Download as PDF, PPTX










![Ingesting streams into Feast # Create feature set from a Kafka stream driver_stream_fs = FeatureSet( name="driver_stream", entities=[Entity(name="driver_id", dtype=ValueType.INT64)], features=[Feature(name="trips_today", dtype=ValueType.INT64)], source=KafkaSource(brokers="kafka:9092", topic="driver-stream-topic"), ) # Register driver stream feature set feast_client.apply(driver_stream_fs) Events on stream](https://image.slidesharecdn.com/499willempienaar-200628042753/75/Scaling-Data-and-ML-with-Apache-Spark-and-Feast-18-2048.jpg)

![Feature references and retrieval Feast ServingModel Training features = [ avg_daily_trips, conv_rate, acc_rate, trips_today, target ] Training Dataset Feast ServingModel Serving Online features < 10ms ■ Each feature is identified through a feature reference ■ Feature references allow clients to request either online or historical feature data from Feast ■ Models have a single consistent view of features in both training and serving ■ Feature references are persisted with model binaries, allowing full automation of online serving features = [ avg_daily_trips, conv_rate, acc_rate, trips_today ]](https://image.slidesharecdn.com/499willempienaar-200628042753/75/Scaling-Data-and-ML-with-Apache-Spark-and-Feast-21-2048.jpg)
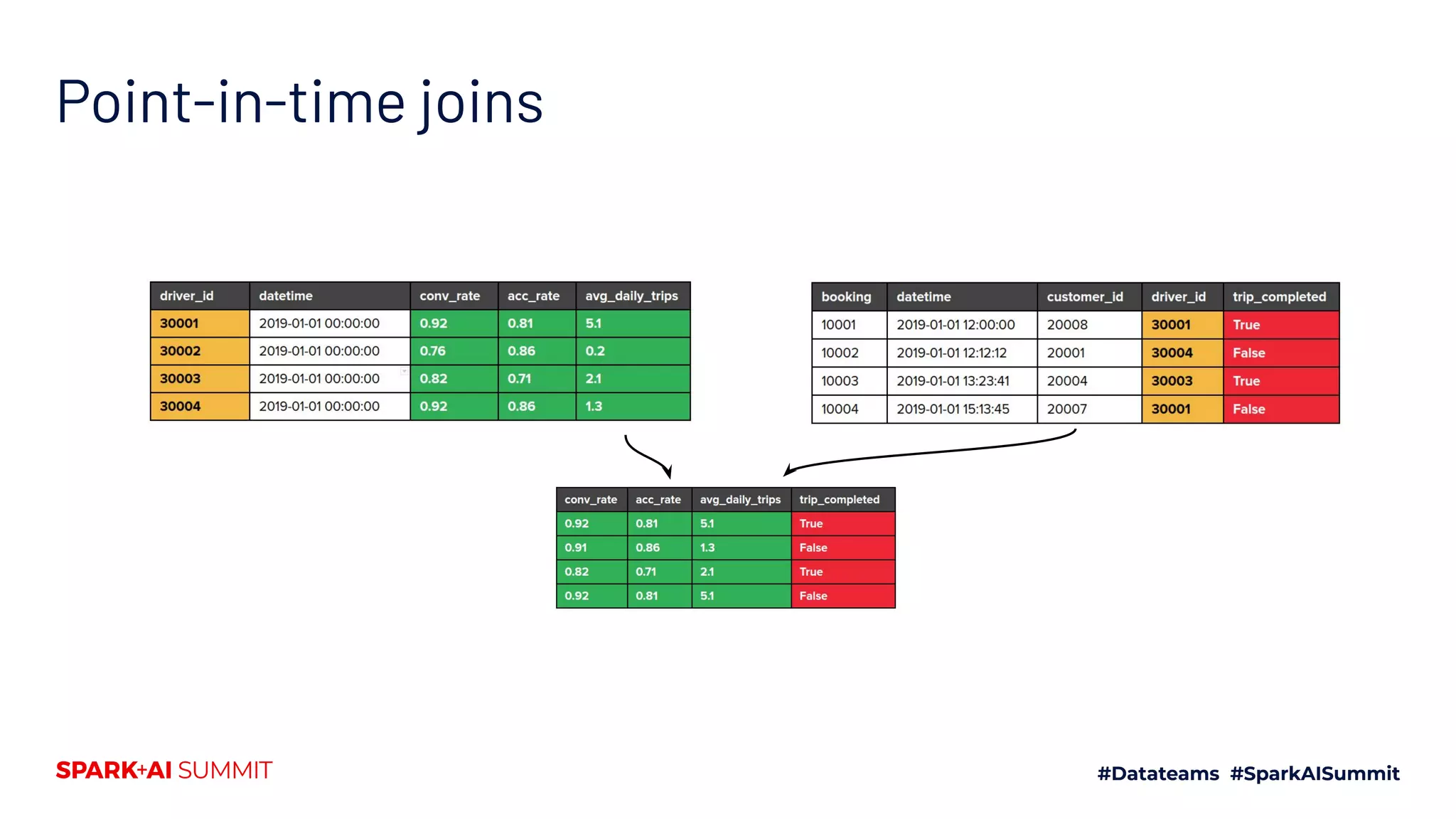
![Getting features for model training features = [ "acc_rate", "conv_rate", "avg_daily_trips", "trips_today", ] # Fetch historical data historic_features = client.get_batch_features( entity_rows=drivers, feature_ids=features ).to_dataframe() # Train model my_model = ml_framework.fit(historic_features) Batch data Stream Target](https://image.slidesharecdn.com/499willempienaar-200628042753/75/Scaling-Data-and-ML-with-Apache-Spark-and-Feast-25-2048.jpg)
![Getting features during online serving features = [ "acc_rate", "conv_rate", "avg_daily_trips", "trips_today", ] # Fetch online features online_features = client.get_online_features( entity_rows=drivers, feature_ids=features ) # Train model result = trip_comp_model.predict(online_features)](https://image.slidesharecdn.com/499willempienaar-200628042753/75/Scaling-Data-and-ML-with-Apache-Spark-and-Feast-26-2048.jpg)










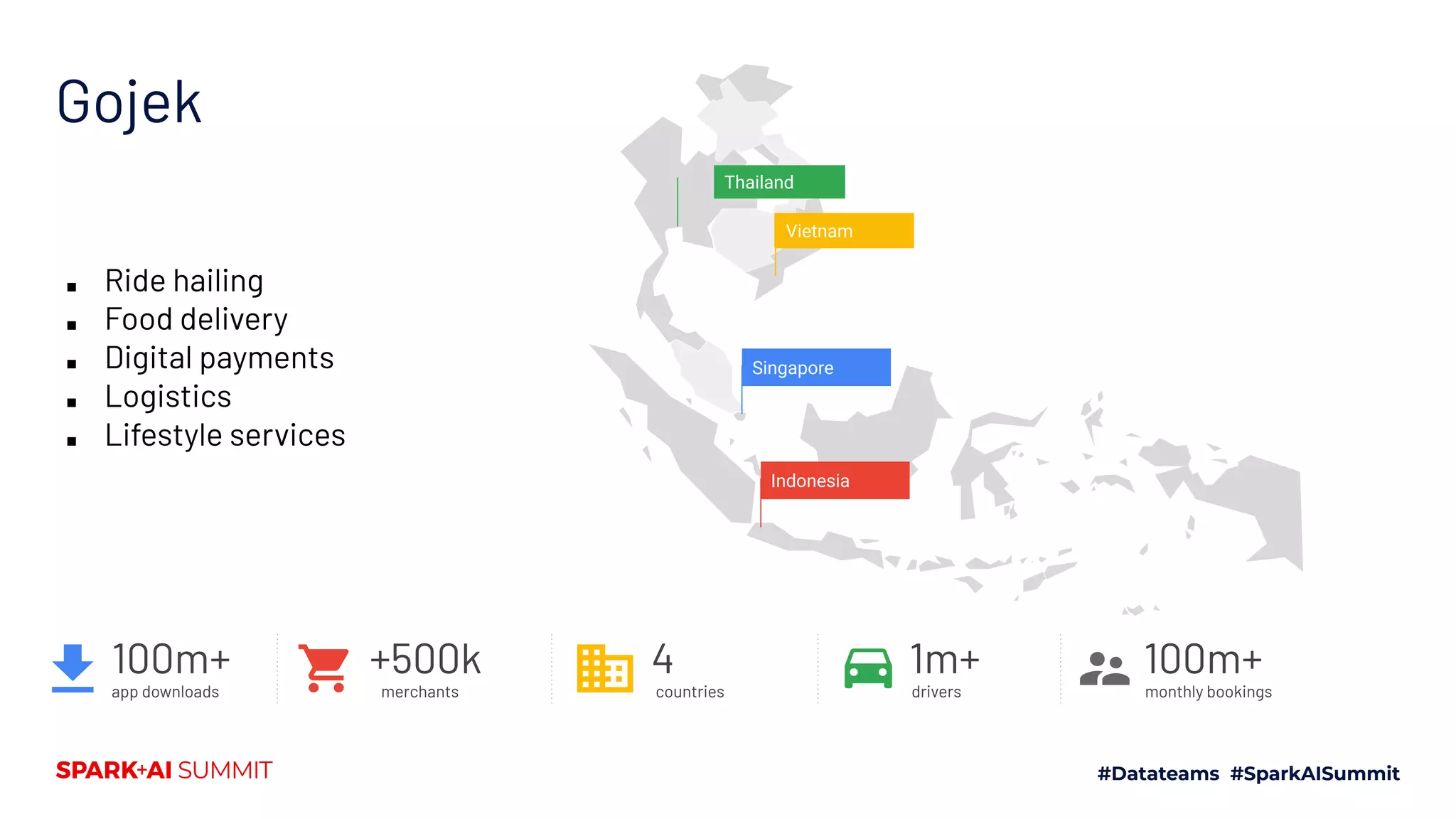
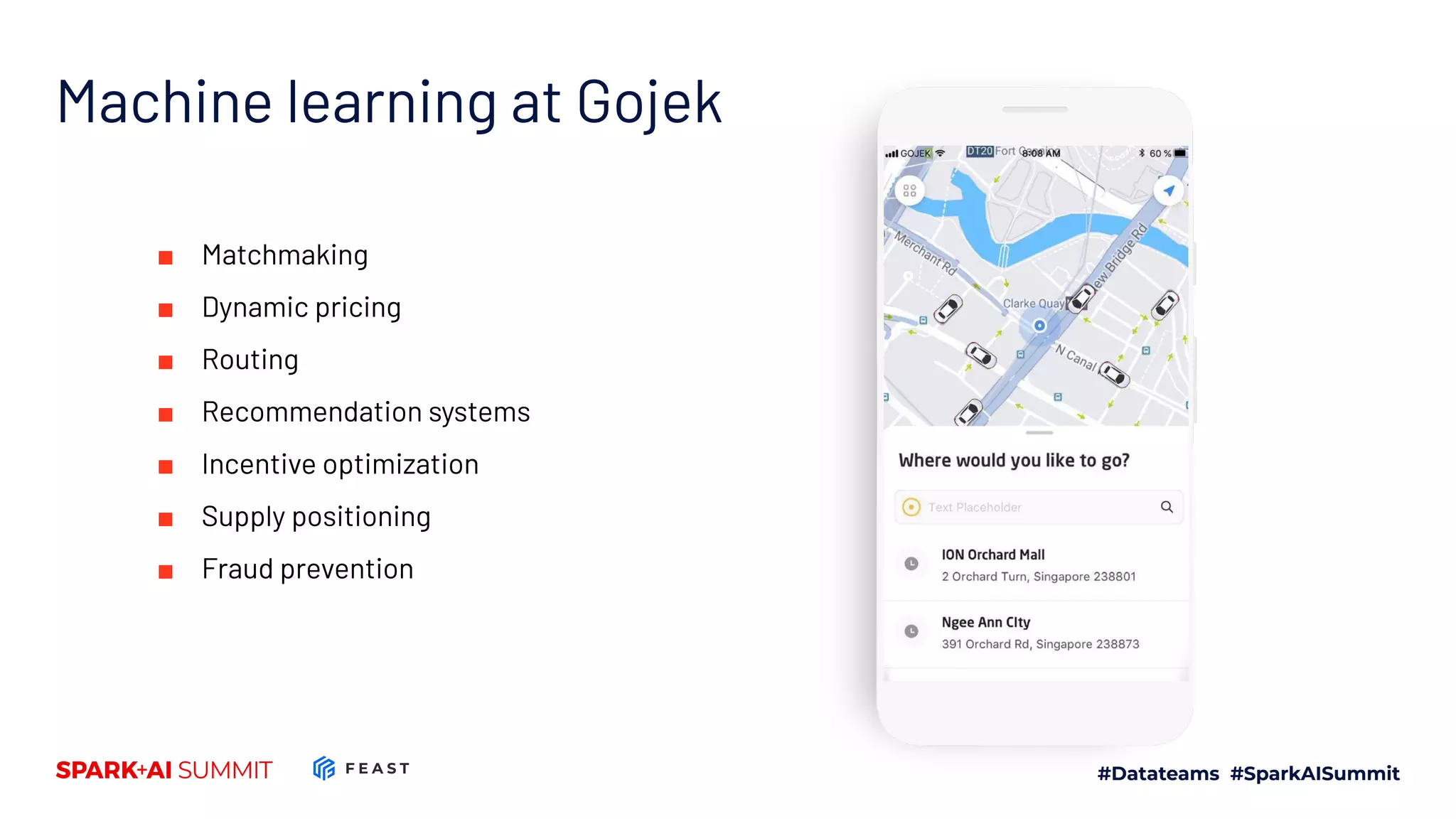
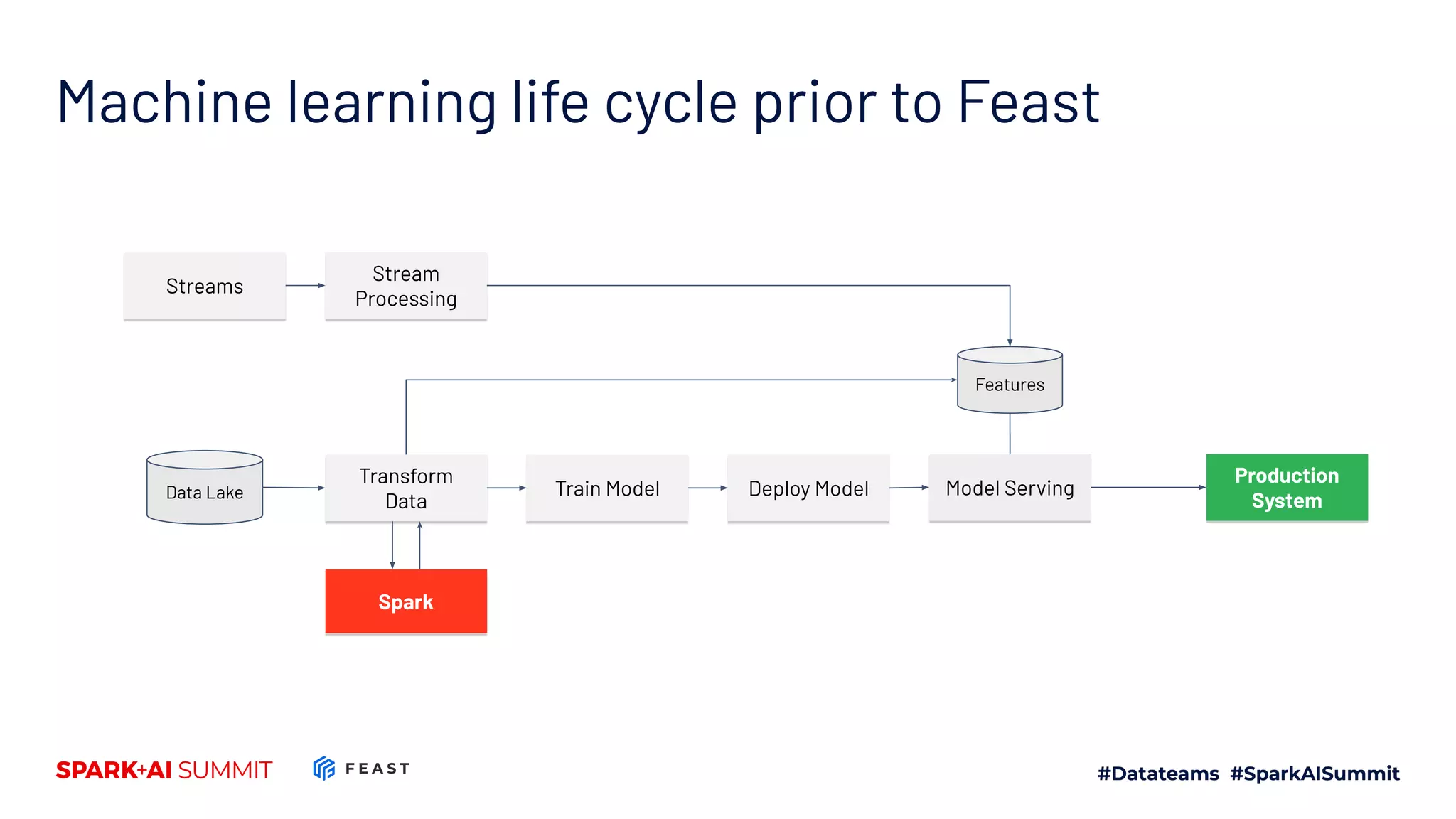
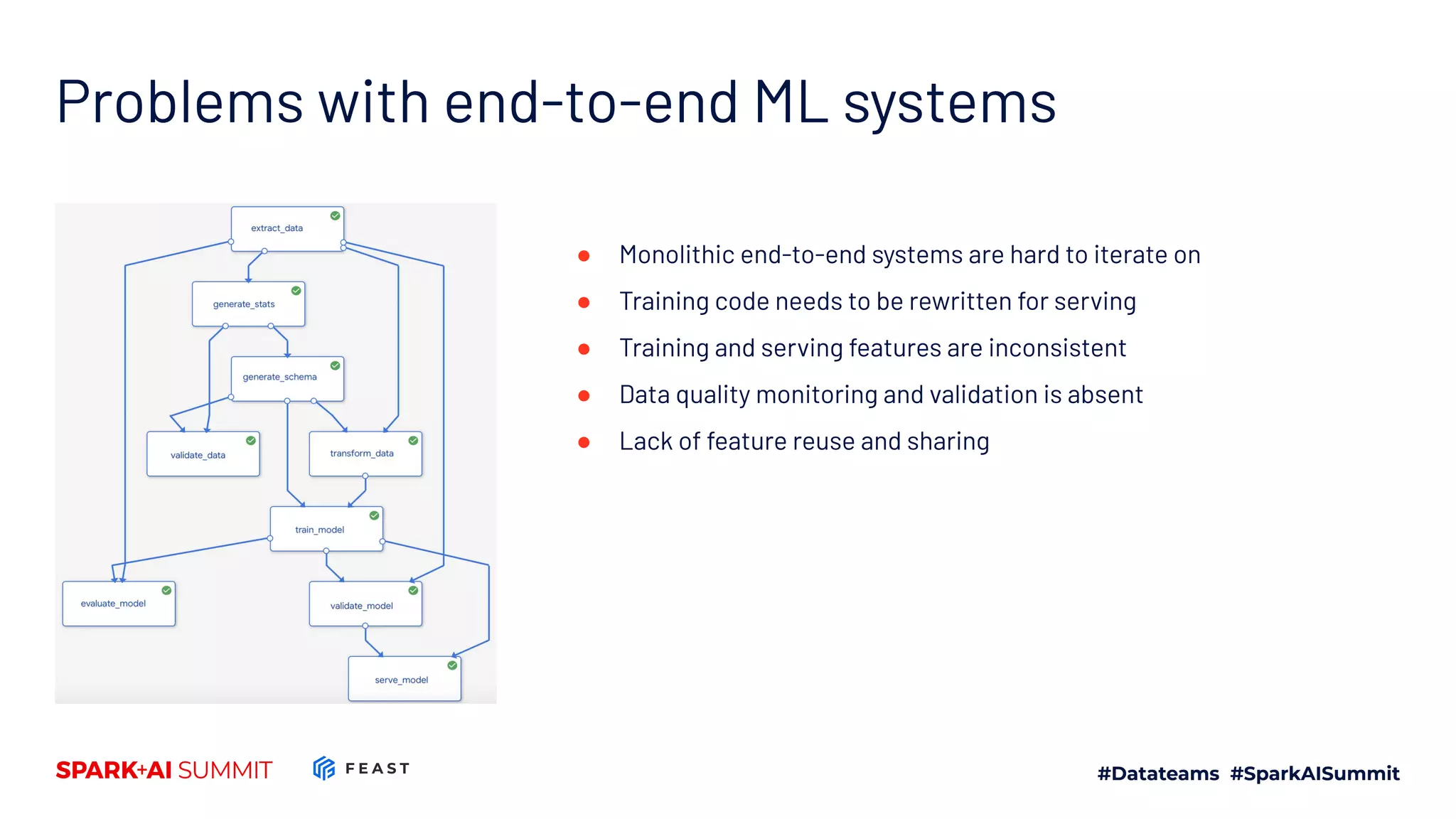
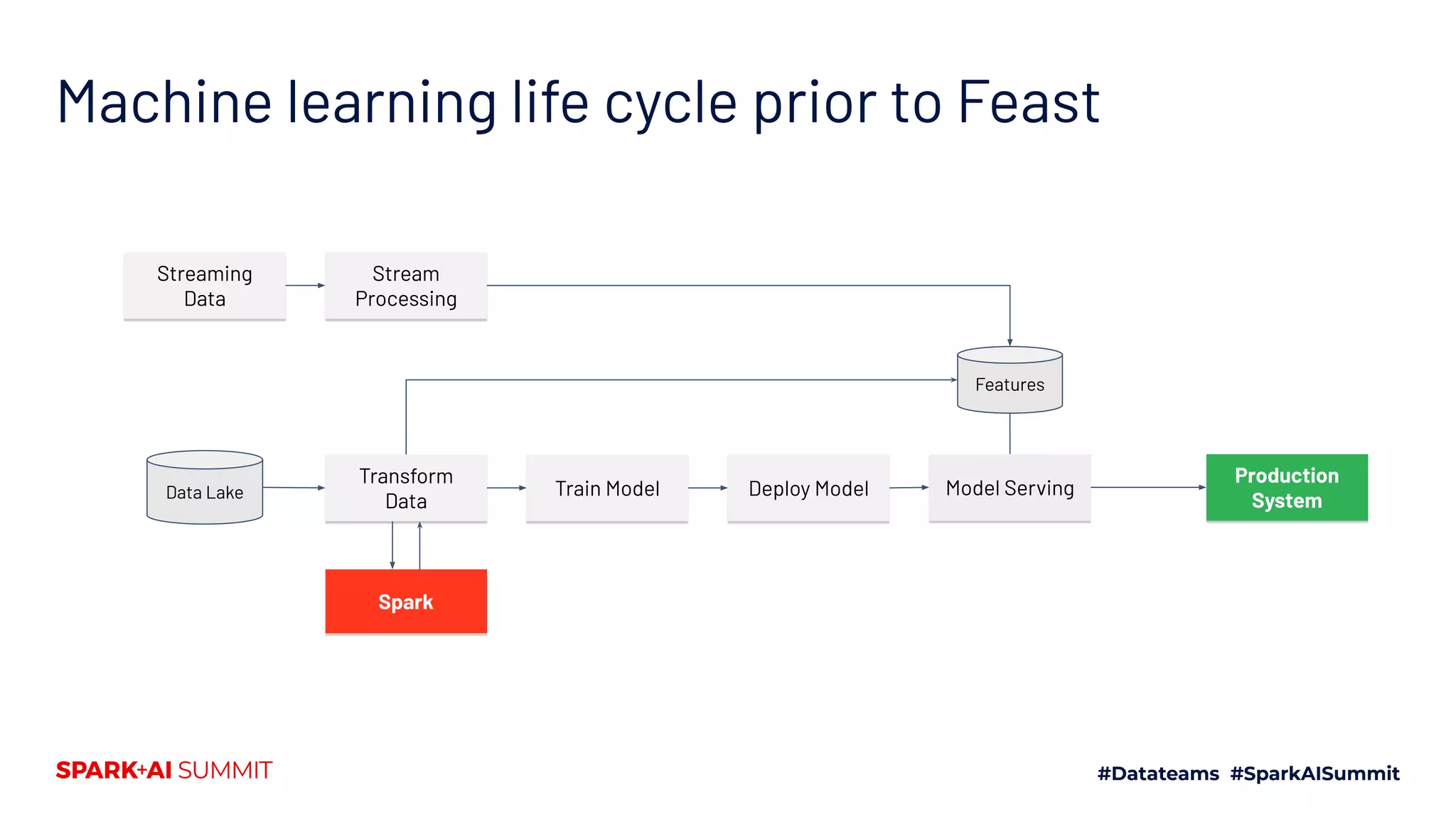
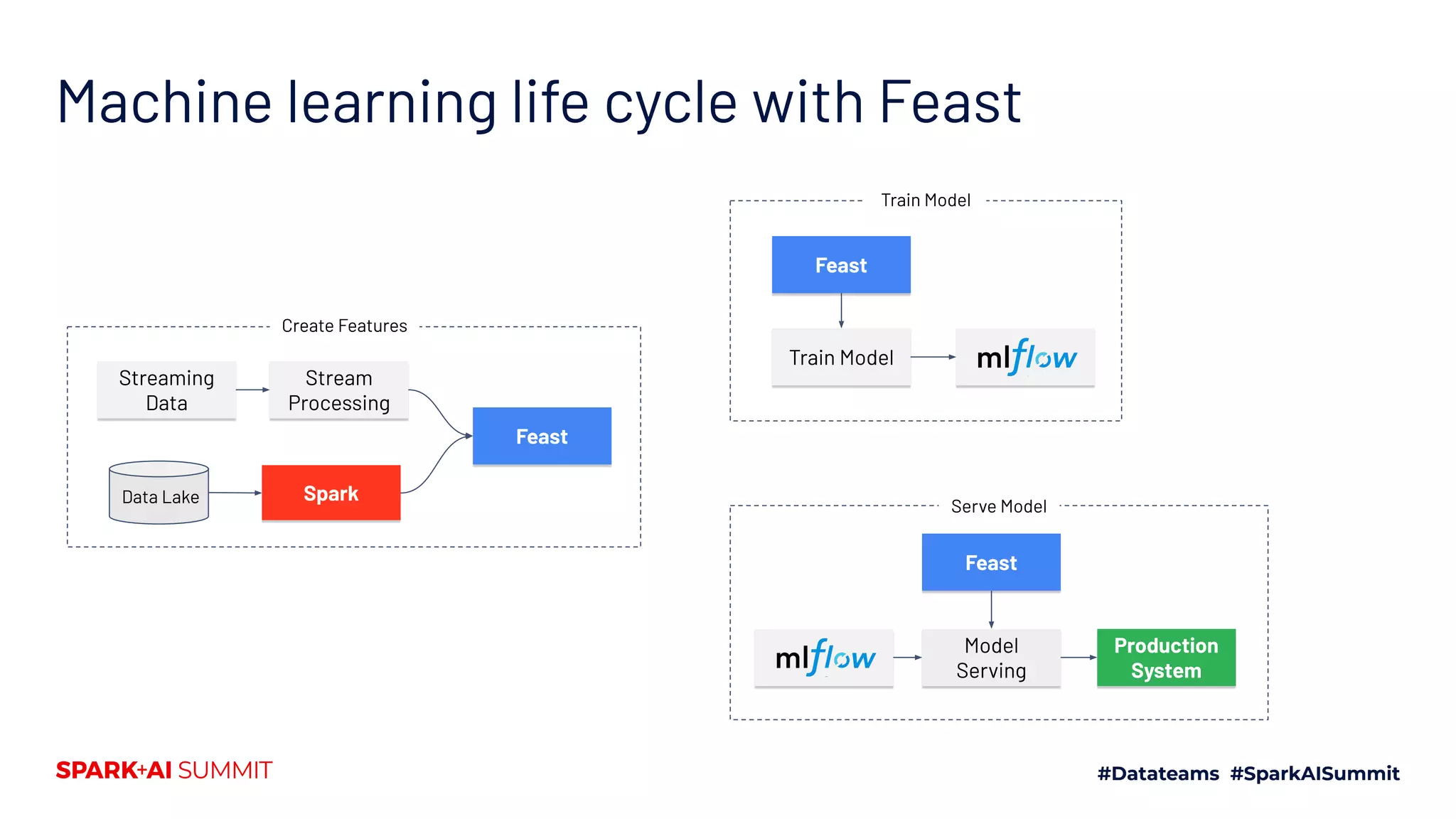
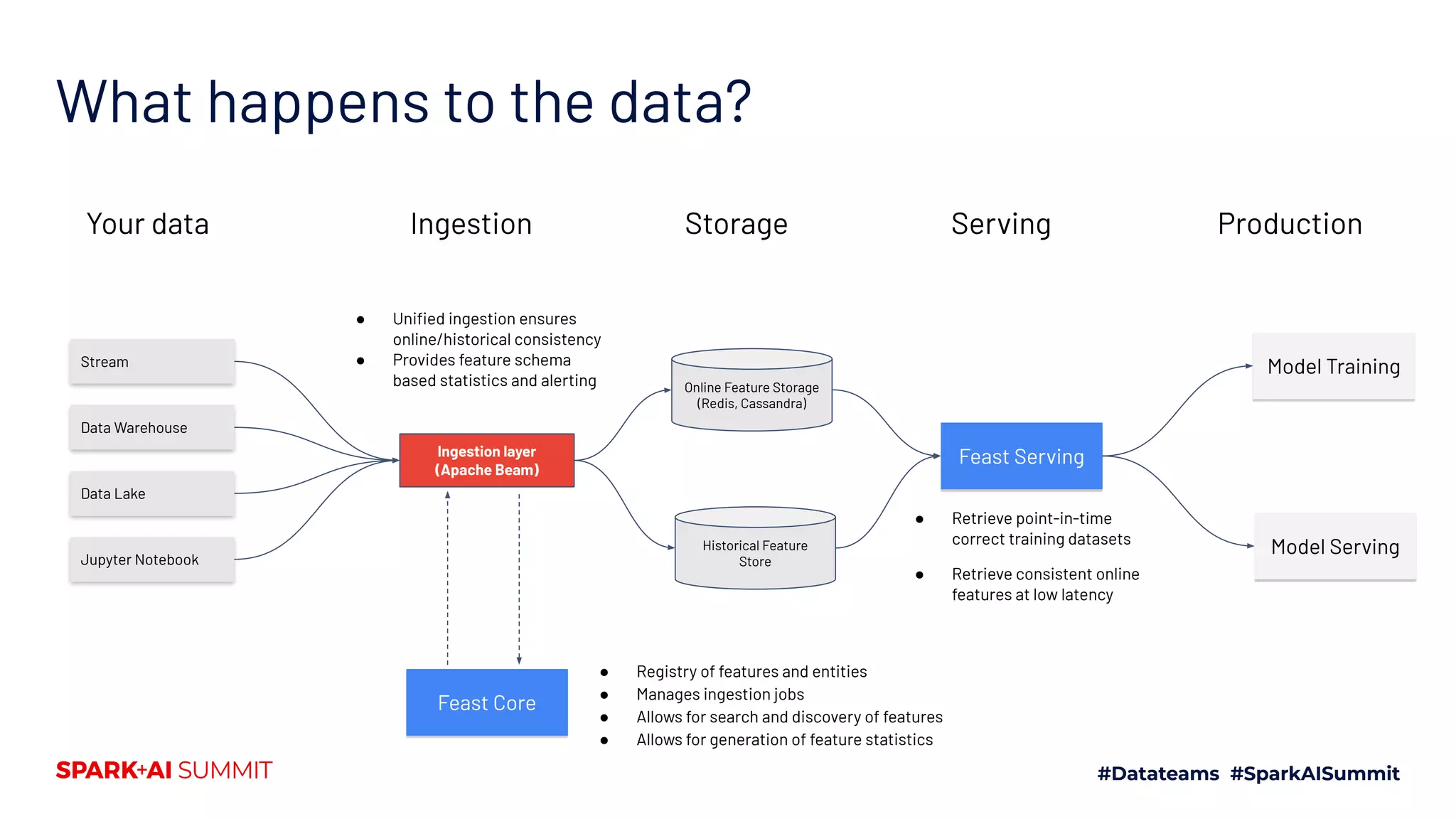
The document discusses the challenges in productionizing machine learning and introduces Feast, an open-source feature store developed by Gojek and Google Cloud. It outlines Feast's capabilities in managing data ingestion, storage, and feature serving, ensuring consistency between training and serving phases while improving model performance. The document also highlights the importance of feature validation and monitoring, as well as the future roadmap for Feast's development.