Downloaded 72 times





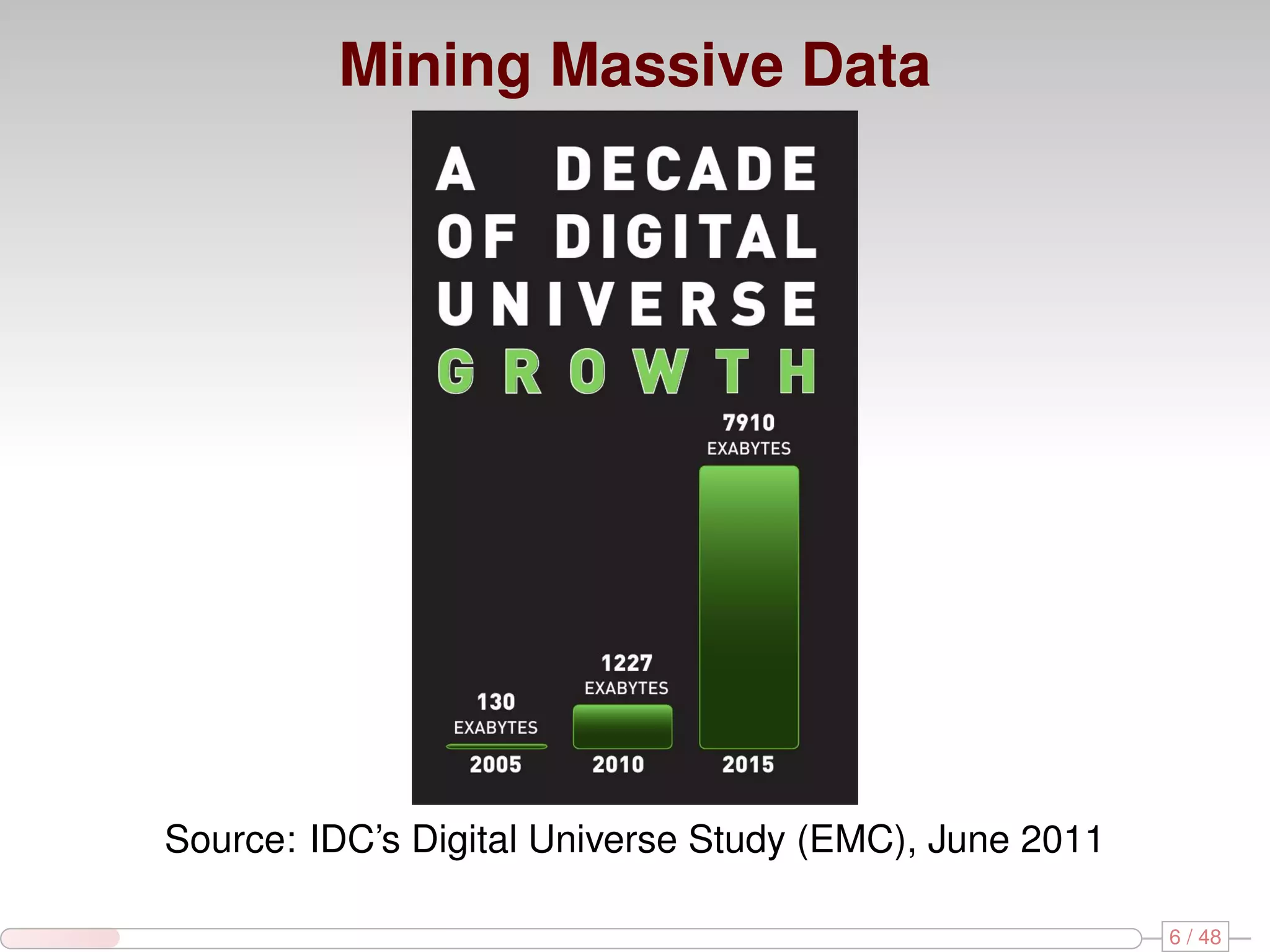












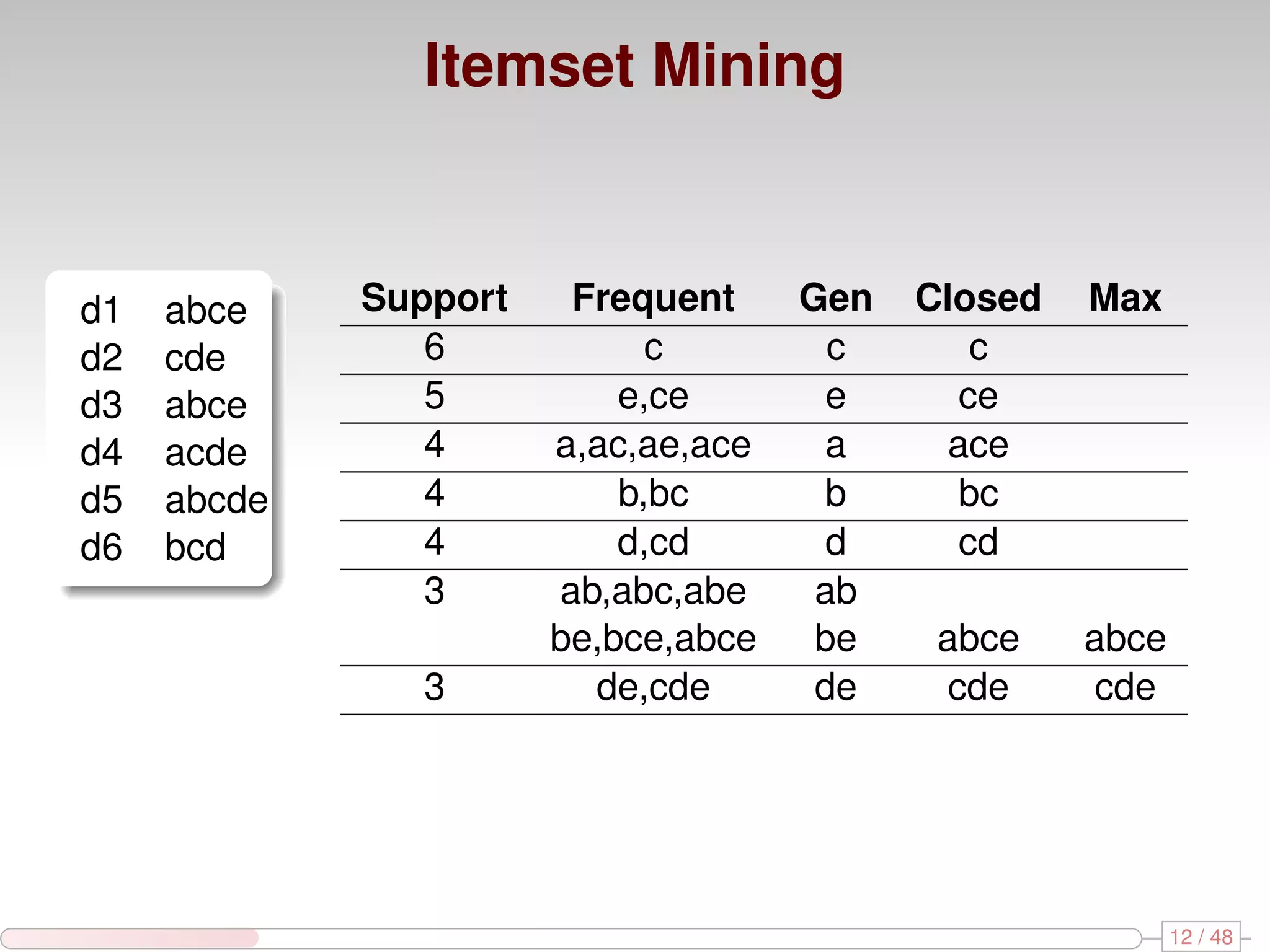

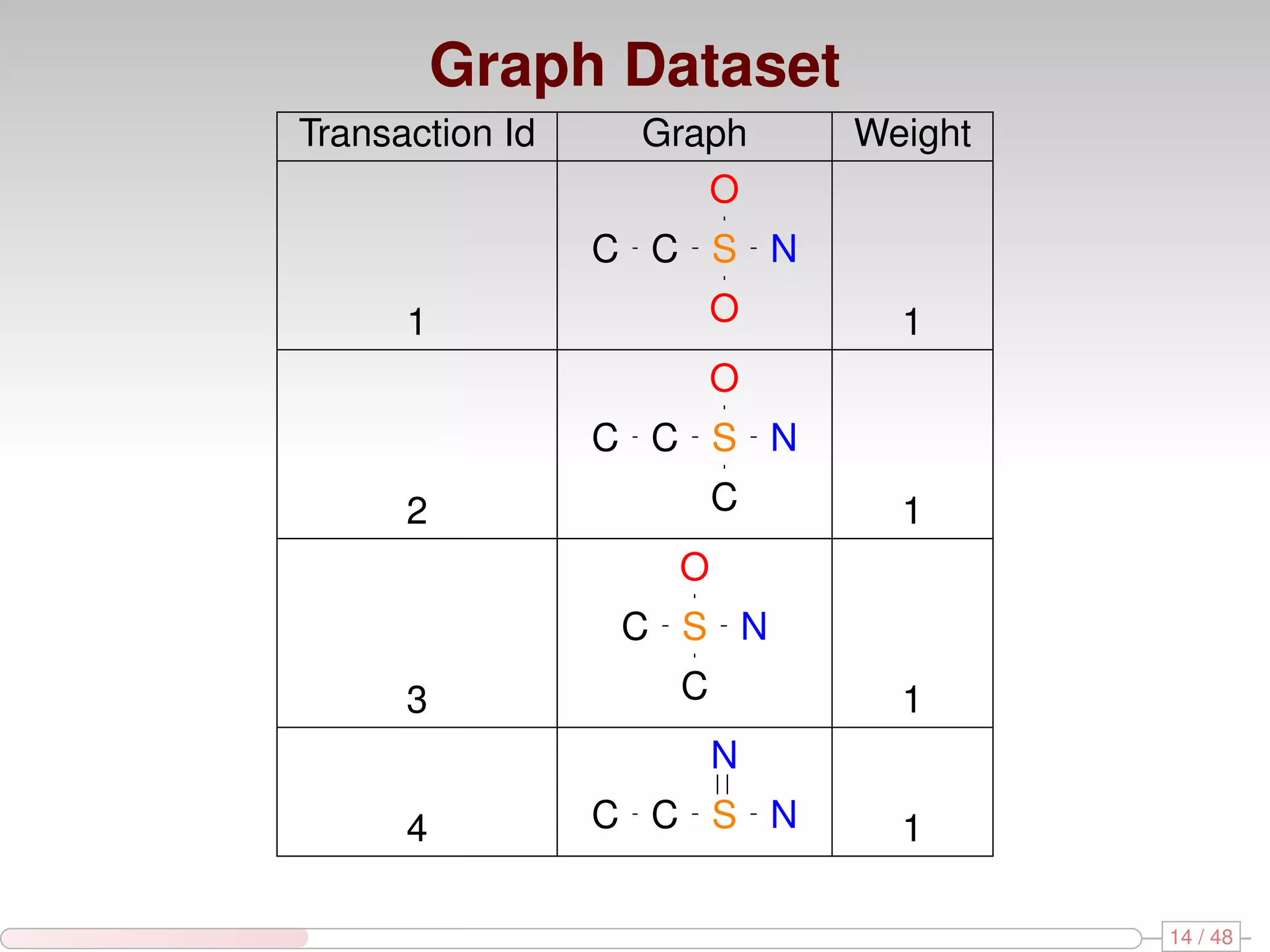
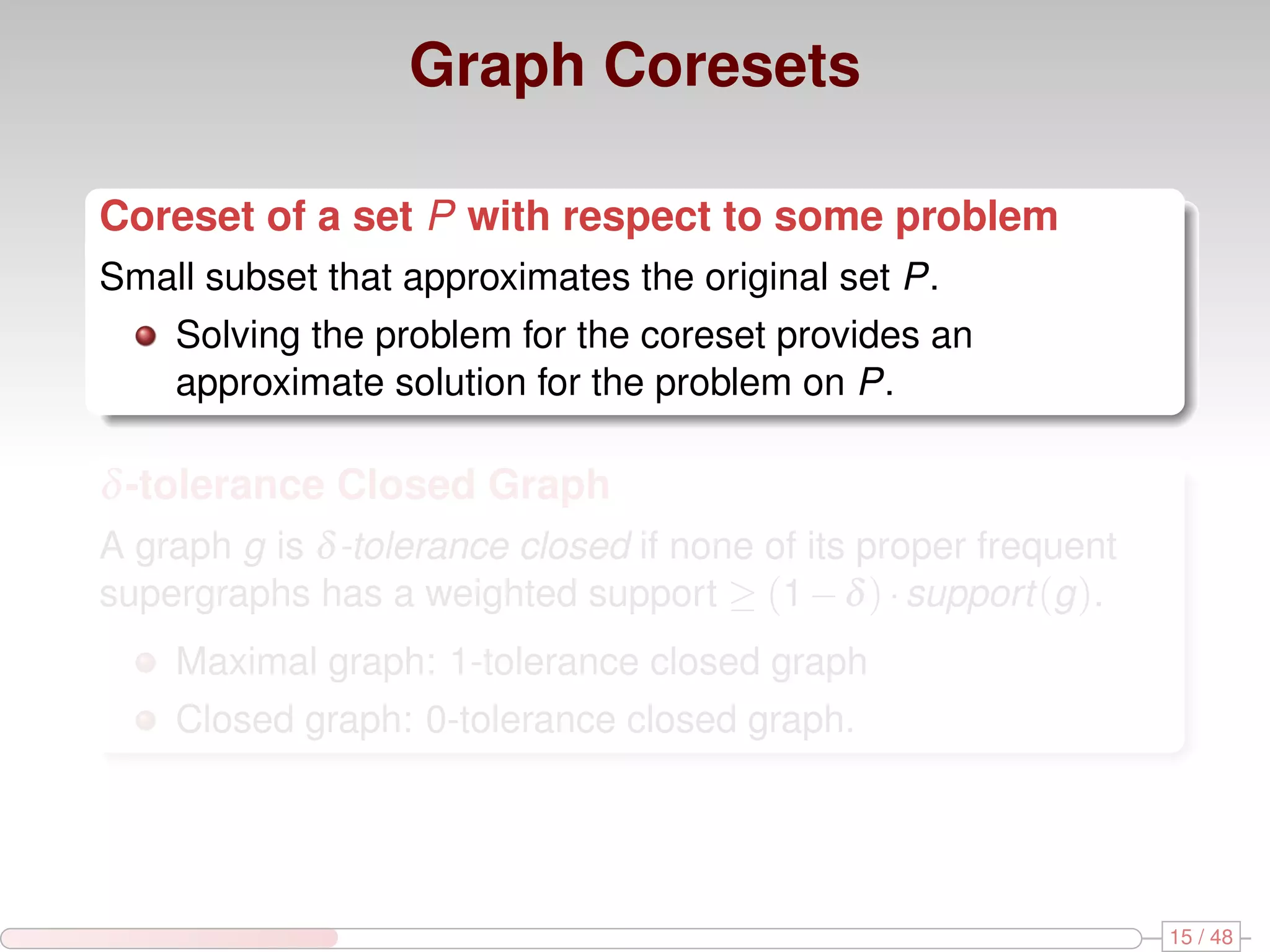

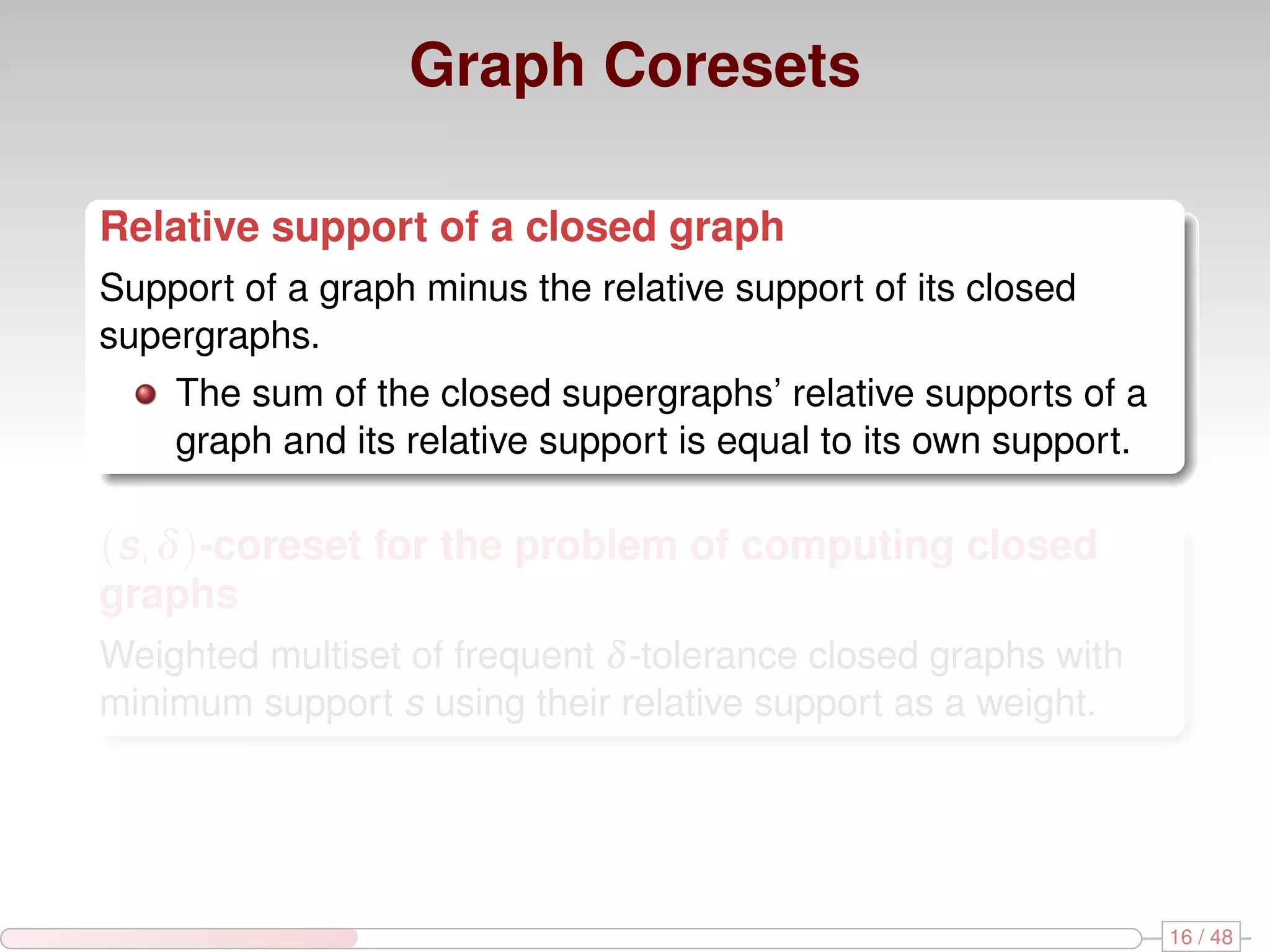

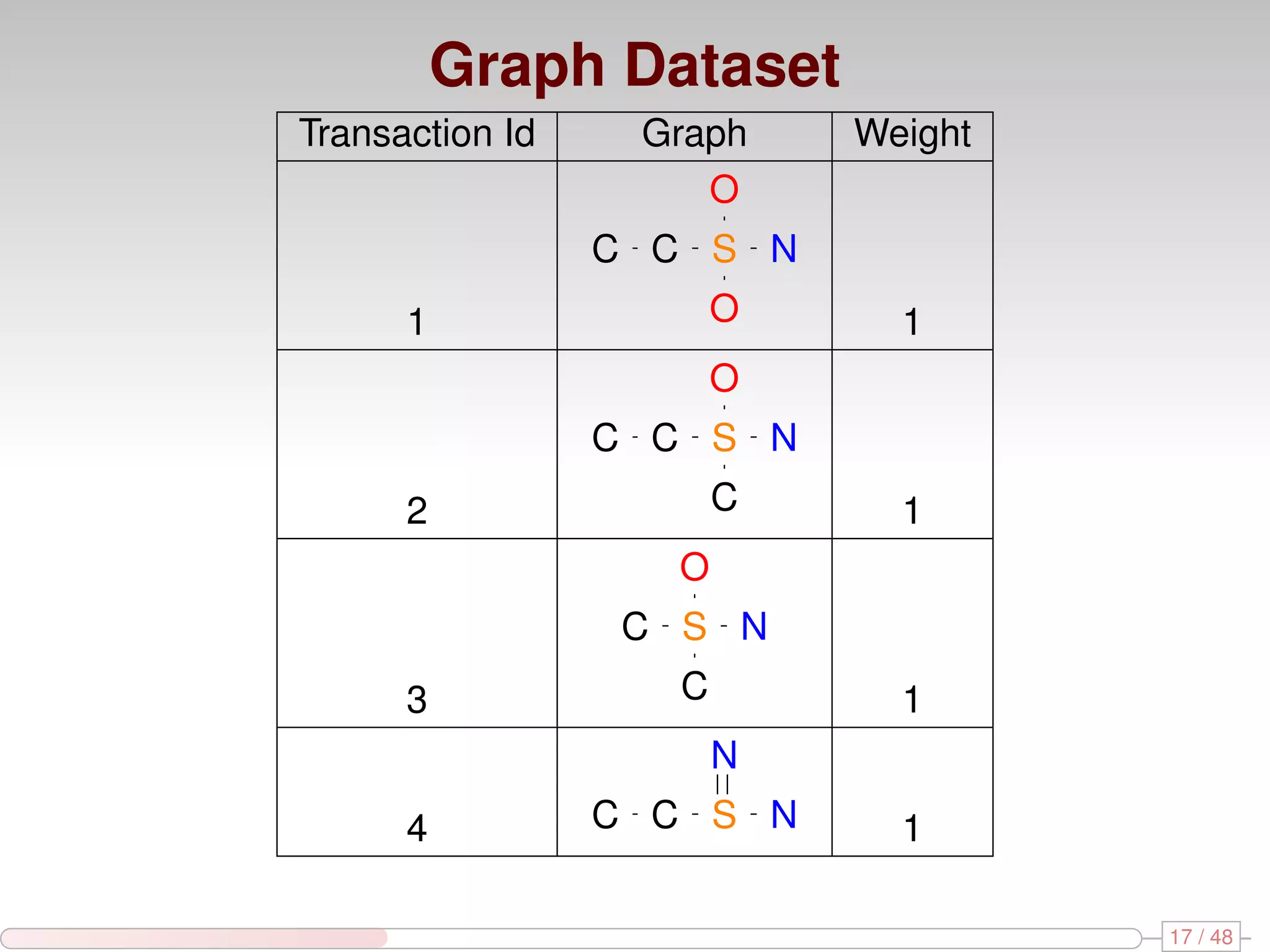

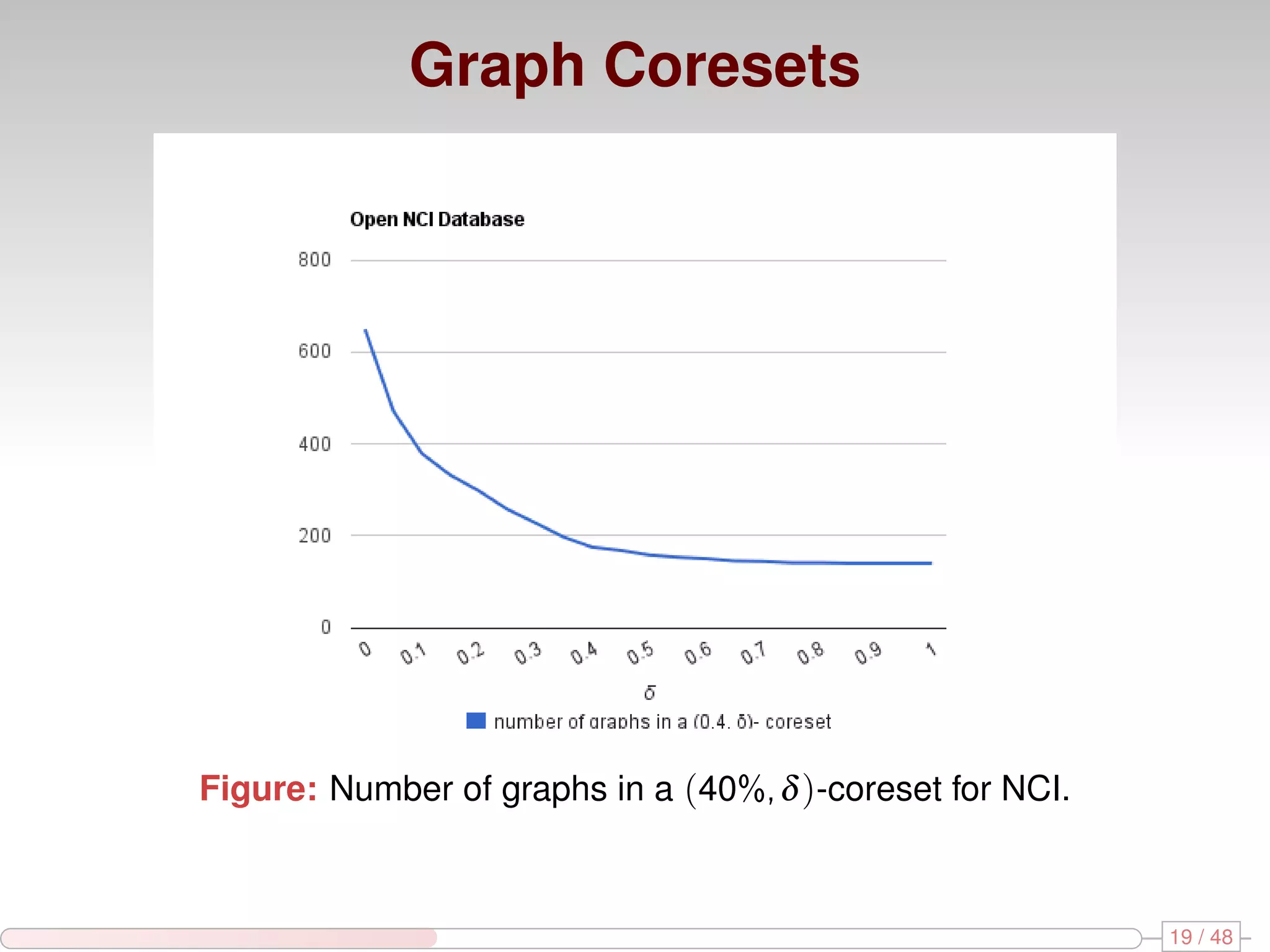



























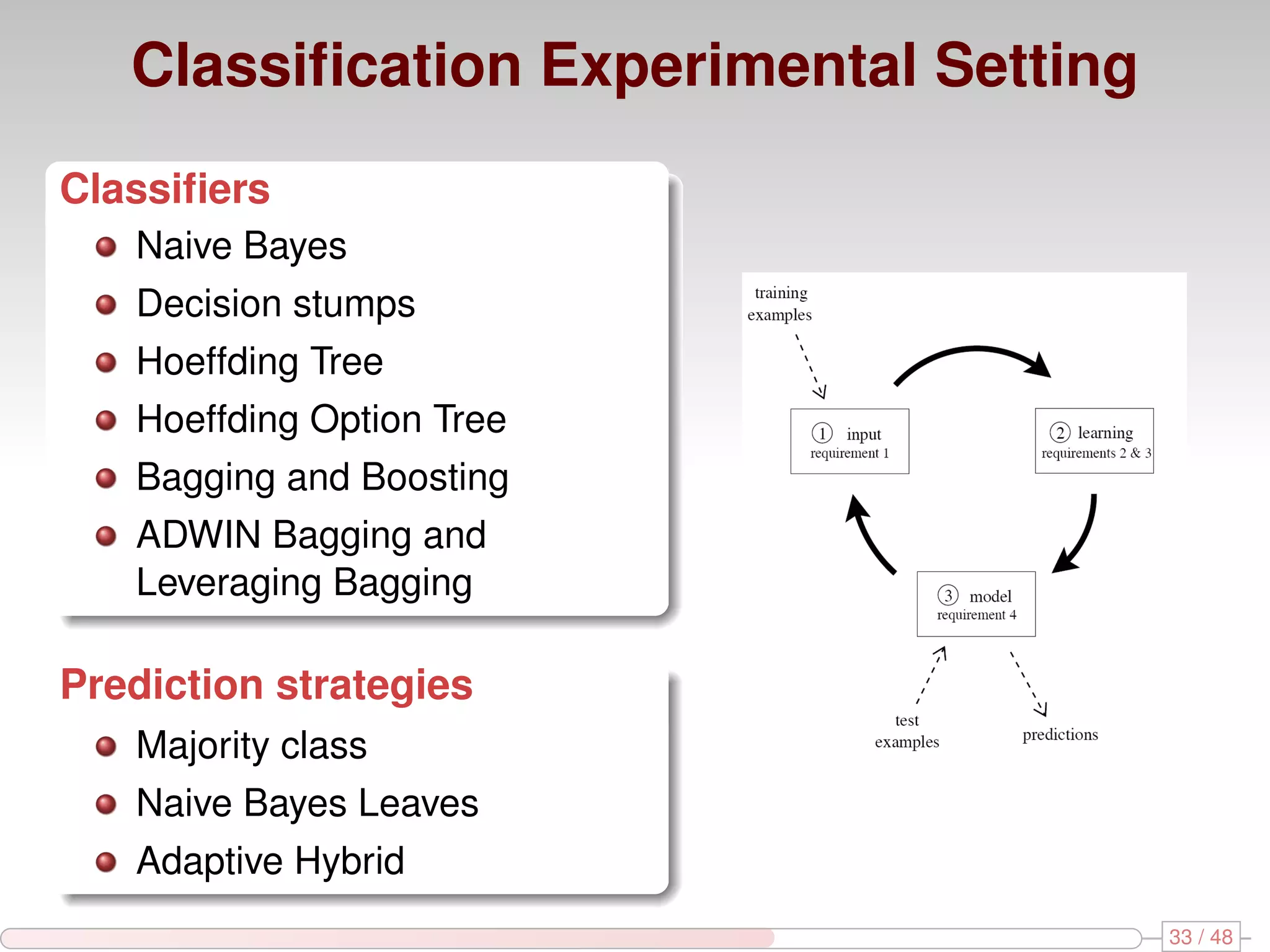
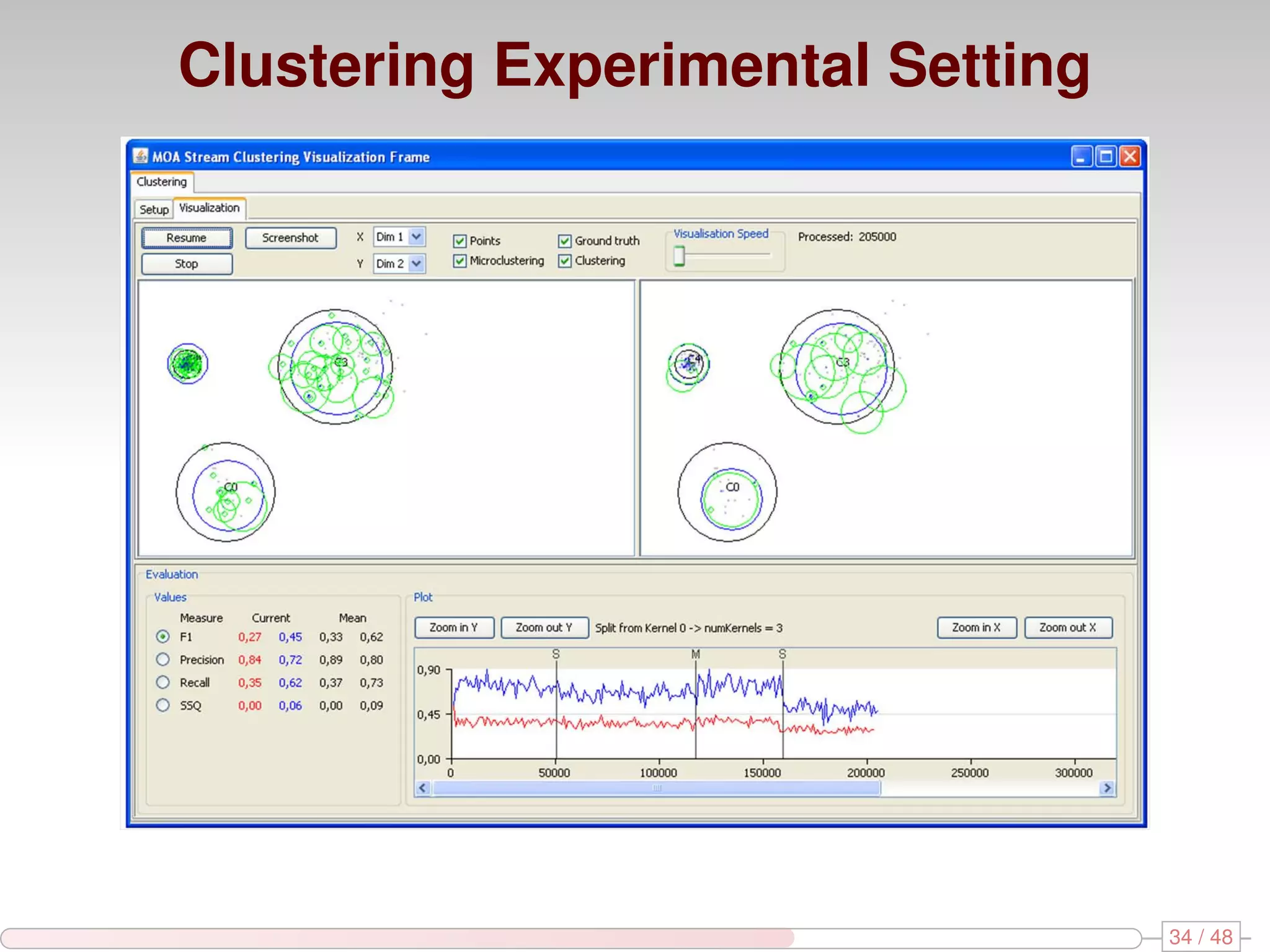
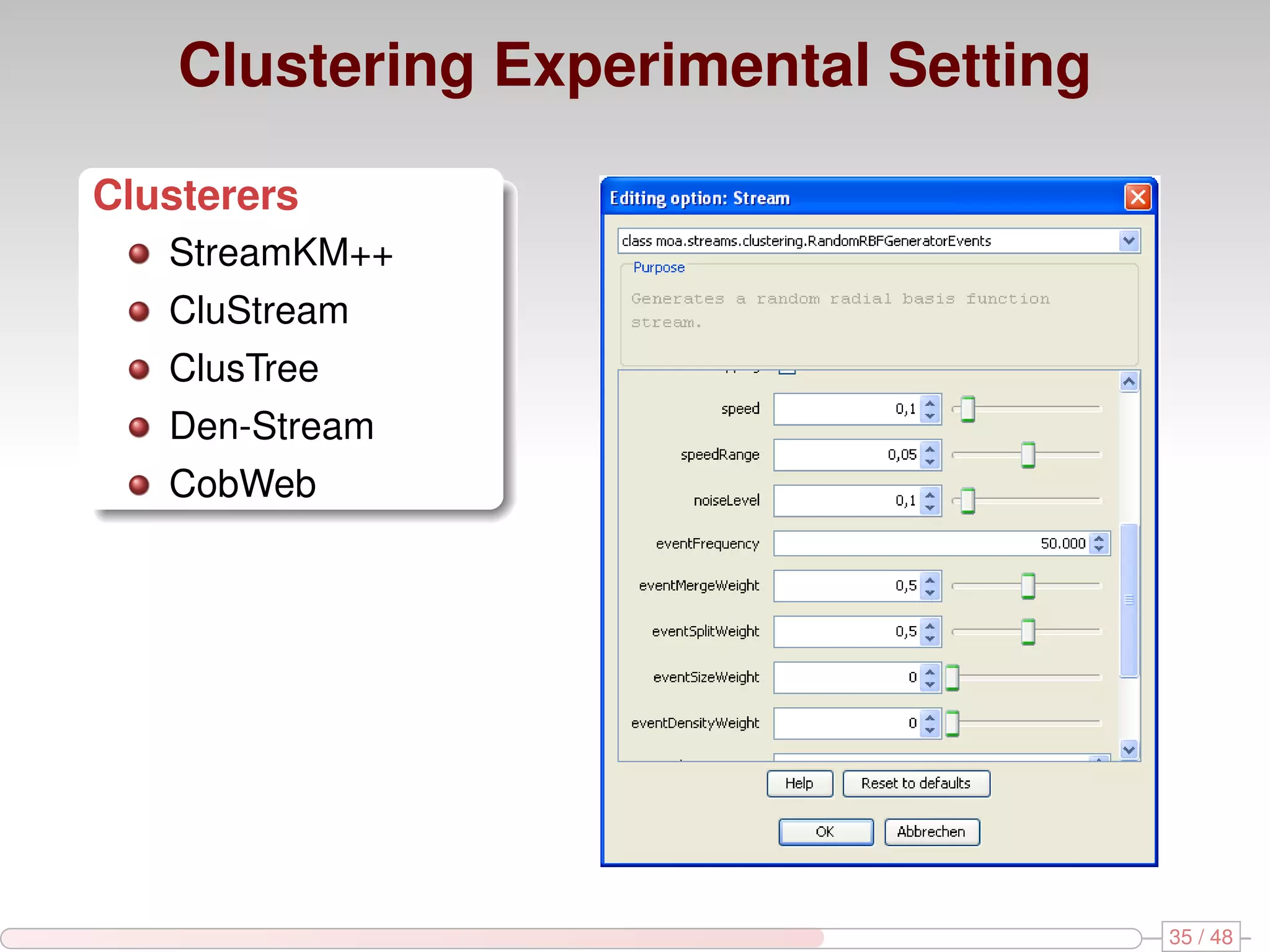
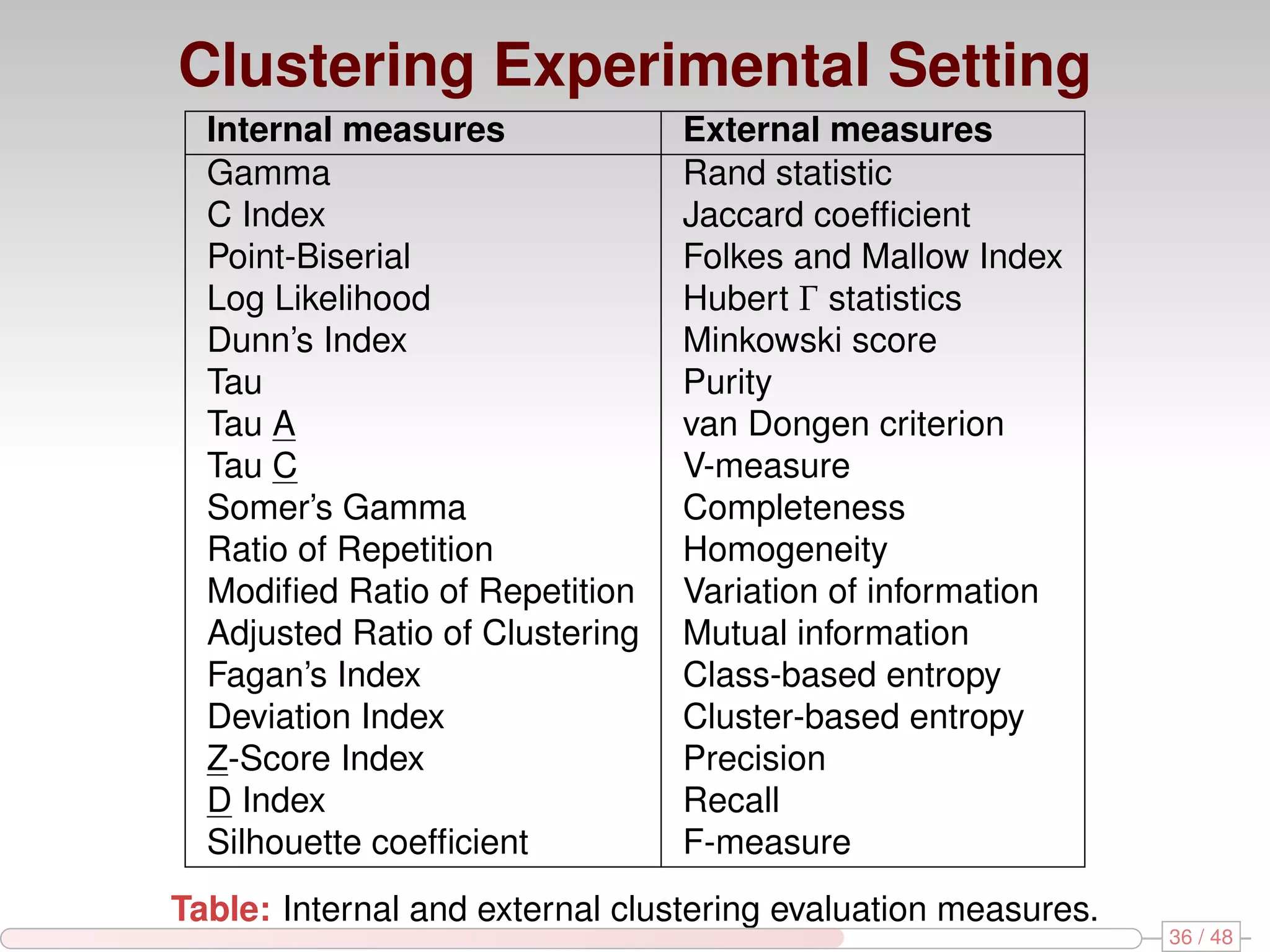


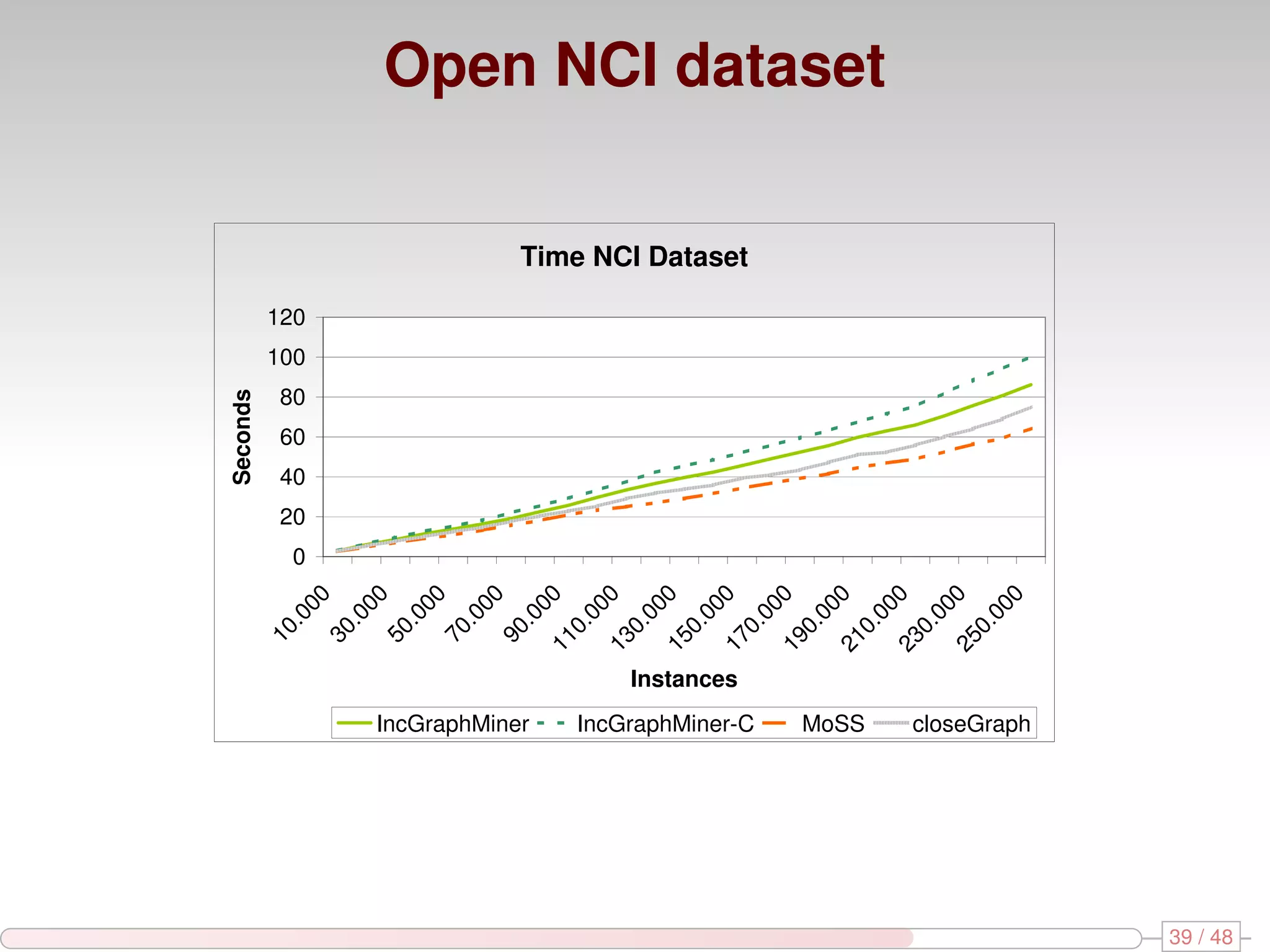
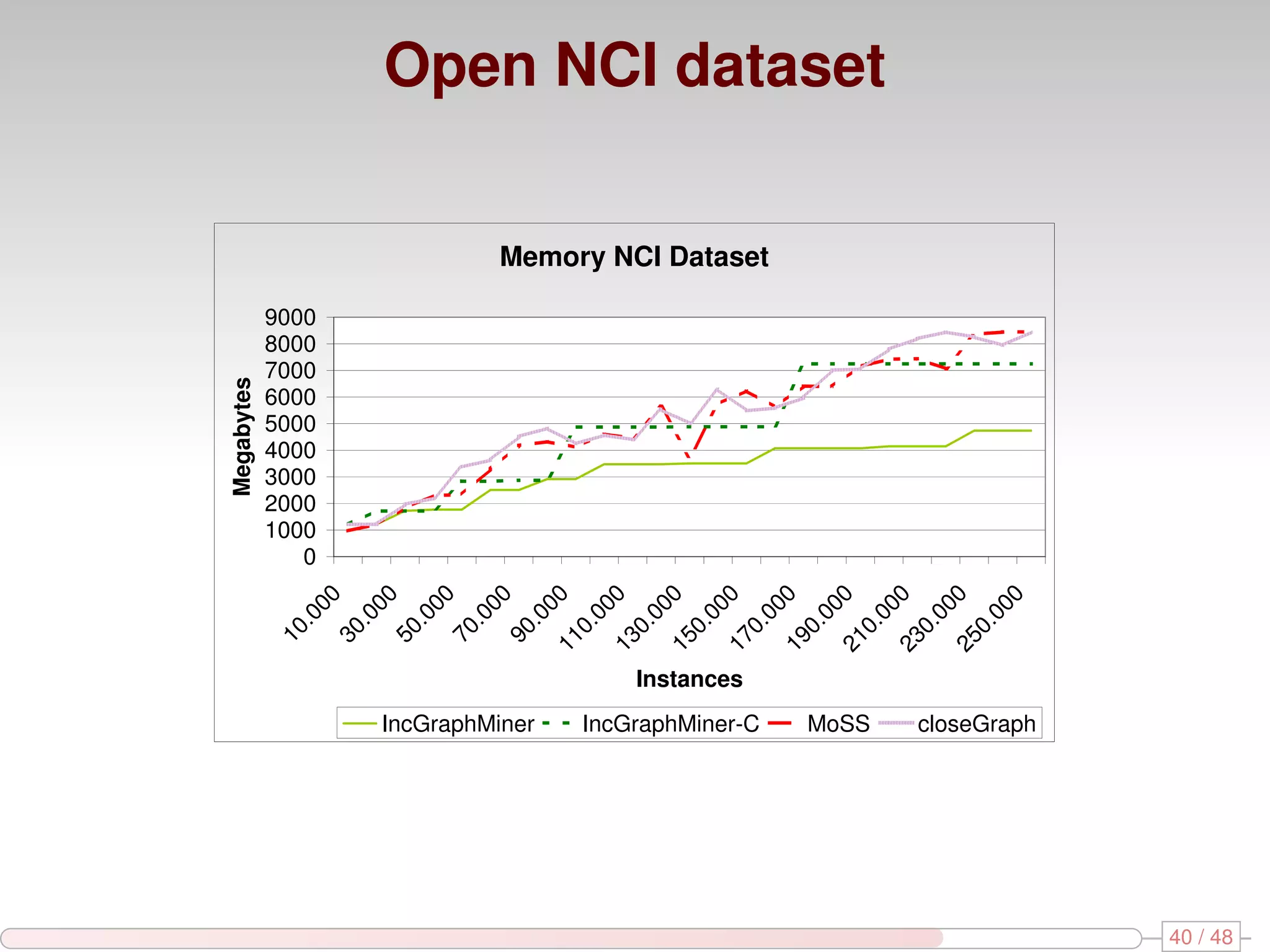
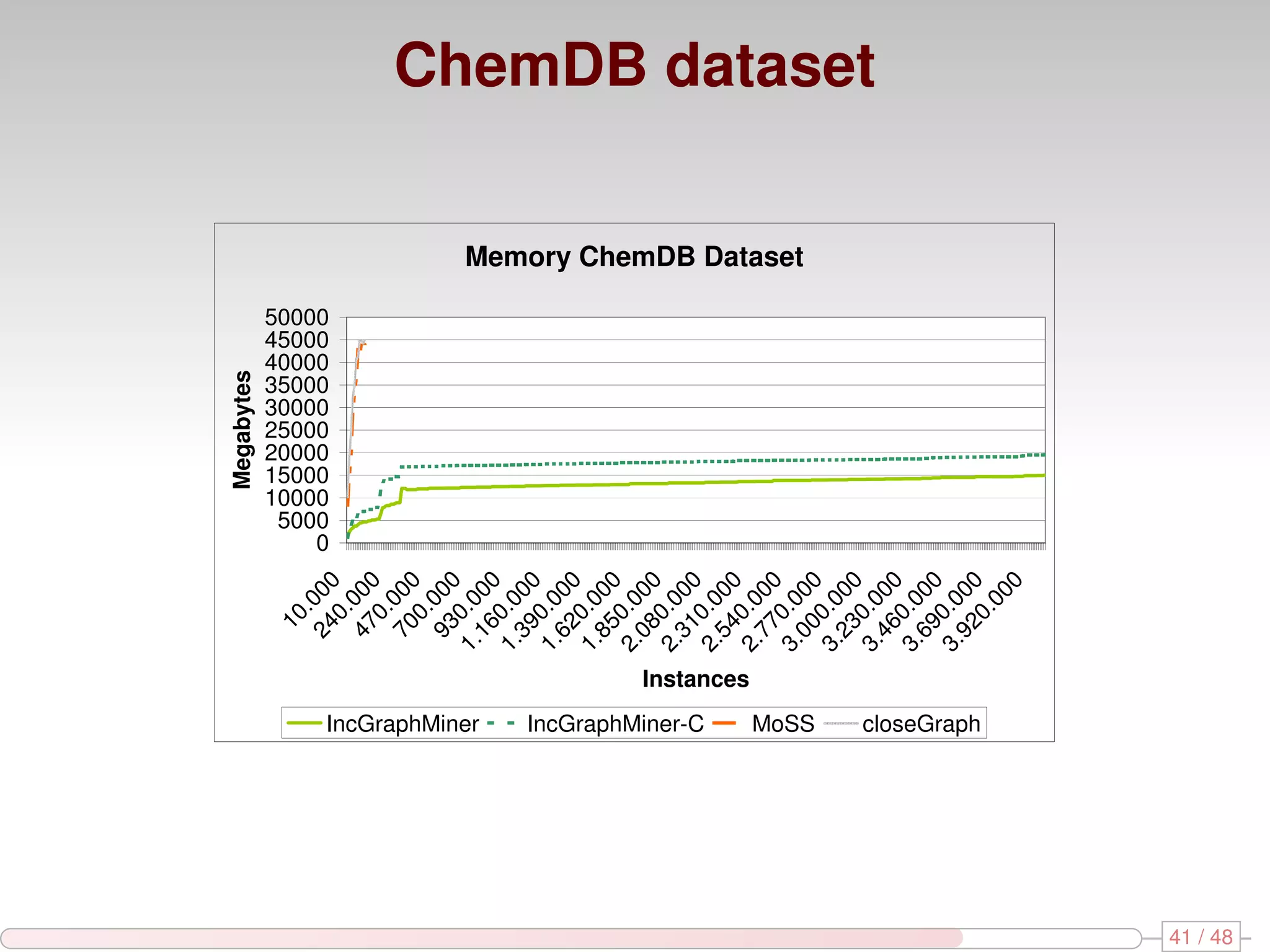
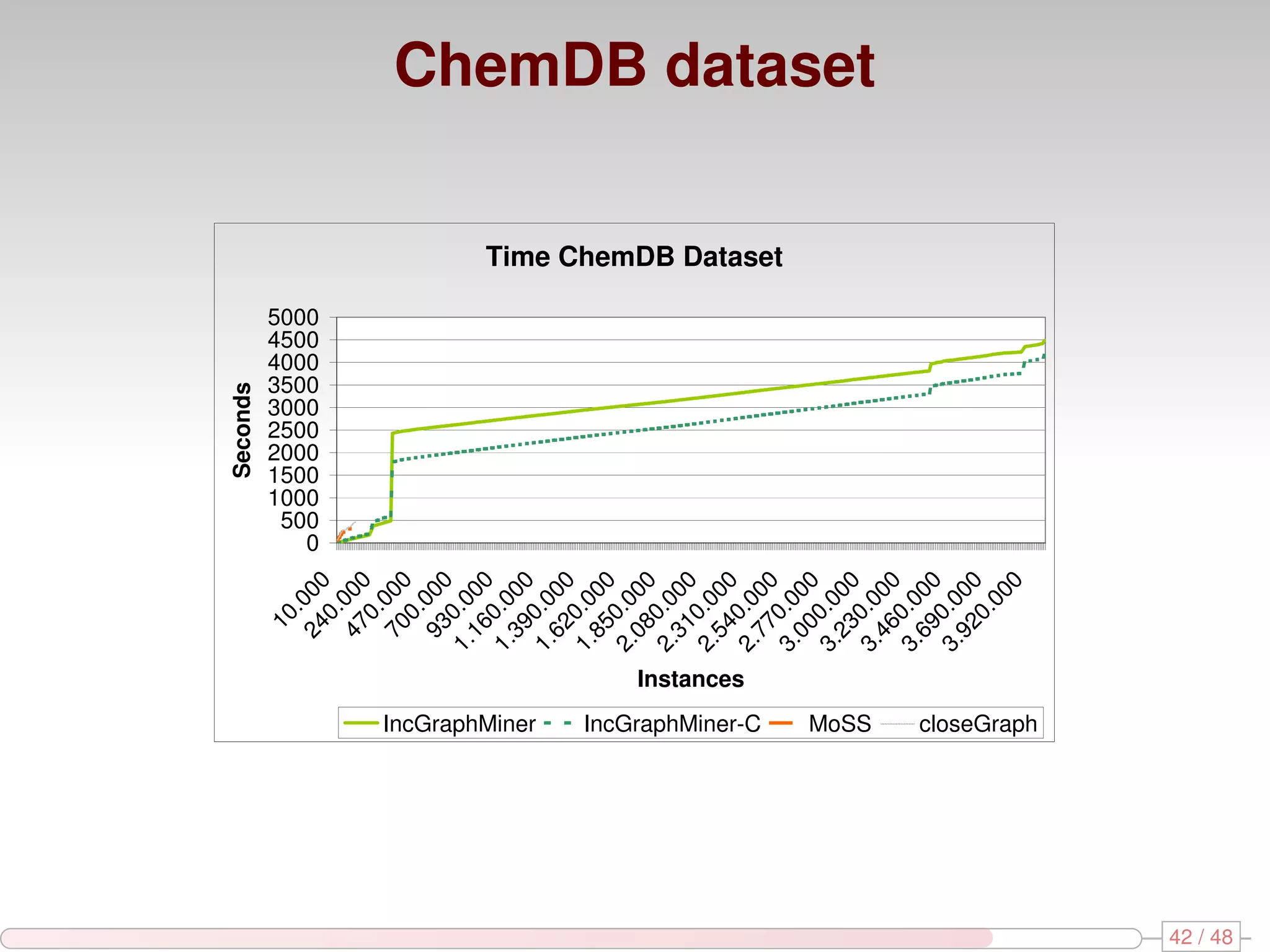
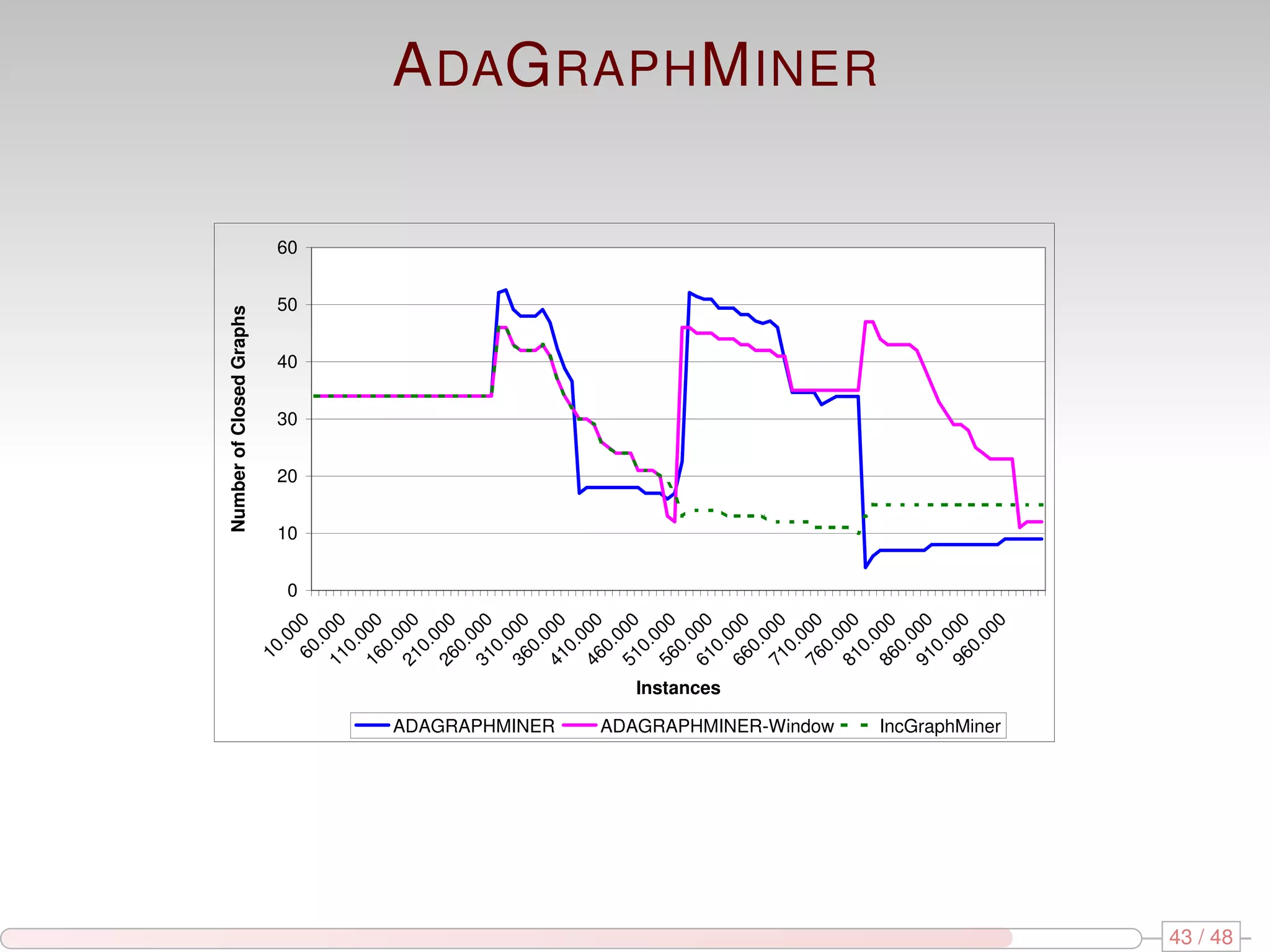






The document discusses algorithms for mining frequent closed graphs from evolving data streams, particularly focusing on incremental and non-incremental approaches. It reviews techniques such as sliding windows and adaptive algorithms for maintaining statistics over graph datasets while highlighting experimental evaluations. The research aims to improve methods for handling large and dynamic data sources in graph mining.