Download as PDF, PPTX

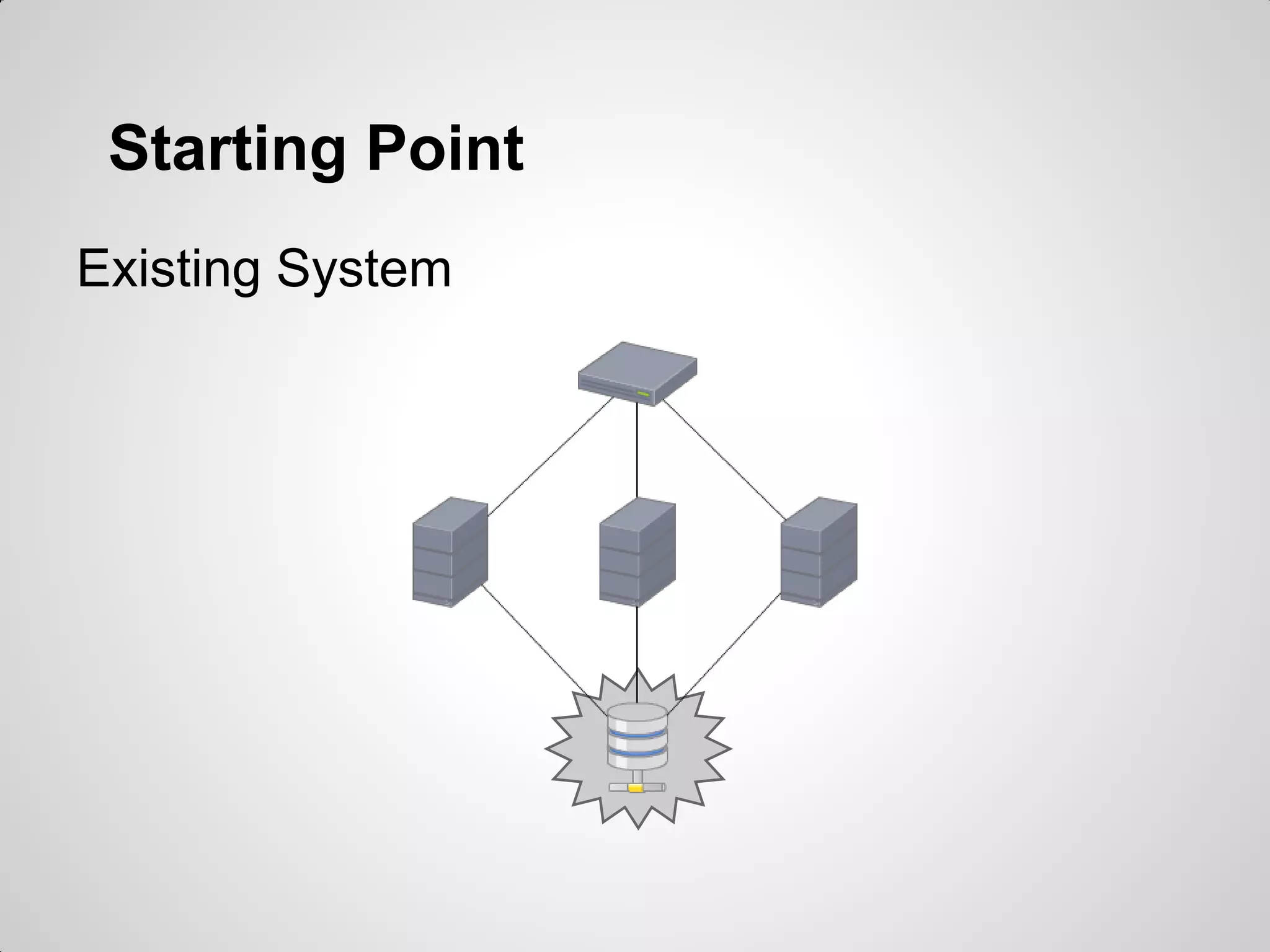



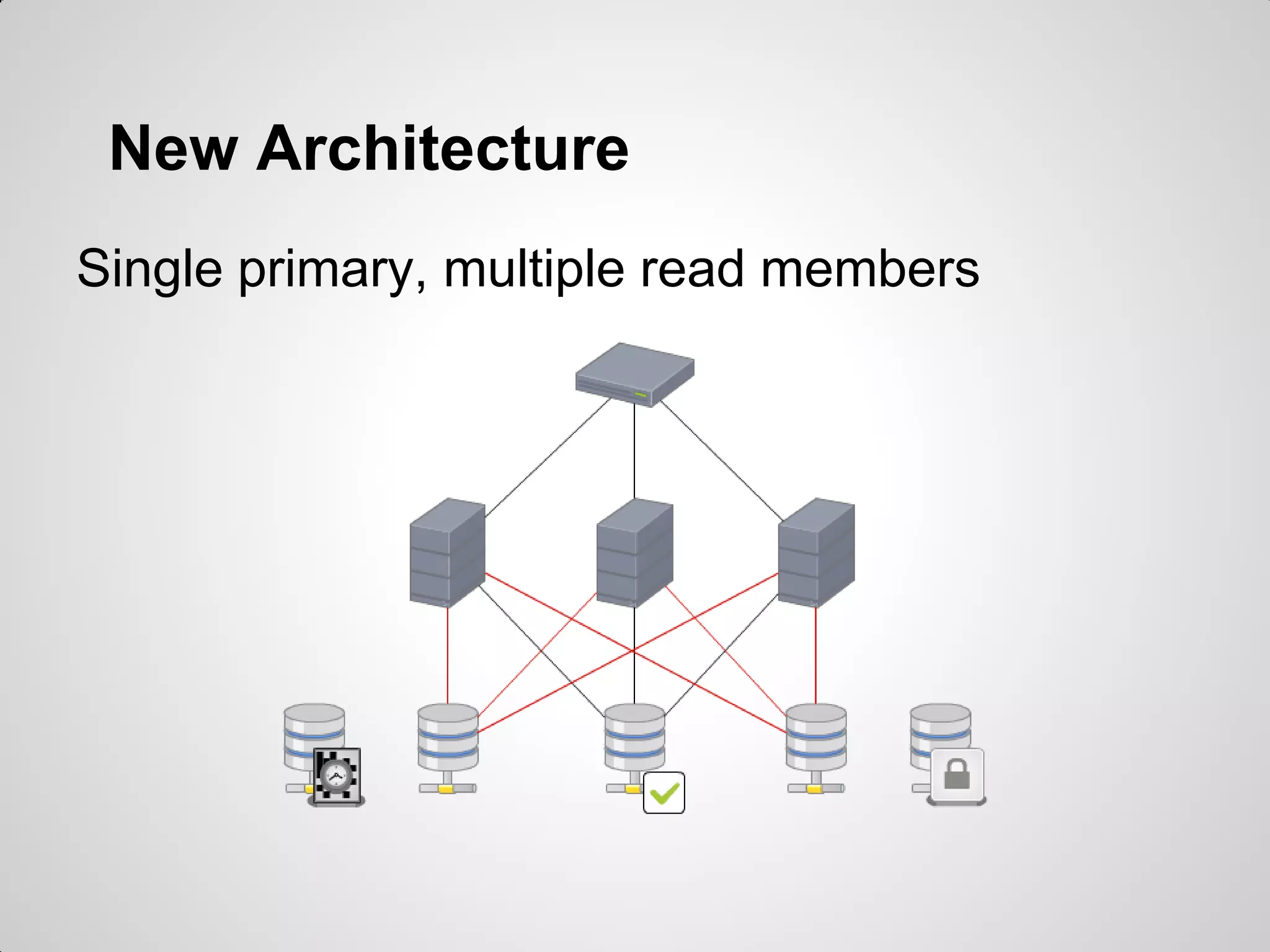

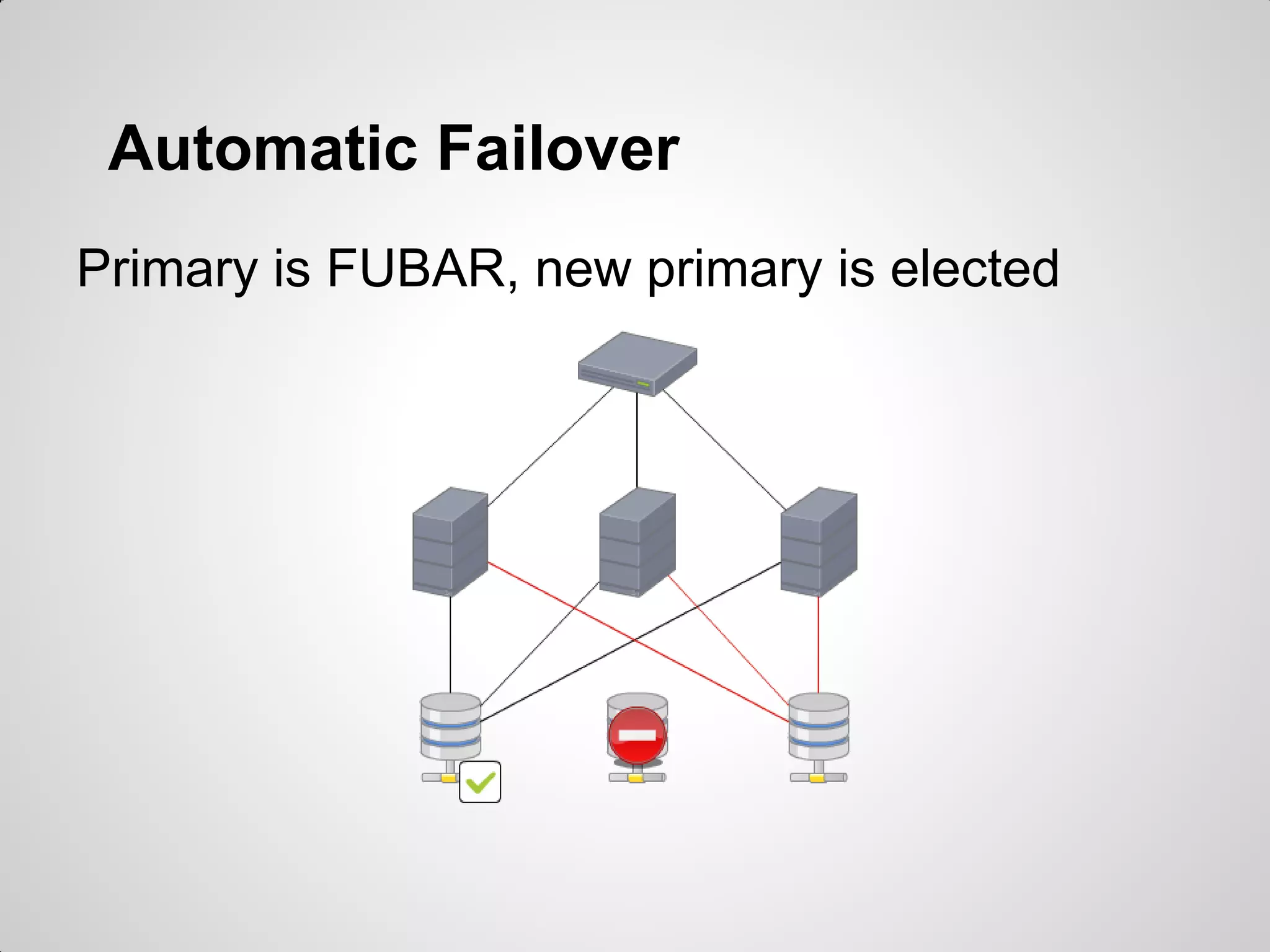


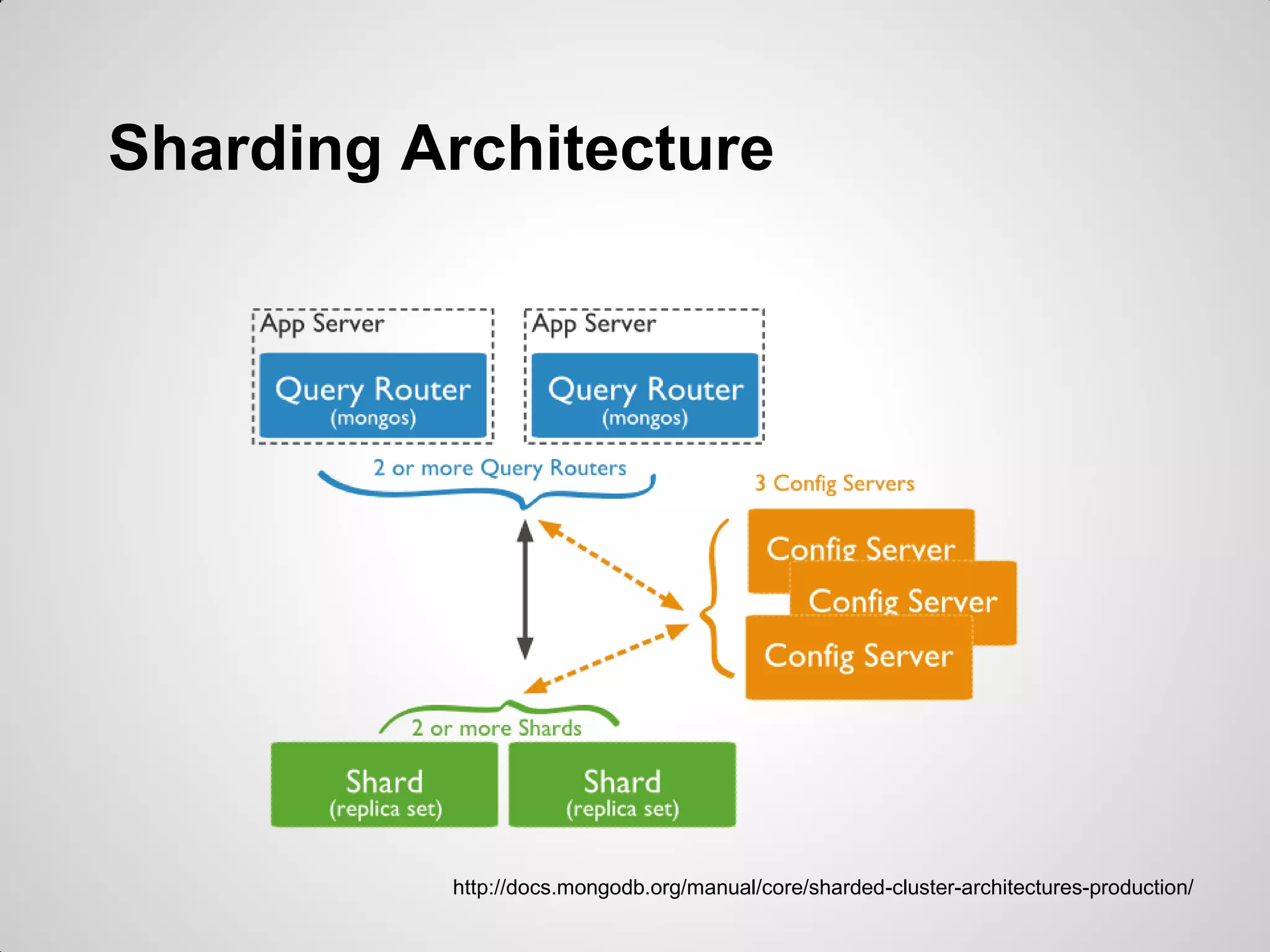





MongoDB was chosen to replace an existing MySQL system due to its high performance for worldwide access across multiple locations, simple usage without needing a DBA, and ability to do real-time reporting without impacting production. MongoDB uses a document-oriented model and simple querying of JSON, supports availability and automatic failover between replica sets, and was considered a better fit than alternative NoSQL databases for the project's requirements without needing to implement complex sharding.