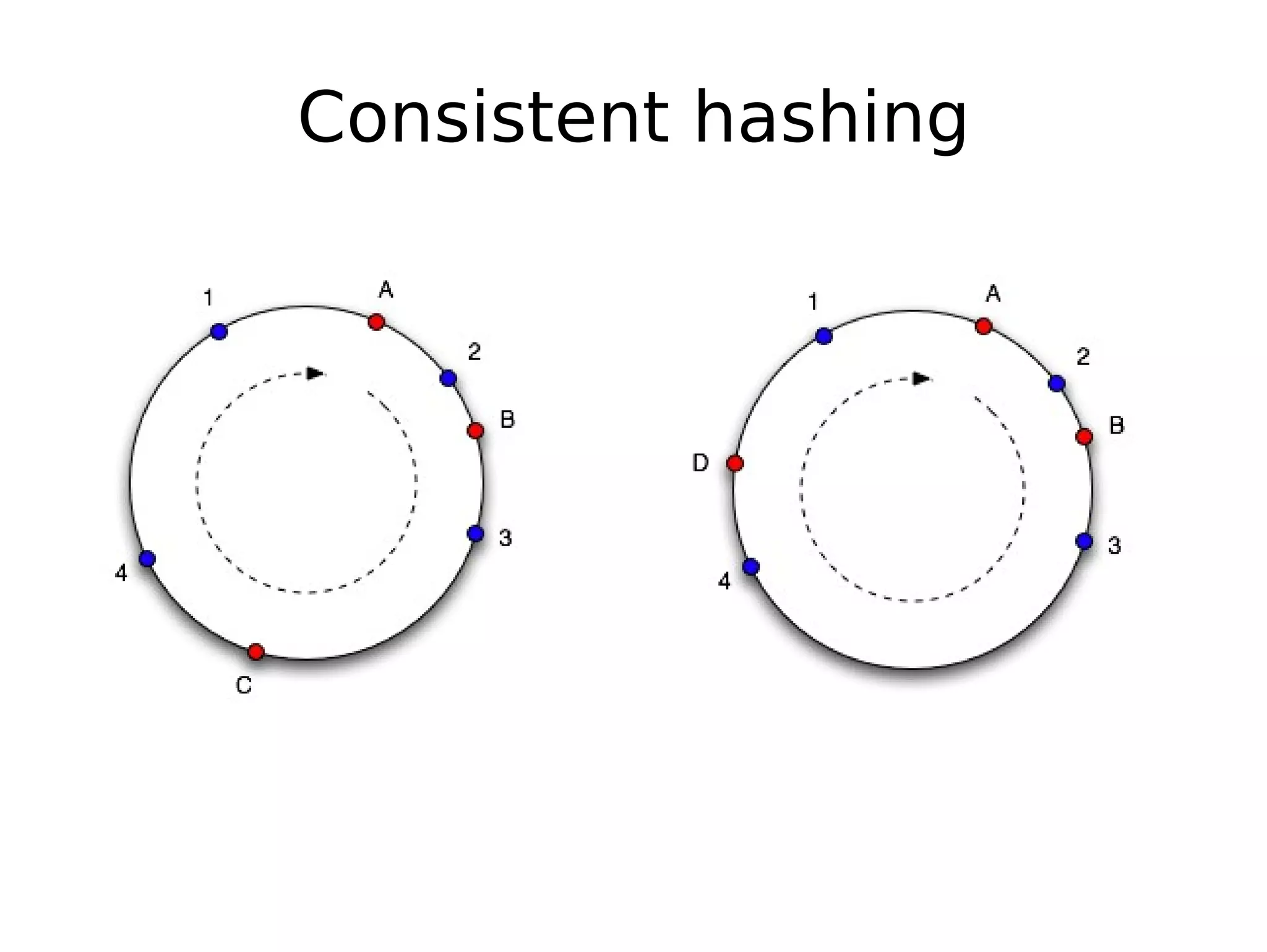
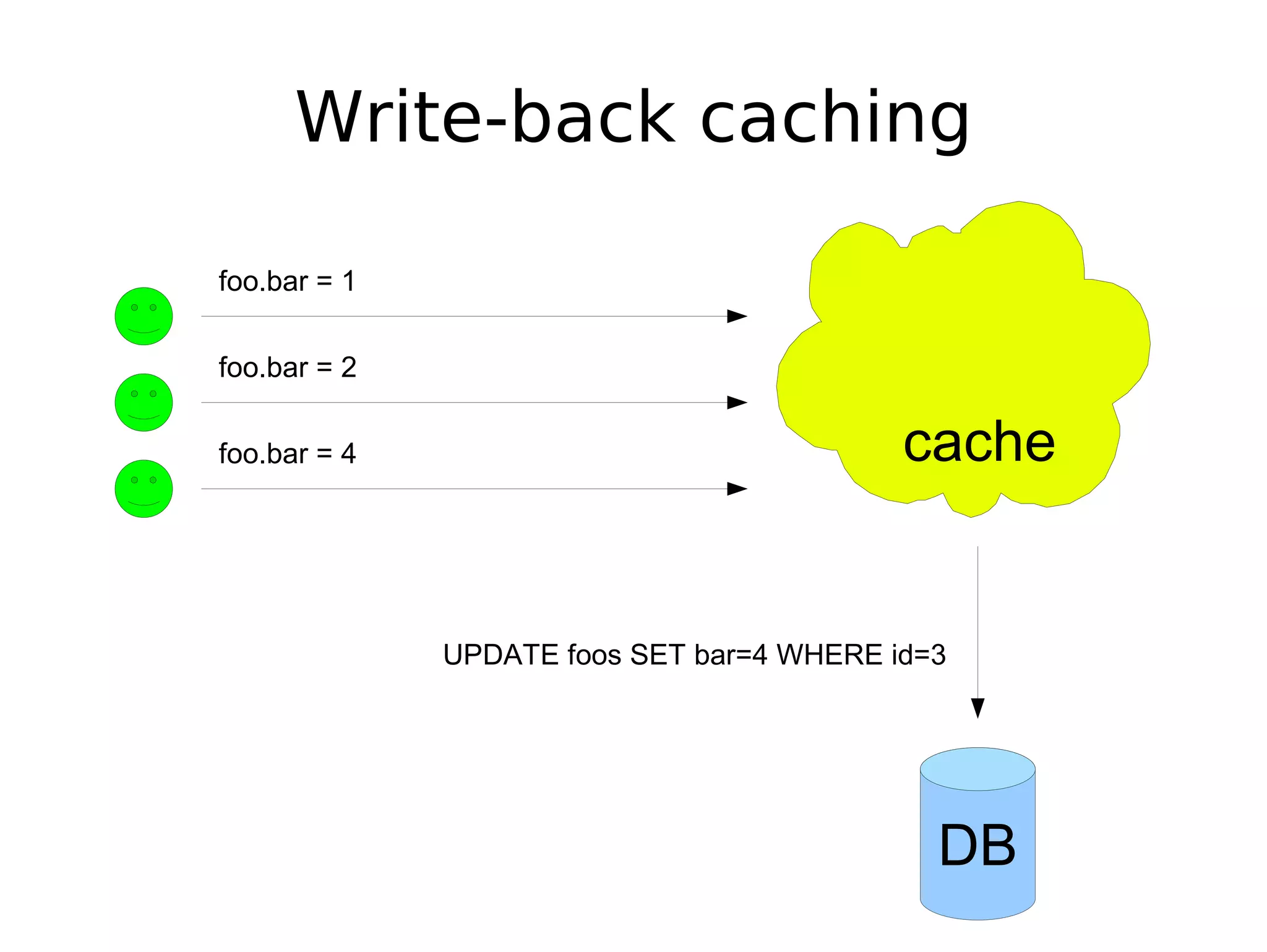
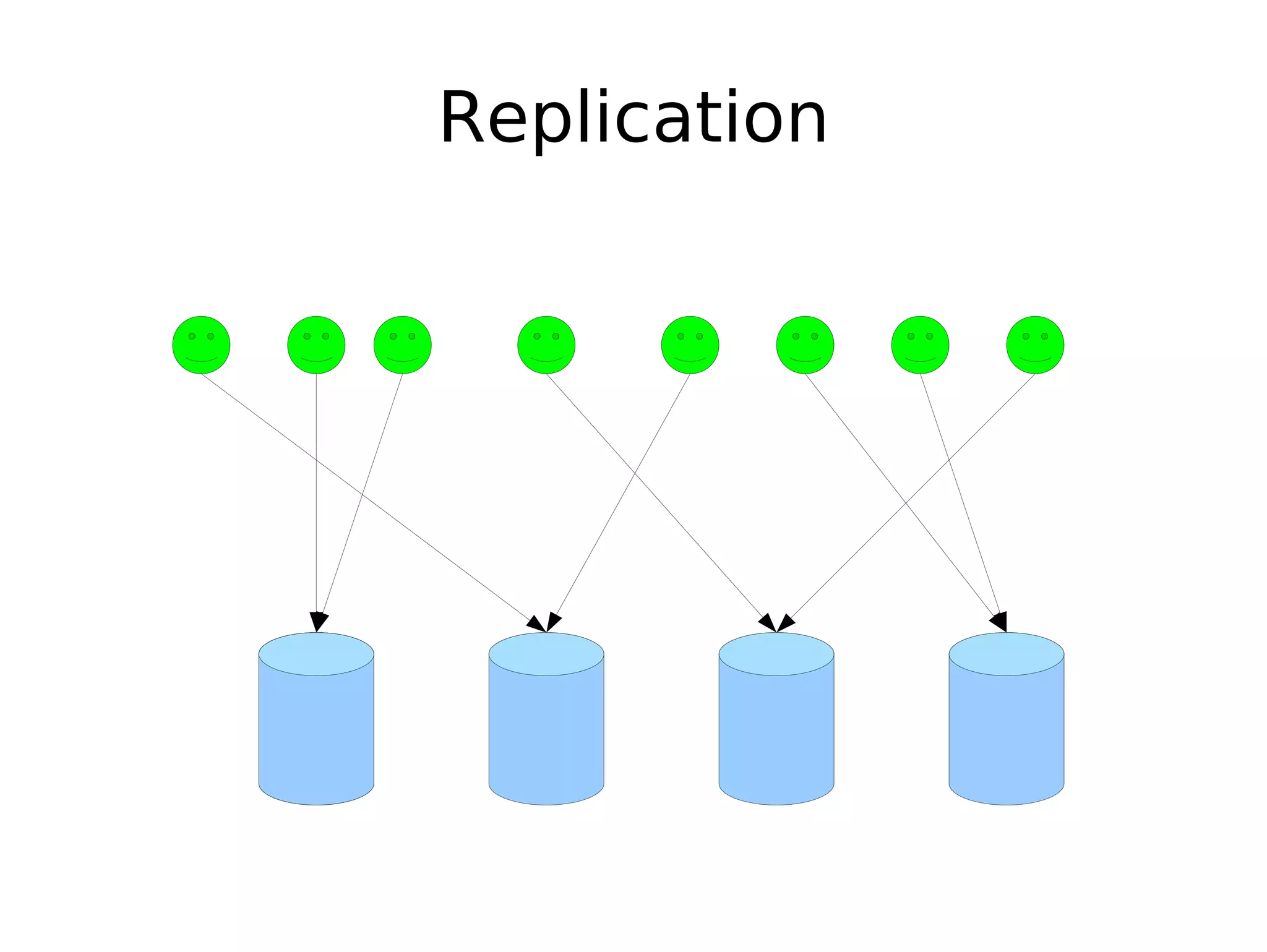
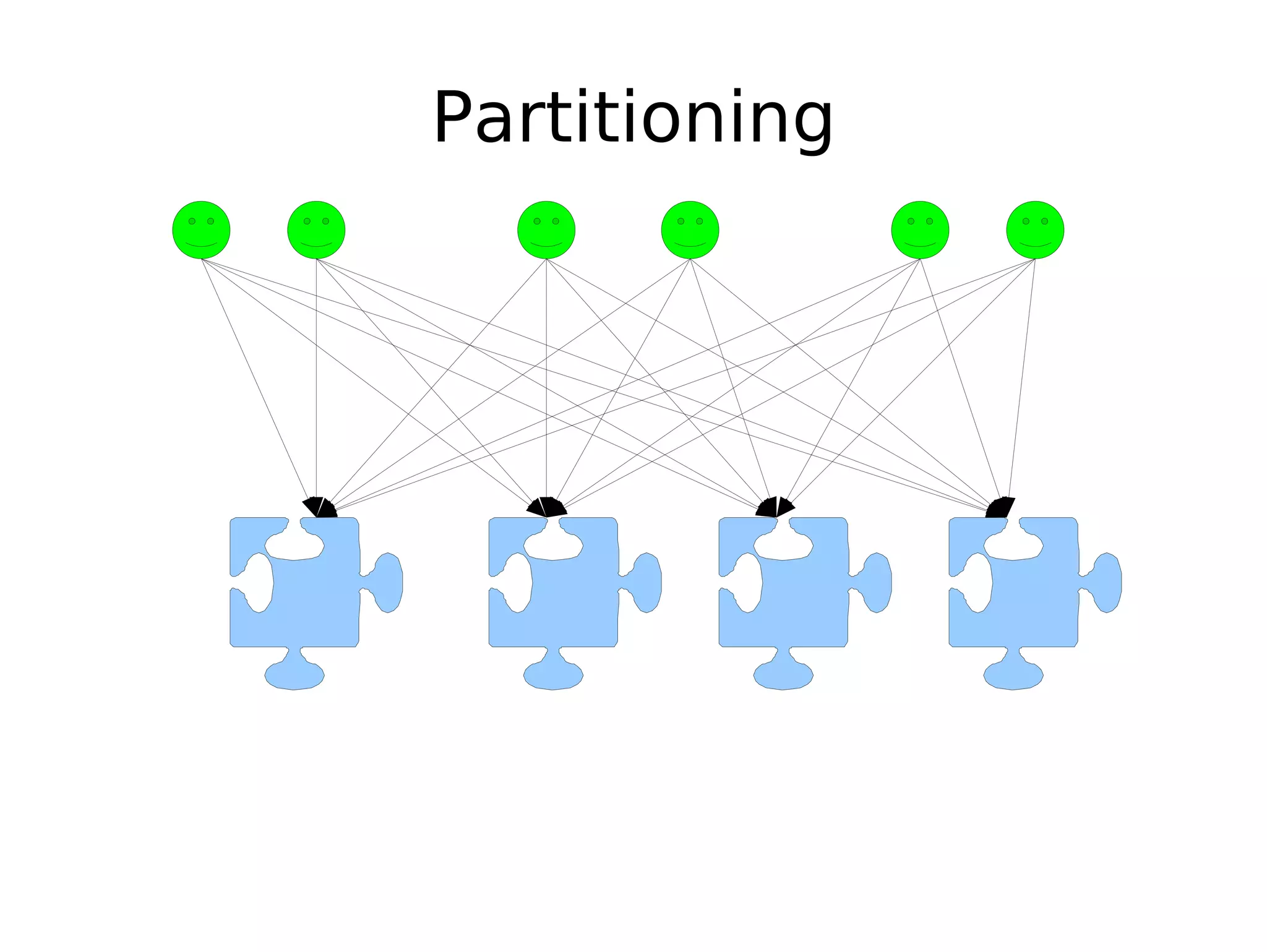
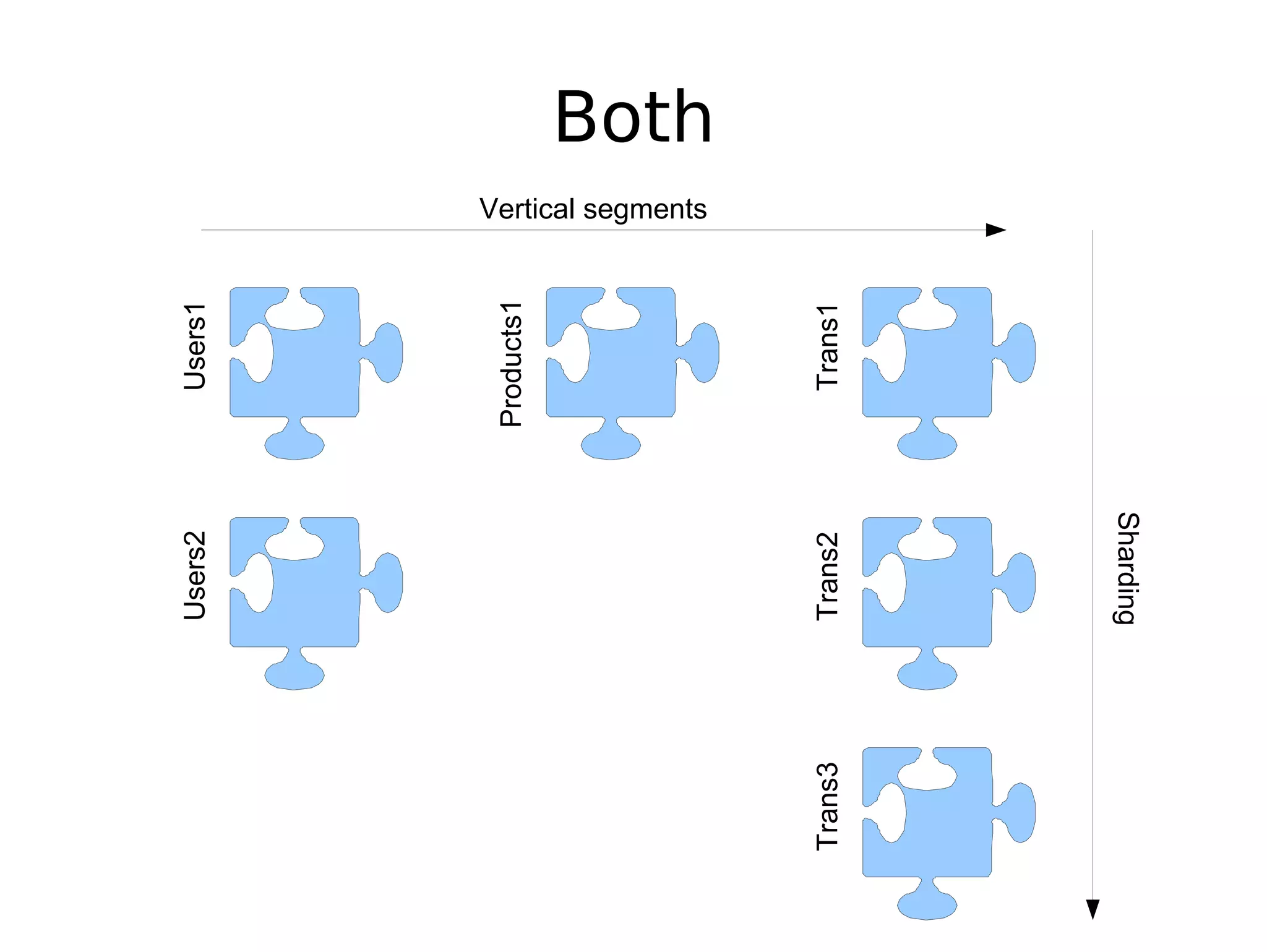
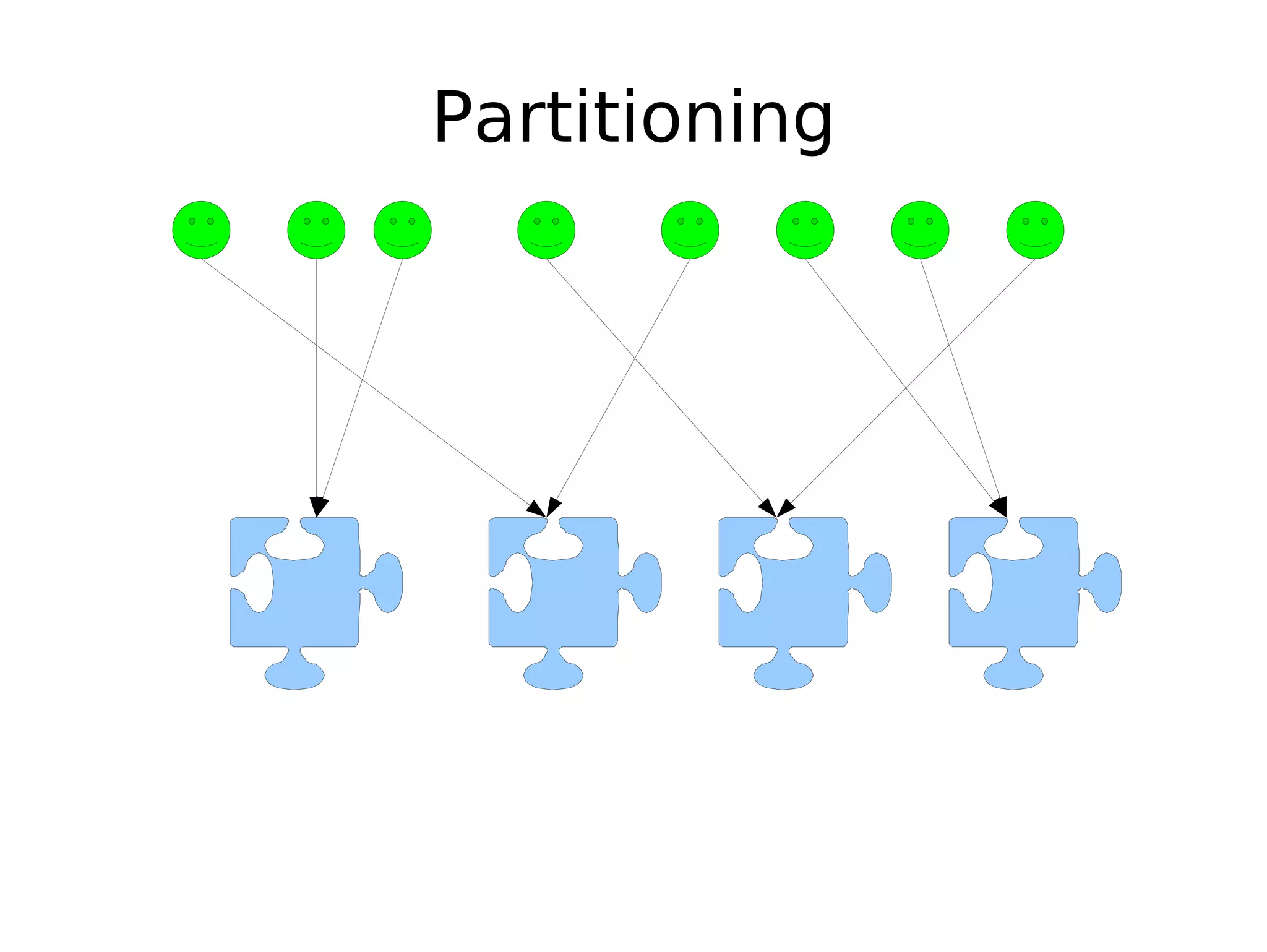
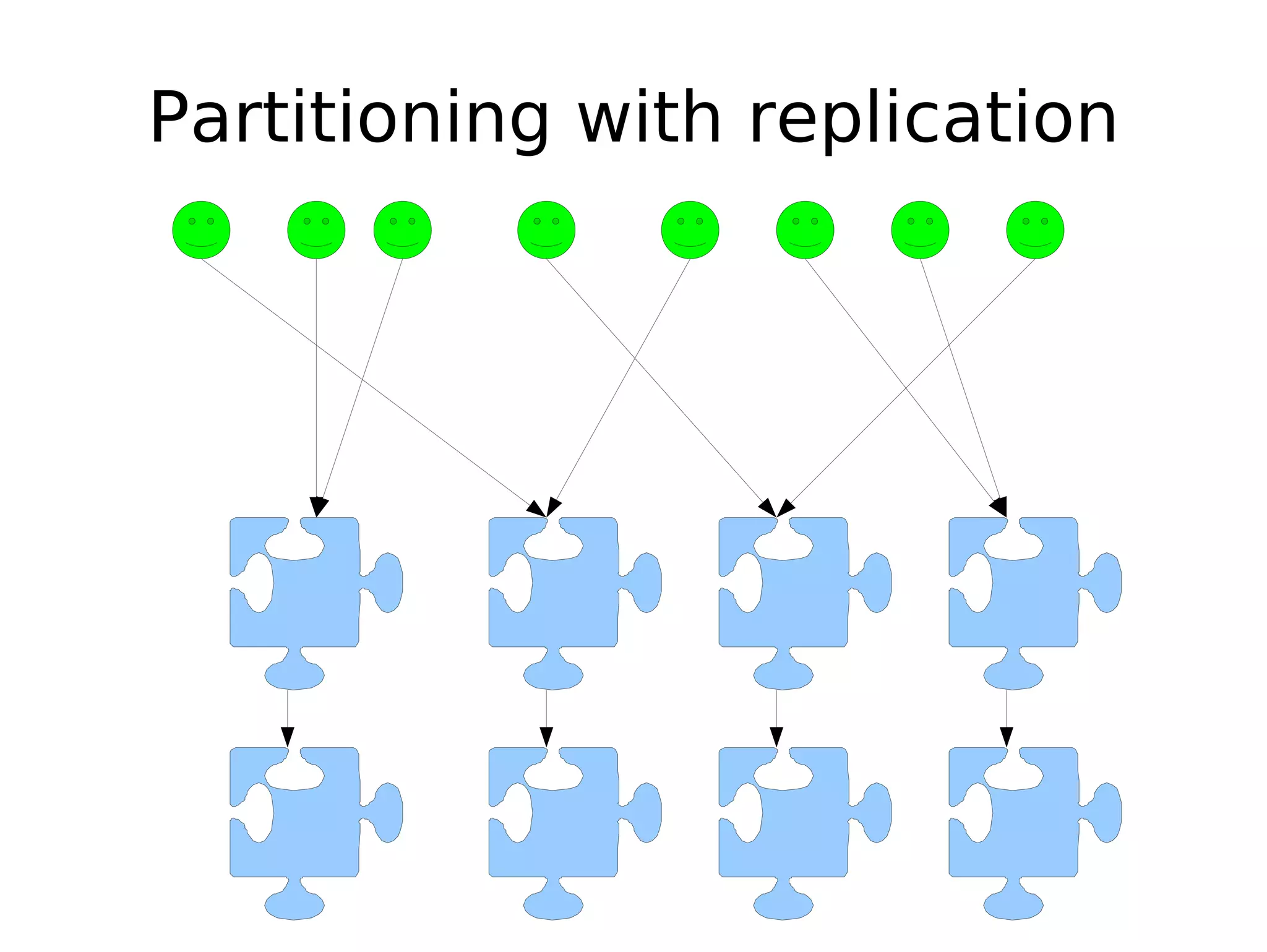
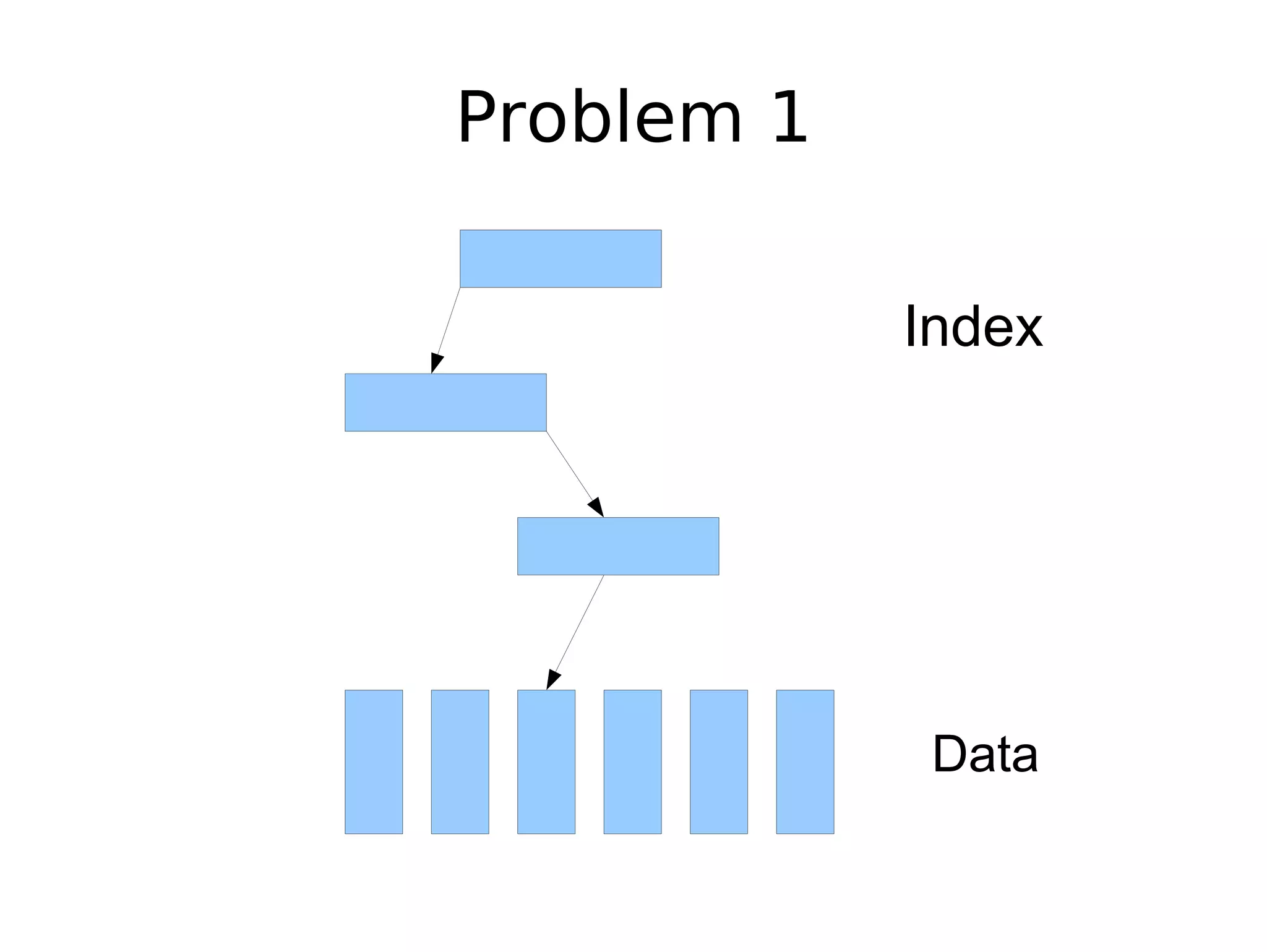
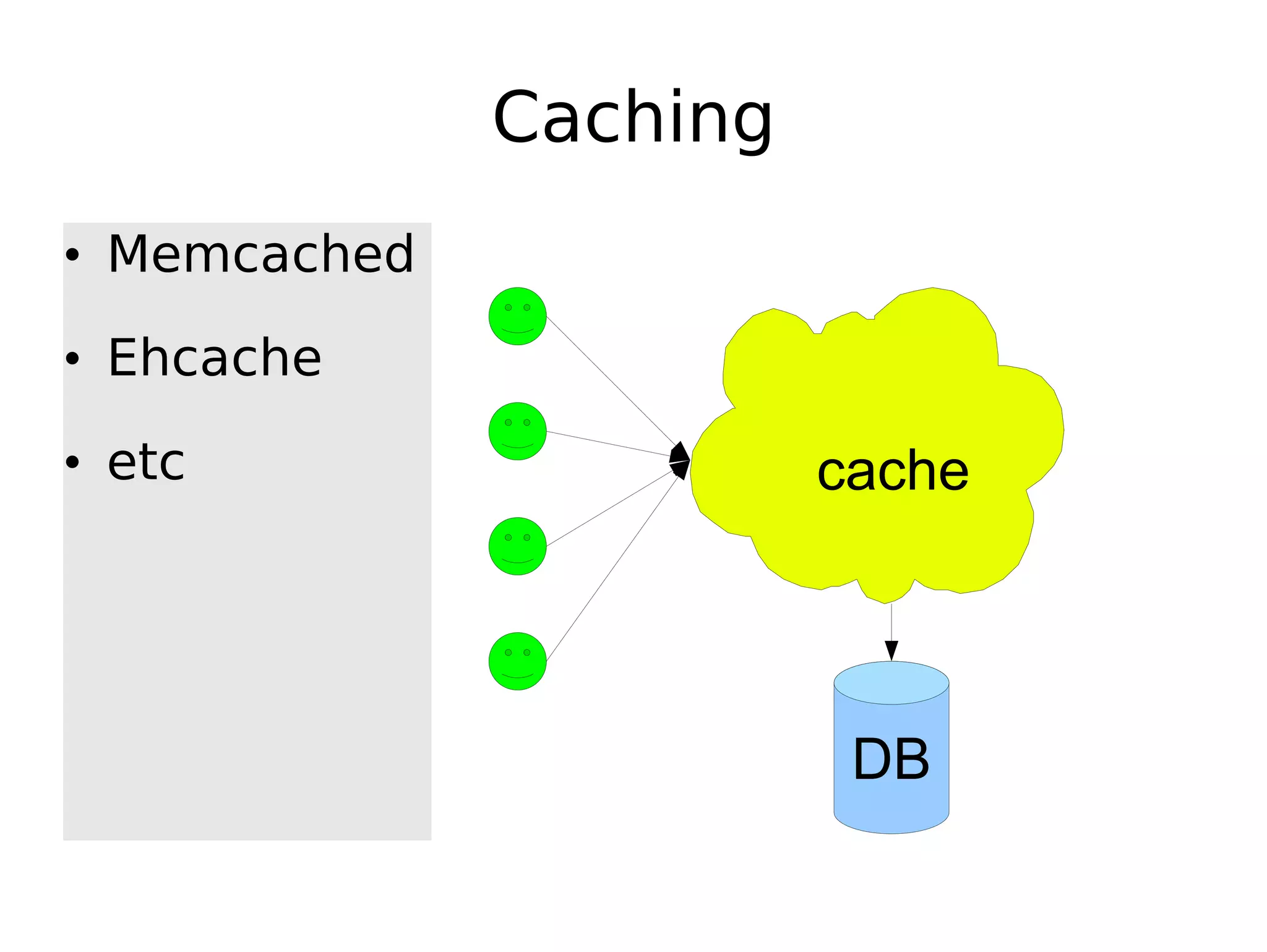
The document discusses the challenges of scaling databases and provides strategies for improving scalability. It covers: 1) The two main types of database operations that need to be scaled are reads and writes. Common "band-aid" approaches that don't actually scale the database are discussed. 2) Scaling reads can be improved through caching, partitioning caches, and replication. Scaling writes is more difficult and requires approaches like write-back caching, asynchronous replication, and data partitioning. 3) Partitioning data through sharding or vertical partitioning distributes the load across multiple database nodes. Consistent hashing is presented as a method to determine which server owns each data key. The challenges of non-transparent partitioning approaches are also










![Partitioning a (read) cache i = hash(key) % len(servers) server = servers[i]](https://image.slidesharecdn.com/databasescalability2010-100219145240-phpapp01/75/What-every-developer-should-know-about-database-scalability-PyCon-2010-14-2048.jpg)