Downloaded 50 times






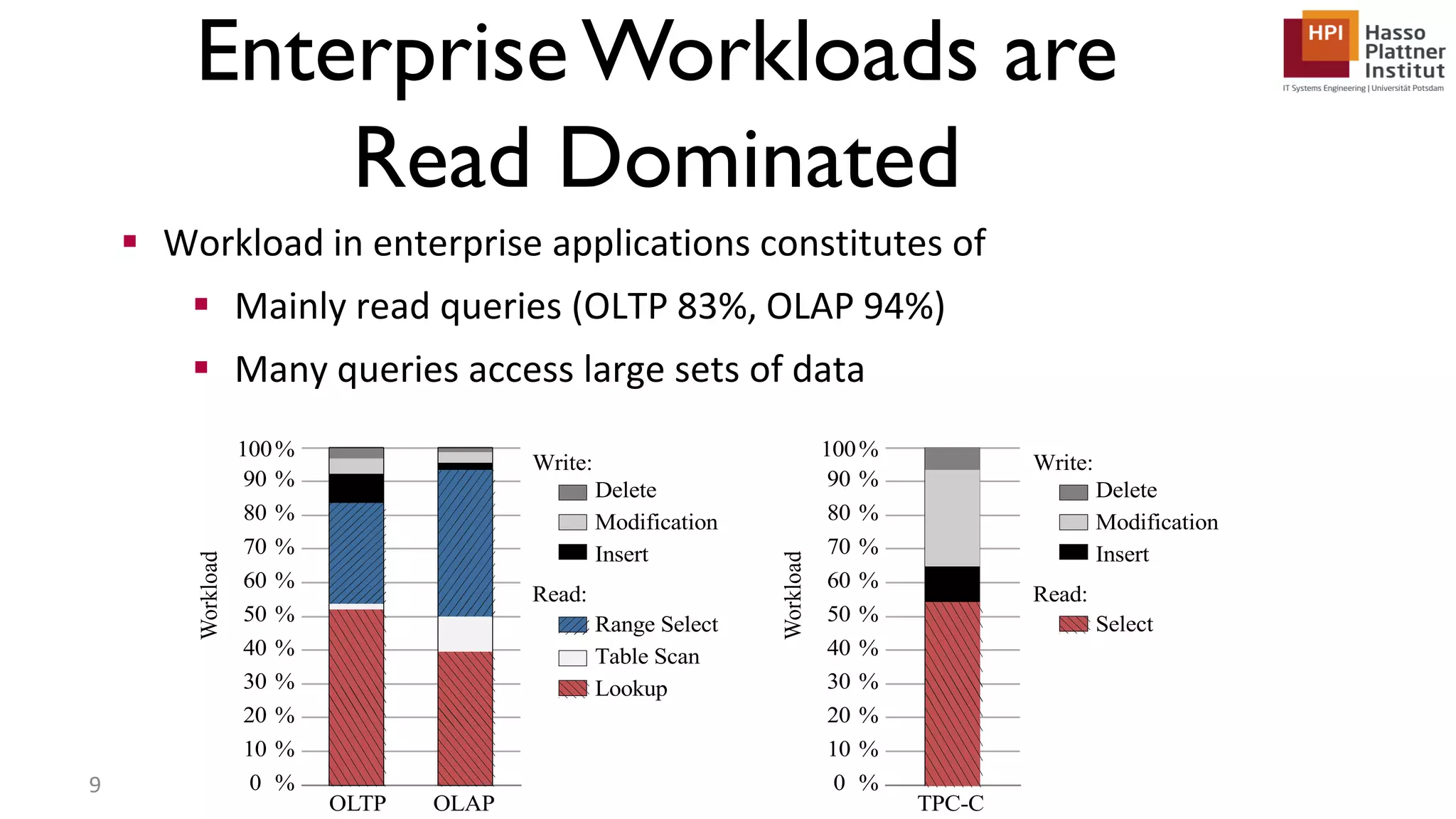
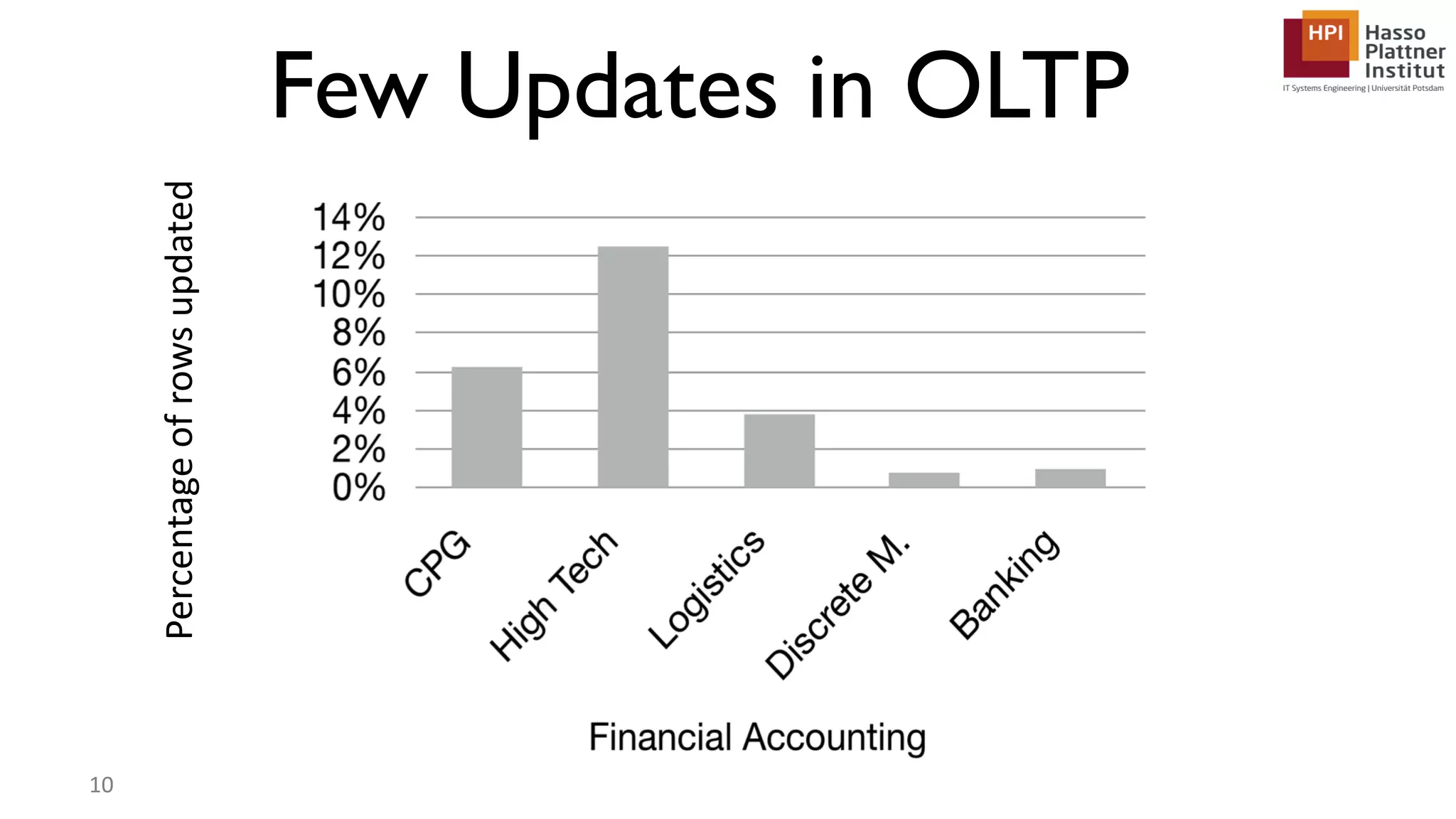










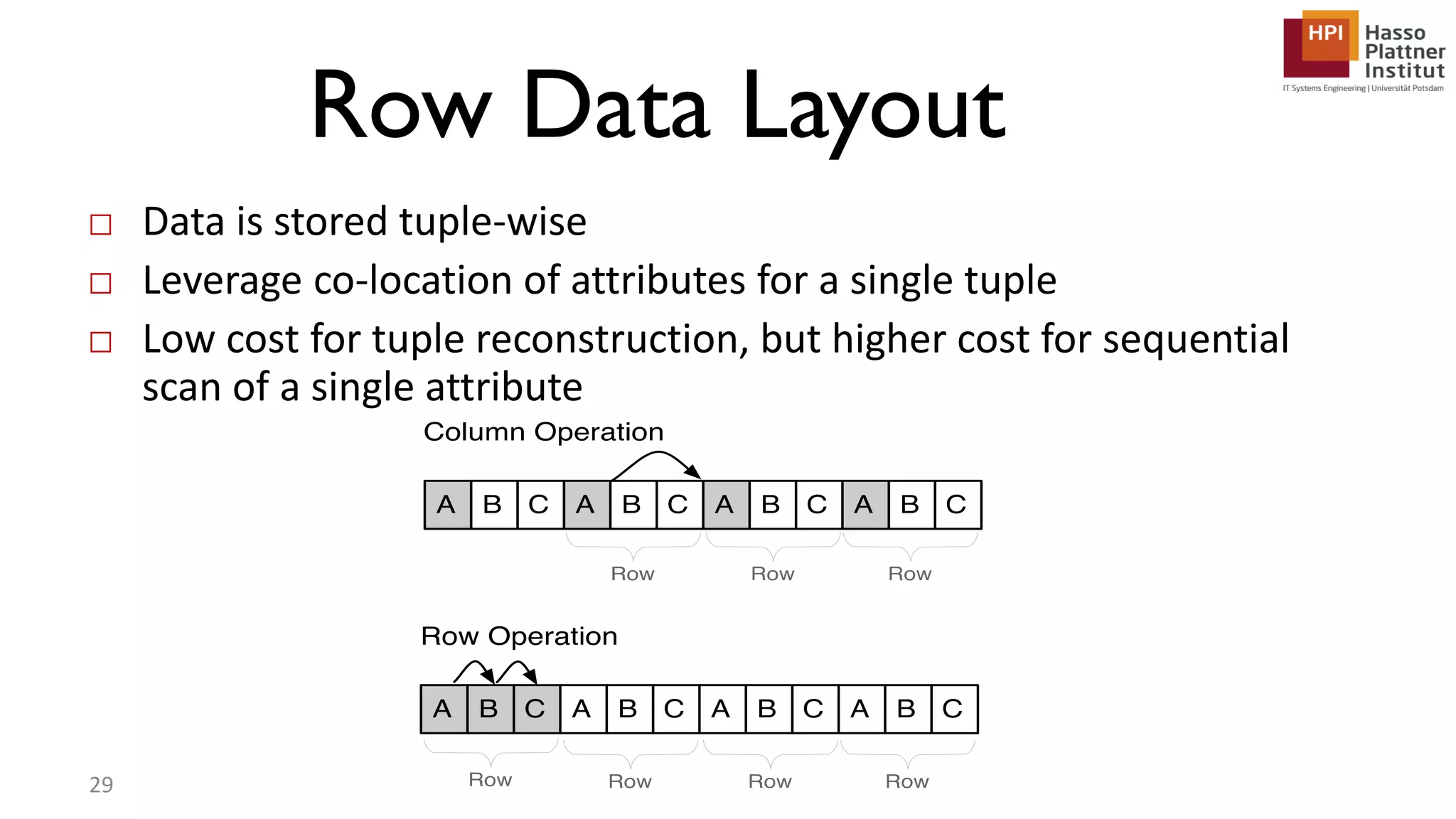

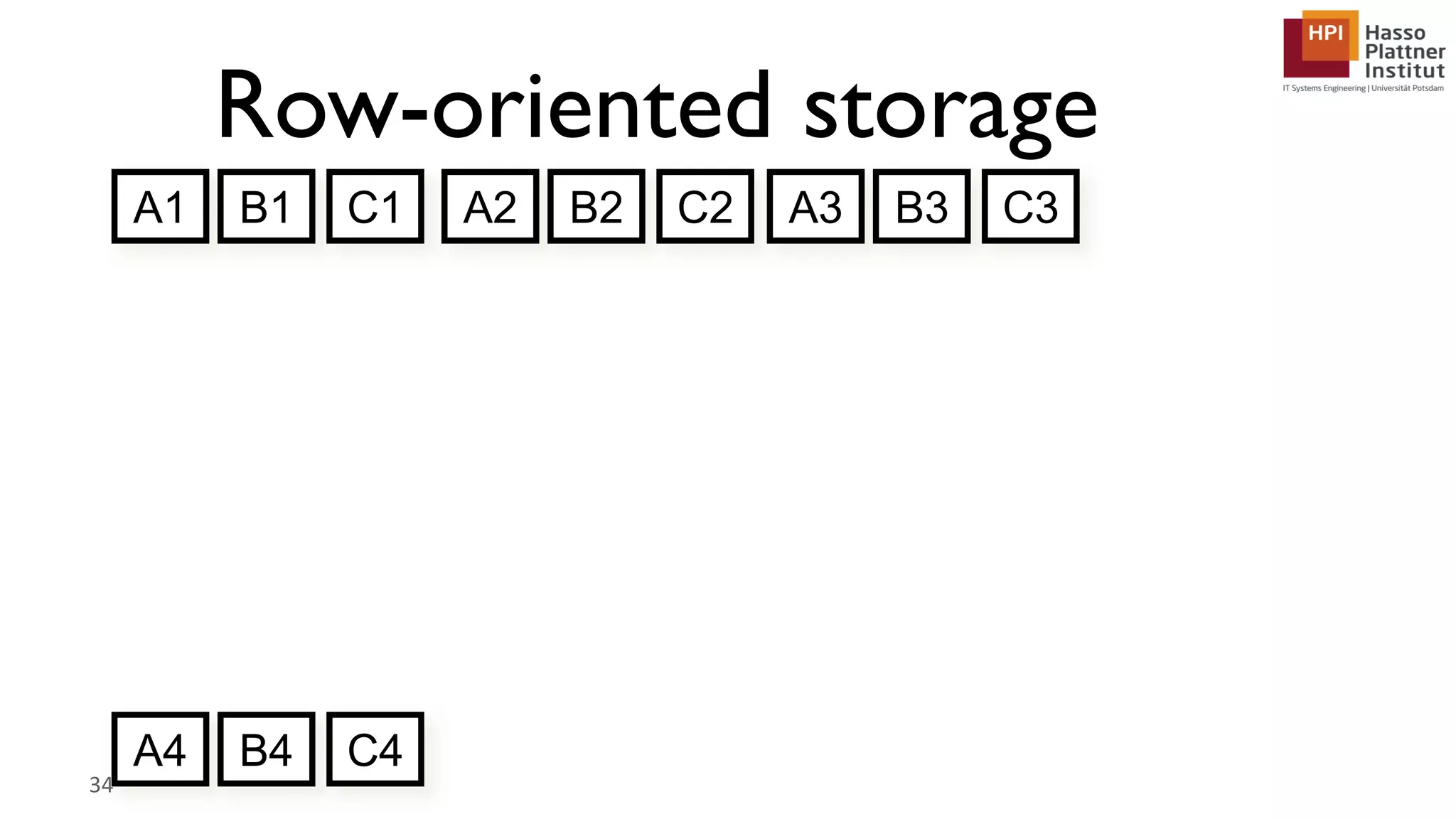

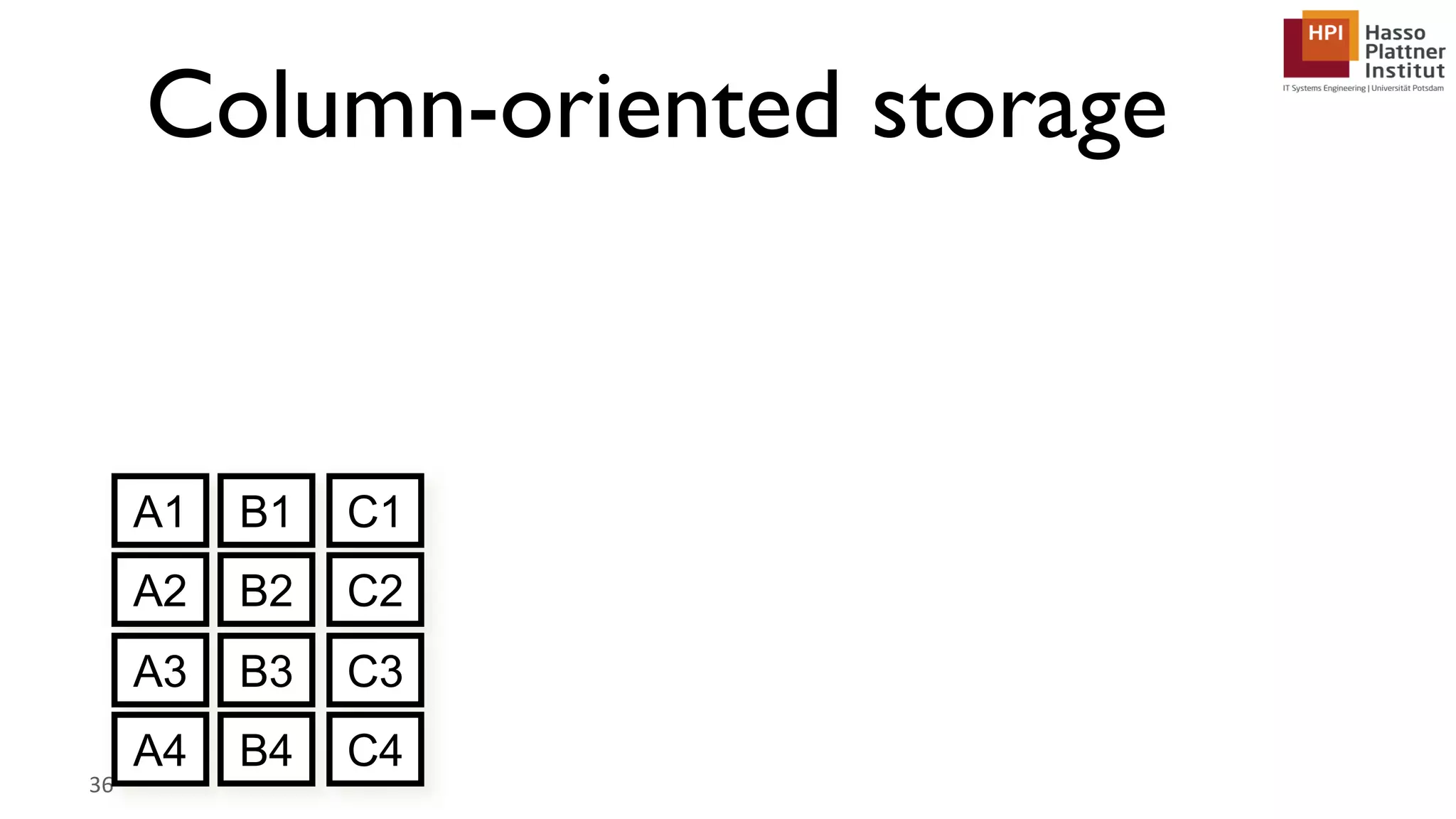
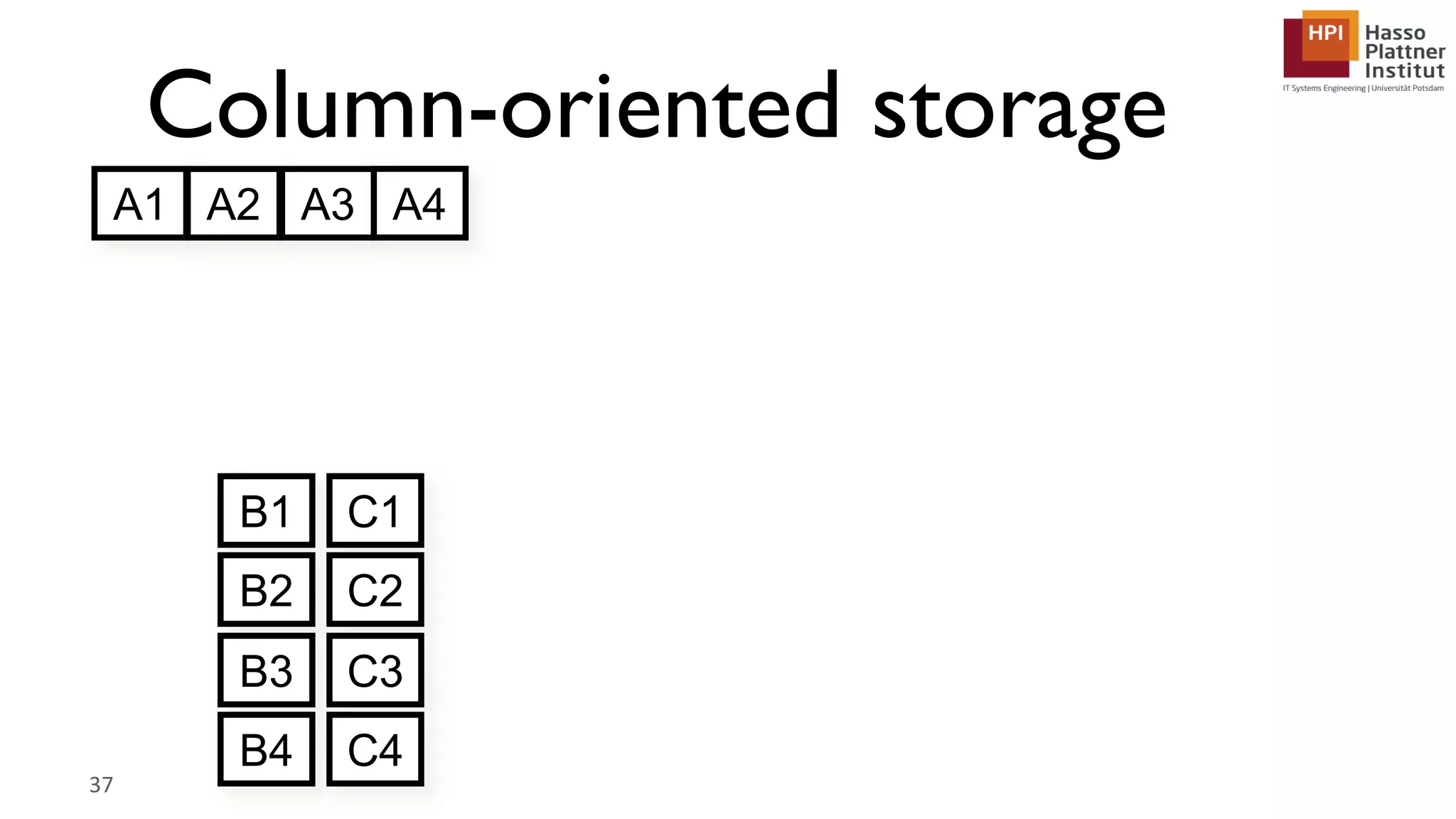
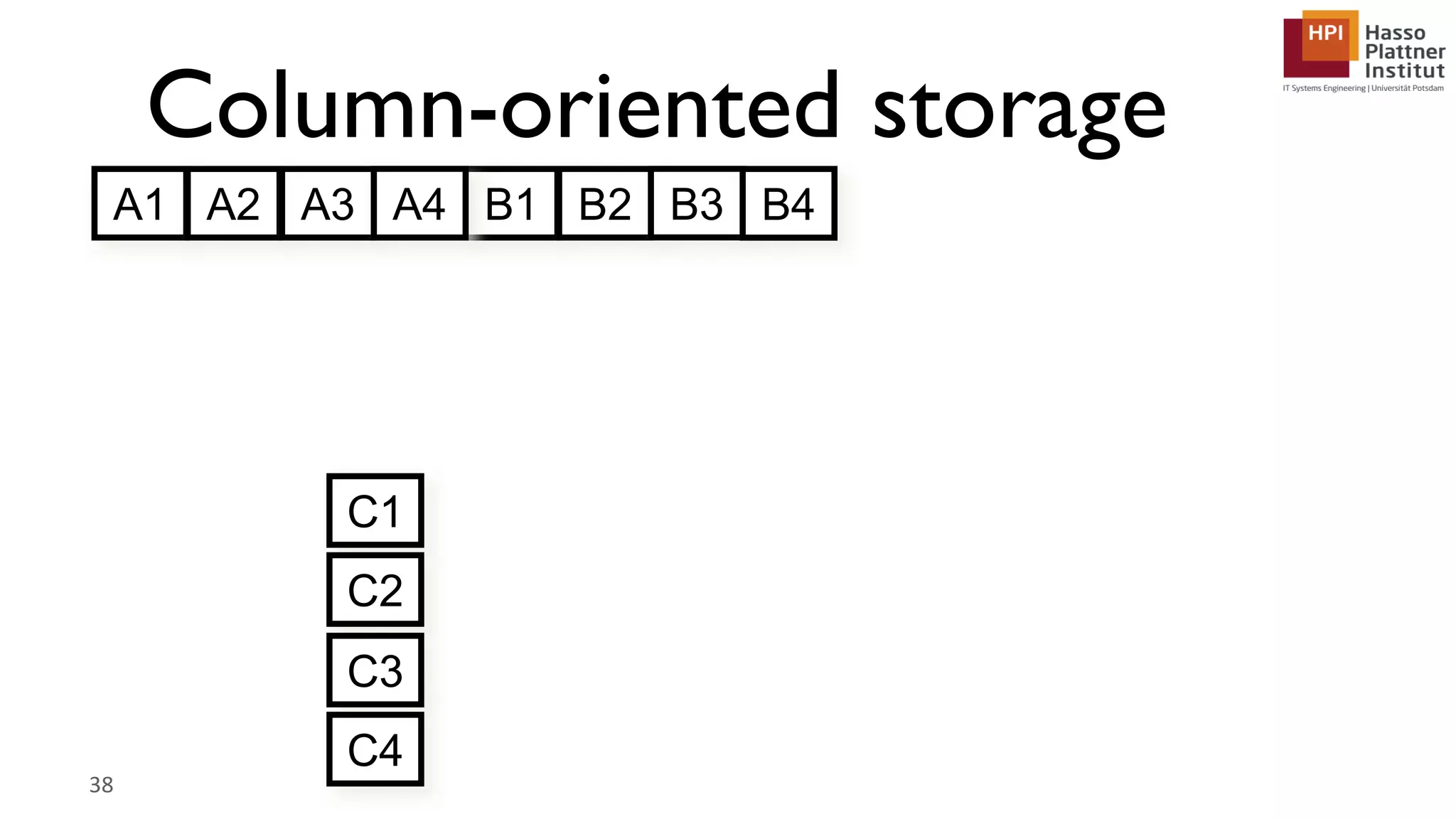



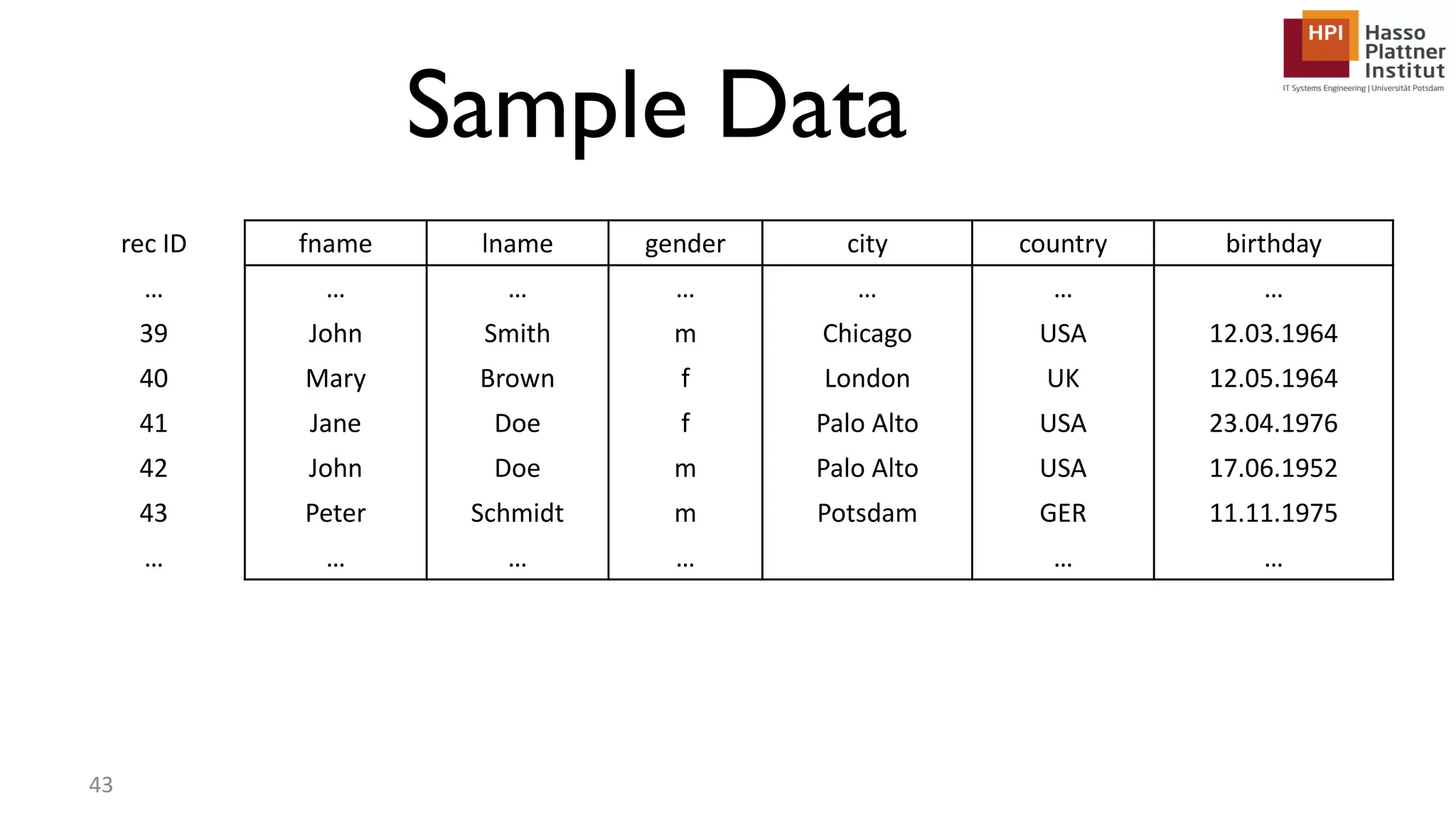

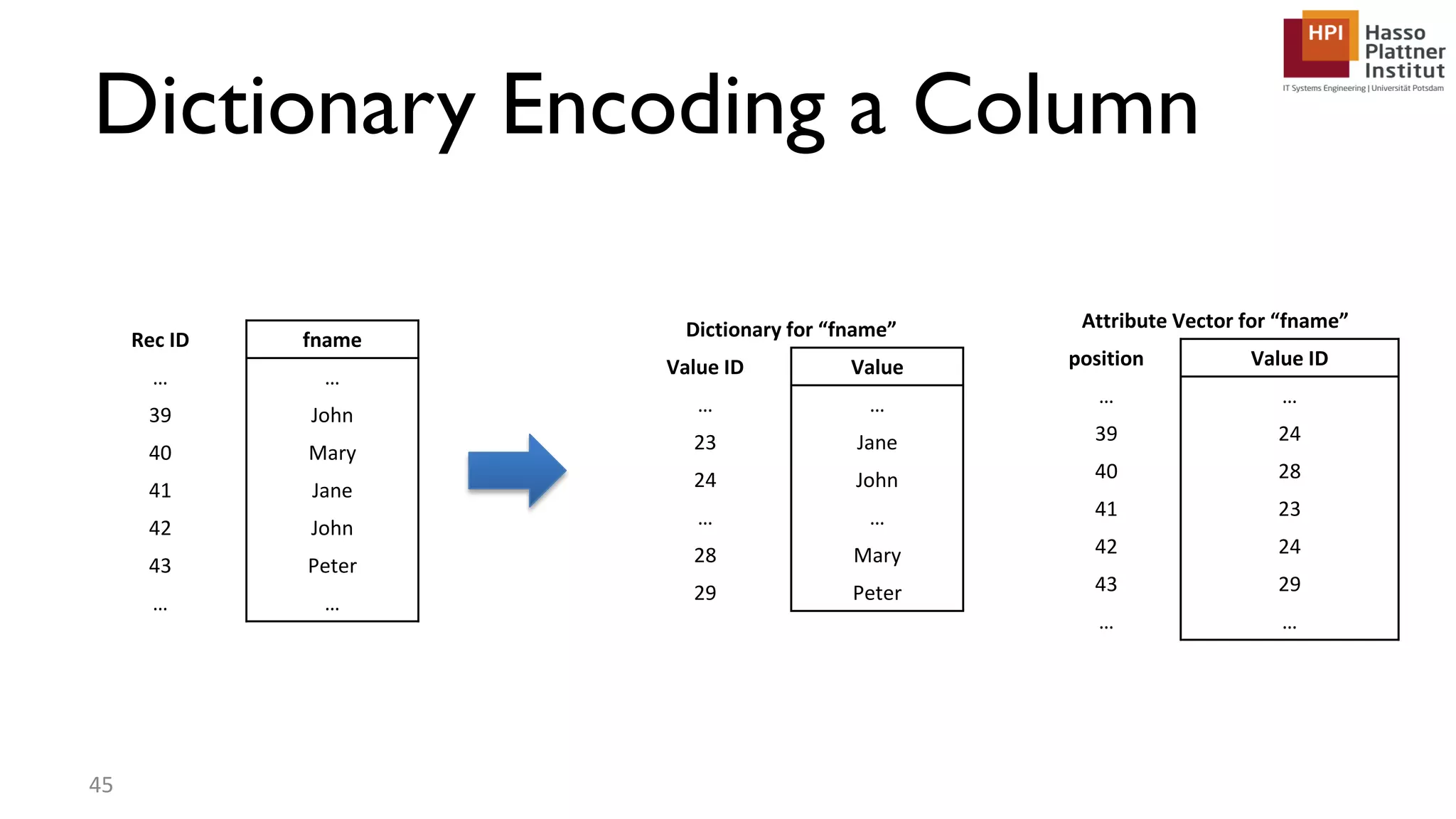

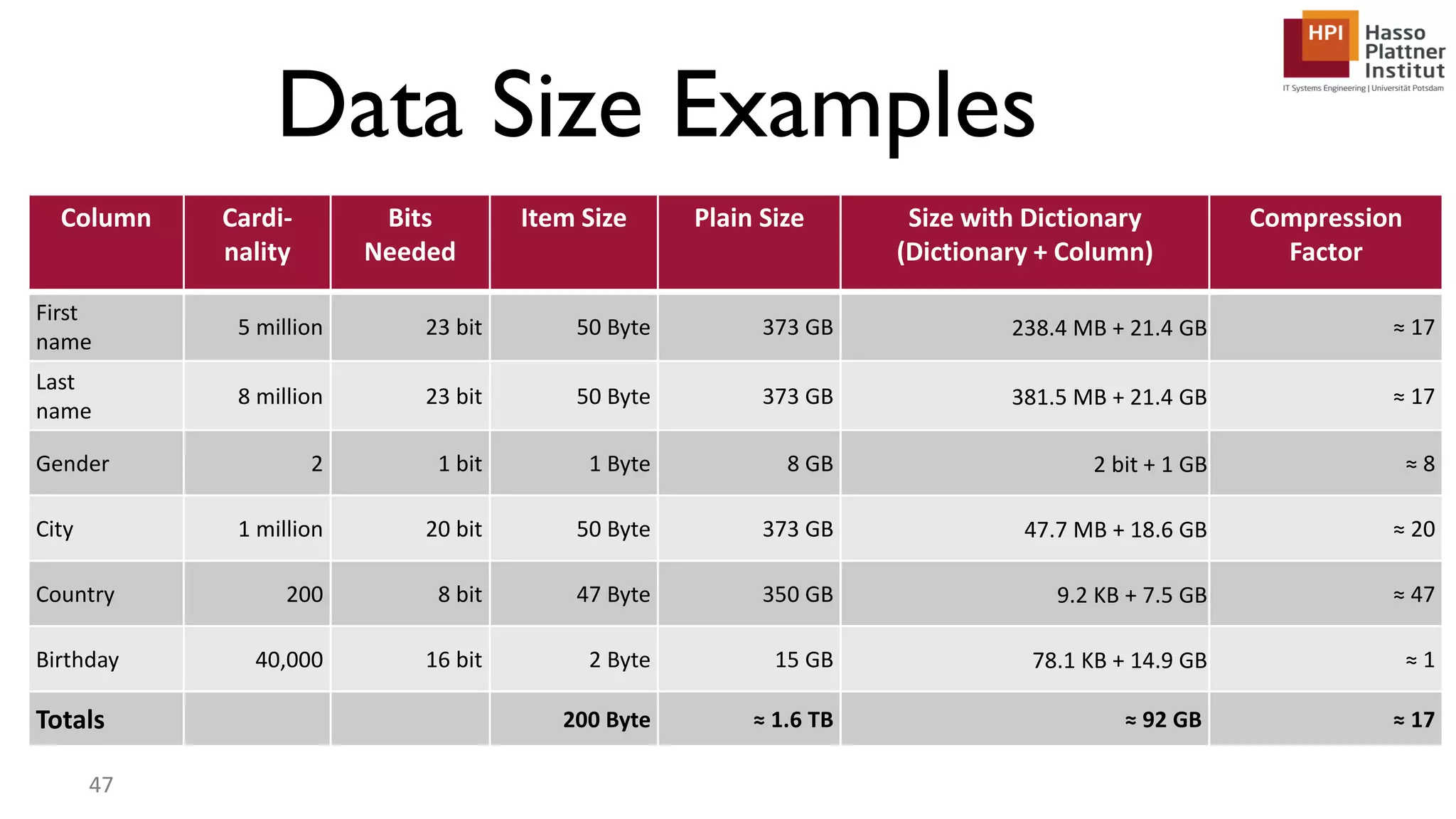



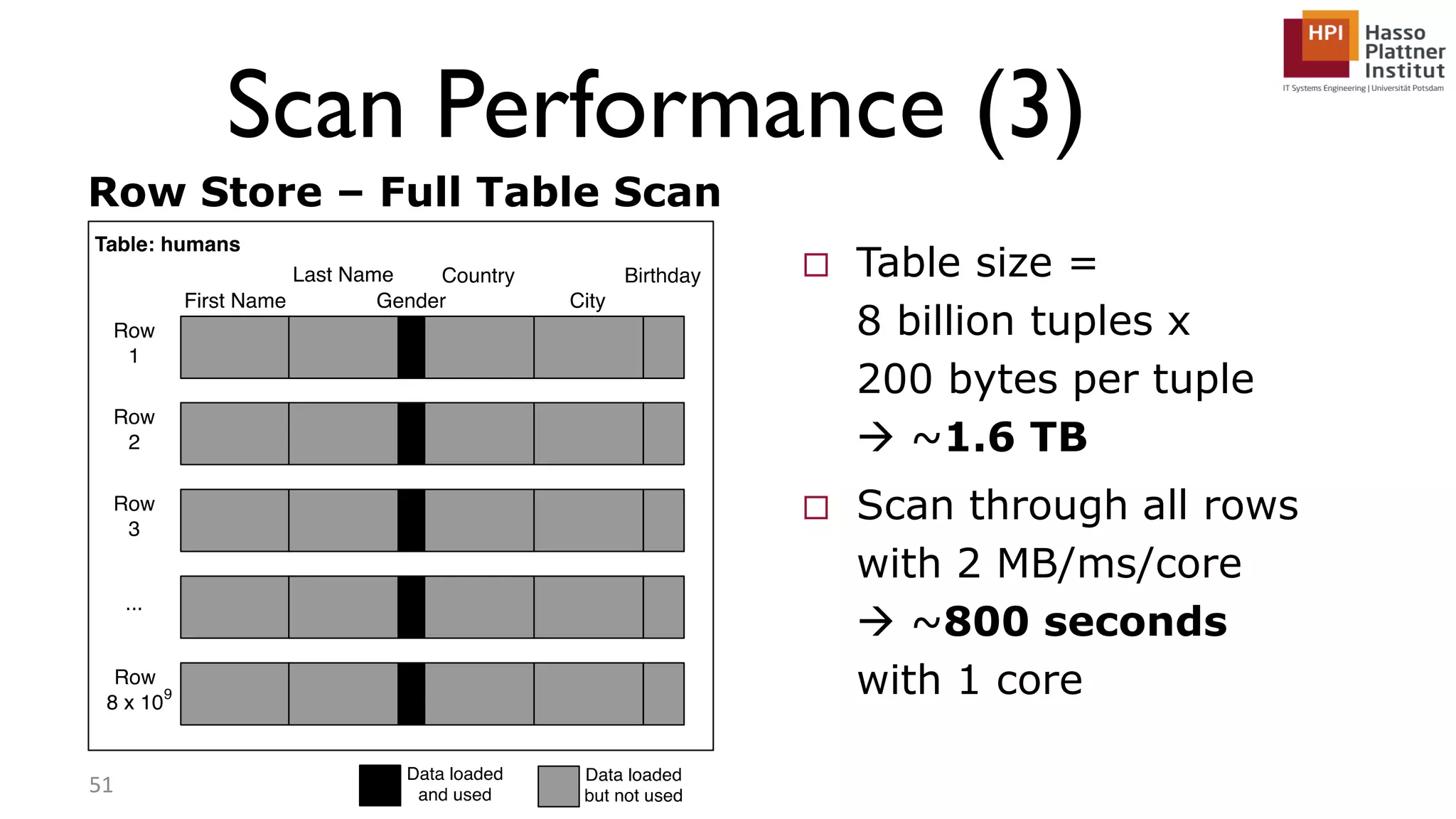
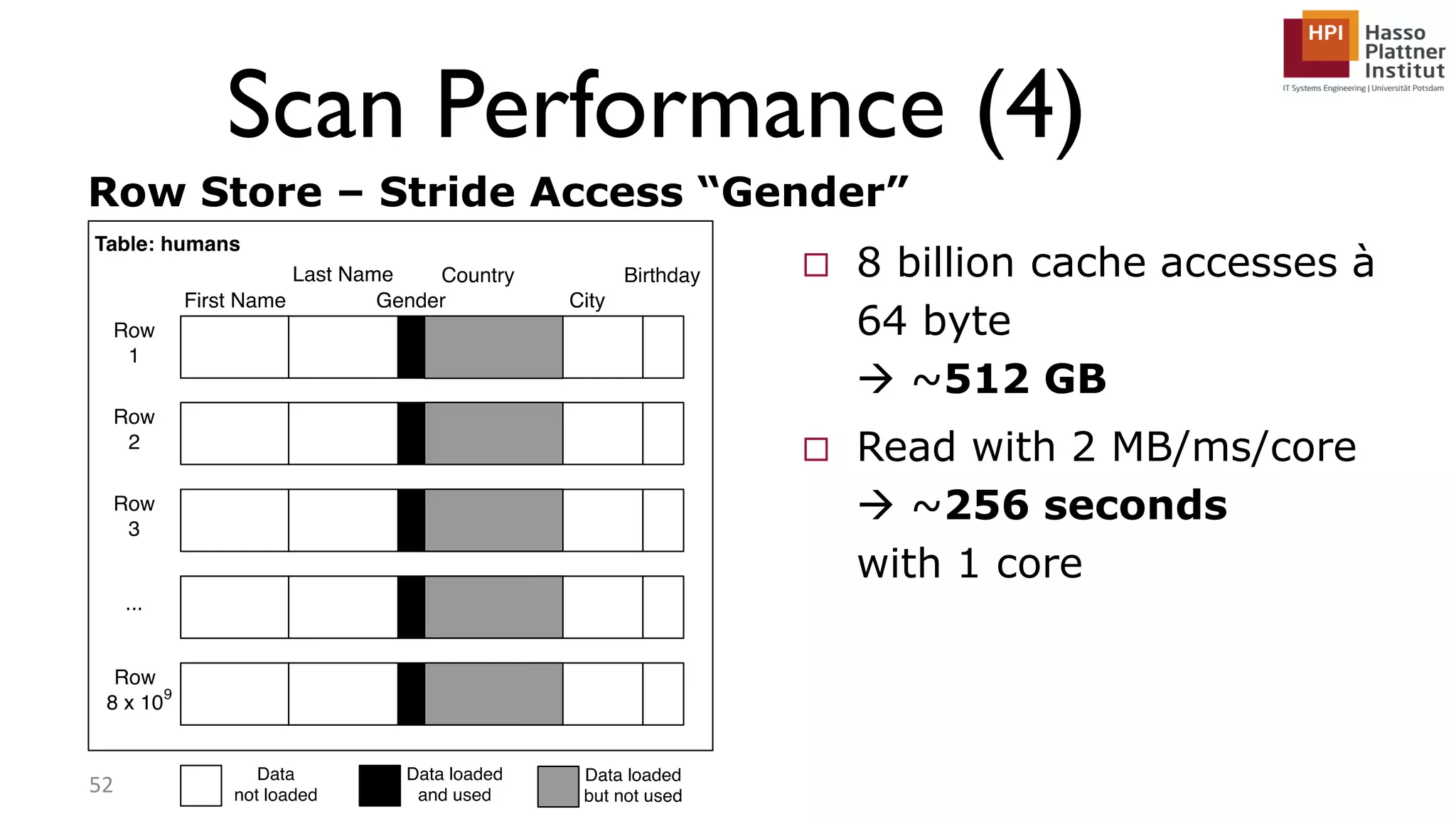

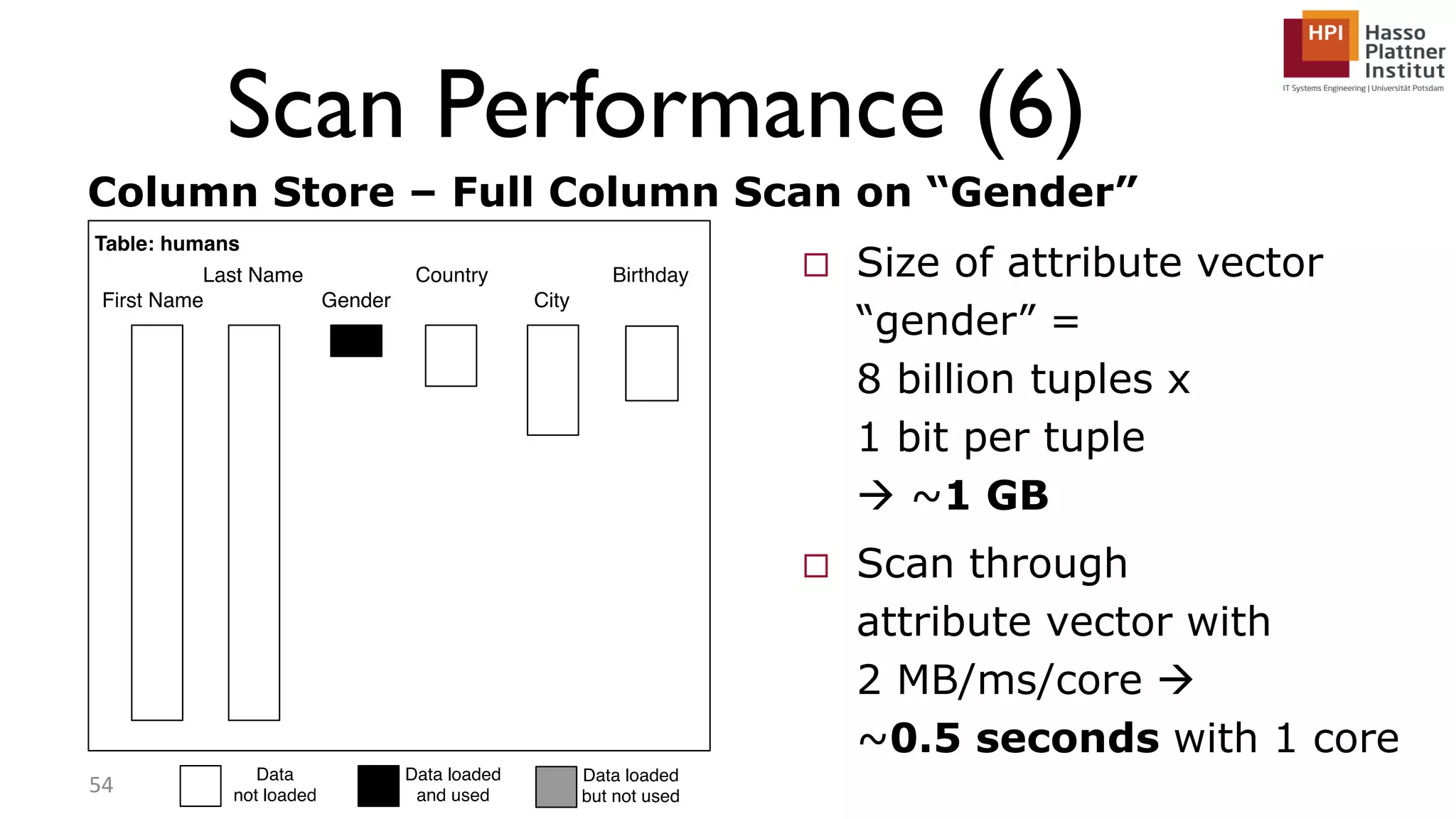
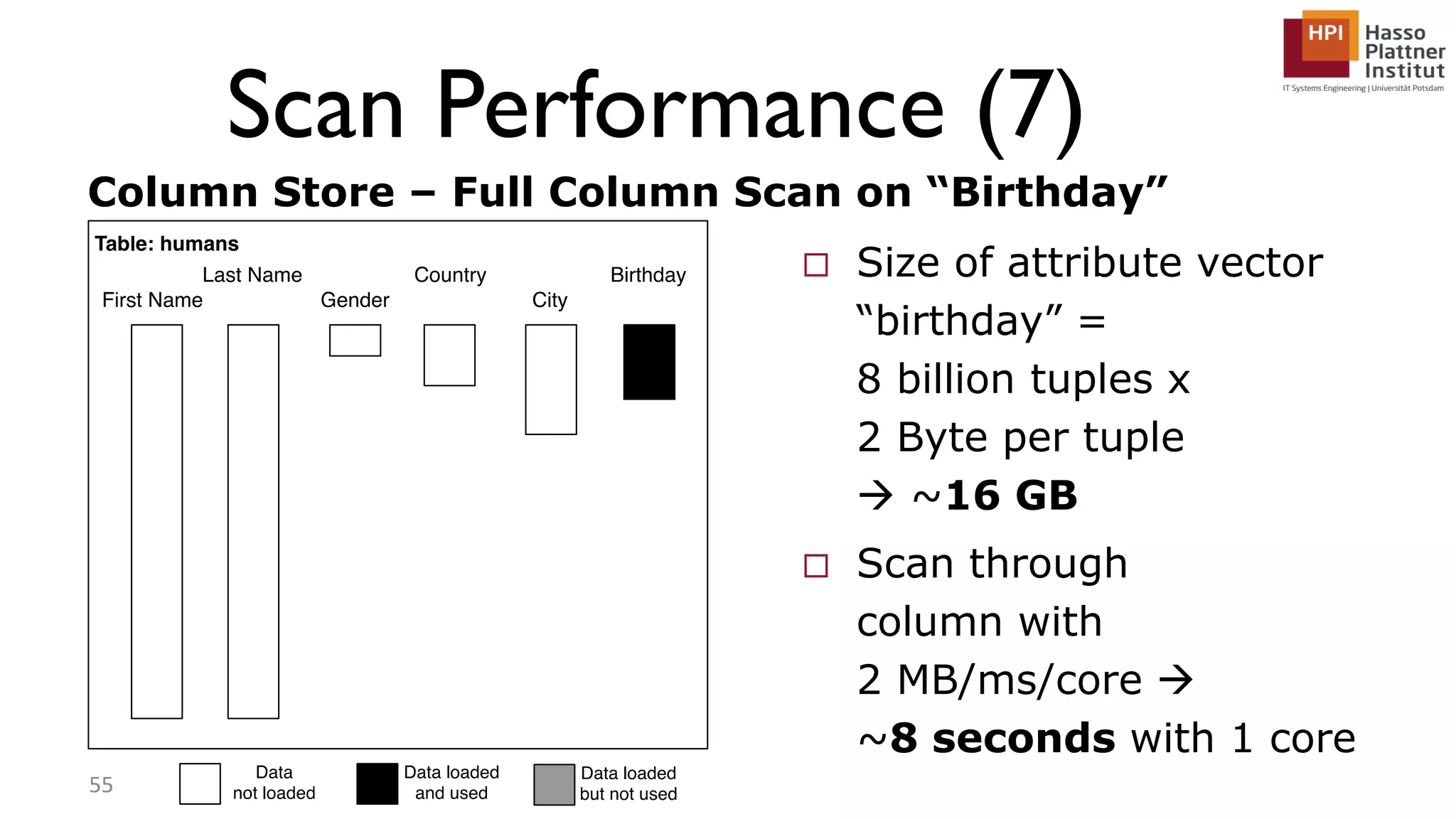







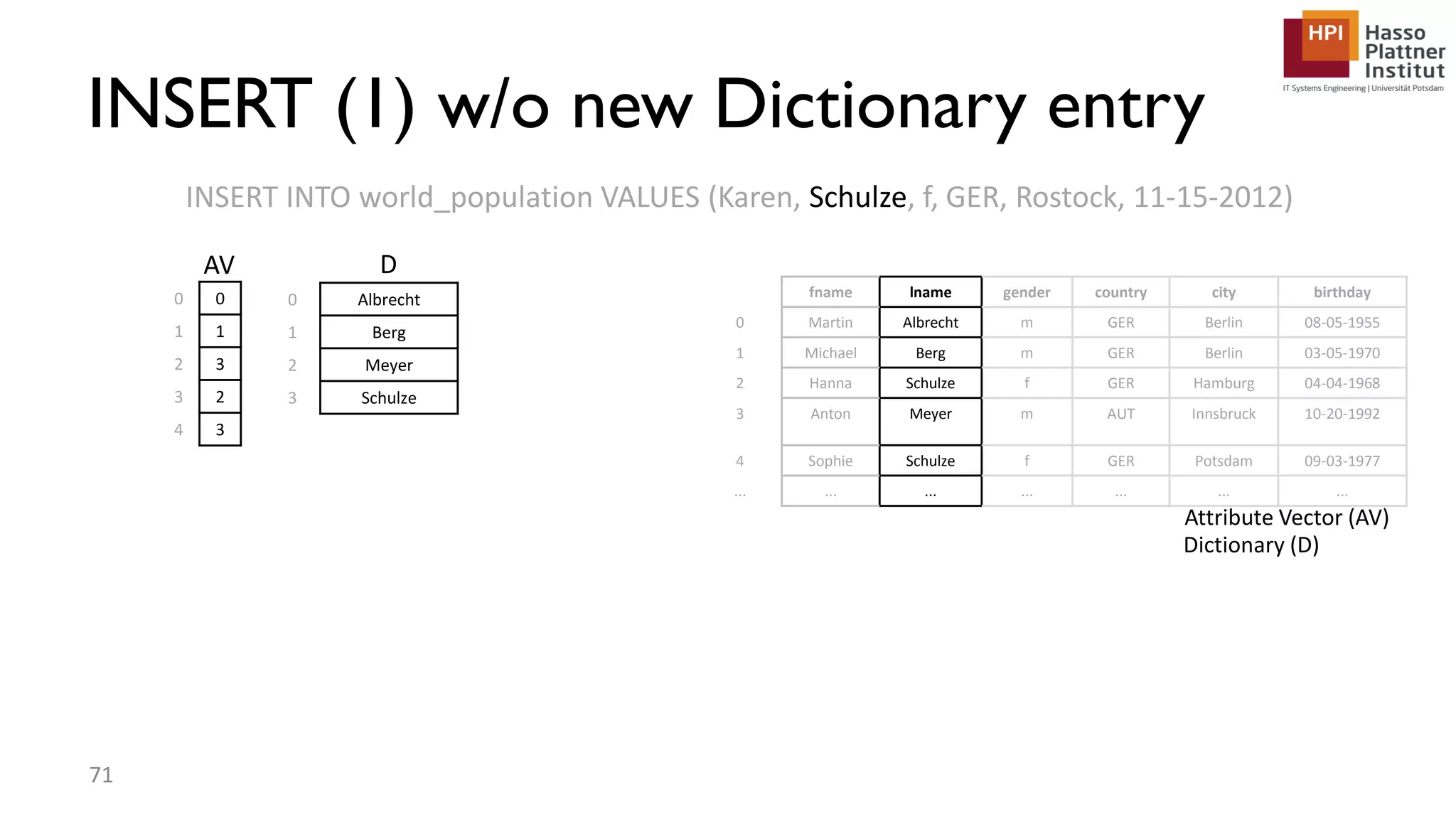


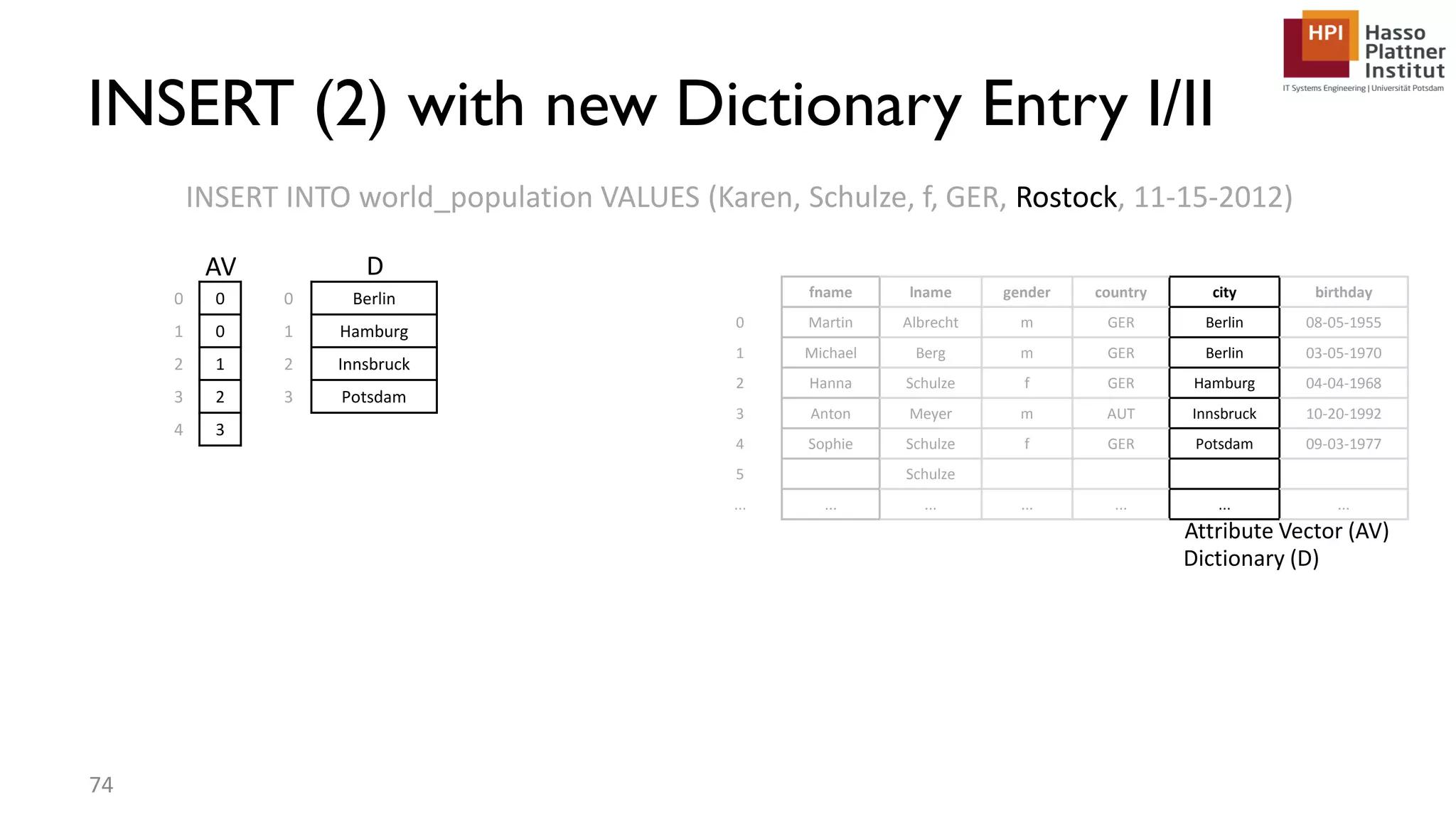



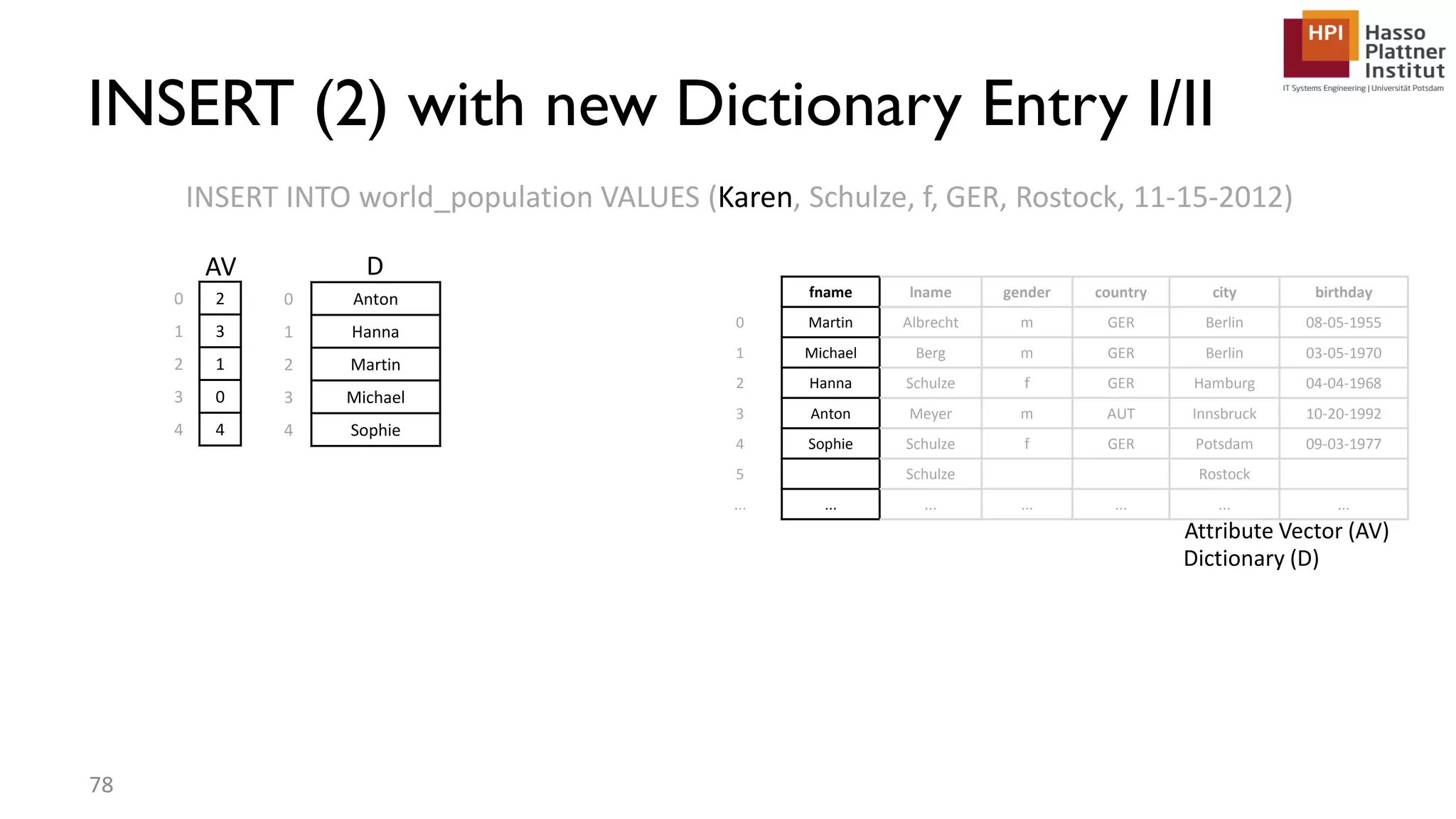





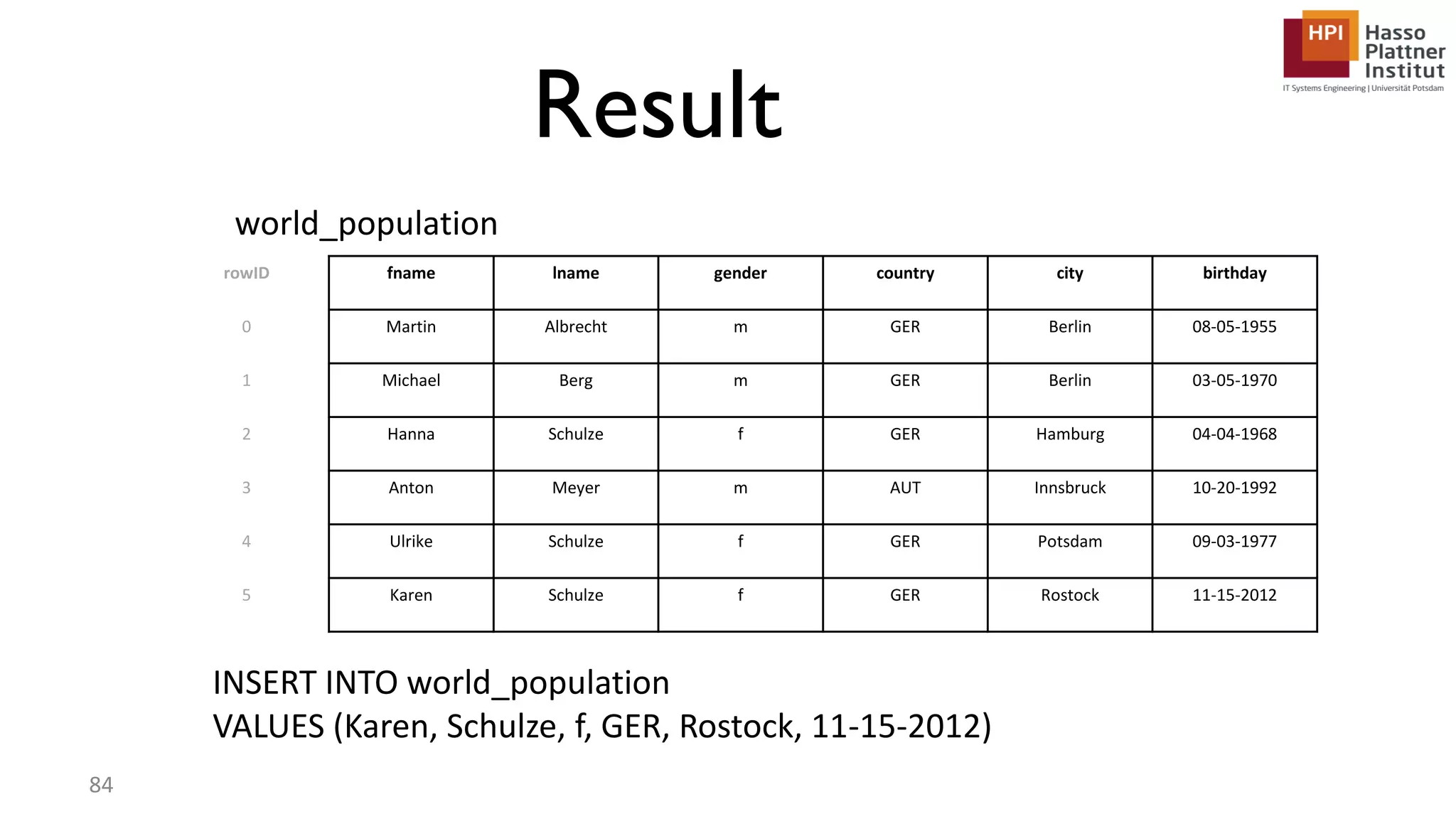



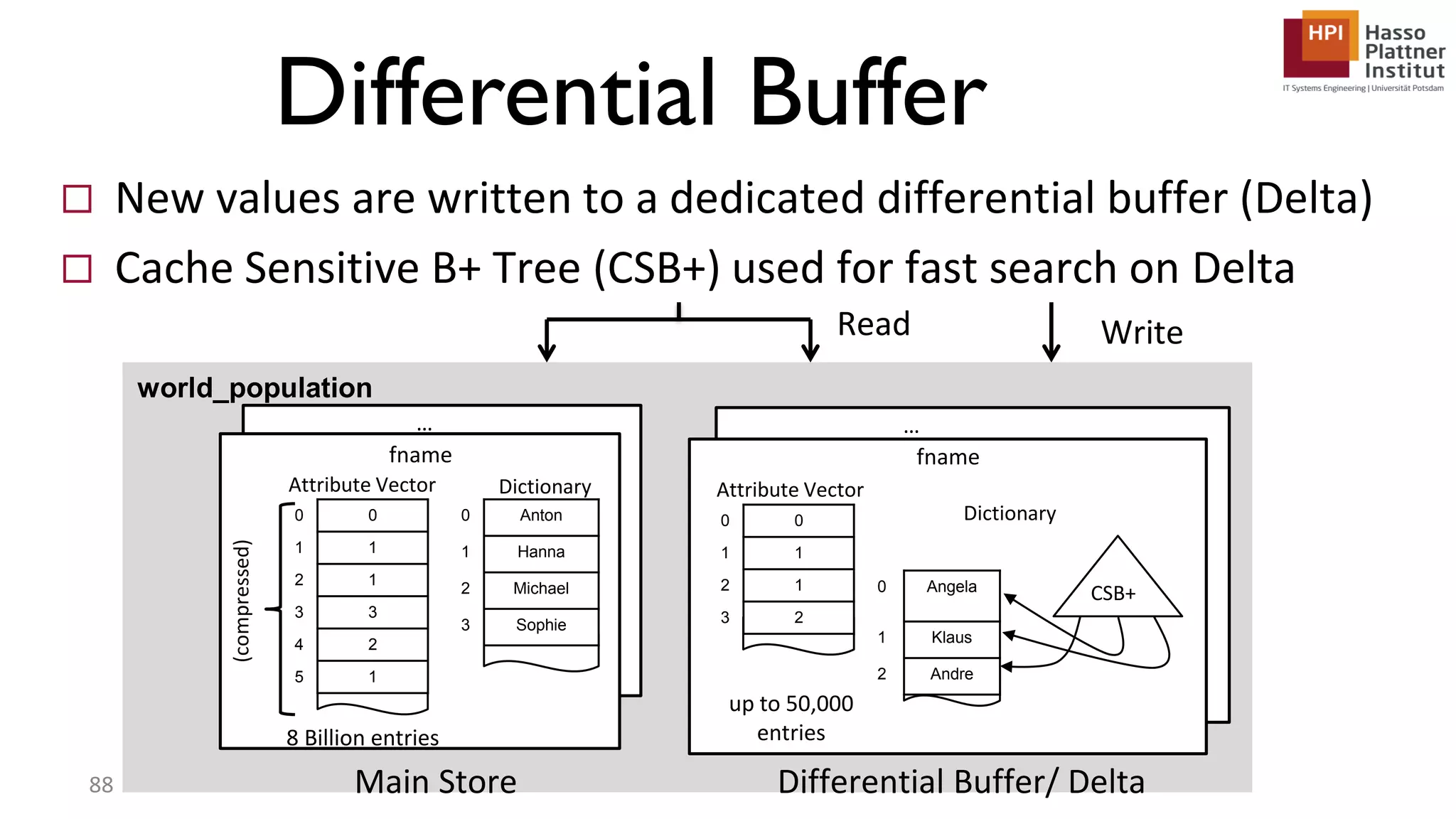





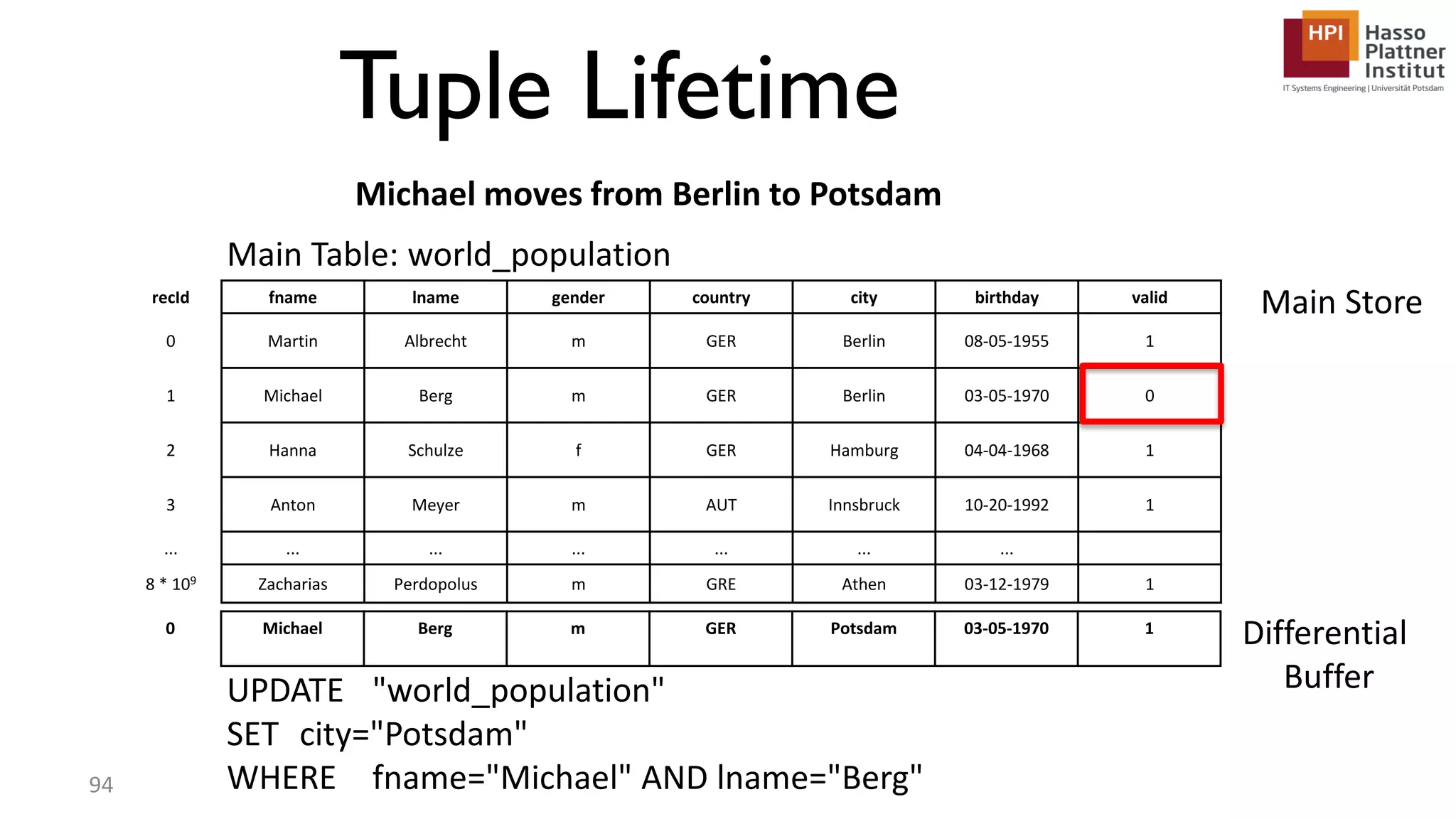



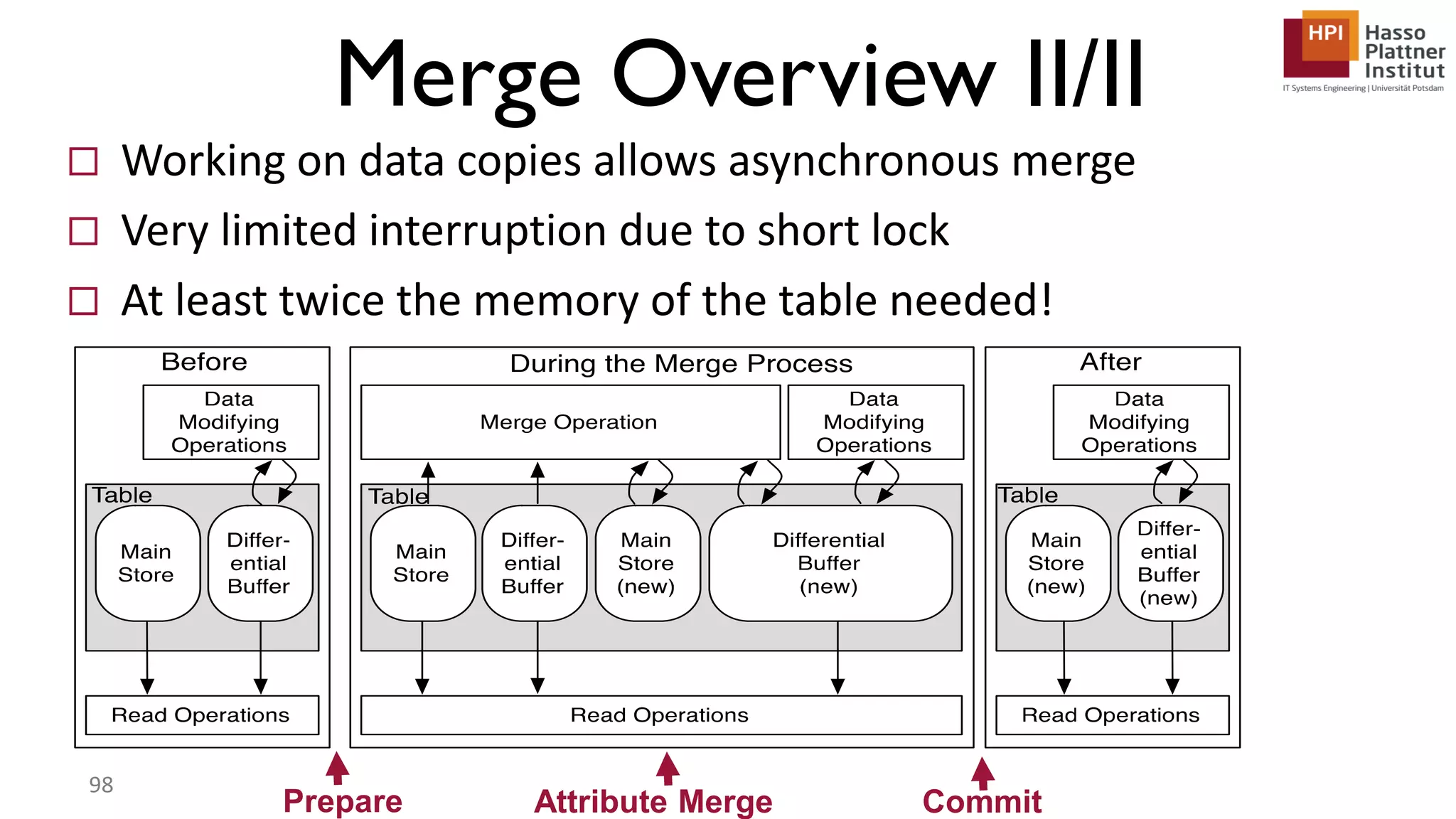


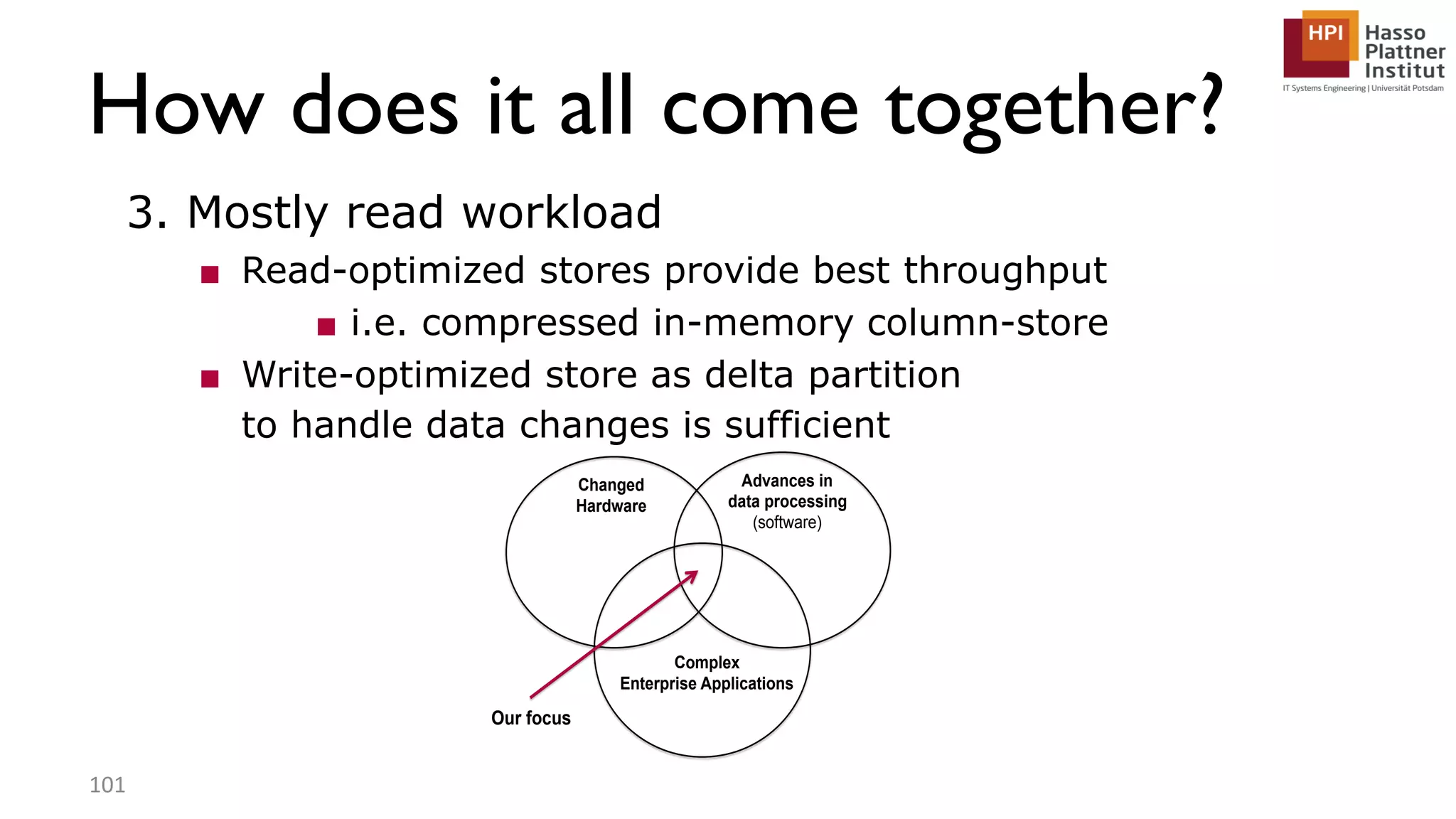
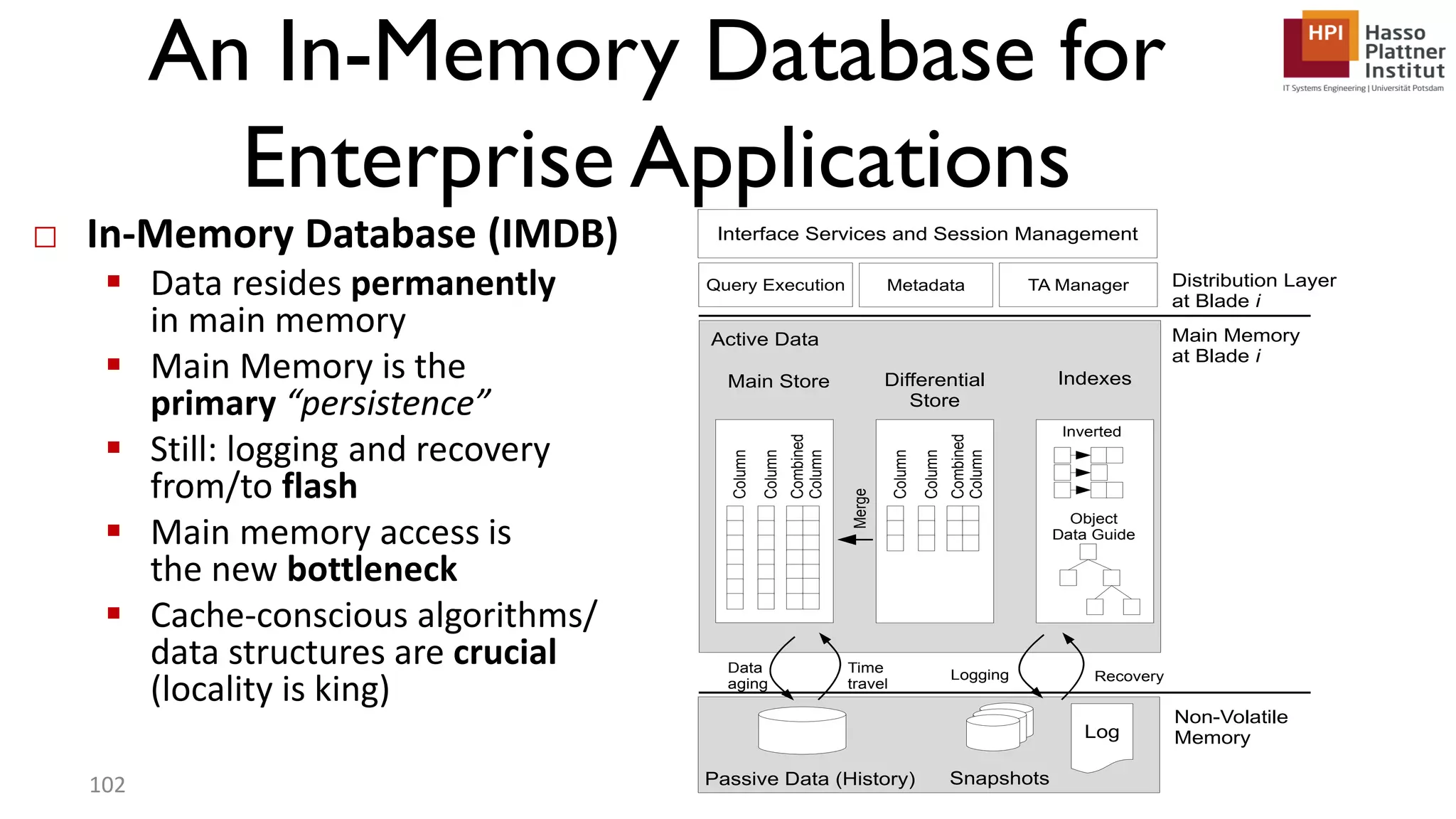




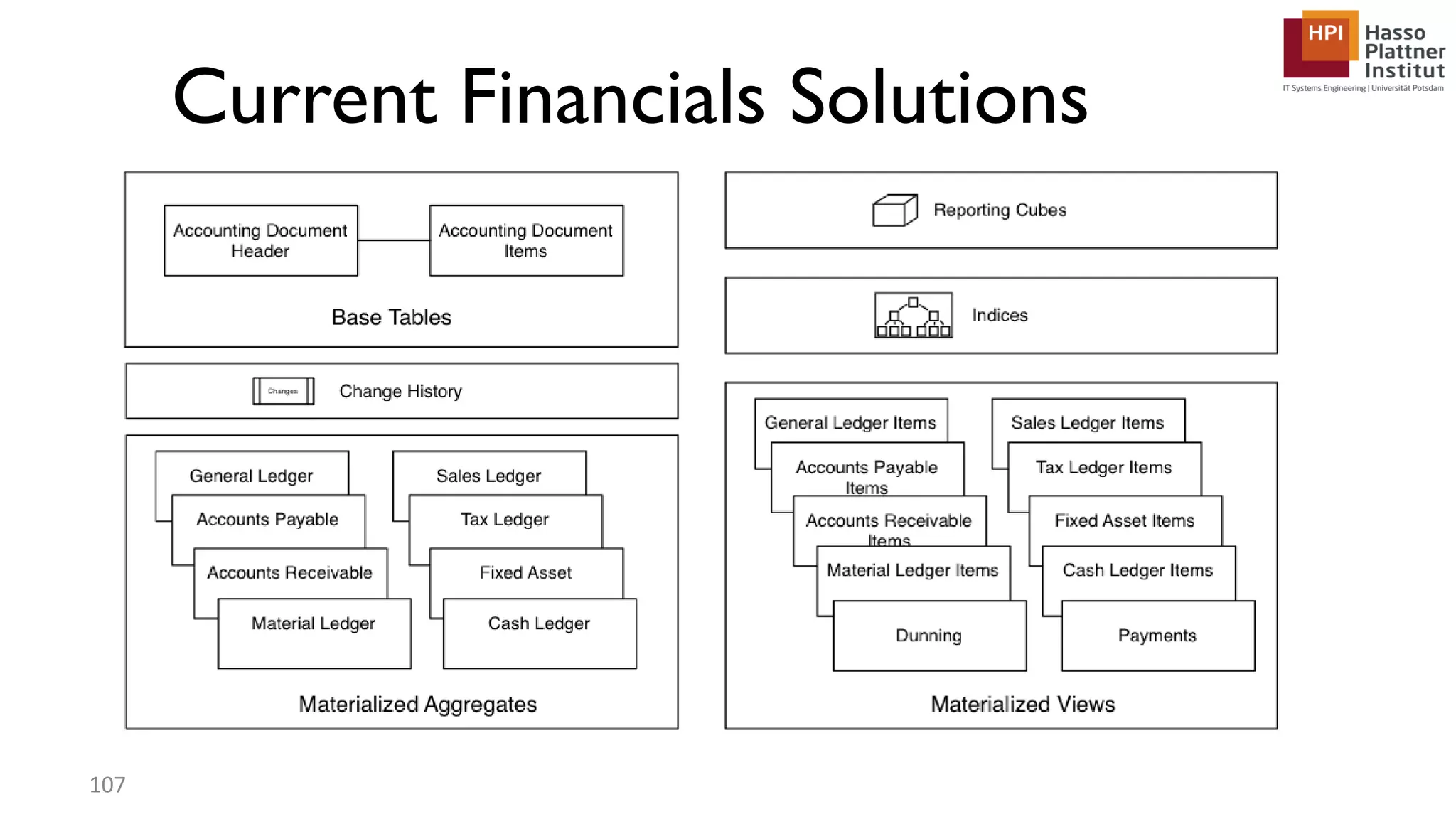
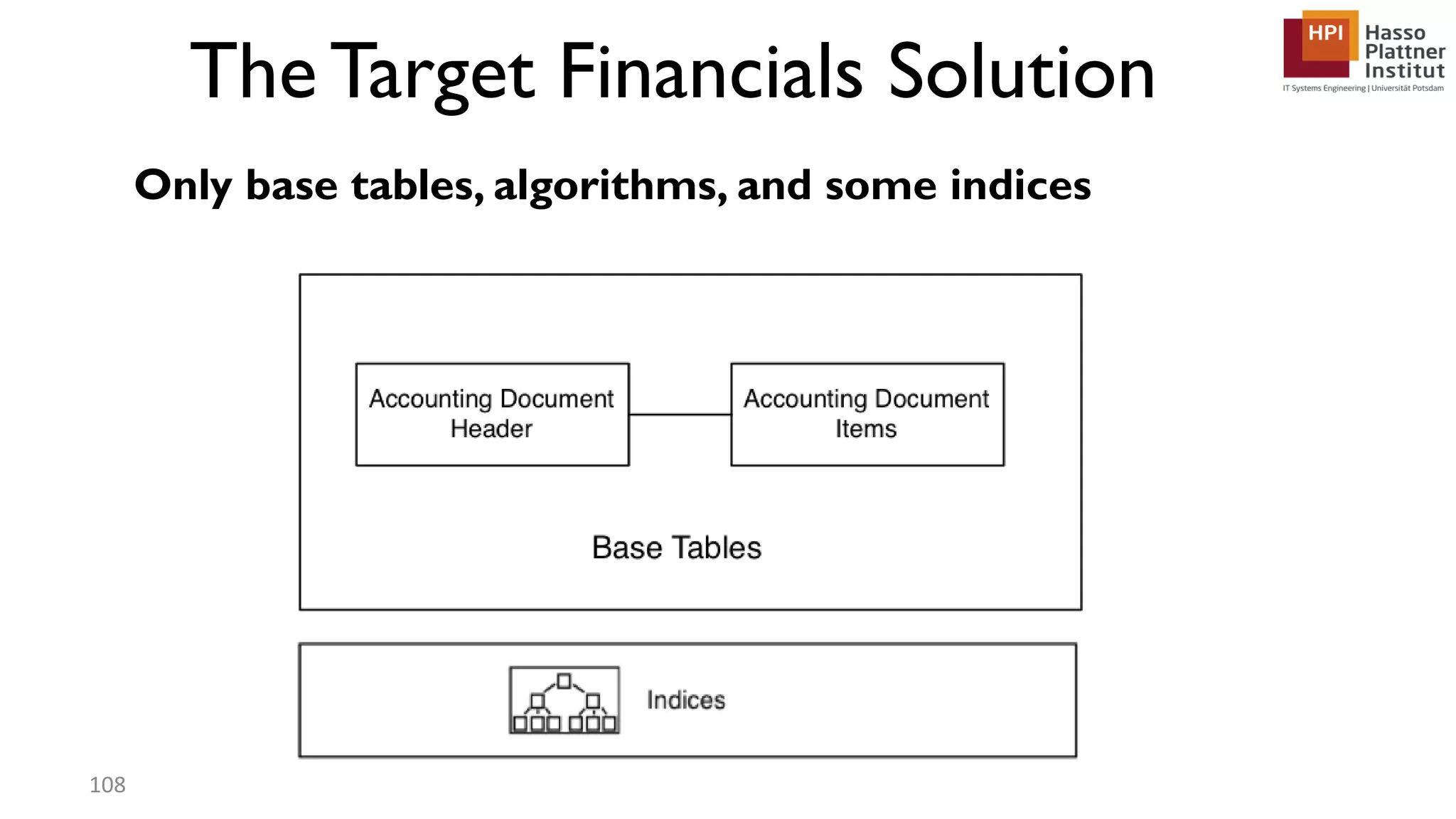


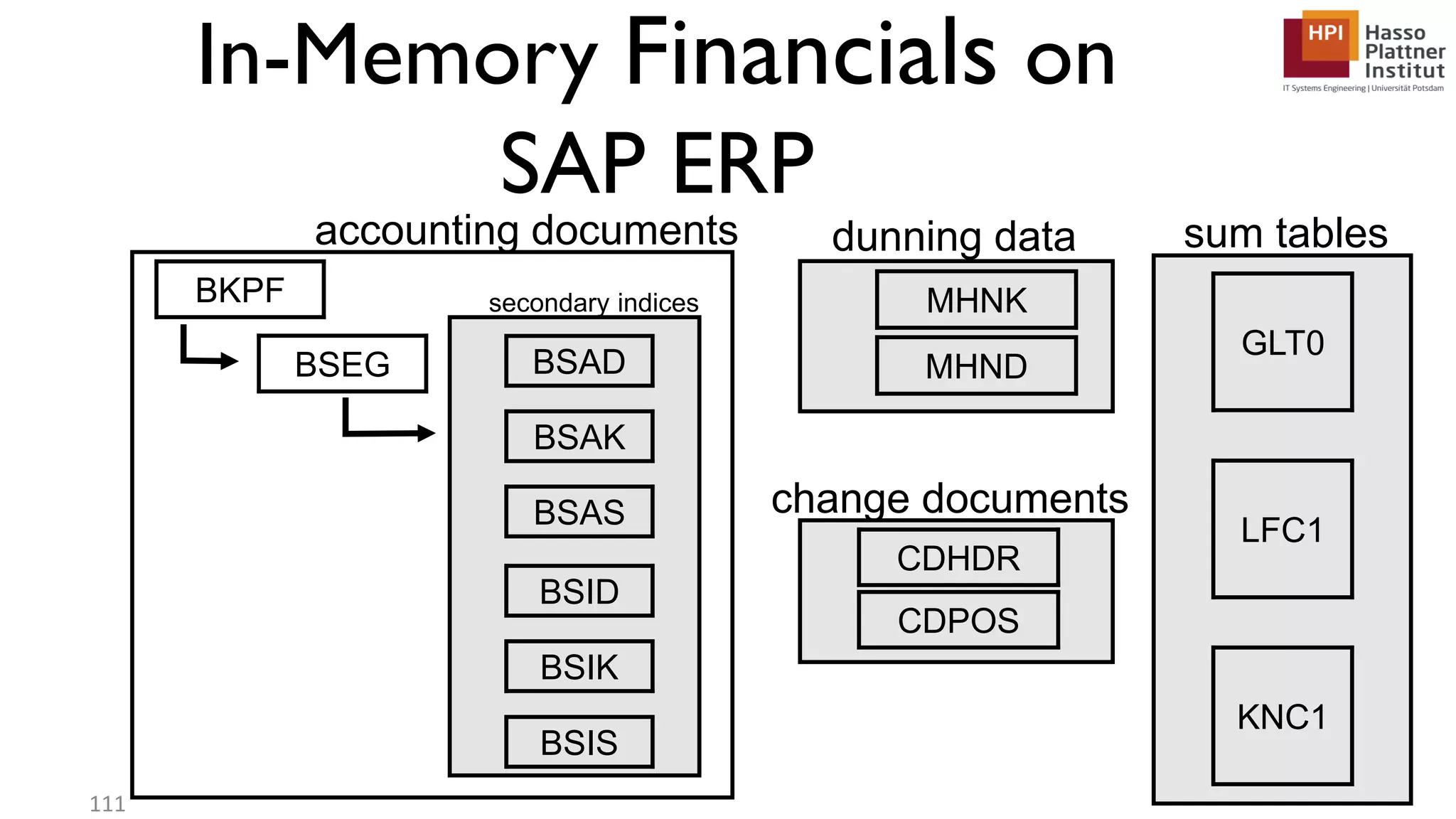















The document describes a lecture on column-oriented in-memory databases. The lecture covers the status quo of enterprise computing, database storage techniques like row and column storage layouts, in-memory database operators like scanning and aggregation, and advanced storage techniques like dictionary encoding and tuple reconstruction. The goal is to provide a deep technical understanding of column-oriented in-memory databases and their application in enterprise systems.