The paper presents a novel algorithm for the compression and encryption of speech signals using hybrid methods including fuzzy c-means, Sudoku patterns, and the Threefish cipher. The approach aims to enhance both the security and efficiency of transferring large speech data by removing less significant frequencies and applying scrambling techniques. Results show that the proposed method offers high effectiveness in preserving signal quality while achieving substantial data reduction.
![International Journal of Electrical and Computer Engineering (IJECE) Vol. 11, No. 6, December 2021, pp. 5049~5059 ISSN: 2088-8708, DOI: 10.11591/ijece.v11i6.pp5049-5059 5049 Journal homepage: http://ijece.iaescore.com Speech signal compression and encryption based on sudoku, fuzzy C-means and threefish cipher Iman Qays Abduljaleel, Amal Hameed Khaleel Department of Computer Science, Basrah University, Iraq Article Info ABSTRACT Article history: Received Oct 19, 2020 Revised May 12, 2021 Accepted May 23, 2021 Compression and encryption of speech signals are essential multimedia technologies. In the field of speech, these technologies are needed to meet the security and confidentiality of information requirements for transferring huge speech signals via a network, and for decreasing storage space for rapid retrieval. In this paper, we propose an algorithm that includes hybrid transformation in order to analyses the speech signal frequencies. The speech signal is then compressed, after removing low and less intense frequencies, to produce a well compressed speech signal and ensure the quality of the speech. The resulting compressed speech is then used as an input in a scrambling algorithm that was proposed on two levels. One of these is an external scramble that works on mixing up the segments of speech that were divided using Fuzzy C-Means and changing their locations. The internal scramble scatters the values of each block internally based on the pattern of a Sudoku puzzle and quadratic map so that the resulting speech is an input to a proposed encryption algorithm using the threefish algorithm. The proposed algorithm proved to be highly efficient in the compression and encryption of the speech signal based on approved statistical measures. Keywords: Encryption Fuzzy C-means Scrambling Speech compression Sudoku puzzle This is an open access article under the CC BY-SA license. Corresponding Author: Amal Hameed Khaleel Department of Computer Science Basrah University Basrah, Iraq Email: amal_albahrany@yahoo.com 1. INTRODUCTION Transferring multimedia files, such as audio, is a common information security problem. Encryption and compression technologies are, therefore, needed to overcome difficulties in handling huge amounts of data that need to be stored and transferred [1]. Speech-based communication has developed in numerous applications such as teleconferencing, the military, e-learning, and other sectors [2]. Speech is a fundamental way in which humans communicate information to each other. The major objective of speech encryption is to provide a high degree of security for the transfer of speech. Encryption can convert the data into unreadable forms so that only the intended receiver can read and alter the message. The major objective of speech compression is to represent signals with a smaller number of bits and remove redundancy between neighbouring samples. The reduction of data should be done in such a way that there is an acceptable loss of quality [3]. There are two main techniques used to compress the data: lossless compression and lossy compression [4]. Compression of speech is achieved by neglecting and discarding small and lesser coefficients and data and then using quantizing and encryption techniques without significant loss of speech intelligibility [3, 5]. Lossless compression reversibly encodes data, while lossy compression removes perceptually less significant information [6].](https://image.slidesharecdn.com/4424003em23may2112may2119oct20y-211116064655/75/Speech-signal-compression-and-encryption-based-on-sudoku-fuzzy-C-means-and-threefish-cipher-1-2048.jpg)
![ ISSN: 2088-8708 Int J Elec & Comp Eng, Vol. 11, No. 6, December 2021 : 5049 - 5059 5050 In the last few years, numerous different performance methods have been used. The most common techniques in signal compression are: Bousselmi et al. [7], present a simulation algorithm of an audio compression scheme based on the fast Hartley transforms that offer a higher compression ratio in combination with a newly modified run-length encoding. Hassan et al. [8] suggest the JPEG scheme algorithm, commonly used in digital image compression and digital voice signal compression. The method contains many steps to prepare the speech signal to make it more comparable to the original JPEG technique. Vig and Chauhan [5], use a hybrid multi-resolution wavelet for speech signals with variable duration for compression. This hybrid wavelet construction uses two transforms (discrete cosine transform-DCT and Walsh). Aloui et al. [9], suggest a speech signal compression algorithm based on the discrete Hartley transformation to ensure a low bit rate and achieve high speaking compression efficiency. Currently, the studies concentrate on the mixing between compression and encryption. For example Al-Azawi and Gaze [10], explain the method for speech signal encryption and compression in a single-step. Compressive sensing theory ensures that compression and encryption occur in a single-step; in addition, the contourlet transformation is applied to ensure the basic principle of compressive sensing and is used as the base encryption. Hameed et al. [11], propose a lightweight system model to process ECG signals efficiently and securely, using buffer blocks and encryption of signal using the AES-CBC algorithm with 256-bit key size encryption. This paper explains a new method for speech signal compression and encryption to ensure the high quality and reliability of the reconstructed signal. Section 2 introduces proposed algorithms. The proposed system is discussed in section 3 while section 4 presents the experimental results and discussion related to the performance measurements used to assess the proposed system. Conclusions are summarized in section 5. 2. PROPOSED METHOD 2.1. Quantization Quantization is an essential phase in data compression, helping to make approximate mapping of the transform coefficient values to limit the length of binary representation of integer values [9, 12]. Uniform quantization is applied in this work to compress the speech signals. The value of the step size is calculated in (1): (1) Where: = The step size, 𝑚𝑚𝑘𝑘= Maximum value, 𝑚𝑚𝑜𝑜= Minimum value, L= The number of quantization levels. 2.2. Discrete cosine transform (DCT) Due to the high correlation within the adjacent coefficient, the DCT can be used for speech compression. This property helps in efficient data reduction. The discrete cosine transform concentrates the content of the information into relatively few coefficients of transformation because it identifies information pieces that can be effectively disposed of without seriously reducing the quality of the signal [13]. The DCT of 1-D sequence X is calculated by [3]: (2) (3) (4) where N= Length X= Discrete cosine transform = Inverse discrete cosine transform (IDCT)](https://image.slidesharecdn.com/4424003em23may2112may2119oct20y-211116064655/75/Speech-signal-compression-and-encryption-based-on-sudoku-fuzzy-C-means-and-threefish-cipher-2-2048.jpg)
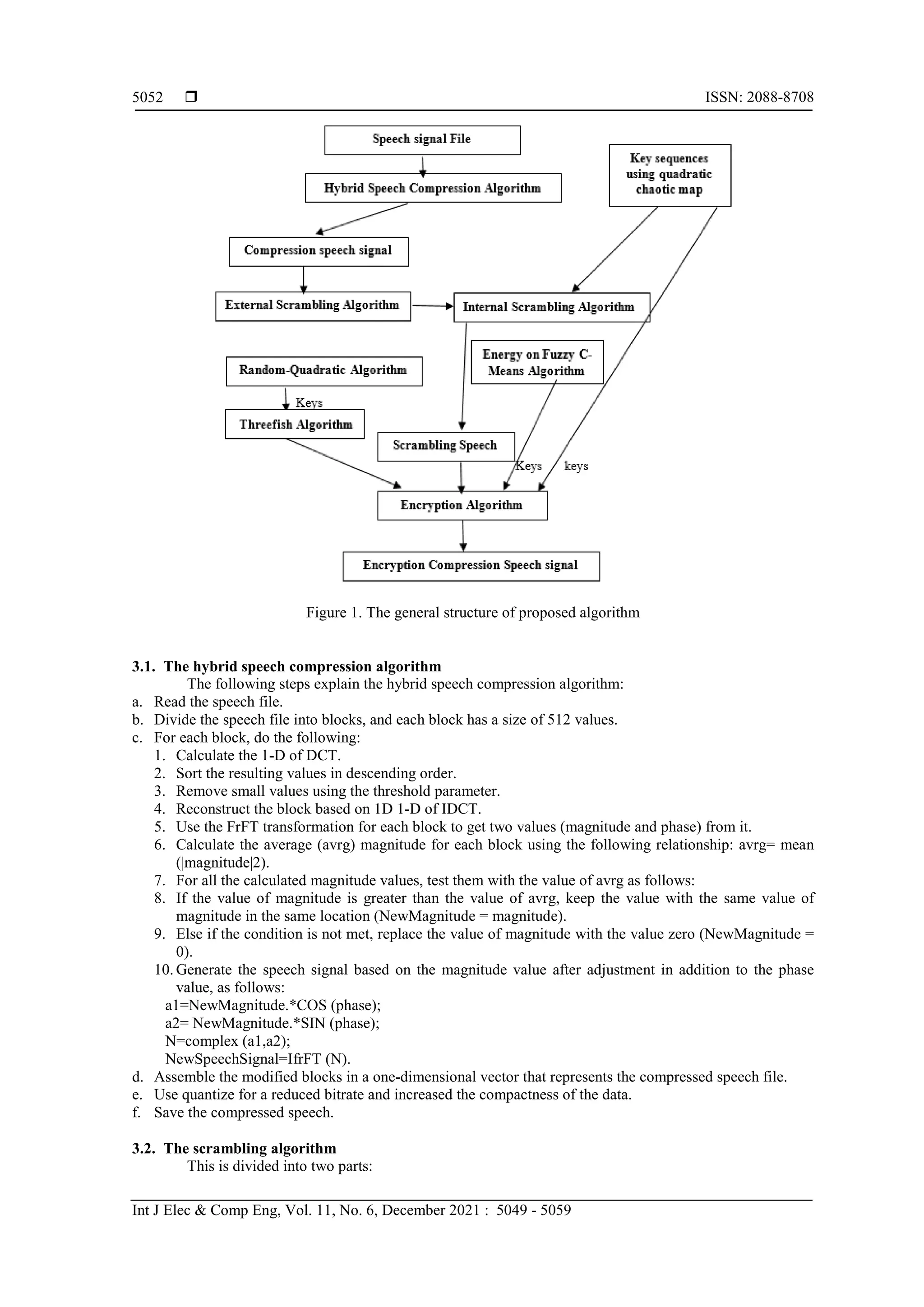
![Int J Elec & Comp Eng ISSN: 2088-8708 Speech signal compression and encryption based on sudoku, fuzzy C-means… (Iman Qays Abduljaleel) 5051 2.3. Fractional fourier transform (FrFT) FrFT is a generalized Fourier transform, and is also known as angular Fourier transform [14]. FrFT is a linear operator with angle (α) and signal (f (t)) according to (5) [15]: (5) (6) (7) where δ(t) = Represents the dirac function, α: represents the angle of rotation (α = α π /2), ƒˊ(t) = The inverse fractional fourier transform. 2.4. Quadratic map The quadratic map is a basic example of a Quadratic Chaotic, one-dimensional, and nonlinear. The quadratic map equation can be defined as [16, 17], (8) where the initial conditions specify that r is the chaotic behaviour parameter and n is the number of iterations. c=1.95 and x0=0.1 [18]. 2.5. Sudoku puzzles Sudoku puzzles are generated by removing some elements from the sudoku matrix but keeping some hints for a unique solution [19]. The central idea of the Sudoku solution is to change the pixel pairs selected in the cover signal using an index matrix [20]. 2.6. Short-term energy (en) The voice and the silence are separated by the thresholds of en(i). The en(i) formulae is as [21]: (9) 2.7. Fuzzy C-means The clustering technique is one of the most important techniques used in data mining. Clustering algorithms are useful in dealing with signal similitude and uncertainty. Fuzzy C-means (FCM) is a fuzzy theory-based algorithm that enables the element to belong to multiple classes with varying memberships. Details of fuzzy C-means algorithm can be found in [22]. 2.8. Threefish algorithm Threefish is a tweakable block cipher (i.e. three parameters are required as the key input, a tweak value, and a message block). Three types of keys inputted as 256, 512, and 1024 bits, are used by the threefish algorithm, and their block size is the same as the key size. Threefish's design philosophy is that a greater number of simple rounds is safer than fewer complex rounds [23]. Threefish comprises three operations: rotation of bits to the left, bitwise exclusive OR (⊕), and modulo 264 addition ( ). Details of the threefish algorithm can be found in [24]. 3. PROPOSED ALGORITHMS In this study, the compressed speech file was encrypted after scrambling it, and thus this work consists of, compression, scrambling, and encryption algorithms, in addition to two secondary algorithms for generating the three keys. The proposed algorithm is shown in Figure 1.](https://image.slidesharecdn.com/4424003em23may2112may2119oct20y-211116064655/75/Speech-signal-compression-and-encryption-based-on-sudoku-fuzzy-C-means-and-threefish-cipher-3-2048.jpg)

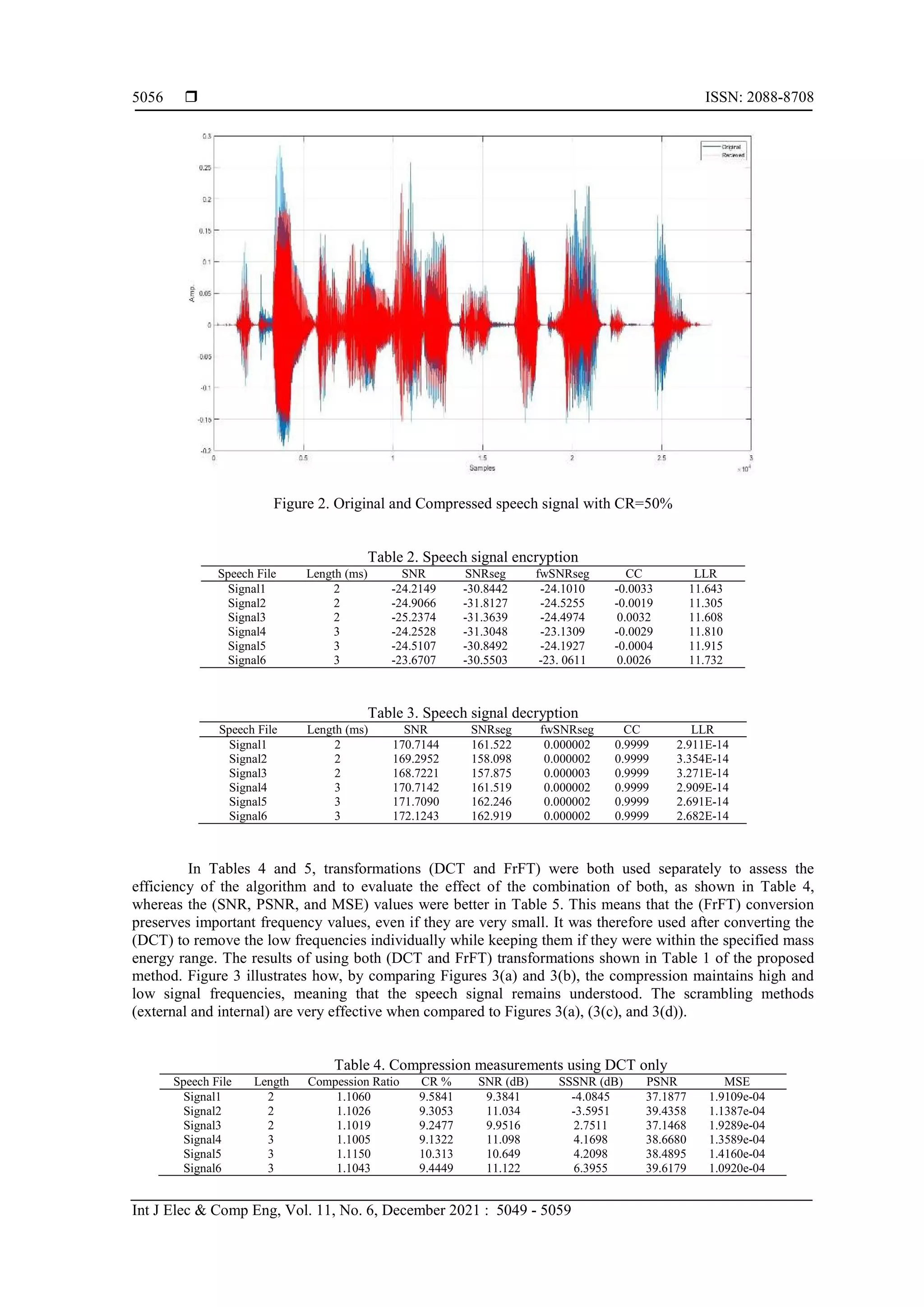
![ ISSN: 2088-8708 Int J Elec & Comp Eng, Vol. 11, No. 6, December 2021 : 5049 - 5059 5054 d. Set the value of a tweak value with the size of 16 characters. e. Set the constant value C240 by 8 characters (i.e. 64 bits). f. Divide the speech signal into several blocks (i.e. 16 values for each block). g. Use the random-quadratic algorithm to generate a series of keys (KeyT) equal to the number of blocks at this stage. h. For each block, test value from the generated keychain as follows: 1. If the key value in the keychain (KeyT) is divisible by 2 (i.e. the key value is even) then encode the block values based on the threefish algorithm and xoredkey1 as the primary key. 2. If the key value in the keychain (KeyT) is not divisible by 2 (i.e. the key value is odd), encode the block values based on the threefish algorithm and key2 as the primary key. i. Repeat step 8 until all of the speech signal blocks are finished. j. Merge the blocks into one audio vector and save it to a wav speech file. 4. RESULTS AND DISCUSSION This work was conducted using the R2018b MATLAB programme. Equipment included a Core i7 PC with Intel Processor, 2.60 GHz CPU, and 6.00 GB RAM. The tested speech file was loaded from the "NOIZEUS" database produced by male and female speakers. Two different "16 KHZ" frequency messages were used from the database, one of which included only vowels (voiced) speech, and the other included voiced and voiceless continuous speech. The statistical measures used to assess the performance of the system in the encryption and decryption processes included (SNR, SNRseg, fwSNRseg, CC, LLR) [25], [26], [27], the statistical measures in compression used included (CR, SNR, SSSNR, PSNR, MSE). The equations of these measures were [2], [9], [10], [28]: a. Signal-to-noise-ratio (SNR) (10) b. Segmental signal-to-noise-ratio (SNRseg) (11) c. frequency-weighed signal-to-noise ratio (fwSNRseg) (12) d. Correlation coefficient (CC):rxy (13) (14) e. Log-likelihood ratio (LLR) (15) f. Segmental spectral signal to noise ratio (SSSNR) (16)](https://image.slidesharecdn.com/4424003em23may2112may2119oct20y-211116064655/75/Speech-signal-compression-and-encryption-based-on-sudoku-fuzzy-C-means-and-threefish-cipher-6-2048.jpg)

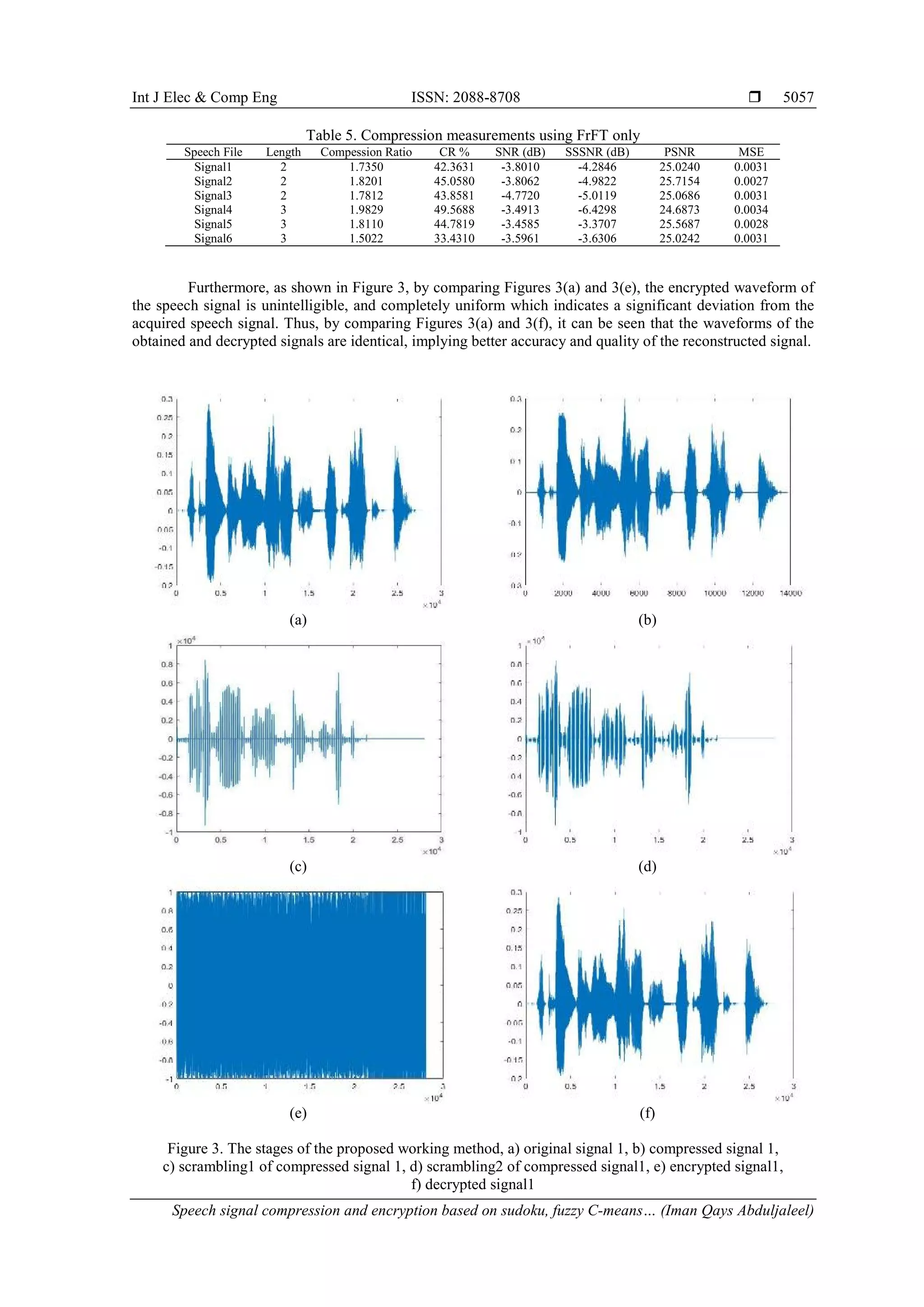
![ ISSN: 2088-8708 Int J Elec & Comp Eng, Vol. 11, No. 6, December 2021 : 5049 - 5059 5058 5. CONCLUSION There is always a demand for compressed audio data with high cybersecurity. By encrypting the compressed speech, we get fast speech data transmission after compressing it because it is smaller in size and simultaneously secure. This study consists of three basic algorithms: hybrid compression, scrambling and encryption algorithms, where scrambling consists of both external and internal scrambling algorithms, in addition to two secondary algorithms to generate the keys, depending on fuzzy C-means and quadratic map techniques. The purpose of this work is to shrink large speech signal files before encrypting them to provide sufficient space during correspondence, in addition to transmission speed, as well as adding a complexity to any attempt to penetrate because there are several stages before the encryption process. This experiment has demonstrated that the proposed method outperforms other current techniques. REFERENCES [1] X. Wang and Y. Su, “An Audio Encryption Algorithm Based on DNA Coding and Chaotic System,” IEEE Access, vol. 8, pp. 9260–9270, 2020, doi: 10.1109/ACCESS.2019.2963329. [2] O. A. Imran, S. F. Yousif, I. S. Hameed, W. N. Al-Din Abed, and A. T. Hammid, “Implementation of El-Gamal algorithm for speech signals encryption and decryption,” Procedia Comput. Sci., vol. 167, no. Iccids 2019, pp. 1028–1037, 2020, doi: 10.1016/j.procs.2020.03.402. [3] S. S. M. V. Patil, A. Gupta, and A. Varma, “Audio and Speech Compression Using DCT and DWT Techniques,” Int. J. Innov. Res. Sci. Eng. Technol., vol. 2, no. 5, pp. 1712–1719, 2013. [4] A. Tsegaye and G. Tariku, “Audio Compression Using DWT and RLE Techniques,” Am. J. Electr. Electron. Eng., vol. 7, no. 1, pp. 14–17, 2019, doi: 10.12691/ajeee-7-1-3. [5] R. Vig and S. S. Chauhan, “Speech Compression using Multi-Resolution Hybrid Wavelet using DCT and Walsh Transforms,” Procedia Comput. Sci., vol. 132, pp. 1404–1411, 2018, doi: 10.1016/j.procs.2018.05.070. [6] B. Kim and Z. Rafii, “Lossy audio compression identification,” Eur. Signal Process. Conf., vol. 2018, 2018, pp. 2459–2463, doi: 10.23919/EUSIPCO.2018.8553611. [7] S. Bousselmi, N. Aloui, and A. Cherif, “DSP Real-Time Implementation of an Audio Compression Algorithm by using the Fast Hartley Transform,” Int. J. Adv. Comput. Sci. Appl., vol. 8, no. 4, 2017, doi: 10.14569/ijacsa.2017.080462. [8] T. A. Hassan, R. H. Al-Hashemy, and R. I. Ajel, “Speech Signal Compression Algorithm Based on the JPEG Technique,” J. Intell. Syst., vol. 29, no. 1, pp. 554–564, 2020, doi: 10.1515/jisys-2018-0127. [9] N. Aloui, S. Bousselmi, and A. Cherif, “New algorithm for speech compression based on discrete hartley transform,” Int. Arab J. Inf. Technol., vol. 16, no. 1, pp. 156–162, 2019. [10] M. K. M. Al-Azawi and A. M. Gaze, “Combined speech compression and encryption using chaotic compressive sensing with large key size,” IET Signal Process., vol. 12, no. 2, pp. 214–218, 2018, doi: 10.1049/iet-spr.2016.0708. [11] M. E. Hameed, M. M. Ibrahim, and N. A. Manap, “Compression and encryption for ECG biomedical signal in healthcare system,” Telkomnika Telecommunication Comput. Electron. Control., vol. 17, no. 6, pp. 2826–2833, 2019, doi: 10.12928/TELKOMNIKA.v17i6.13240. [12] P. K. R. Manohar, M. Pratyusha, R. Satheesh, S. Geetanjali, and N. Rajasekhar, “Audio Compression Using Daubechie Wavelet,” IOSR J. Electron. Commun. Eng. Ver. III, vol. 10, no. 2, pp. 2278–2834, 2015, doi: 10.9790/2834-10234144. [13] Z. T. Drweesh and L. E. George, “Audio Compression Based on Discrete Cosine Transform, Run Length and High Order Shift Encoding,” International Journal of Engineering and Innovative Technology (IJEIT), vol. 4, no. 1, pp. 45–51, 2014. [14] K. Pramila R. and G. Shital S., “A Survey Paper on Different Speech Compression Techniques,” IJARIIE, vol. 2, no. 5, pp. 736–741, 2016. [15] B. T. Krishna, “Fractional Fourier transform: A survey,” ACM Int. Conf. Proceeding Ser., 2012, pp. 751–757, doi: 10.1145/2345396.2345519. [16] C. R. Revanna and C. Keshavamurthy, “A new selective document image encryption using GMM-EM and mixed chaotic system,” Int. J. Appl. Eng. Res., vol. 12, no. 19, pp. 8854–8865, 2017. [17] C. R. Revanna and C. Keshavamurthy, “A novel priority based document image encryption with mixed chaotic systems using machine learning approach,” Facta Univ. - Ser. Electron. Energ., vol. 32, no. 1, pp. 147–177, 2019, doi: 10.2298/fuee1901147r. [18] N. Ramadan, H. E. H. Ahmed, S. E. Elkhamy, and F. E. A. El-samie, “Chaos-Based Image Encryption Using an Improved Quadratic Chaotic Map,” Am. J. Signal Process., vol. 6, no. 1, pp. 1–13, 2016, doi: 10.5923/j.ajsp.20160601.01. [19] Y. Wu, Y. Zhou, J. P. Noonan, K. Panetta, and S. Agaian, “Image encryption using the Sudoku matrix,” Mob. Multimedia/Image Process. Secur. Appl., vol. 7708, Art. No. 77080P, 2010, doi: 10.1117/12.853197. [20] S. Ijeri, S. Pujeri, S. B, and U. B A, “Image Steganography using Sudoku Puzzle for Secured Data Transmission,” Int. J. Comput. Appl., vol. 48, no. 17, pp. 31–35, 2012, doi: 10.5120/7443-0460. [21] Y. Zhang, D. Xiao, Q. Ren, S. Guo, and F. Mo, “An effective speech compression based on syllable division,” Proc. Meet. Acoust., vol. 29, no. 1, Art. no. 055002, 2016, doi: 10.1121/2.0000480.](https://image.slidesharecdn.com/4424003em23may2112may2119oct20y-211116064655/75/Speech-signal-compression-and-encryption-based-on-sudoku-fuzzy-C-means-and-threefish-cipher-10-2048.jpg)
![Int J Elec & Comp Eng ISSN: 2088-8708 Speech signal compression and encryption based on sudoku, fuzzy C-means… (Iman Qays Abduljaleel) 5059 [22] J. Kong, J. Hou, M. Jiang, and J. Sun, “A novel image segmentation method based on improved intuitionistic fuzzy C-Means clustering algorithm,” KSII Trans. Internet Inf. Syst., vol. 13, no. 6, pp. 3121–3143, 2019, doi: 10.3837/tiis.2019.06.020. [23] M. Usman et al., “A Comprehensive Comparison of Symmetric Cryptographic Algorithms by Using Multiple Types of Parameters,” International Journal Of Computer Science And Network Security, vol. 18, no. 12, pp. 131–137, 2018. [24] P. G. Ayathri, K. U. N. A. S. Ateesh, and C. H. N. Avya, “High-Throughput Hardware Implementation of Three Fish Block Cipher Encryption and Decryption on FPGA,” International Journal of VLSI System Design And Communication Systems, vol. 03, no. 08, pp. 1325–1329, 2015. [25] S. F. Yousif, “Speech Encryption Based on Zaslavsky Map,” J. Eng. Appl. Sci., vol. 14, no. 17, pp. 6392–6399, 2019, doi: 10.36478/jeasci.2019.6392.6399. [26] E. Hato and D. Shihab, “Lorenz and Rossler Chaotic System for Speech Signal Encryption,” Int. J. Comput. Appl., vol. 128, no. 11, pp. 25–33, 2015, doi: 10.5120/ijca2015906670. [27] A. H. Khaleel and I. Q. Abduljaleel, “A novel technique for speech encryption based on k-means clustering and quantum chaotic map,” Bulletin of Electrical Engineering and Informatics (BEEI), vol. 10, no. 1, pp. 160–170, 2021, doi: 10.11591/eei.v10i1.2405. [28] A. H. Khaleel and I. Q. Abduljaleel, “Secure image hiding in speech signal by steganography-mining and encryption,” Indonesian Journal of Electrical Engineering and Computer Science (IJEECS), vol. 21, no. 3, pp. 1692–1703, 2021, doi: 10.11591/ijeecs.v21.i3.pp1692-1703.](https://image.slidesharecdn.com/4424003em23may2112may2119oct20y-211116064655/75/Speech-signal-compression-and-encryption-based-on-sudoku-fuzzy-C-means-and-threefish-cipher-11-2048.jpg)