Downloaded 158 times























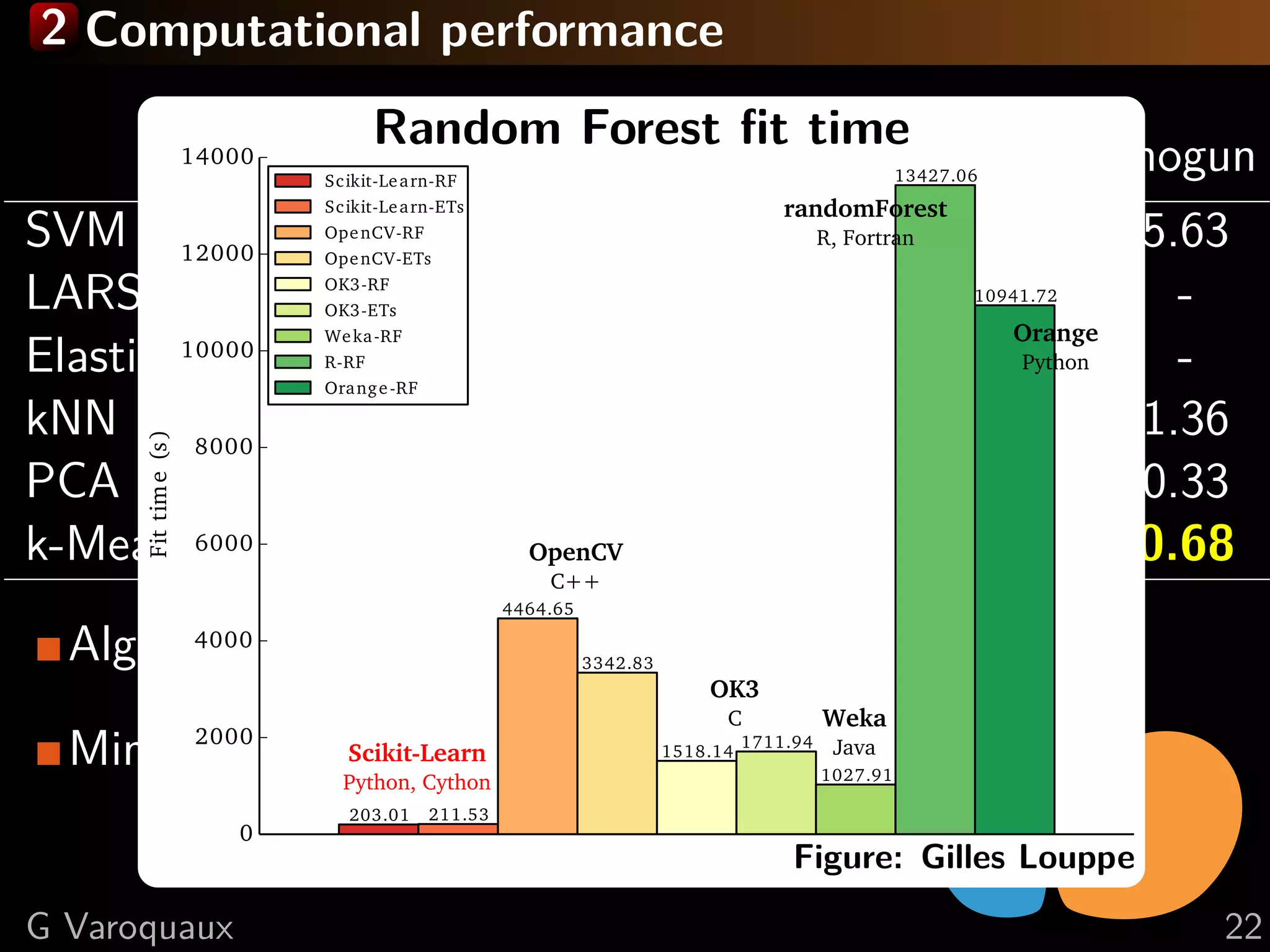










![3 On-the-fly data reduction Example: randomized SVD Random projection sklearn.utils.extmath.randomized svd X = np.random.normal(size=(50000, 200)) %timeit lapack = linalg.svd(X, full matrices=False) 1 loops, best of 3: 6.09 s per loop %timeit arpack=splinalg.svds(X, 10) 1 loops, best of 3: 2.49 s per loop %timeit randomized = randomized svd(X, 10) 1 loops, best of 3: 303 ms per loop linalg.norm(lapack[0][:, :10] - arpack[0]) / 2000 0.0022360679774997738 linalg.norm(lapack[0][:, :10] - randomized[0]) / 2000 0.0022121161221386925 G Varoquaux 26](https://image.slidesharecdn.com/slides-141126035842-conversion-gate01/75/Simple-big-data-in-Python-51-2048.jpg)








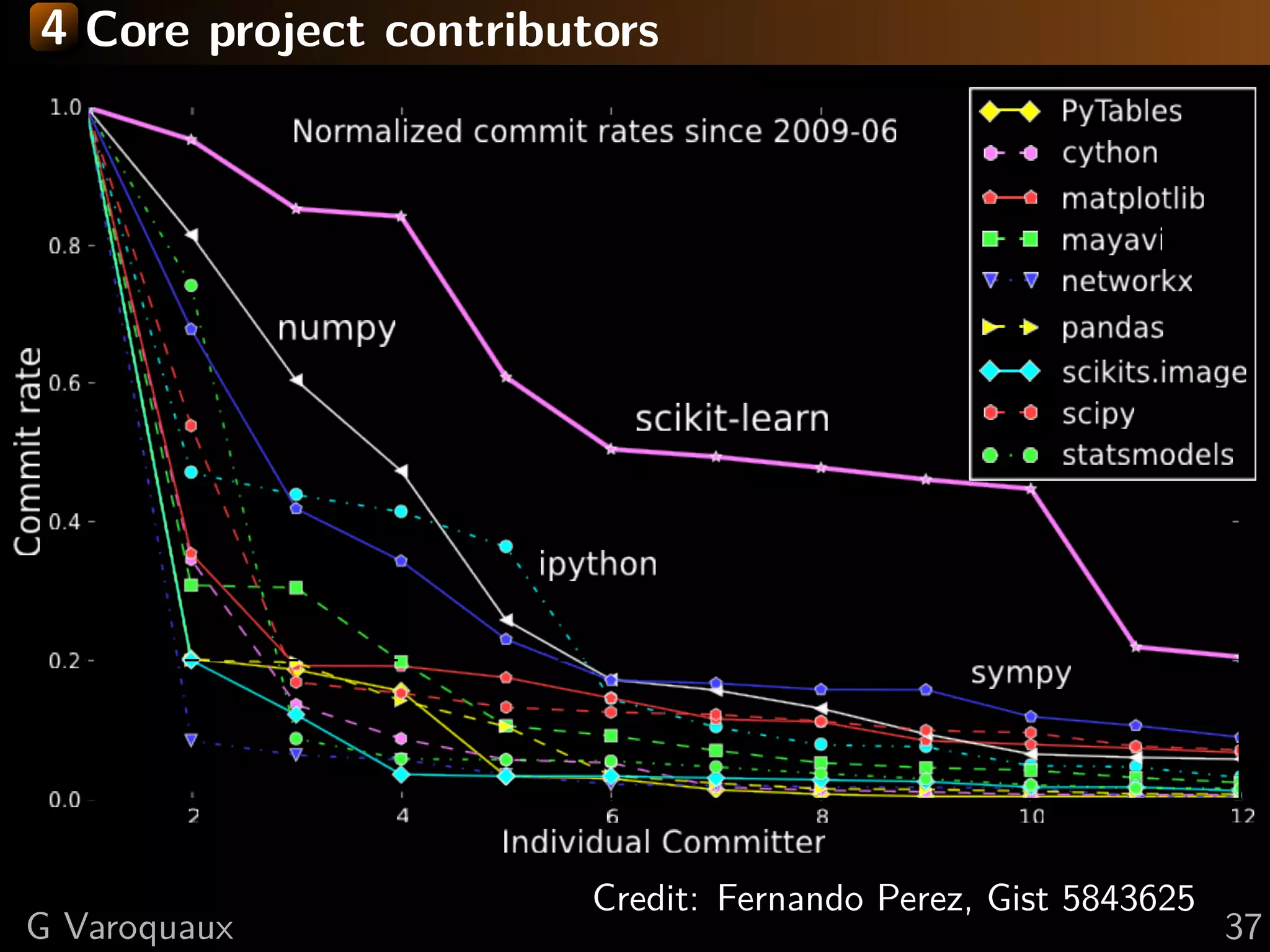



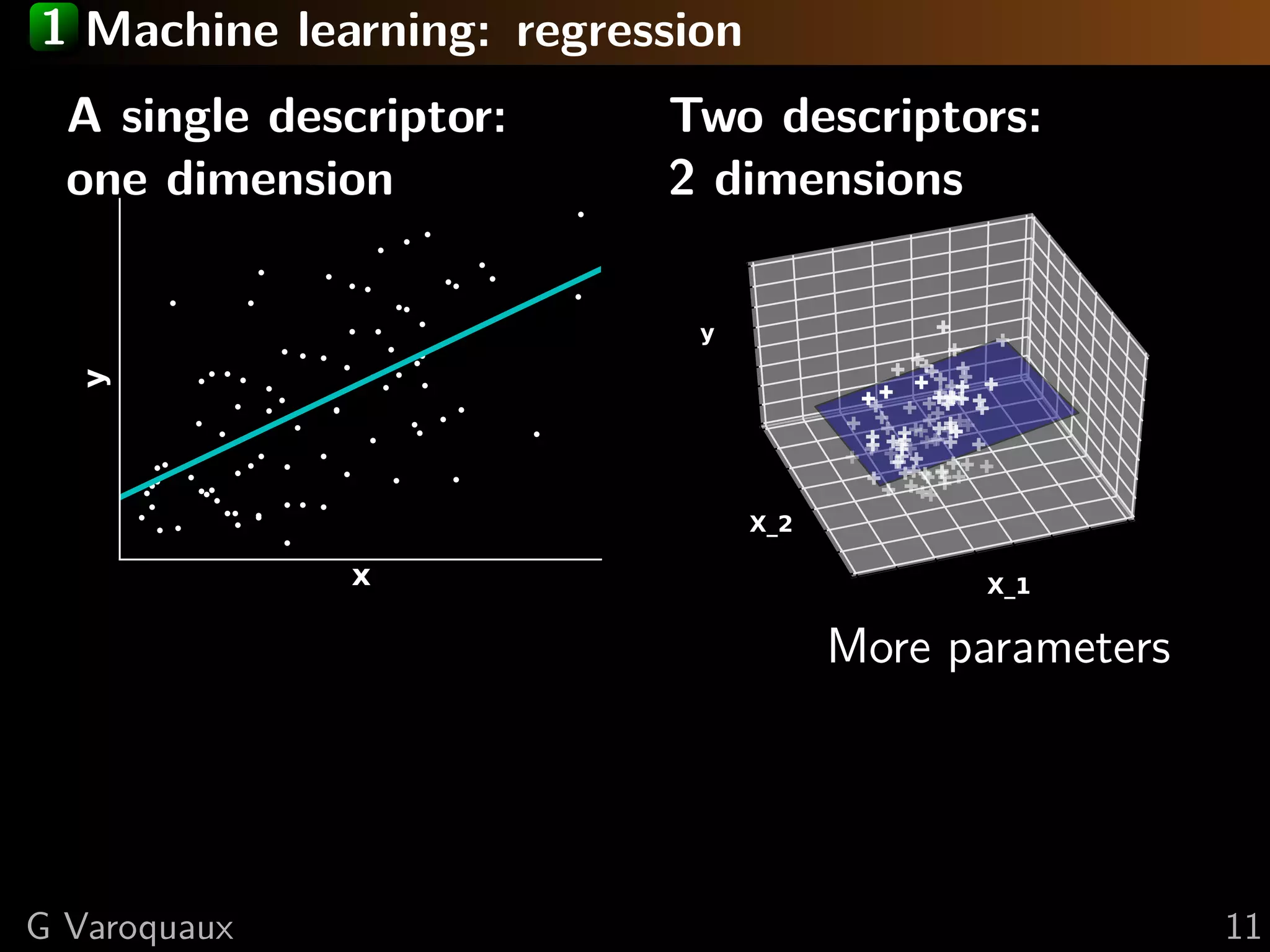
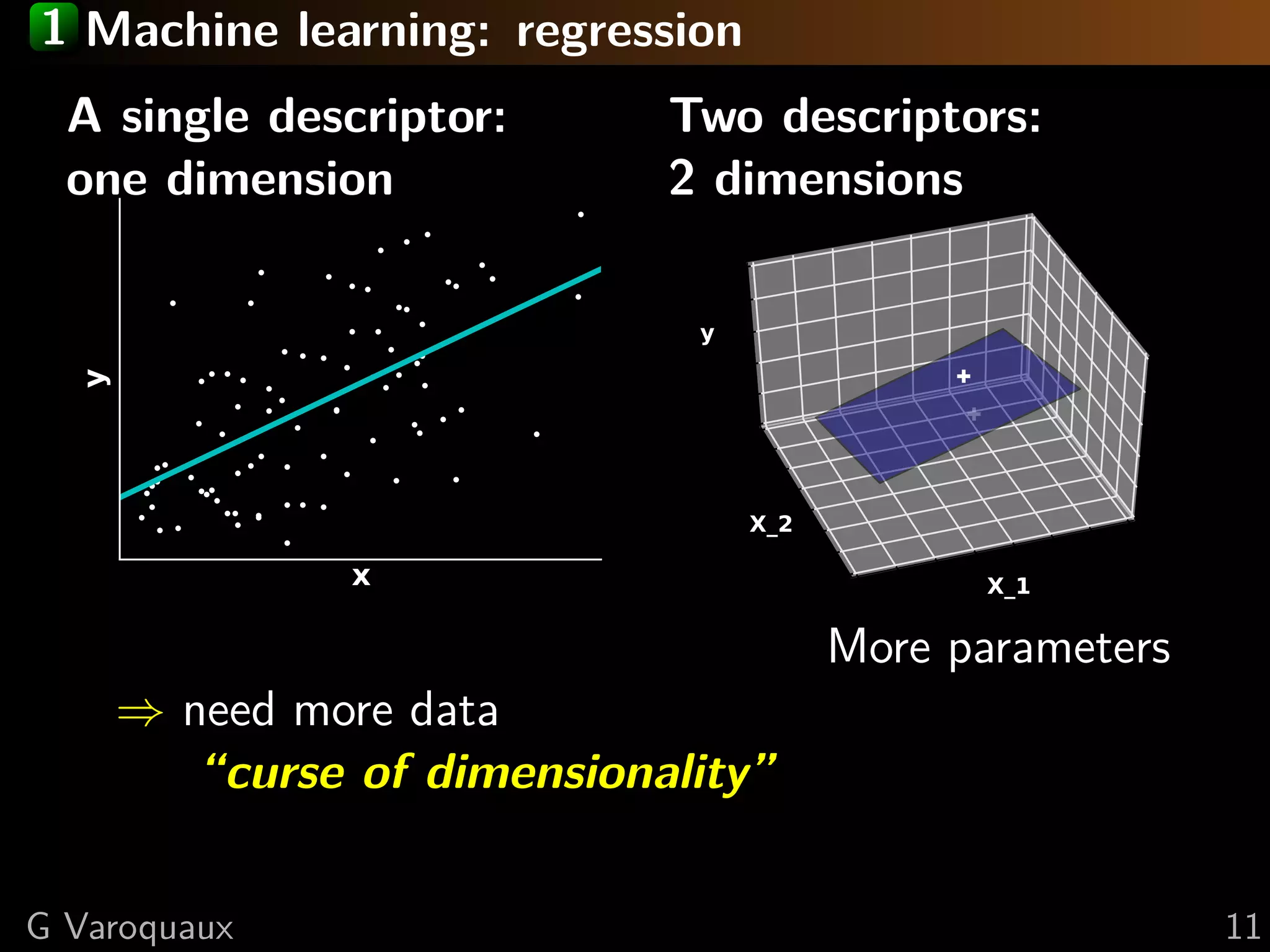
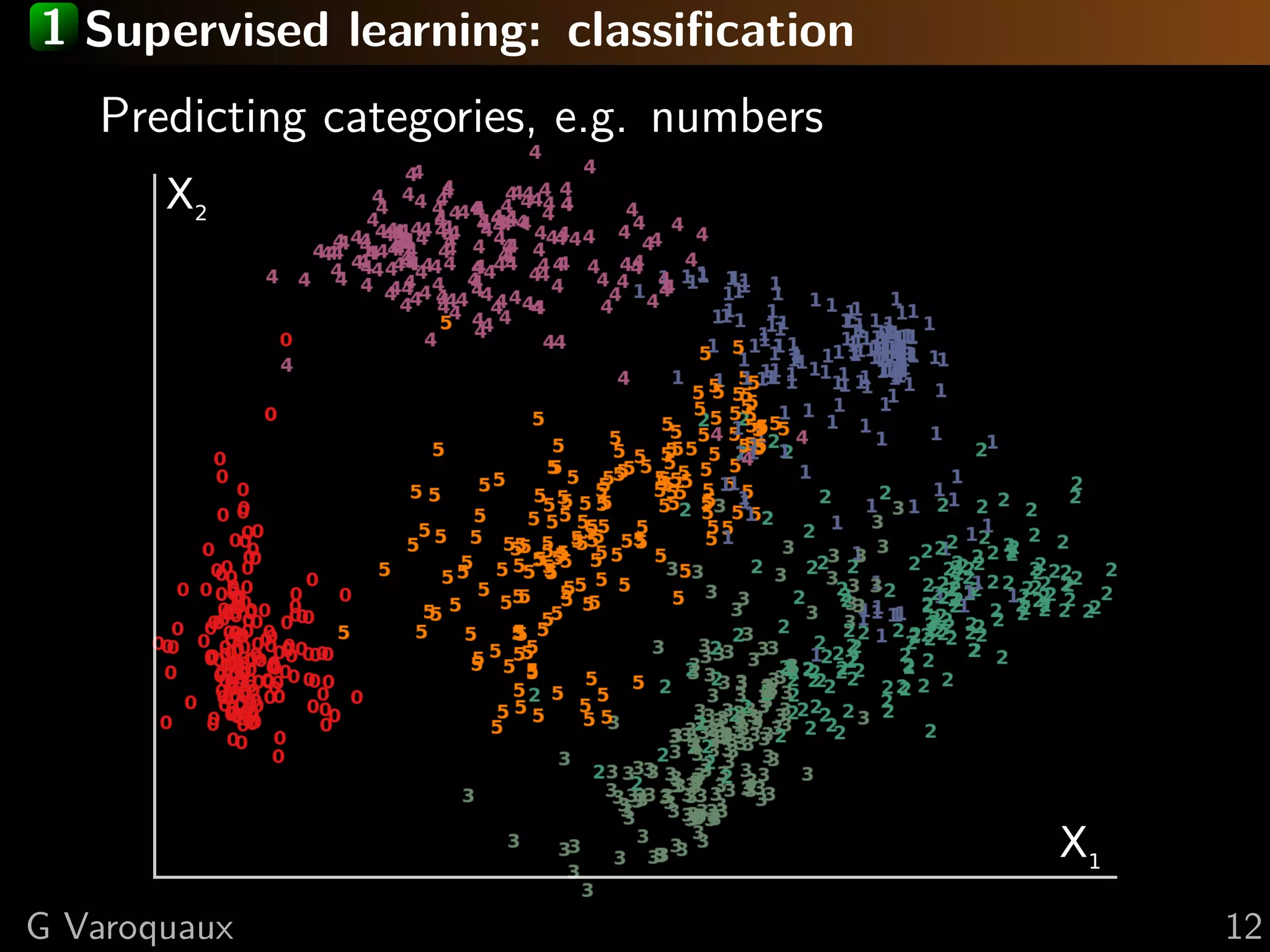
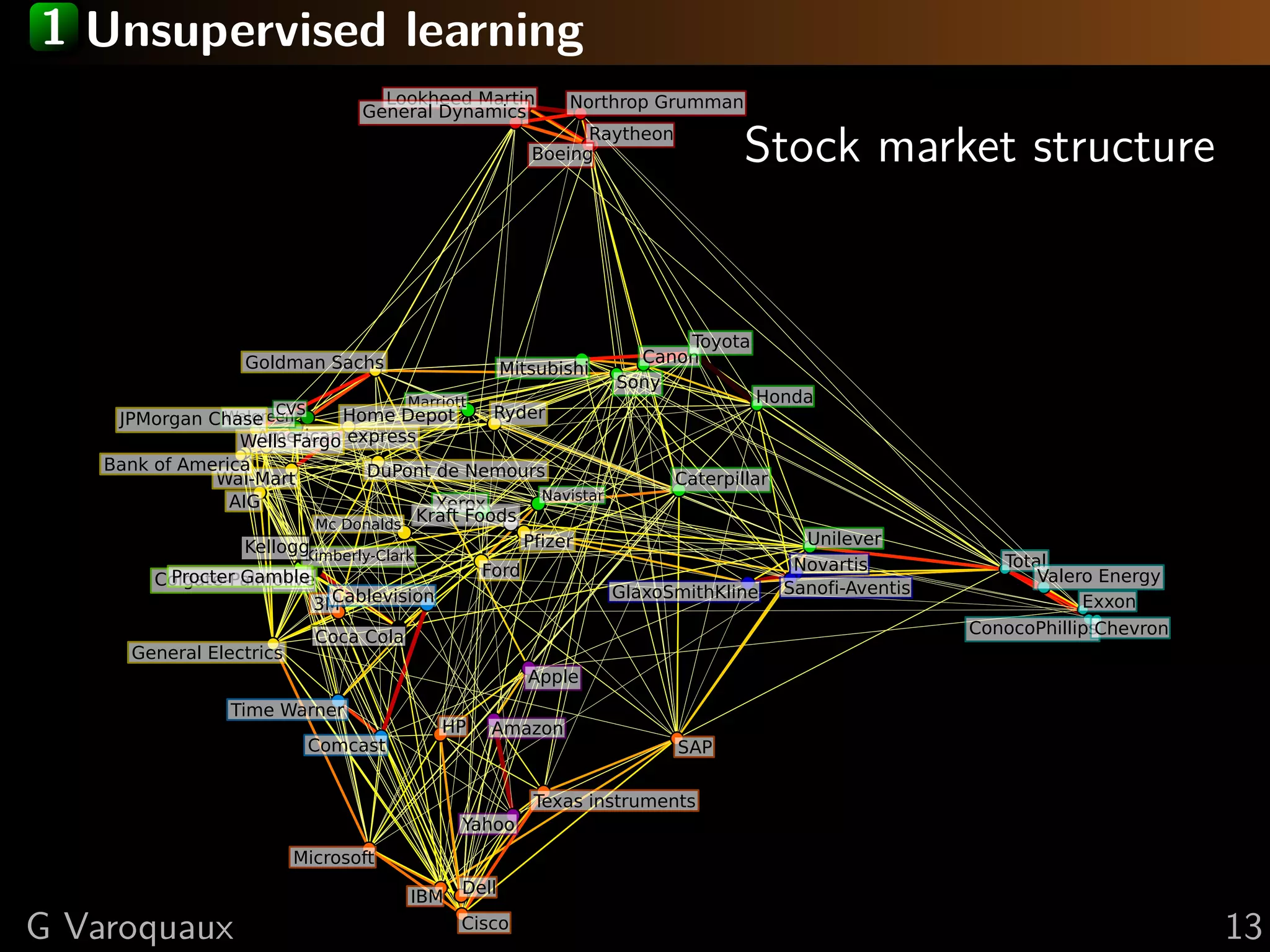
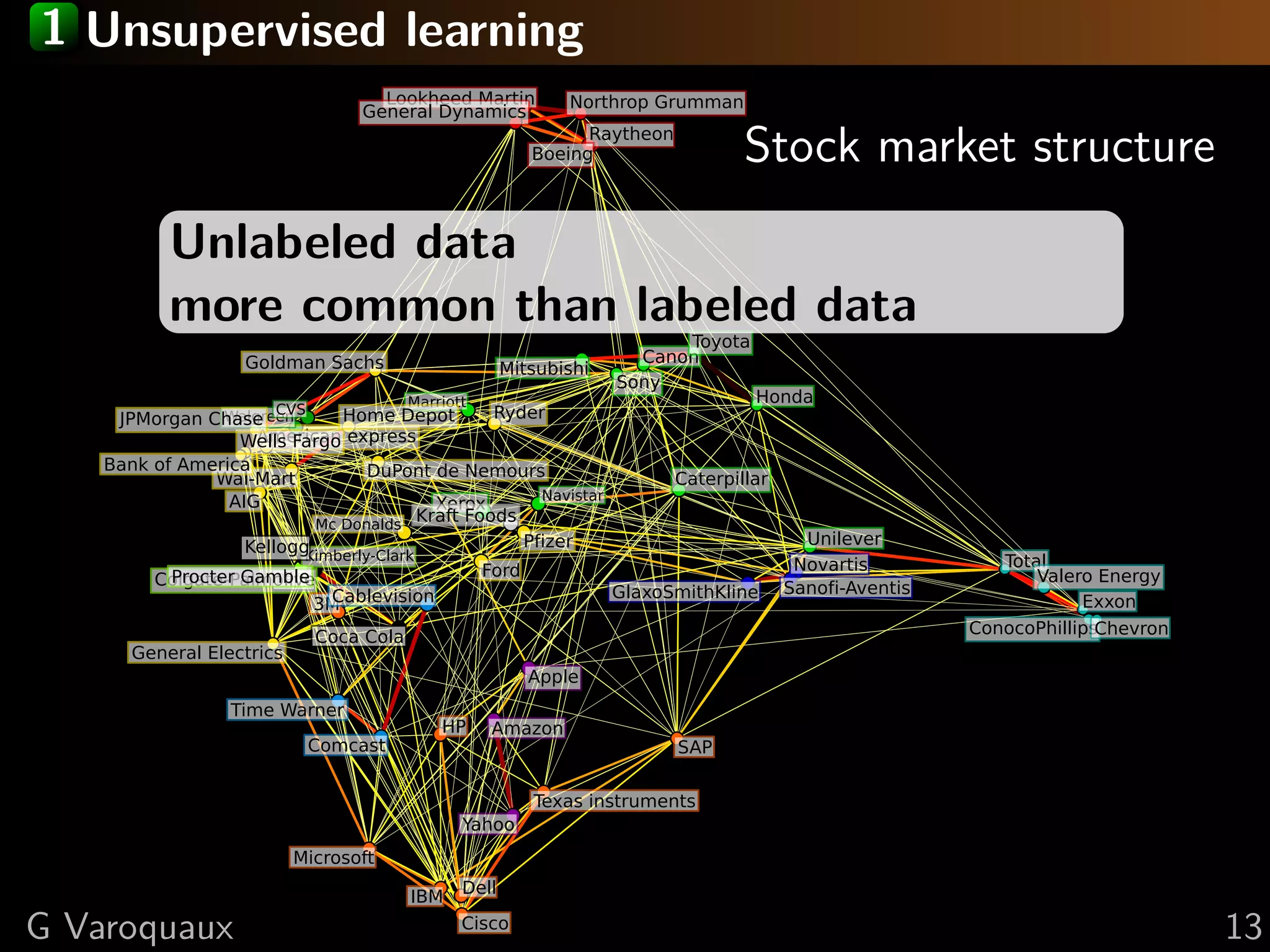
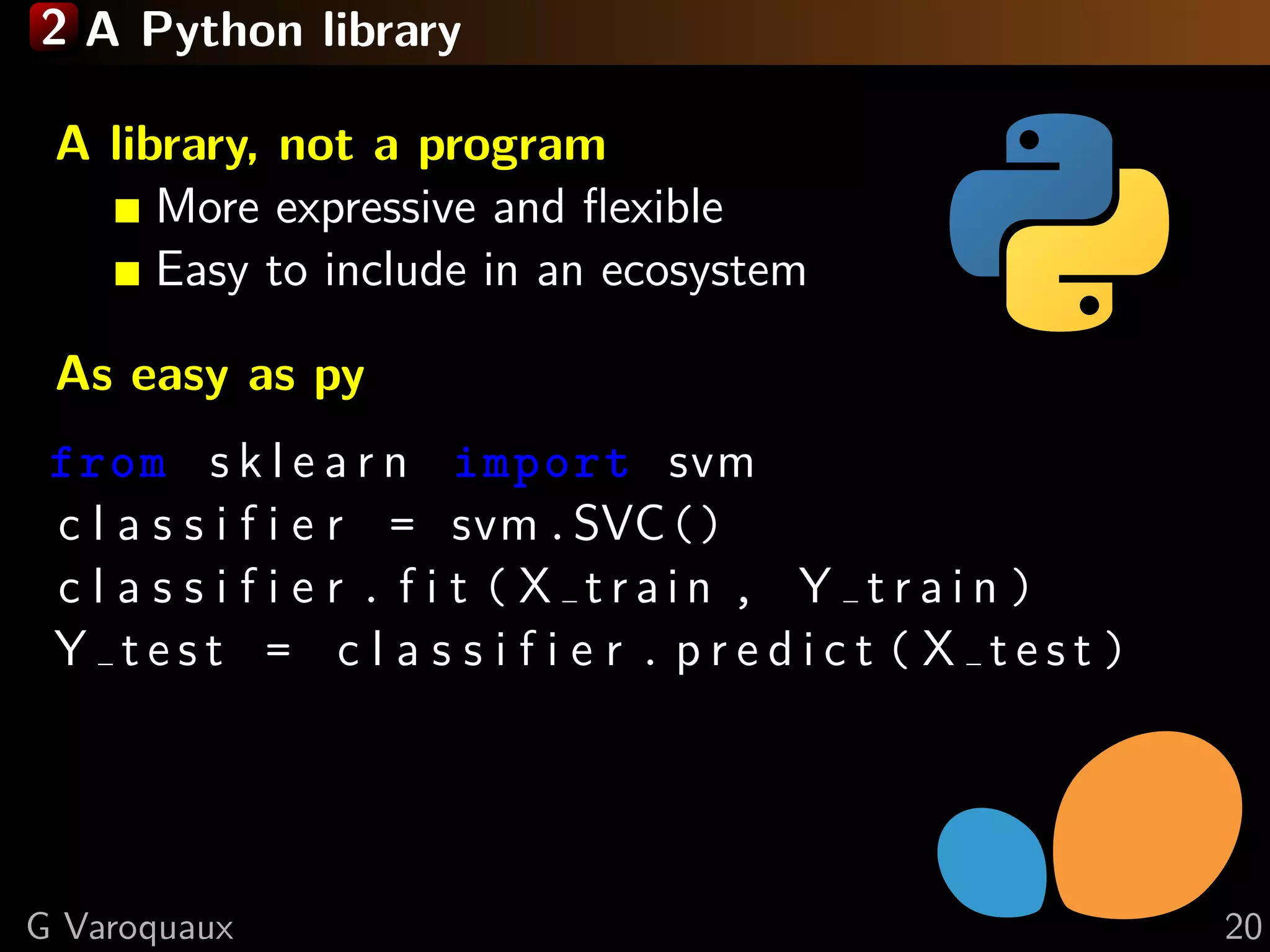
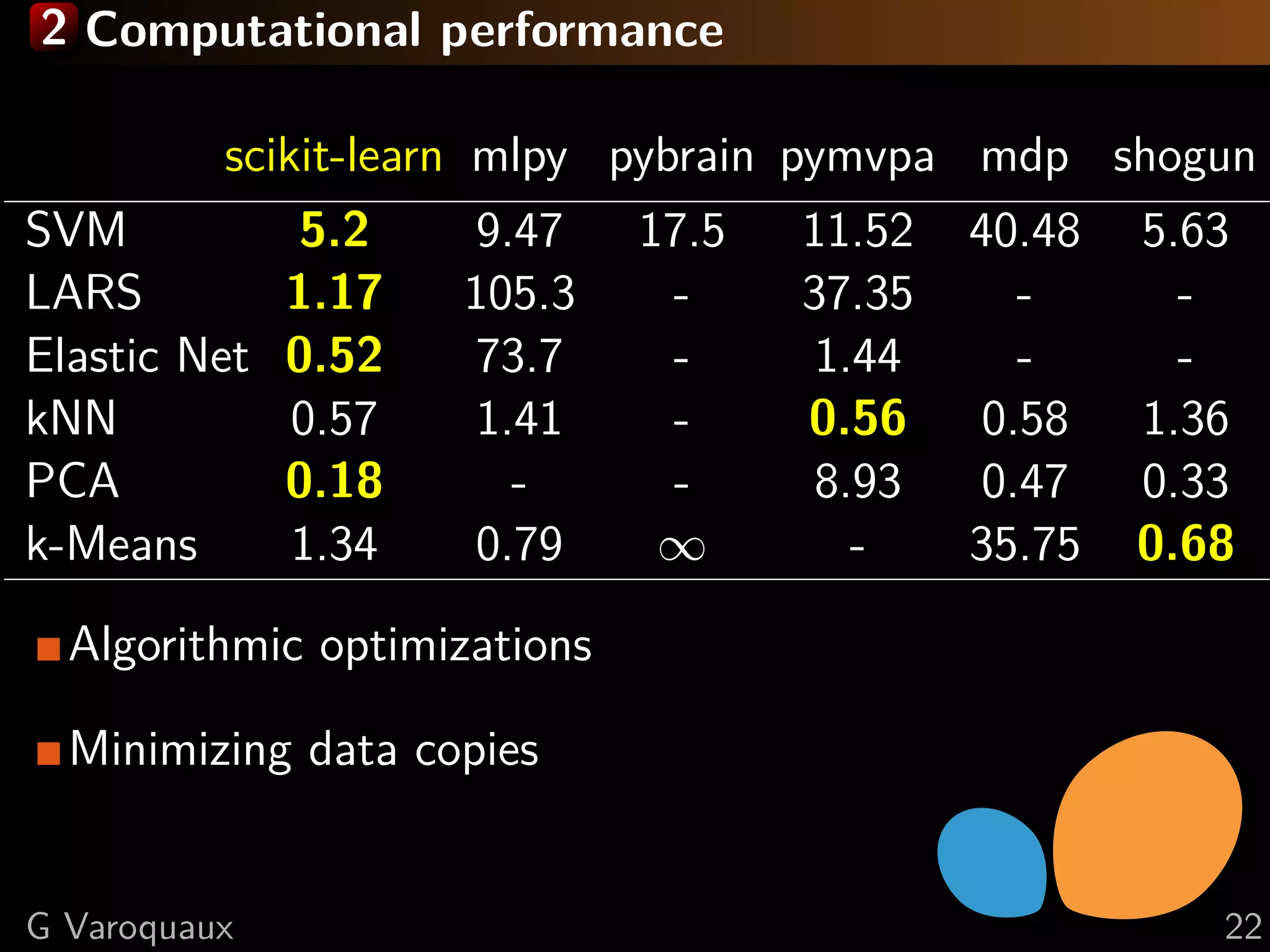
This document discusses machine learning and working with big data on a budget. It begins with a brief history of machine learning and discusses challenges like overfitting and the curse of dimensionality. It then introduces scikit-learn as a Python library for machine learning that provides many algorithms and tools. Finally, it discusses techniques for working with "big data" even when resources are limited, such as online algorithms, data reduction, and data-parallel computing.