

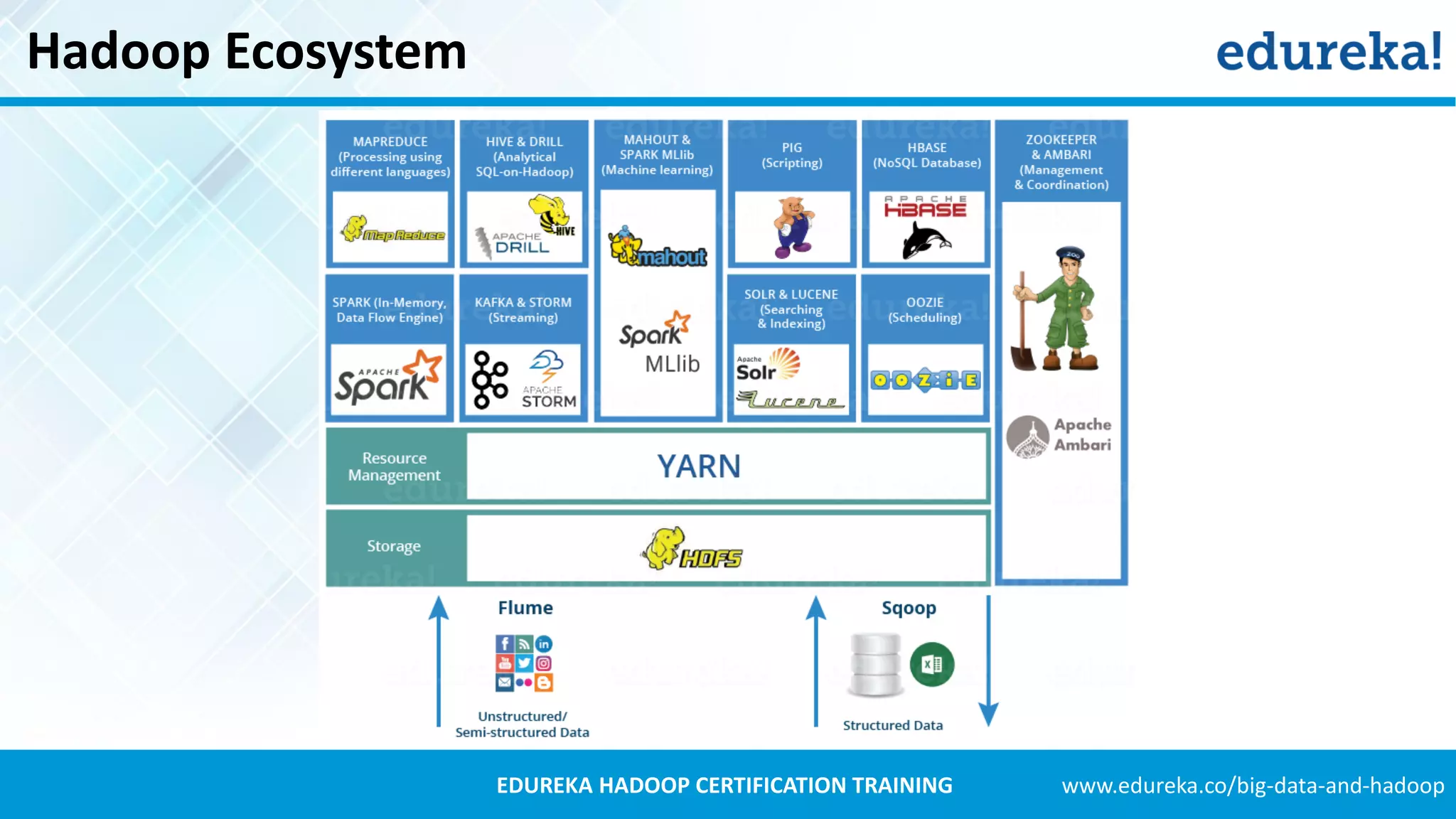



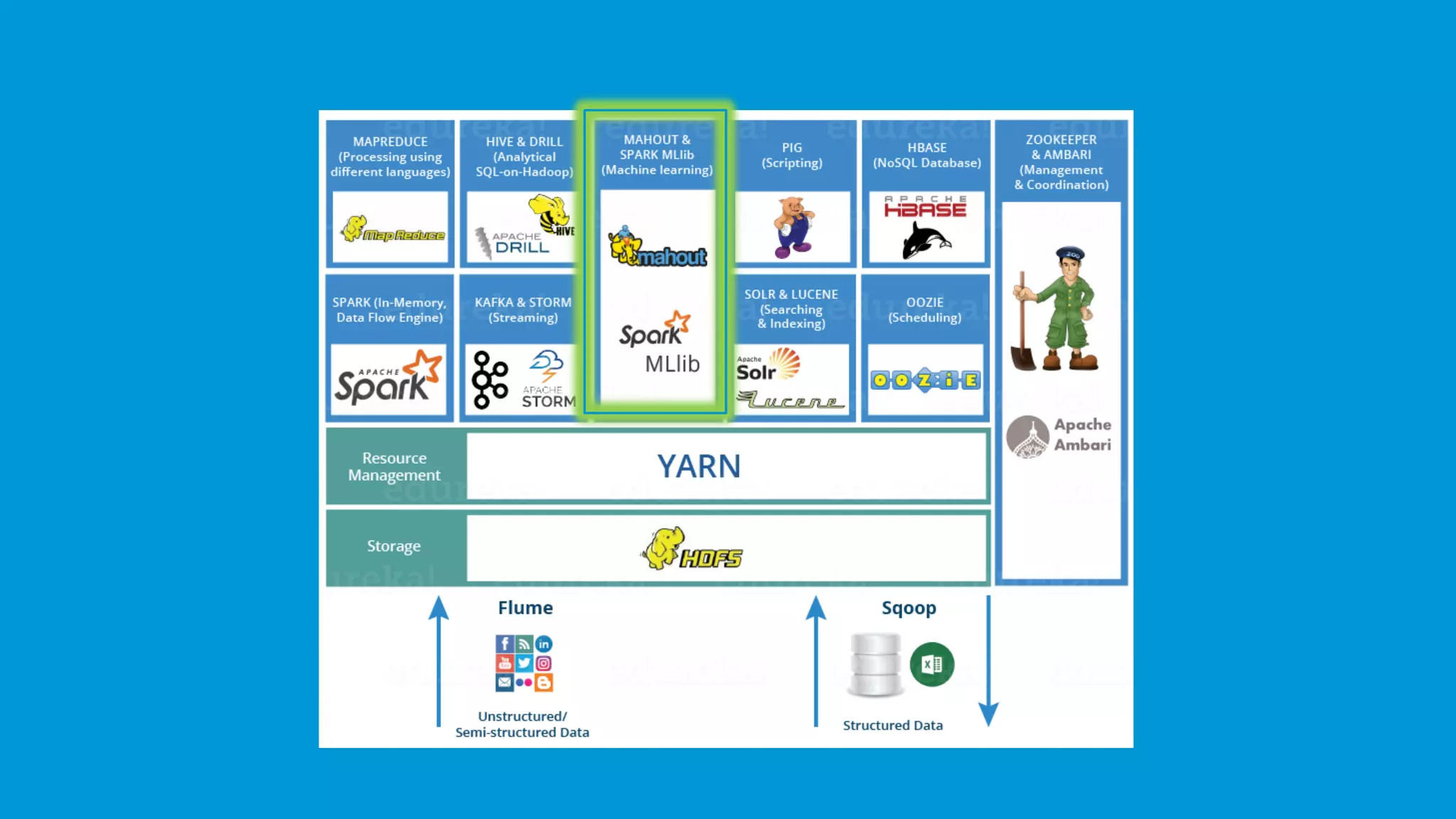

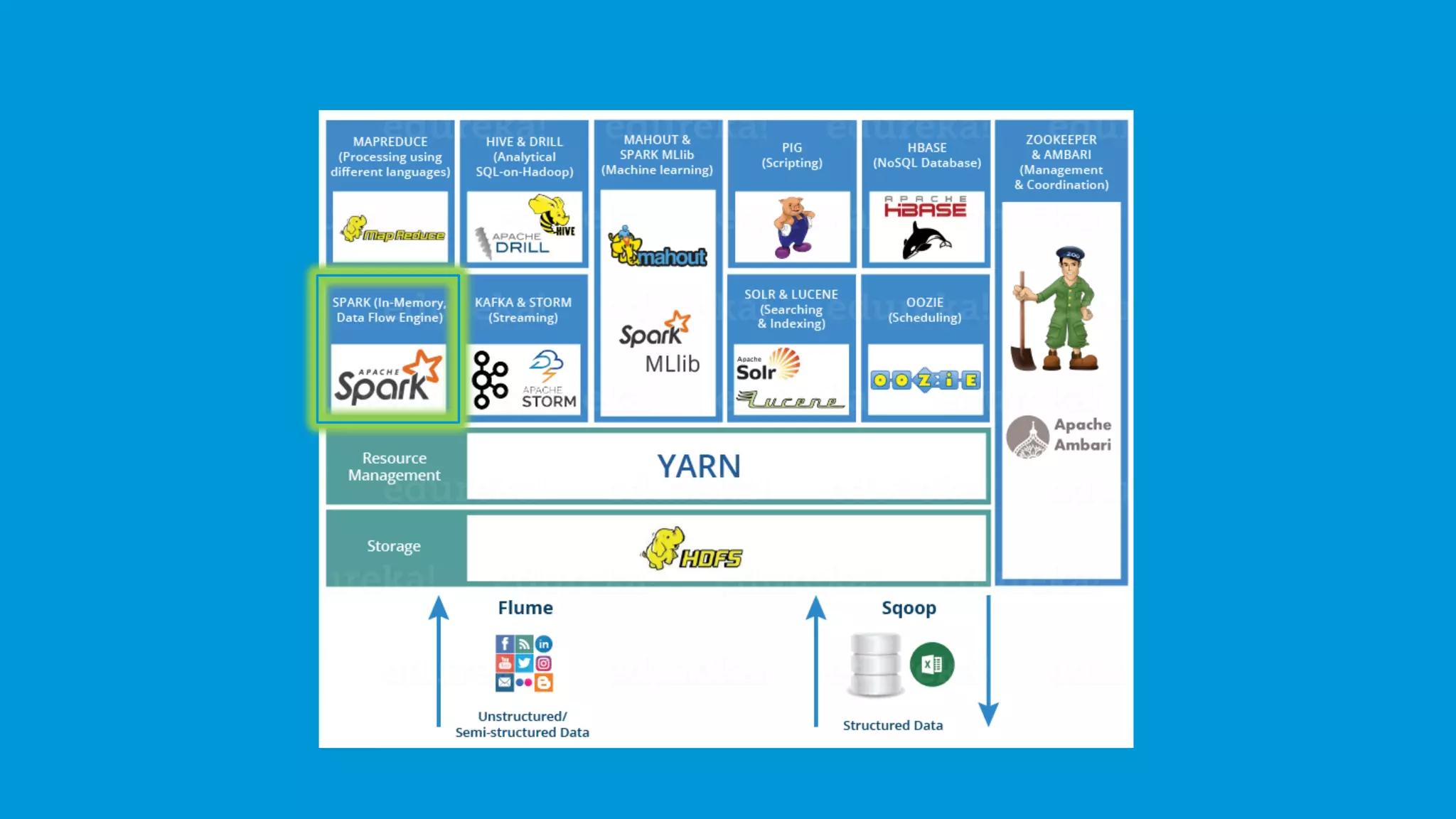

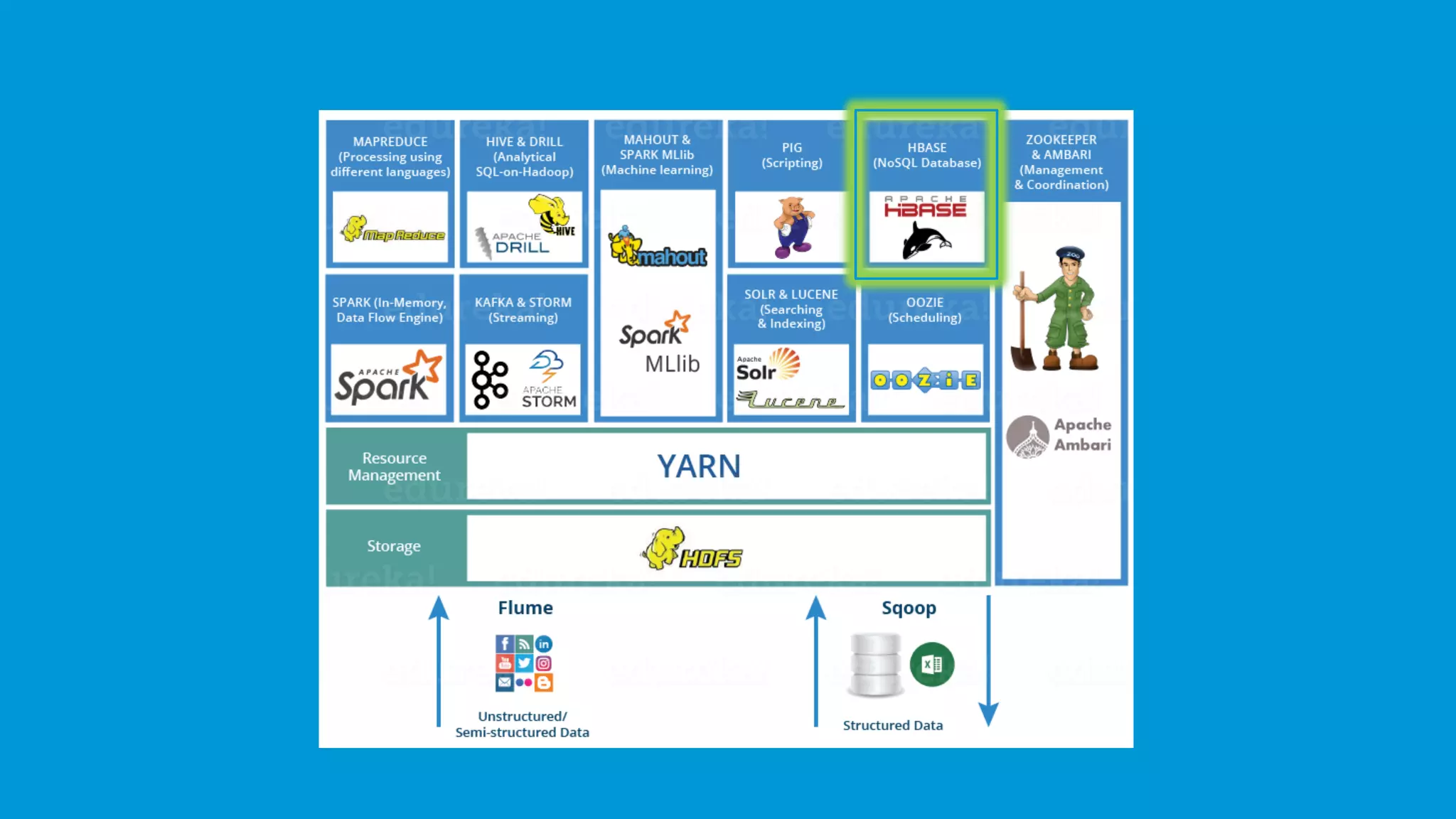










The document provides an overview of the Hadoop ecosystem and its various components such as HDFS, YARN, MapReduce, Spark, Pig, Hive, and more, which are essential for storing, processing, and analyzing big data. Each component is described with its functionality, including data ingestion by Flume and Sqoop, machine learning capabilities through Mahout, and job scheduling with Oozie. Additional details on related tools like Zookeeper and Ambari for cluster management are also included.
Introduction to Edureka's Hadoop Certification, outlining the agenda including the Hadoop ecosystem components.
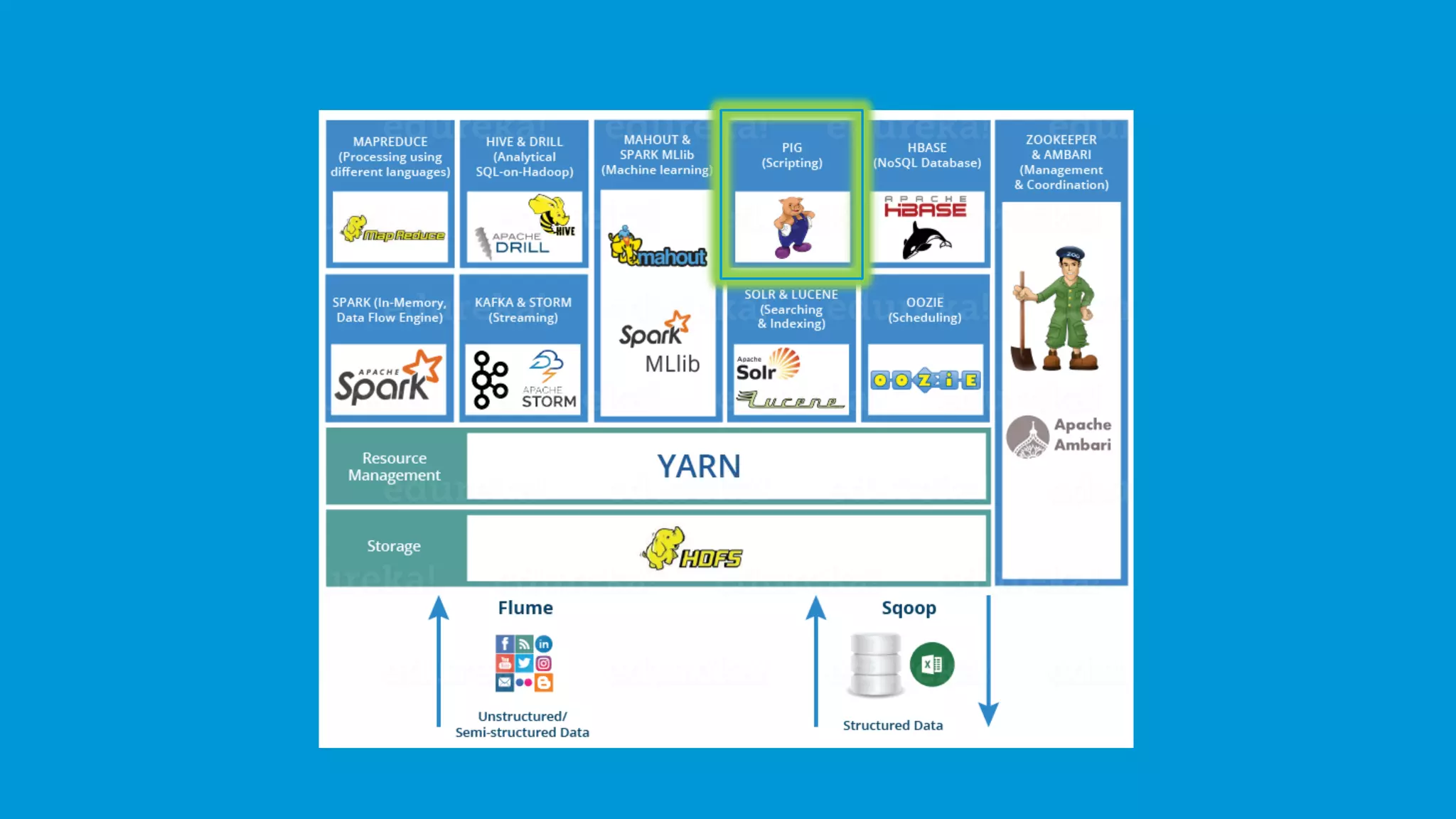
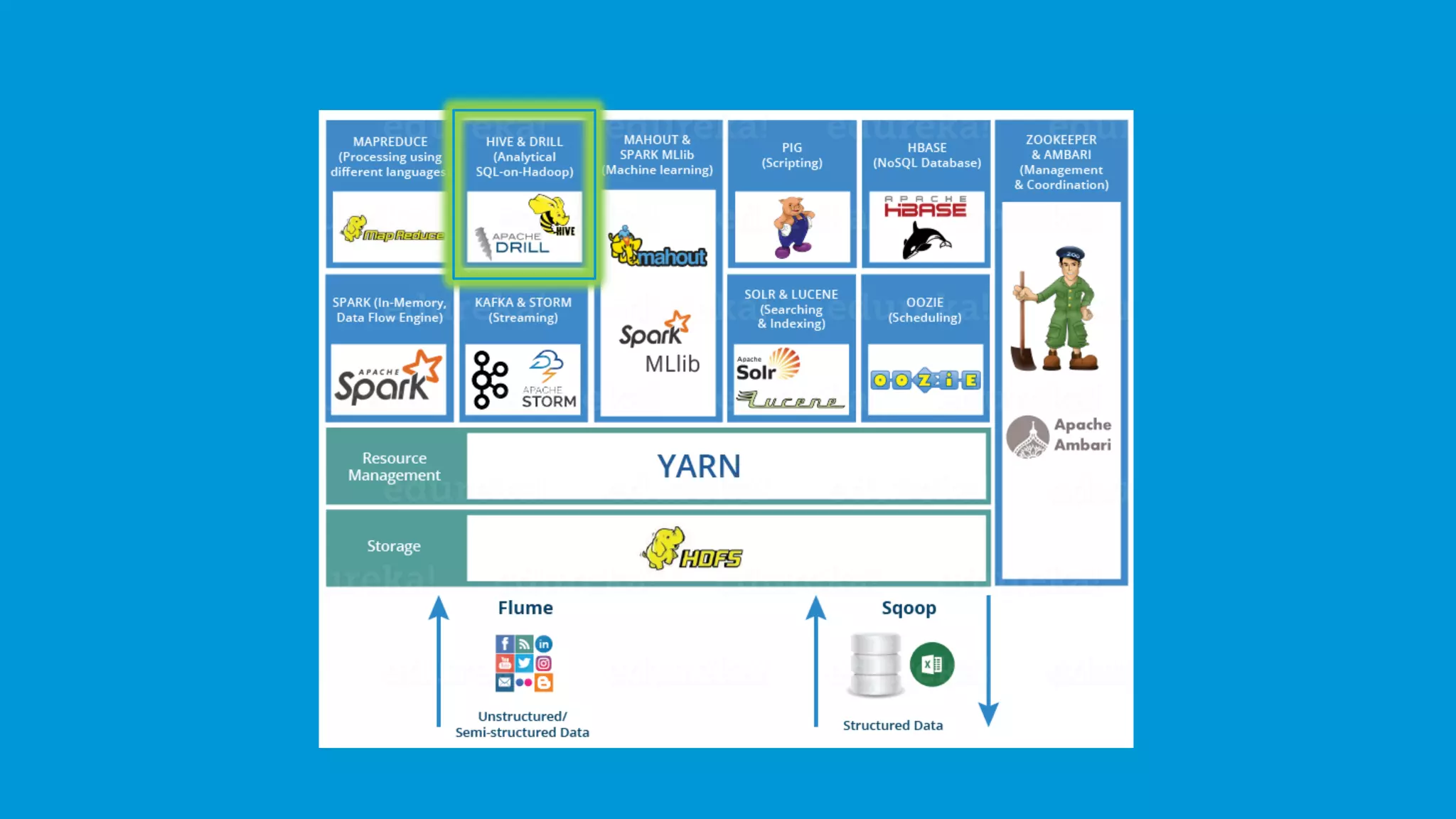
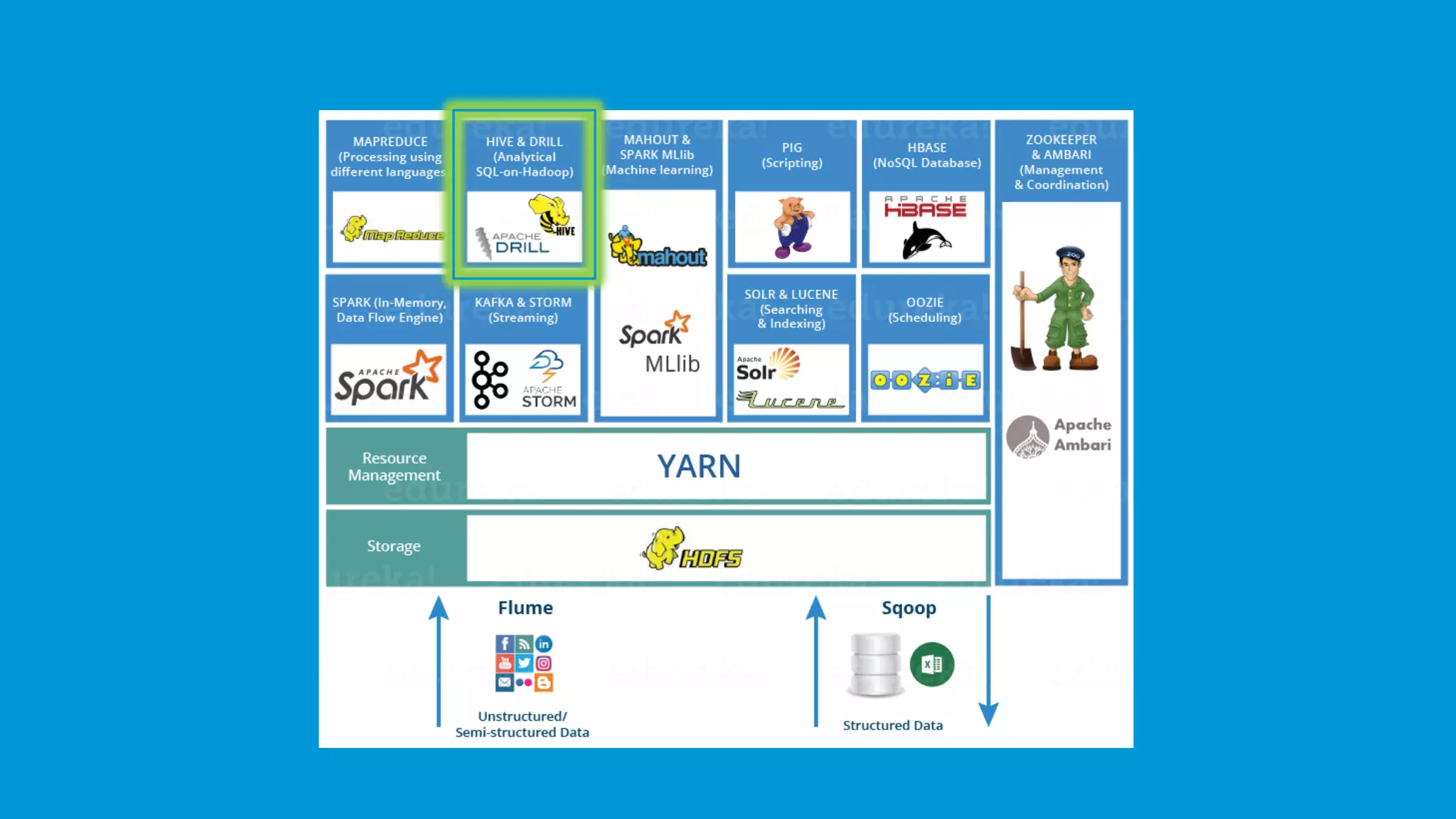
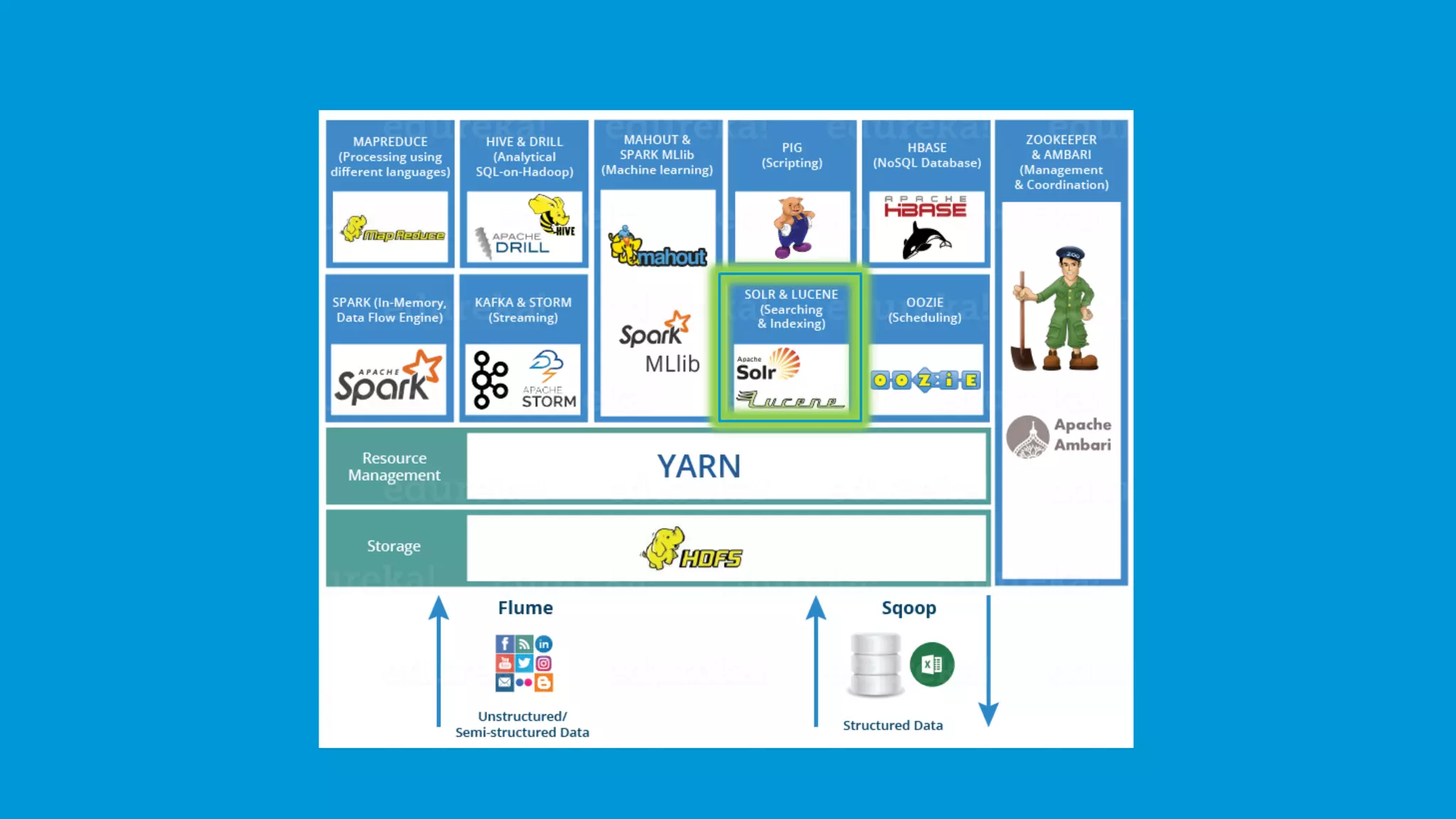
A brief mention of the Hadoop Ecosystem, emphasizing its vital components.
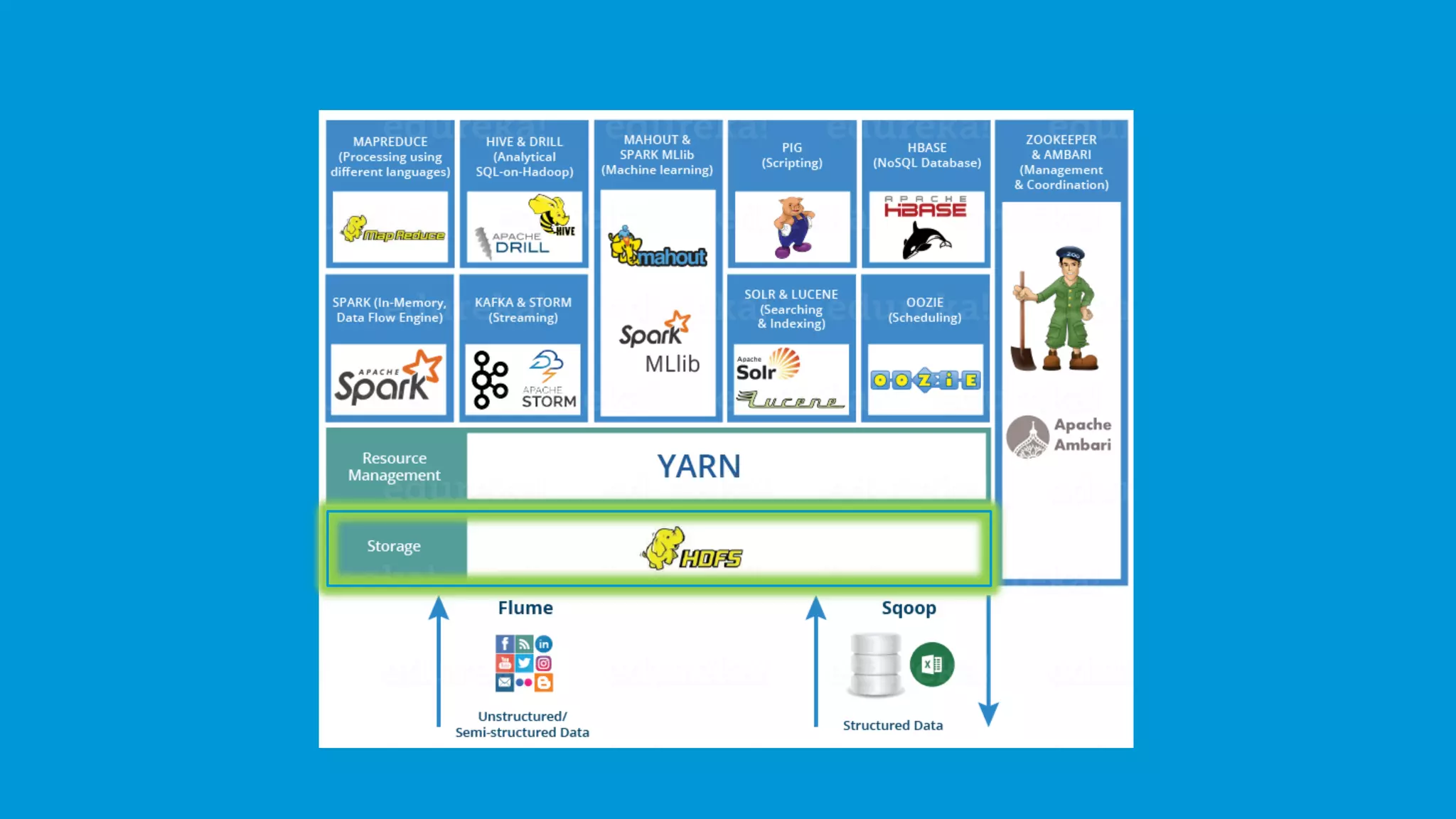
Hadoop Distributed File System (HDFS) stores large data sets, including structured, unstructured, and semi-structured data.
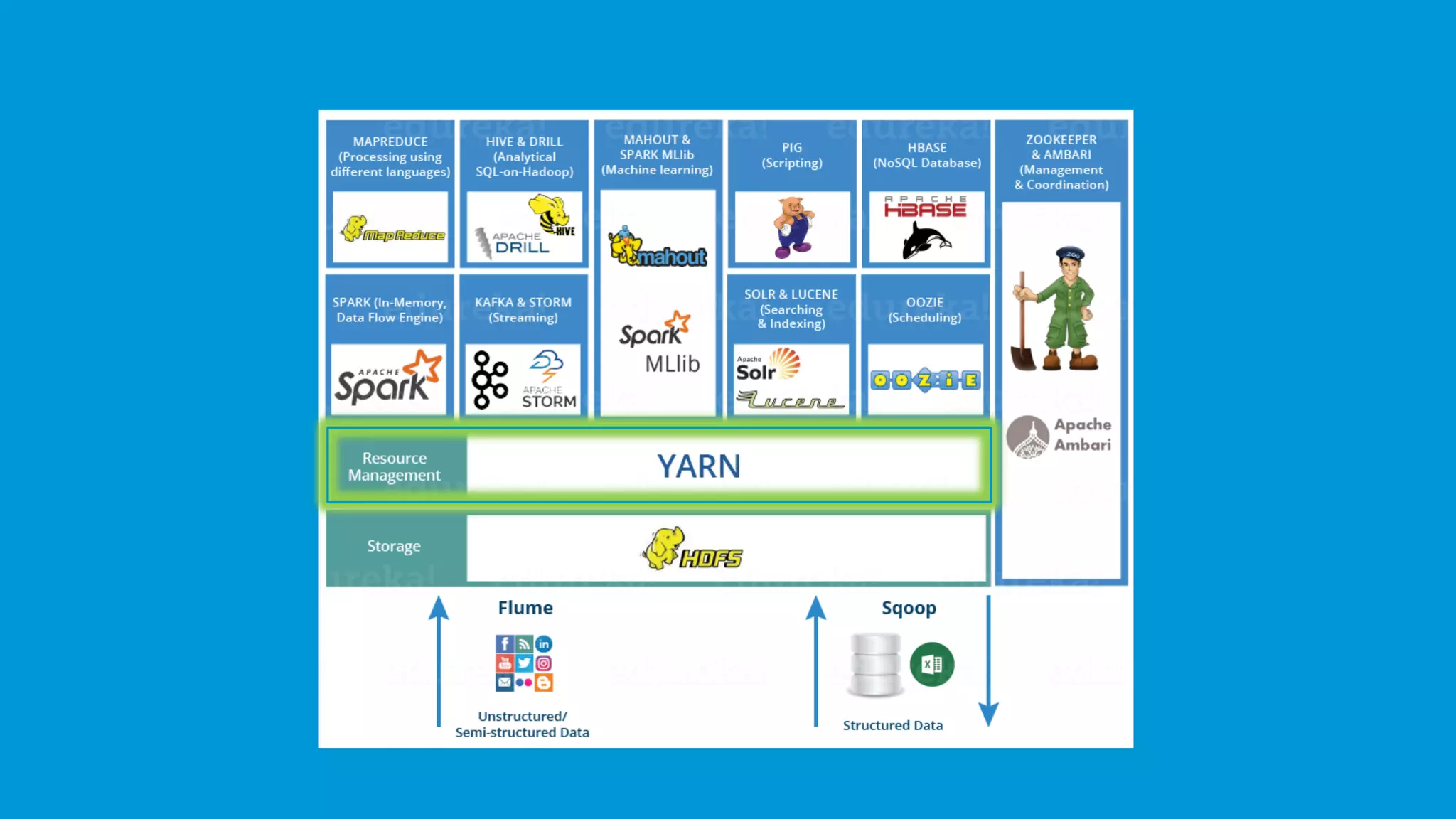
YARN (Yet Another Resource Negotiator) manages resources and schedules tasks, with ResourceManager and NodeManager.
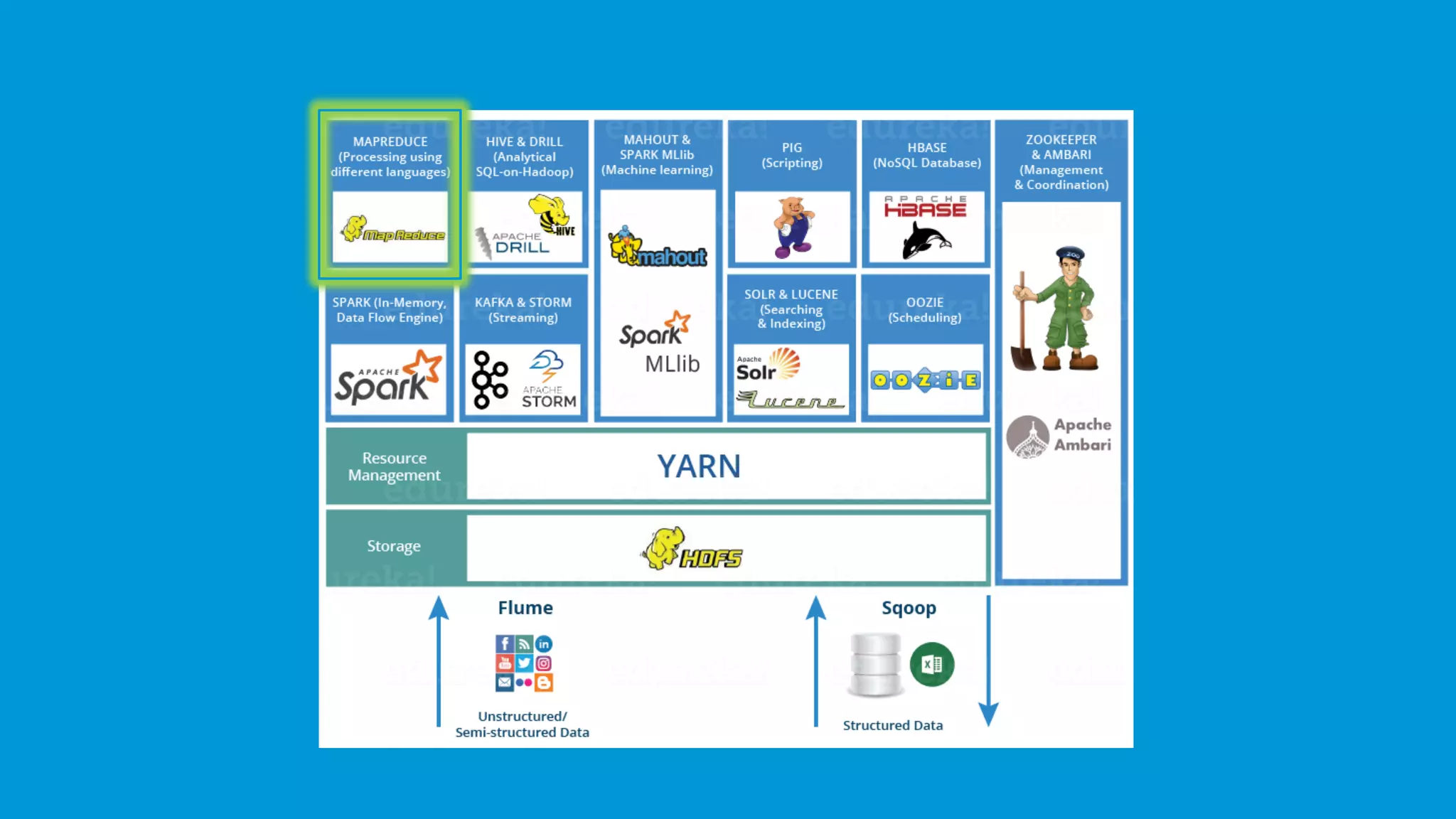
MapReduce processes large data sets through the Map and Reduce functions, applying distributed algorithms.
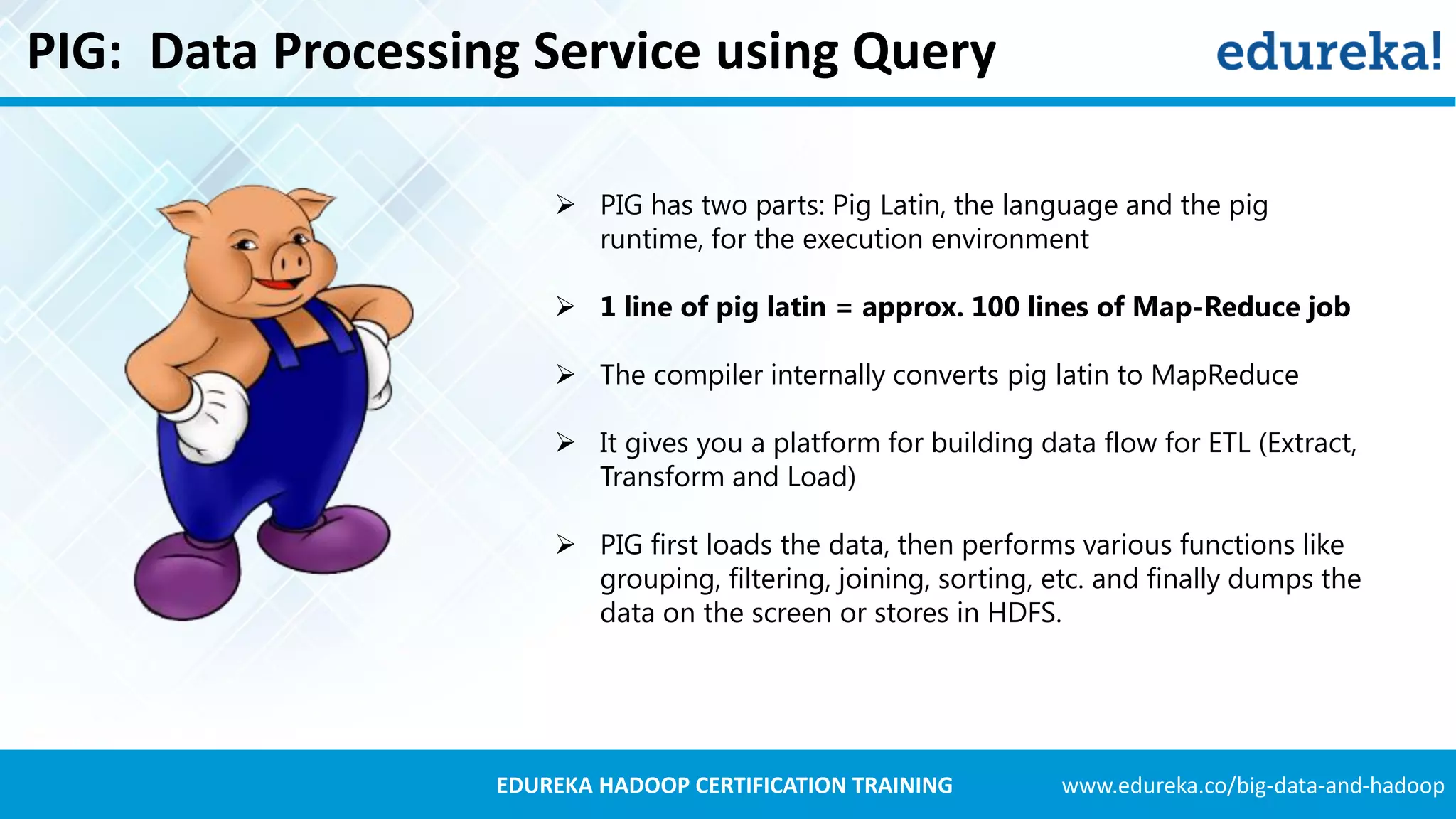
PIG utilizes Pig Latin for data flow processing within Hadoop, converting it to MapReduce for execution.
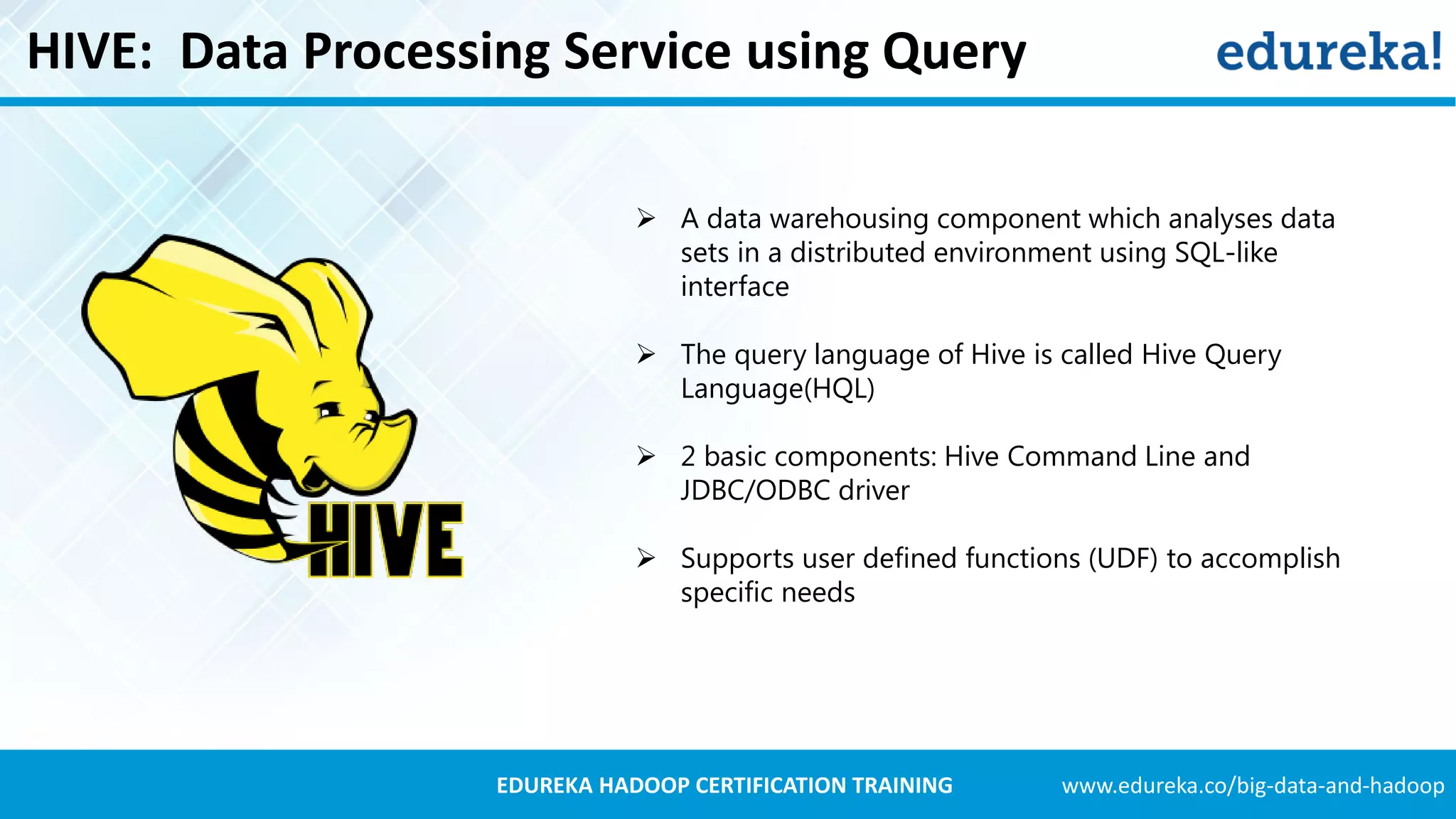
Hive serves as a data warehousing solution for analyzing datasets using a SQL-like interface.
Mahout provides tools for creating machine learning applications, featuring collaborative filtering and classification.
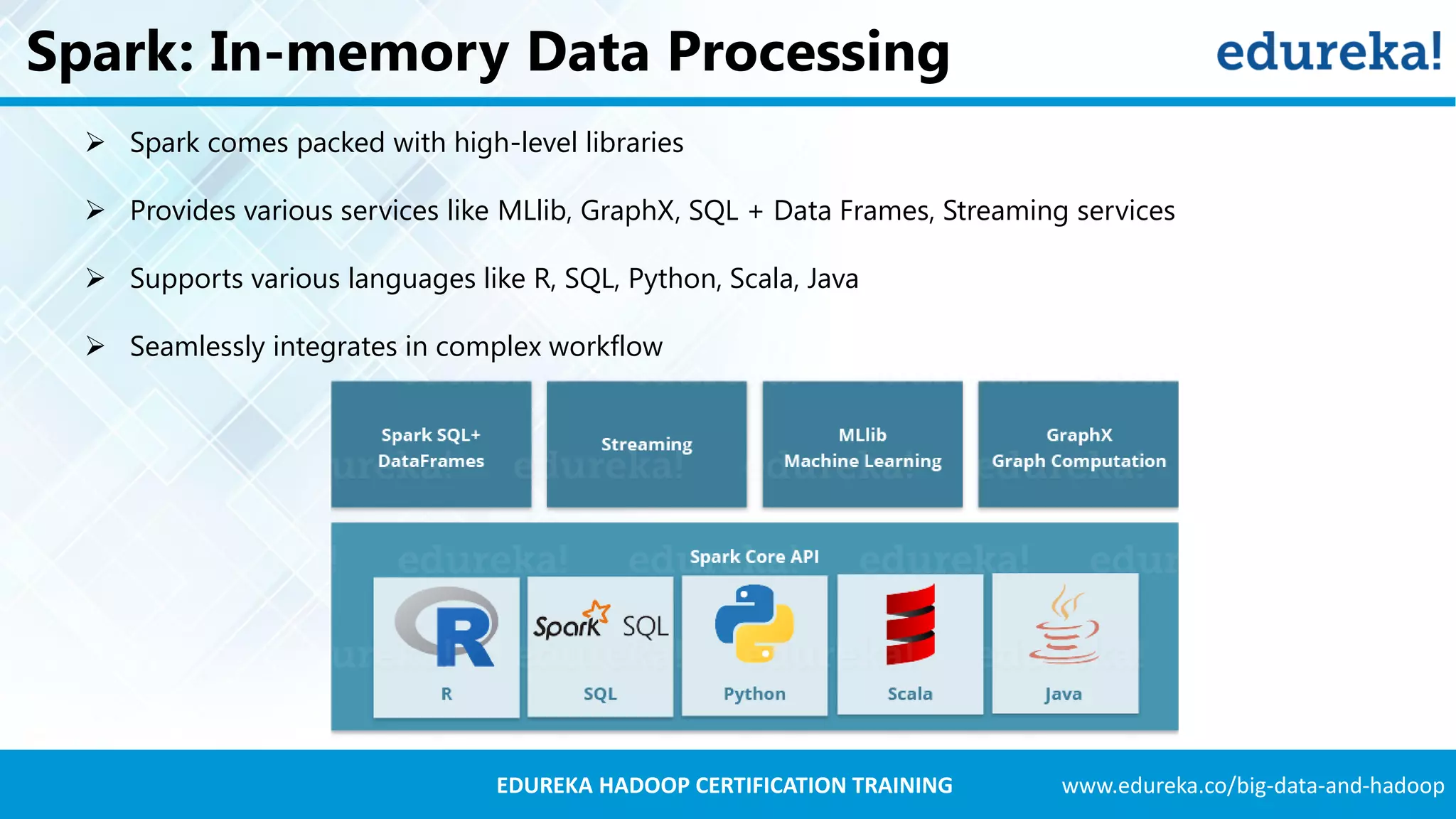
Spark delivers real-time data analytics, works faster than MapReduce, and supports various programming languages.
HBase is a non-relational, distributed NoSQL database capable of handling any types of data, modeled after BigTable.
Apache Drill allows SQL queries on various data sources including Hadoop, enabling analysis of large datasets.
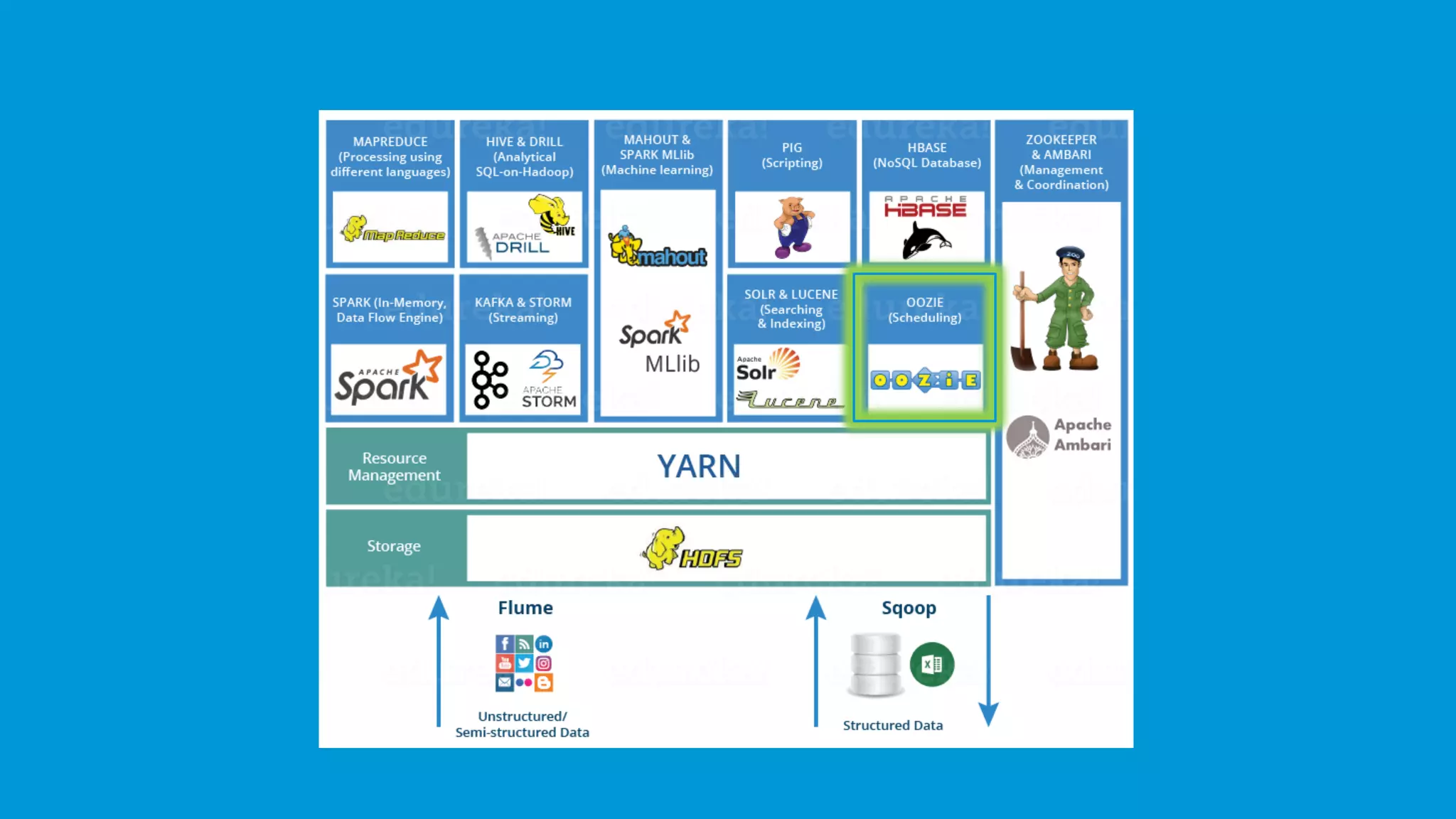
Oozie manages Hadoop job scheduling, supporting both workflow and coordinator jobs based on data availability or time.
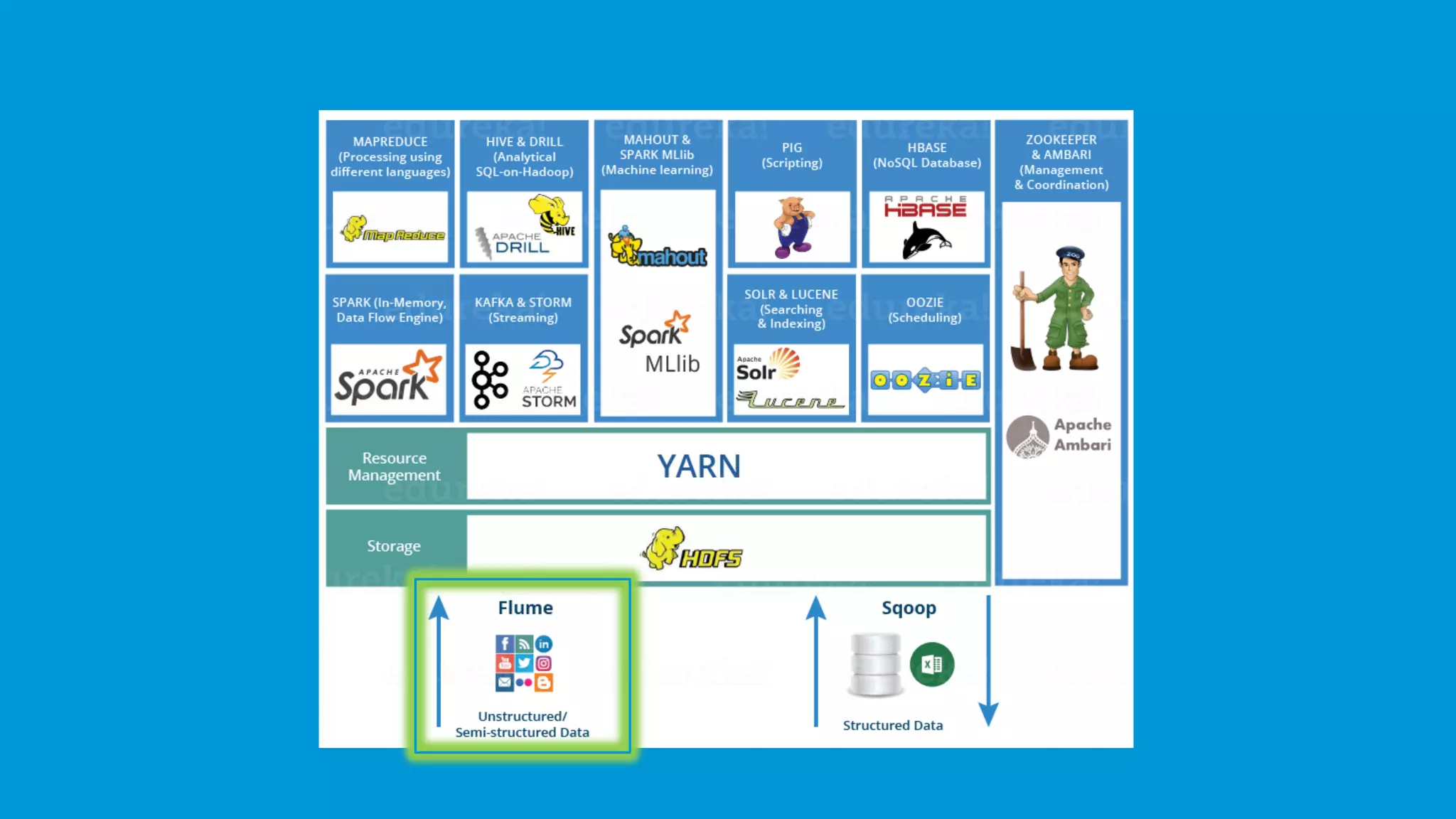
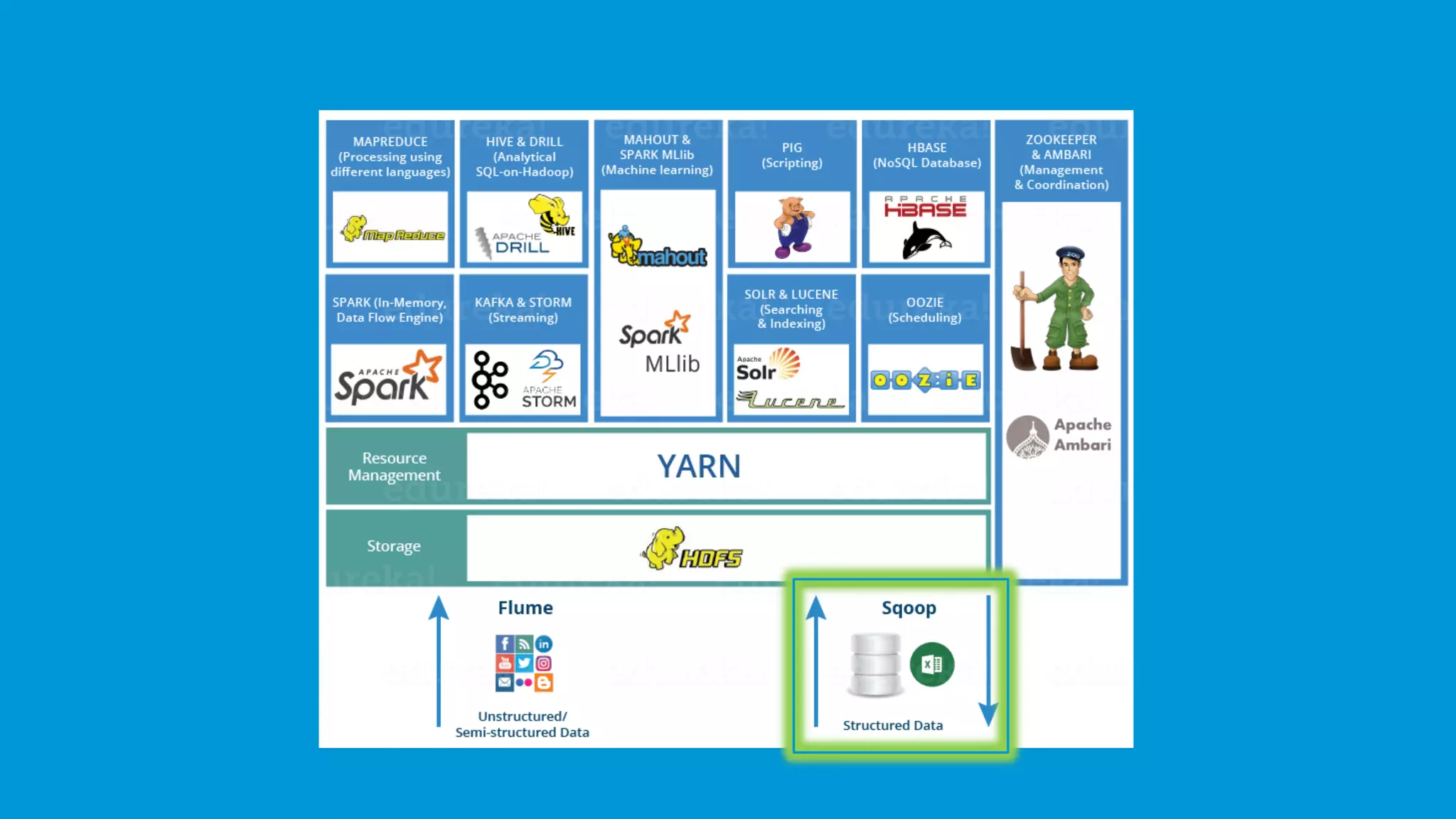
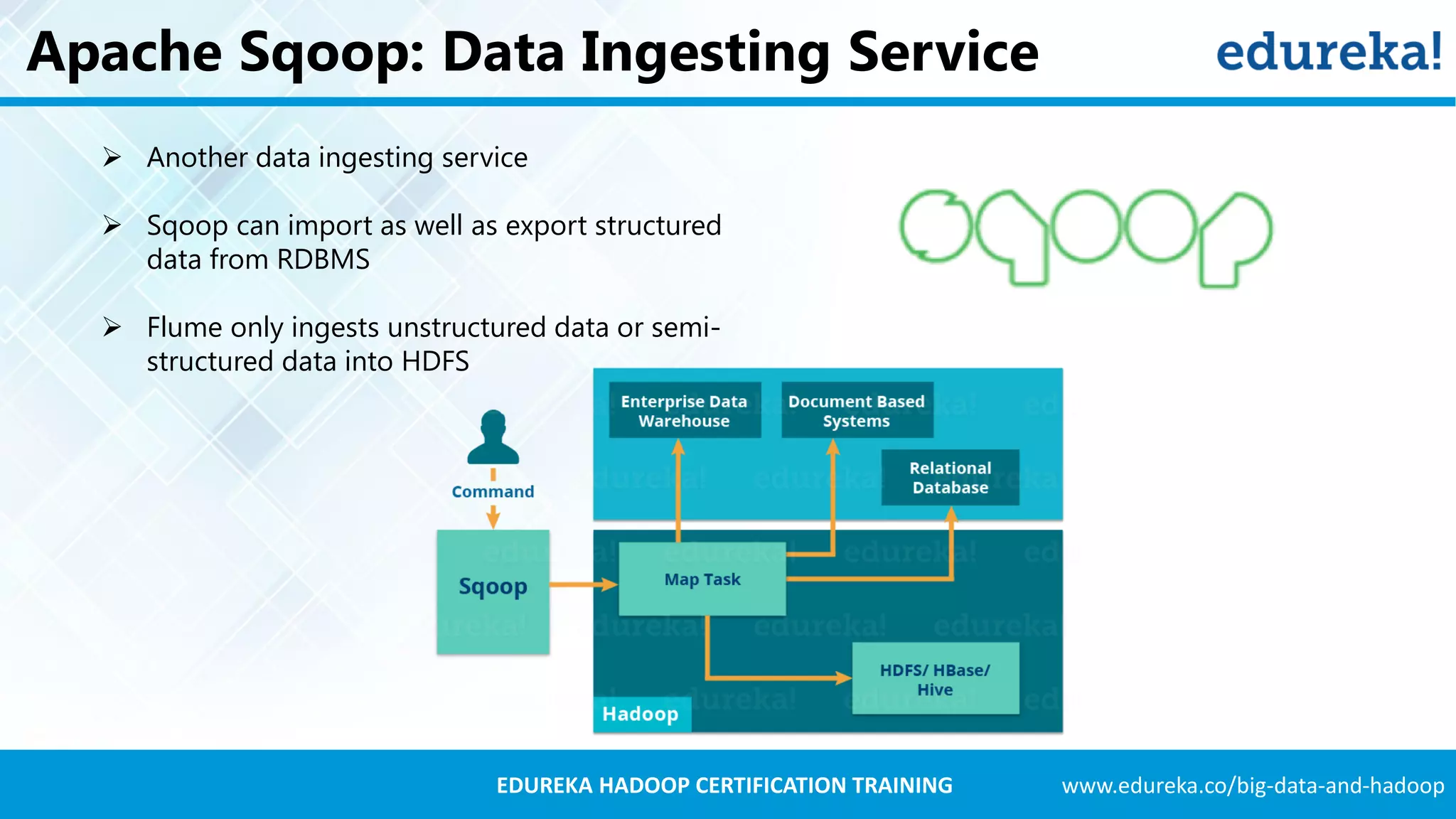
Flume and Sqoop ingest both unstructured and structured data into Hadoop; Flume focuses on unstructured data.
Apache Solr and Lucene assist in searching and indexing data within Hadoop, utilizing Lucene's capabilities.
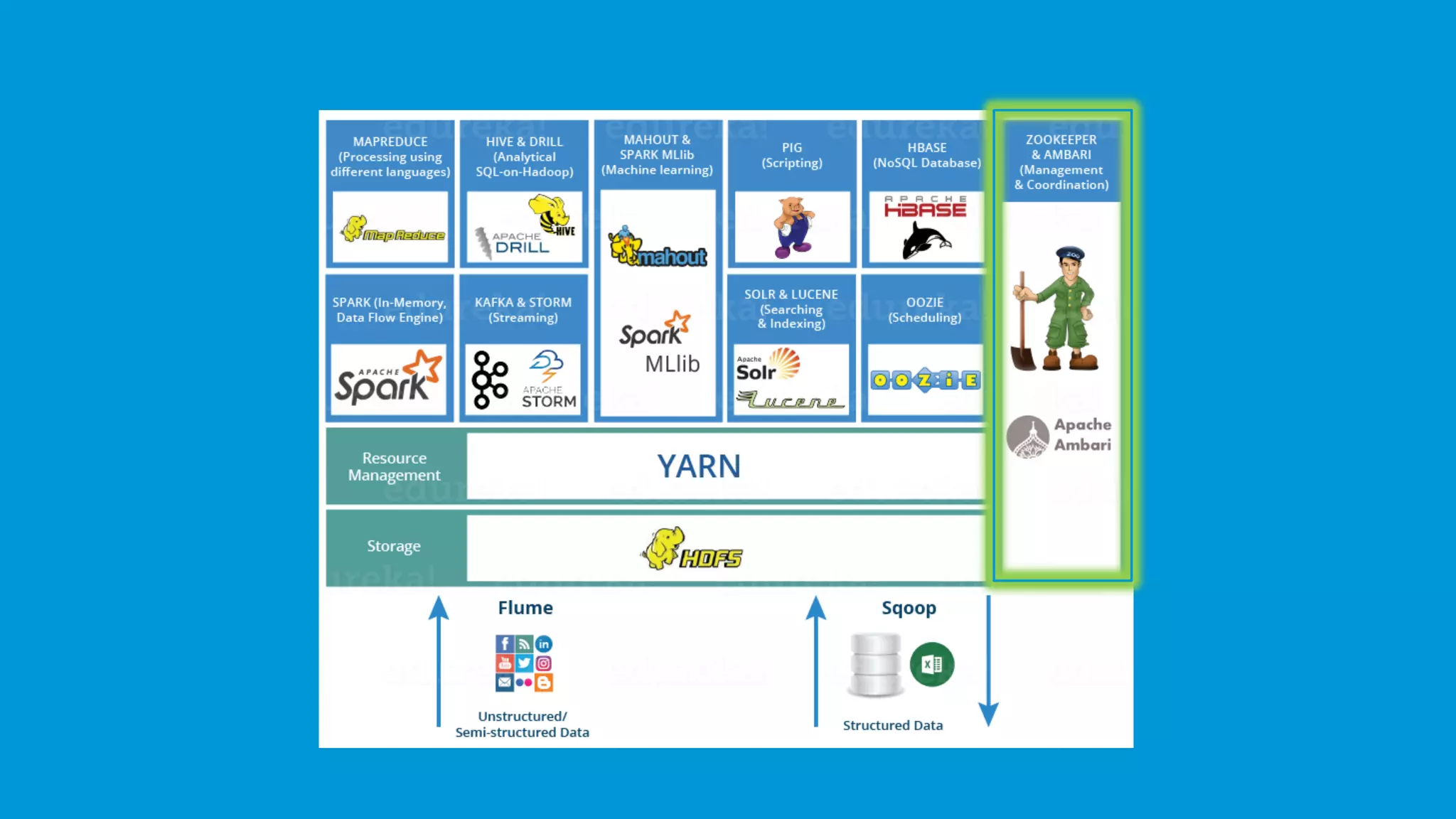
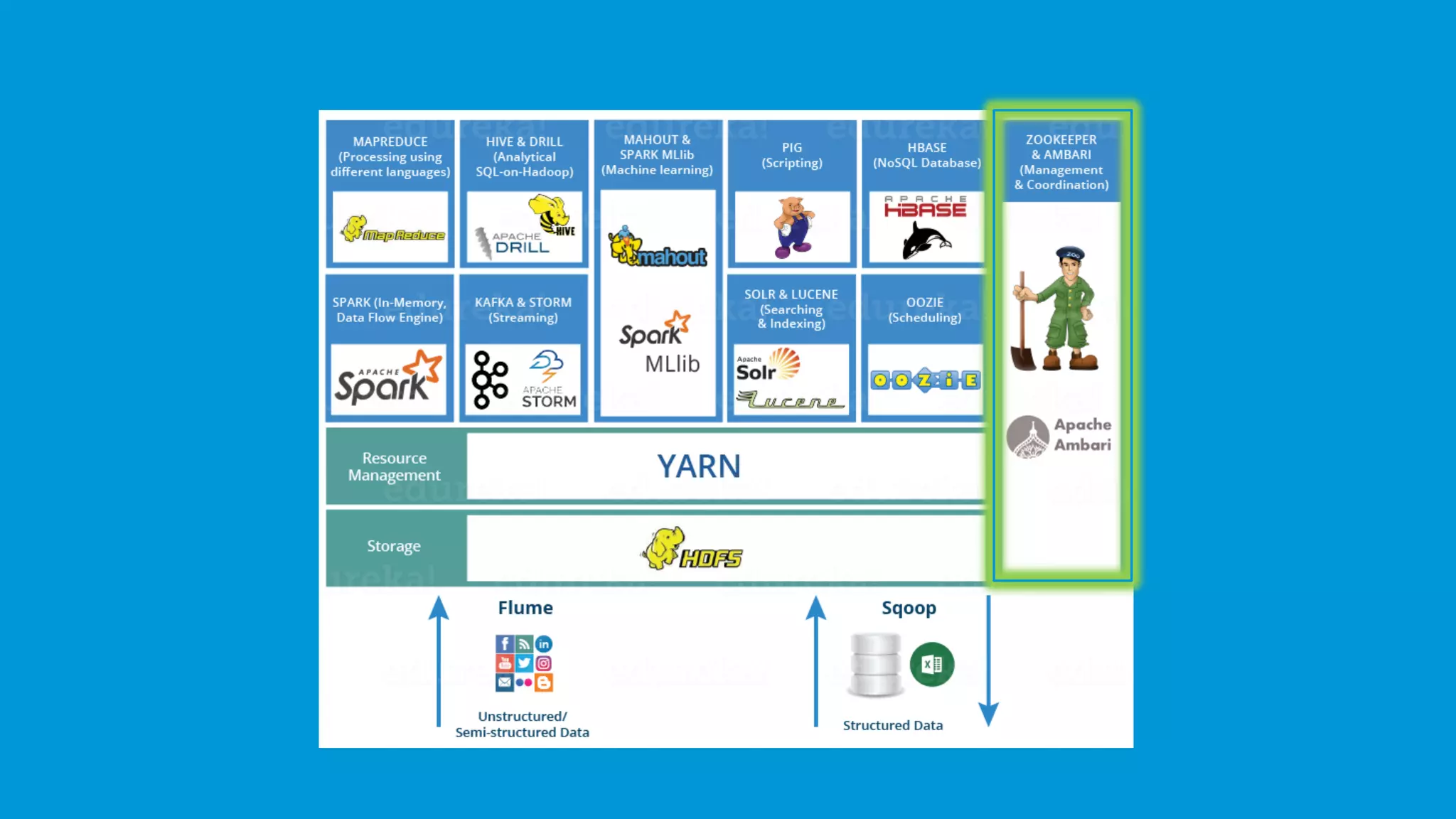
ZooKeeper provides reliable coordination and synchronization in Hadoop's distributed environment.
Ambari facilitates the management of Hadoop clusters, offering provisioning, monitoring, and management services.
Acknowledgment and references to additional learning resources related to Hadoop.