Download as PDF, PPTX

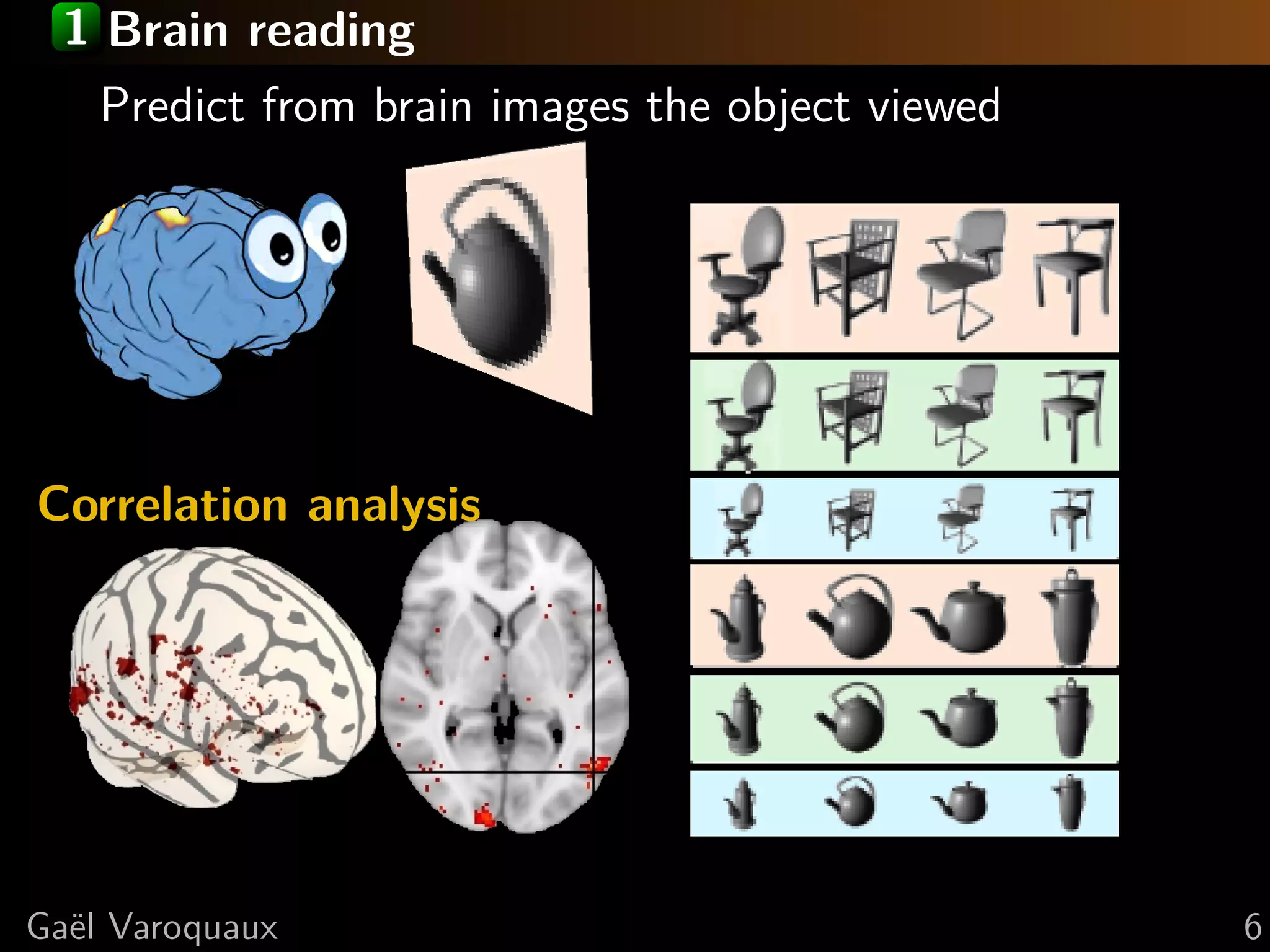
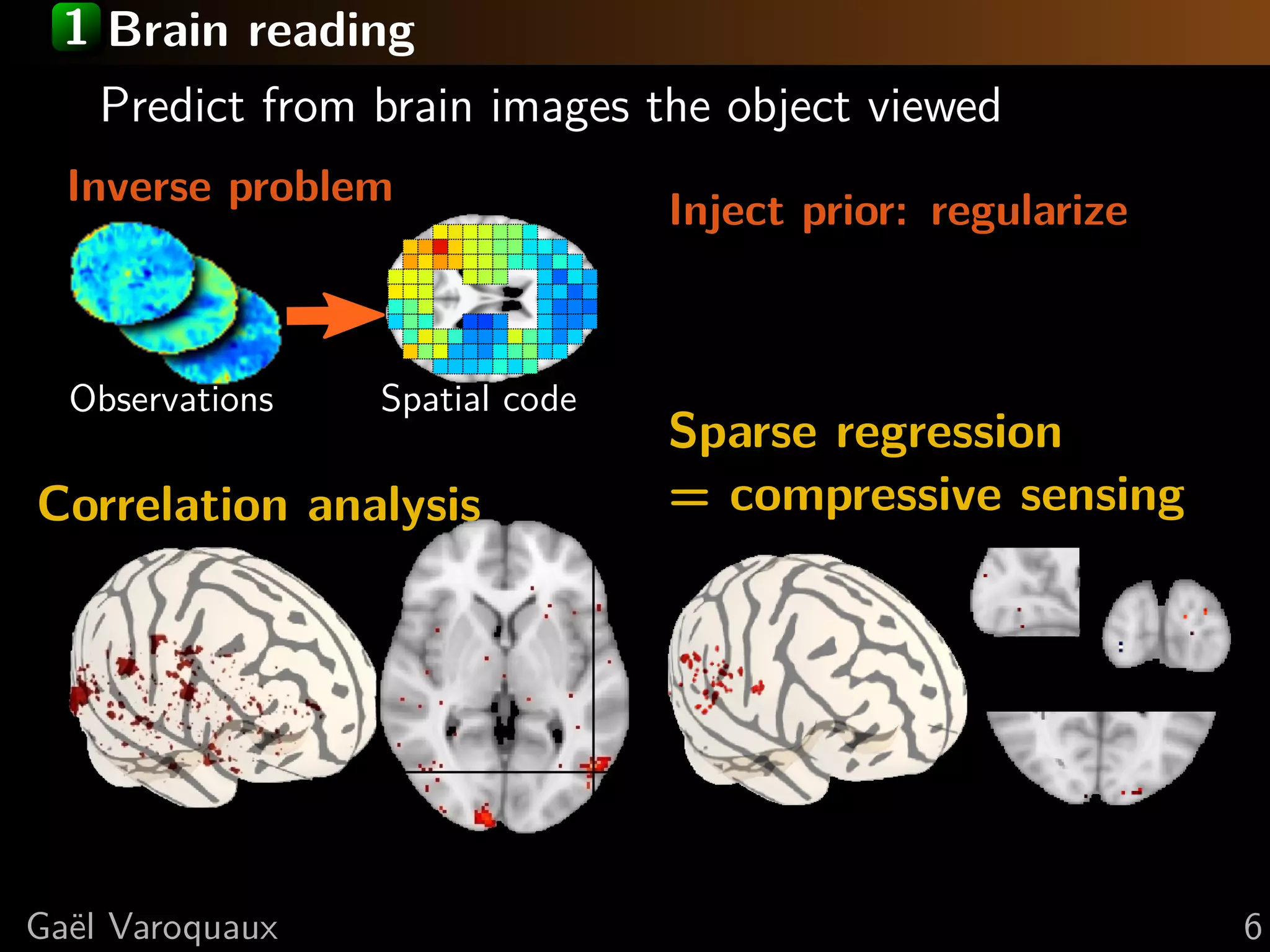
![1 Brain reading Predict from brain images the object viewed Inverse problem Inject prior: regularize Extract brain regions Observations Spatial code Total variation Correlation analysis regression [Michel, Trans Med Imag 2011] Ga¨l Varoquaux e 6](https://image.slidesharecdn.com/slides-110714171721-phpapp01/75/Python-for-brain-mining-neuro-science-with-state-of-the-art-machine-learning-and-data-visualization-12-2048.jpg)
![1 Brain reading Predict from brain images the object viewed Inverse problem Inject prior: regularize Cast the problem in Extract brain regions a prediction task: Observations supervised Total variation Spatial code learning. Correlation analysis a model-selection metric Prediction is regression [Michel, Trans Med Imag 2011] Ga¨l Varoquaux e 6](https://image.slidesharecdn.com/slides-110714171721-phpapp01/75/Python-for-brain-mining-neuro-science-with-state-of-the-art-machine-learning-and-data-visualization-13-2048.jpg)
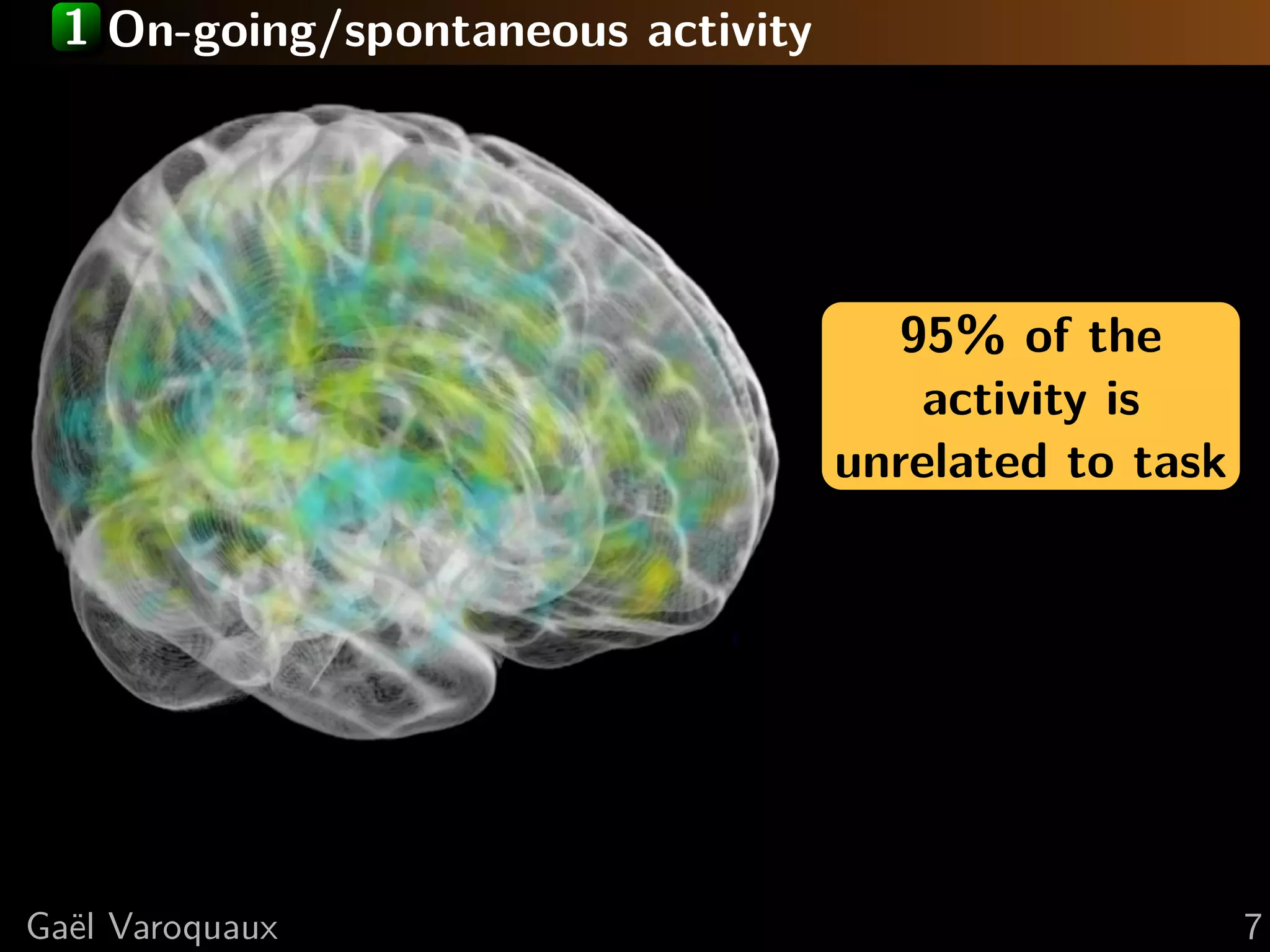
![1 Learning regions from spontaneous activity Spatial Time series map Multi-subject dictionary learning Sparsity + spatial continuity + spatial variability ⇒ Individual maps + functional regions atlas [Varoquaux, Inf Proc Med Imag 2011] Ga¨l Varoquaux e 8](https://image.slidesharecdn.com/slides-110714171721-phpapp01/75/Python-for-brain-mining-neuro-science-with-state-of-the-art-machine-learning-and-data-visualization-15-2048.jpg)
![1 Graphical models: interactions between regions Estimate covariance structure Many parameters to learn Regularize: conditional independence = sparsity on inverse covariance [Varoquaux NIPS 2010] Ga¨l Varoquaux e 9](https://image.slidesharecdn.com/slides-110714171721-phpapp01/75/Python-for-brain-mining-neuro-science-with-state-of-the-art-machine-learning-and-data-visualization-16-2048.jpg)
![1 Graphical models: interactions between regions Estimate covariance structure Many parameters to learn Regularize: conditional Find structure via a density estimation: independence unsupervised learning. = sparsity on inverse Model selection: likelihood of new data covariance [Varoquaux NIPS 2010] Ga¨l Varoquaux e 9](https://image.slidesharecdn.com/slides-110714171721-phpapp01/75/Python-for-brain-mining-neuro-science-with-state-of-the-art-machine-learning-and-data-visualization-17-2048.jpg)







![2 joblib Lazy recomputing >>> from j o b l i b import Memory >>> mem = Memory ( c a c h e d i r = ’/ tmp / joblib ’) >>> import numpy a s np >>> a = np . v a n d e r ( np . a r a n g e (3) ) >>> s q u a r e = mem. c a c h e ( np . s q u a r e ) >>> b = square (a) [ Memory ] C a l l i n g s q u a r e ... s q u a r e ( a r r a y ([[0 , 0 , 1] , [1 , 1 , 1] , [4 , 2 , 1]]) ) s q u a r e - 0.0 s >>> c = s q u a r e ( a ) >>> # No recomputation Ga¨l Varoquaux e 19](https://image.slidesharecdn.com/slides-110714171721-phpapp01/75/Python-for-brain-mining-neuro-science-with-state-of-the-art-machine-learning-and-data-visualization-27-2048.jpg)


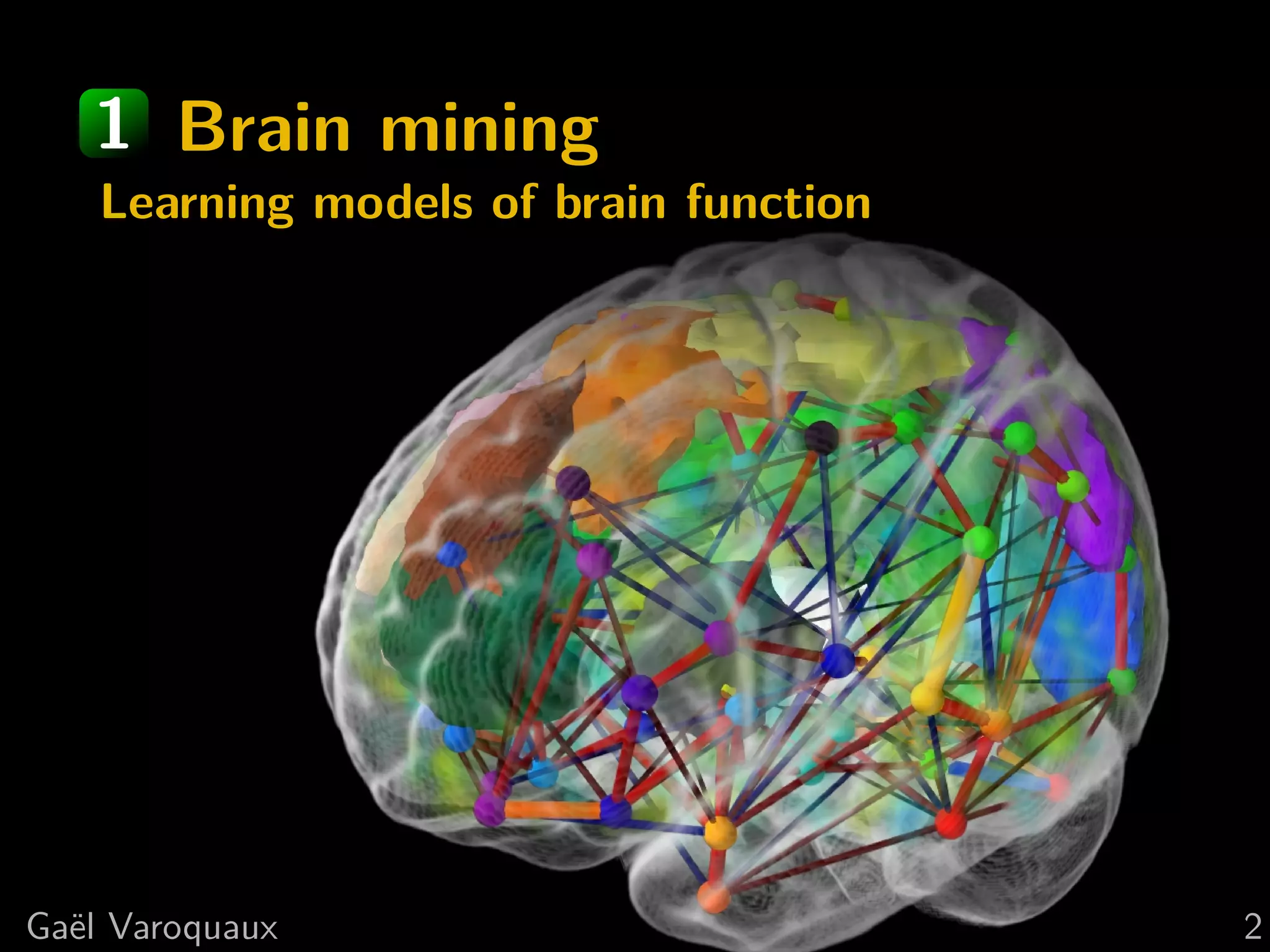
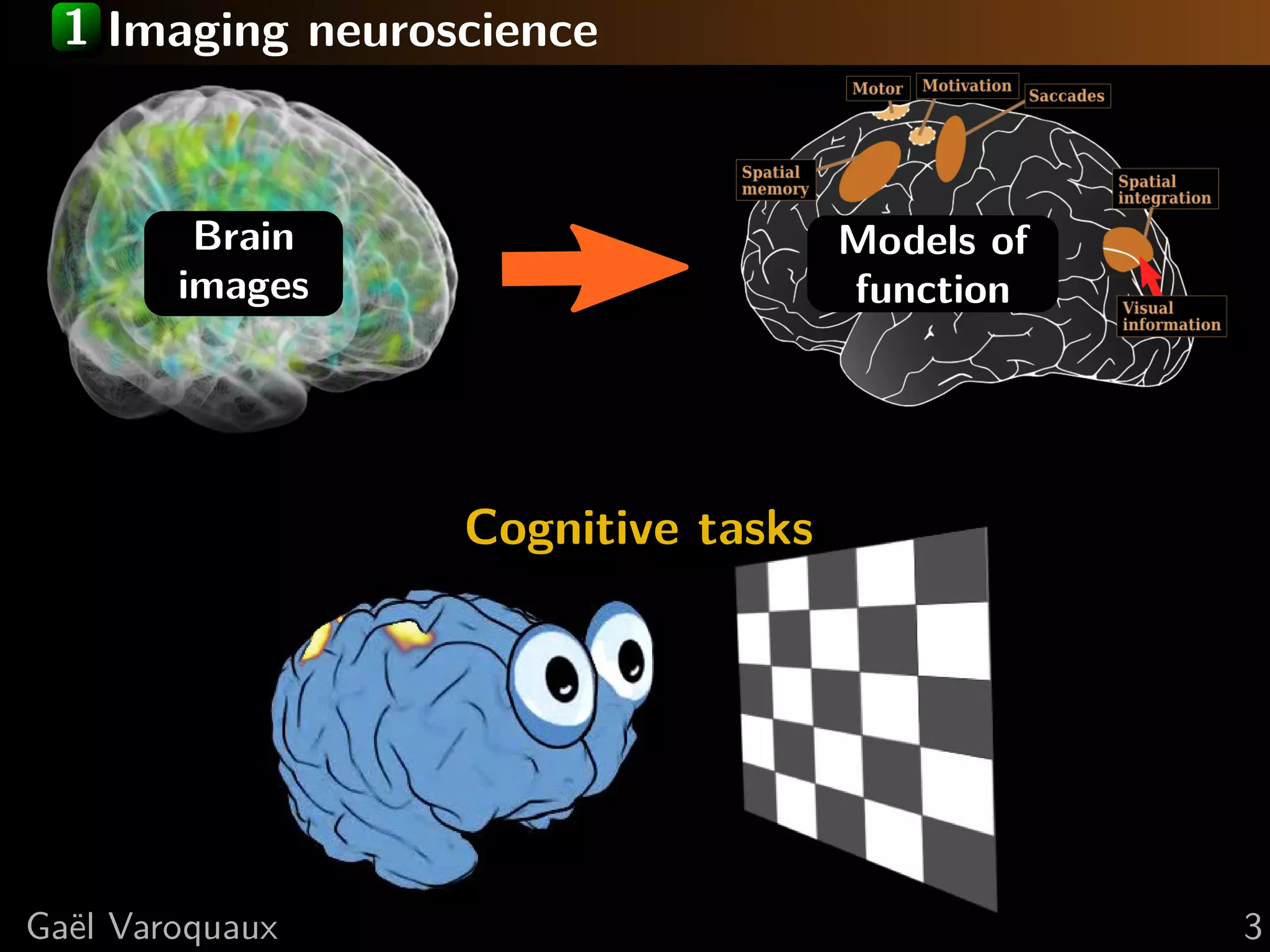
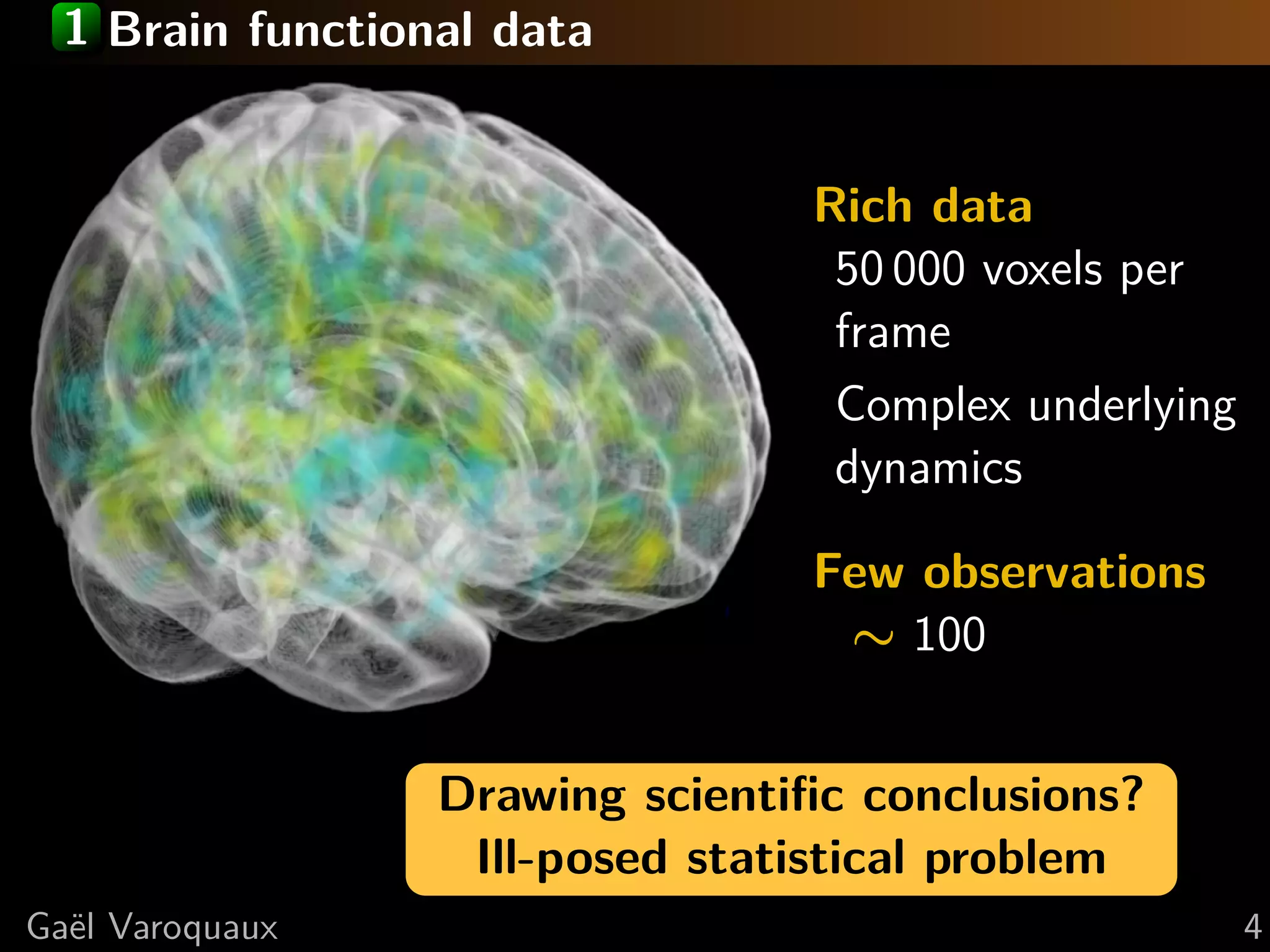
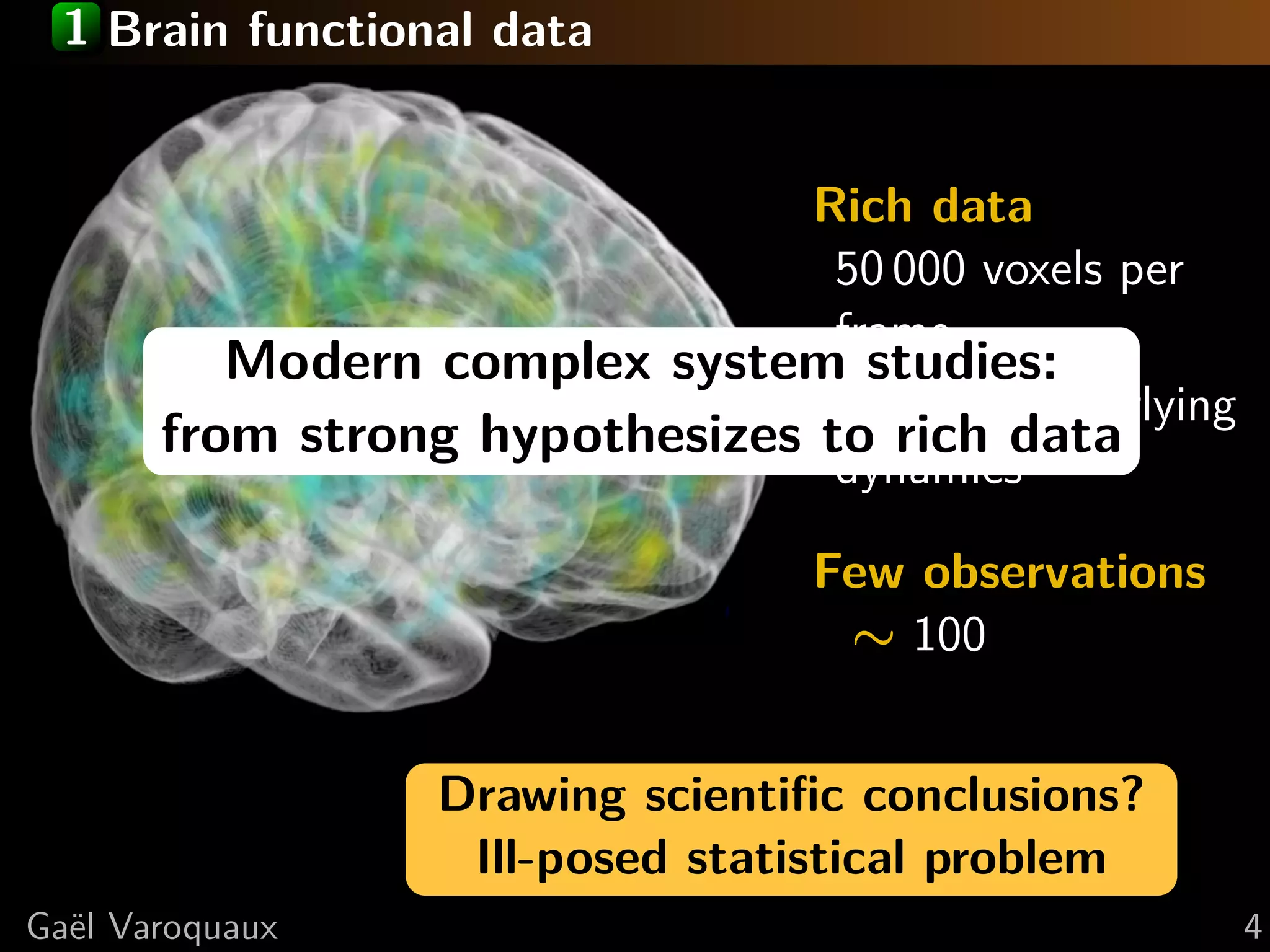
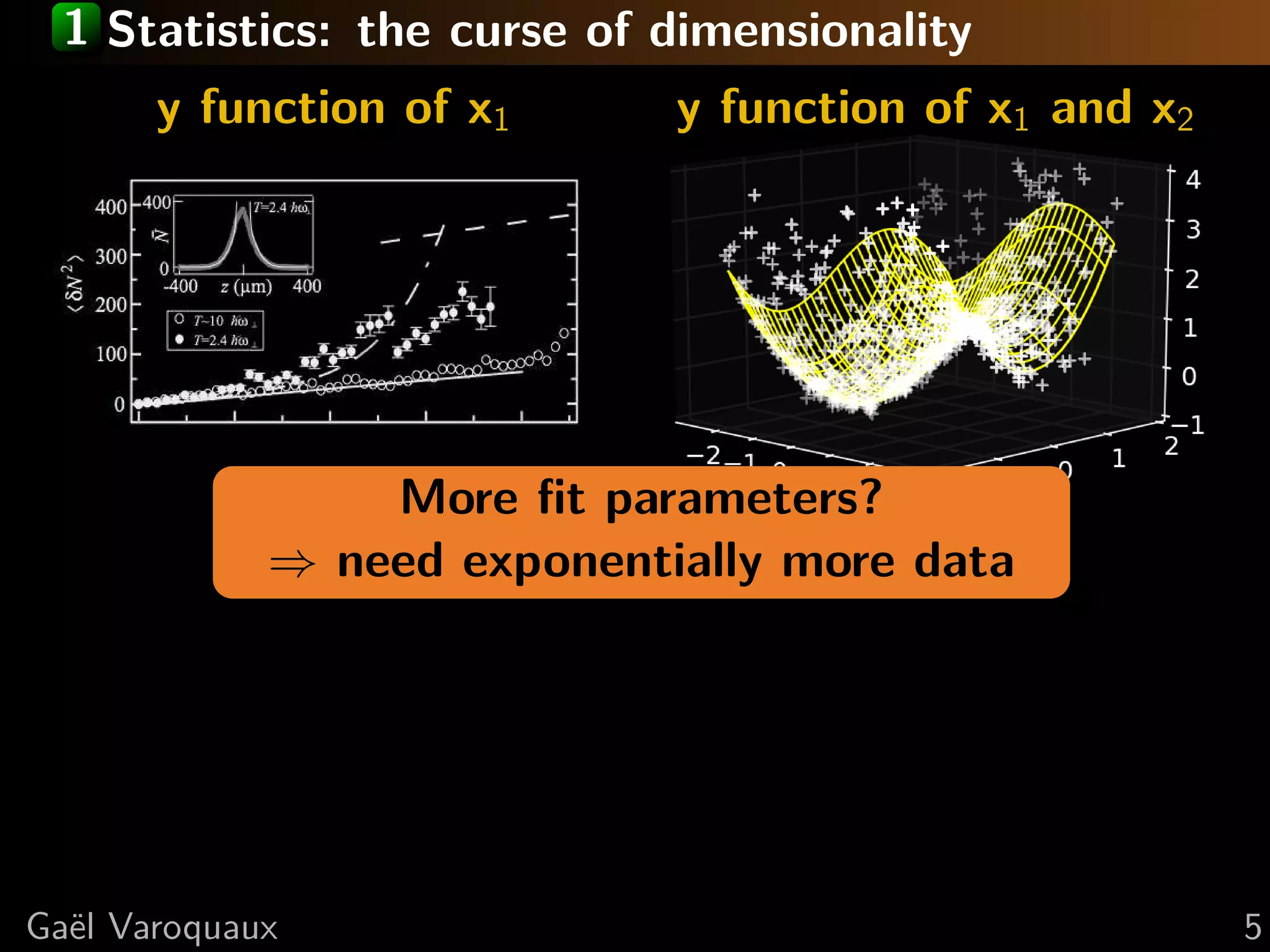
This document discusses using Python for neuroscience applications with machine learning and data visualization. It describes using tools like Mayavi, scikit-learn, and joblib for tasks like analyzing brain imaging data, learning functional regions of the brain from spontaneous activity, and modeling interactions between brain regions. It highlights challenges in analyzing high-dimensional brain data with few observations and discusses how machine learning can help address these challenges by incorporating expert knowledge and regularization.