Download as PDF, PPTX


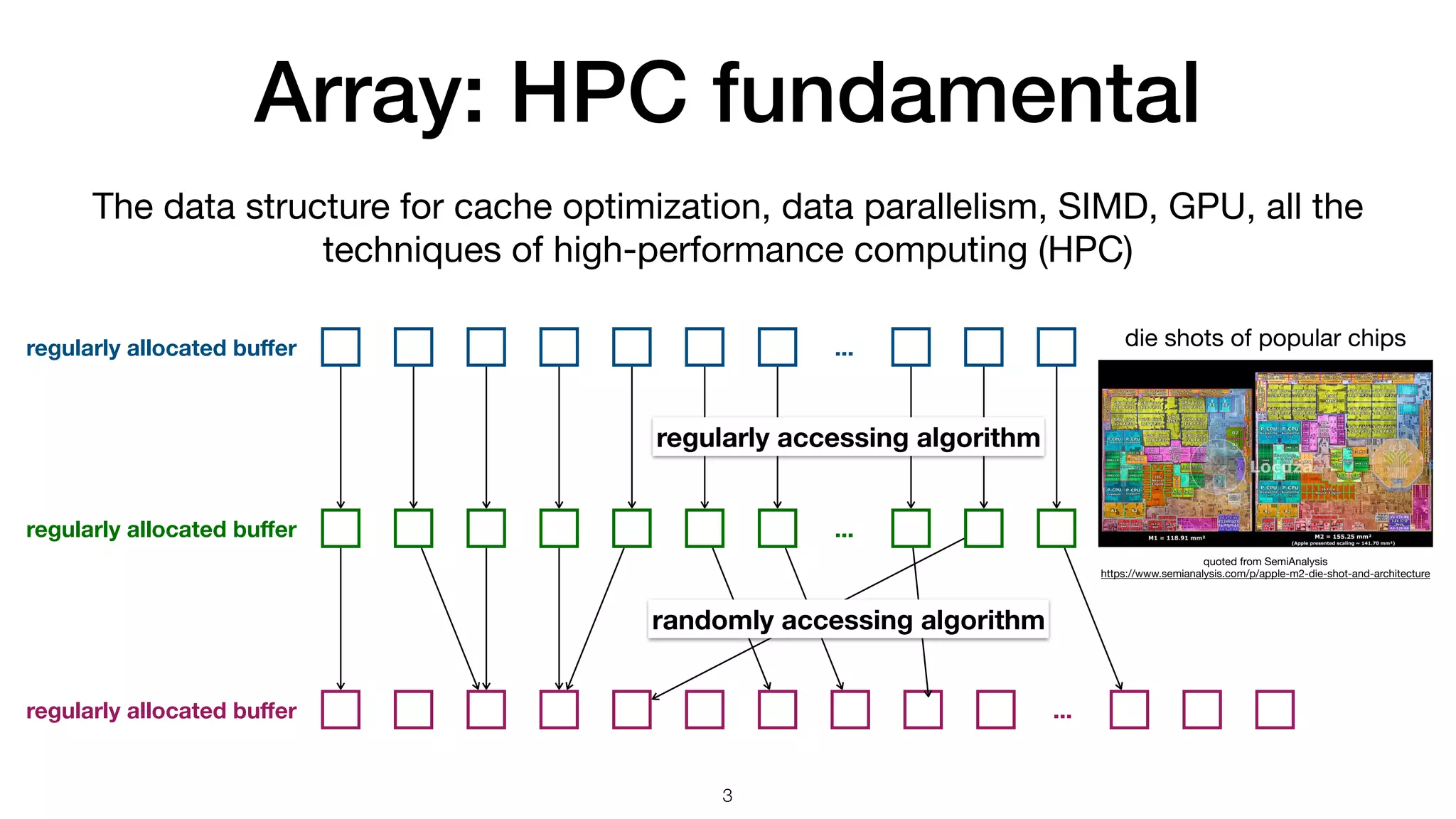
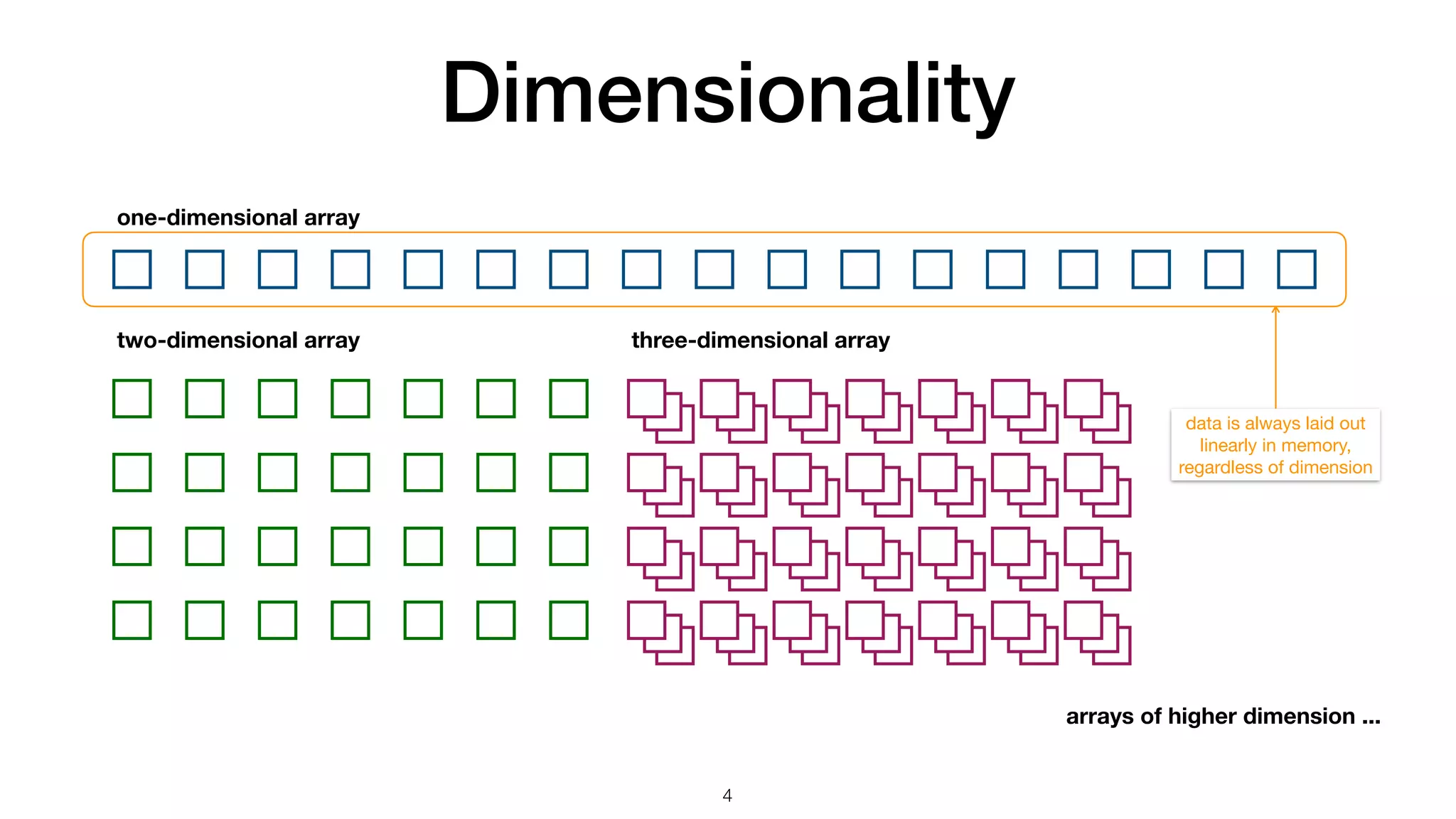

![Make your own array • Make SimpleArray • Vehicle to carry ad hoc optimization in addition to general array operations buffer management data access void calc_distance( size_t const n , double const * x , double const * y , double * r) { for (size_t i = 0 ; i < n ; ++i) { r[i] = std::sqrt(x[i]*x[i] + y[i]*y[i]); } } vmovupd ymm0, ymmword [rsi + r9*8] vmulpd ymm0, ymm0, ymm0 vmovupd ymm1, ymmword [rdx + r9*8] vmulpd ymm1, ymm1, ymm1 vaddpd ymm0, ymm0, ymm1 vsqrtpd ymm0, ymm0 movupd xmm0, xmmword [rsi + r8*8] mulpd xmm0, xmm0 movupd xmm1, xmmword [rdx + r8*8] mulpd xmm1, xmm1 addpd xmm1, xmm0 sqrtpd xmm0, xmm1 AVX: 256-bit-wide vectorization SSE: 128-bit-wide vectorization C++ code 6 Key components:](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-6-2048.jpg)
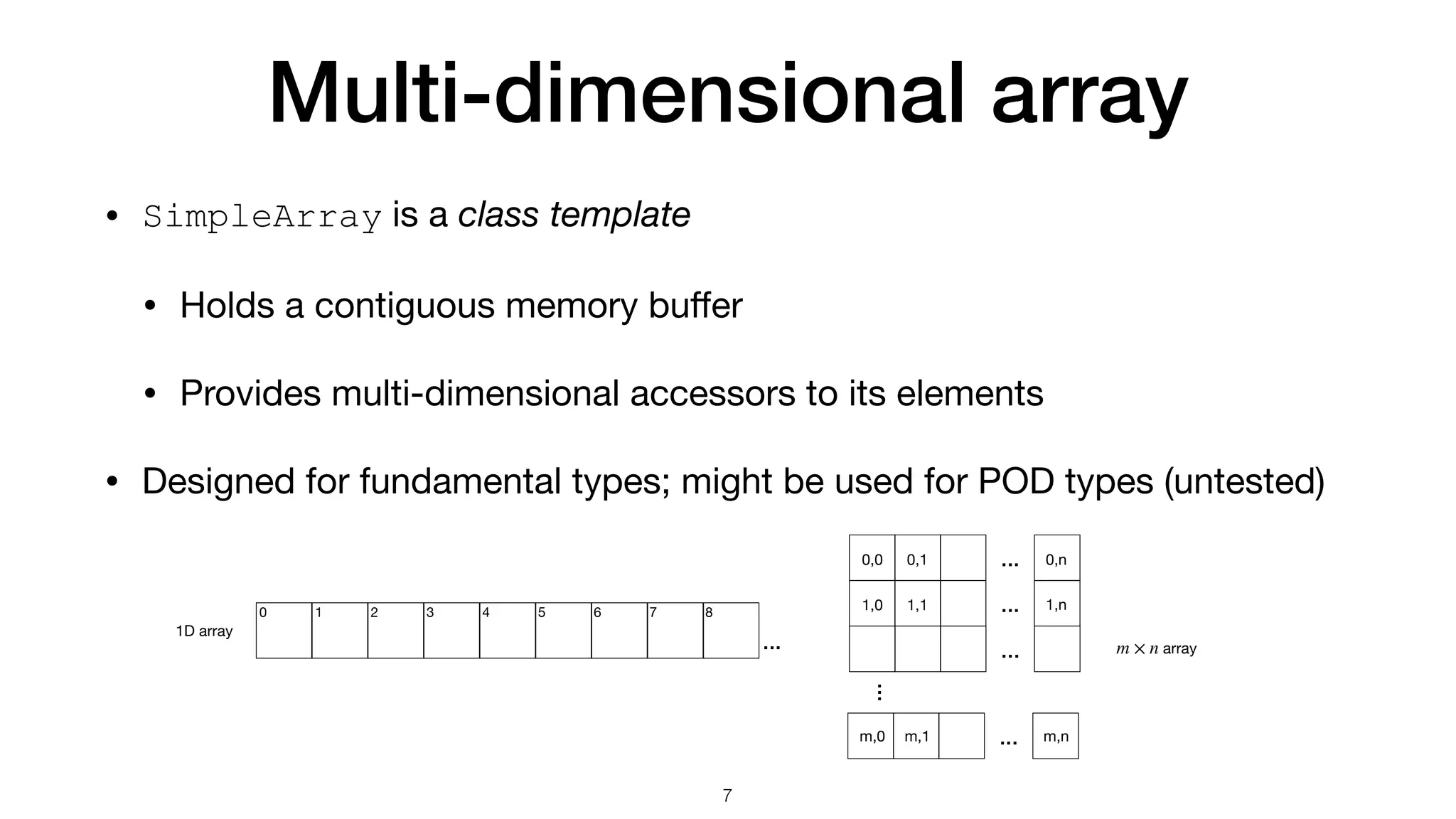
![SimpleArray is not C++ std::vector SimpleArray std::vector SimpleArray is fi xed size • Only allocate memory on construction std::vector is variable size • Bu ff er may be invalidated • Implicit memory allocation (reallocation) Multi-dimensional access: operator() One-dimensional access: operator[] 8](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-8-2048.jpg)


![ConcreteBuffer class ConcreteBuffer : public std::enable_shared_from_this<ConcreteBuffer> { private: // Protect the constructors struct ctor_passkey {}; public: static std::shared_ptr<ConcreteBuffer> construct(size_t nbytes) { return std::make_shared<ConcreteBuffer>(nbytes, ctor_passkey()); } ... }; // Turn off move ConcreteBuffer(ConcreteBuffer &&) = delete; ConcreteBuffer & operator=(ConcreteBuffer &&) = delete; // Use a deleter to customize memory management with unique_ptr using data_deleter_type = detail::ConcreteBufferDataDeleter; using unique_ptr_type = std::unique_ptr<int8_t, data_deleter_type>; size_t m_nbytes; // Remember the amount of bytes unique_ptr_type m_data; // Point to the allocated momery ConcreteBuffer(size_t nbytes, const ctor_passkey &) : m_nbytes(nbytes) , m_data(allocate(nbytes)) {} // Allocate memory static unique_ptr_type allocate(size_t nbytes) { unique_ptr_type ret(nullptr, data_deleter_type()); if (0 != nbytes) { ret = unique_ptr_type(new int8_t[nbytes], data_deleter_type()); } return ret; } 1. Exclusively manage it using std::shared_ptr 1.1. Turn o ff move to prevent the pointer from going away 3. Use a deleter to customize deallocation from outside 2. Allocate memory and keep it in a std::unique_ptr 11](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-11-2048.jpg)
![Design a custom management interface using data_deleter_type = detail::ConcreteBufferDataDeleter; using unique_ptr_type = std::unique_ptr<int8_t, data_deleter_type>; struct ConcreteBufferDataDeleter { using remover_type = ConcreteBufferRemover; explicit ConcreteBufferDataDeleter( std::unique_ptr<remover_type> && remover_in) : remover(std::move(remover_in)) {} void operator()(int8_t * p) const { if (!remover) { // Array deletion if no remover is available. delete[] p; } else { (*remover)(p); } } std::unique_ptr<remover_type> remover{nullptr}; }; struct ConcreteBufferRemover { virtual ~ConcreteBufferRemover() = default; virtual void operator()(int8_t * p) const { delete[] p; } }; struct ConcreteBufferNoRemove : public ConcreteBufferRemover { void operator()(int8_t *) const override {} }; unique_ptr deleter is a proxy to ConcreteBuffer remover Remover is a polymorphic functor type Allow change to work with a foreign sub- system for memory management 12](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-12-2048.jpg)

![Shape and stride explicit SimpleArray(size_t length) : m_buffer(buffer_type::construct(length * ITEMSIZE)) , m_shape{length} , m_stride{1} , m_body(m_buffer->data<T>()) {} explicit SimpleArray(shape_type const & shape) : m_shape(shape) , m_stride(calc_stride(m_shape)) { if (!m_shape.empty()) { m_buffer = buffer_type::construct( m_shape[0] * m_stride[0] * ITEMSIZE); m_body = m_buffer->data<T>(); } } static shape_type calc_stride(shape_type const & shape) { shape_type stride(shape.size()); if (!shape.empty()) { stride[shape.size() - 1] = 1; for (size_t it = shape.size() - 1; it > 0; --it) { stride[it - 1] = stride[it] * shape[it]; } } return stride; } One-dimensional shape Multi-dimensional shape Stride is the number of elements to be skipped when the index is changed by 1 in the corresponding dimension: ... ... ... ... ... array m × n 0,0 0,1 1,0 1,1 m,0 m,1 0,n 1,n m,n 14](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-14-2048.jpg)
![Multi-dimensional accessor template <typename T> class SimpleArray { ... template <typename... Args> value_type const & operator()(Args... args) const { return *vptr(args...); } template <typename... Args> value_type & operator()(Args... args) { return *vptr(args...); } template <typename... Args> value_type const * vptr(Args... args) const { return m_body + buffer_offset(m_stride, args...); } template <typename... Args> value_type * vptr(Args... args) { return m_body + buffer_offset(m_stride, args...); } ... }; namespace detail { // Use recursion in templates. template <size_t D, typename S> size_t buffer_offset_impl(S const &) { return 0; } template <size_t D, typename S, typename Arg, typename... Args> size_t buffer_offset_impl (S const & strides, Arg arg, Args... args) { return arg * strides[D] + buffer_offset_impl<D + 1>(strides, args...); } } /* end namespace detail */ template <typename S, typename... Args> size_t buffer_offset(S const & strides, Args... args) { return detail::buffer_offset_impl<0>(strides, args...); } Element and pointer accessor by using variadic template Recursive implementation (compile-time) to save conditional branching 15](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-15-2048.jpg)
![Ghost (negative) index • Ghost: elements indexed by negative integer • Similar to the negative index for the POD array • No overhead for normal arrays that start with 0 index // C-style POD array. int32_t data[100]; // Make a pointer to the head address of the array. int32_t * pdata = data; // Make another pointer to the 50-th element from the head of the array. int32_t * odata = pdata + 50; odata[-10] 0 1 2 3 4 5 6 7 8 9 40 41 42 43 44 45 46 47 48 49 data[40] data ... ... 50 *(data+40) *(odata-10) pdata odata 16](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-16-2048.jpg)
![Get ghost information on construction template <typename T> class SimpleArray { private: // Number of ghost elements size_t m_nghost = 0; // Starting address of non-ghost value_type * m_body = nullptr; }; static T * calc_body(T * data, shape_type const & stride, size_t nghost) { if (nullptr == data || stride.empty() || 0 == nghost) { // Do nothing. } else { shape_type shape(stride.size(), 0); shape[0] = nghost; data += buffer_offset(stride, shape); } return data; } SimpleArray(SimpleArray const & other) : m_buffer(other.m_buffer->clone()) , m_shape(other.m_shape) , m_stride(other.m_stride) , m_nghost(other.m_nghost) , m_body(calc_body(m_buffer->data<T>(), m_stride, other.m_nghost)) {} SimpleArray(SimpleArray && other) noexcept : m_buffer(std::move(other.m_buffer)) , m_shape(std::move(other.m_shape)) , m_stride(std::move(other.m_stride)) , m_nghost(other.m_nghost) , m_body(other.m_body) {} Keep ghost number and body address Assign ghost and body information in constructors Calculate body address 17 No additional overhead during element access](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-17-2048.jpg)
![Make your own small vector template <typename T, size_t N = 3> class small_vector { public: T const * data() const { return m_head; } T * data() { return m_head; } private: T * m_head = nullptr; unsigned int m_size = 0; unsigned int m_capacity = N; std::array<T, N> m_data; }; explicit small_vector(size_t size) : m_size(static_cast<unsigned int>(size)) { if (m_size > N) { m_capacity = m_size; // Allocate only when the size is too large. m_head = new T[m_capacity]; } else { m_capacity = N; m_head = m_data.data(); } } small_vector() { m_head = m_data.data(); } ~small_vector() { if (m_head != m_data.data() && m_head != nullptr) { delete[] m_head; m_head = nullptr; } } Spend a small size of memory to reduce dynamic memory allocation Allocate memory only when size is too large No deallocation is needed if no allocation *data val val initial after push-back (empty) (dynamically allocated bu ff er) std::vector *data val val initial and after fi rst couple of push-back (preallocated bu ff er) (our) small_vector 18](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-18-2048.jpg)
![Small vector, cont. Copy constructor may also allocate memory Move constructor should not allocate memory small_vector(small_vector const & other) : m_size(other.m_size) { if (other.m_head == other.m_data.data()) { m_capacity = N; m_head = m_data.data(); } else { m_capacity = m_size; m_head = new T[m_capacity]; } std::copy_n(other.m_head, m_size, m_head); } small_vector(small_vector && other) noexcept : m_size(other.m_size) { if (other.m_head == other.m_data.data()) { m_capacity = N; std::copy_n(other.m_data.begin(), m_size, m_data.begin()); m_head = m_data.data(); } else { m_capacity = m_size; m_head = other.m_head; other.m_size = 0; other.m_capacity = N; other.m_head = other.m_data.data(); } } 19 Constructors are the key of making C++ work](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-19-2048.jpg)
![Numpy for dense array • The numpy library provides everything we need for arrays in Python • Convention of using numpy: • The created array copies the Python data: >>> import numpy as np >>> lst = [1, 1, 2, 3, 5] >>> print('A list:', lst) A list: [1, 1, 2, 3, 5] >>> array = np.array(lst) >>> print('An array:', np.array(array)) An array: [1 1 2 3 5] Create a list: Create an array: >>> array[2] = 8 >>> print(array) # The array changes. [1 1 8 3 5] >>> print(lst) # The input sequence is not changed. [1, 1, 2, 3, 5] 20](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-20-2048.jpg)
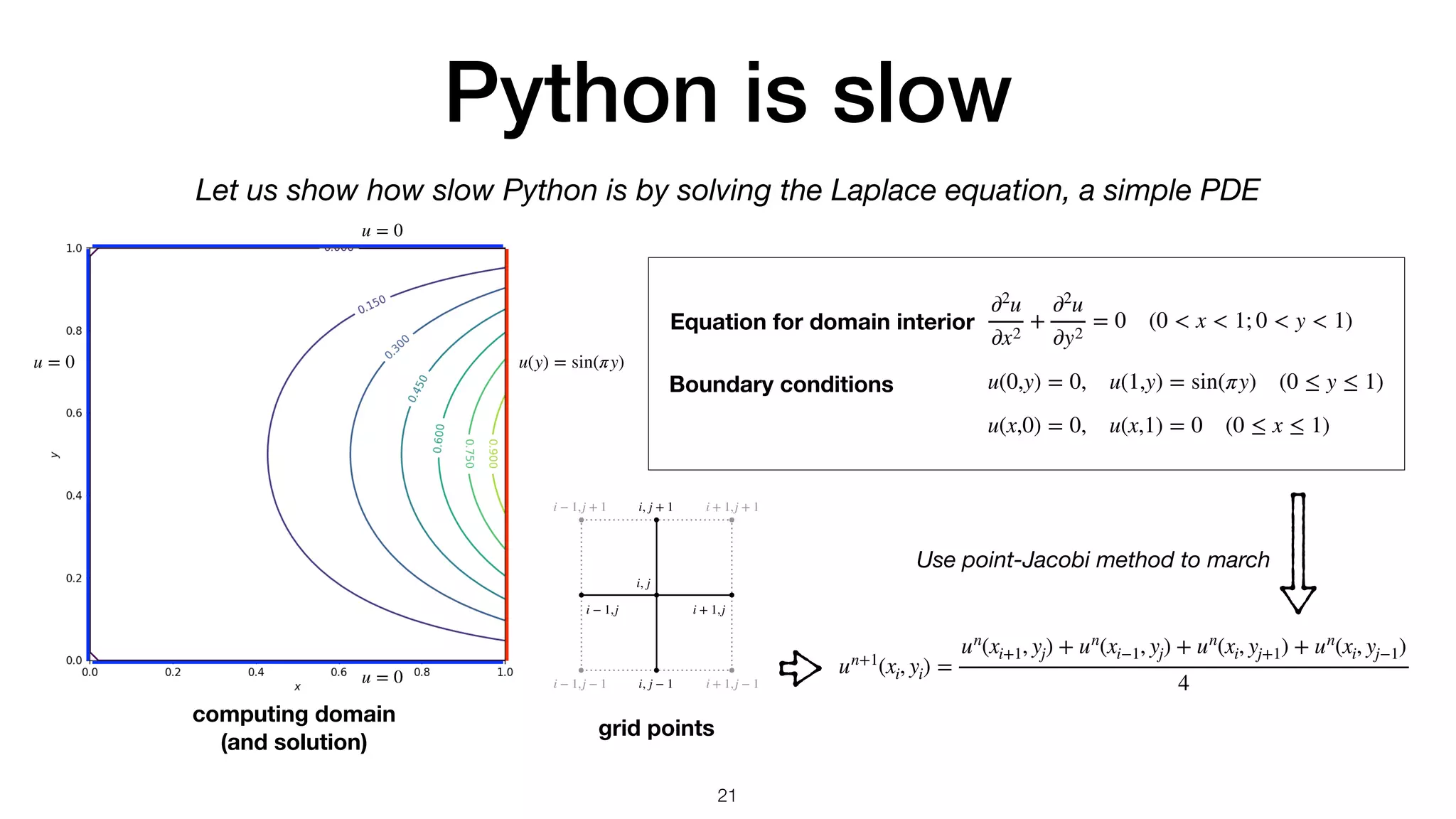
![Python vs numpy def solve_array(): u = uoriginal.copy() # Input from outer scope un = u.copy() # Create the buffer for the next time step converged = False step = 0 while not converged: step += 1 un[1:nx-1,1:nx-1] = (u[2:nx,1:nx-1] + u[0:nx-2,1:nx-1] + u[1:nx-1,2:nx] + u[1:nx-1,0:nx-2]) / 4 norm = np.abs(un-u).max() u[...] = un[...] converged = True if norm < 1.e-5 else False return u, step, norm def solve_python_loop(): u = uoriginal.copy() # Input from outer scope un = u.copy() # Create the buffer for the next time step converged = False step = 0 # Outer loop. while not converged: step += 1 # Inner loops. One for x and the other for y. for it in range(1, nx-1): for jt in range(1, nx-1): un[it,jt] = (u[it+1,jt] + u[it-1,jt] + u[it,jt+1] + u[it,jt-1]) / 4 norm = np.abs(un-u).max() u[...] = un[...] converged = True if norm < 1.e-5 else False return u, step, norm >>> with Timer(): >>> u, step, norm = solve_array() Wall time: 0.0552309 s >>> with Timer(): >>> u, step, norm = solve_python_loop() Wall time: 4.79688 s numpy array for point-Jacobi python loop for point-Jacobi The array version is 87x faster than the loop version 22](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-22-2048.jpg)
 { auto ret = solve1(modmesh::python::makeSimpleArray(uin)); return std::make_tuple( modmesh::python::to_ndarray(std::get<0>(ret)), std::get<1>(ret), std::get<2>(ret)); } ); } >>> with Timer(): >>> u, step, norm = solve_cpp.solve_cpp(uoriginal) Wall time: 0.0251369 s c++ loop for point-Jacobi expose to Python 23](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-23-2048.jpg)
![Runtime and maintainability 24 for it in range(1, nx-1): for jt in range(1, nx-1): un[it,jt] = (u[it+1,jt] + u[it-1,jt] + u[it,jt+1] + u[it,jt-1]) / 4 un[1:nx-1,1:nx-1] = (u[2:nx,1:nx-1] + u[0:nx-2,1:nx-1] + u[1:nx-1,2:nx] + u[1:nx-1,0:nx-2]) / 4 for (size_t it=1; it<nx-1; ++it) { for (size_t jt=1; jt<nx-1; ++jt) { un(it,jt) = (u(it+1,jt) + u(it-1,jt) + u(it,jt+1) + u(it,jt-1)) / 4; } } Point-Jacobi method Python nested loop Numpy array C++ nested loop 4.797s (1x) 0.055s (87x) 0.025s (192x) un+1 (xi, yi) = un (xi+1, yj) + un (xi−1, yj) + un (xi, yj+1) + un (xi, yj−1) 4](https://image.slidesharecdn.com/simplearraybetweenpythonandc-230905103107-ec7953e5/75/SimpleArray-between-Python-and-C-24-2048.jpg)
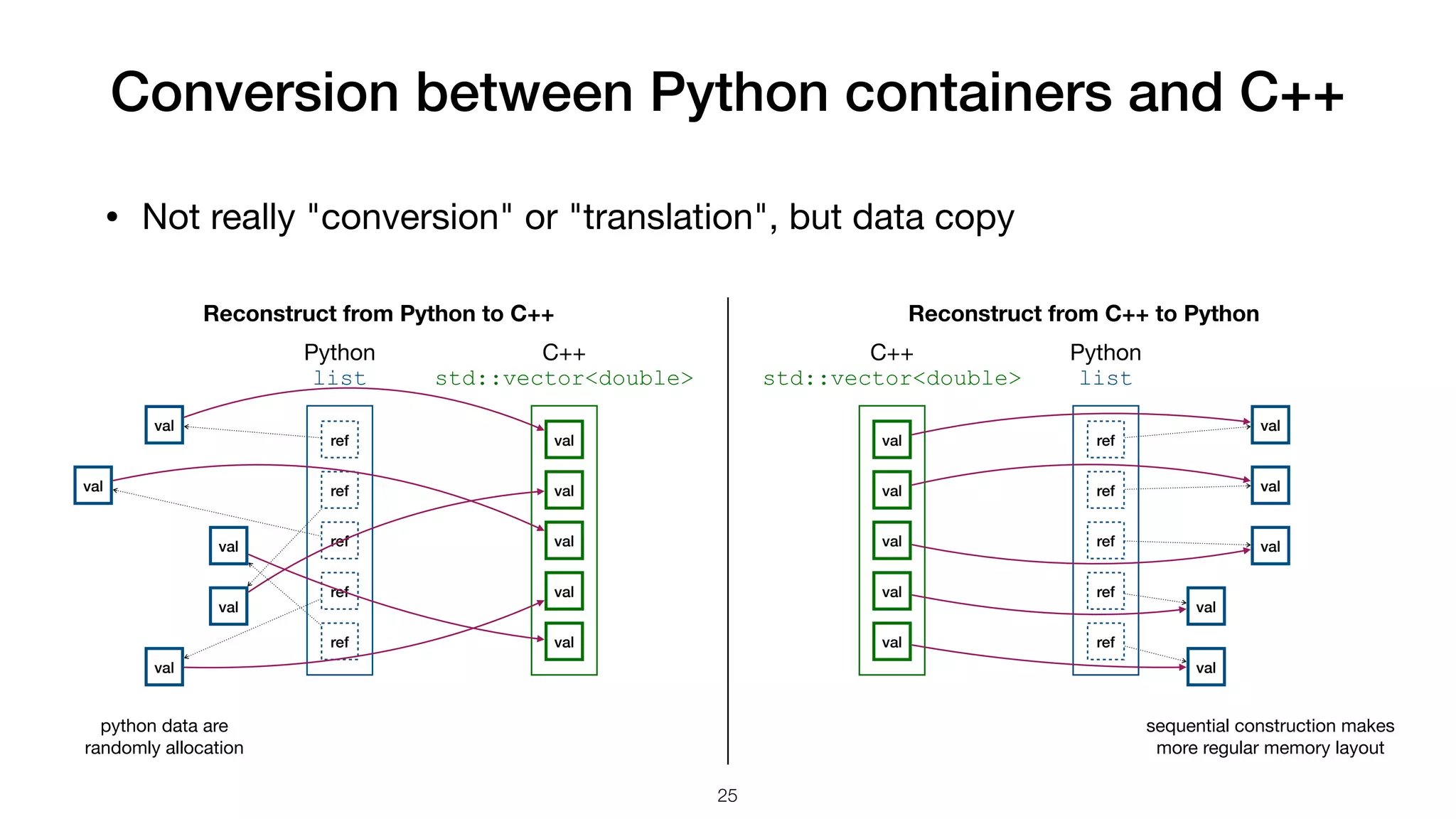
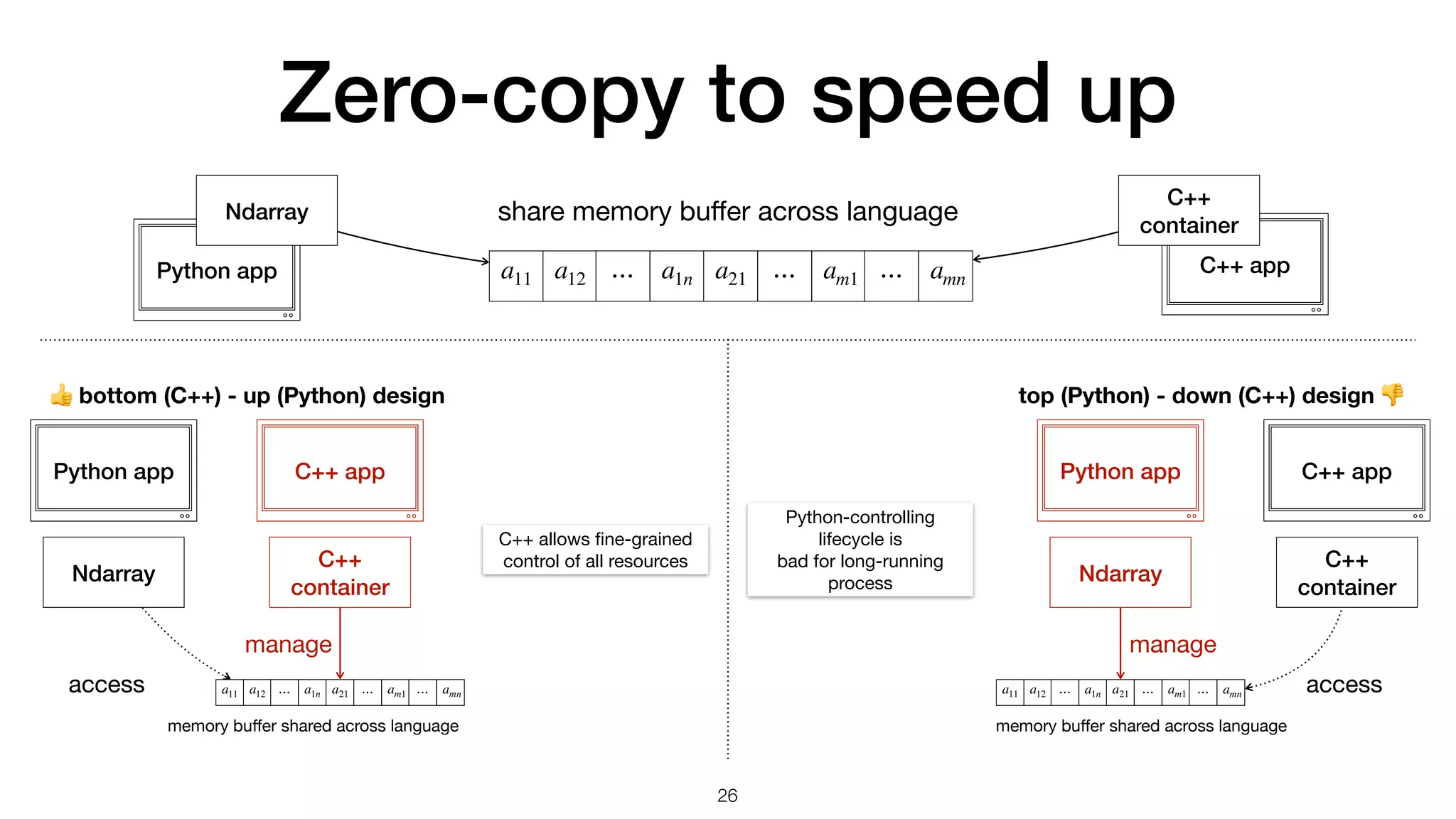



The document presents a comparison between array handling in Python and C++, focusing on a custom array library named 'simplearray' designed for high-performance computing. It highlights key features such as multi-dimensional access, fixed size allocation, and custom buffer management. Additionally, it contrasts performance benchmarks of Python's native loops with numpy arrays, illustrating significant efficiency differences.