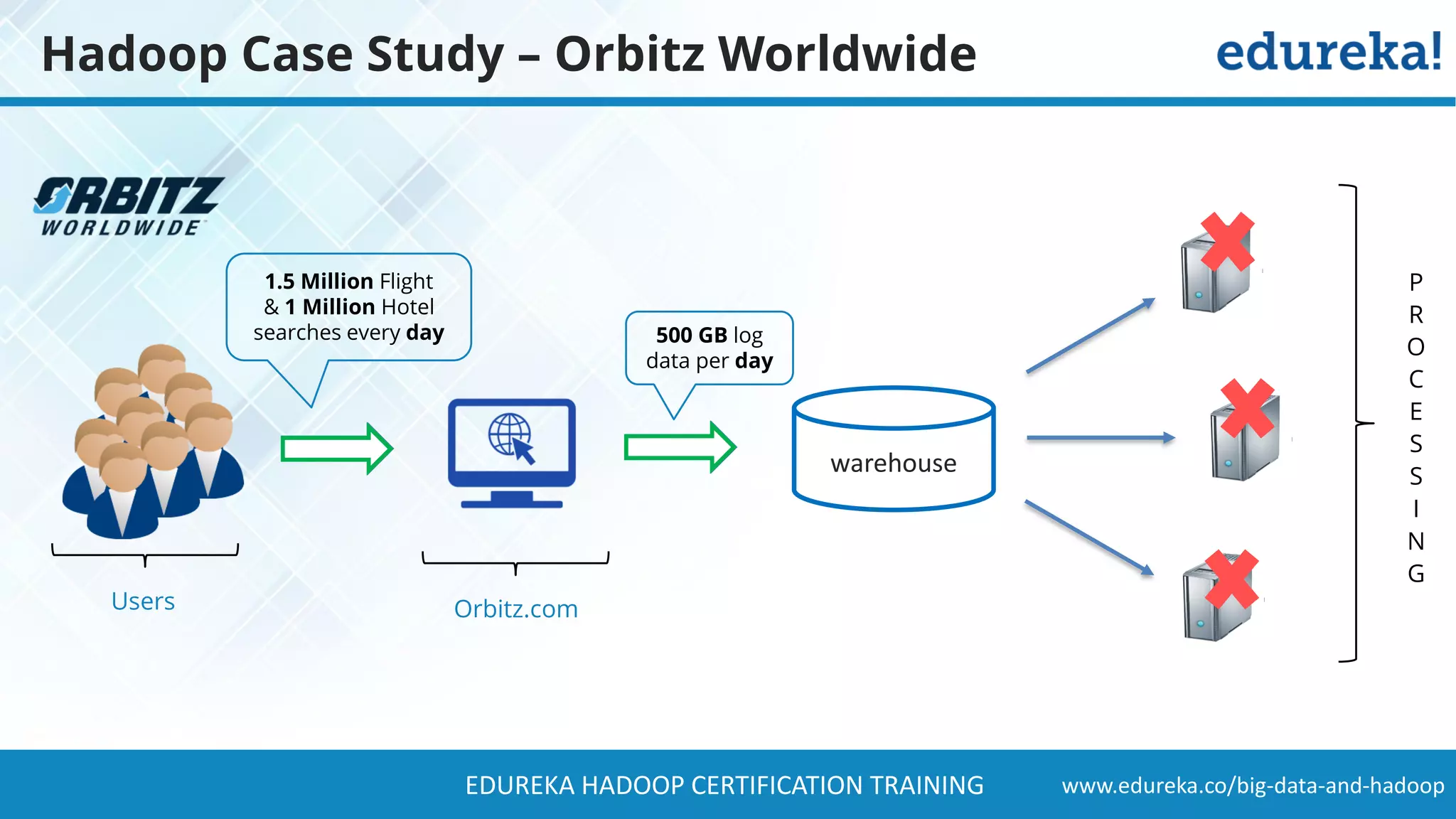


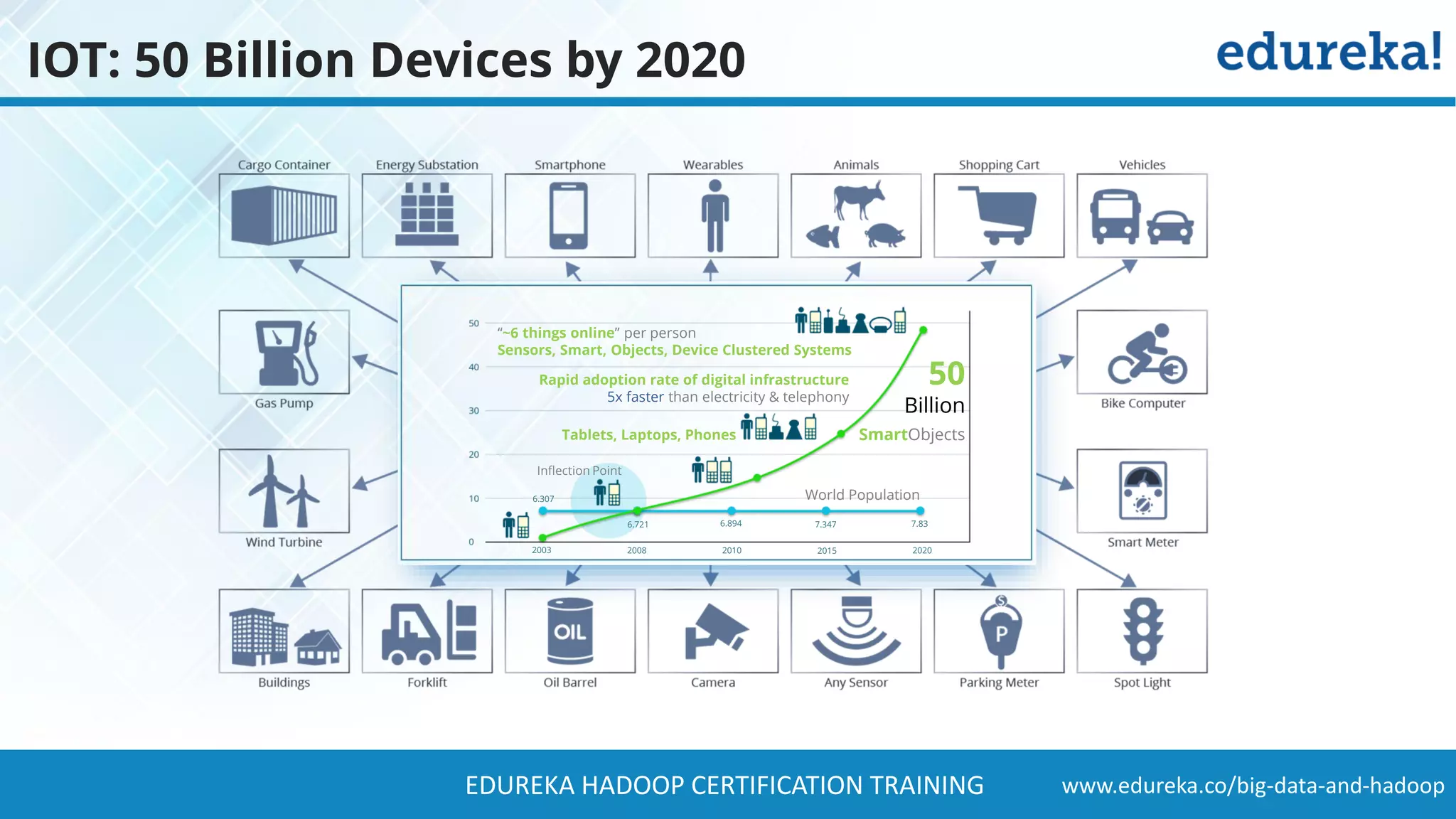




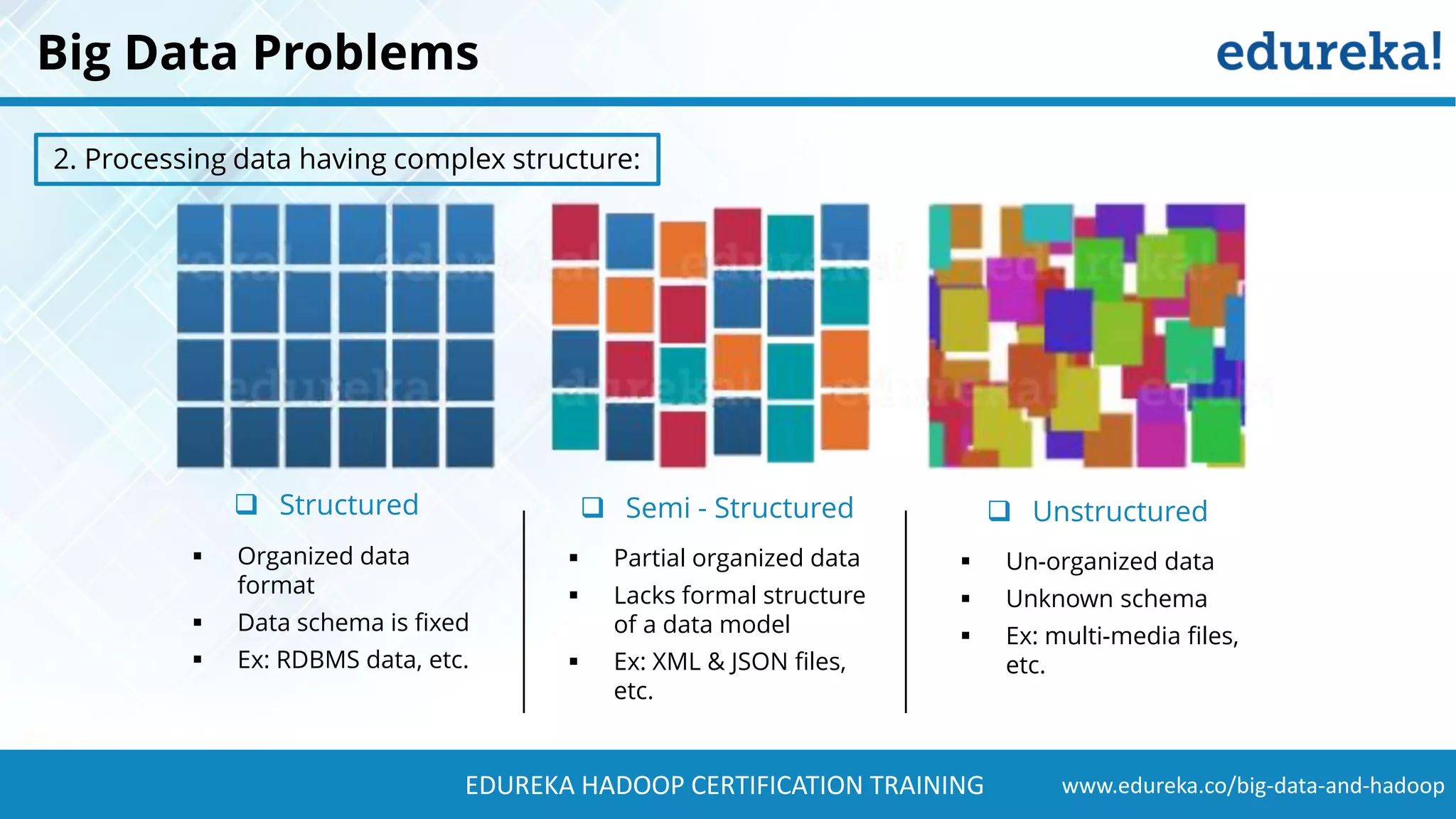
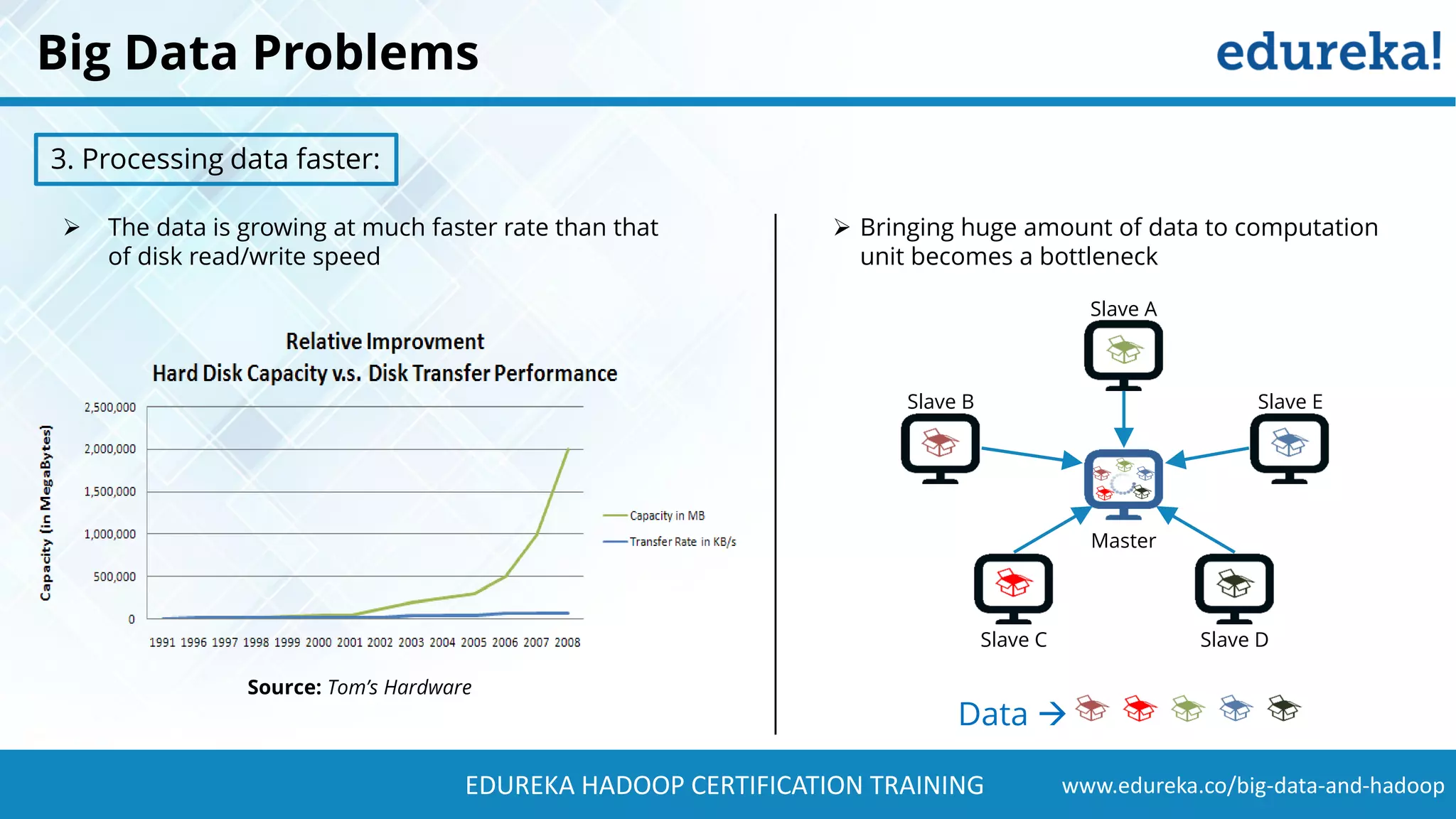

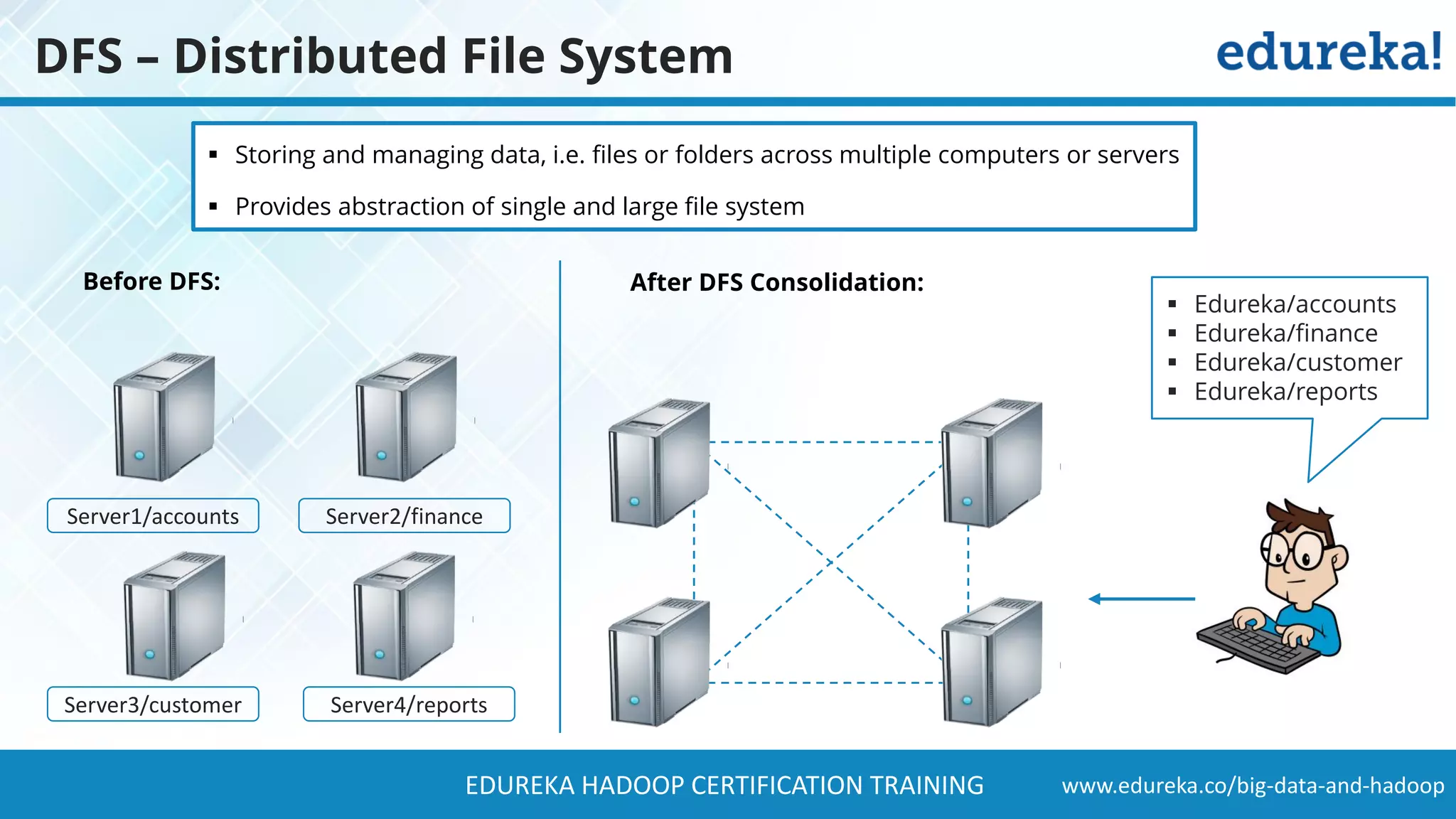




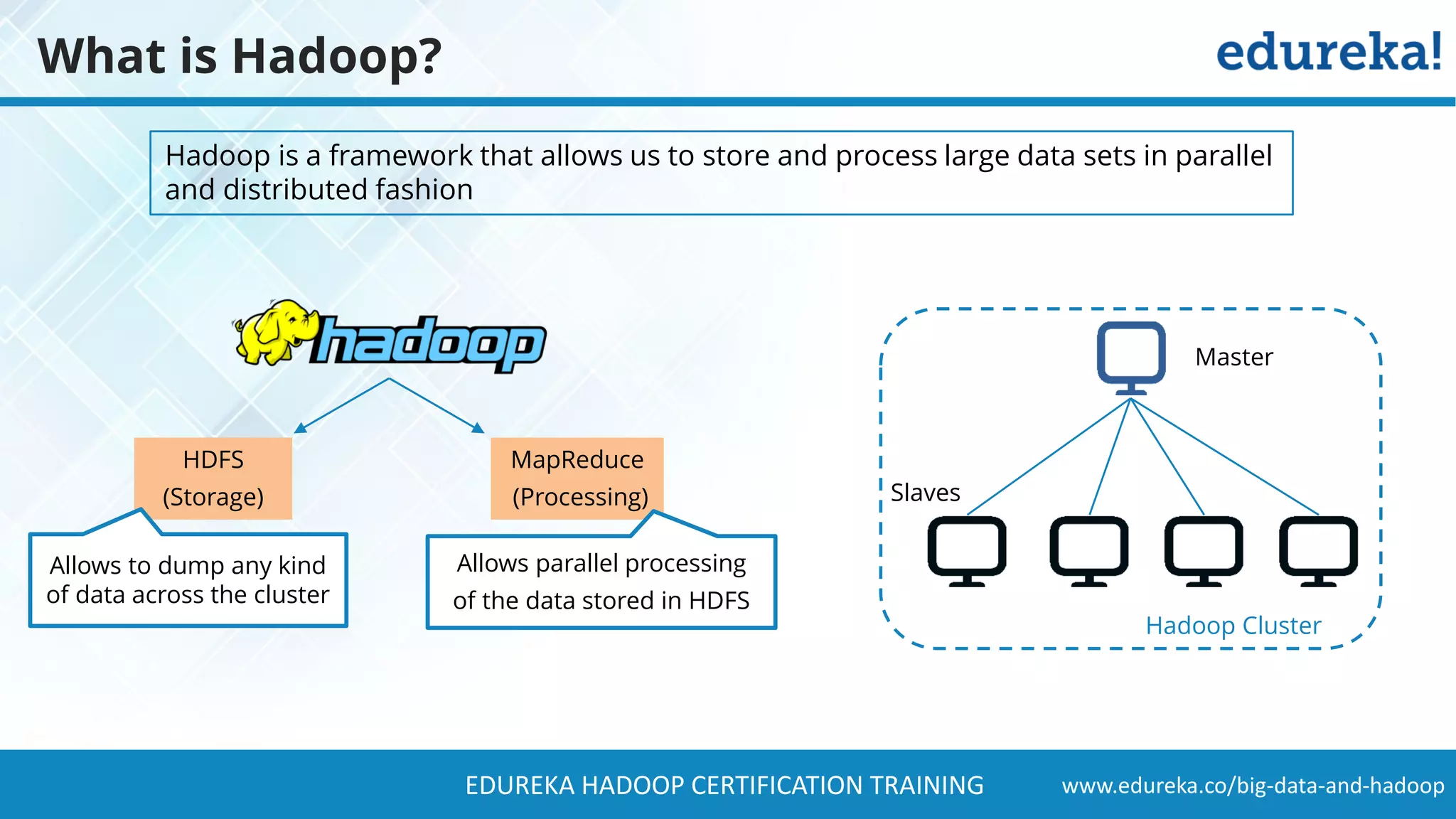

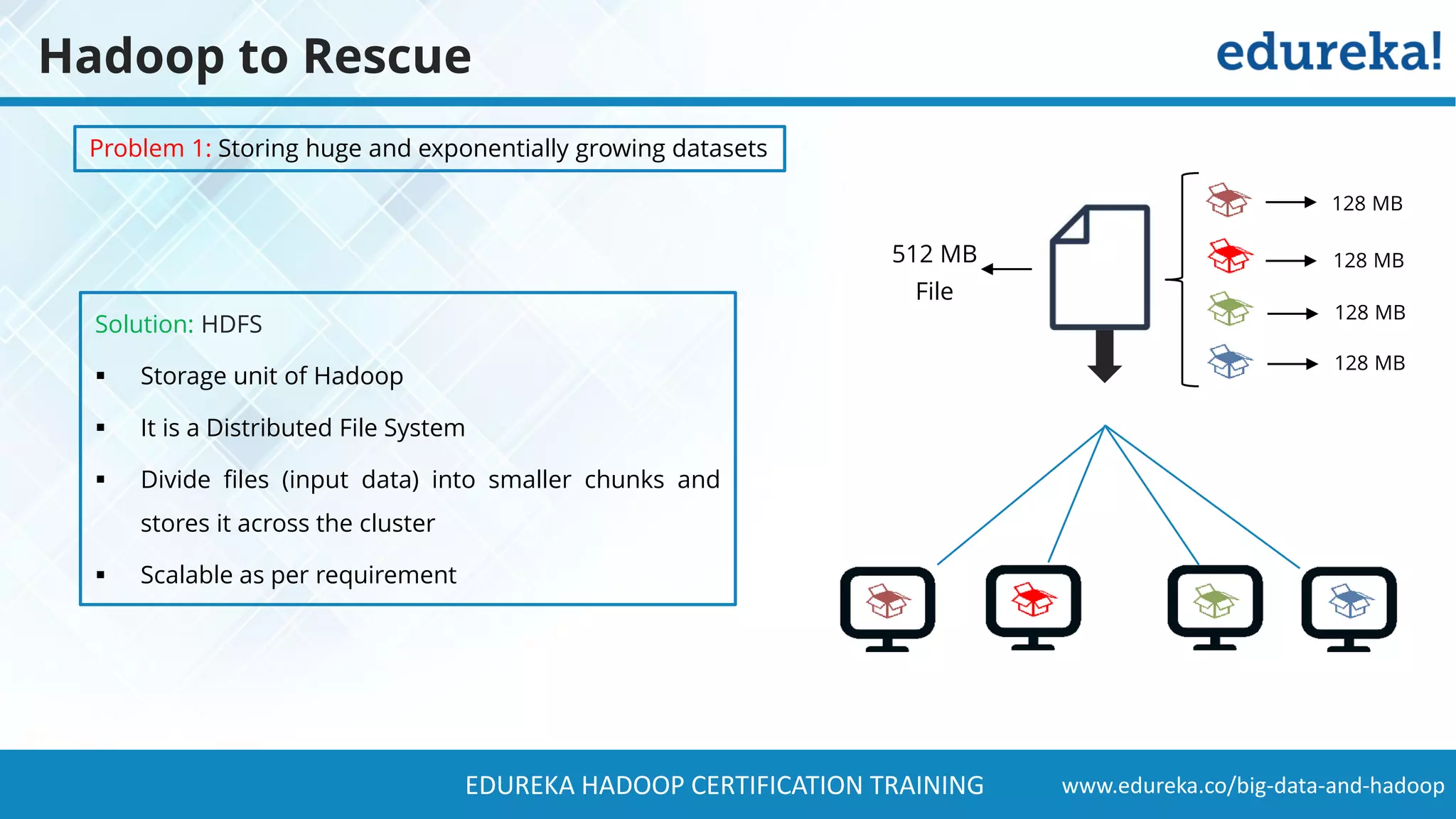
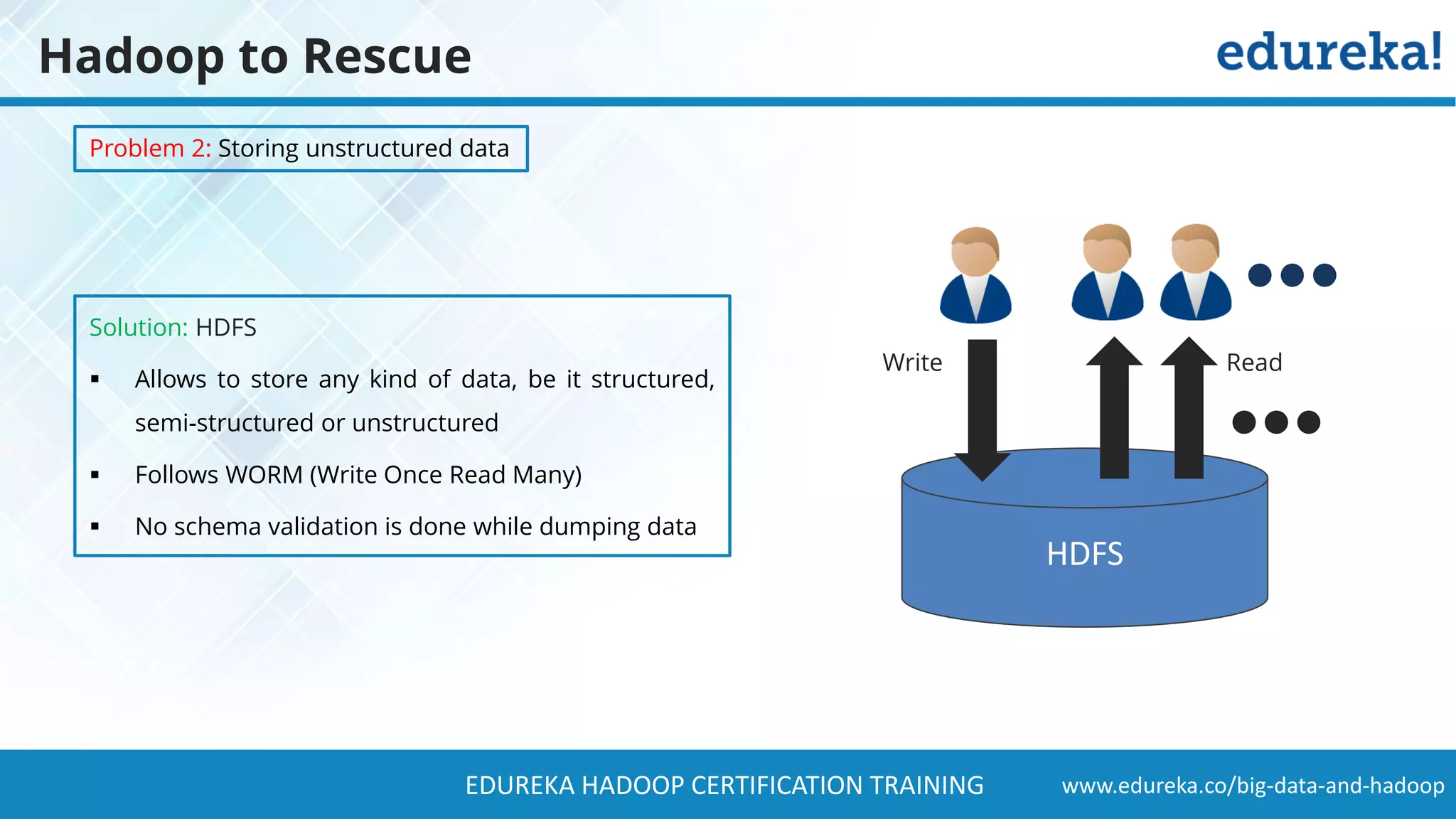
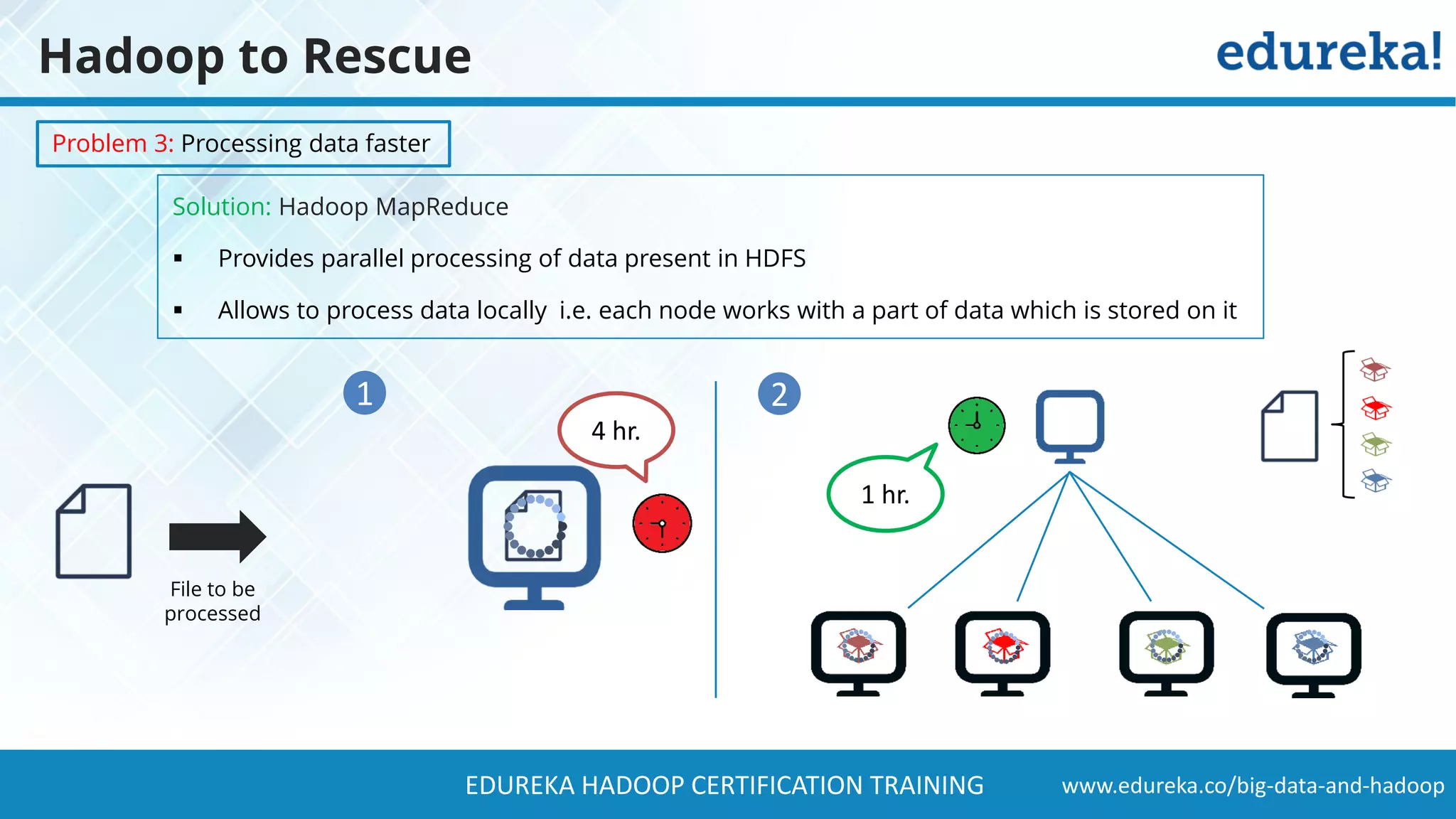

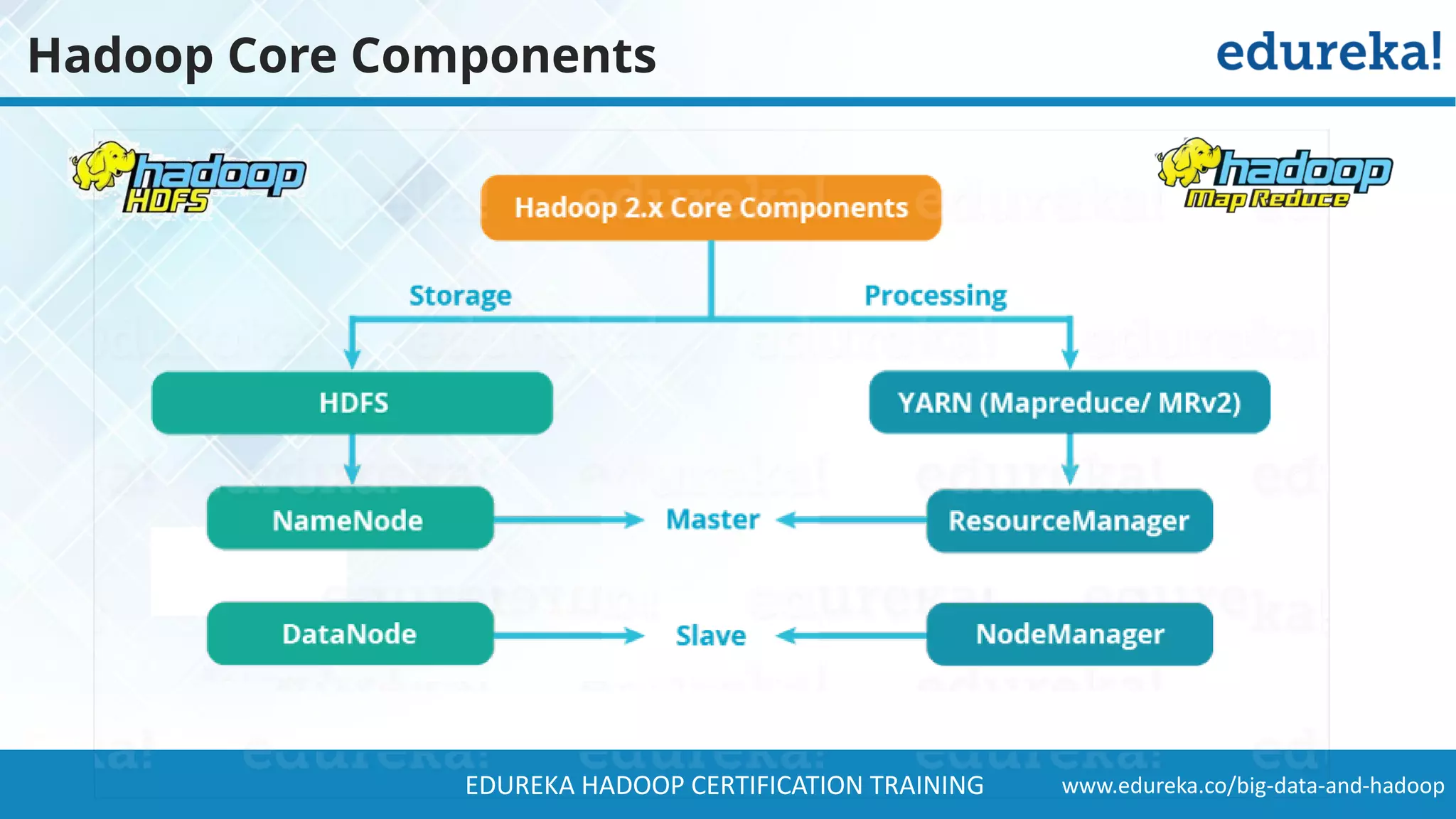



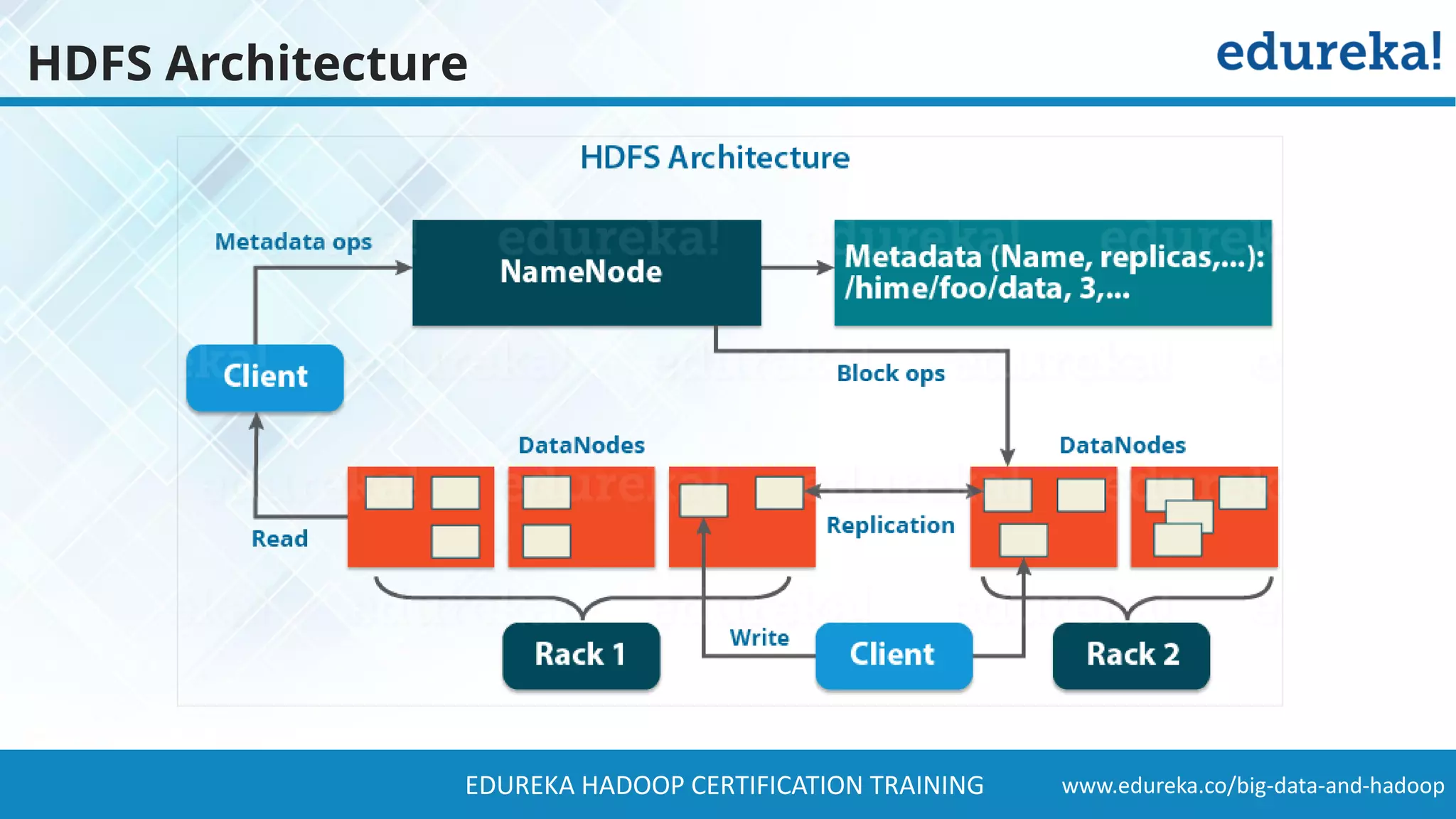





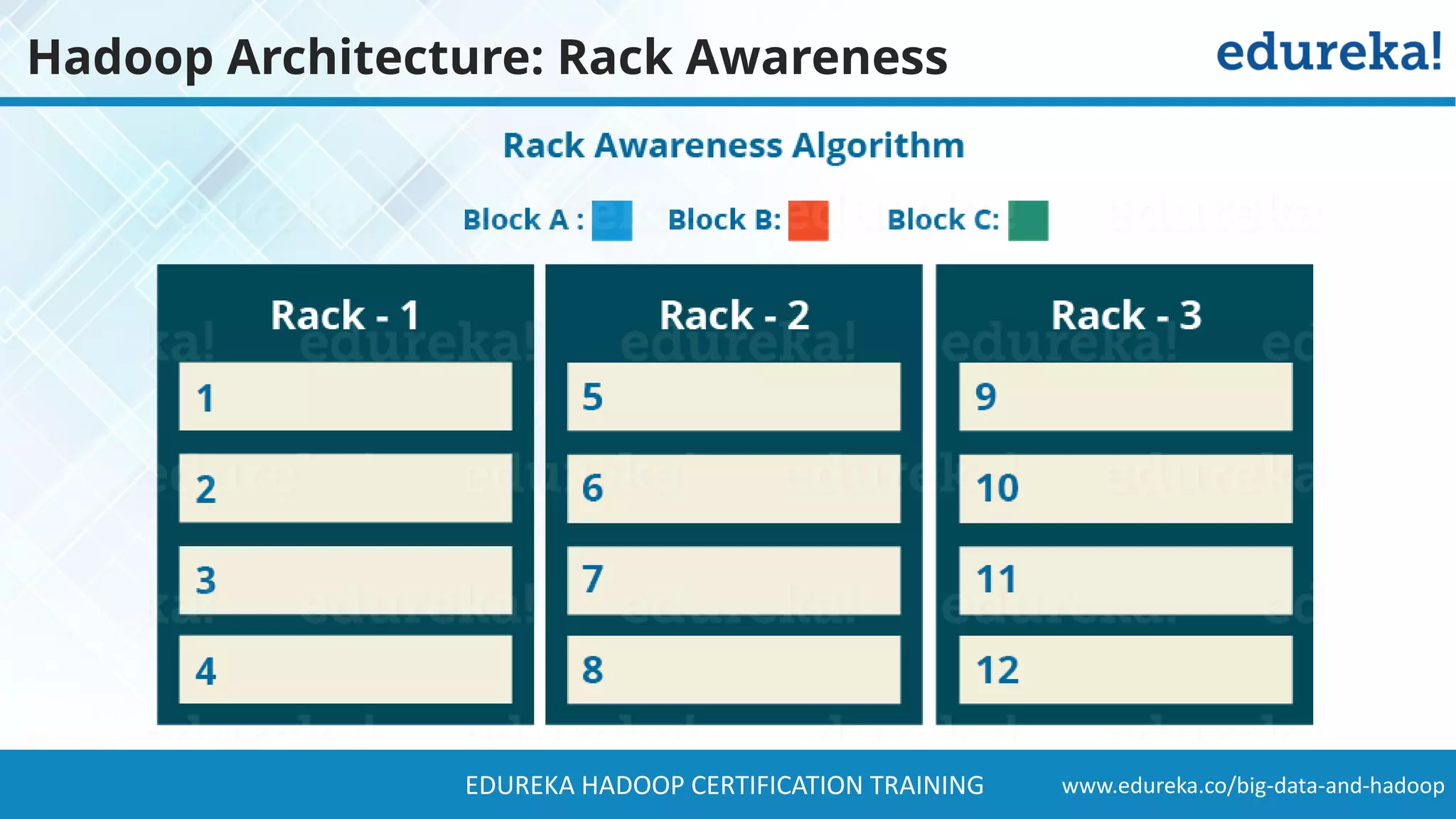







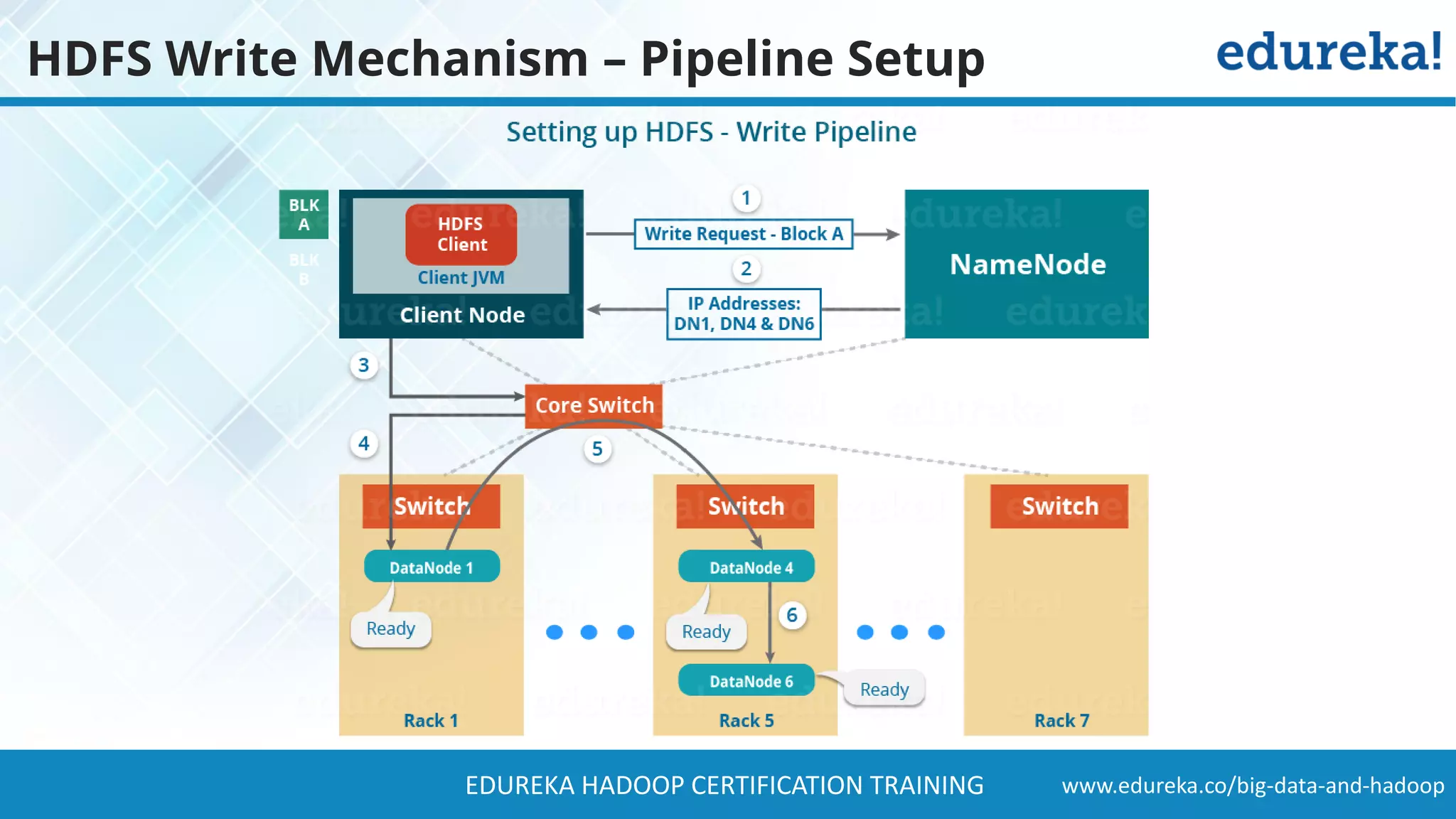
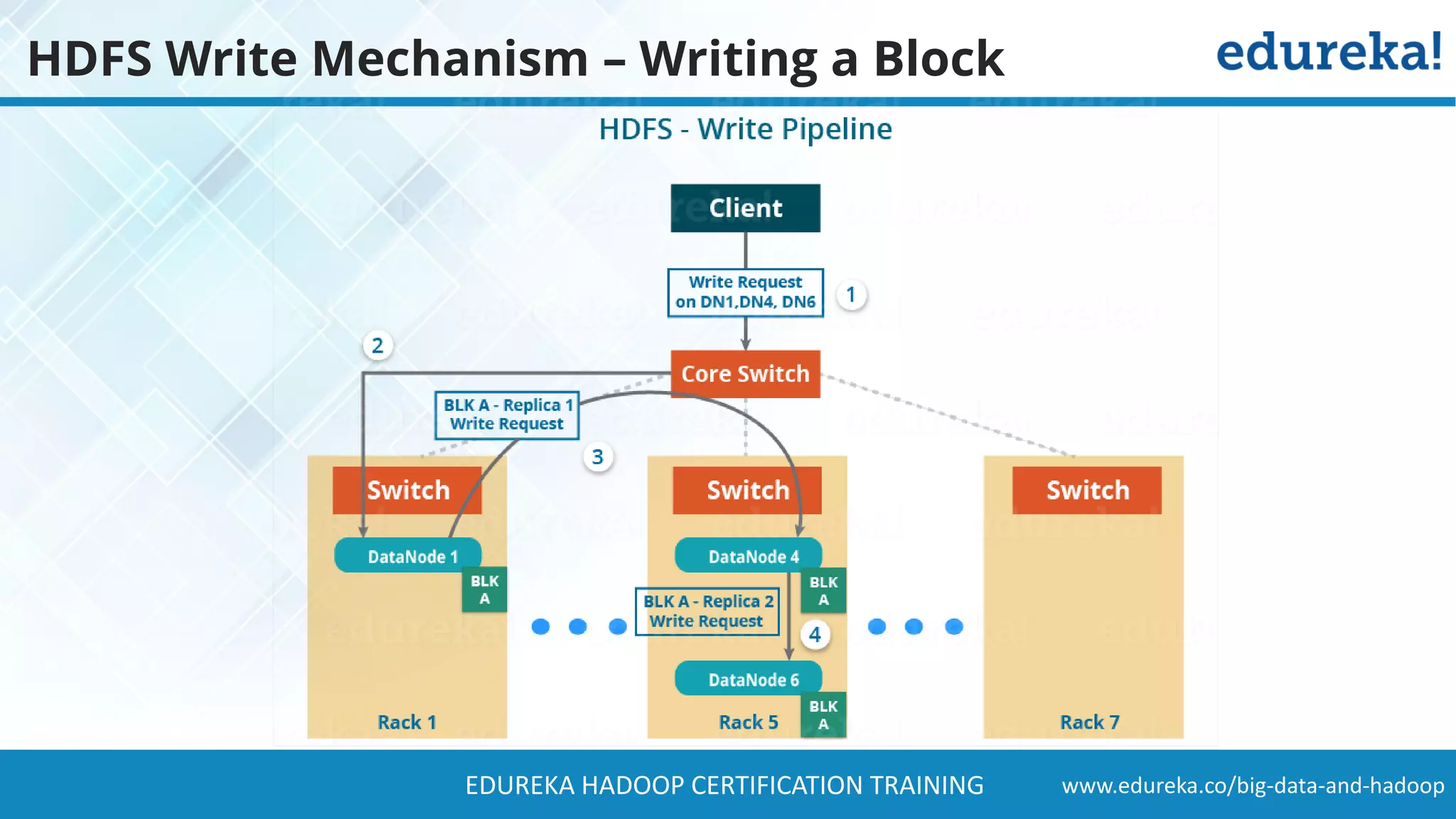
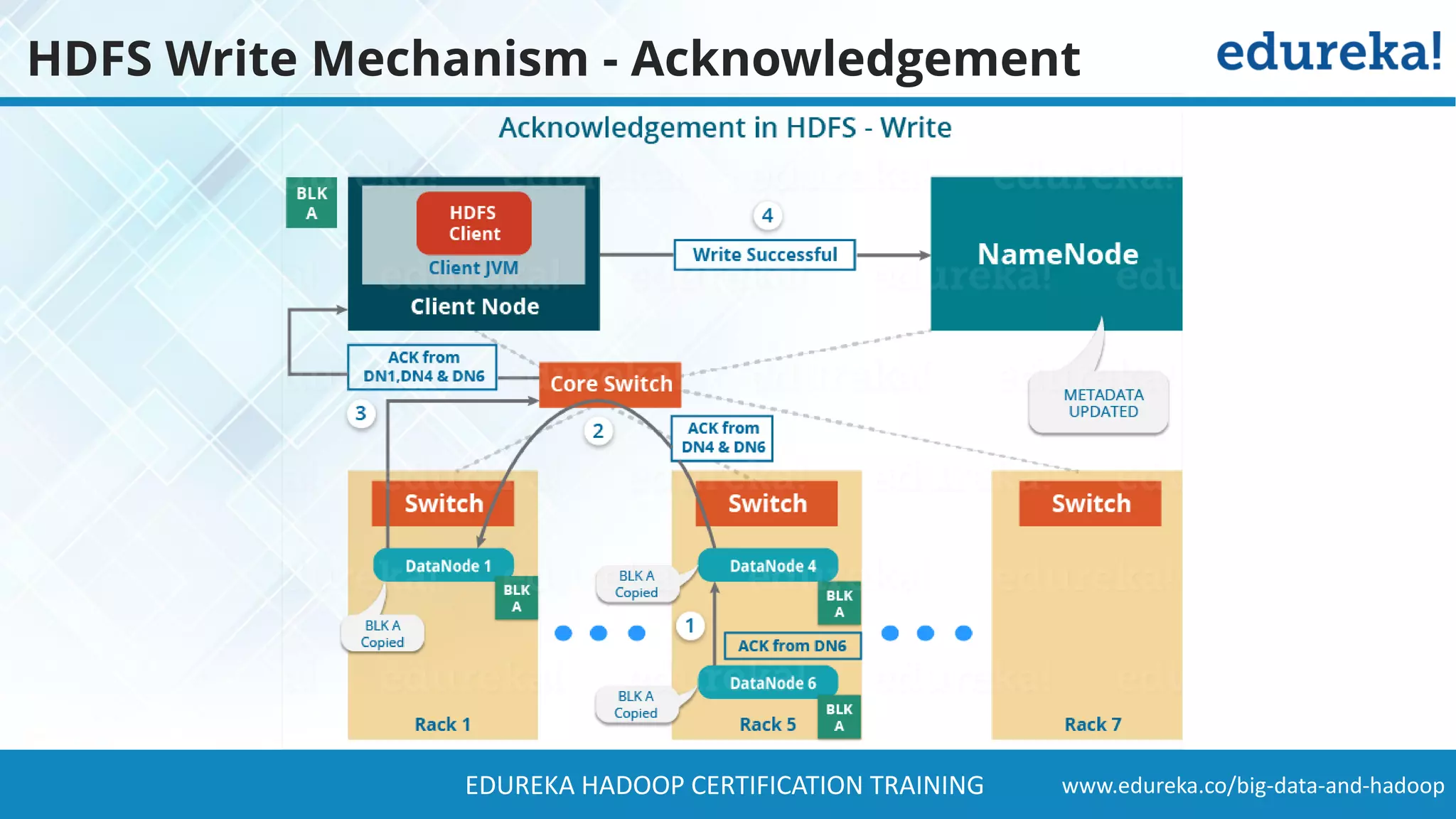
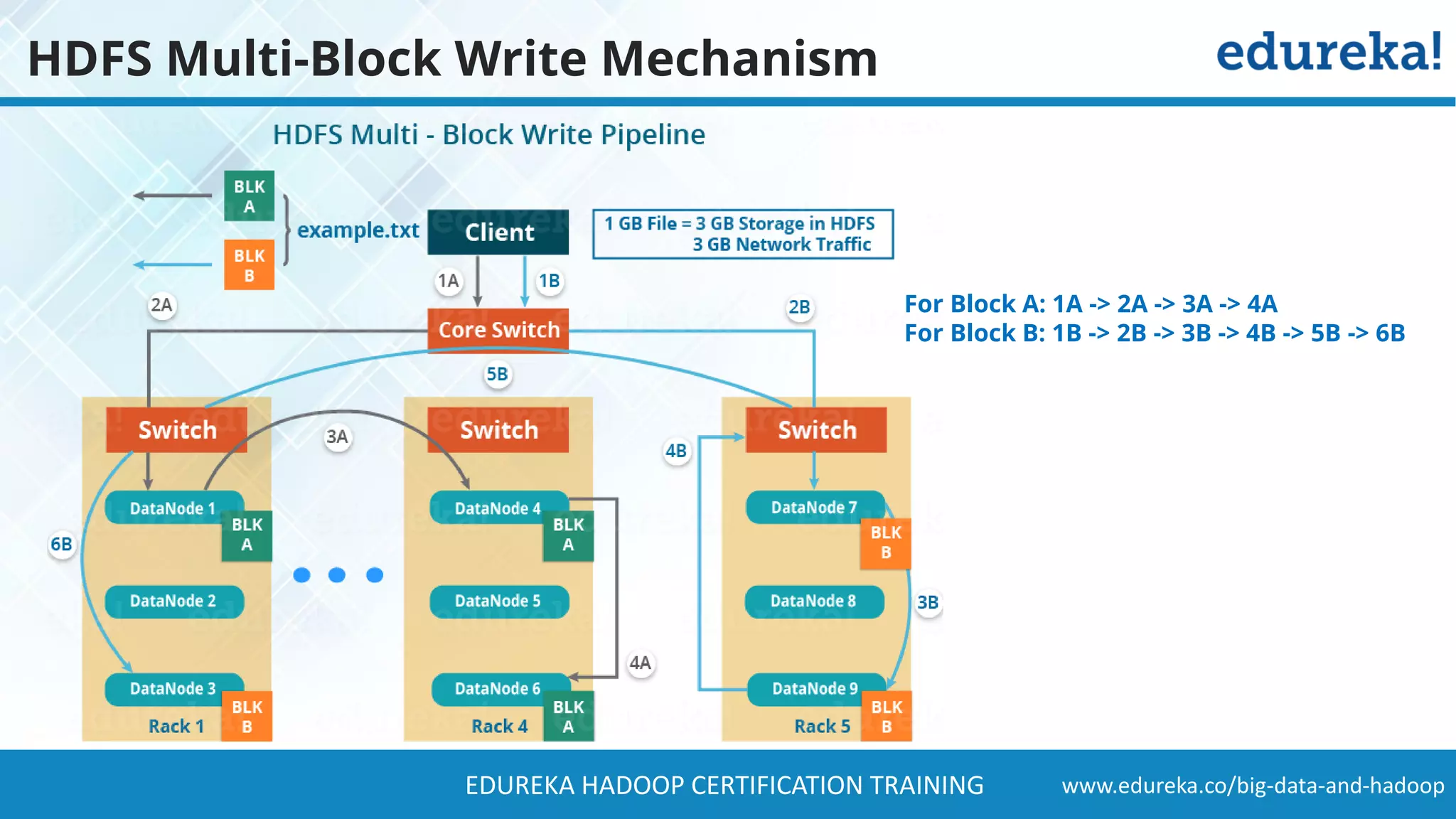
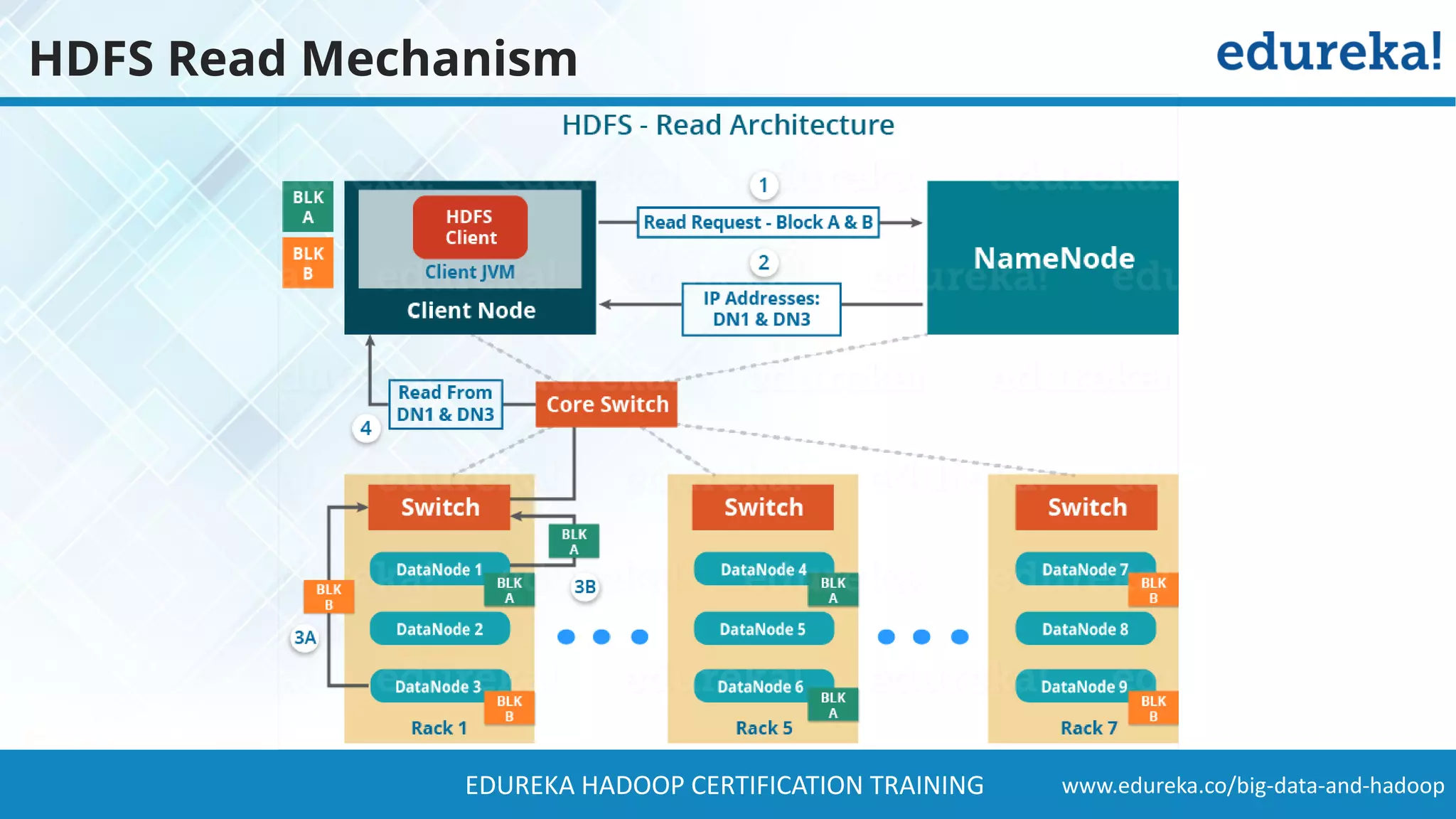

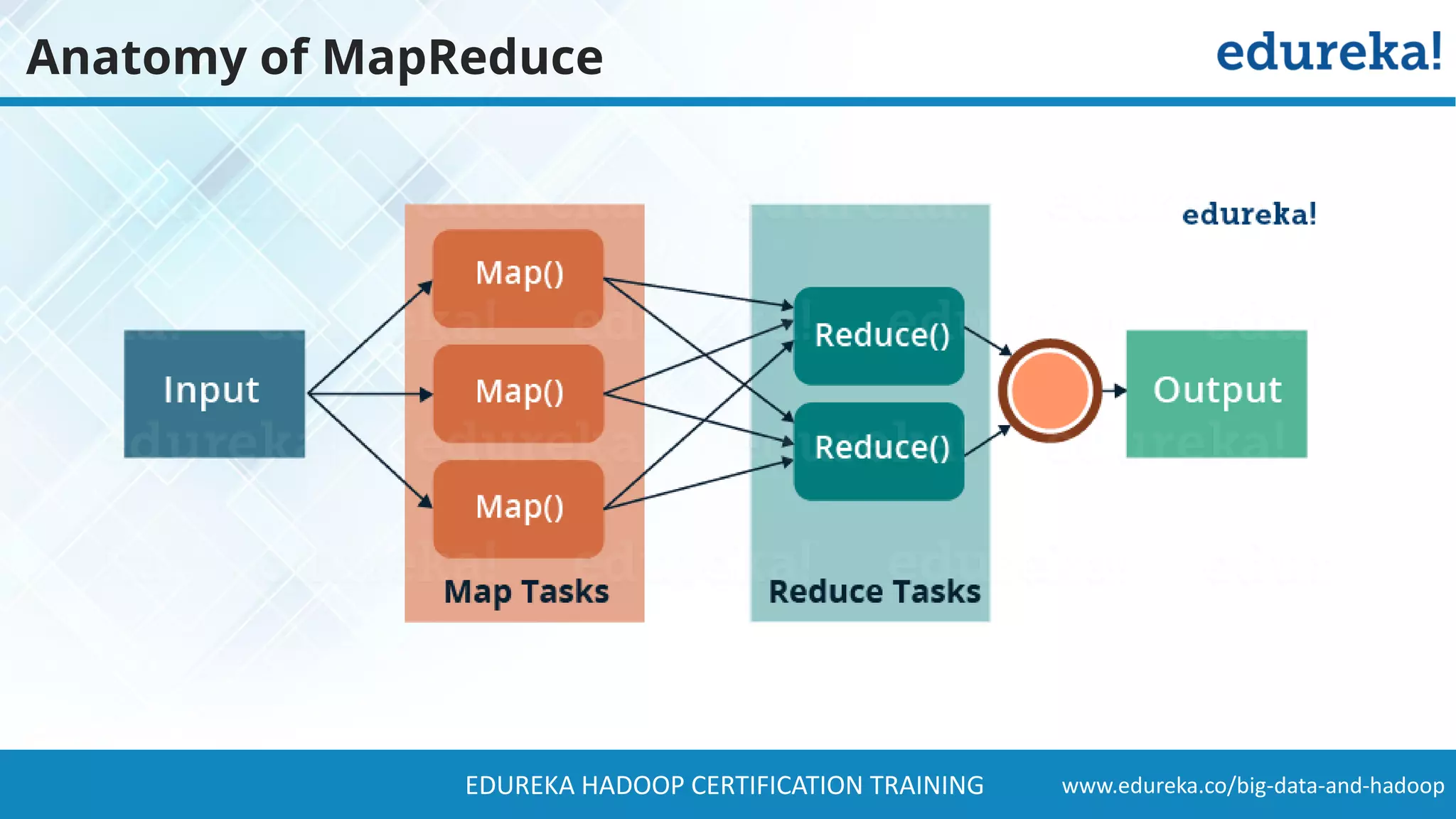

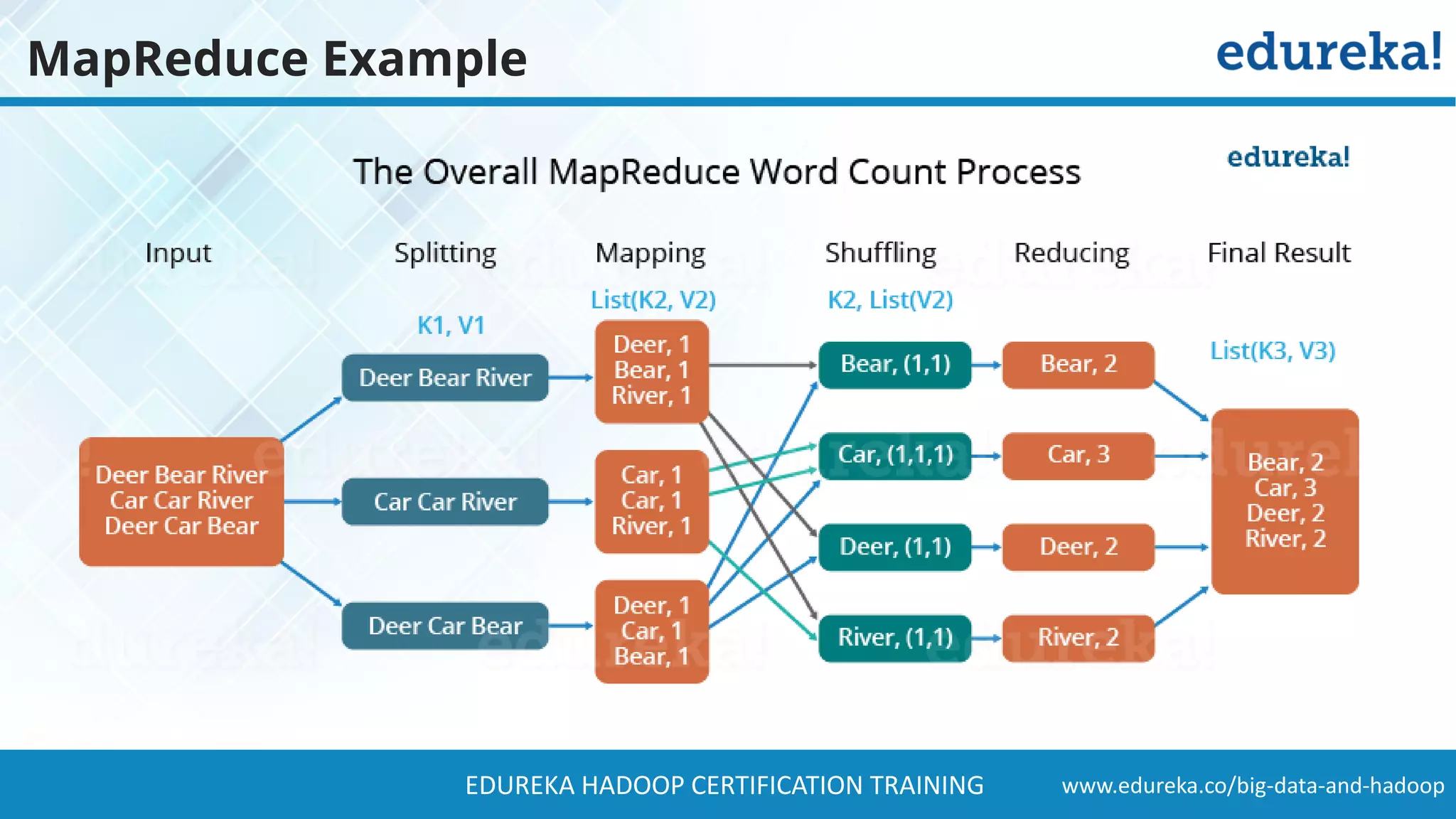



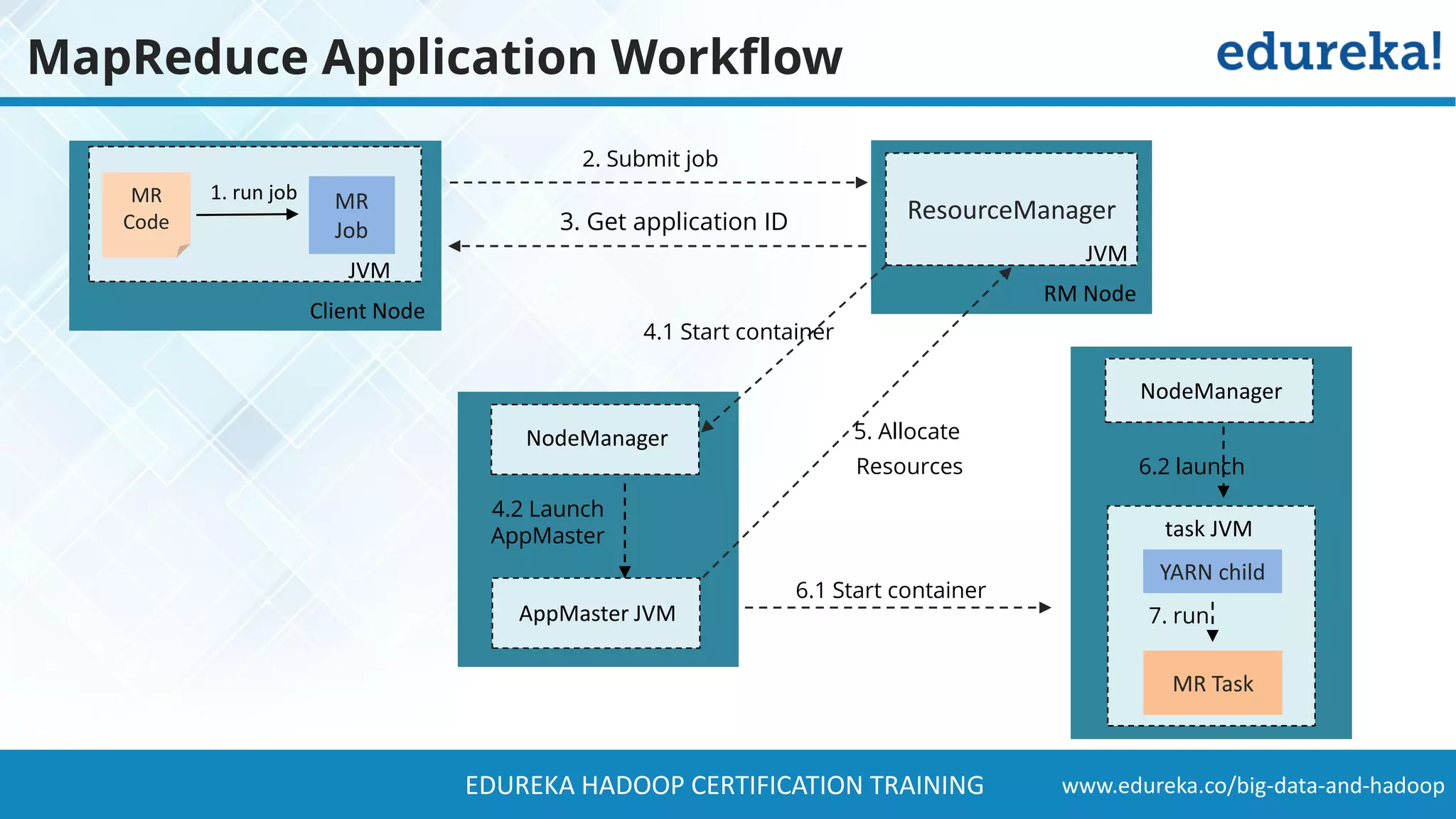
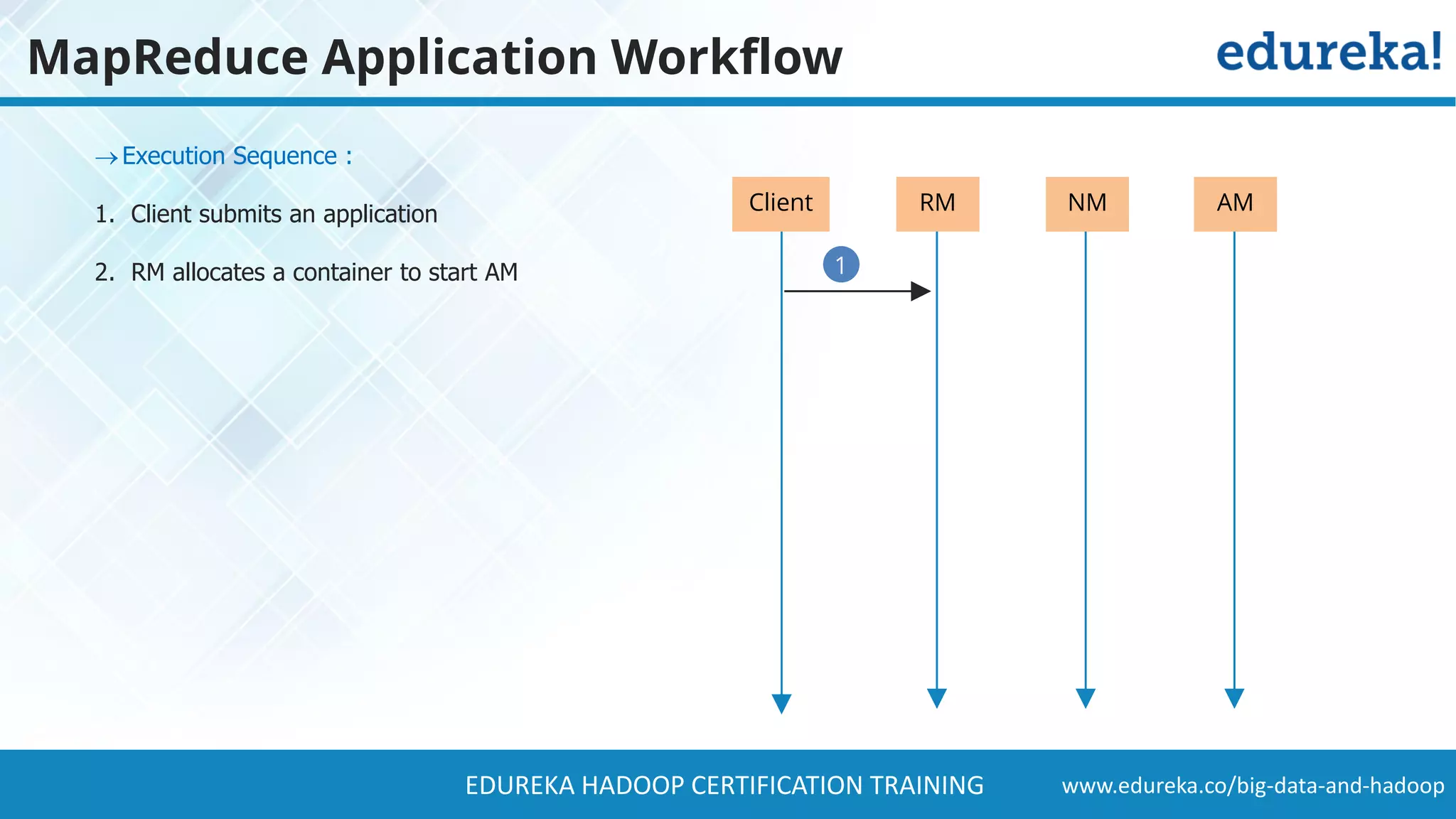
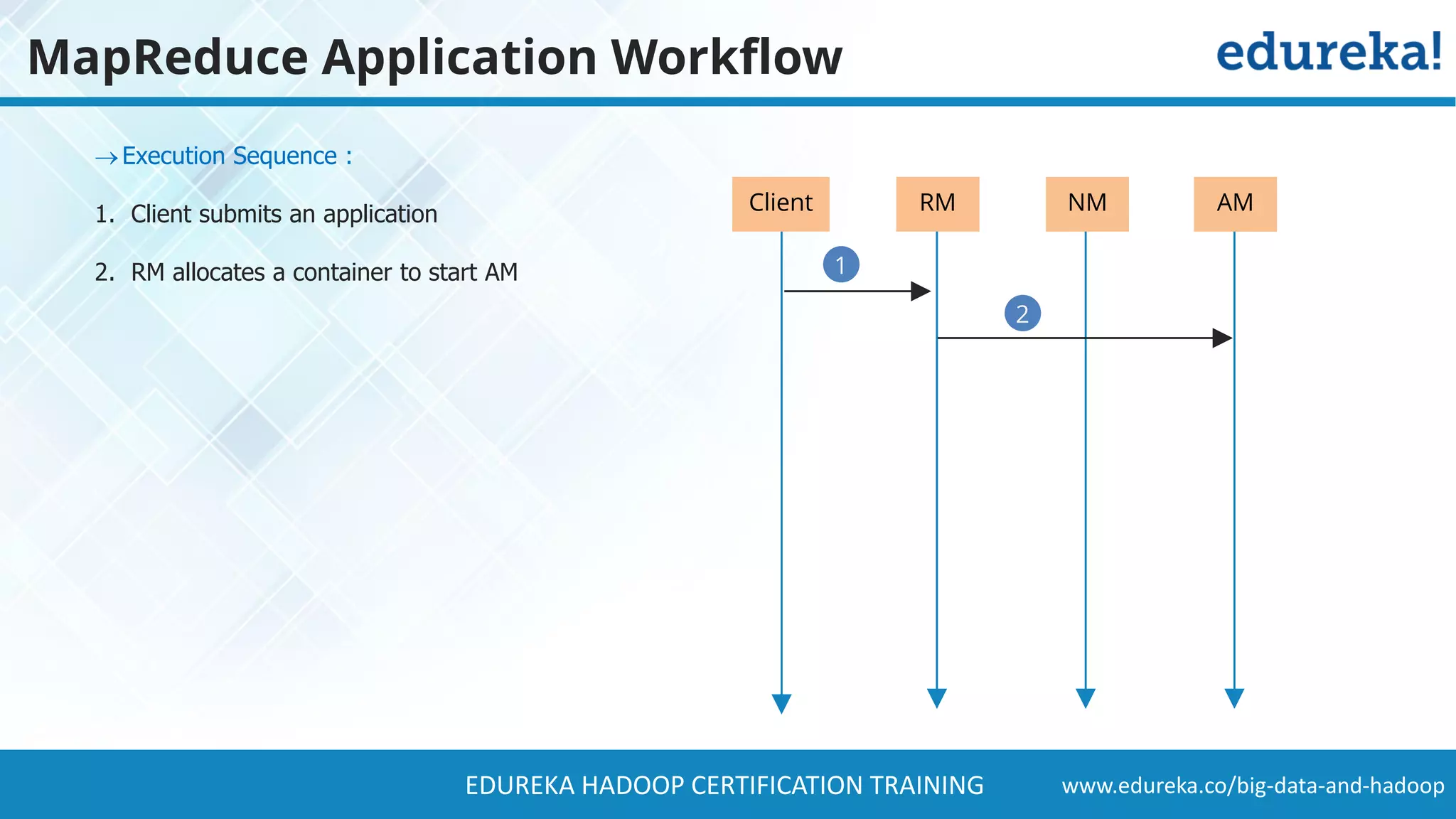
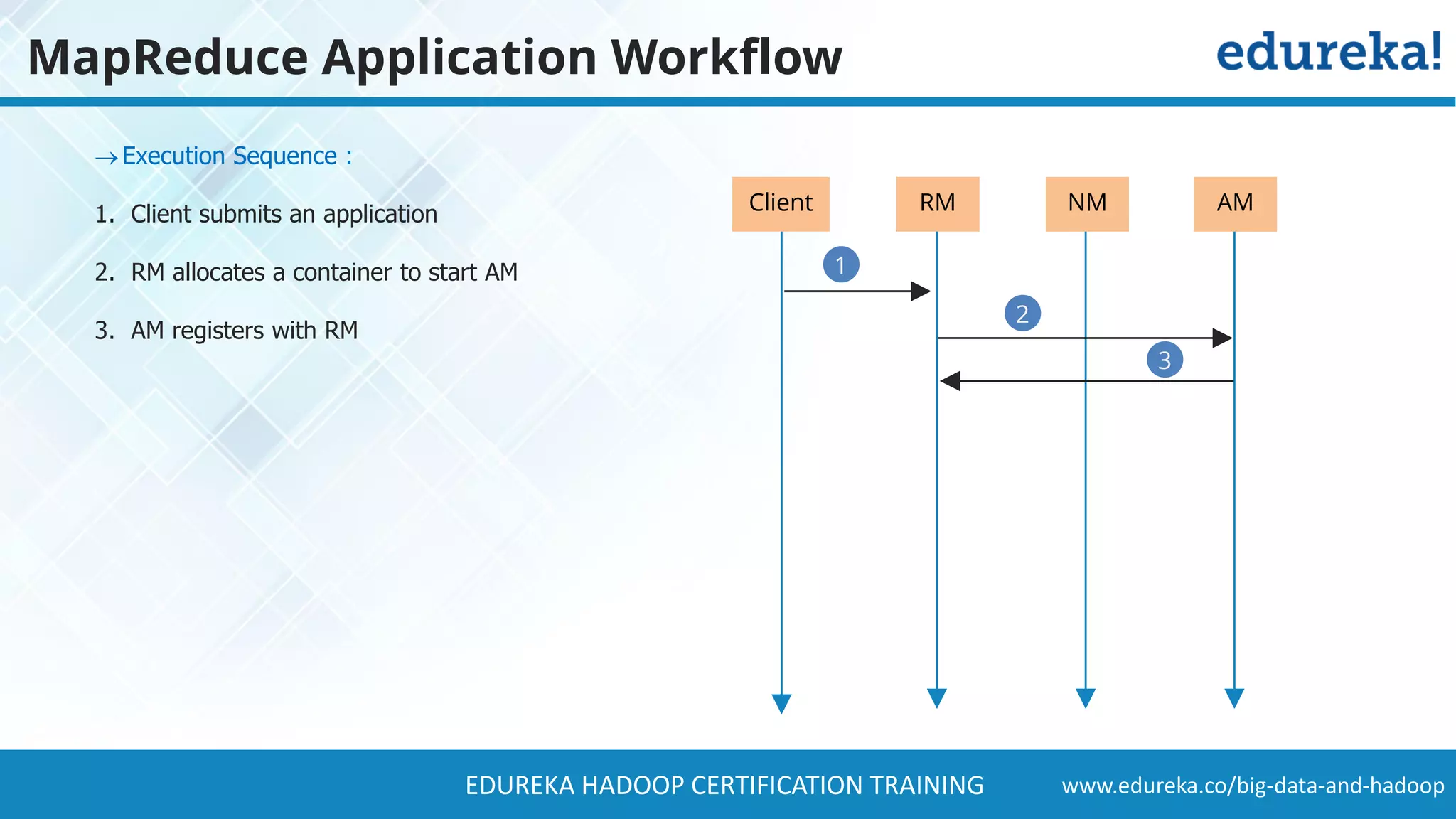
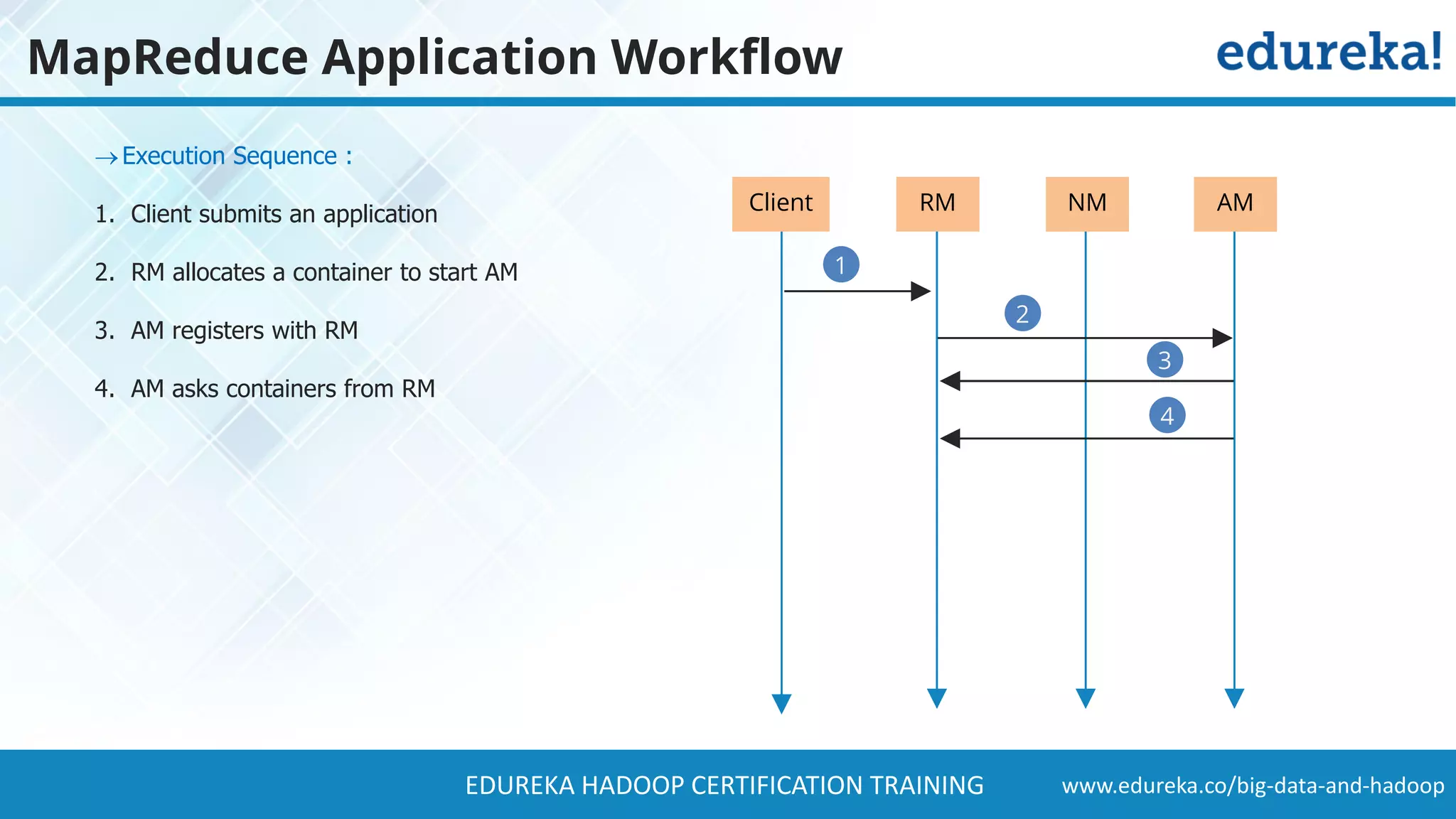
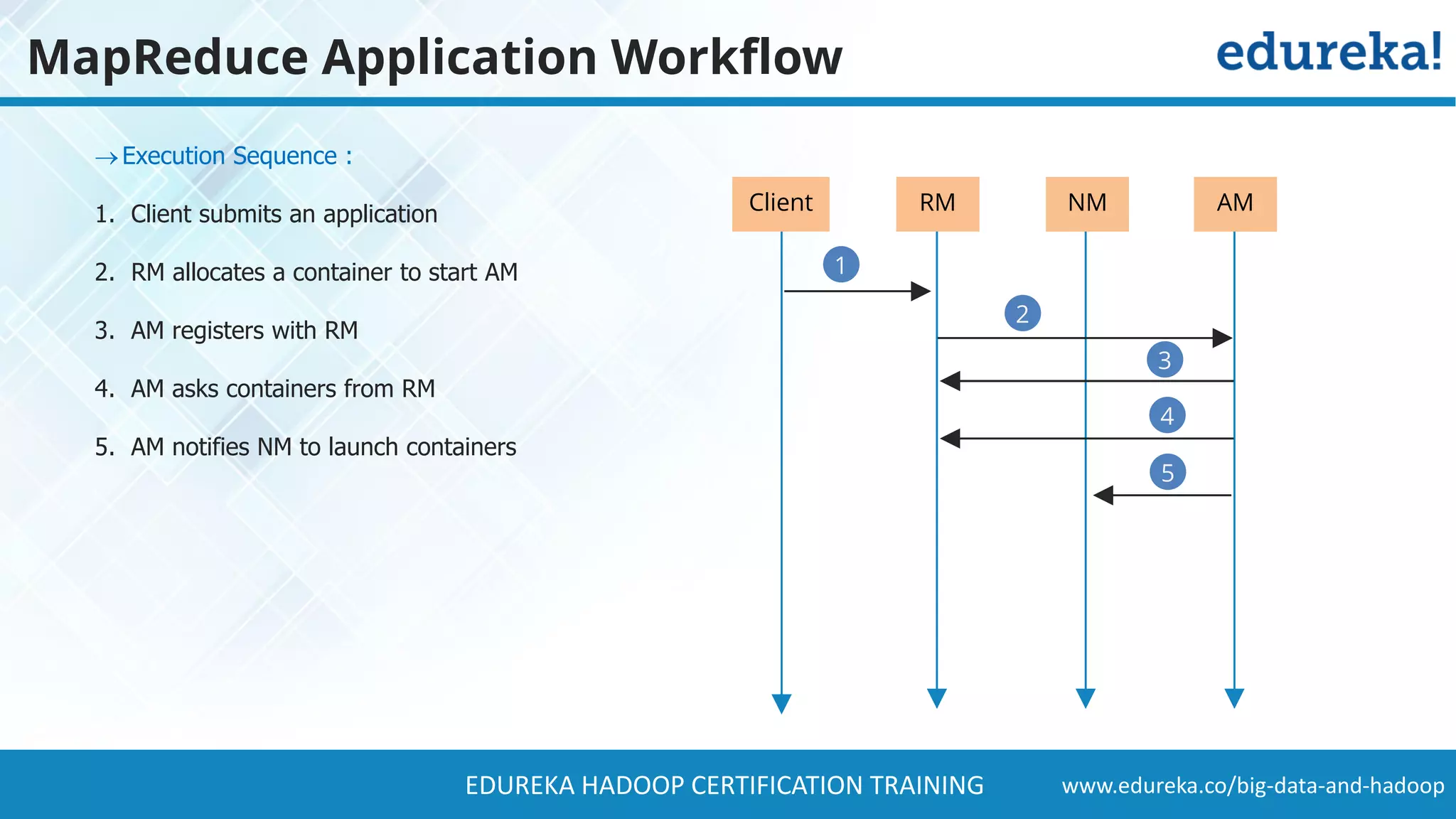
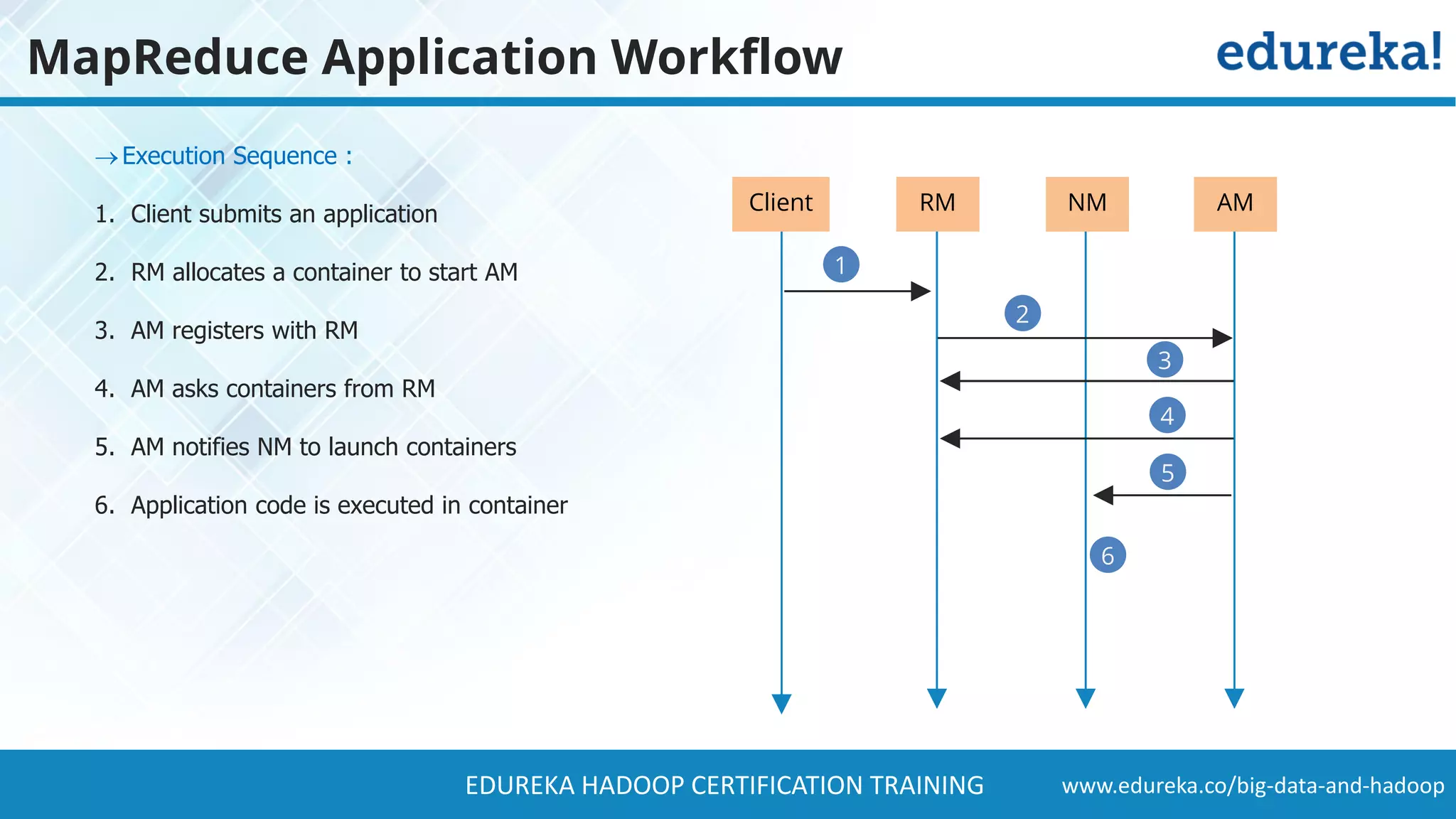
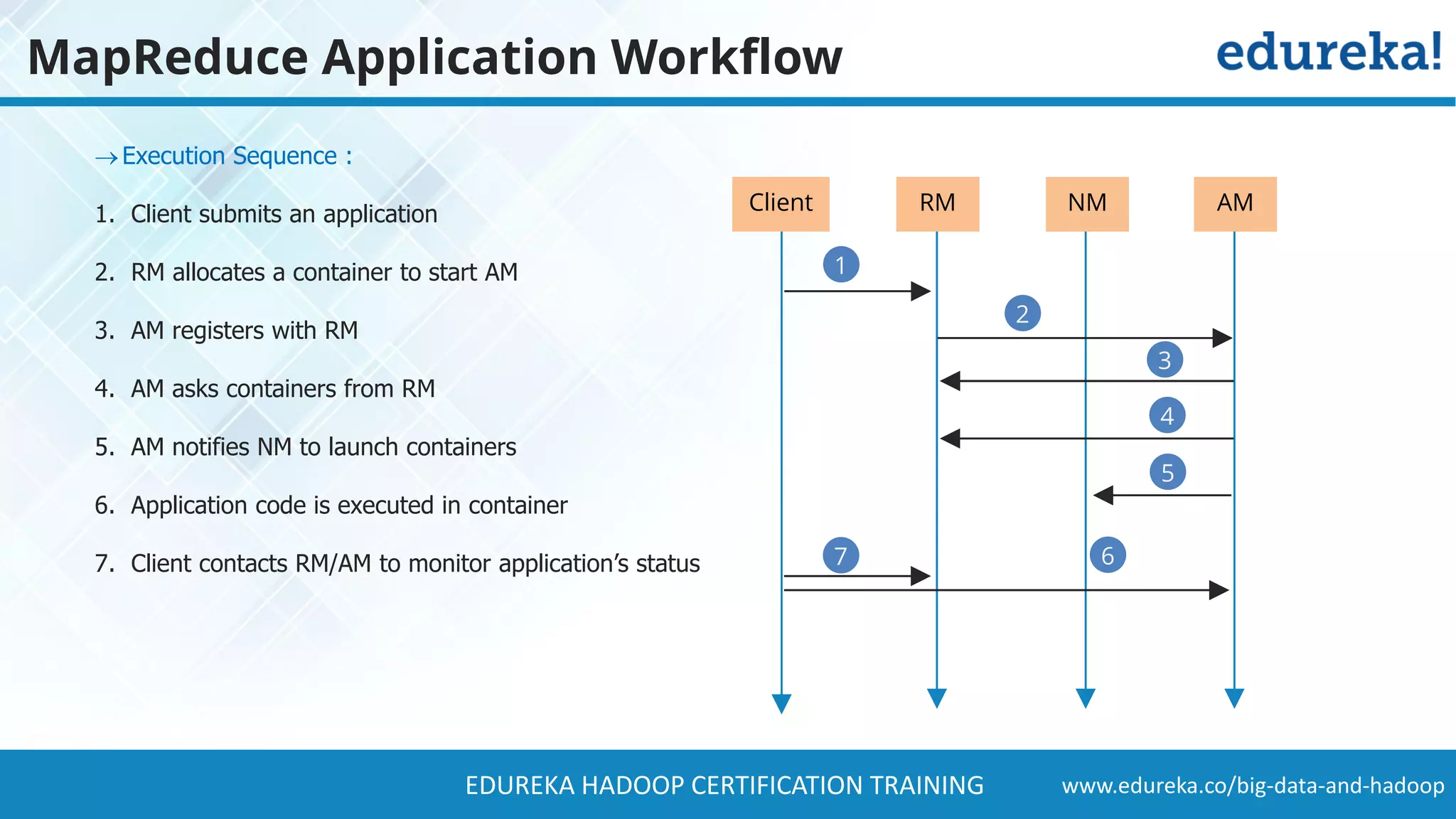
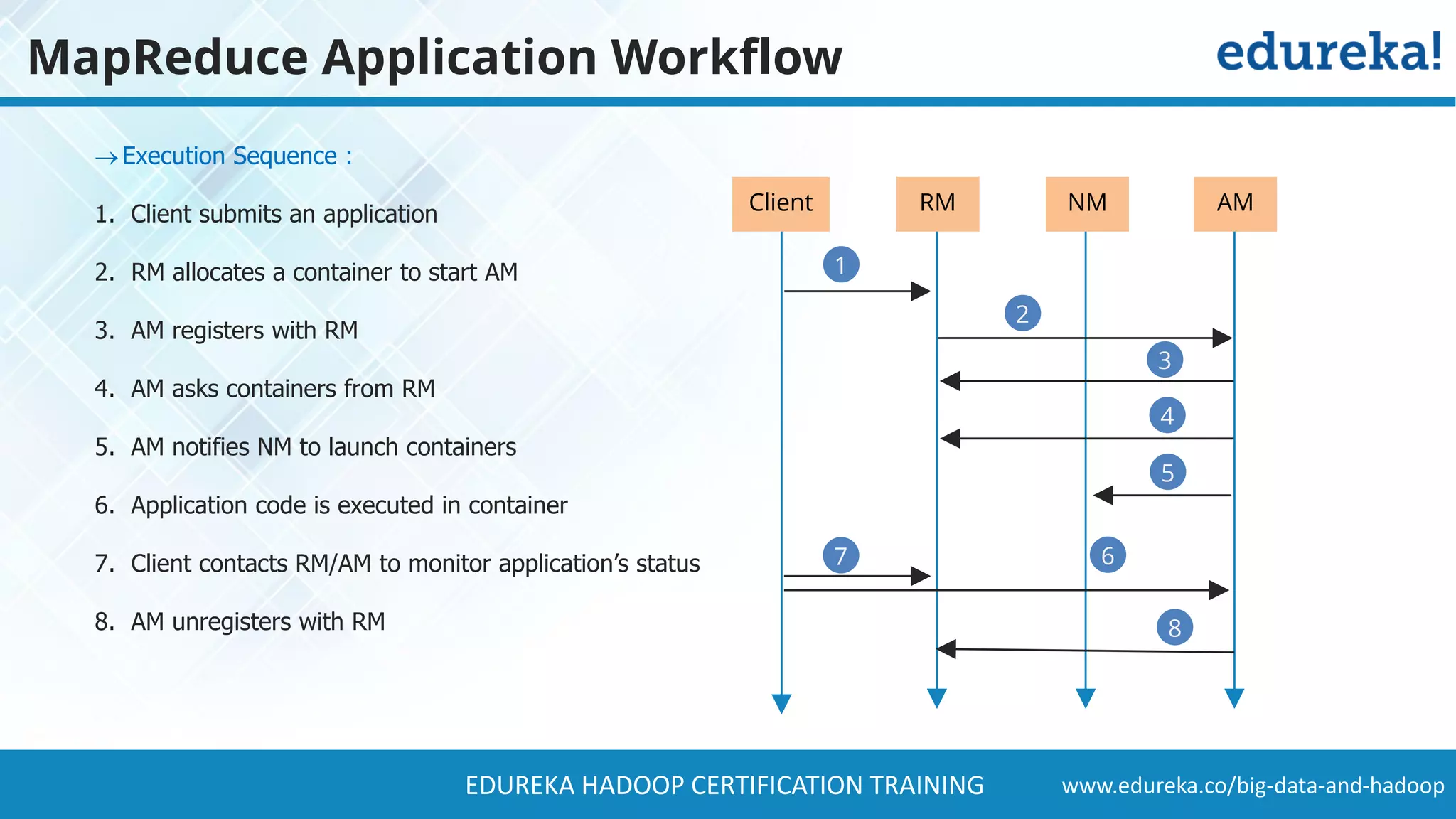

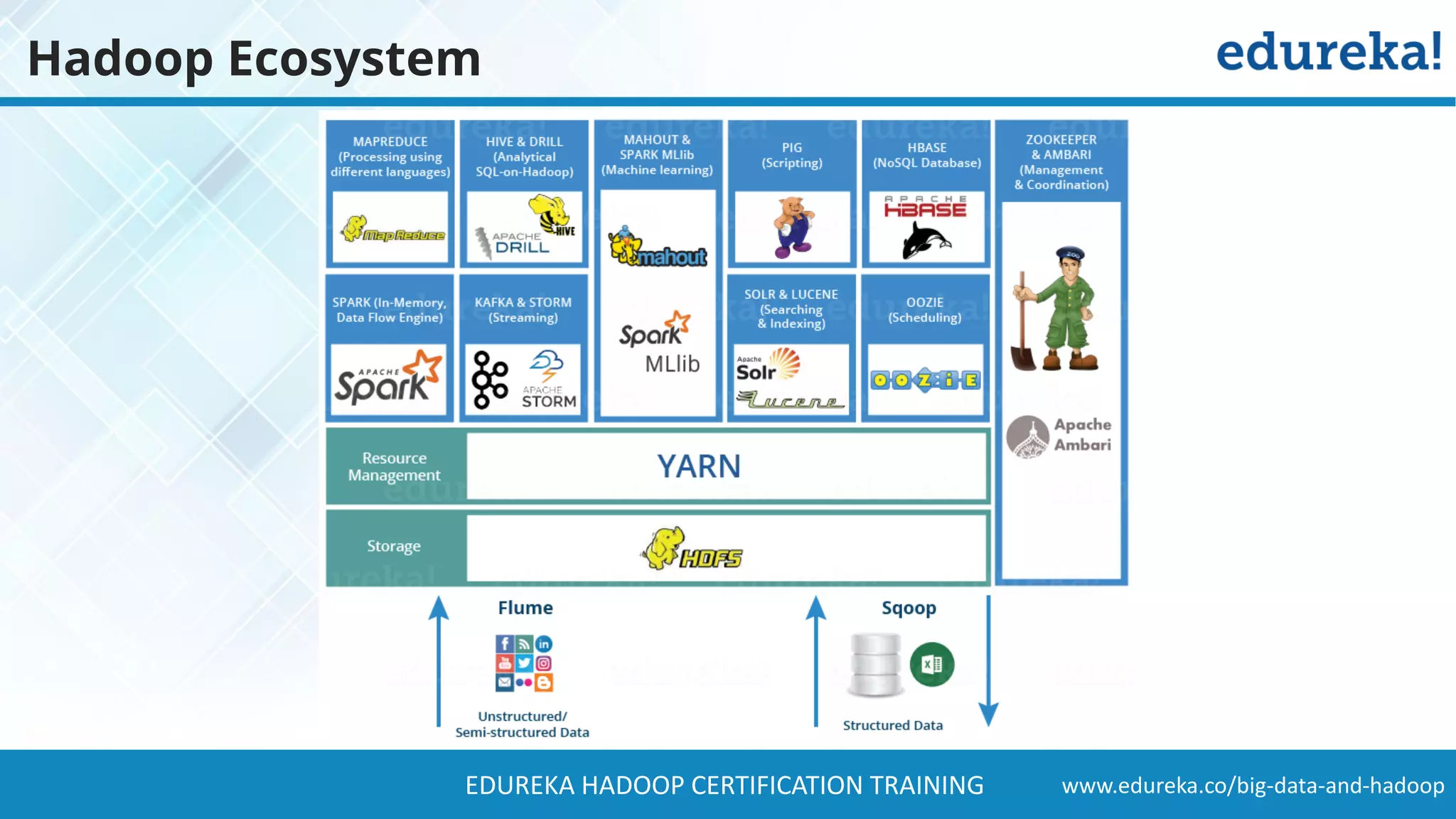

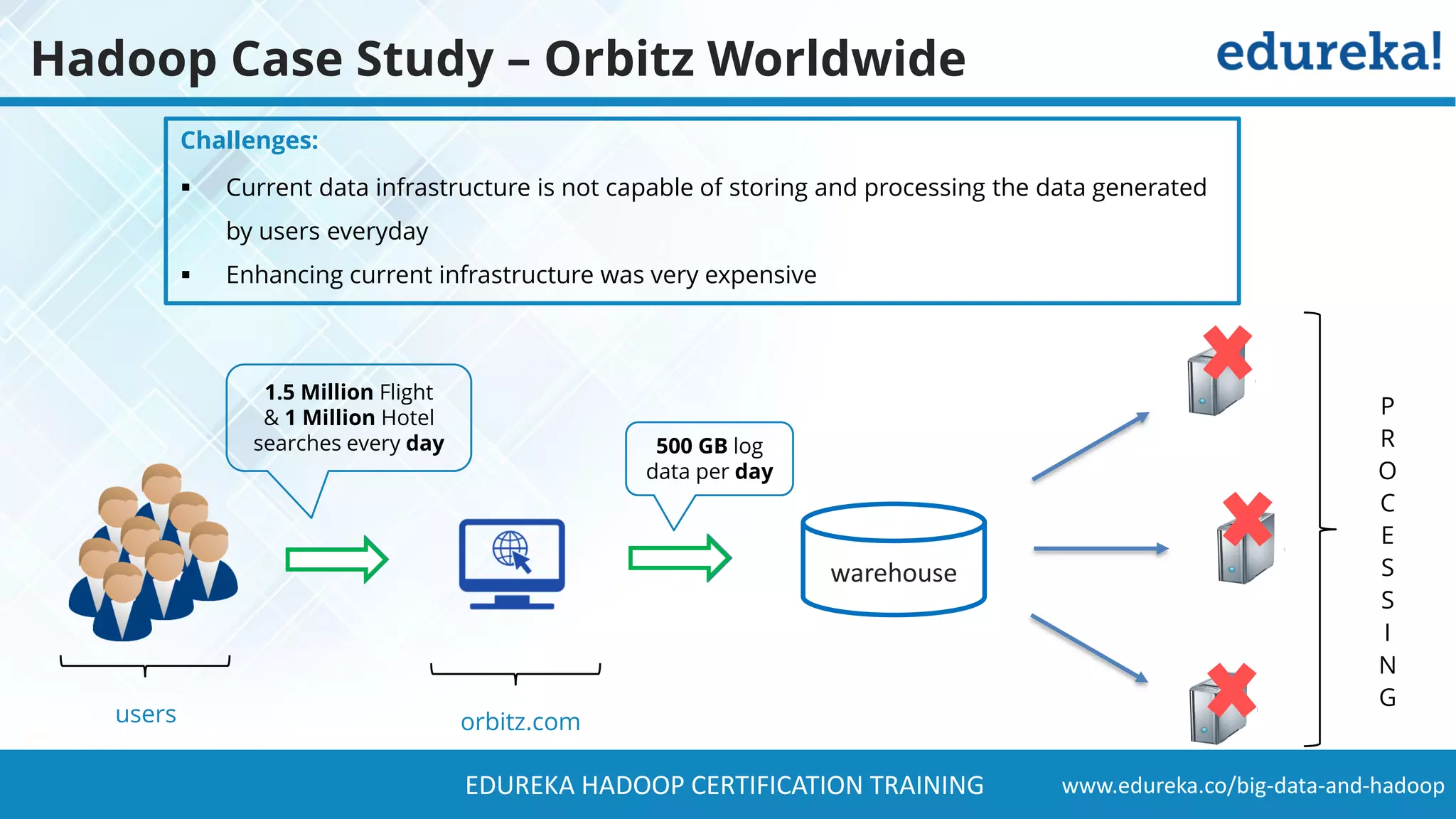
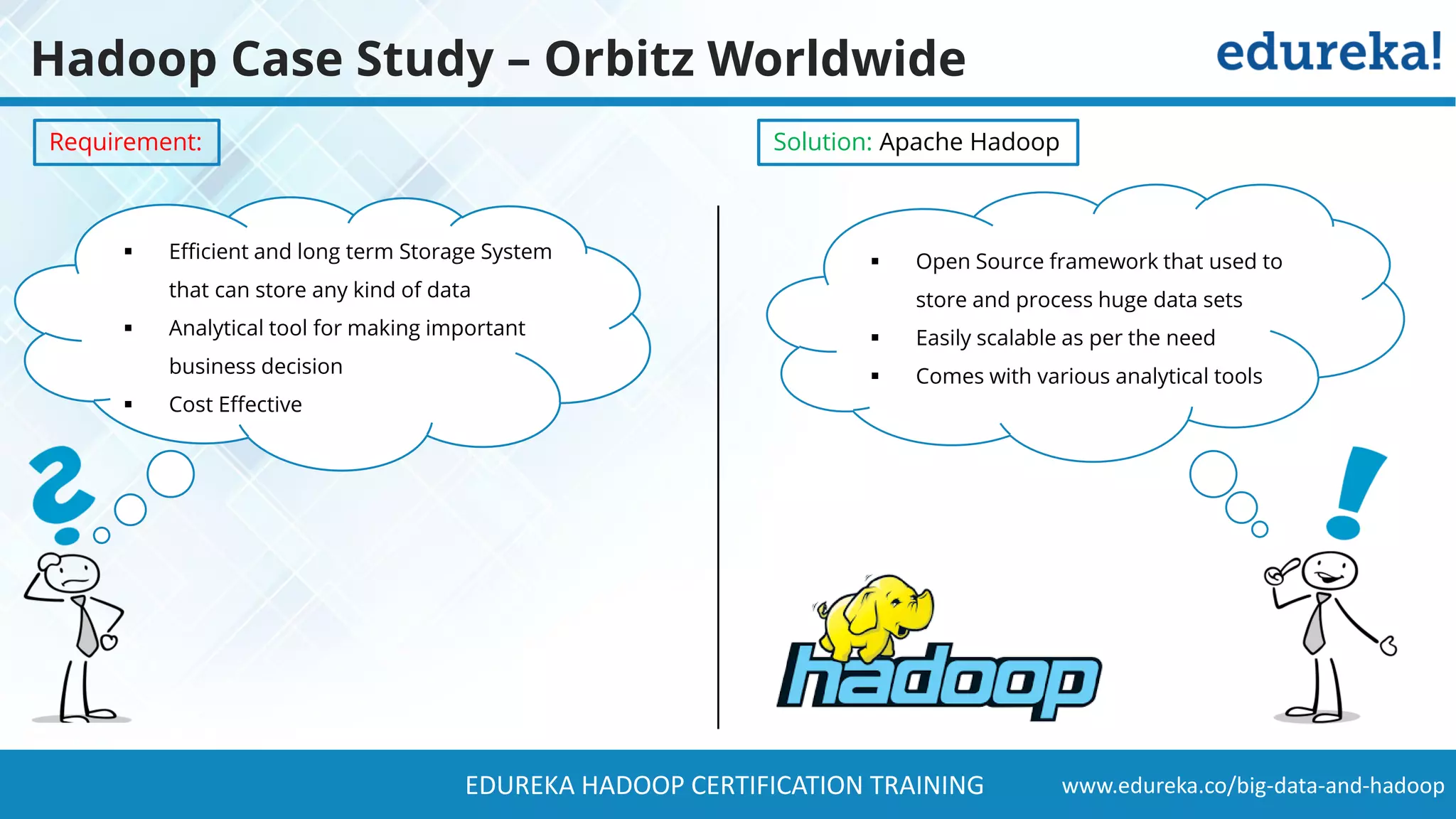

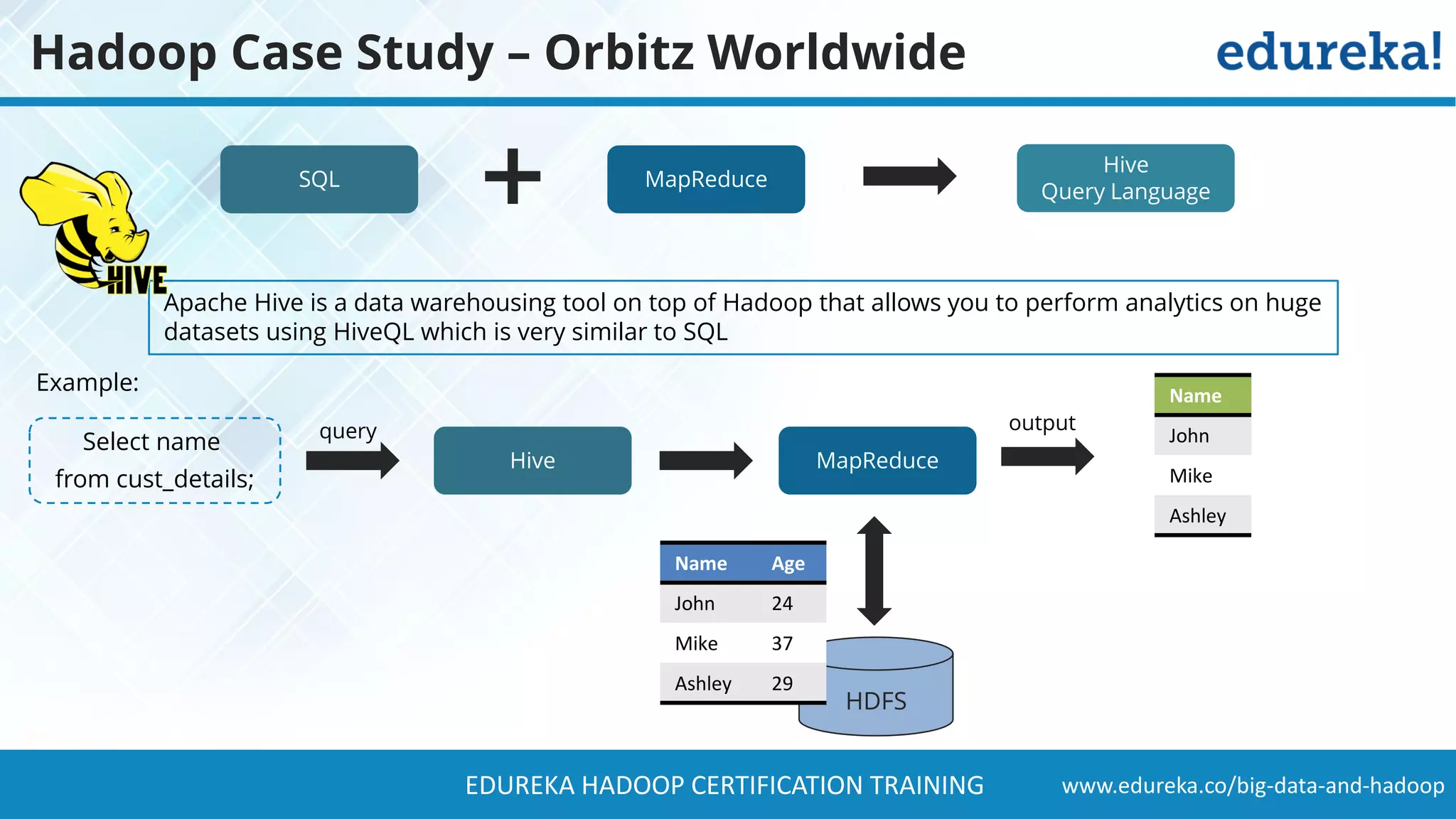
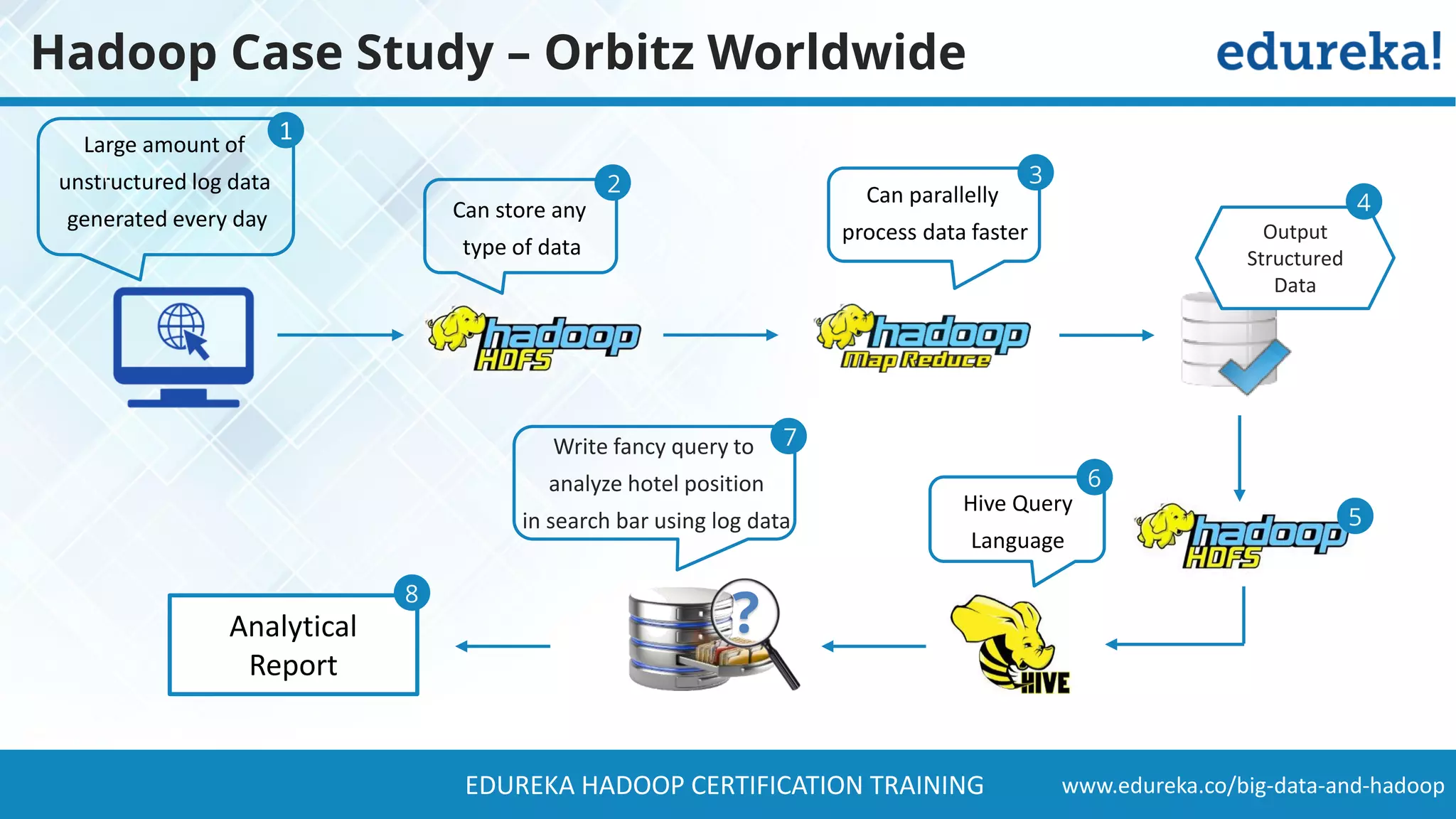
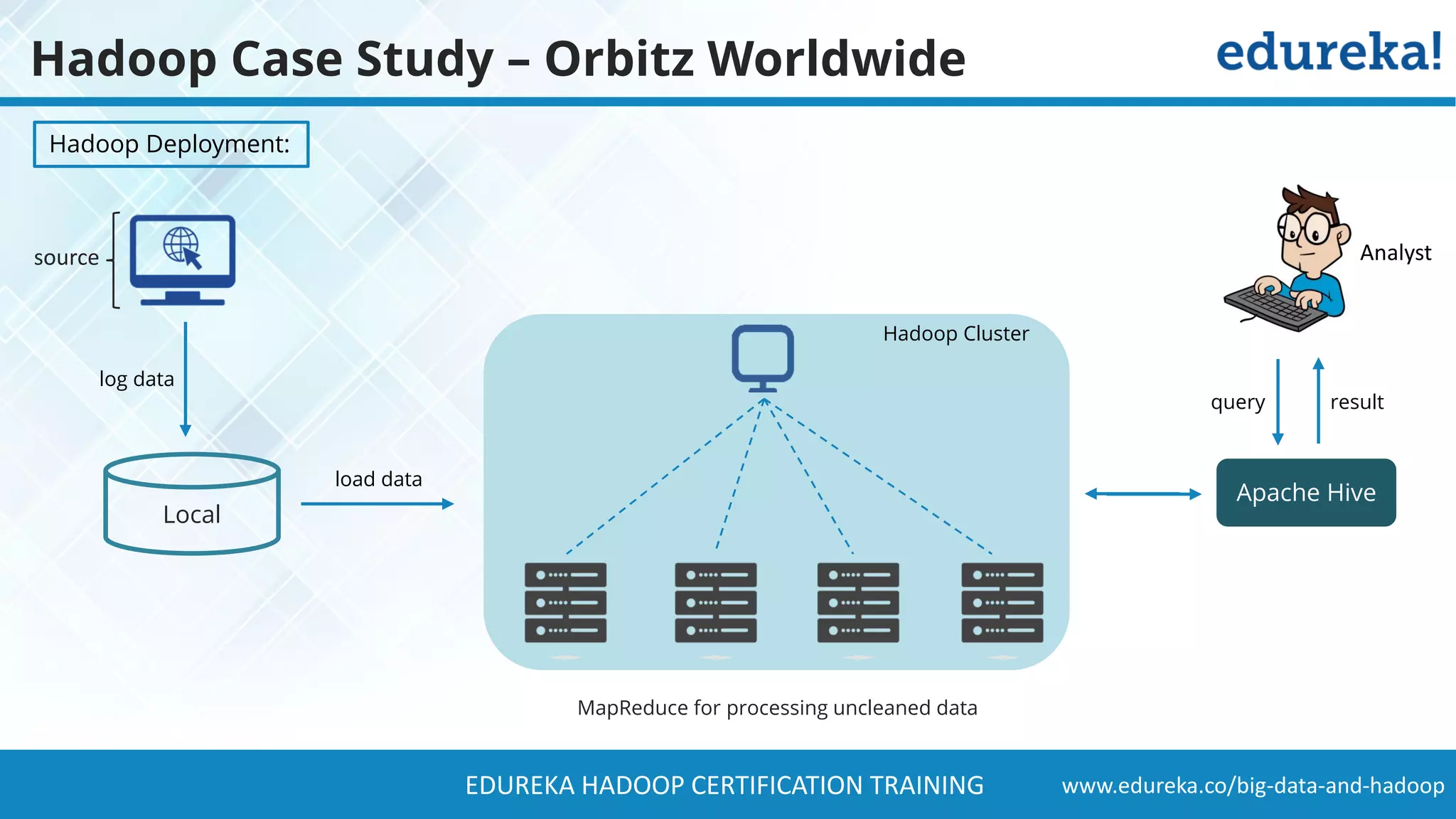



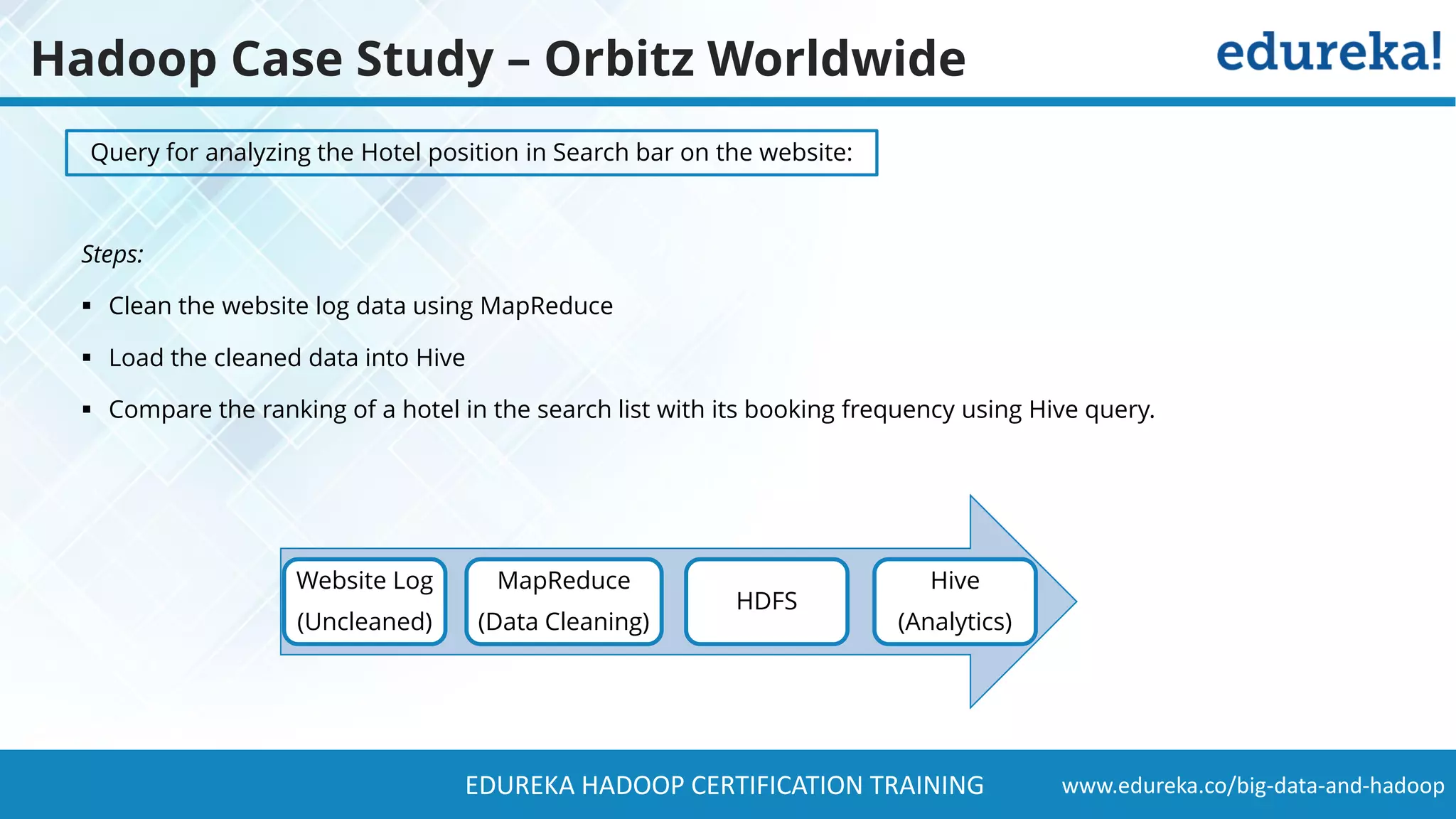



The document provides a comprehensive overview of Hadoop and its role in addressing big data challenges, including data processing, storage, and the limitations of traditional approaches. It discusses the Hadoop ecosystem, key components like HDFS and MapReduce, and presents case studies demonstrating Hadoop's effectiveness in managing large datasets. Additionally, it highlights the growth of data, problems associated with it, and suggests Hadoop as a scalable and cost-effective solution for modern data processing needs.