Download as PDF, PPTX



















GPU computing provides a way to access the power of massively parallel graphics processing units (GPUs) for general purpose computing. GPUs contain over 100 processing cores and can achieve over 500 gigaflops of performance. The CUDA programming model allows programmers to leverage this parallelism by executing compute kernels on the GPU from their existing C/C++ applications. This approach democratizes parallel computing by making highly parallel systems accessible through inexpensive GPUs in personal computers and workstations. Researchers can now explore manycore architectures and parallel algorithms using GPUs as a platform.
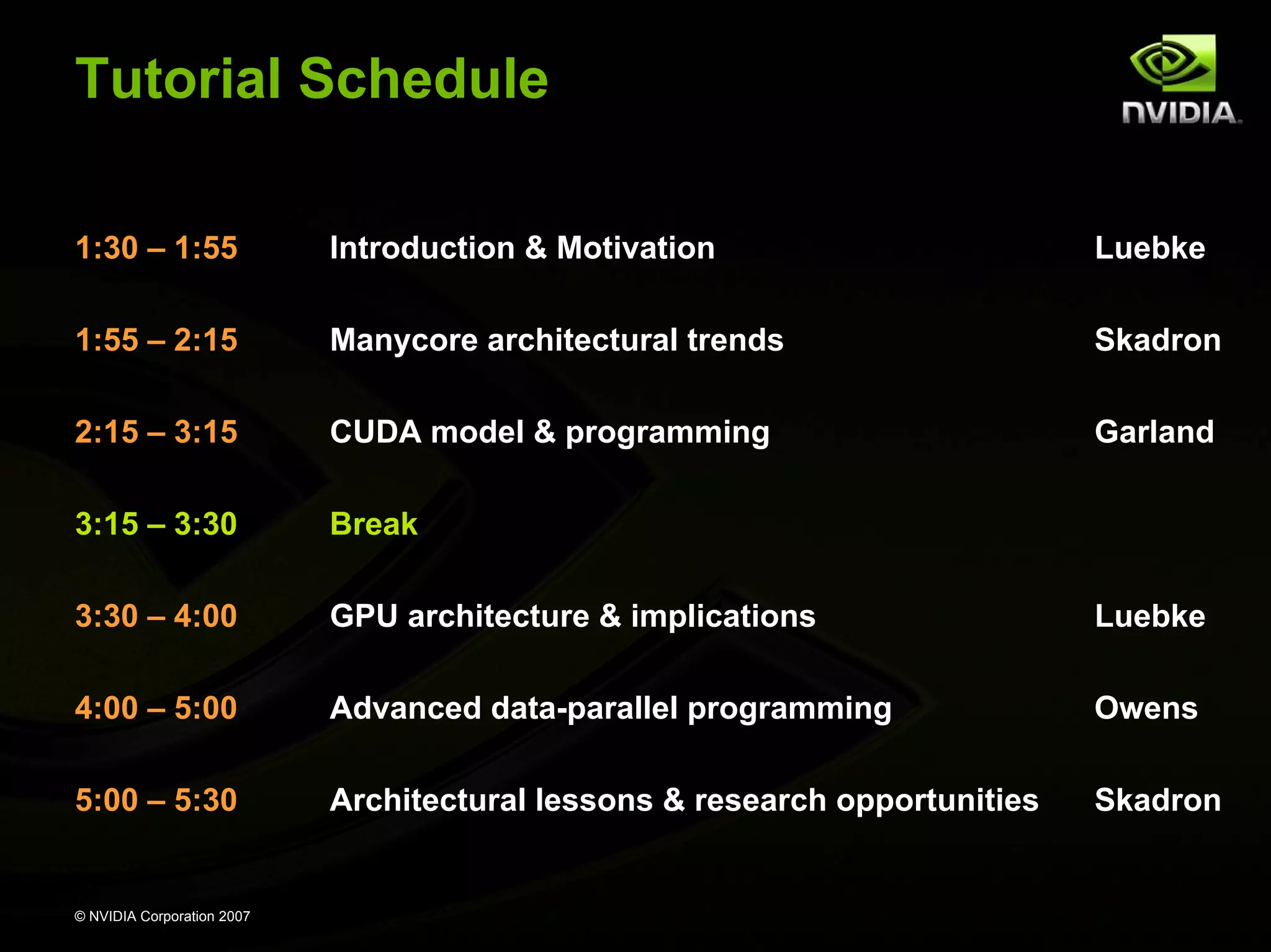
Overview of GPU computing by NVIDIA, tutorial speakers and schedule, focused on democratizing parallel computing.
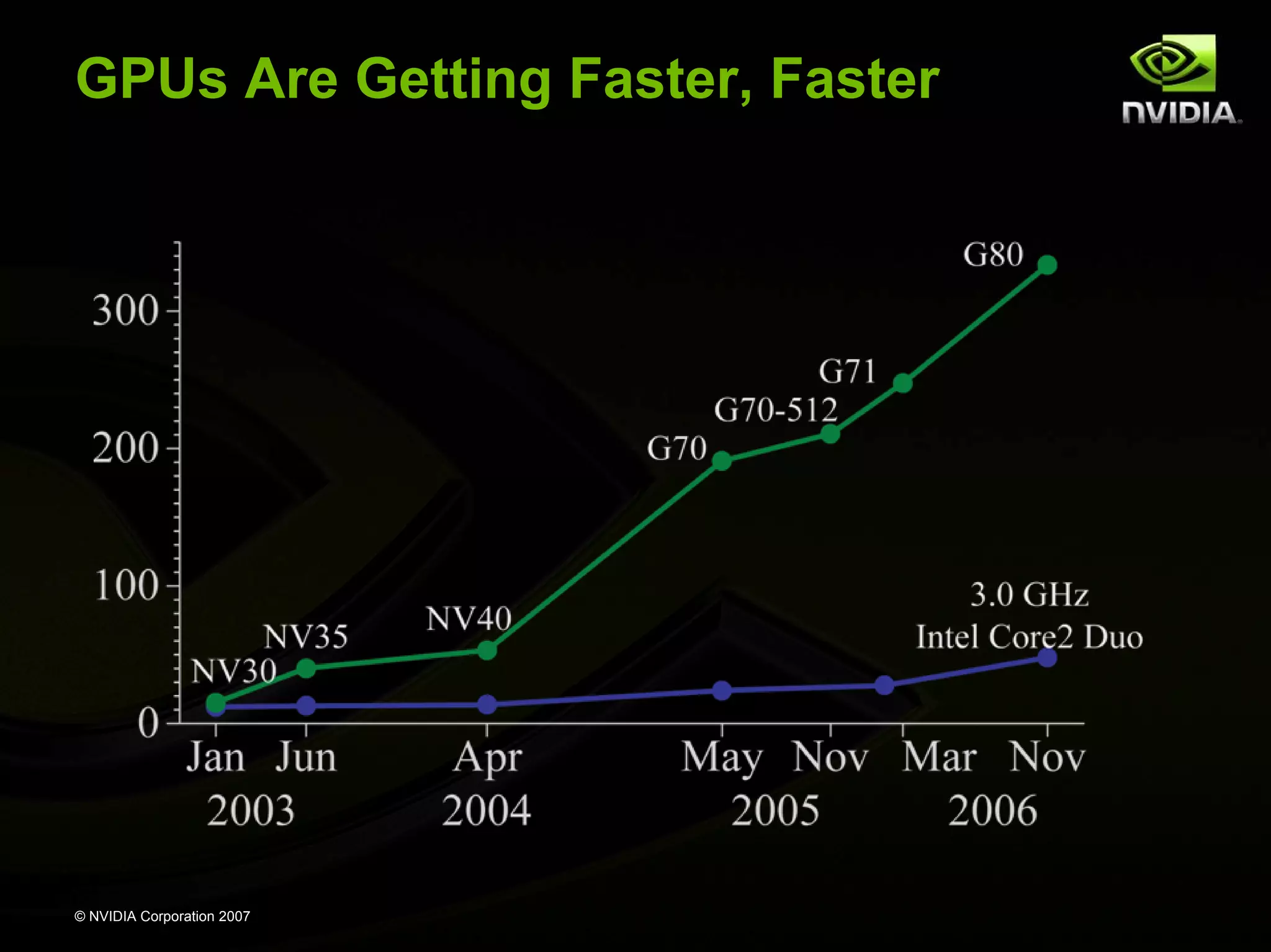
Discusses the golden age of parallel computing, significant architectures, followed by a dark age marked by limited impact and shift to commodity technology.
Explains GPU capabilities as multithreaded manycore chips, highlighting NVIDIA Tesla performance and the advantages of using GPUs in various fields.
CUDA as a parallel programming model that democratizes parallel computing, showcasing sales of CUDA-capable GPUs and affordable developer kits.
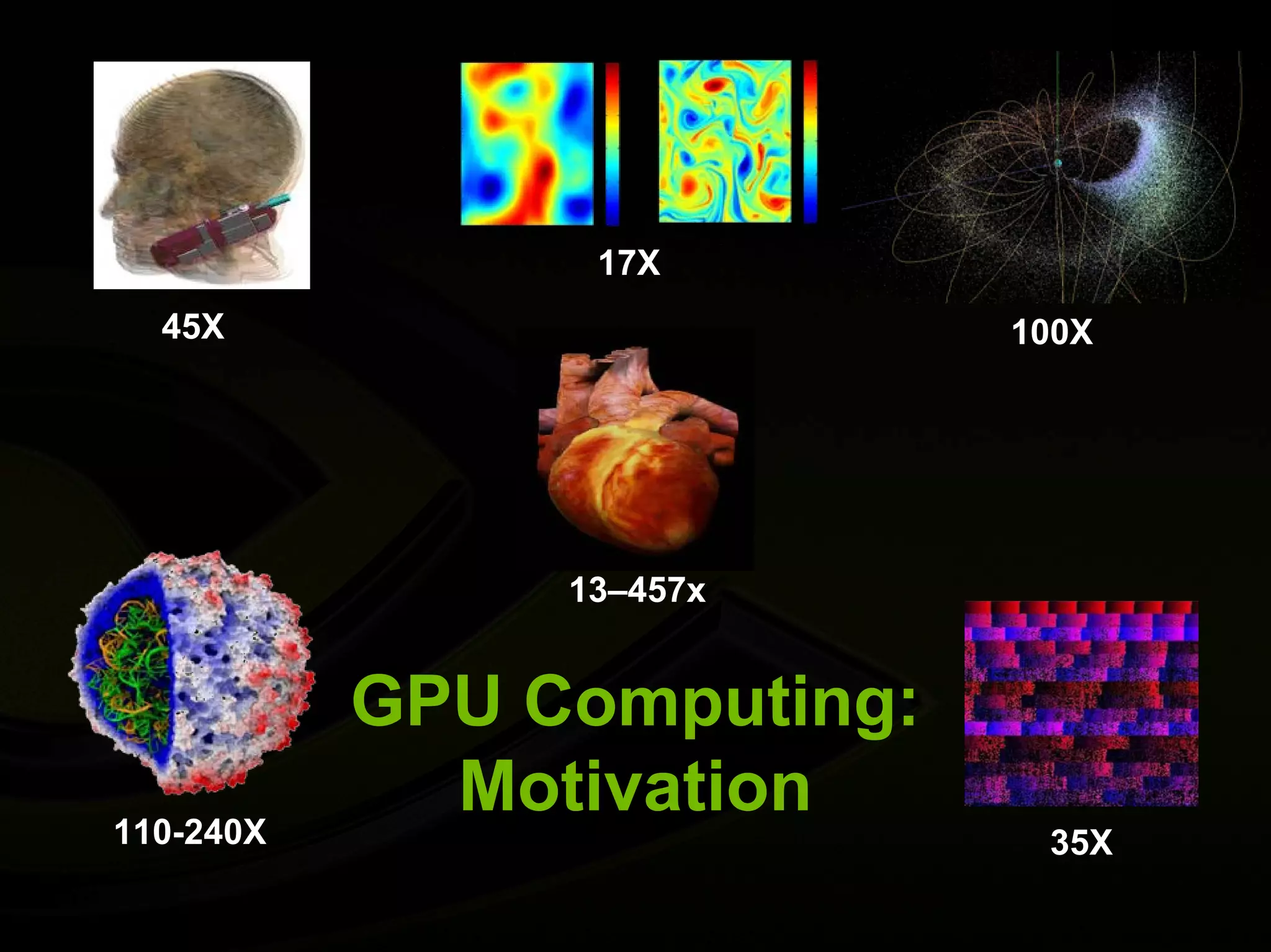
Introduction to GPU computing motivation, showcasing performance metrics and speedup data in various applications.
Presents peak and sustained performance of GPUs, including theoretical benchmarks and actual application performance figures.
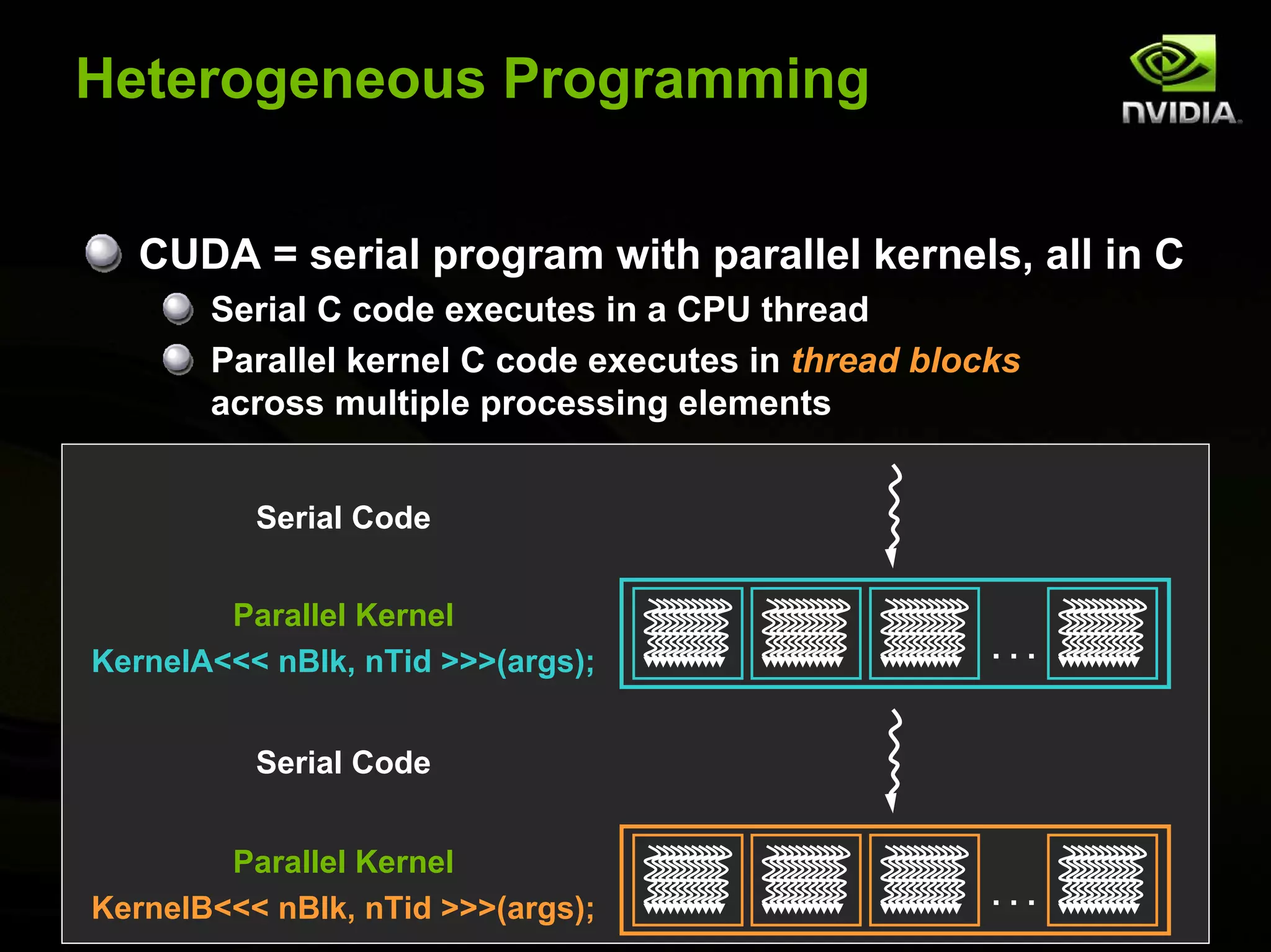
Describes the architecture and functionality of manycore GPUs, focusing on the CUDA programming model and heterogeneous programming strategies.
Details on CUDA programming, including kernel functions, shared memory, and thread identification, aimed at harnessing GPU power for computations.
Introduces NVIDIA's Tesla product line as high-performance computing solutions, detailing specifications of various Tesla models.
Summarizes GPUs as powerful parallel processors with CUDA offering accessible programming models and large research opportunities, followed by a Q&A.