Downloaded 16 times



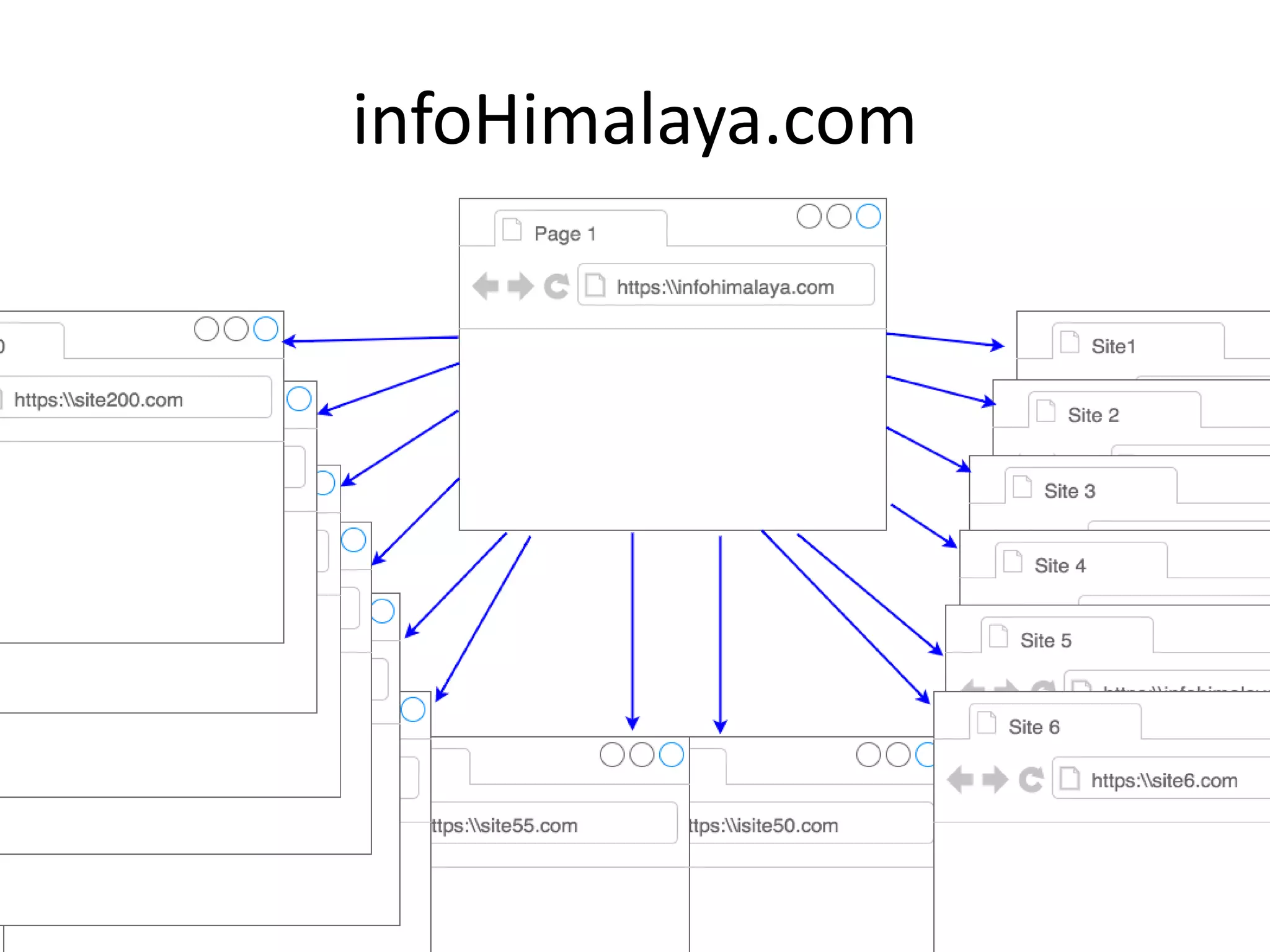







This document discusses web scraping technologies, detailing what scraping is and its purposes such as data extraction for business intelligence. It covers essential tools and libraries for web scraping, as well as challenges like server throttling and captcha. The document also provides tips for effective scraping and mentions applications like the Scrapy framework.