Download to read offline



![Alignment C++11 struct alignas(16) foo { int i; // 4 bytes int j; // 4 bytes alignas(4) char s[3]; // 3 bytes short q; // 2 bytes }; // outputs 16: std::cout << alignof(foo) << 'n';](https://image.slidesharecdn.com/simd-160715013846/75/SIMD-Processing-Using-Compiler-Intrinsics-6-2048.jpg)







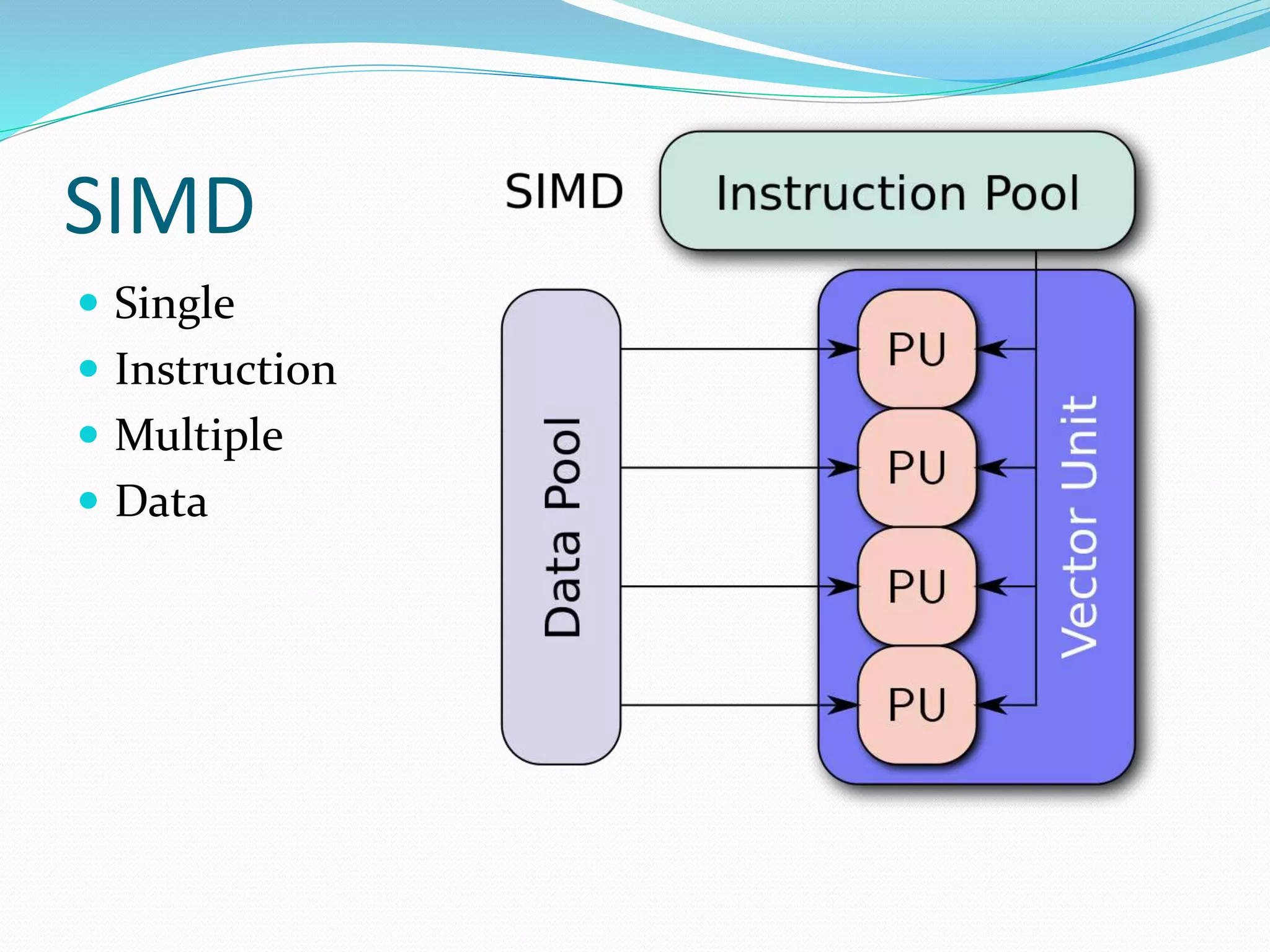
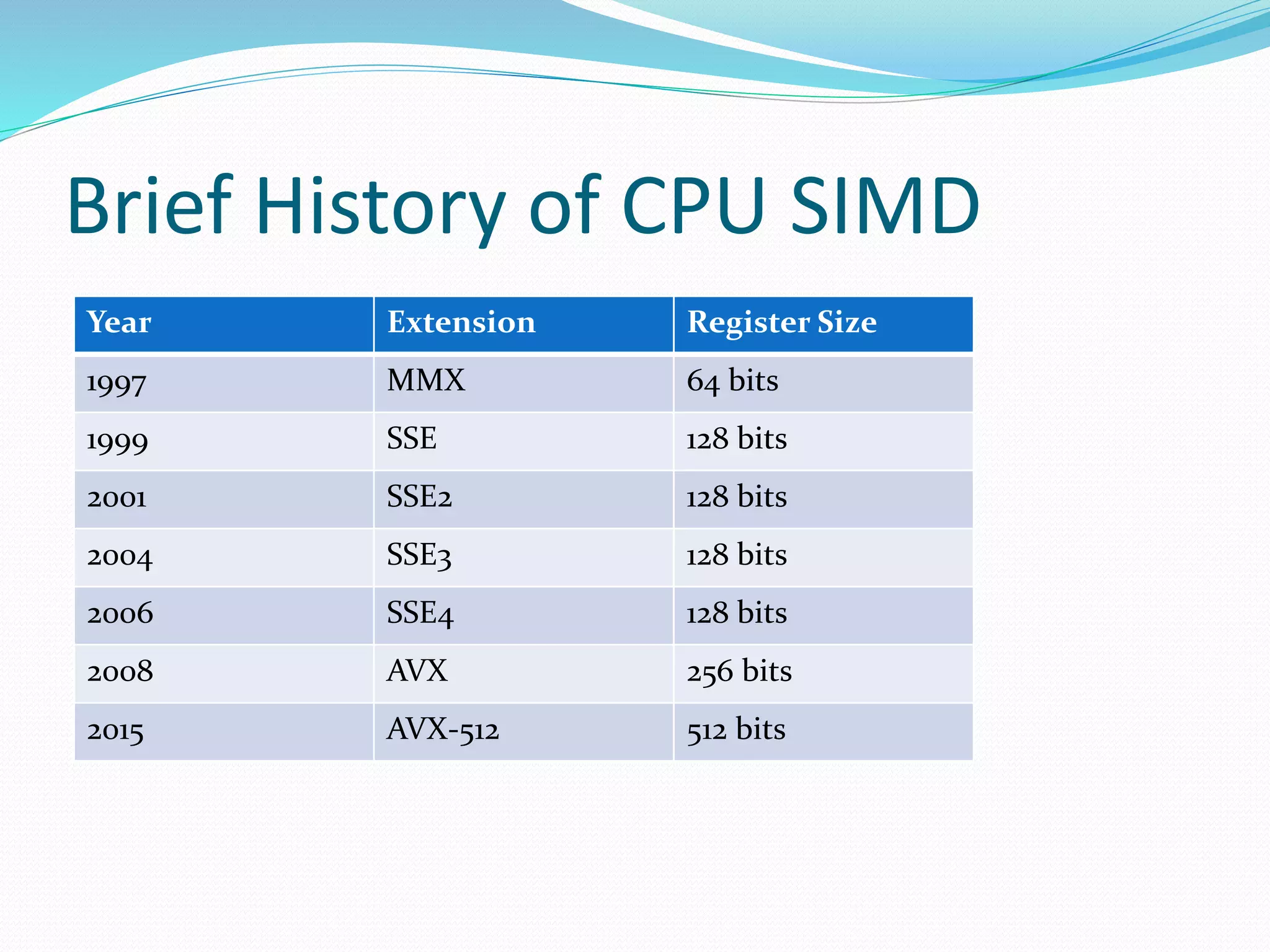
The document discusses SIMD (Single Instruction Multiple Data), which exploits data parallelism to perform the same operation on multiple data points simultaneously using SIMD instructions. It provides a brief history of CPU SIMD extensions and their register sizes. It also covers data types, alignment requirements in C++, compiler intrinsics to access SIMD instructions, and options for programming with SIMD like using intrinsics directly or libraries like Boost.Simd. It proposes an exercise to modify a Mandelbrot set program to use AVX intrinsics to perform calculations on multiple data points in parallel.