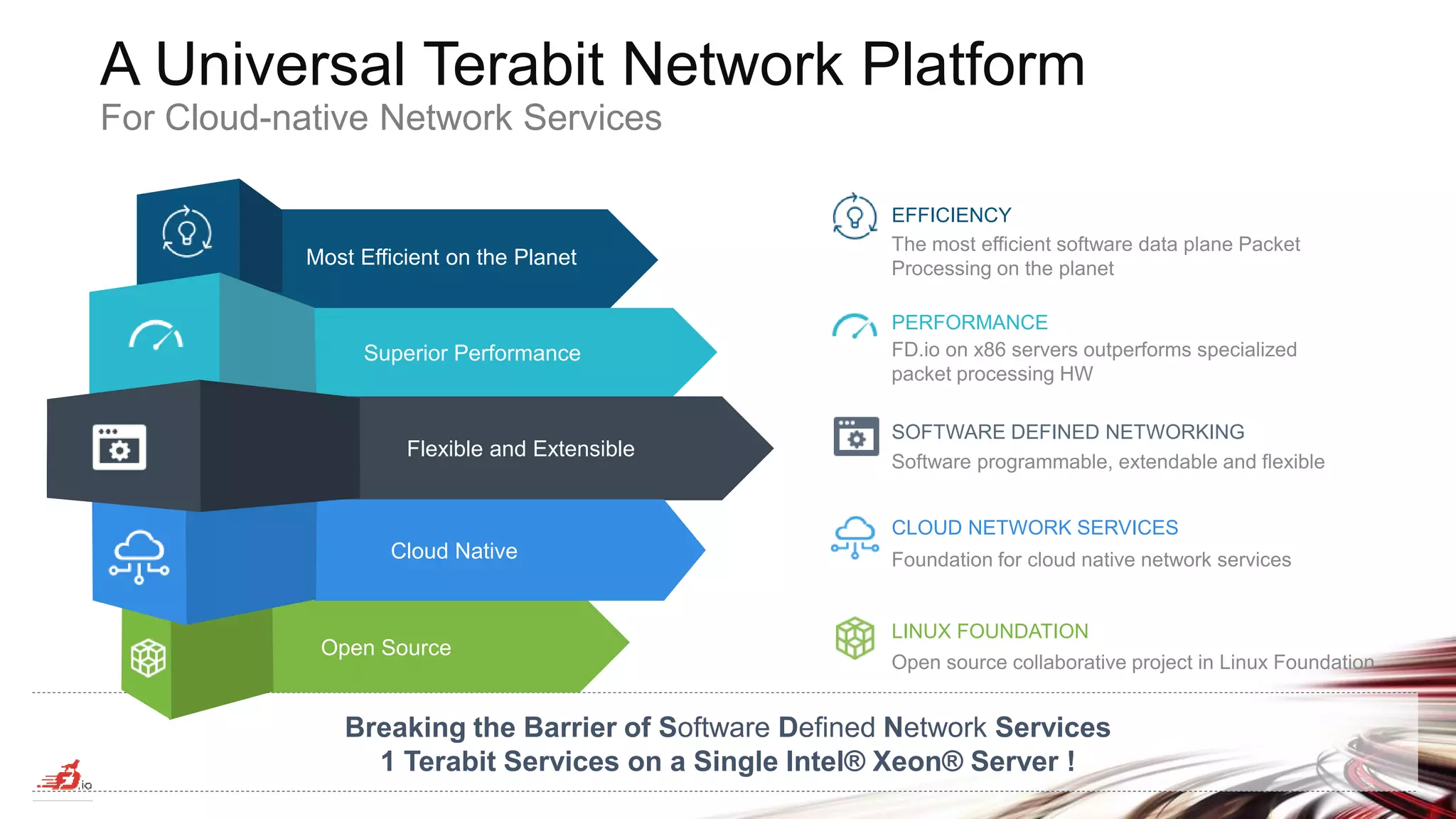
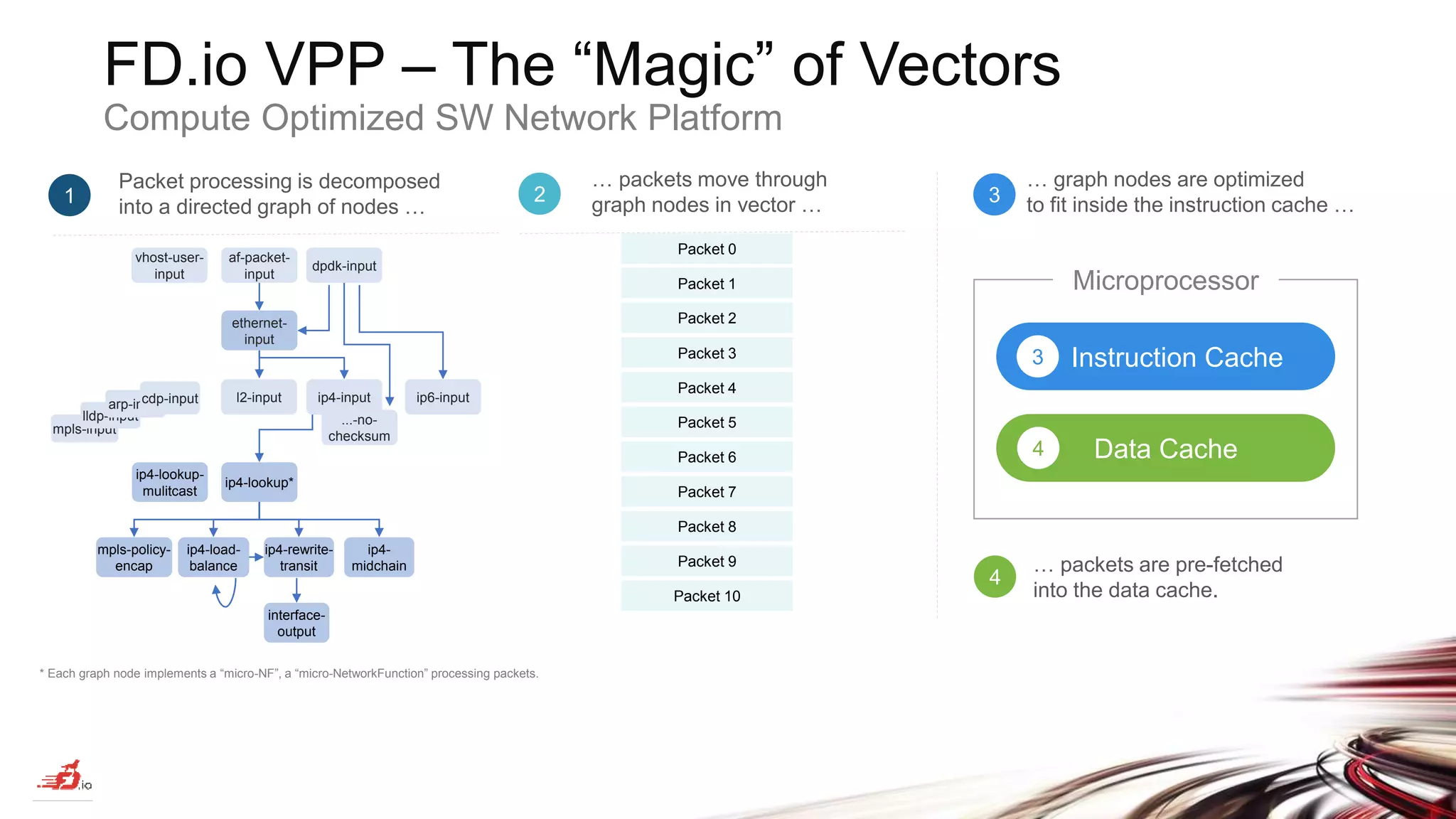
The document discusses advancements in software-defined networking (SDN) through the FD.io project, which utilizes the Vector Packet Processing (VPP) framework to achieve terabit-level data processing on Intel Xeon servers. It describes ongoing work in continuous system integration and testing (CSIT) for performance metrics and benchmarking, highlighting the efficiency and flexibility of VPP as an open-source solution for cloud-native network services. The document emphasizes the need for industry collaboration to maintain best-in-class performance and facilitate the integration of SDN into cloud environments.





![FD.io Benefits from Intel® Xeon® Processor Developments Increased Processor I/O Improves Packet Forwarding Rates YESTERDAY Intel® Xeon® E5-2699v4 22 Cores, 2.2 GHz, 55MB Cache Network I/O: 160 Gbps Core ALU: 4-wide parallel µops Memory: 4-channels 2400 MHz Max power: 145W (TDP) 1 2 3 4 Socket 0 Broadwell Server CPU Socket 1 Broadwell Server CPU 2 DDR4 QPI QPI 4 2 DDR4 DDR4 PCIe PCIe PCIe x8 50GE x16 100GE x16 100GE 3 1 4 PCIe PCIe x8 50GE x16 100GE Ethernet 1 3 DDR4 DDR4 DDR4 DDR4 DDR4 SATA B I O S PCH Intel® Xeon® Platinum 8168 24 Cores, 2.7 GHz, 33MB Cache TODAY Network I/O: 280 Gbps Core ALU: 5-wide parallel µops Memory: 6-channels 2666 MHz Max power: 205W (TDP) 1 2 3 4 Socket 0 Skylake Server CPU Socket 1 Skylake Server CPU UPI UPI DDR4 DDR4 DDR4 PCIe PCIe PCIe PCIe PCIe PCIe x8 50GE x16 100GE x8 50GE x16 100GE x16 100GE SATA B I O S 2 4 2 1 3 1 4 3 x8 50GE DDR4 PCIe x8 40GE Lewisburg PCH DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 0 200 400 600 800 1000 1200 160 280 320 560 640 Server [1 Socket] Server [2 Sockets] Server 2x [2 Sockets] +75% +75% PCle Packet Forwarding Rate [Gbps] Intel® Xeon® v3, v4 Processors Intel® Xeon® Platinum 8180 Processors 1,120* Gbps +75% * On compute platforms with all PCIe lanes from the Processors routed to PCIe slots. Breaking the Barrier of Software Defined Network Services 1 Terabit Services on a Single Intel® Xeon® Server ! FD.io Takes Full Advantage of Faster Intel® Xeon® Scalable Processors No Code Change Required https://goo.gl/UtbaHy](https://image.slidesharecdn.com/fdiocsitatootbnetdev16apr2018-180425125325/75/Software-Network-Data-Plane-Satisfying-the-need-for-speed-FD-io-VPP-and-CSIT-projects-8-2048.jpg)
![2CPU Network I/O 490 Gbps Crypto I/O 100 Gbps 2CPU Network I/O 490 Gbps Crypto I/O 100 Gbps Socket 0 Skylake Server CPU Socket 1 Skylake Server CPU UPI UPI DDR4 DDR4 DDR4 PCIe PCIe PCIe PCIe PCIe PCIe x8 50GE x16 100GE x8 50GE x16 100GE x16 100GE SATA B I O S 2 4 2 1 3 1 4 3 x8 50GE DDR4 PCIe x8 40GE Lewisburg PCH DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 FD.io VPP – The “Magic” Behind the Equation FD.io Takes Full Advantage of Faster Intel® Xeon® Scalable Processors No Code Change Required FD.io Data Plane Efficiency Metrics: { + } higher is better { - } lower is better YESTERDAY TODAY Intel® Xeon® E5-2699v4 Intel® Xeon® Platinum 8168 Improvement { + } 4 Socket forwarding rate [Gbps] 560 Gbps 948 Gbps* +69 % { - } Cycles / Packet 180 158 -12 % { + } Instructions / Cycle (HW max.) 2.8 ( 4 ) 3.28 ( 5 ) +17 % { - } Instructions / Packet 499 497 ~0 % Socket 0 Skylake Server CPU Socket 1 Skylake Server CPU UPI UPI DDR4 DDR4 DDR4 PCIe PCIe PCIe PCIe PCIe PCIe x8 50GE x16 100GE x8 50GE x16 100GE x16 100GE SATA B I O S 2 4 2 1 3 1 4 3 x8 50GE DDR4 PCIe x8 40GE Lewisburg PCH DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 DDR4 Per processor: 24 cores 48 threads 2.7GHz On-board LBG-NS 100G QAT Crypto Machine with Intel® Xeon® Platinum 8168 * Measured 4 Socket forwarding rate is limited by PCIe I/O slot layout on tested compute machines; nominal forwarding rate for tested FD.io VPP configuration is 280 Gbps per Platinum Processor. Not all cores are used. 9 Breaking the Barrier of Software Defined Network Services 1 Terabit Services on a Single Intel® Xeon® Server ! https://goo.gl/UtbaHy](https://image.slidesharecdn.com/fdiocsitatootbnetdev16apr2018-180425125325/75/Software-Network-Data-Plane-Satisfying-the-need-for-speed-FD-io-VPP-and-CSIT-projects-9-2048.jpg)
![tℎ𝑟𝑜𝑢𝑔ℎ𝑝𝑢𝑡 [𝑏𝑝𝑠] = tℎ𝑟𝑜𝑢𝑔ℎ𝑝𝑢𝑡 𝑝𝑝𝑠 ∗ 𝑝𝑎𝑐𝑘𝑒𝑡_𝑠𝑖𝑧𝑒[𝑝𝑝𝑠] DP Benchmarking Metrics – External and Internal Compute CPP from PPS or vice versa.. 𝑝𝑟𝑜𝑔𝑟𝑎𝑚_𝑢𝑛𝑖𝑡_𝑒𝑥𝑒𝑐𝑢𝑡𝑖𝑜𝑛_𝑡𝑖𝑚𝑒[𝑠𝑒𝑐] = #𝑖𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛𝑠 𝑝𝑟𝑜𝑔𝑟𝑎𝑚_𝑢𝑛𝑖𝑡 ∗ #𝑐𝑦𝑐𝑙𝑒𝑠 𝑖𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛 ∗ 𝑐𝑦𝑐𝑙𝑒_𝑡𝑖𝑚𝑒 𝑝𝑎𝑐𝑘𝑒𝑡_𝑝𝑟𝑜𝑐𝑒𝑠𝑠𝑖𝑛𝑔_𝑡𝑖𝑚𝑒[𝑠𝑒𝑐] = #𝑖𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛𝑠 𝑝𝑎𝑐𝑘𝑒𝑡 ∗ #𝑐𝑦𝑐𝑙𝑒𝑠 𝑖𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛 ∗ 𝑐𝑦𝑐𝑙𝑒_𝑡𝑖𝑚𝑒 #cycles_per_packet = #𝑖𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛𝑠 𝑝𝑎𝑐𝑘𝑒𝑡 ∗ #𝑐𝑦𝑐𝑙𝑒𝑠 𝑖𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛 tℎ𝑟𝑜𝑢𝑔ℎ𝑝𝑢𝑡[𝑝𝑝𝑠] = 1 ]𝑝𝑎𝑐𝑘𝑒𝑡_𝑝𝑟𝑜𝑐𝑒𝑠𝑠𝑖𝑛𝑔_𝑡𝑖𝑚𝑒[𝑠𝑒𝑐 = ]𝐶𝑃𝑈_𝑓𝑟𝑒𝑞[𝐻𝑧 #𝑐𝑦𝑐𝑙𝑒𝑠_𝑝𝑒𝑟_𝑝𝑎𝑐𝑘𝑒𝑡 Treat software network Data Plane as one would any program, .. with the instructions per packet being the program unit, .. and arrive to the main data plane benchmarking metrics. CPP PPS BPS CPI or 1/IPCIPP External Metrics Internal Metrics](https://image.slidesharecdn.com/fdiocsitatootbnetdev16apr2018-180425125325/75/Software-Network-Data-Plane-Satisfying-the-need-for-speed-FD-io-VPP-and-CSIT-projects-10-2048.jpg)











![#cycles/packet = cpu_freq[MHz] / throughput[Mpps] Future: Planned Summary Data Views Results and Analysis – #cycles/packet (CPP) and Throughput (Mpps) See Kubecon Dec-2017, Benchmarking and Analysis.., https://wiki.fd.io/view/File:Benchm arking-sw-data-planes-Dec5_2017.pdf](https://image.slidesharecdn.com/fdiocsitatootbnetdev16apr2018-180425125325/75/Software-Network-Data-Plane-Satisfying-the-need-for-speed-FD-io-VPP-and-CSIT-projects-22-2048.jpg)



![References FD.io VPP, CSIT-CPL and related projects • VPP: https://wiki.fd.io/view/VPP • CSIT-CPL: https://wiki.fd.io/view/CSIT • pma_tools - https://wiki.fd.io/view/Pma_tools Benchmarking Methodology • Kubecon Dec-2017, Benchmarking and Analysis.., https://wiki.fd.io/view/File:Benchmarking-sw-data-planes-Dec5_2017.pdf • “Benchmarking and Analysis of Software Network Data Planes” by M. Konstantynowicz, P. Lu, S.M. Shah, https://fd.io/resources/performance_analysis_sw_data_planes.pdf Benchmarks • EEMBC CoreMark® - http://www.eembc.org/index.php • DPDK testpmd - http://dpdk.org/doc/guides/testpmd_app_ug/index.html • FDio VPP – Fast Data IO packet processing platform, docs: https://wiki.fd.io/view/VPP, code: https://git.fd.io/vpp/ Performance Analysis Tools • “Intel Optimization Manual” – Intel® 64 and IA-32 architectures optimization reference manual • Linux PMU-tools, https://github.com/andikleen/pmu-tools TMAM • Intel Developer Zone, Tuning Applications Using a Top-down Microarchitecture Analysis Method, https://software.intel.com/en-us/top-down-microarchitecture-analysis-method-win • Technion presentation on TMAM , Software Optimizations Become Simple with Top-Down Analysis Methodology (TMAM) on Intel® Microarchitecture Code Name Skylake, Ahmad Yasin. Intel Developer Forum, IDF 2015. [Recording] • A Top-Down Method for Performance Analysis and Counters Architecture, Ahmad Yasin. In IEEE International Symposium on Performance Analysis of Systems and Software, ISPASS 2014, https://sites.google.com/site/analysismethods/yasin-pubs](https://image.slidesharecdn.com/fdiocsitatootbnetdev16apr2018-180425125325/75/Software-Network-Data-Plane-Satisfying-the-need-for-speed-FD-io-VPP-and-CSIT-projects-26-2048.jpg)

