Downloaded 261 times


![KNO.E.SIS knoesis.org Director: Amit Sheth knoesis.wright.edu/amit/ Graduate Students: Meena Nagarajan knoesis.wright.edu/students/meena/ [email_address] Cartic Ramakrishnan knoesis.wright.edu/students/cartic/ [email_address]](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-3-2048.jpg)










![Undiscovered Public Knowledge [Swanson] – as mentioned in [Hearst99] Search no longer enough Information overload – prohibitively large number of hits UPK increases with increasing corpus size Manual analysis very tedious Examples [Hearst99] Example 1 – Using Text to Form Hypotheses about Disease Example 2 – Using Text to Uncover Social Impact](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-17-2048.jpg)
![Swanson’s discoveries Associations between Migraine and Magnesium [Hearst99] stress is associated with migraines stress can lead to loss of magnesium calcium channel blockers prevent some migraines magnesium is a natural calcium channel blocker spreading cortical depression (SCD) is implicated in some migraines high levels of magnesium inhibit SCD migraine patients have high platelet aggregability magnesium can suppress platelet aggregability](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-18-2048.jpg)

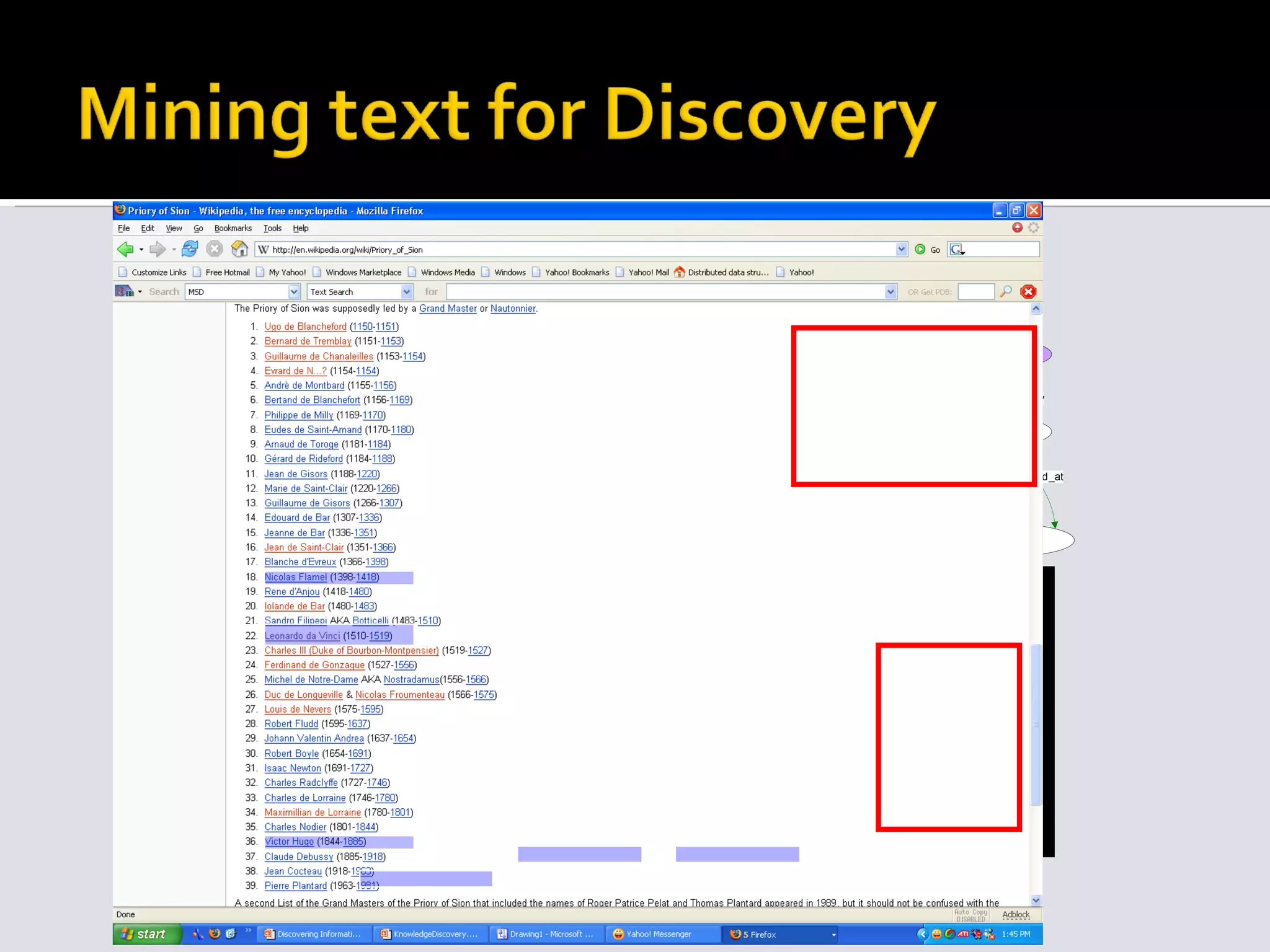
![Mining text to improve existing information access mechanisms Search [Storylines] IR [QA systems] Browsing [Flamenco] Mining text for Discovery & insight [Relationship Extraction] Creation of new knowledge Ontology instance-base population Ontology schema learning](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-20-2048.jpg)
![Web search – aims at optimizing for top k (~10) hits Beyond top 10 Pages expressing related latent views on topic Possible reliable sources of additional information Storylines in search results [3]](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-21-2048.jpg)

![TextRunner[4] A system that uses the result of dependency parses of sentences to train a Naïve Bayes classifier for Web-scale extraction of relationships Does not require parsing for extraction – only required for training Training on features – POS tag sequences, if object is proper noun, number of tokens to right or left etc. This system is able to respond to queries like "What did Thomas Edison invent?"](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-23-2048.jpg)
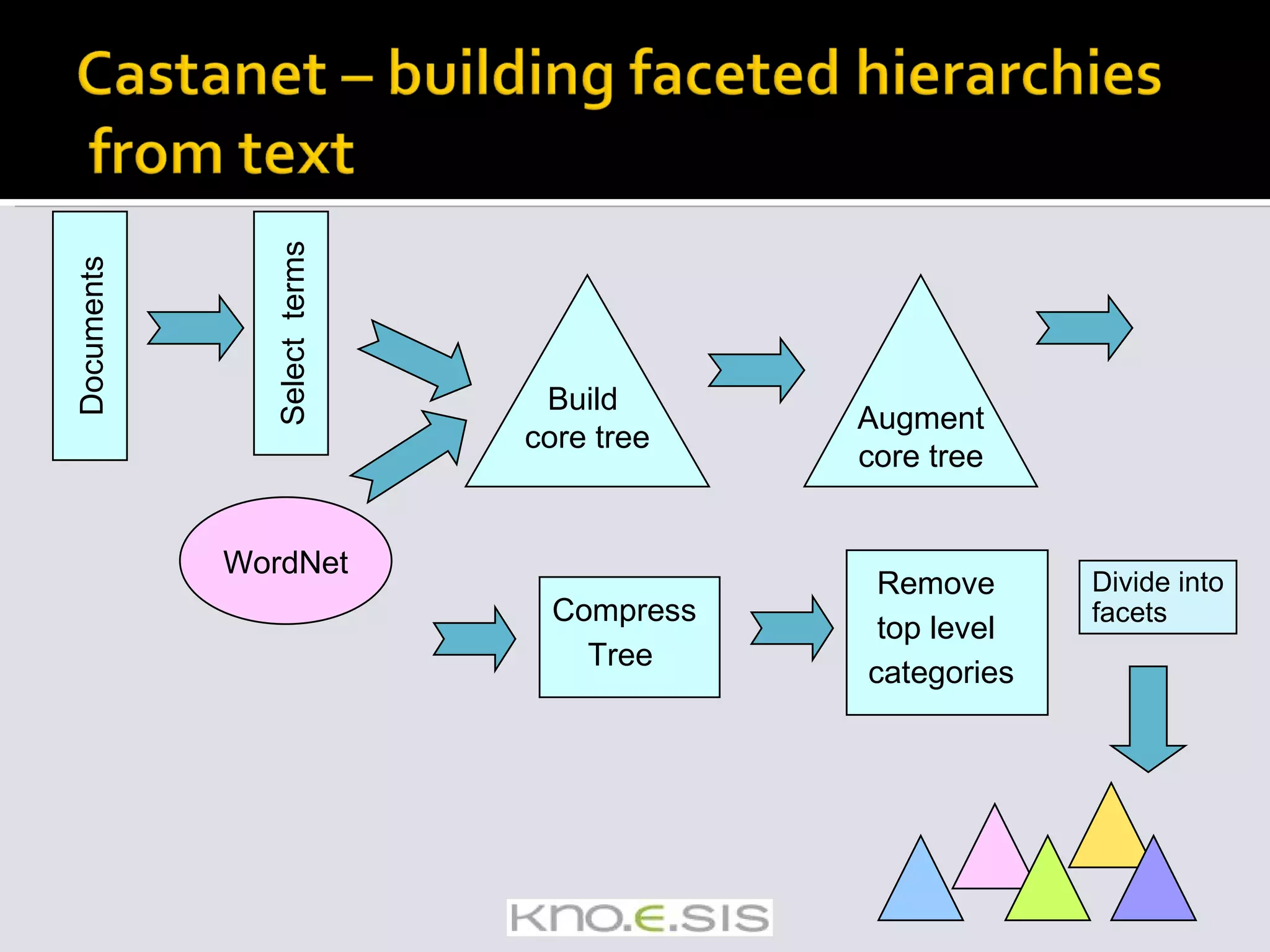
![Castanet [1] Semi-automatically builds faceted hierarchical metadata structures from text This is combined with Flamenco [2] to support faceted browsing of content](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-24-2048.jpg)


![[Hearst92] Finding class instances [Ramakrishnan et. al. 08] [Nguyen07] Finding attribute “like” relation instances](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-28-2048.jpg)


![[hearst 97] Abstract concepts are difficult to represent “ Countless” combinations of subtle, abstract relationships among concepts Many ways to represent similar concepts E.g. space ship, flying saucer, UFO Concepts are difficult to visualize High dimensionality Tens or hundreds of thousands of features](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-32-2048.jpg)

![[hearst 97] Highly redundant data … most of the methods count on this property Just about any simple algorithm can get “good” results for simple tasks: Pull out “important” phrases Find “meaningfully” related words Create some sort of summary from documents](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-34-2048.jpg)


























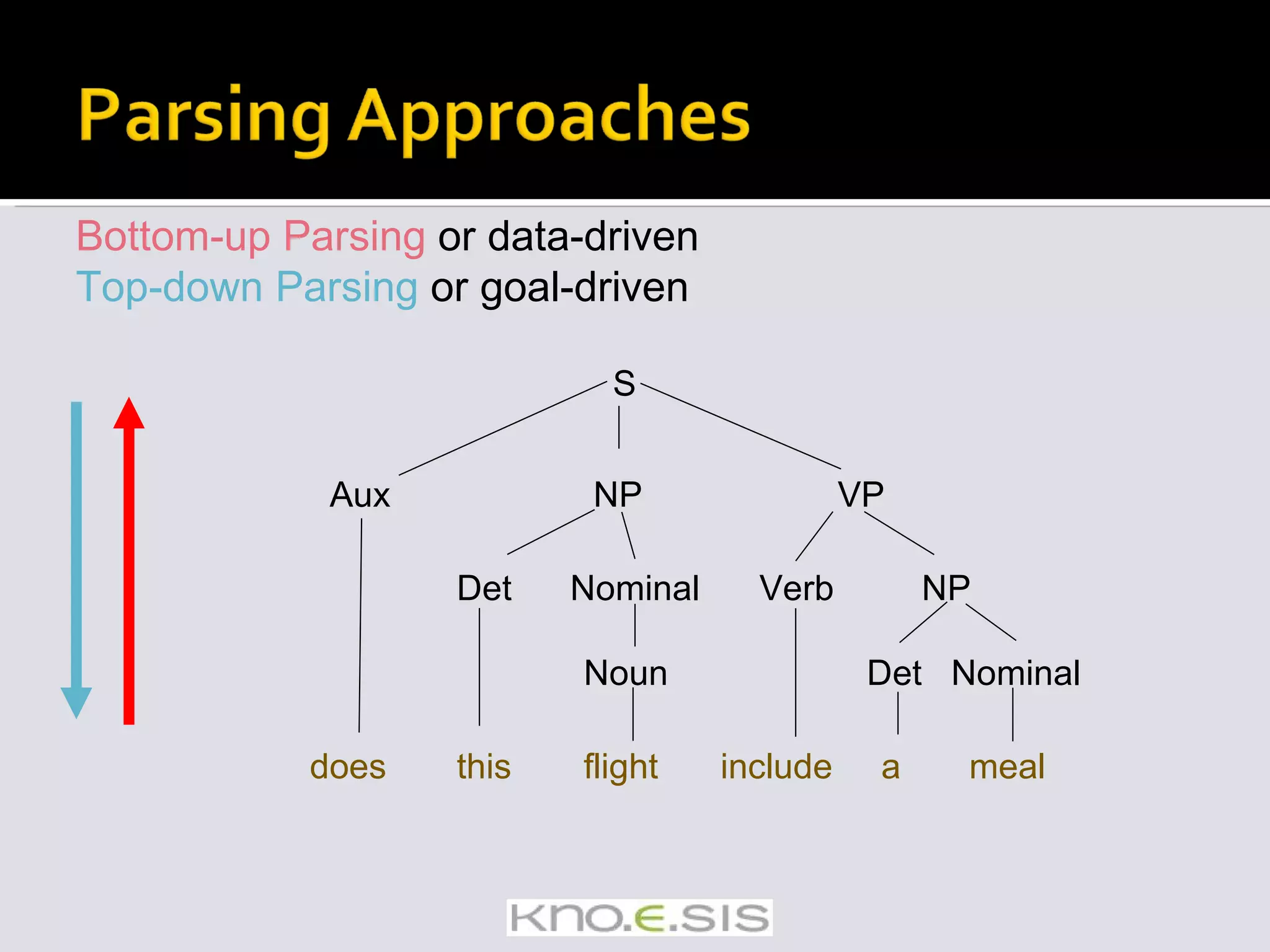
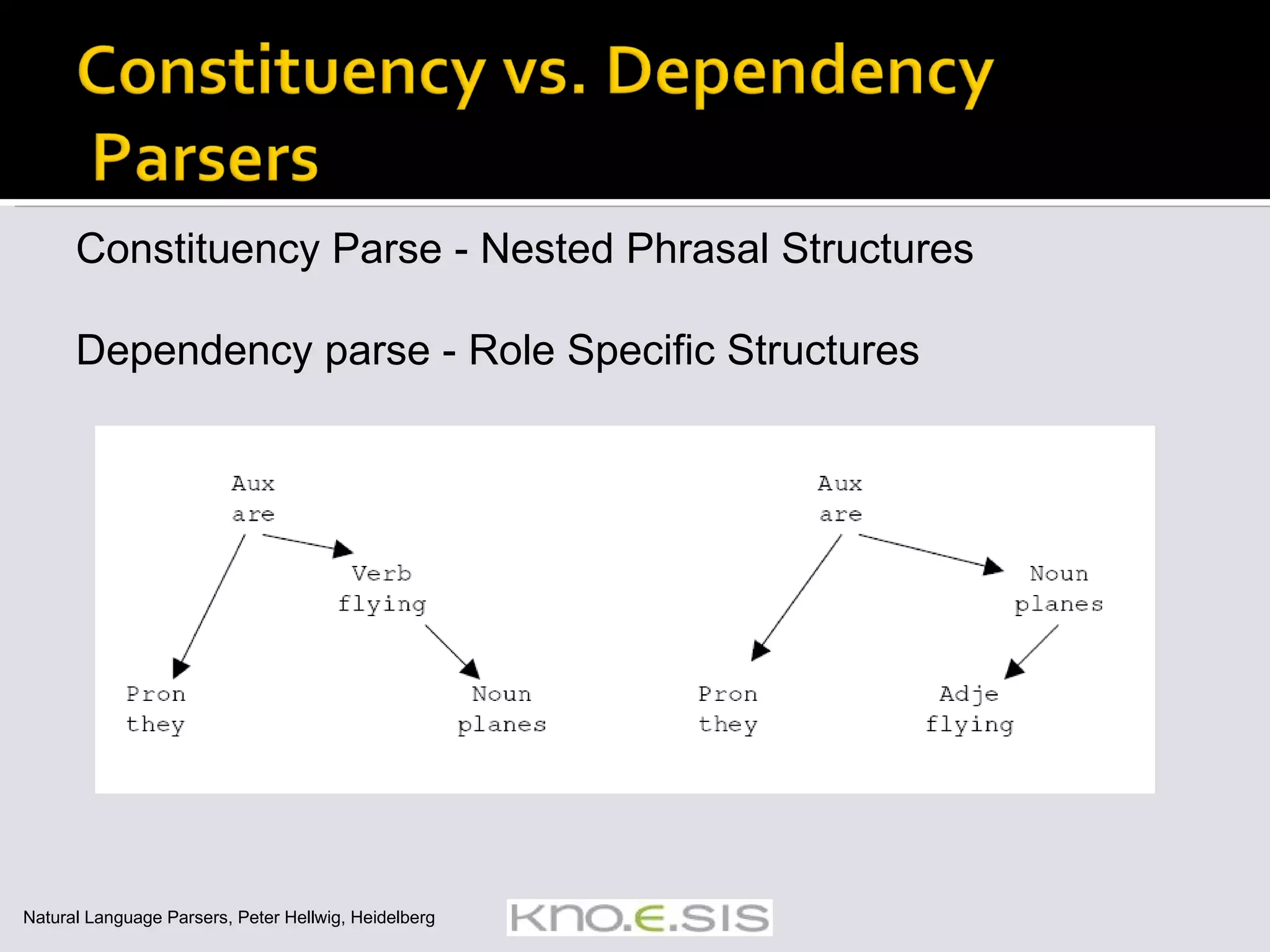



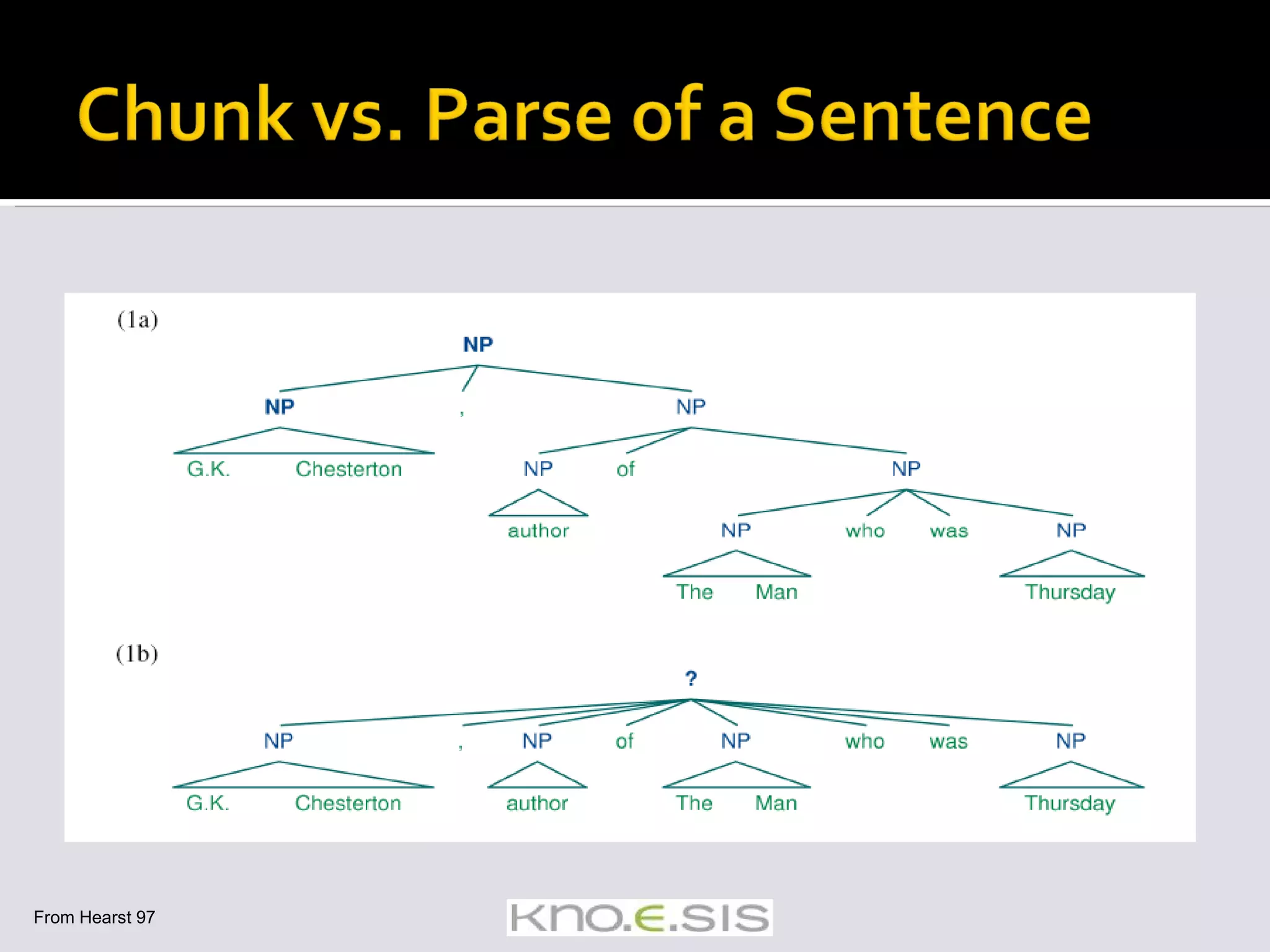
![Some applications don’t need the complex output of a full parse Chunking / Shallow Parse / Partial Parse Identifying and classifying flat, non-overlapping contiguous units in text Segmenting and tagging Example of chunking a sentence [ NP The morning flight] from [ NP Denver] [ VP has arrived] Chunking algos mention](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-66-2048.jpg)




































![Rule based [Mikheev et. Al 1999] Frequency Based "China International Trust and Investment Corp” "Suspended Ceiling Contractors Ltd” "Hughes“ when "Hughes Communications Ltd.“ is already marked as an organization Scalability issues: Expensive to create manually Leverages domain specific information – domain specific Tend to be corpus-specific – due to manual process](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-106-2048.jpg)
![Machine learning approaches Ability to generalize better than rules Can capture complex patterns Requires training data Often the bottleneck Techniques [list taken from Agichtein2007 ] Naive Bayes SRV [Freitag 1998], Inductive Logic Programming Rapier [Califf and Mooney 1997] Hidden Markov Models [Leek 1997] Maximum Entropy Markov Models [McCallum et al. 2000] Conditional Random Fields [Lafferty et al. 2001]](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-107-2048.jpg)


![MEMMs [McCallum et. al, 2000] Discriminative Find parameters to maximize P(Y|X) No longer assume that features are independent f<Is-capitalized,Company>(“Apple”, Company) = 1. Do not take future observations into account (no forward-backward) Problems Label bias problem](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-110-2048.jpg)
![CRFs [Lafferty et. al, 2001] Discriminative Doesn’t assume that features are independent When labeling Y i future observations are taken into account Global optimization – label bias prevented The best of both worlds!](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-111-2048.jpg)
![Example [ORG U.S. ] general [PER David Petraeus ] heads for [LOC Baghdad ] . Token POS Chunk Tag --------------------------------------------------------- U.S. NNP I-NP I-ORG general NN I-NP O David NNP I-NP B-PER Petraeus NNP I-NP I-PER heads VBZ I-VP O for IN I-PP O Baghdad NNP I-NP I-LOC . . O O CONLL format – Mallet Major bottleneck is training data](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-112-2048.jpg)
![Context Induction approach [Talukdar2006] Starting with a few seed entities, it is possible to induce high-precision context patterns by exploiting entity context redundancy. New entity instances of the same category can be extracted from unlabeled data with the induced patterns to create high-precision extensions of the seed lists. Features derived from token membership in the extended lists improve the accuracy of learned named-entity taggers. Pruned Extraction patterns Feature generation For CRF](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-113-2048.jpg)


![Supervised BioText – extraction of relationships between diseases and their treatments [Rosario et. al 2004] Rule-based supervised approach [Rinaldi et. al 2004] Semantics of specific relationship encoded as rules Identify a set of relations along with their morphological variants (bind, regulate, signal etc.) subj(bind,X,_,_),pobj(bind,Y,to,_) prep(Y,to,_,_) => bind(X,Y). Axiom formulation was however a manual process involving a domain expert.](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-116-2048.jpg)
![Hand-coded domain specific rules that encode patterns used to extract Molecular pathways [Freidman et. al. 2001] Protein interaction [Saric et. al. 2006] All of the above in the biomedical domain Notice – specificity of relationship types Amount of effort required Also notice types of entities involved in the relationships](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-117-2048.jpg)














![Barbara, R. and A.H. Marti, Classifying semantic relations in bioscience texts, in Proceedings of the 42 nd ACL. 2004, Association for Computational Linguistics: Barcelona, Spain. M.A. Hearst. 1992. Automatic acquisition of hyponyms from large text corpora. In Proceedings of COLING‘ 92, pages 539–545 M. Hearst, "Untangling text data mining," 1999. [Online]. Available: http://citeseer.ist.psu.edu/563035.html Friedman, C., et al., GENIES: a natural-language processing system for the extraction of molecular pathways from journal articles. Bioinformatics, 2001. 17 Suppl 1: p. 1367-4803. Saric, J., et al., Extraction of regulatory gene/protein networks from Medline. Bioinformatics, 2005. Ciaramita, M., et al., Unsupervised Learning of Semantic Relations between Concepts of a Molecular Biology Ontology, in 19th IJCAI. 2005. Dmitry Davidov, Ari Rappoport, Moshe Koppel. Fully Unsupervised Discovery of Concept-Specific Relationships by Web Mining . Proceedings, ACL 2007 , June 2007, Prague. Rosenfeld, B. and Feldman, R. 2007. Clustering for unsupervised relation identification. In Proceedings of the Sixteenth ACM Conference on Conference on information and Knowledge Management (Lisbon, Portugal, November 06 - 10, 2007). Michele Banko , Michael J. Cafarella , Stephen Soderland, Matthew Broadhead , Oren Etzioni : Open Information Extraction from the Web. IJCAI 2007 : 2670-2676 Sekine, S. 2006. On-demand information extraction. In Proceedings of the COLING/ACL on Main Conference Poster Sessions (Sydney, Australia, July 17 - 18, 2006). Annual Meeting of the ACL. Association for Computational Linguistics, Morristown, NJ, 731-738. Suchanek, F. M., Kasneci, G., and Weikum, G. 2007. Yago: a core of semantic knowledge. In Proceedings of the 16th international Conference on World Wide Web (Banff, Alberta, Canada, May 08 - 12, 2007). WWW '07.](https://image.slidesharecdn.com/icsc2008-tutorial-091105161225-phpapp01/75/Text-Analytics-for-Semantic-Computing-138-2048.jpg)

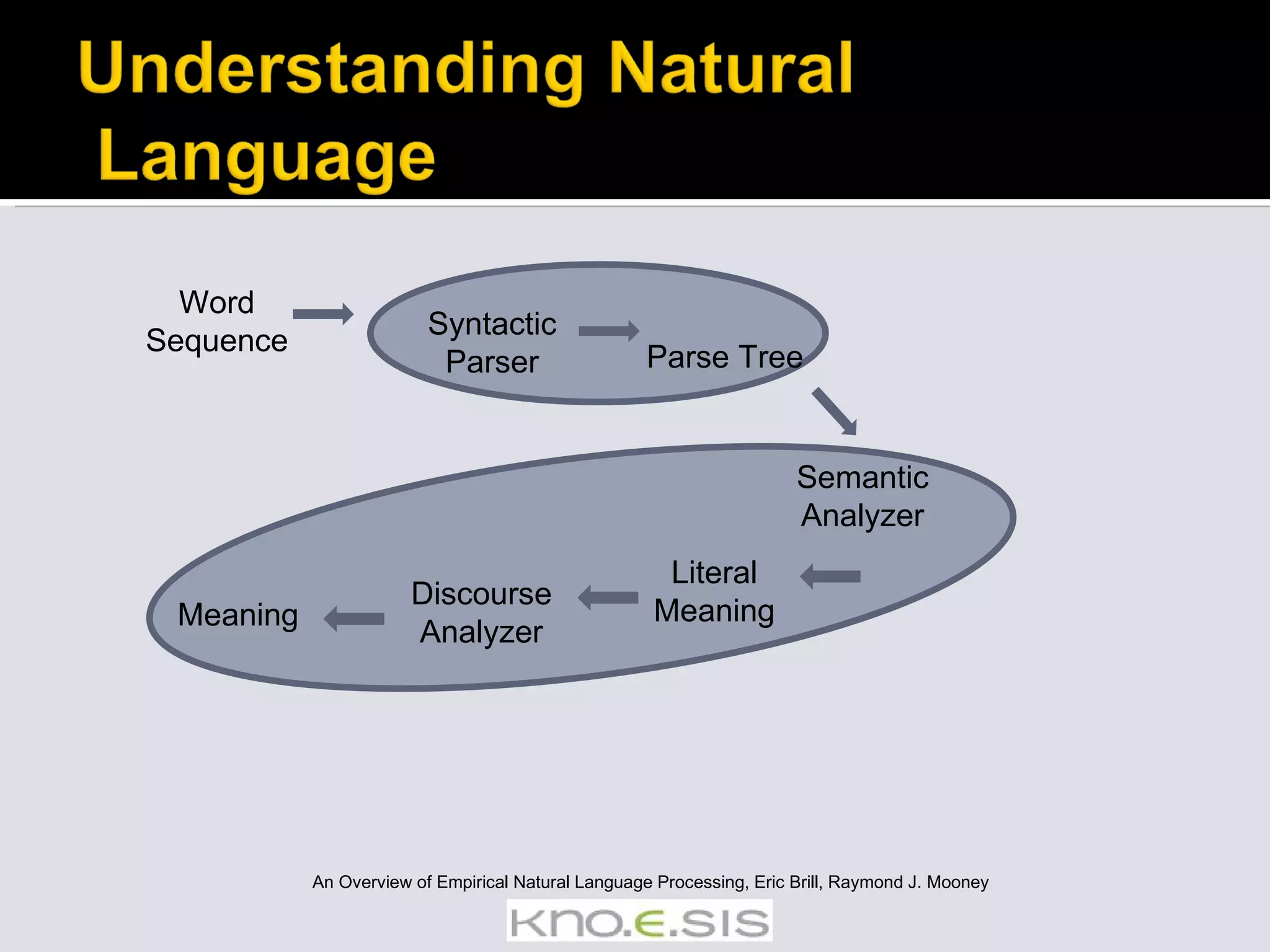
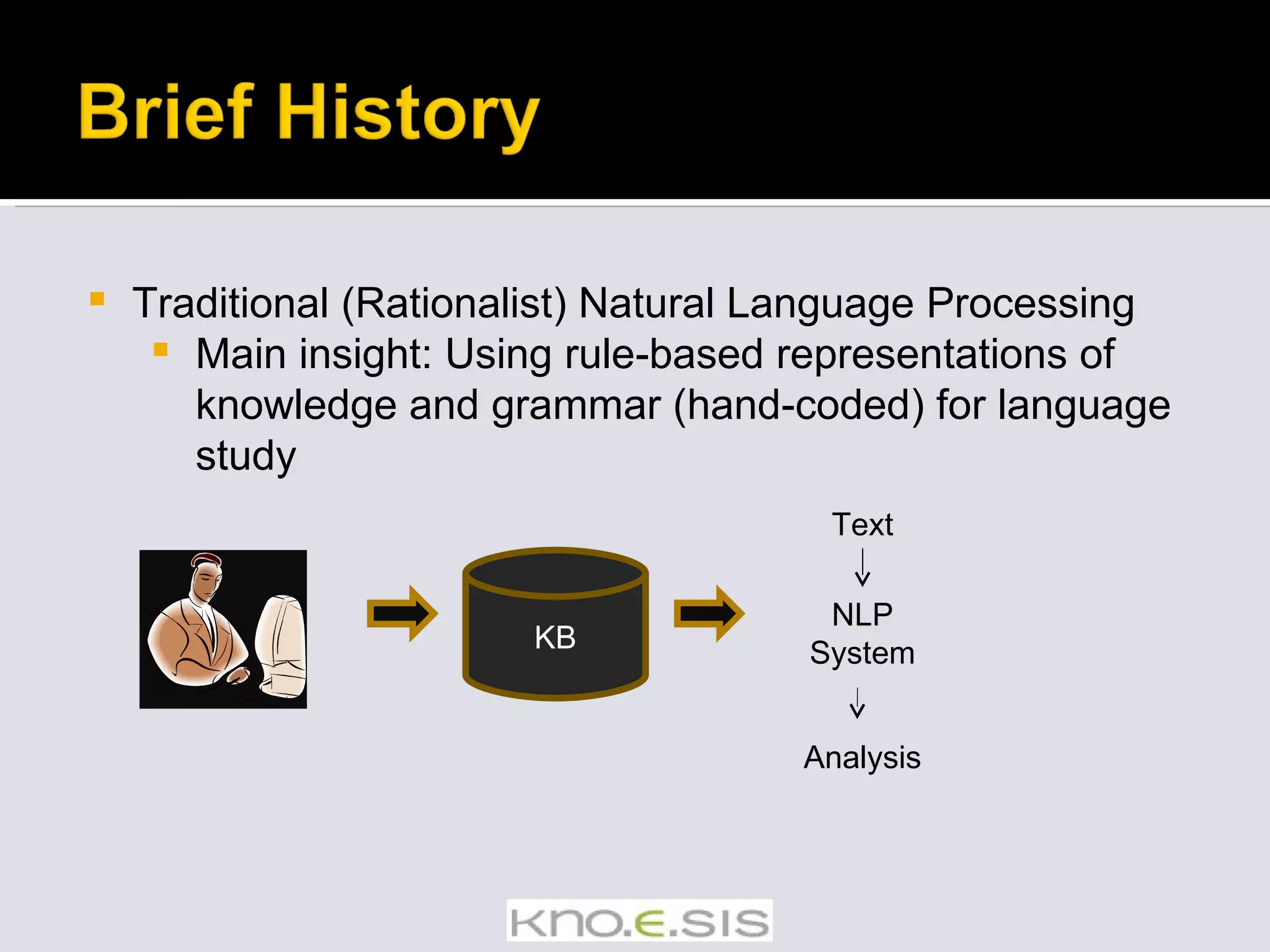
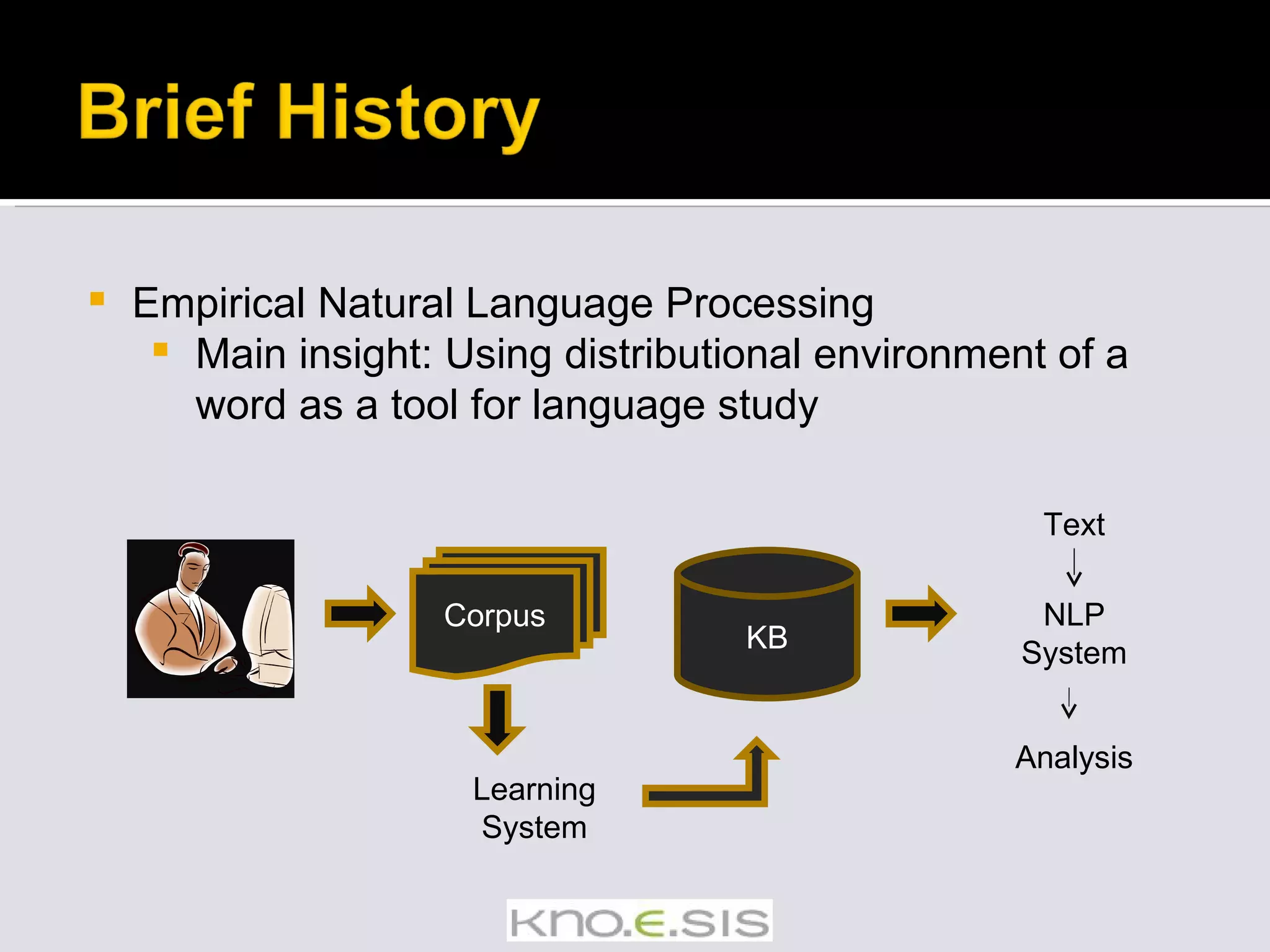
The document provides an overview of empirical natural language processing (NLP), emphasizing the integration of rule-based and data-driven approaches, and explores various NLP tasks such as parsing, semantic analysis, and information extraction. It highlights the challenges in handling text from different sources and the importance of syntactic and semantic understanding to derive new knowledge from data. Additionally, it outlines various algorithms, tools, and methods used in NLP applications, alongside examples of discoveries made through text mining.