Download as PDF, PPTX



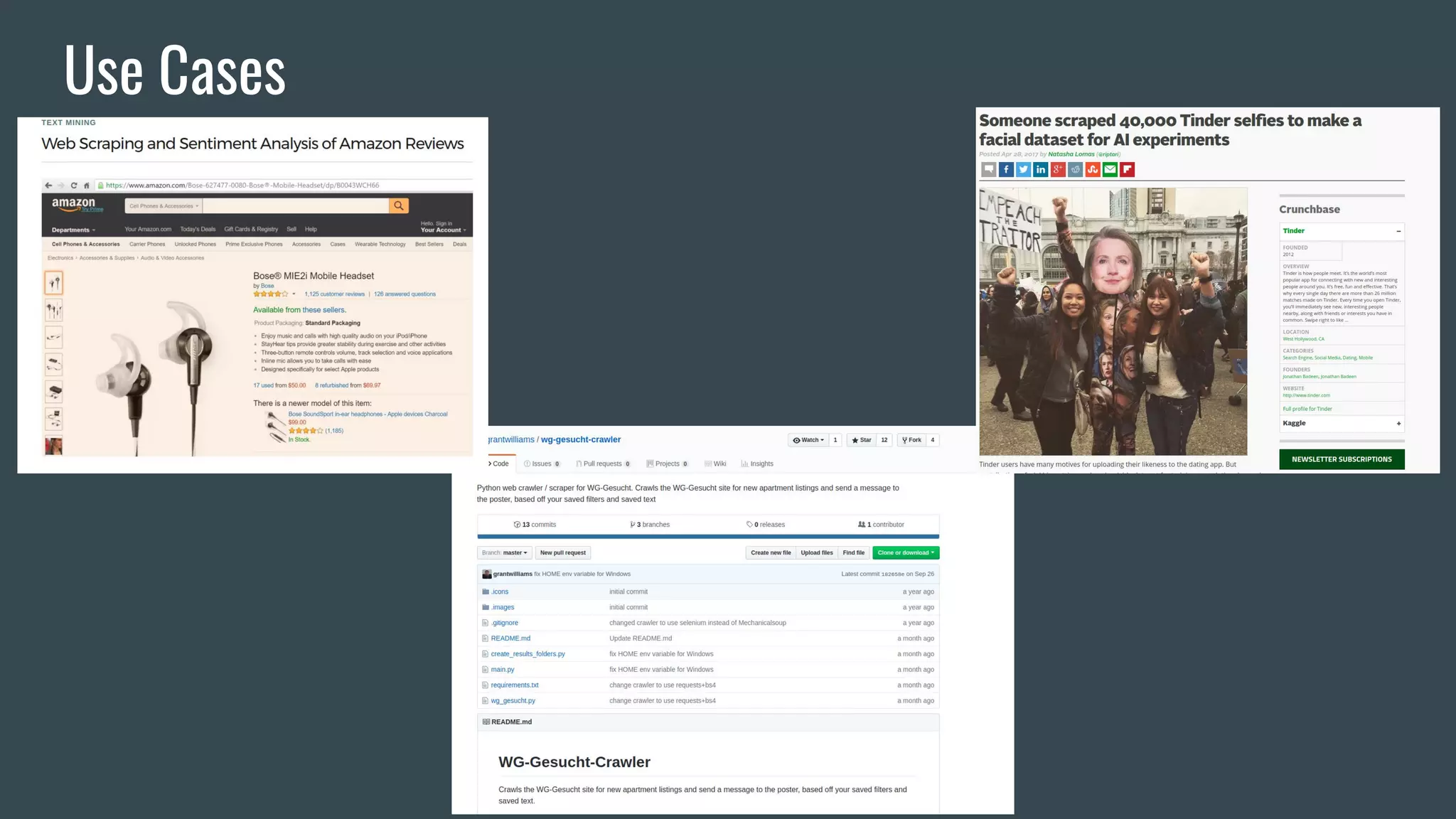








The document discusses web scraping using Scrapy and Beautiful Soup, highlighting their use in extracting and structuring data from websites. It emphasizes the importance of ethical scraping practices and the potential pitfalls, such as dealing with JavaScript-heavy sites and respecting robots.txt files. Additionally, it presents email marketing for customer acquisition as a use case for scraping, mentioning techniques to improve email list quality.