Downloaded 12 times


![3 dom(SSN)=Social_security_numbers; It is also possible to refer to attributes of a relation schema by their position within the relation; thus, the second attribute of the STUDENT relation is SSN, whereas the fourth attribute is Address. Formally, Given R(A1, A2, .........., An) r(R) dom (A1) X dom (A2) X ....X dom(An) Relation state: A relation (or relation state) r of the relation schema R(A1, A2, .........., An) also denoted by r(R), is a set of tuples (rows) r(R) = {t1, t2, …, tn} where each ti is an n-tuple. ti = <v1, v2, …, vn> where each vj element-of dom(Aj). Let R(A1, A2) be a relation schema: Let dom(A1) = {0,1} Let dom(A2) = {a,b,c} Then: dom(A1) X dom(A2) is all possible combinations: {<0,a> , <0,b> , <0,c>, <1,a>, <1,b>, <1,c> } The relation state r(R) dom(A1) X dom(A2) A relation (or relation state) r of the relation schema R(A1, A2, .........., An) also denoted by r(R), is a set of n-tuples r = {tl , tz, ... , tm}. Each n-tuple t is an ordered list of n values t = <vI' VZ, ... , vn>, where each value Vi' 1 ::; i ::; n, is an element of dom(A) or is a special null value. The ith value in tuple t, which corresponds to the attribute Ai' is referred to as t[AJ (or t[i] if we use the positional notation). The terms relation intension for the schema R and relation extension for a relation state r(R) are also commonly used. Figure 5.1 shows an example of a STUDENT relation, which corresponds to the STUDENT schema just specified. Each tuple in the relation represents a particular student entity. We Let R(A1, A2) be a relation schema: Let dom(A1) = {0,1} Let dom(A2) = {a,b,c} Then: dom(A1) X dom(A2) is all possible combinations: {<0,a> , <0,b> , <0,c>, <1,a>, <1,b>, <1,c> } The relation state r(R) dom(A1) X dom(A2) FORMAL DEFINITION Formally, Given R(A1, A2, .........., An)](https://image.slidesharecdn.com/chap5relationaldatamodel-190406083311/75/The-Relational-Data-Model-and-Relational-Database-Constraints-Ch5-Navathe-4th-edition-Ch7-Navathe-3rd-edition-3-2048.jpg)

![6 may have a different number of attributes. In other words, you should not interpret 'minimal' to mean the super key with the fewest attributes. A candidate key has two properties: (i) in each tuple of R, the values of K uniquely identify that tuple (uniqueness) (ii) no proper subset of K has the uniqueness property (irreducibility). Primary Key The primary key of a relation is a candidate key especially selected to be the key for the relation. In other words, it is a choice, and there can be only one candidate key designated to be the primary key. Relationship between identity keys The relationship between keys: Superkey ⊇ Candidate Key ⊇ Primary Key Foreign keys The attribute(s) within one relation that matches a candidate key of another relation. A relation may have several foreign keys, associated with different target relations. Relational Model Notations: A relation schema R of degree n is denoted by R(A1, A2, . . ., An). The letters Q, R, S denote relation names. The letters q, r, s denote relation states. The letters t, u, v denote tuples. In general, the name of a relation schema such as STUDENT also indicates the current set of tuples in that relation—the current relation state—whereas STUDENT(Name, SSN, . . .) refers only to the relation schema. An attribute A can be qualified with the relation name R to which it belongs by using the dot notation R.A—for example, STUDENT.Name or STUDENT.Age. This is because the same name may be used for two attributes in different relations. However, all attribute names in a particular relation must be distinct. An n-tuple t in a relation r(R) is denoted by t = <v1, v2, . . ., vn>, where vi is the value corresponding to attribute Ai. The following notation refers to component values of tuples: Both t[Ai] and t.Ai refer to the value vi in t for attribute Ai. Both t[Au, Aw, . . ., Az] and t.(Au, Aw, . . ., Az), where Au, Aw, . . ., Az is a list of attributes from R, refer to the subtuple of values <vu, vw, . . ., vz> from t corresponding to the attributes specified in the list. 5.2 RELATIONAL MODEL CONSTRAINTS AND RELATIONAL DATABASE SCHEMAS](https://image.slidesharecdn.com/chap5relationaldatamodel-190406083311/75/The-Relational-Data-Model-and-Relational-Database-Constraints-Ch5-Navathe-4th-edition-Ch7-Navathe-3rd-edition-6-2048.jpg)
![7 Constraints: Constraints are conditions that must hold on all valid relation instances. Restrictions on the actual values in a database state. Derived from the rules in the miniworld that the database represents. Constraints on databases can generally be divided into three main categories: Constraints that are inherent in the data model. We call these inherent model based or implicit constraints. Constraints that can be directly expressed in the schemas of the data model, typically by specifying them in the DDL. We call these schema-based constraints or explicit constraints. Constraints that cannot be directly expressed in the schemas of the data model, and hence must be expressed and enforced by the application programs. We call these application-based constraints or semantic constraints or business rule. 5.2.1 Domain constraints Domain constraints specify that within each tuple, the value of each attribute A must be an atomic value from the domain dom(A). The data types associated with domains typically include: Numeric data types for integers and real numbers Characters Booleans Fixed-length strings Variable-length strings Date, time, timestamp Money Other special data types These various data types are offered by SQL-99. 5.2.2. Key Constraints and Constraints on Null Values Superkey of R: A set of attributes, SK, of R such that no two tuples in any valid relational instance, r( R), will have the same value for SK. Therefore, for any two distinct tuples, t1 and t2 in r( R), t1[ SK] != t2[SK]. Key of R: A minimal superkey. That is, a superkey, K, of R such that the removal of ANY attribute from K will result in a set of attributes that are not a superkey. Example: The CAR relation schema: CAR(State, Reg#, SerialNo, Make, Model, Year) has two keys Key1 = {State, Reg#}, Key2 = {SerialNo}, which are also superkeys. {SerialNo, Make} is a superkey but not a key. If a relation has several candidate keys, one is chosen arbitrarily to be the primary key. The primary key attributes are underlined. 5.2.3 Relational Databases and Relational Database Schema](https://image.slidesharecdn.com/chap5relationaldatamodel-190406083311/75/The-Relational-Data-Model-and-Relational-Database-Constraints-Ch5-Navathe-4th-edition-Ch7-Navathe-3rd-edition-7-2048.jpg)

![10 5.2.4 Entity Integrity, Referential Integrity,and Foreign Keys Entity integrity constraint No primary key value can be NULL because the primary key value is used to distinguish each tuples in a relation. Key constraints and Entity integrity constraint are specified on individual relations. Referential integrity constraint A constraint involving two relations (the previous constraints involve a single relation). Used to specify a relationship among tuples in two relations: the referencing relation and the referenced relation. Tuples in the referencing relation R1 have attributes FK (called foreign key attributes) that reference the primary key attributes PK of the referenced relation R2. A tuple t1 in R1 is said to reference a tuple t2 in R2 if t1[FK] = t2[PK]. A referential integrity constraint can be displayed in a relational database schema as a directed arc from R1.FK to R2. Foreign key rules: The attributes in FK have the same domain(s) as the primary key attributes PK. The value in the foreign key column (or columns) FK of the the referencing relation R1 can be either: i) A value of an existing primary key value of the corresponding primary key PK in the referenced relation R2, or ii) A null. In case (ii), the FK in R1 should not be a part of its own primary key.](https://image.slidesharecdn.com/chap5relationaldatamodel-190406083311/75/The-Relational-Data-Model-and-Relational-Database-Constraints-Ch5-Navathe-4th-edition-Ch7-Navathe-3rd-edition-10-2048.jpg)



The document outlines the relational data model concepts and constraints as introduced by Dr. E.F. Codd in 1970, highlighting the advantages of relational database management systems (RDBMS) over earlier data models. It explains key components such as relations, attributes, tuples, and various types of constraints including domain, key, and referential integrity constraints. Additionally, it discusses Codd's 12 rules that define the criteria for a fully relational database system.
Overview of relational database concepts, history, and foundational principles based on E.F. Codd's work.
Introduction to basic terms: relations, tuples, attributes, and their definitions in the relational model.
Detailed definitions of relation states, tuples, and their mathematical representations in the relational model.
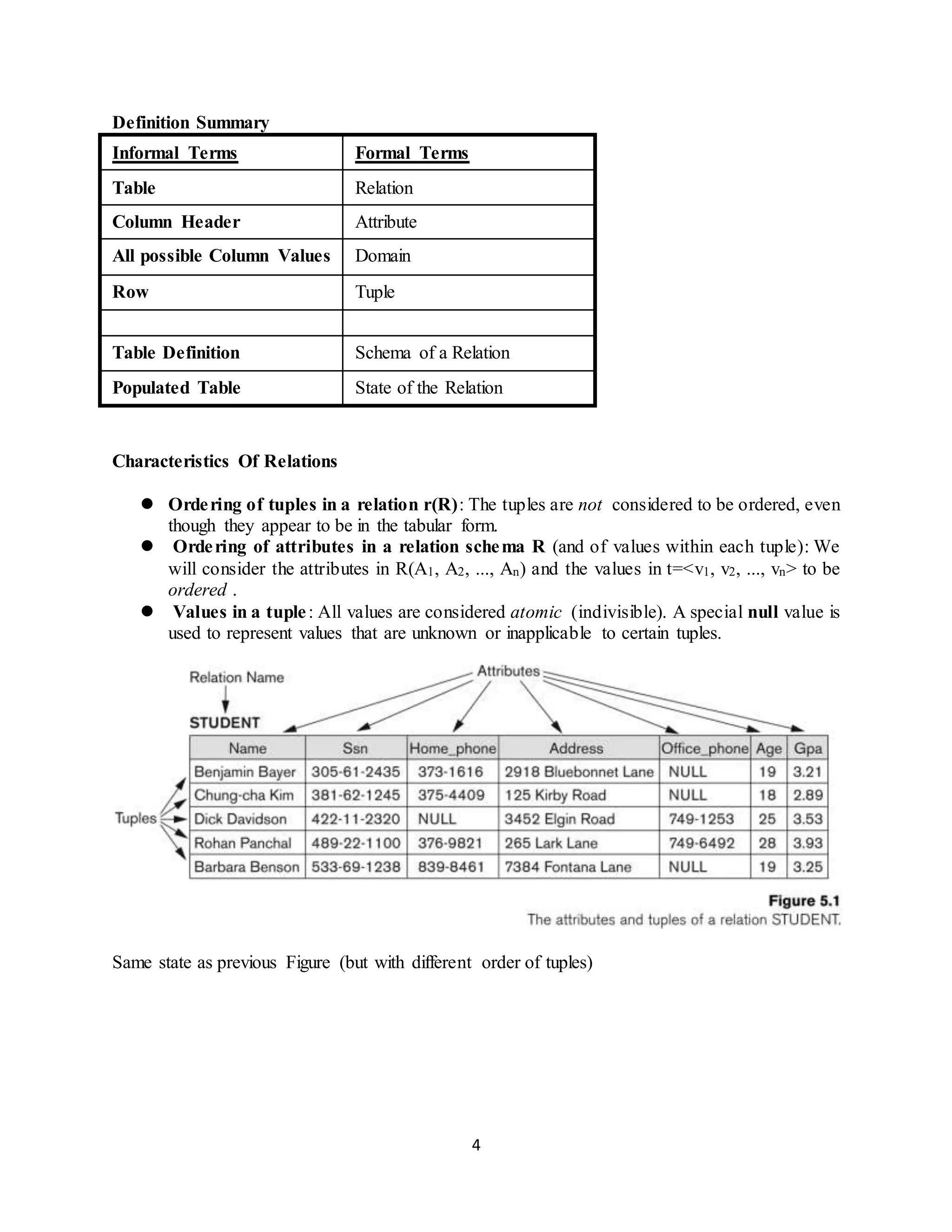
Characteristics of relations, ordering of tuples, attributes, and atomic values in a relational database.
Discussion on atomic values, handling NULLs, composite/multivalued attributes, and basic relational model constraints.
Explanation of superkeys, candidate keys, primary keys, foreign keys, and their relationships in the relational model.
Categories of constraints in relational databases, including domain constraints and their importance.
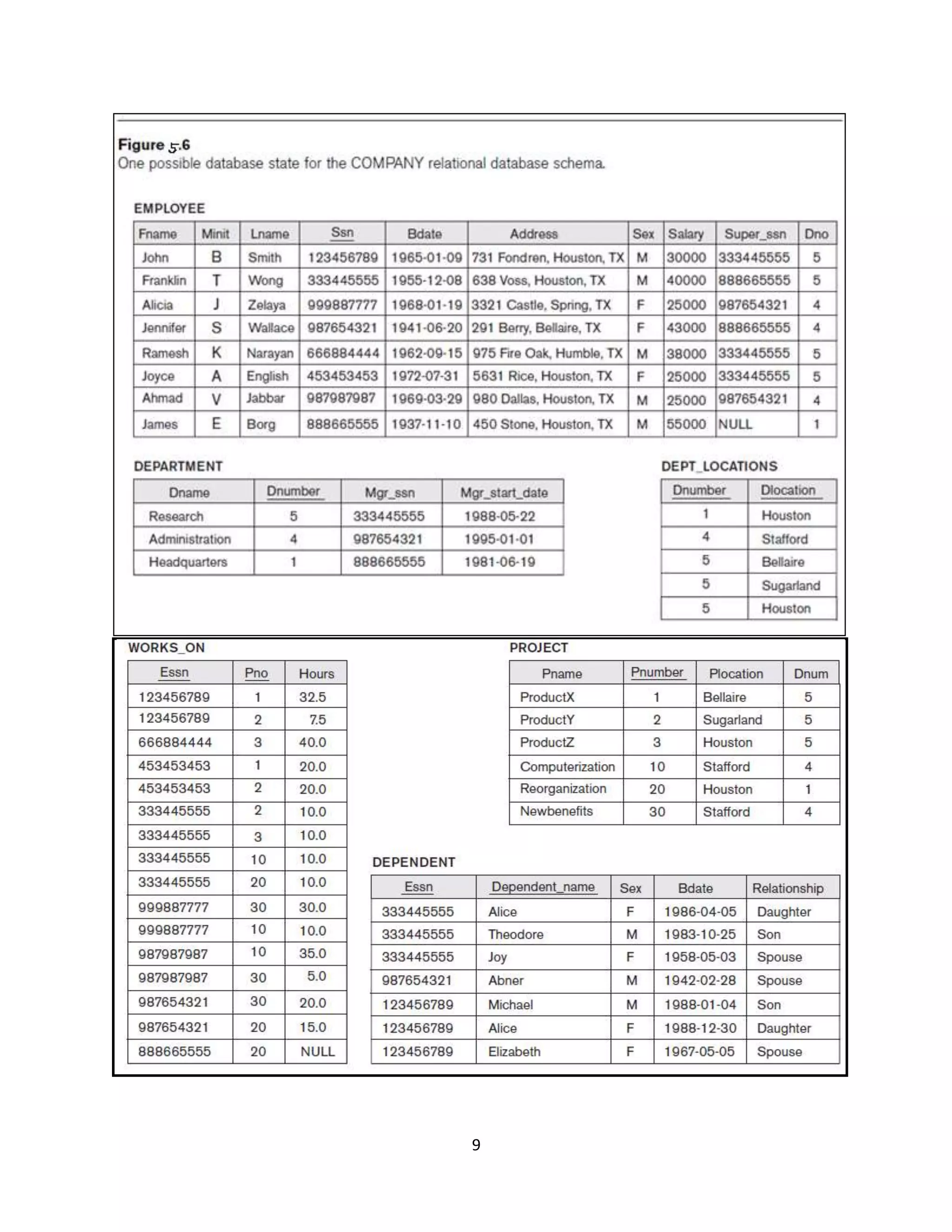
Definition of relational database schema, set of relation states, and integrity constraints in validating data.
Entity integrity and referential integrity constraints, importance of primary/foreign keys in relational databases.
Dr. Codd's 12 rules defining the requirements for a DBMS to be considered fully relational and their implications.