Descargar como PDF, PPTX









![Regular expressions [A-Z] matches a capital letter [0-9] matches a number [a-z][0-9] matches a lowercase letter followed by a number star * matches the previous item 0 or more times plus + matches the previous item 1 or more times dot . will match anything but line break characters r n question ? makes the preceeding item optional](https://image.slidesharecdn.com/scraping-theweb-151130183948-lva1-app6891/75/Scraping-the-web-with-python-13-2048.jpg)












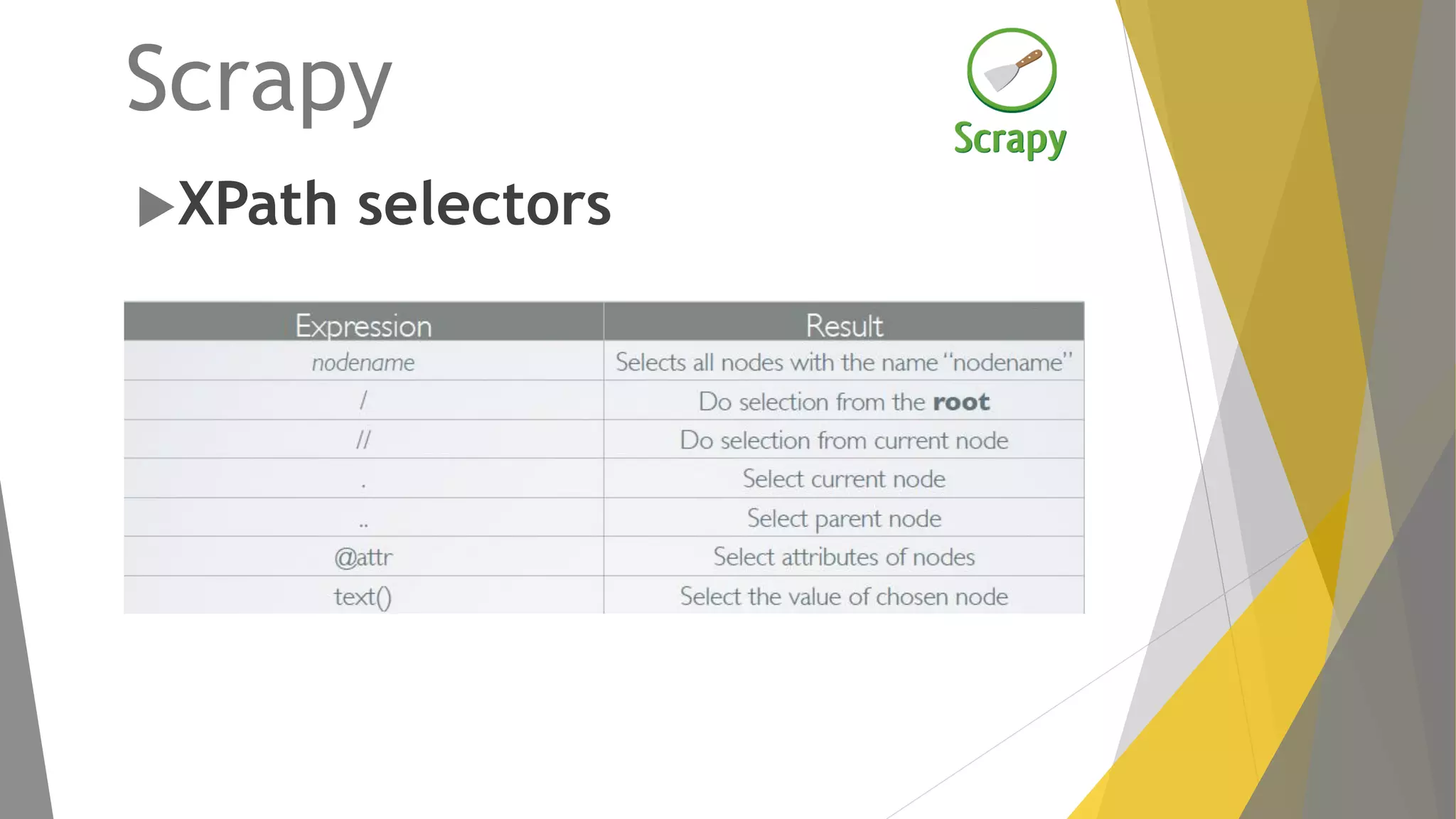
![Xpath selectors Expression Meaning name matches all nodes on the current level with the specified name name[n] matches the nth element on the current level with the specified name / Do selection from the root // Do selection from current node * matches all nodes on the current level . Or .. Select current / parent node @name the attribute with the specified name [@key='value'] all elements with an attribute that matches the specified key/value pair name[@key='value'] all elements with the specified name and an attribute that matches the specified key/value pair [text()='value'] all elements with the specified text name[text()='value'] all elements with the specified name and text](https://image.slidesharecdn.com/scraping-theweb-151130183948-lva1-app6891/75/Scraping-the-web-with-python-32-2048.jpg)



![Scrapy Shell (no es necesario crear proyecto) scrapy shell <url> from scrapy.select import Selector hxs = Selector(response) Info = hxs.select(‘//div[@class=“slot-inner”]’)](https://image.slidesharecdn.com/scraping-theweb-151130183948-lva1-app6891/75/Scraping-the-web-with-python-38-2048.jpg)




![Pipeline ITEM_PIPELINES = [‘<your_project_name>.pipelines.<your_pipeline_classname>'] pipelines.py](https://image.slidesharecdn.com/scraping-theweb-151130183948-lva1-app6891/75/Scraping-the-web-with-python-45-2048.jpg)










![Mechanize import mechanize # service url URL = ‘’ def main(): # Create a Browser instance b = mechanize.Browser() # Load the page b.open(URL) # Select the form b.select_form(nr=0) # Fill out the form b[key] = value # Submit! return b.submit()](https://image.slidesharecdn.com/scraping-theweb-151130183948-lva1-app6891/75/Scraping-the-web-with-python-59-2048.jpg)



















![Scrapy Cloud /scrapy.cfg # Project: demo [deploy] url =https://dash.scrapinghub.com/api/scrapyd/ #API_KEY username = ec6334d7375845fdb876c1d10b2b1622 password = project = 25767](https://image.slidesharecdn.com/scraping-theweb-151130183948-lva1-app6891/75/Scraping-the-web-with-python-97-2048.jpg)



El documento presenta un taller sobre técnicas de scraping web utilizando Python, abordando bibliotecas como BeautifulSoup, Scrapy, Mechanize y Selenium. Se exploran metodologías para extraer datos de páginas web automáticamente, junto con ejemplos prácticos y el uso de expresiones XPath para la selección de elementos. También se menciona la instalación y configuración de herramientas necesarias para llevar a cabo estos procesos de extracción de datos.
Introducción al taller sobre scraping web y técnicas como screen scraping, web scraping, report mining y spider.
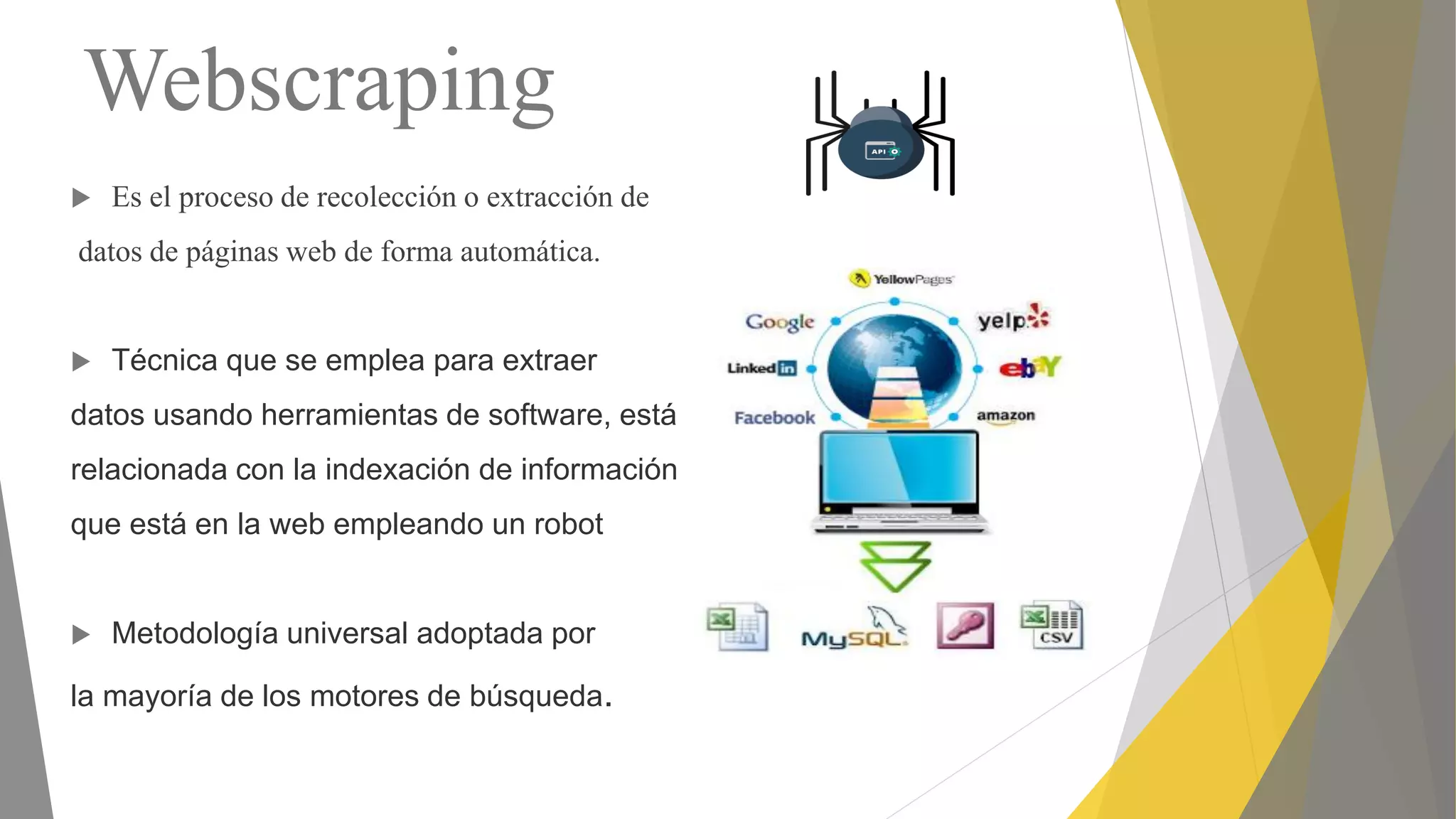
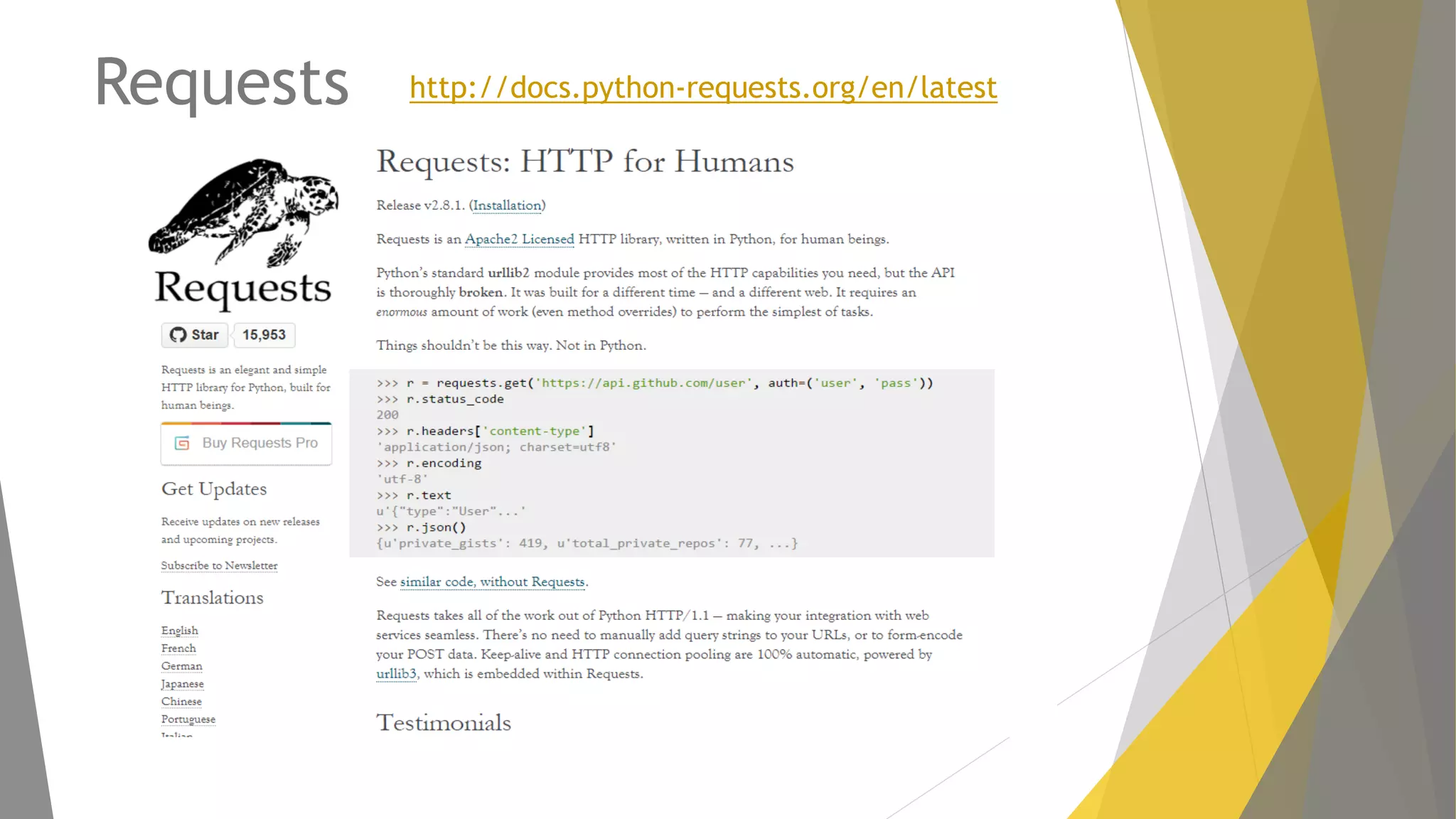
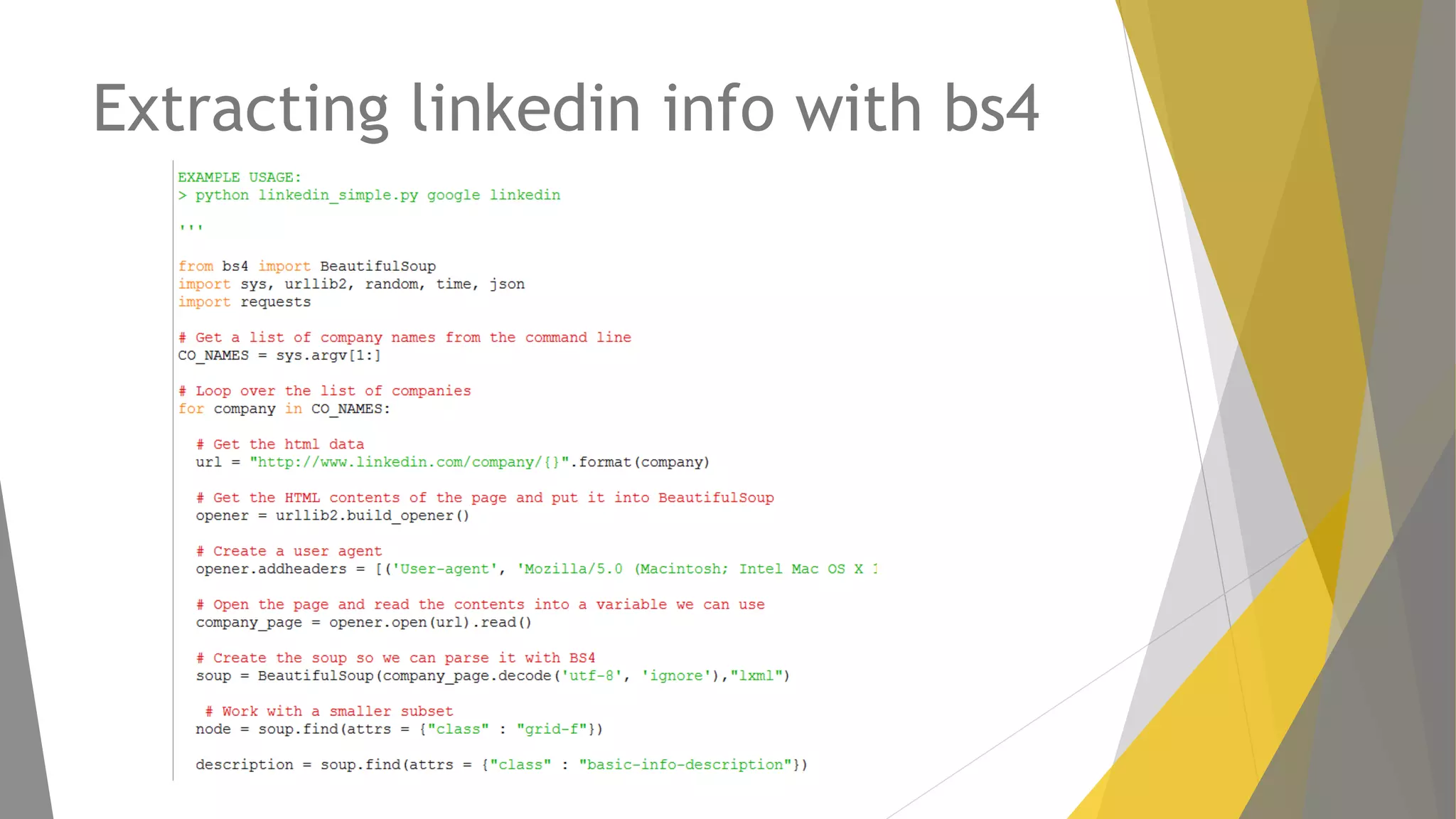
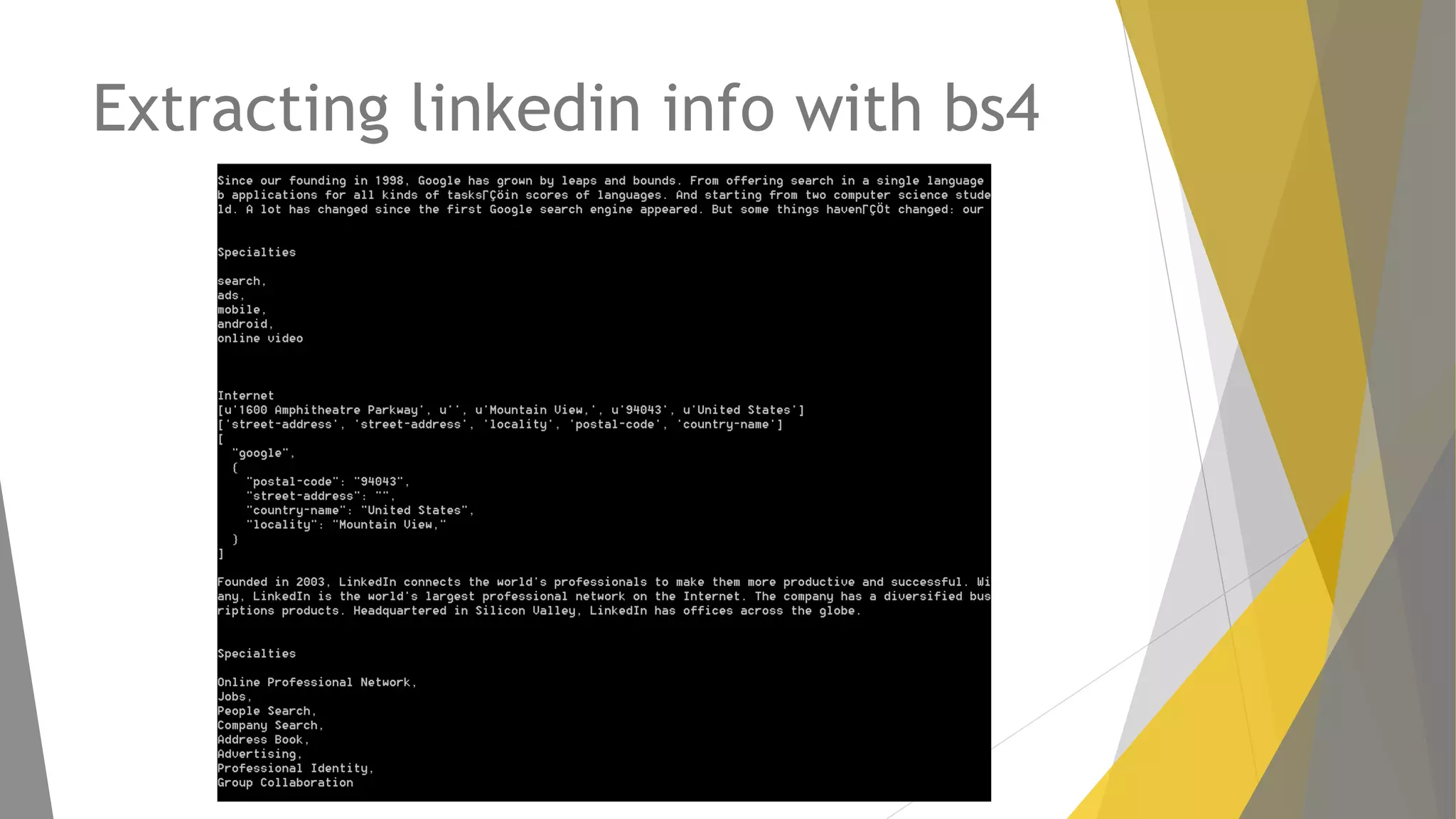
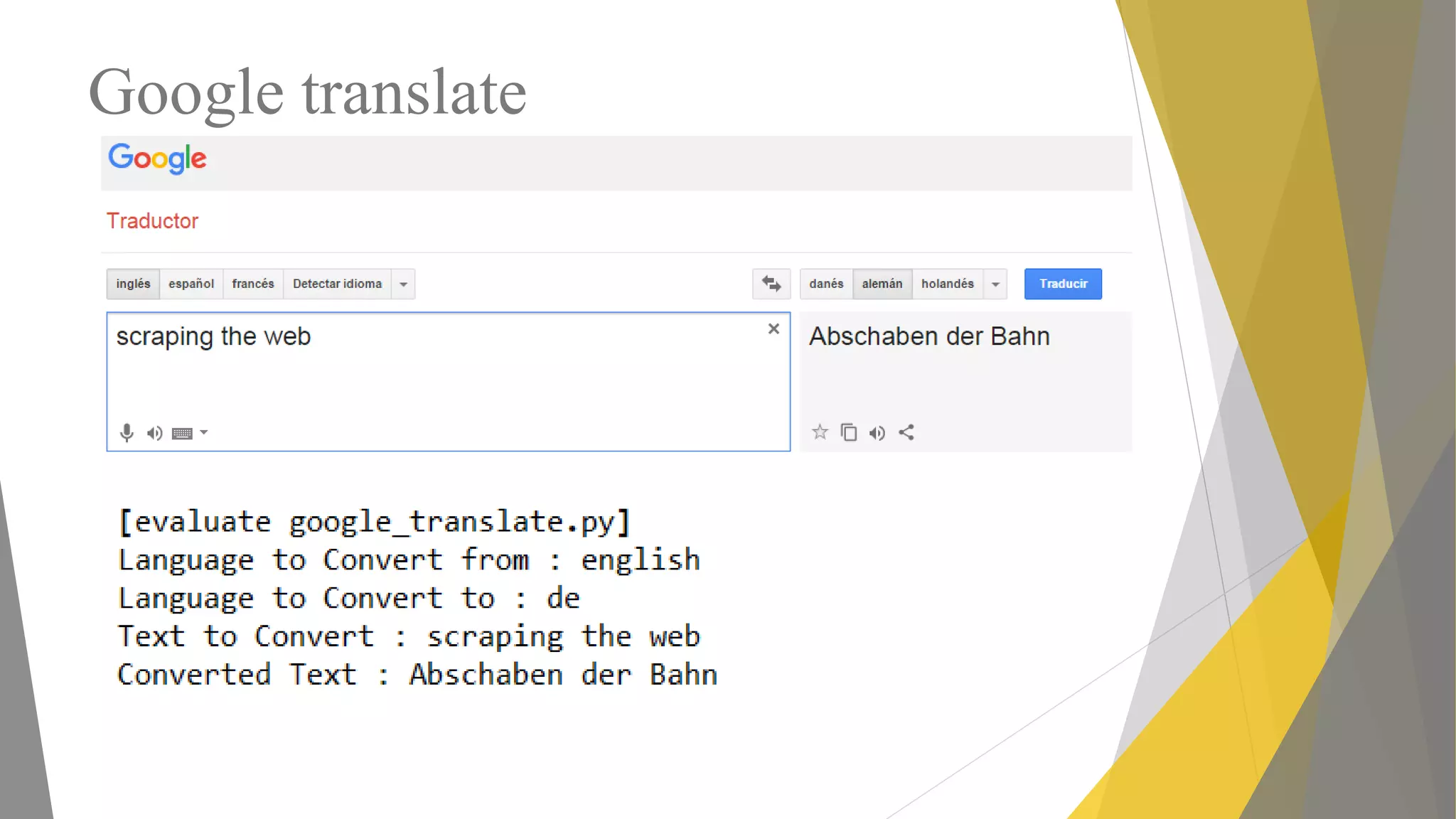
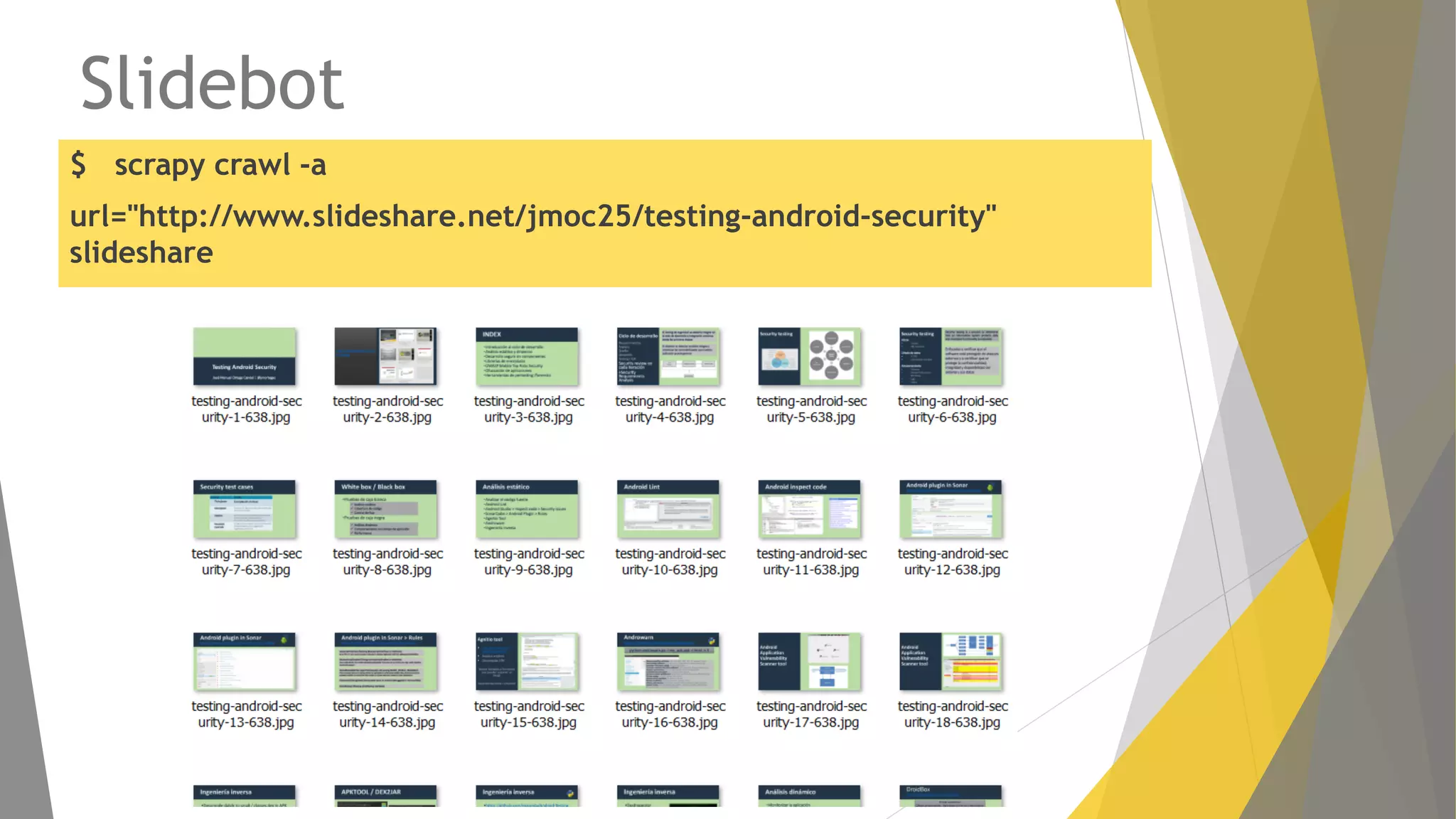
Descripción de web scraping con Python, librerías populares como Requests y BeautifulSoup.
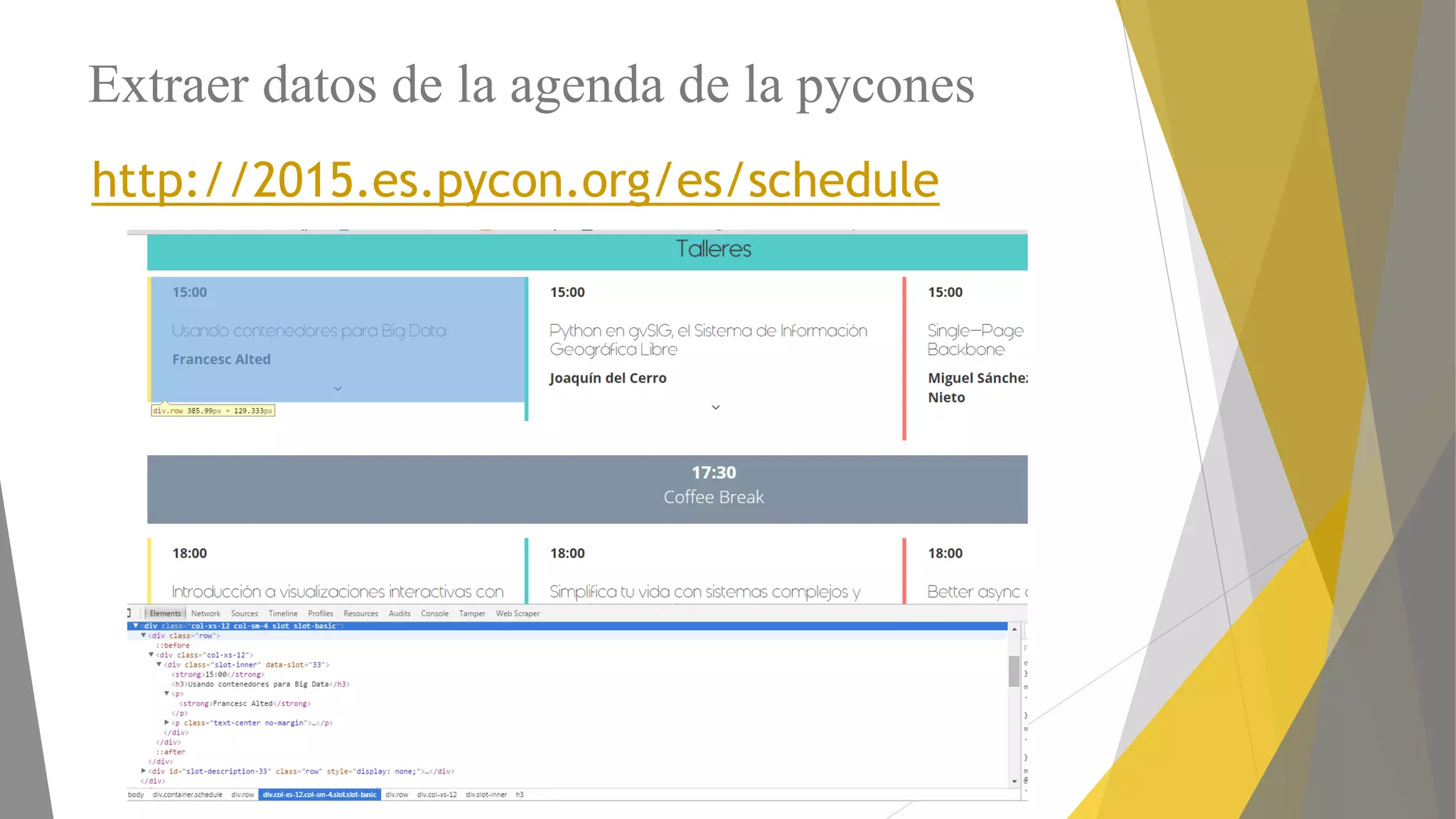
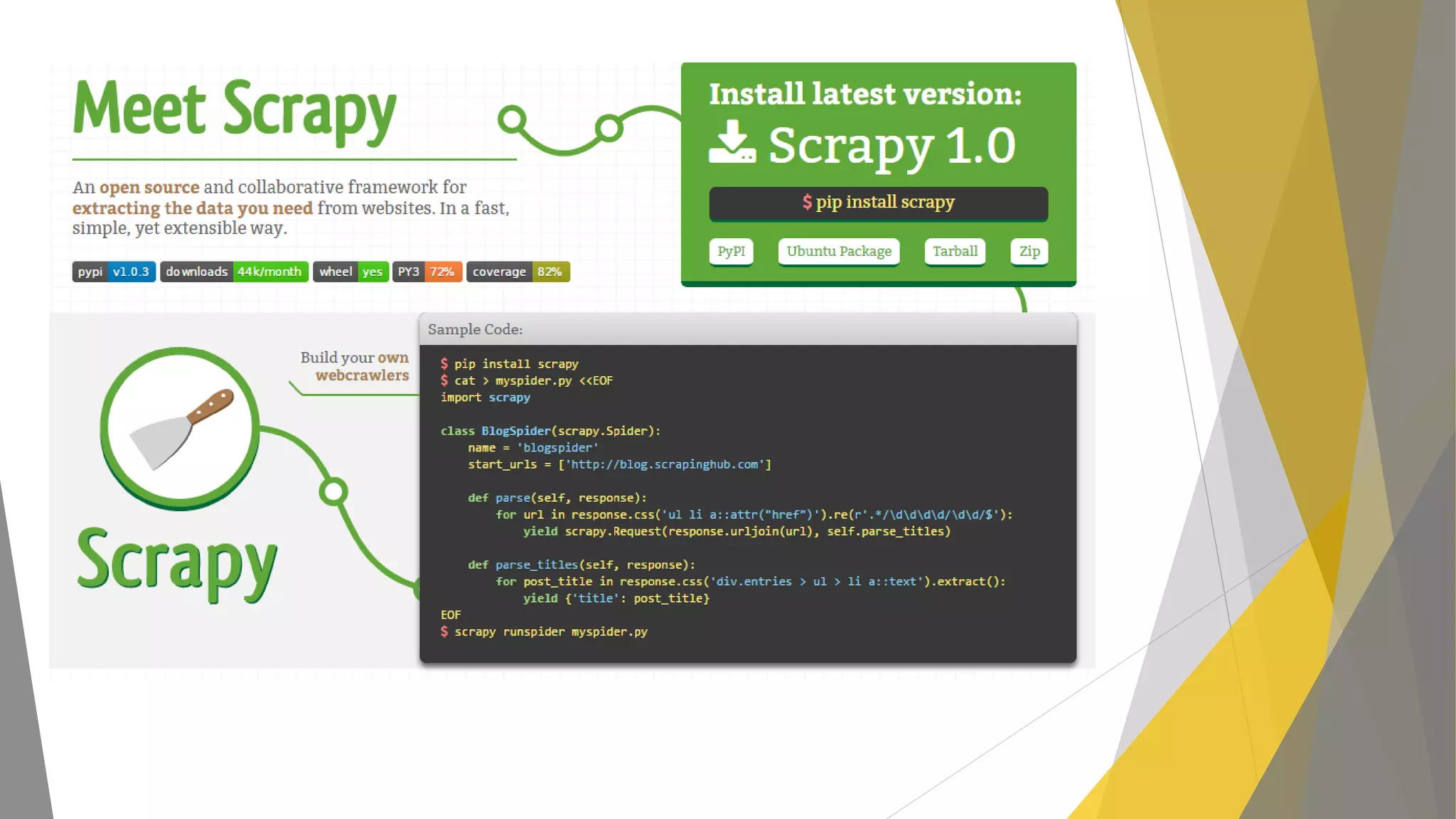
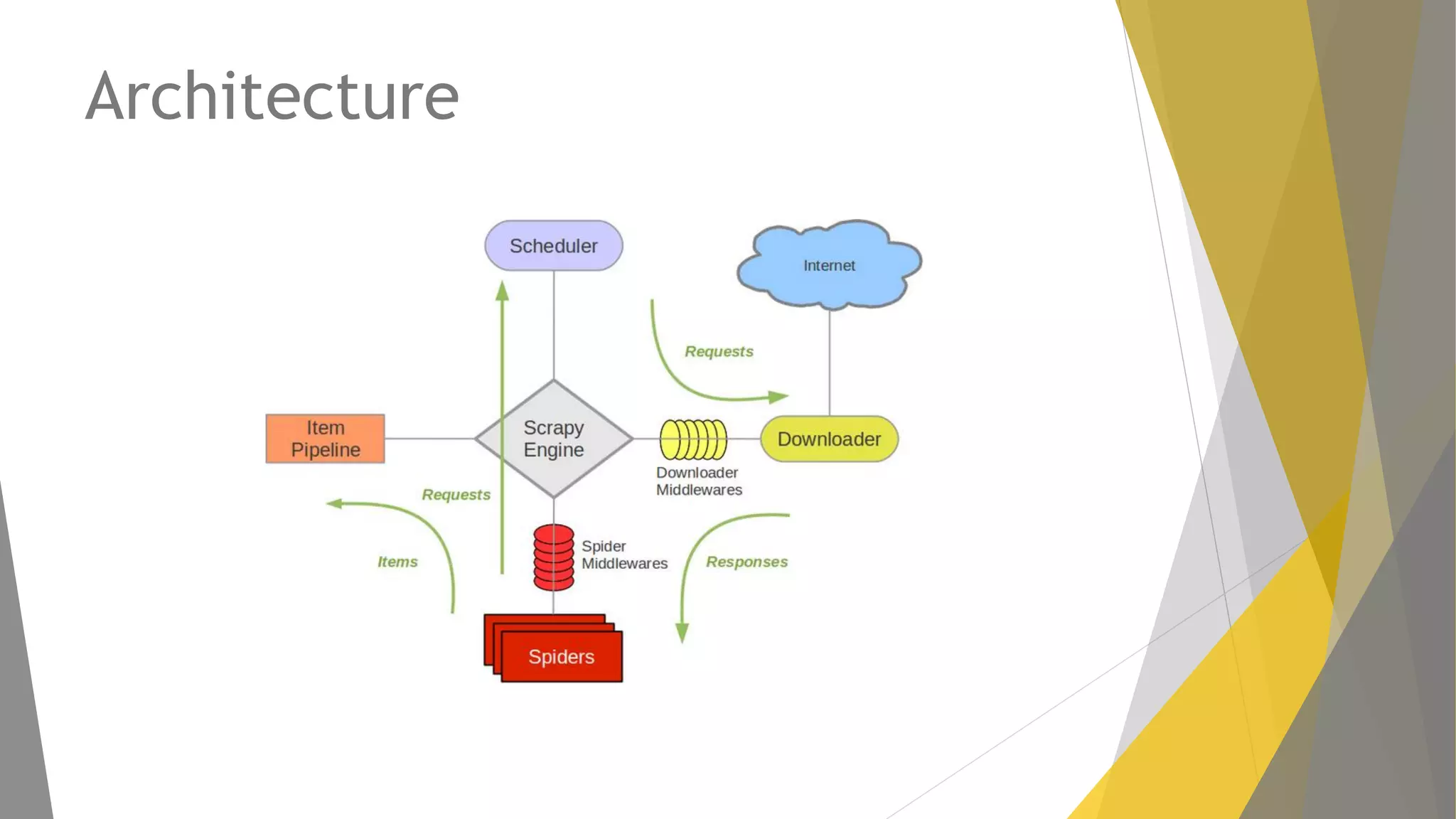
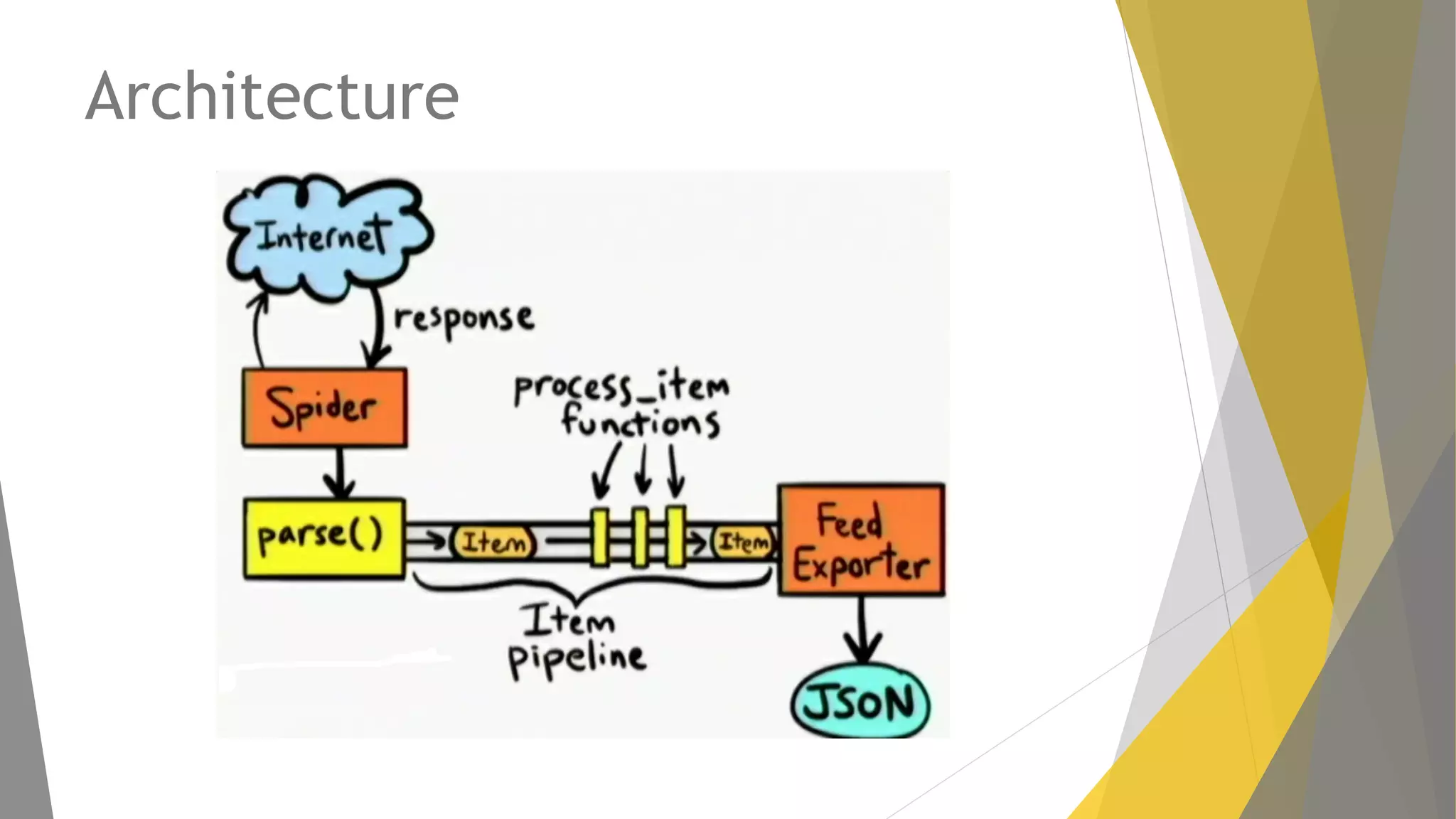
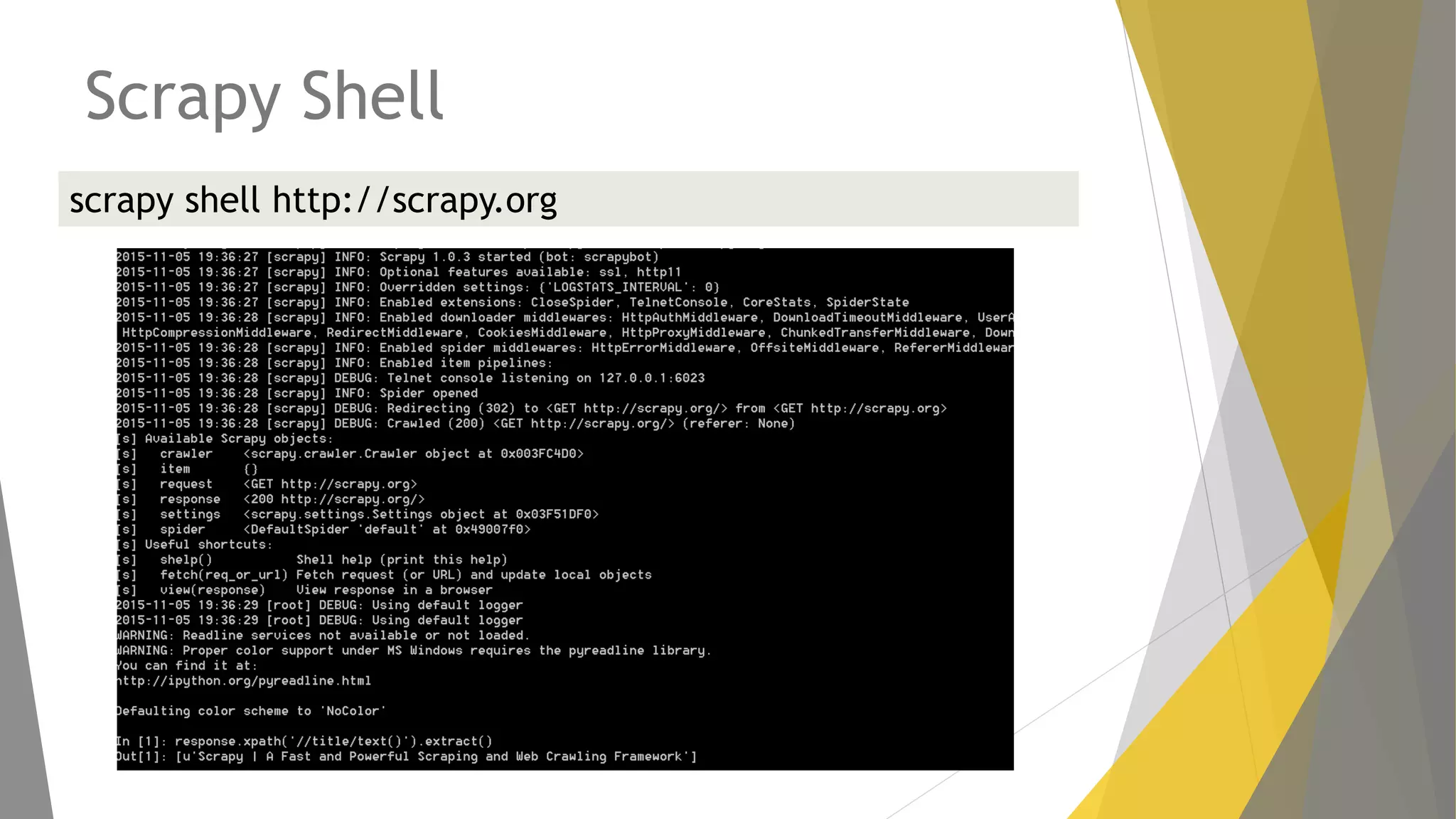
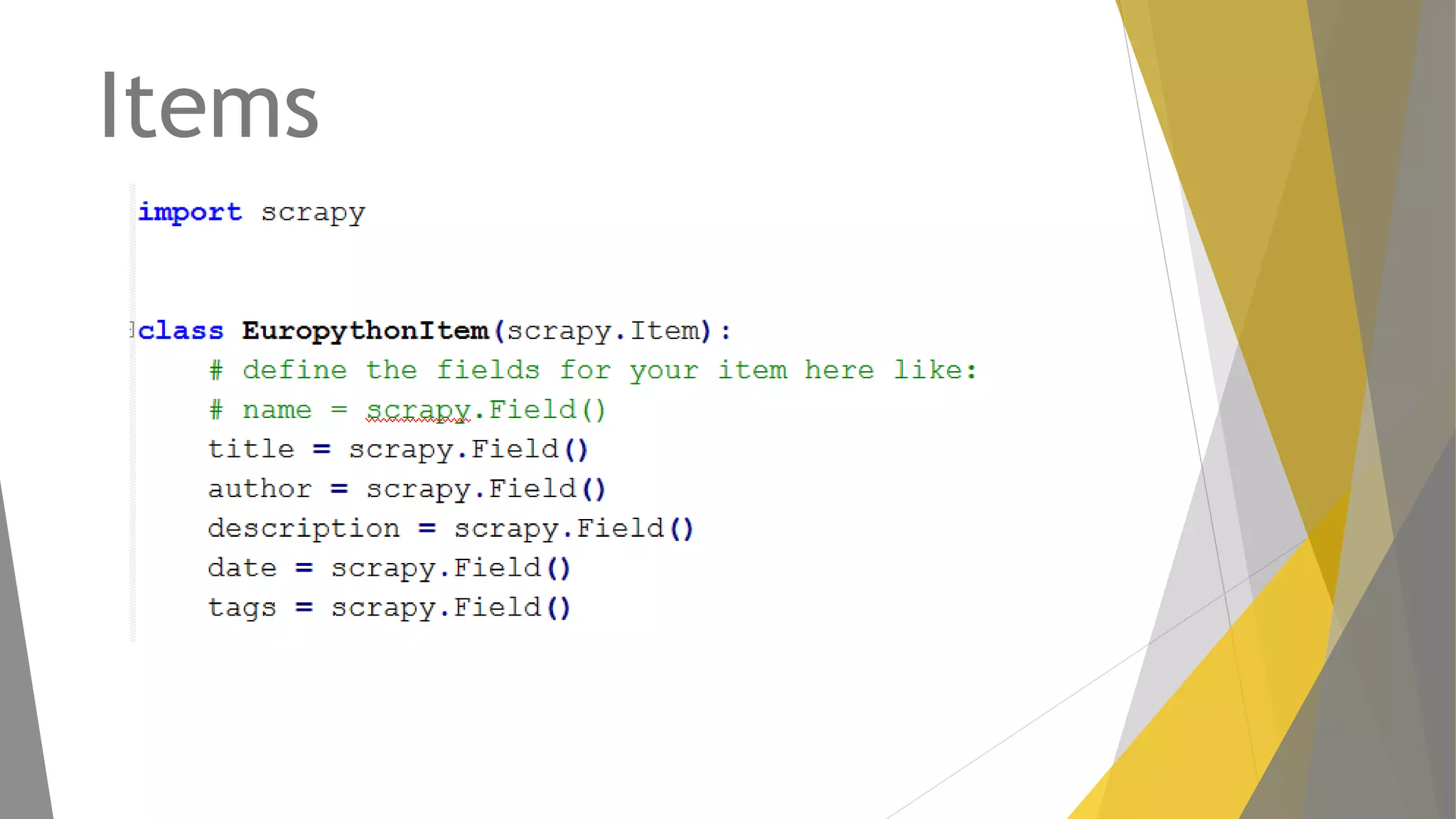
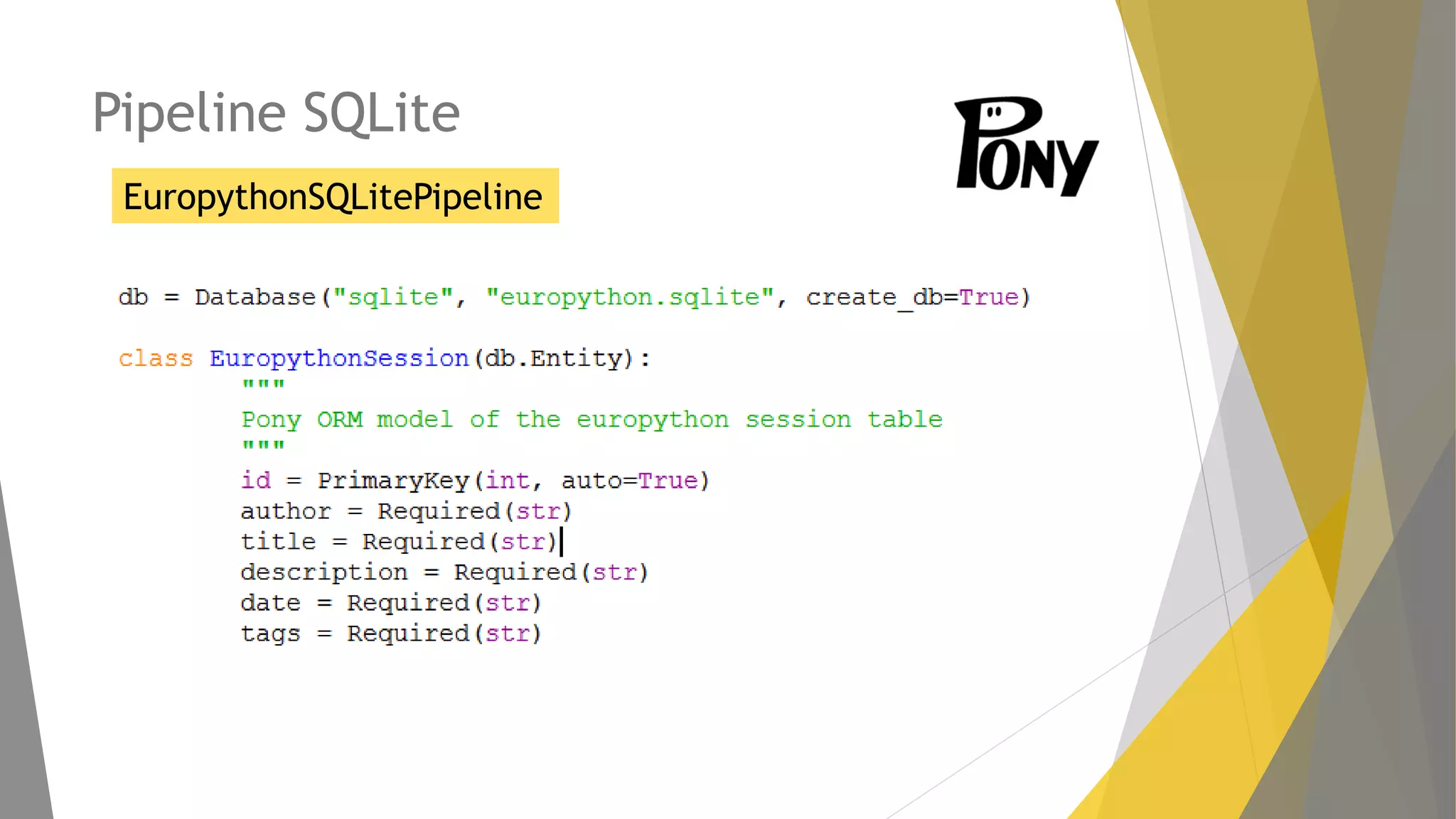
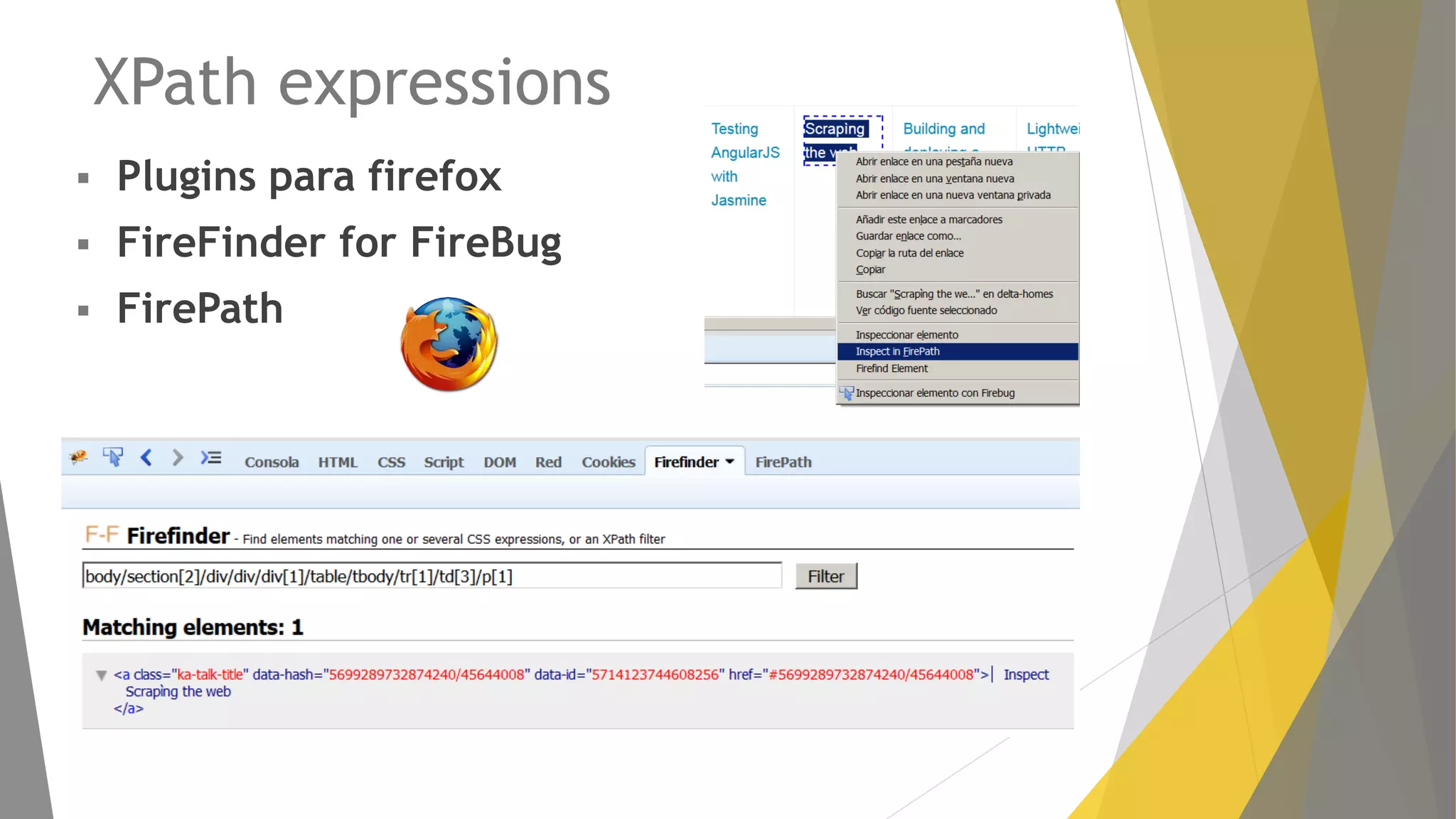
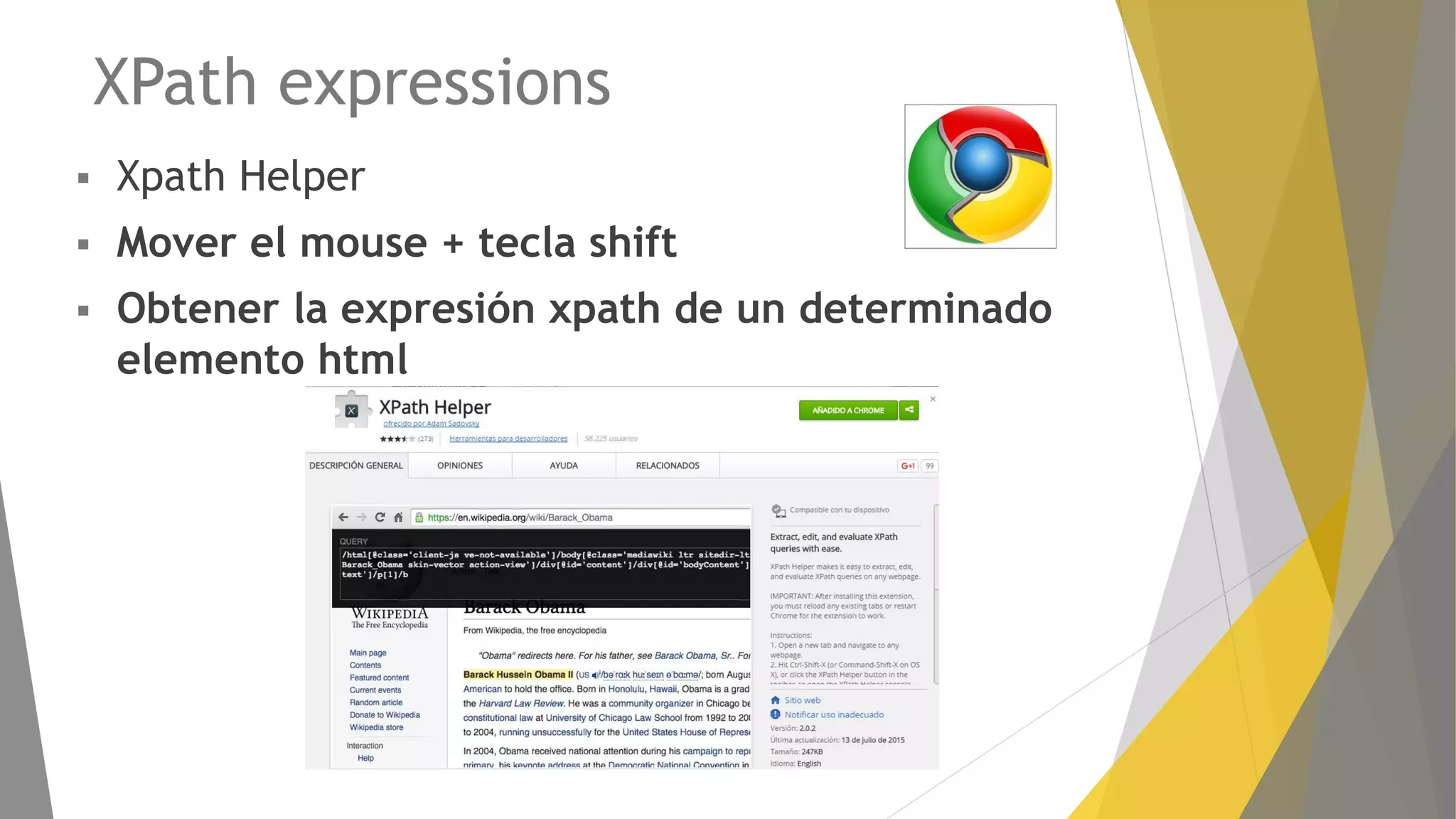
Explicación del framework Scrapy y su arquitectura, componentes como Items, Spiders y Pipelines. Instrucciones para instalar Scrapy, trabajar con la shell y crear spiders utilizando Xpath.
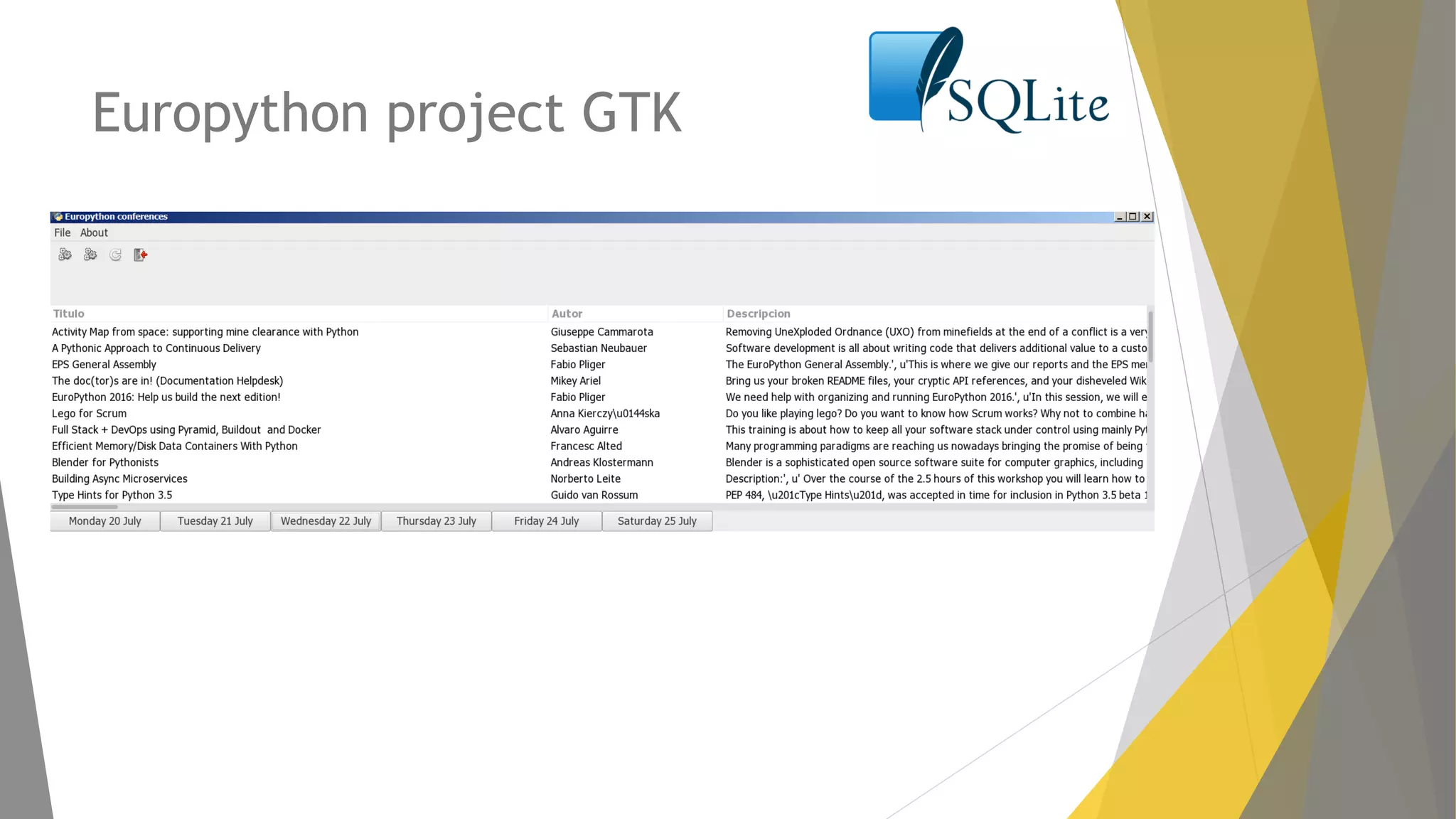
Métodos para ejecutar spiders en Scrapy y exportar datos a diferentes formatos como JSON y CSV.
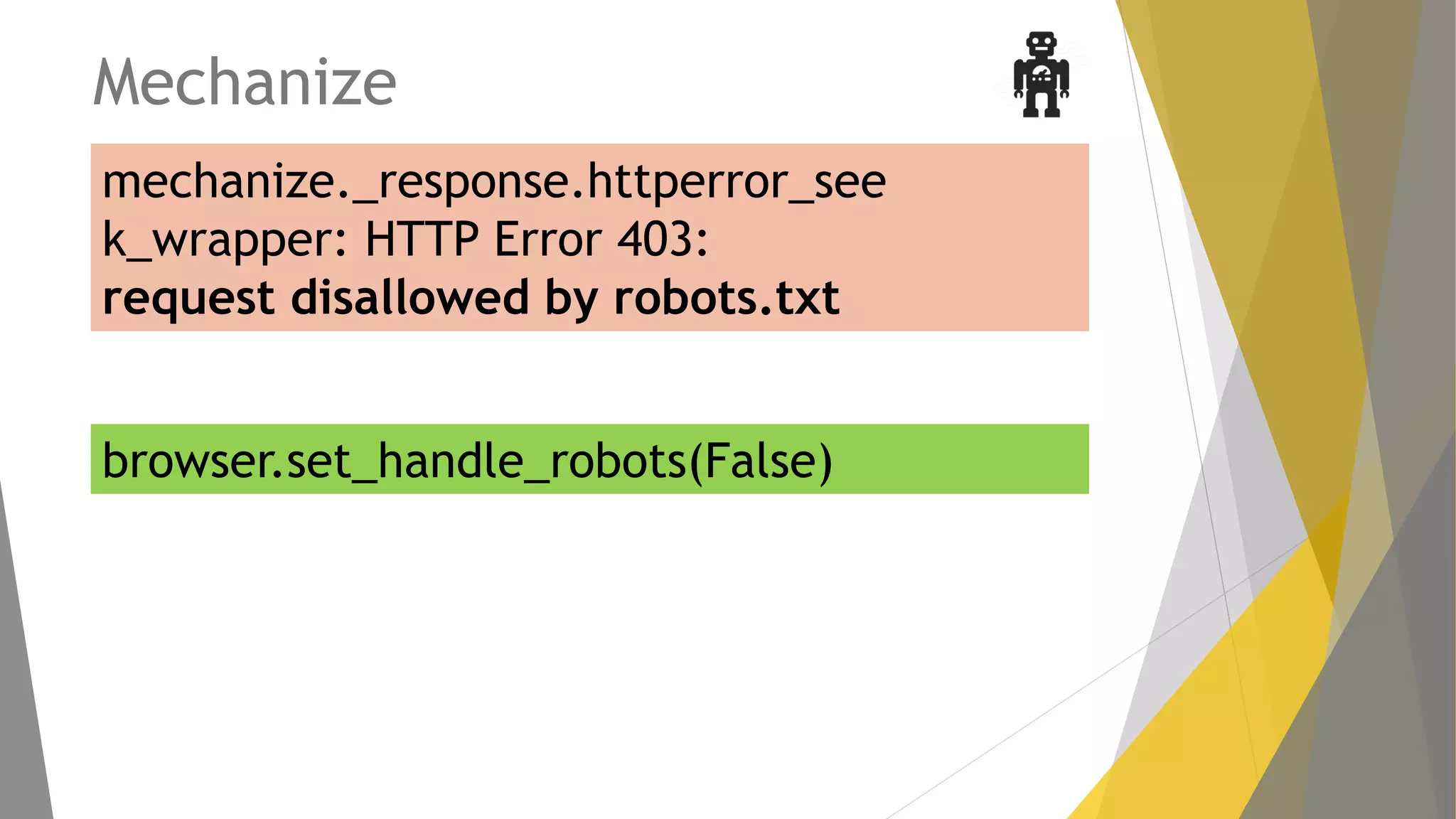
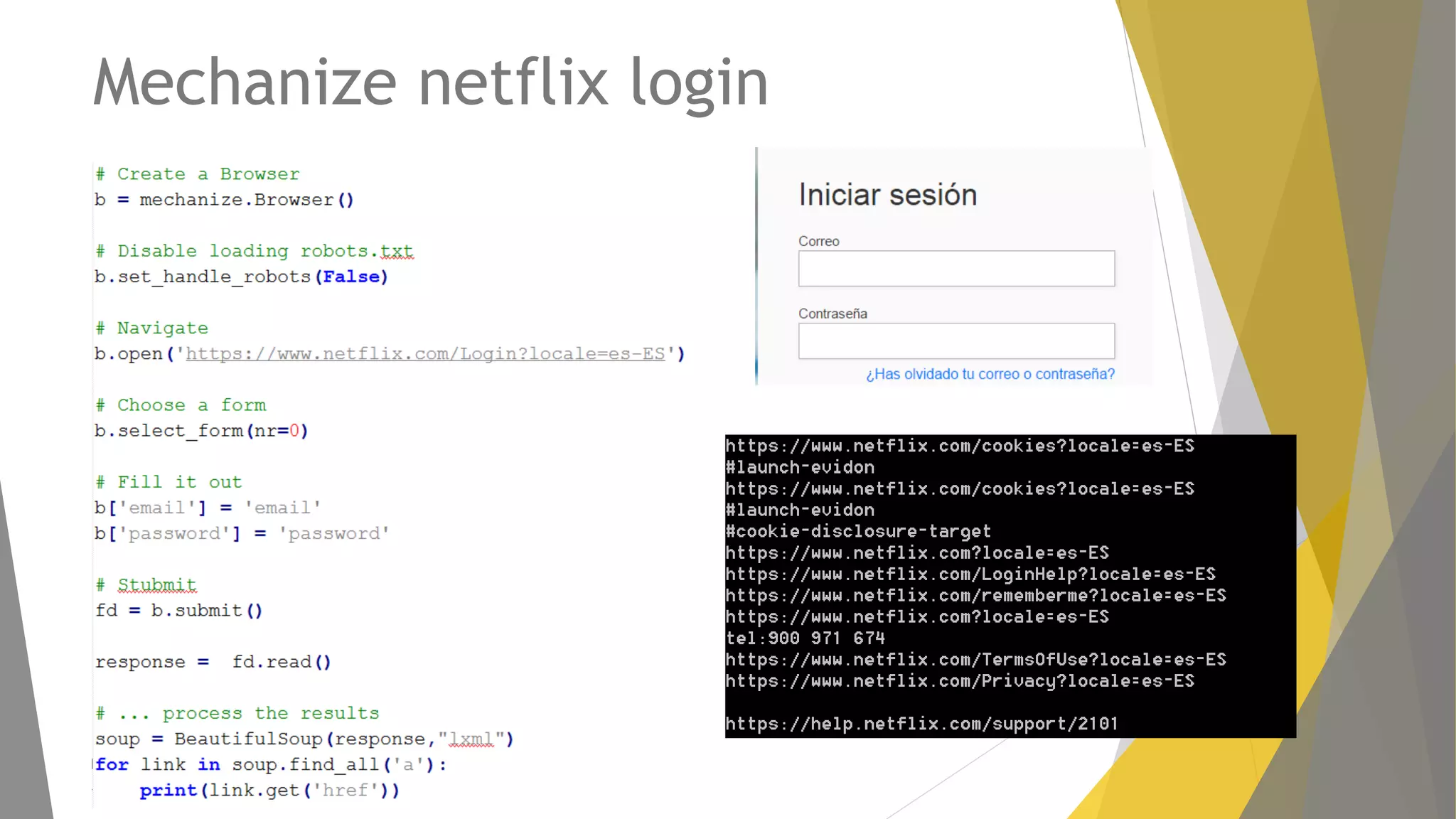
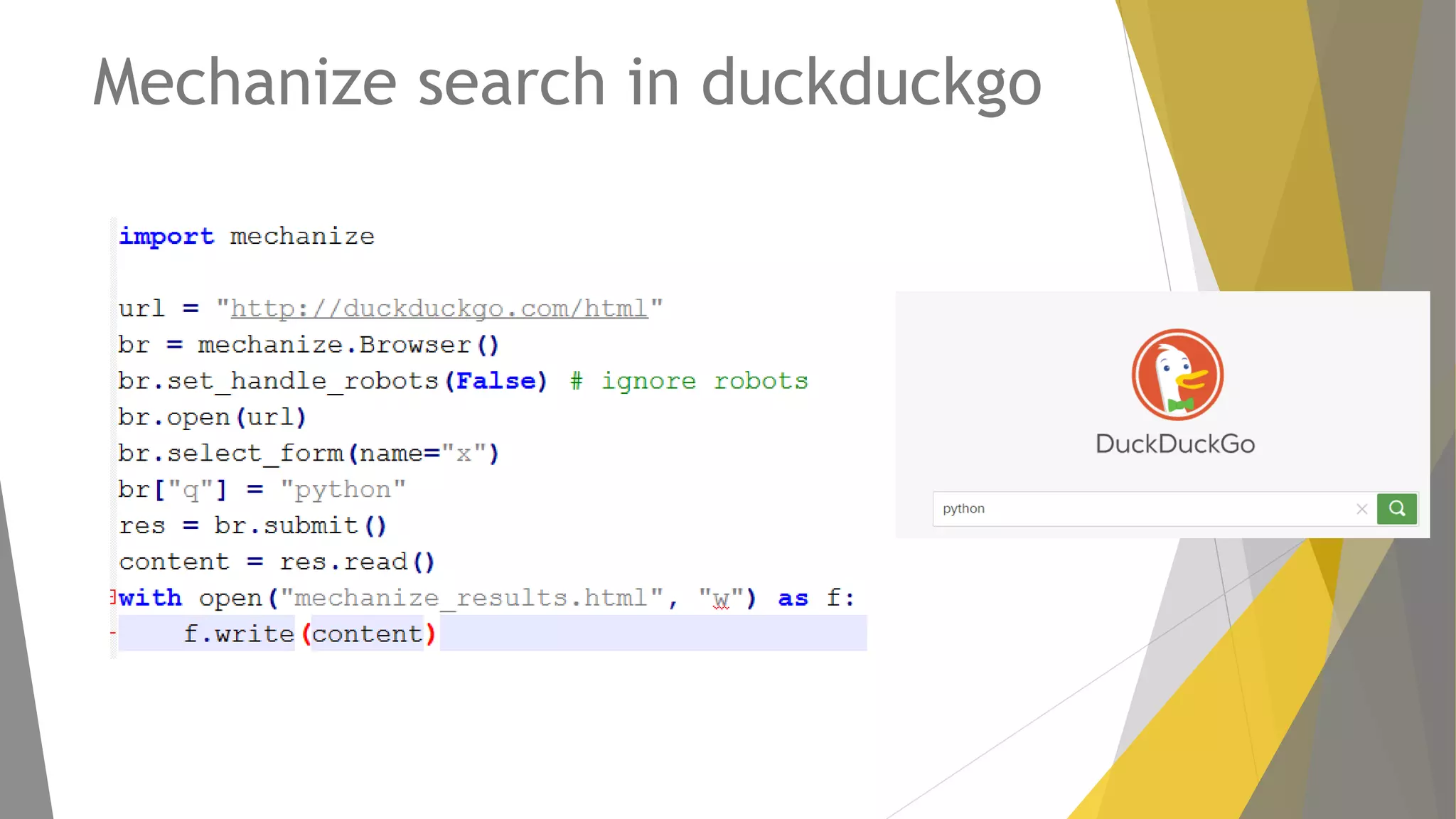
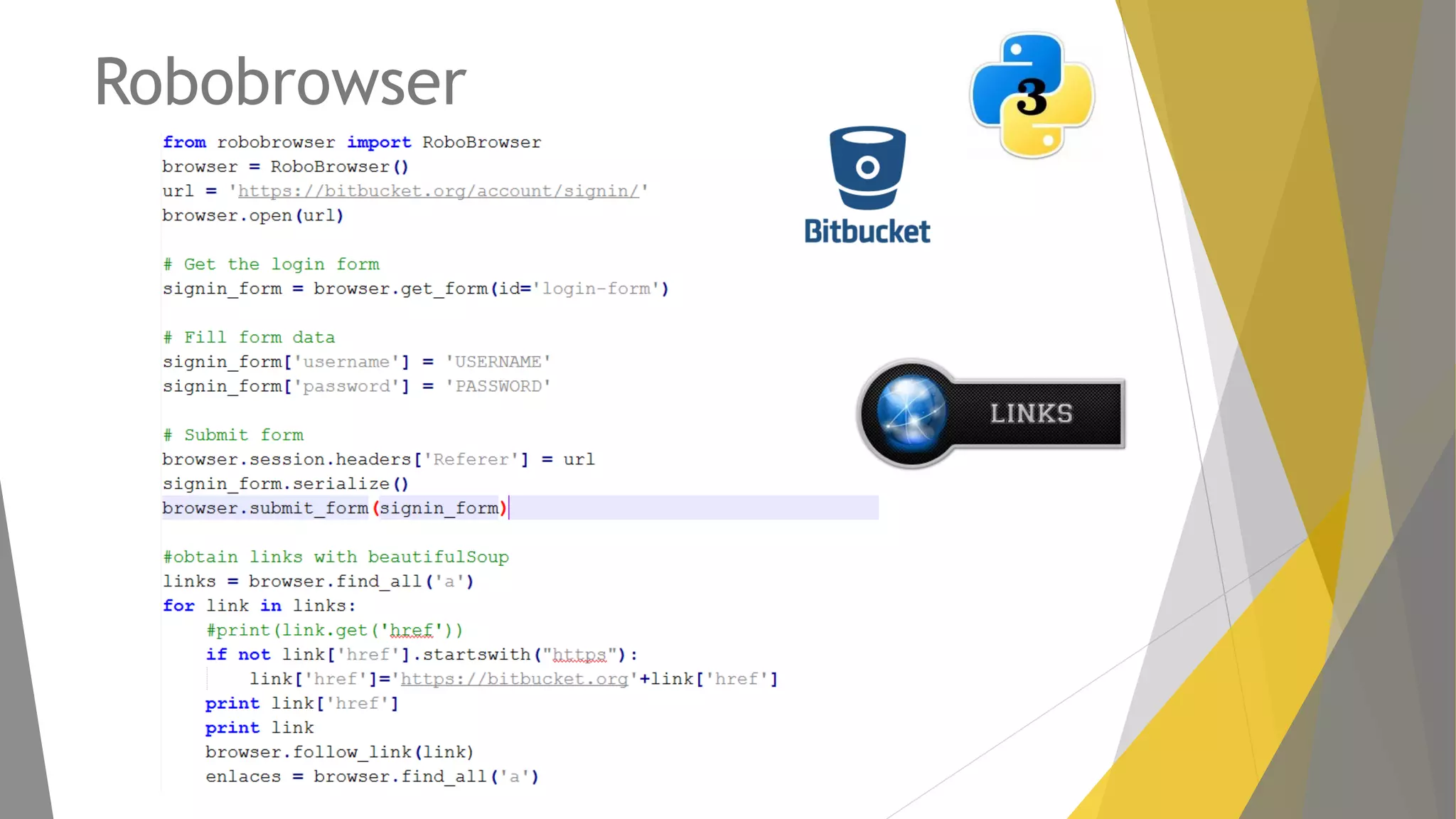
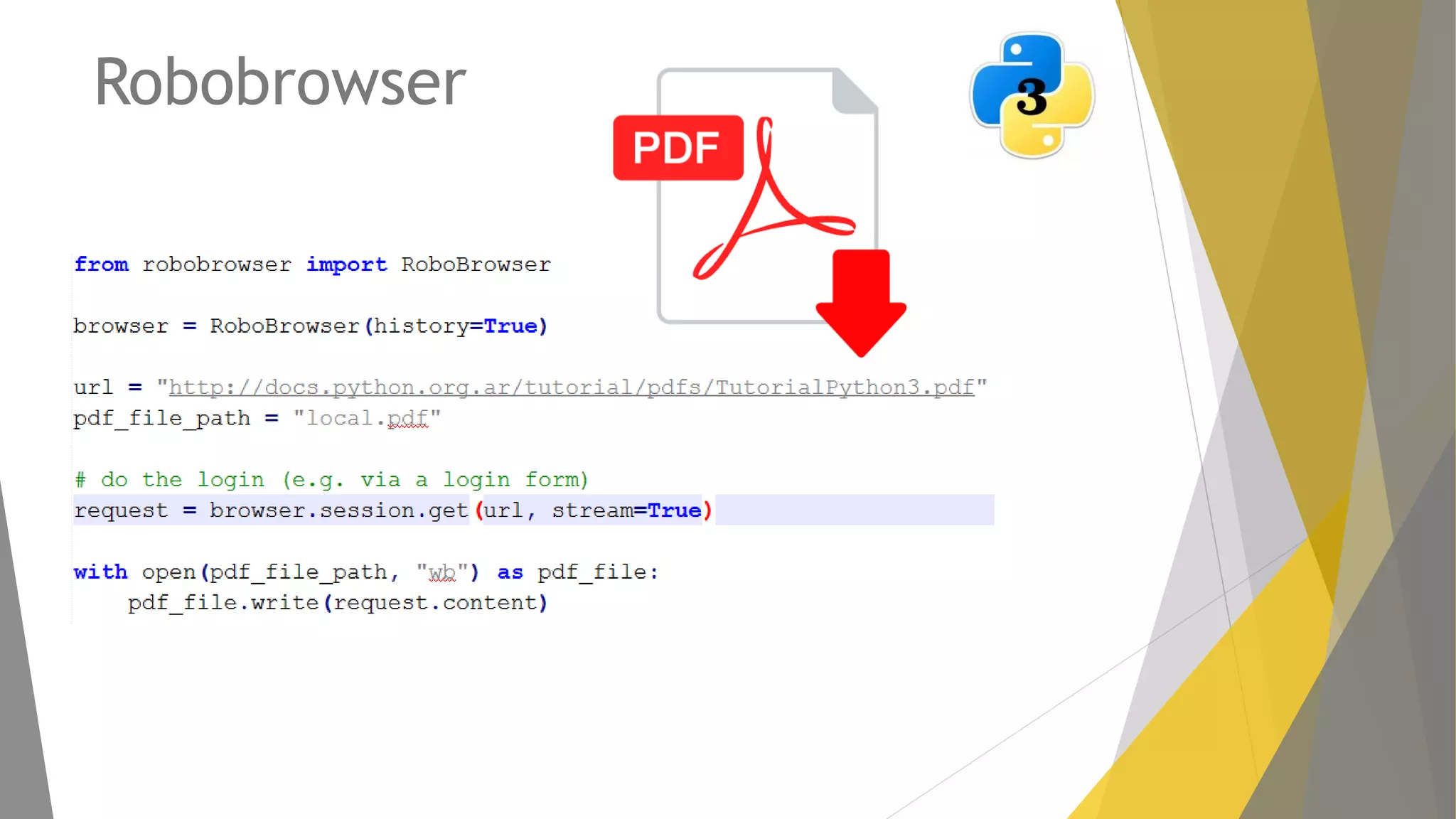
Descripción de Mechanize, su uso para la navegación programática y alternativas como RoboBrowser.
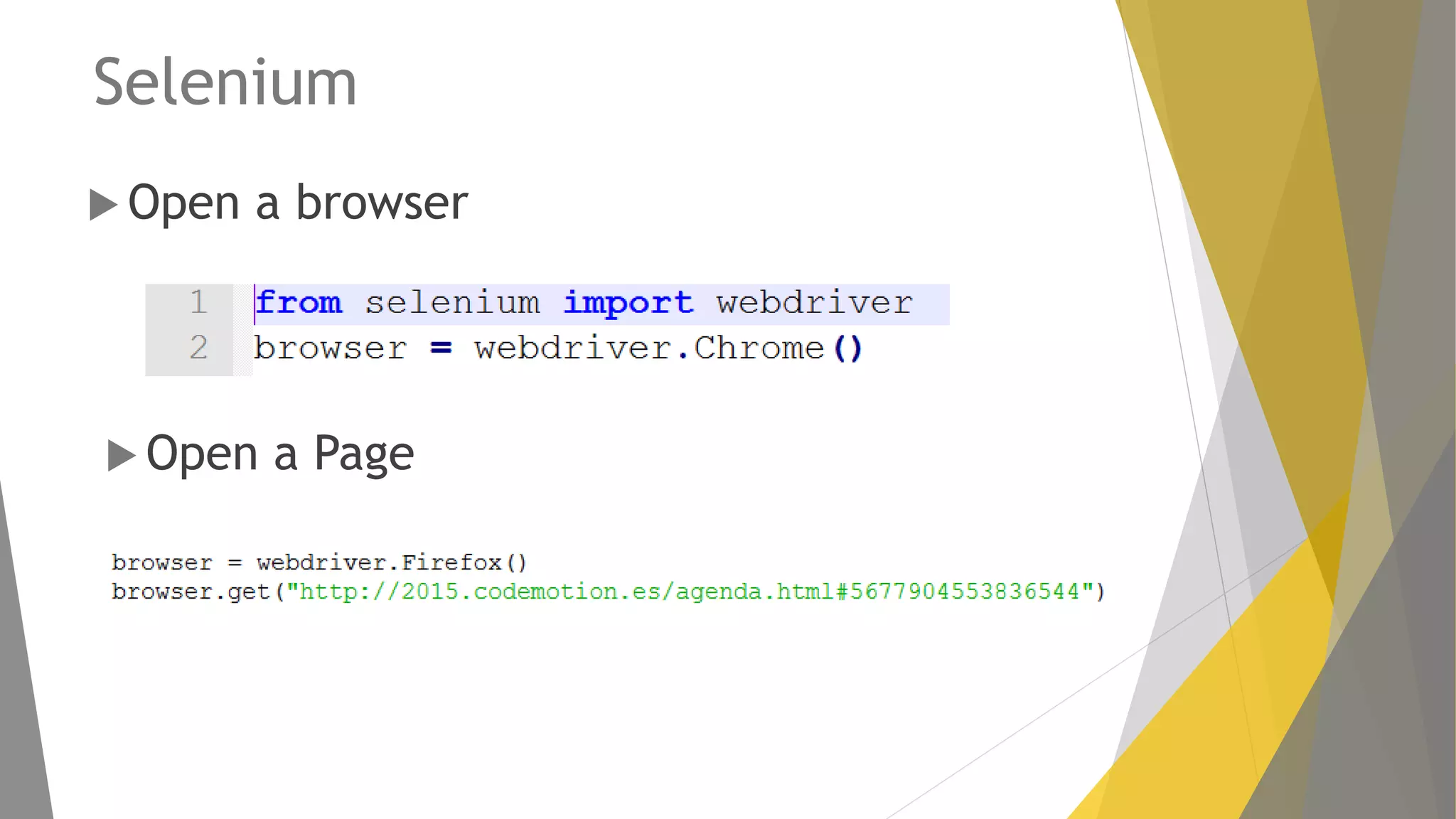
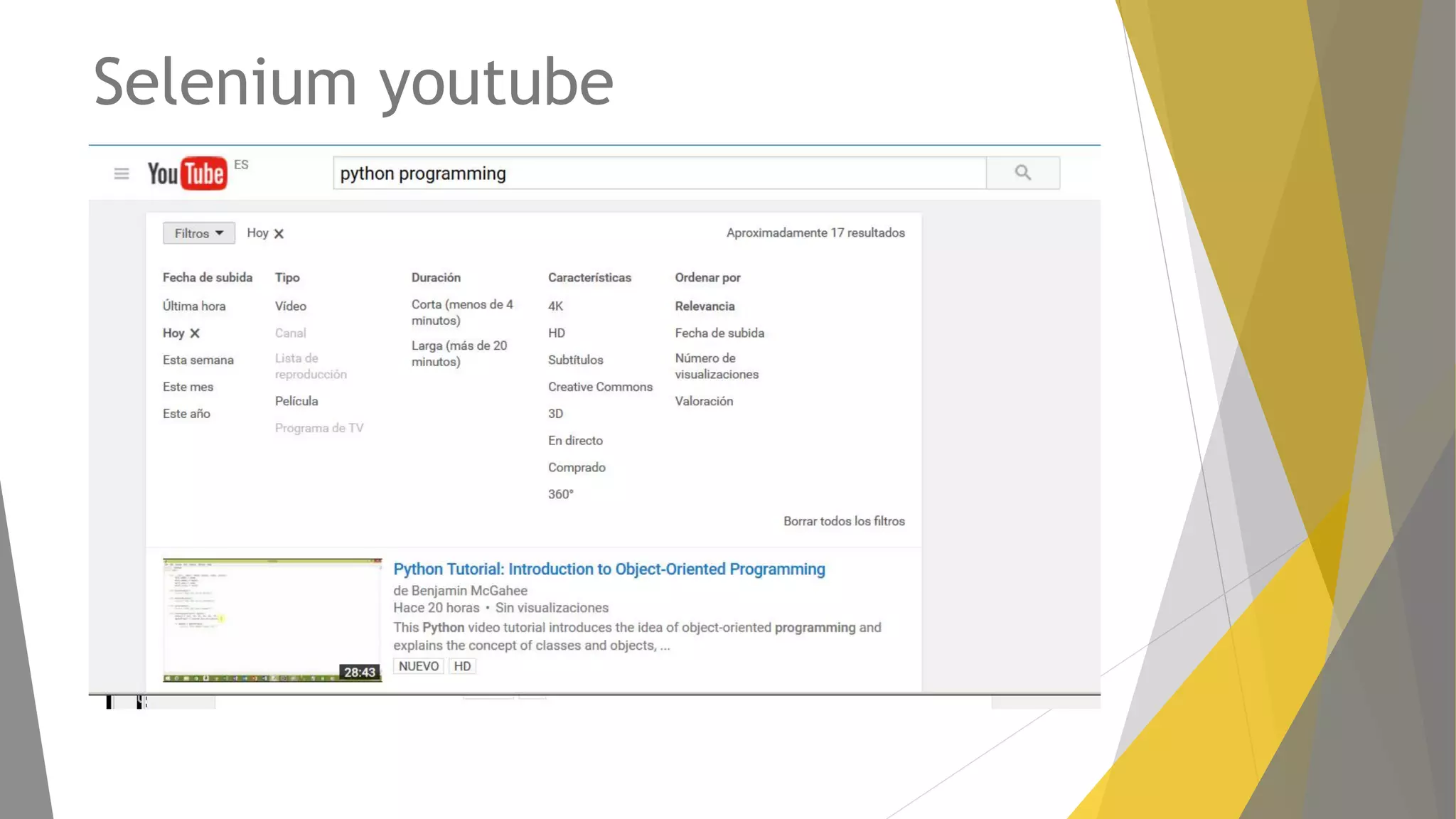
Introducción a Selenium para automatización de navegadores, técnicas para extraer datos y manejar cookies.
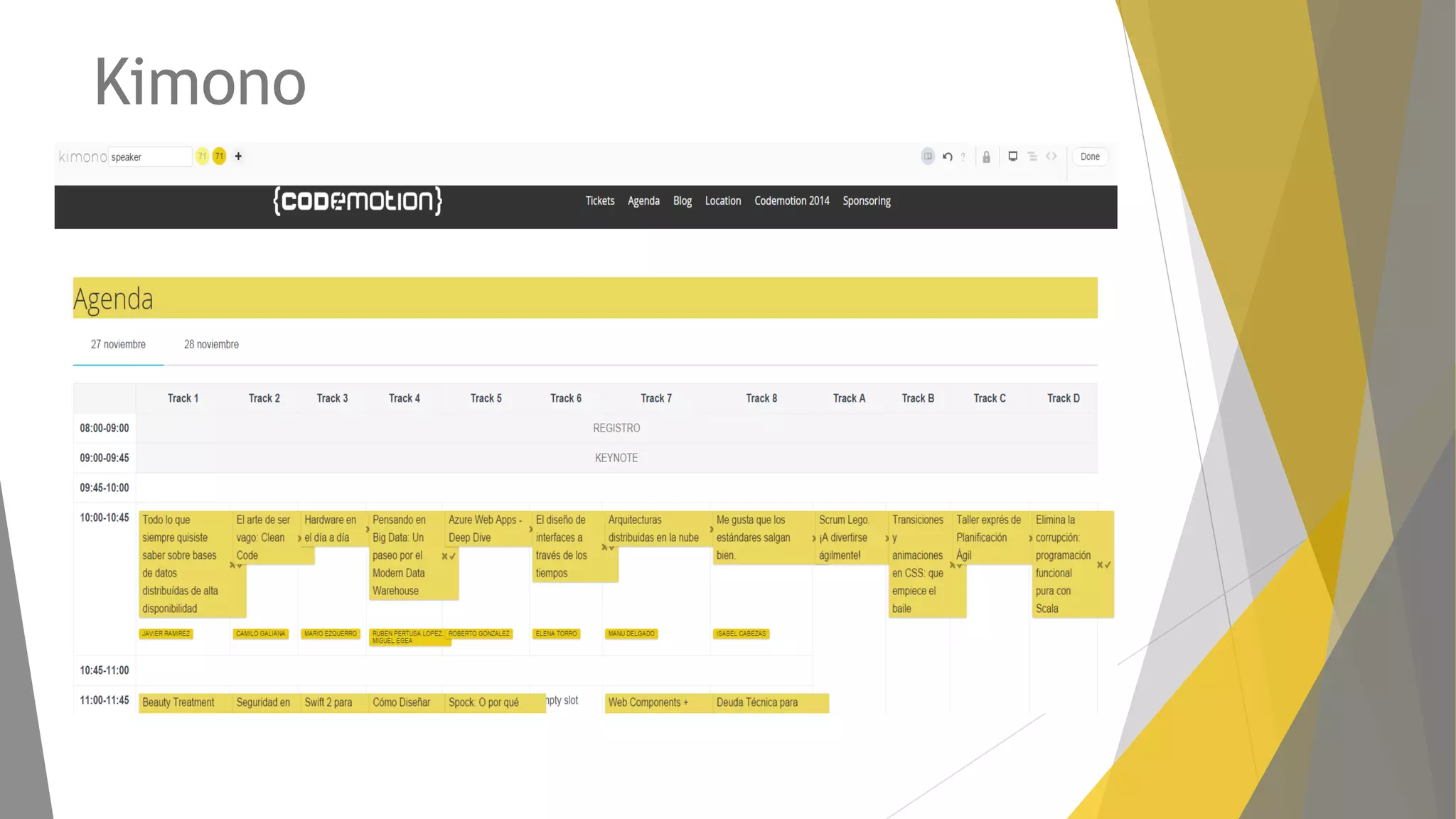
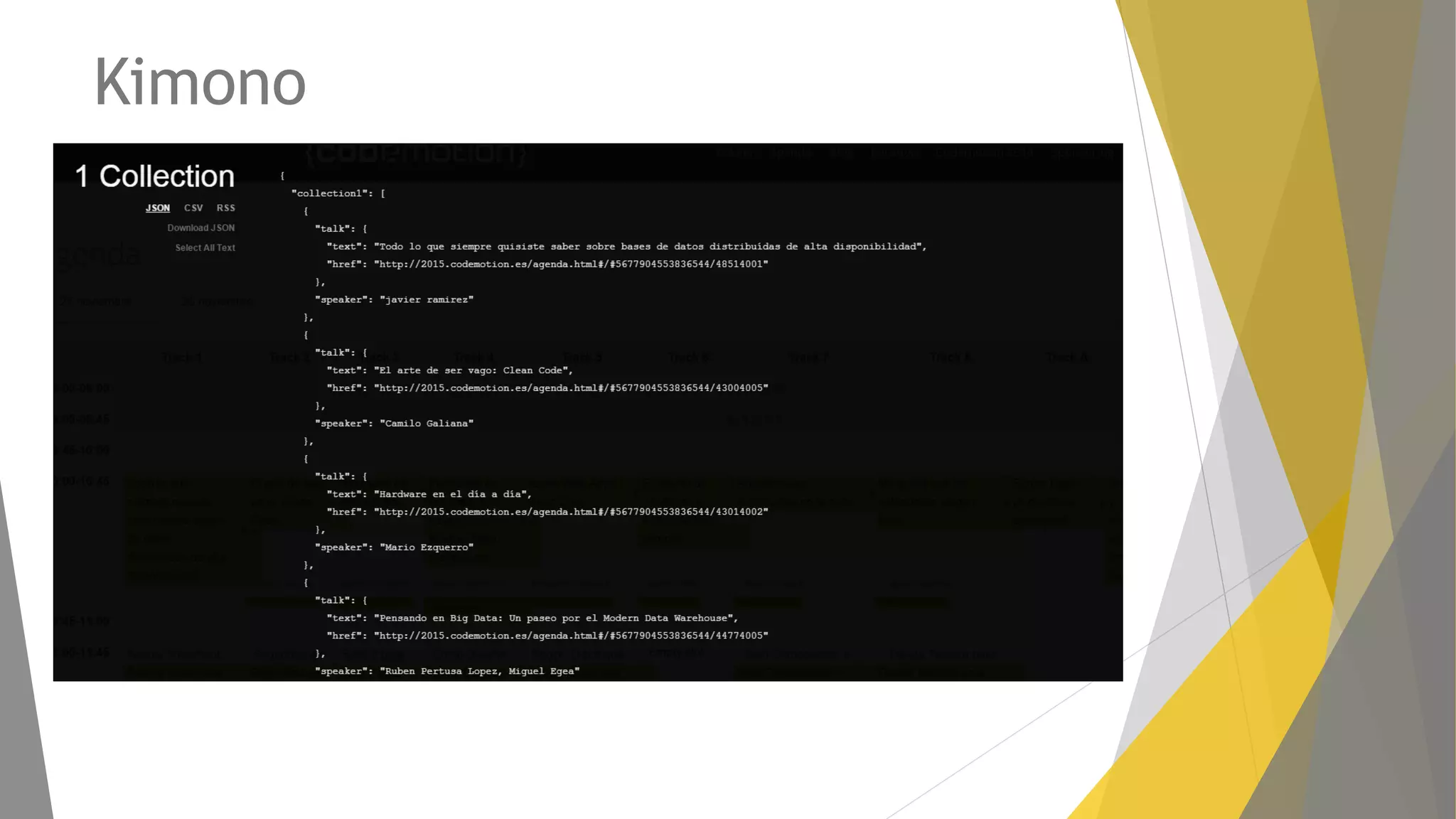
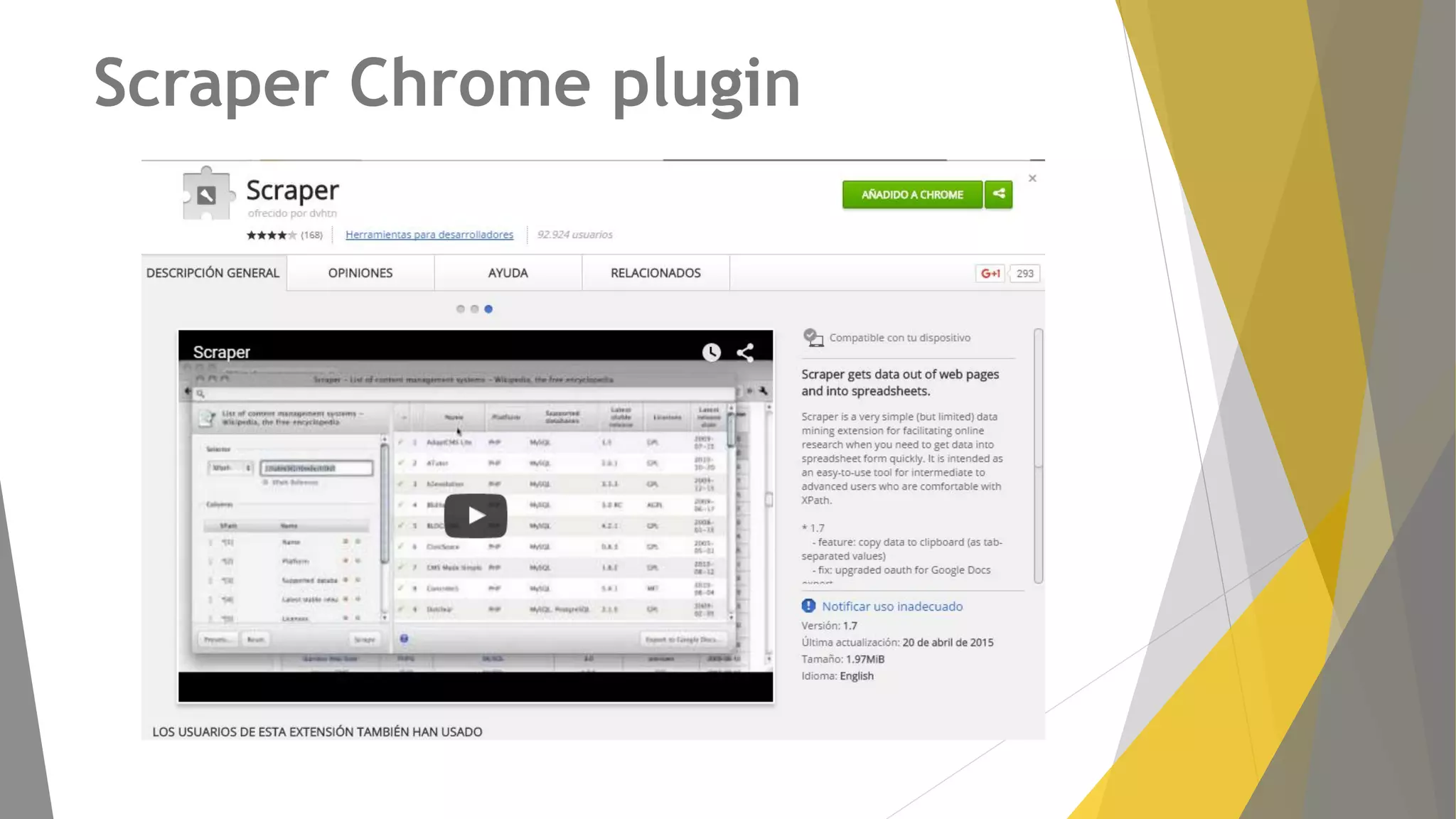
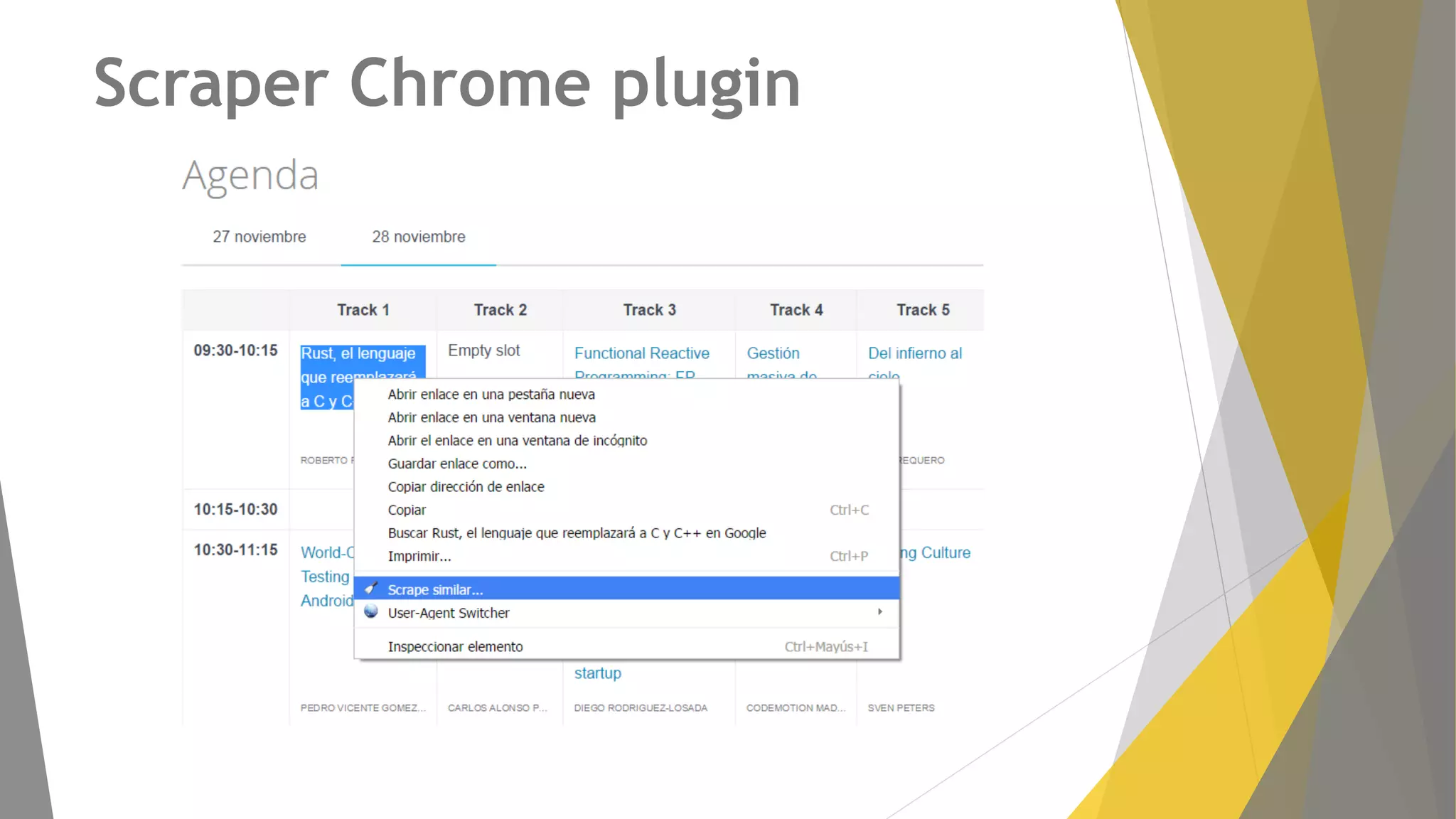
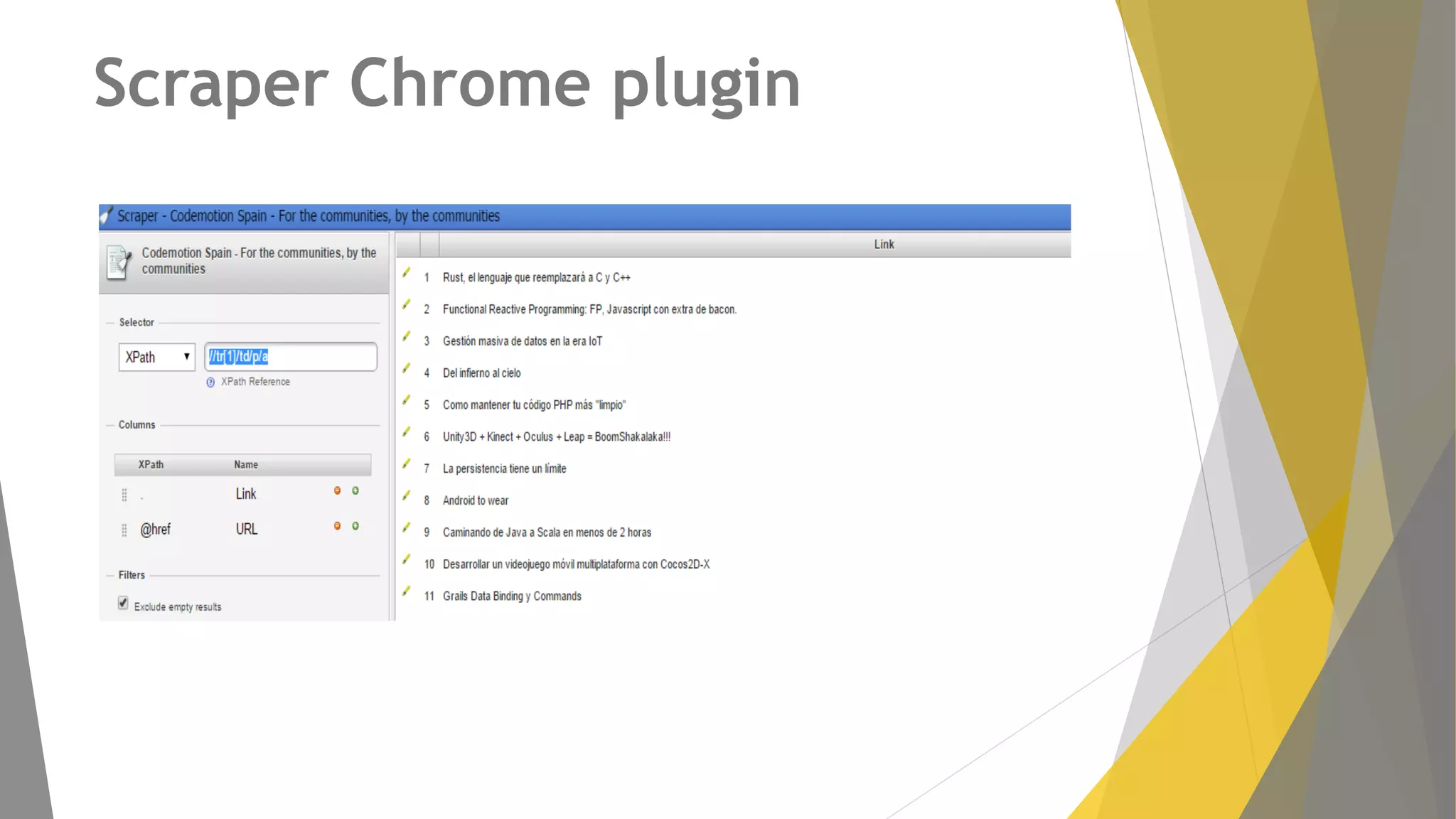
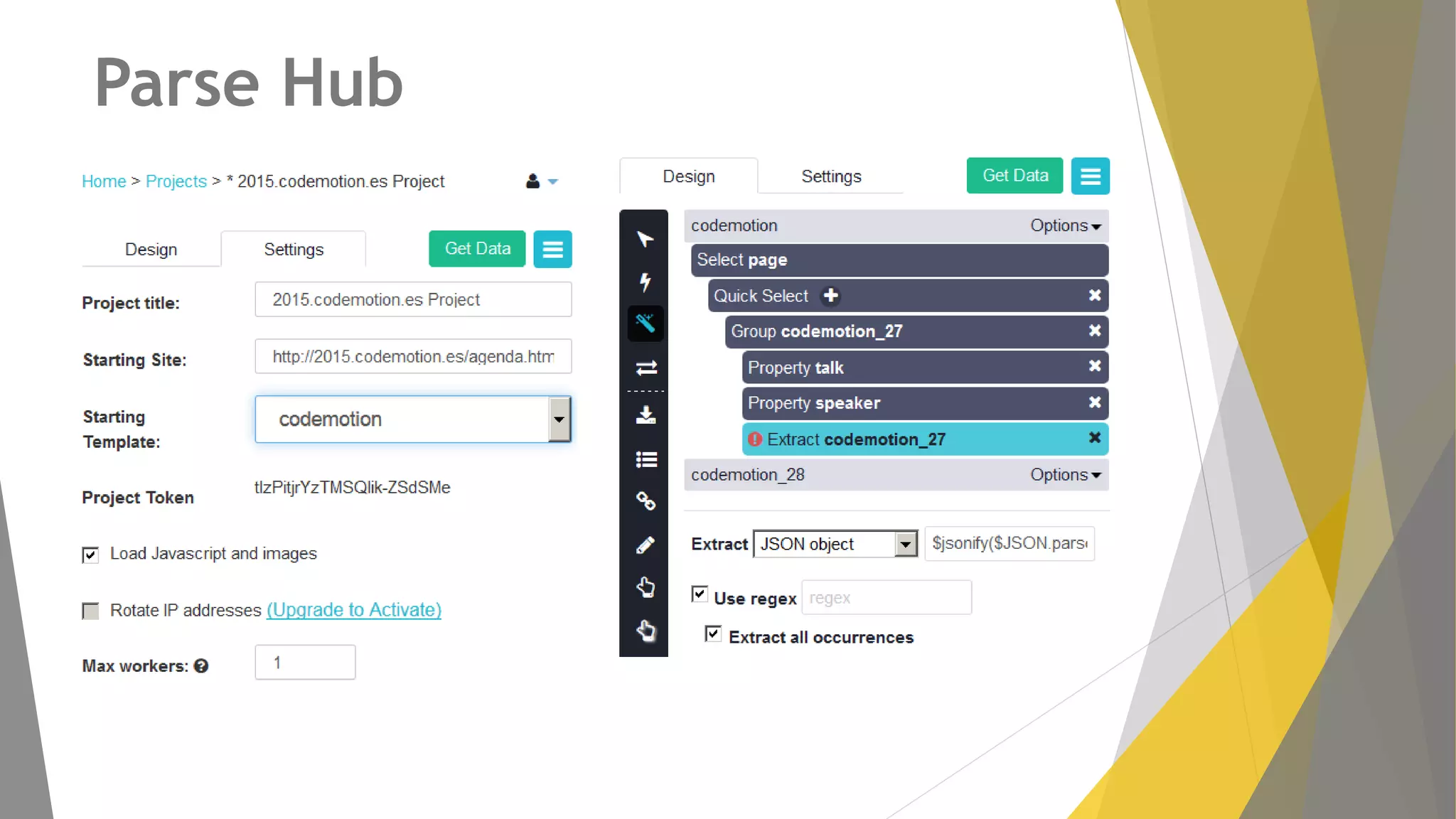
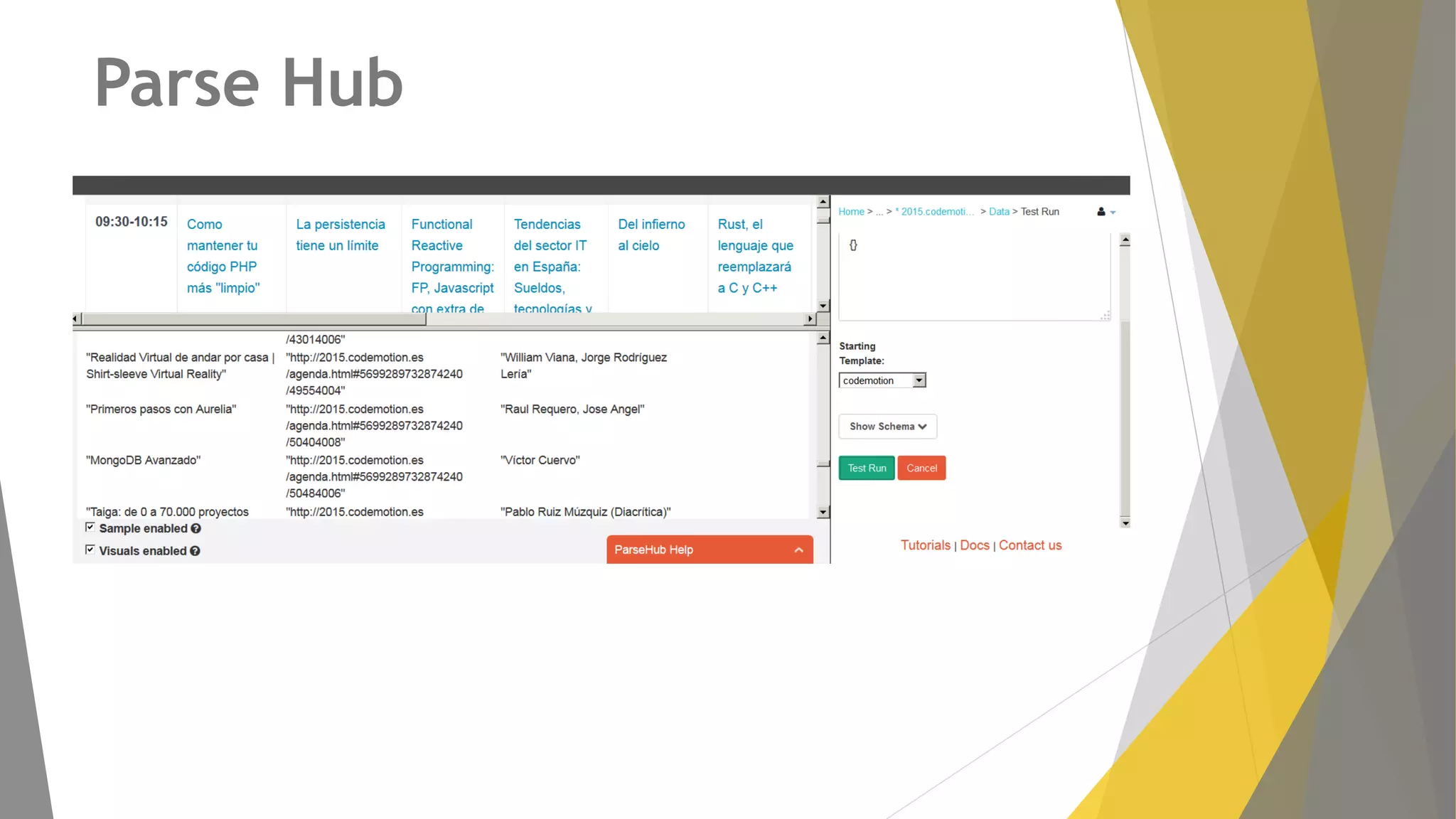
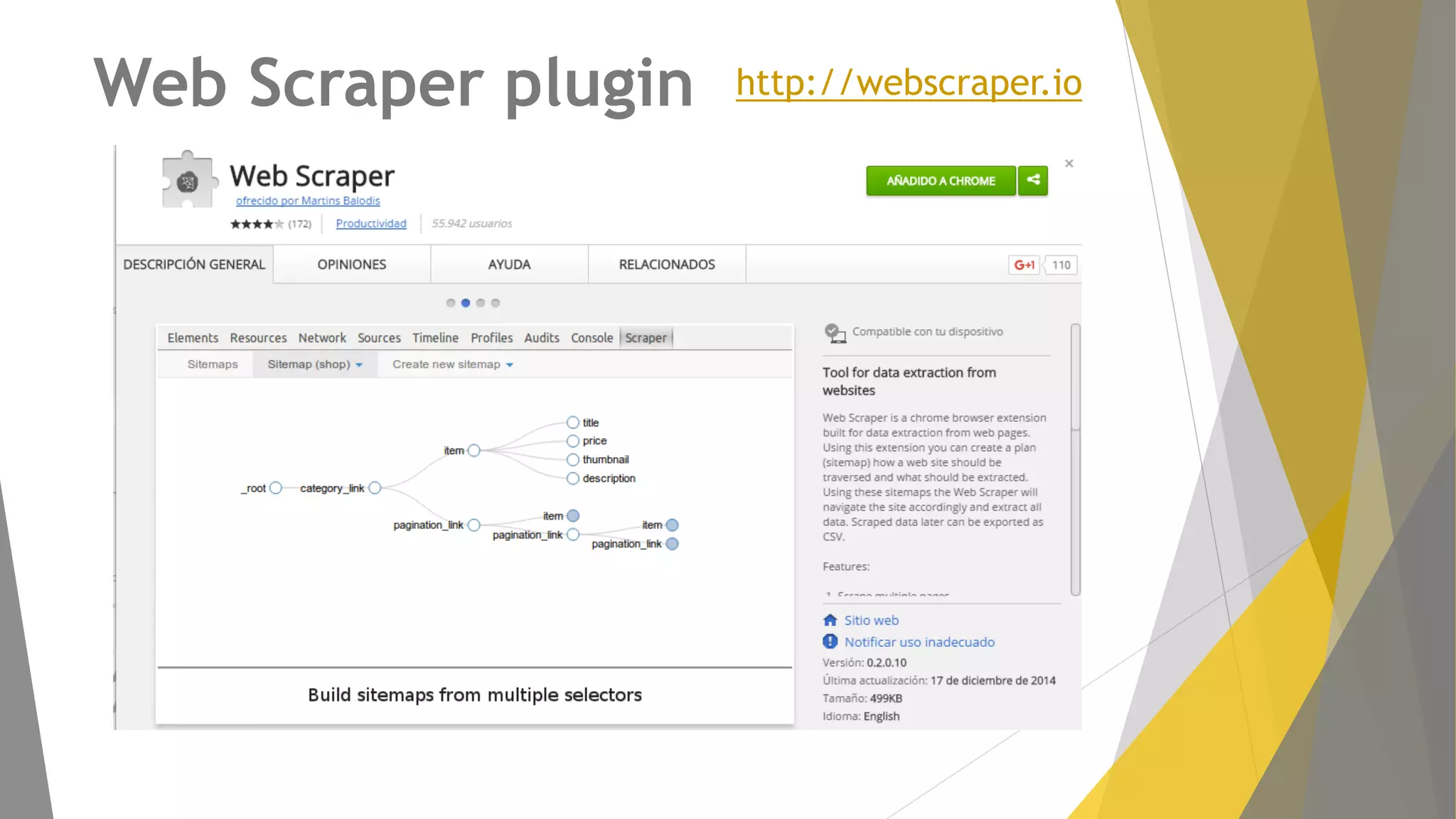
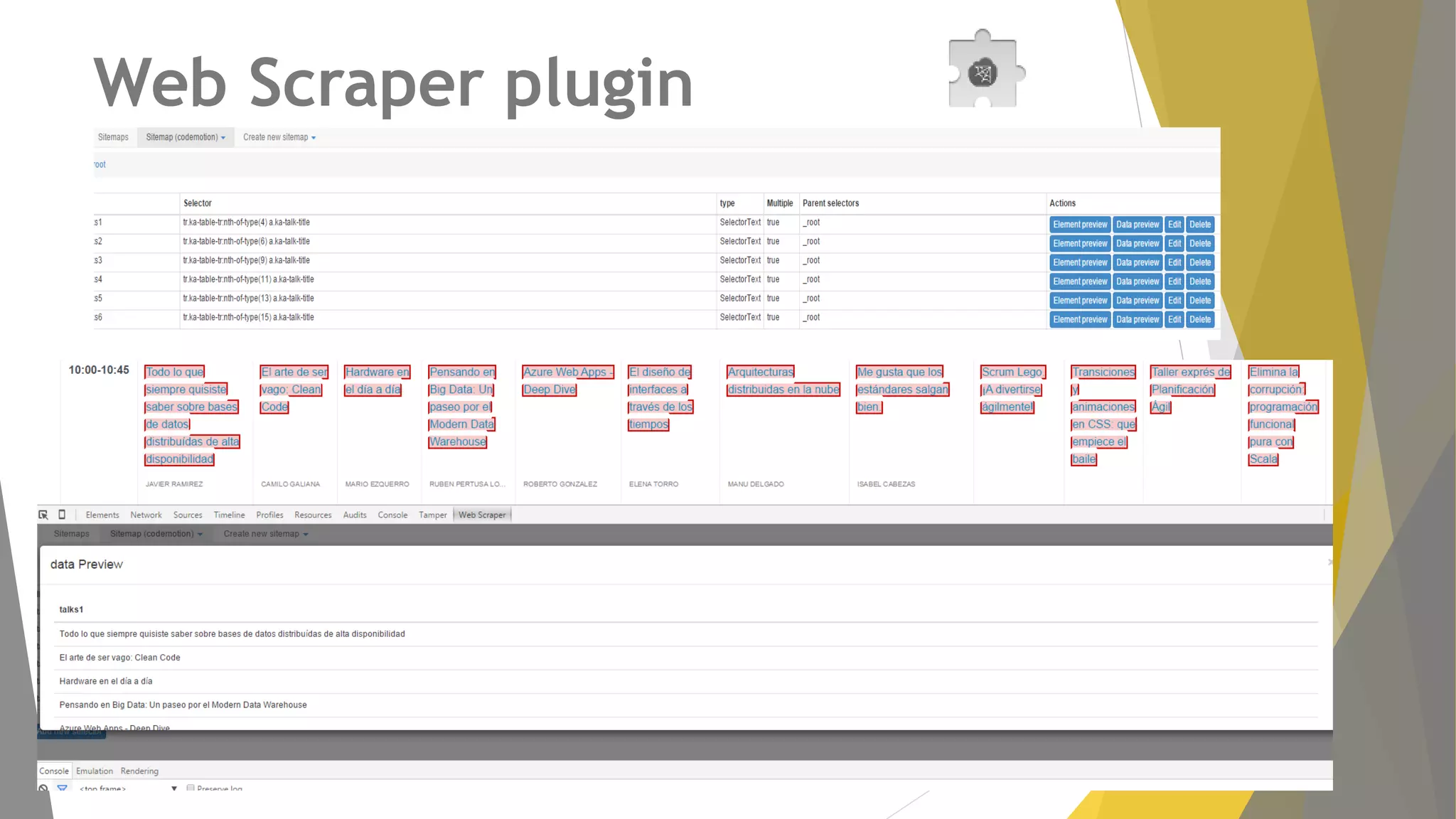
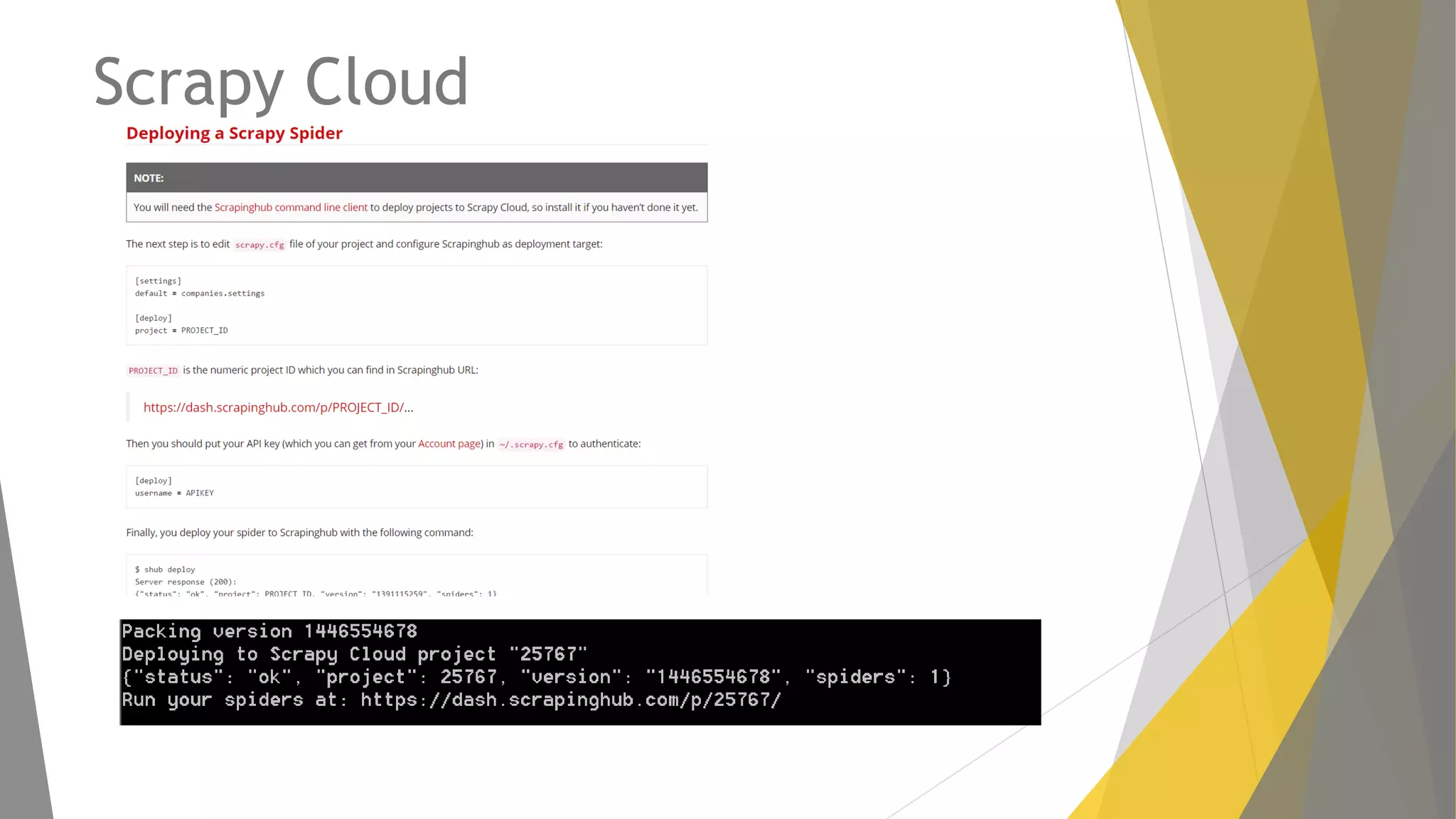
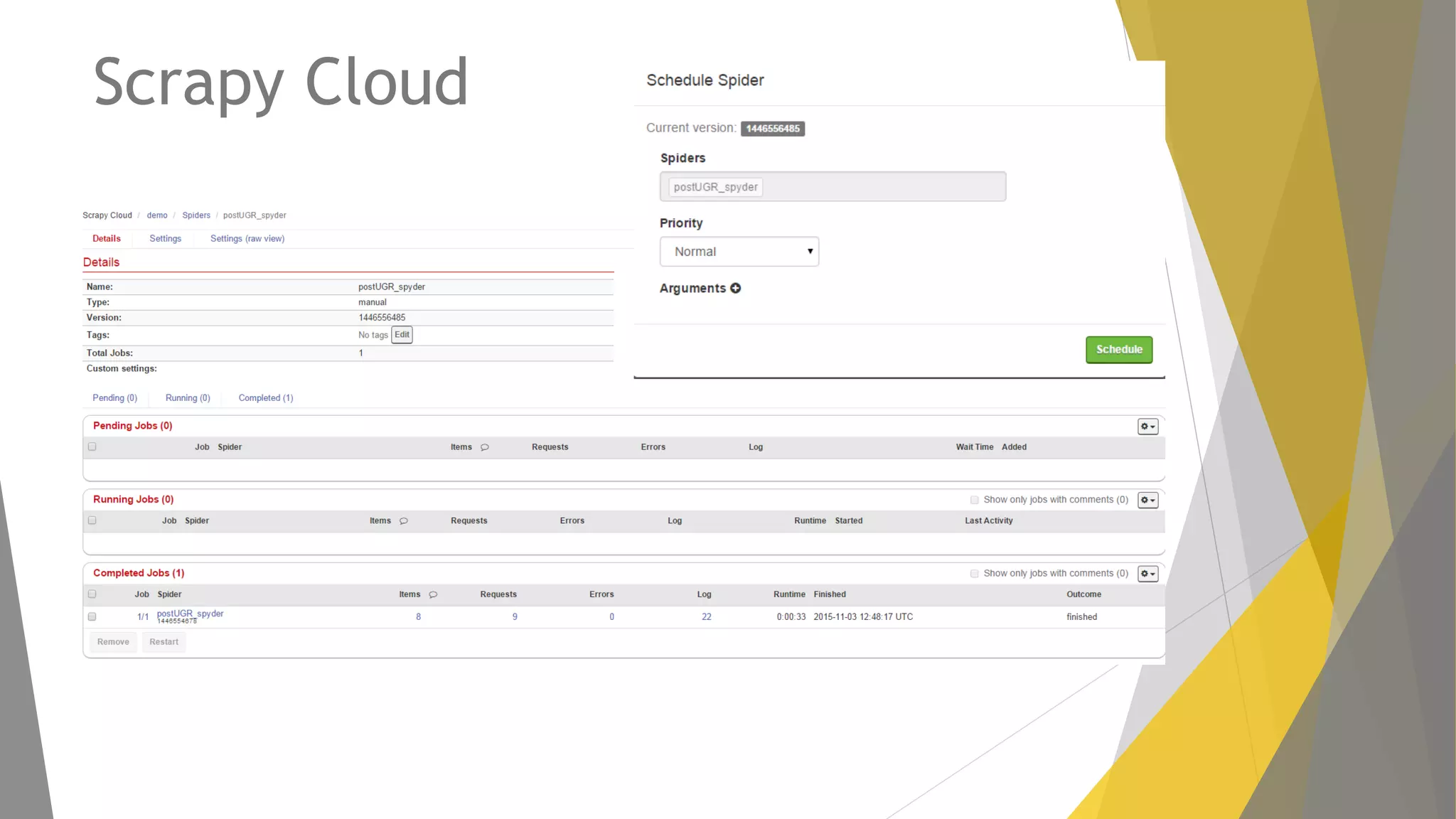
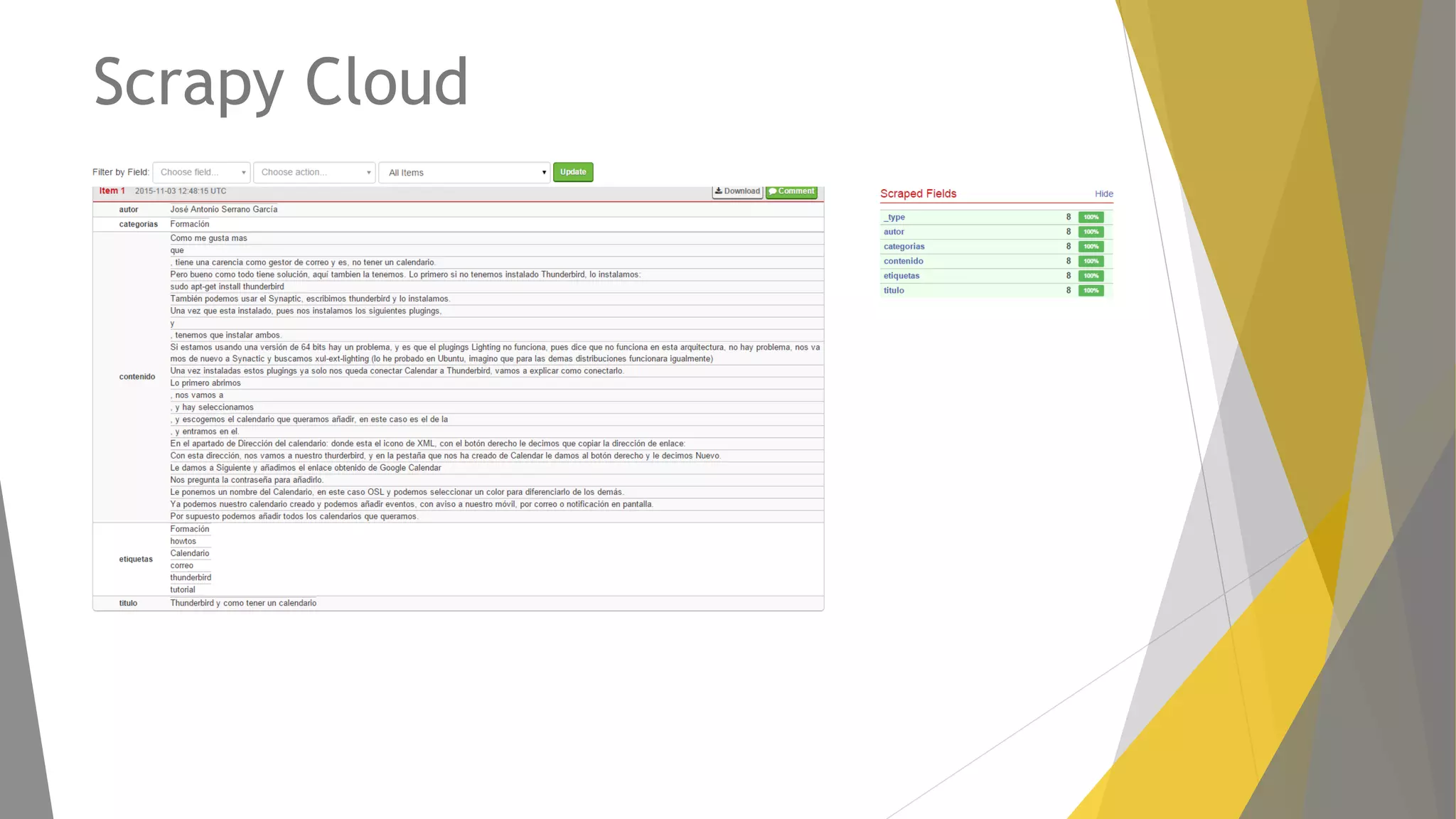
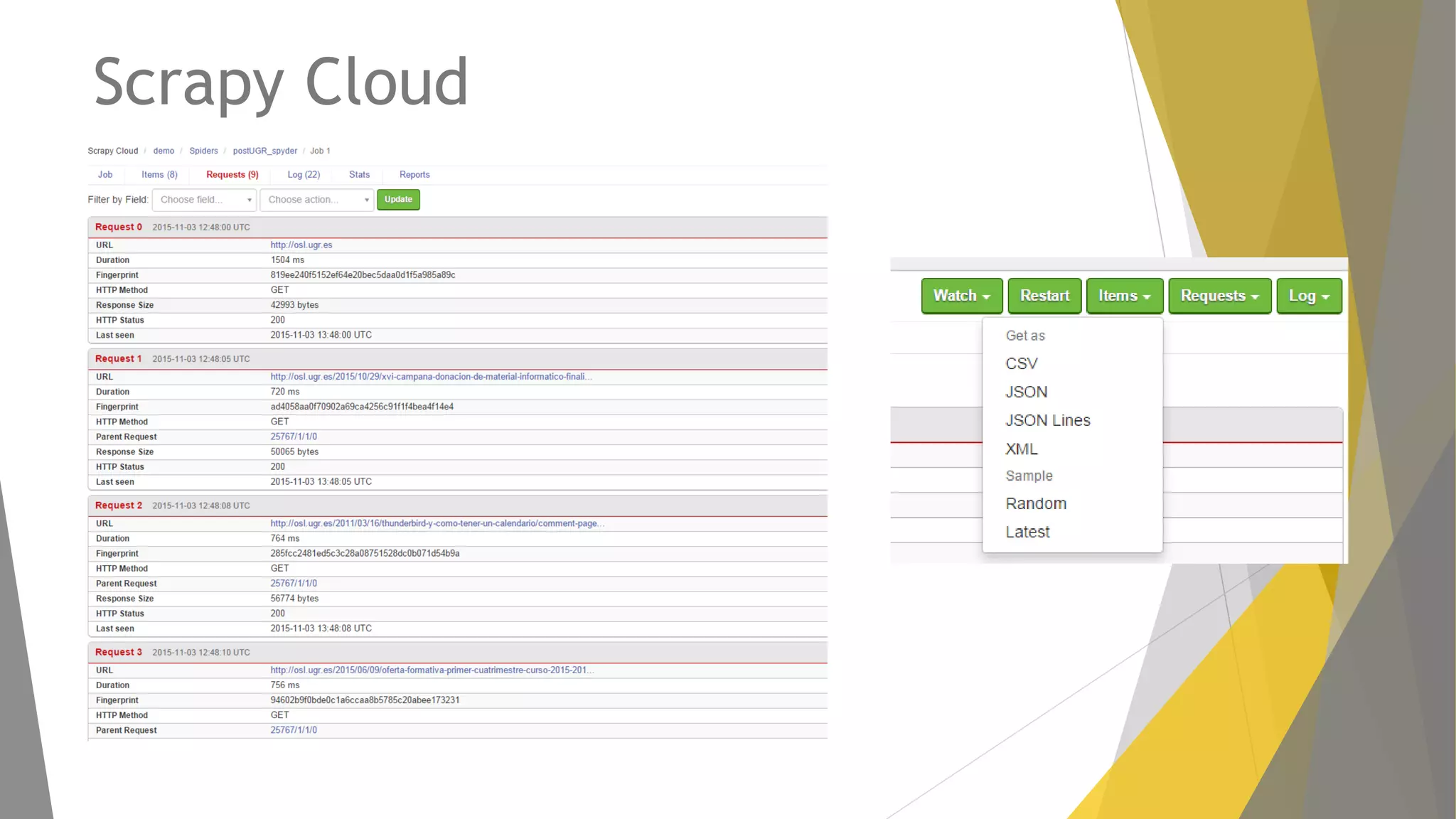
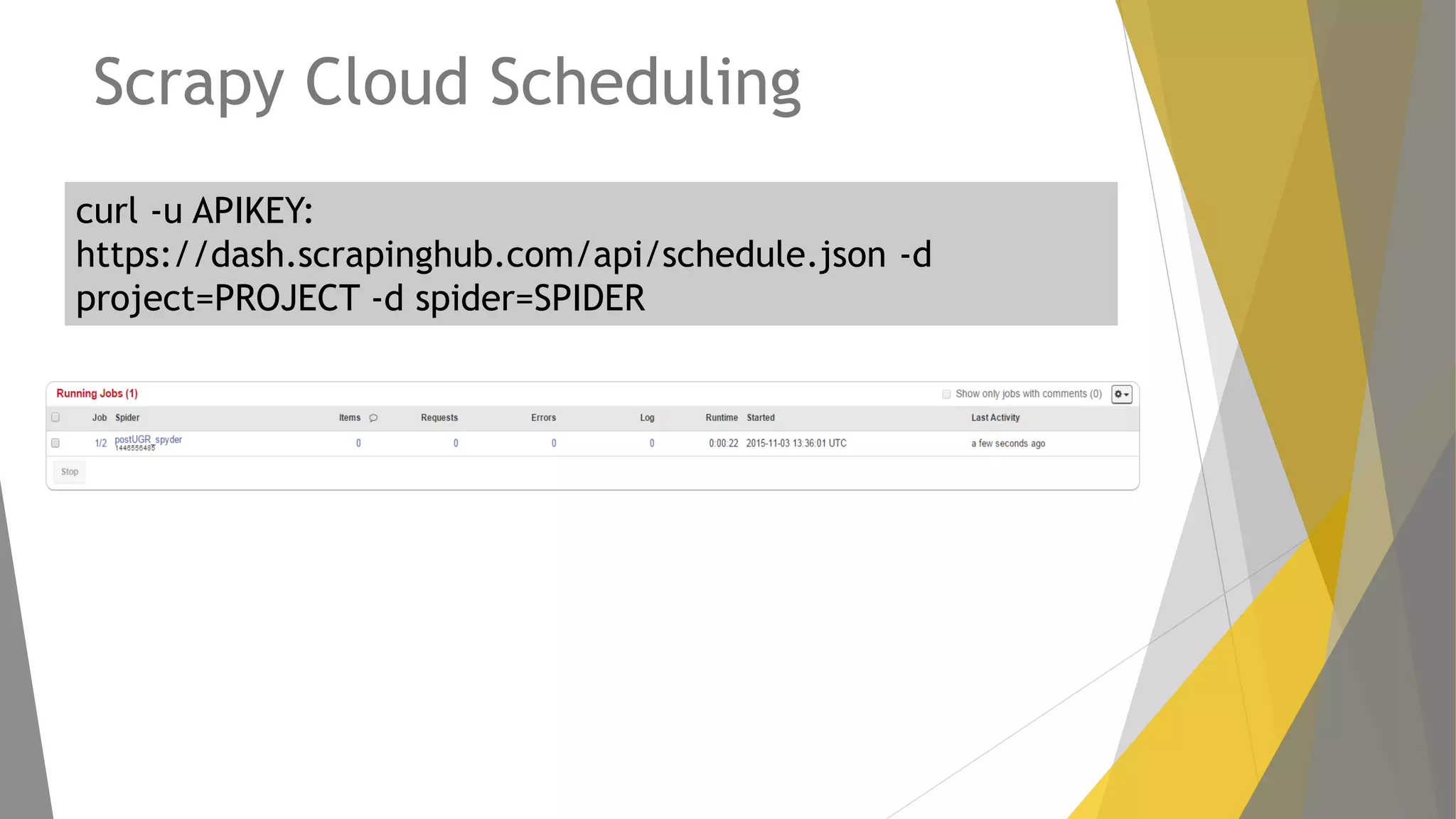
Descripción de plugins como Scraper y Parse Hub, además de Scrapy Cloud para la implementación y seguimiento.
Fuentes y referencias útiles sobre herramientas de scraping, librerías y documentación.