The document discusses GPU accelerated data mining, highlighting its benefits of retrieving more information in less time through parallelism enabled by GPUs. It compares the architectures of CPUs and GPUs, emphasizing the computational advantages of GPUs for data-intensive tasks, and introduces programming models like CUDA and OpenCL for implementing parallel data mining algorithms. The conclusion asserts that leveraging GPUs for data mining can lead to significant cost and time efficiencies in business applications.

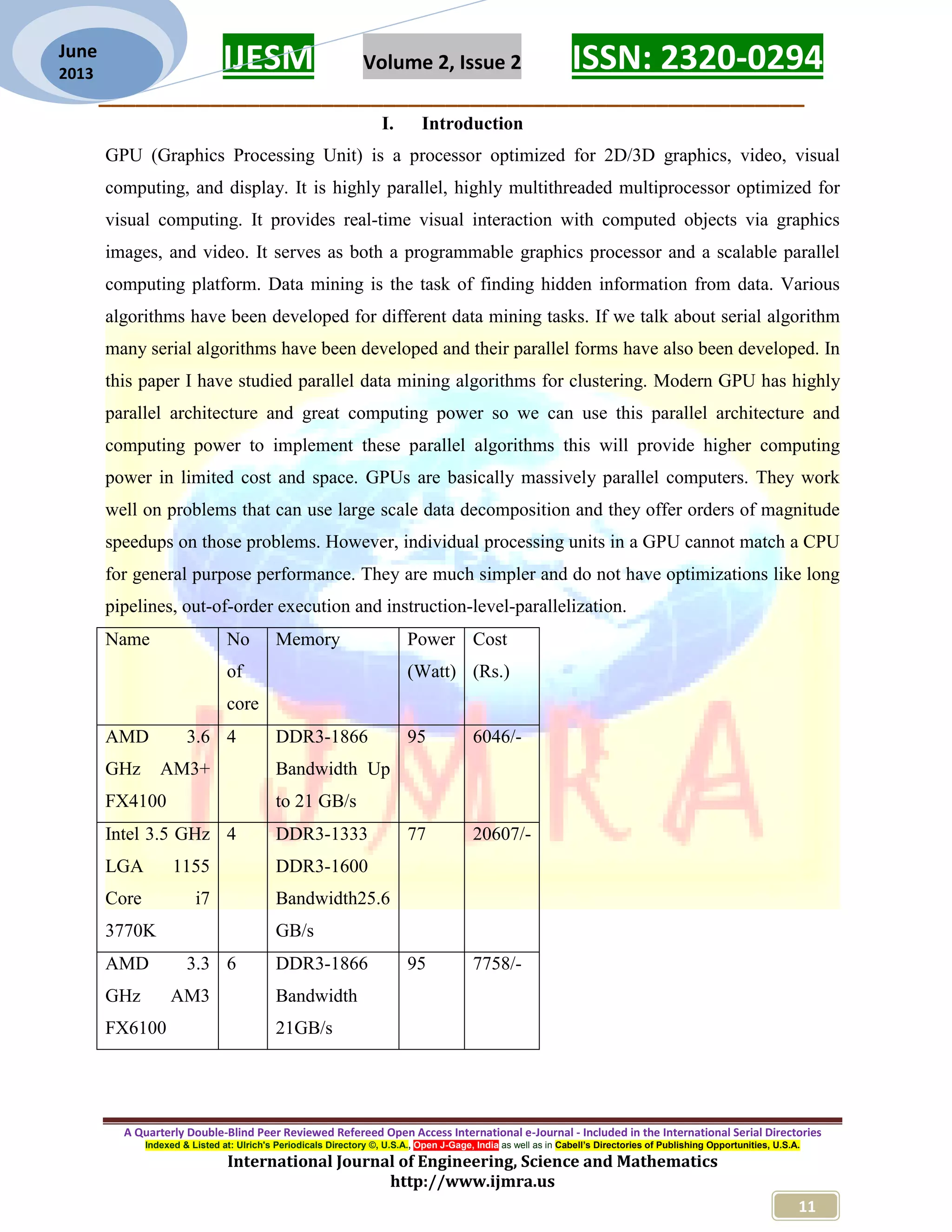
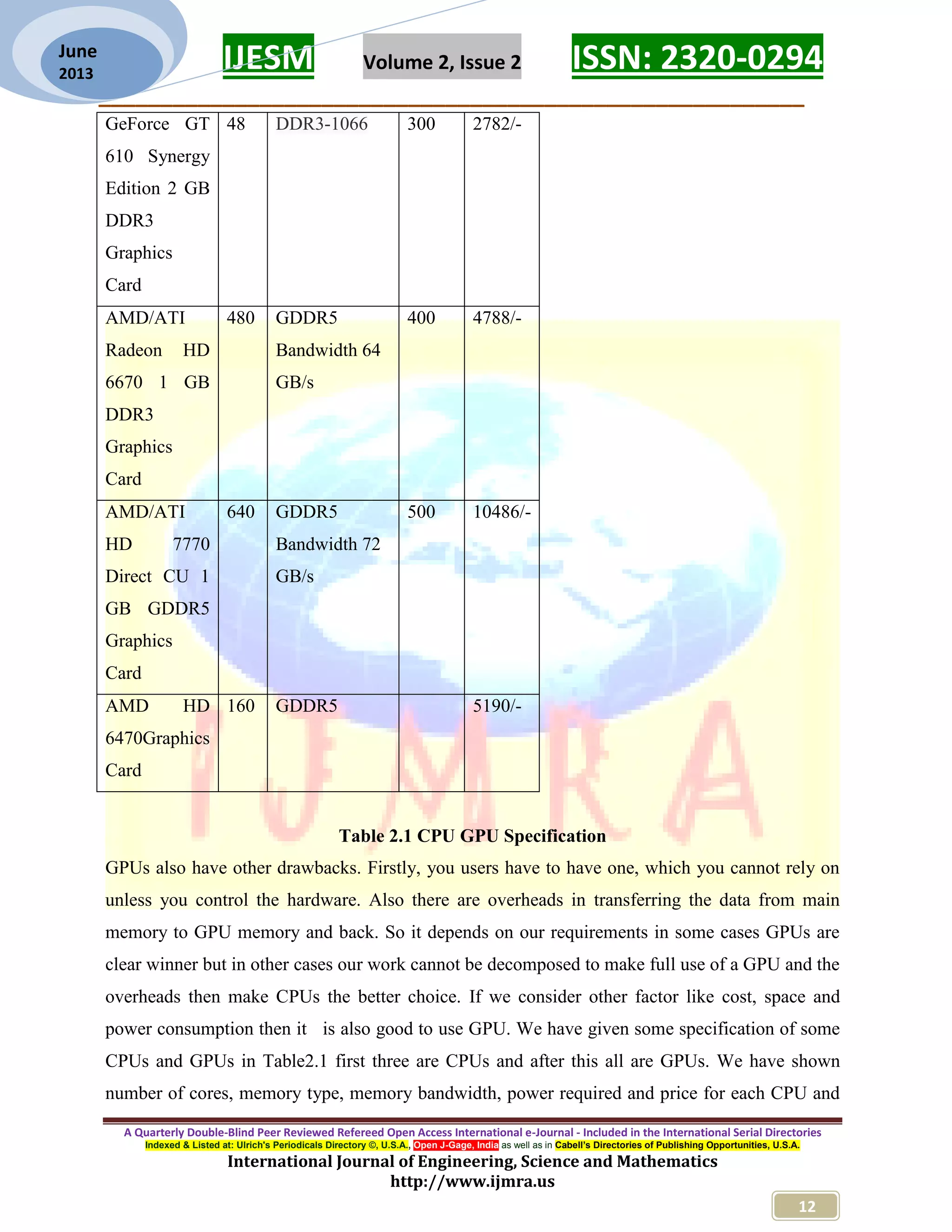
![IJESM Volume 2, Issue 2 ISSN: 2320-0294 _________________________________________________________ A Quarterly Double-Blind Peer Reviewed Refereed Open Access International e-Journal - Included in the International Serial Directories Indexed & Listed at: Ulrich's Periodicals Directory ©, U.S.A., Open J-Gage, India as well as in Cabell’s Directories of Publishing Opportunities, U.S.A. International Journal of Engineering, Science and Mathematics http://www.ijmra.us 13 June 2013 GPU in table. As shown in table 2.1 a 4 core CPU has price Rs.6076/- and a 48 core GPU has price Rs.2072/- so by the given table we can compare other thing also. In the above table we have given cost benefit of GPU over CPU and if we see theoretically GPUs is specially design for parallel computing so it would be faster as compare to parallel CPU. So we will implement parallel data mining algorithm in OpenCL, so that these algorithm can run on GPU and accelerated the data mining in limited cost and space. II. GPU Architecture GPU (Graphics Processing Unit) is an integral part of machine. Previously design as co-processor of CPU which is specially aimed for graphics processing but now day’s GPUs are highly advance because of faster and higher definition graphics requirement. Semiconductor capability, driven by advances in fabrication technology, increases at the same rate for both platforms. The disparity can be attributed to fundamental architectural differences: CPUs are optimized for high performance on sequential code, with many transistors dedicated to extracting instruction-level parallelism with techniques such as branch prediction and out-of order execution. On the other hand, the highly data-parallel nature of graphics computations enables GPUs to use additional transistors more directly for computation, achieving higher arithmetic intensity with the same transistor count [7]. Graphics processing required fast computation, higher memory bandwidth and better memory transfer speed. These features of GPU make it useful as hardware accelerator in general purpose computing that why it is also called GPGPU (General purpose GPU). We are describing the architecture of an Nvidia GPU GeForce 8800 as shown in figure 2.1 it has • 16 Multiprocessors Blocks • Each MP Block Has: • 8 Streaming floating point processors @1.5Ghz • 16K Shared Memory • 64K Constant Cache • 8K Texture Cache • 1.5 GB Shared RAM with 86Gb/s bandwidth • 500 Gflop on one chip (single precision)](https://image.slidesharecdn.com/2ijmra-esm3072-170815135415/75/Survey-for-GPU-Accelerated-Data-Mining-4-2048.jpg)
![IJESM Volume 2, Issue 2 ISSN: 2320-0294 _________________________________________________________ A Quarterly Double-Blind Peer Reviewed Refereed Open Access International e-Journal - Included in the International Serial Directories Indexed & Listed at: Ulrich's Periodicals Directory ©, U.S.A., Open J-Gage, India as well as in Cabell’s Directories of Publishing Opportunities, U.S.A. International Journal of Engineering, Science and Mathematics http://www.ijmra.us 15 June 2013 Figure 2.3: Stream Processor GPU GeForce 8800 has 16 such multi processing unit. In this each multi processor block has its own cache which is limited in their context during GPU computing. III. GPU Computing GPU computing is nothing but the uses of graphics-processing unit (GPU) to accelerate compute- intensive-tasks. GPU’s rapid evolution from a configurable graphics processor to a programmable parallel processor, the ubiquitous GPU in every PC, laptop, desktop, and workstation is a many- core multithreaded multiprocessor that excels at both graphics and computing applications. Today’s GPUs use hundreds of parallel processor cores executing tens of thousands of parallel threads to rapidly solve large problems having substantial inherent parallelism which is proving very useful in today’s high performance computing.GPU computing has become an important part of high performance computing. The programmable units of the GPU follow a single program multiple-data (SPMD) programming model. For efficiency, the GPU processes many elements (vertices or fragments) in parallel using the same program. Each element is independent from the other elements, and in the base programming model, elements cannot communicate with each other [8].CUDA and OpenCL are two different interfaces for programming GPUs. A. CUDA](https://image.slidesharecdn.com/2ijmra-esm3072-170815135415/75/Survey-for-GPU-Accelerated-Data-Mining-6-2048.jpg)

![IJESM Volume 2, Issue 2 ISSN: 2320-0294 _________________________________________________________ A Quarterly Double-Blind Peer Reviewed Refereed Open Access International e-Journal - Included in the International Serial Directories Indexed & Listed at: Ulrich's Periodicals Directory ©, U.S.A., Open J-Gage, India as well as in Cabell’s Directories of Publishing Opportunities, U.S.A. International Journal of Engineering, Science and Mathematics http://www.ijmra.us 17 June 2013 inti = threadIdx.x; C[i] = A[i] + B[i]; } int main() { ... // Kernel invocation with N threads VecAdd<<<1, N>>>(A, B, C); } B. OpenCL OpenCL (Open Computing Language)by the Khronos Group, is an open royalty-free standard for general purpose parallel programming across CPUs, GPUs and other processors, giving software developers portable and efficient access to the power of these heterogeneous processing platforms. OpenCL consists of an API for coordinating parallel computation across heterogeneous processors and a cross-platform programming language with a well specified computation environment. The OpenCL standard Supports both data- and task-based parallel programming models Utilizes a subset of ISO C99 with extensions for parallelism Defines consistent numerical requirements based on IEEE 754 Defines a configuration profile for handheld and embedded devices Efficiently interoperates with OpenGL, OpenGL ES and other graphics APIs Figure 3.2 OpenCL platform model](https://image.slidesharecdn.com/2ijmra-esm3072-170815135415/75/Survey-for-GPU-Accelerated-Data-Mining-8-2048.jpg)


