15-721 (Spring 2023) OBSERVATION Today'slecture is about the lowest physical representation of data in a database. What data "looks" like determines almost a DBMS's entire system architecture. → Processing Model → Tuple Materialization Strategy → Operator Algorithms → Data Ingestion / Updates → Concurrency Control (we will ignore this) → Query Optimization 2
15-721 (Spring 2023) STORAGEMODELS A DBMS's storage model specifies how it physically organizes tuples on disk and in memory. Choice #1: N-ary Storage Model (NSM) Choice #2: Decomposition Storage Model (DSM) Choice #3: Hybrid Storage Model (PAX) 4 COLUMN-STORES VS. ROW-STORES: HOW DIFFERENT ARE THEY REALLY? SIGMOD 2008
5.
15-721 (Spring 2023) N-ARYSTORAGE MODEL (NSM) The DBMS stores (almost) all the attributes for a single tuple contiguously in a single page. Ideal for OLTP workloads where txns tend to access individual entities and insert-heavy workloads. → Use the tuple-at-a-time iterator processing model. NSM database page sizes are typically some constant multiple of 4 KB hardware pages. → Example: Oracle (4 KB), Postgres (8 KB), MySQL (16 KB) 5
6.
15-721 (Spring 2023) Database Page NSM:PHYSICAL ORGANIZATION A disk-oriented NSM system stores a tuple's fixed-length and variable- length attributes contiguously in a single slotted page. The tuple's record id (page#, slot#) is how the DBMS uniquely identifies a physical tuple. 6 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header b0 a0 c0 header Slot Array
7.
15-721 (Spring 2023) Database Page NSM:PHYSICAL ORGANIZATION A disk-oriented NSM system stores a tuple's fixed-length and variable- length attributes contiguously in a single slotted page. The tuple's record id (page#, slot#) is how the DBMS uniquely identifies a physical tuple. 6 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header b0 a0 c0 header b1 c1 a1 header Slot Array
8.
15-721 (Spring 2023) Database Page NSM:PHYSICAL ORGANIZATION A disk-oriented NSM system stores a tuple's fixed-length and variable- length attributes contiguously in a single slotted page. The tuple's record id (page#, slot#) is how the DBMS uniquely identifies a physical tuple. 6 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header b0 a0 c0 header b1 c1 a1 header Slot Array b2 a2 c2 header b3 a3 c3 header b4 c4 a4 header b5 a5 c5 header
9.
15-721 (Spring 2023) Database Page NSM:PHYSICAL ORGANIZATION 6 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header b0 a0 c0 header b1 c1 a1 header Slot Array b2 a2 c2 header b3 a3 c3 header b4 c4 a4 header b5 a5 c5 header SELECT SUM(colA), AVG(colC) FROM xxx WHERE colA > 1000
10.
15-721 (Spring 2023) Database Page NSM:PHYSICAL ORGANIZATION 6 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header b0 a0 c0 header b1 c1 a1 header Slot Array b2 a2 c2 header b3 a3 c3 header b4 c4 a4 header b5 a5 c5 header SELECT SUM(colA), AVG(colC) FROM xxx WHERE colA > 1000
11.
15-721 (Spring 2023) Database Page NSM:PHYSICAL ORGANIZATION 6 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header b0 a0 c0 header b1 c1 a1 header Slot Array b2 a2 c2 header b3 a3 c3 header b4 c4 a4 header b5 a5 c5 header SELECT SUM(colA), AVG(colC) FROM xxx WHERE colA > 1000
12.
15-721 (Spring 2023) N-ARYSTORAGE MODEL (NSM) Advantages → Fast inserts, updates, and deletes. → Good for queries that need the entire tuple (OLTP). → Can use index-oriented physical storage for clustering. Disadvantages → Not good for scanning large portions of the table and/or a subset of the attributes. → Terrible memory locality in access patterns. → Not ideal for compression because of multiple value domains within a single page. 7
13.
15-721 (Spring 2023) DECOMPOSITIONSTORAGE MODEL (DSM) The DBMS stores a single attribute for all tuples contiguously in a block of data. Ideal for OLAP workloads where read-only queries perform large scans over a subset of the table’s attributes. → Use a batched vectorized processing model. File sizes are larger (100s of MBs), but it may still organize tuples within the file into smaller groups. 8
14.
15-721 (Spring 2023) DSM:PHYSICAL ORGANIZATION Store attributes and meta-data (e.g., nulls) in separate arrays of fixed- length values. → Most systems identify unique physical tuples using offsets into these arrays. → Need to handle variable-length values… Maintain a separate file per attribute with a dedicated header area for meta- data about entire column. 9 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header null bitmap a0 a1 a2 a3 a4 a5 File #1
15.
15-721 (Spring 2023) DSM:PHYSICAL ORGANIZATION Store attributes and meta-data (e.g., nulls) in separate arrays of fixed- length values. → Most systems identify unique physical tuples using offsets into these arrays. → Need to handle variable-length values… Maintain a separate file per attribute with a dedicated header area for meta- data about entire column. 9 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header null bitmap a0 a1 a2 a3 a4 a5 File #1 header null bitmap b0 b1 b2 b3 b4 b5 File #2
16.
15-721 (Spring 2023) DSM:PHYSICAL ORGANIZATION Store attributes and meta-data (e.g., nulls) in separate arrays of fixed- length values. → Most systems identify unique physical tuples using offsets into these arrays. → Need to handle variable-length values… Maintain a separate file per attribute with a dedicated header area for meta- data about entire column. 9 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header null bitmap a0 a1 a2 a3 a4 a5 File #1 header null bitmap b0 b1 b2 b3 b4 b5 File #2 header null bitmap c5 c0 c1 c2 c3 c4 File #3
17.
15-721 (Spring 2023) DSM:TUPLE IDENTIFICATION Choice #1: Fixed-length Offsets → Each value is the same length for an attribute. Choice #2: Embedded Tuple Ids → Each value is stored with its tuple id in a column. 10 Offsets 0 1 2 3 A B C D Embedded Ids A 0 1 2 3 B 0 1 2 3 C 0 1 2 3 D 0 1 2 3
18.
15-721 (Spring 2023) DSM:VARIABLE-LENGTH DATA Padding variable-length fields to ensure they are fixed-length is wasteful, especially for large attributes. A better approach is to use dictionary compression to convert repetitive variable-length data into fixed- length values (typically 32-bit integers). → More on this next week. 11
15-721 (Spring 2023) DECOMPOSITIONSTORAGE MODEL (DSM) Advantages → Reduces the amount wasted I/O per query because the DBMS only reads the data that it needs. → Faster query processing because of increased locality and cached data reuse. → Better data compression (more on this later) Disadvantages → Slow for point queries, inserts, updates, and deletes because of tuple splitting/stitching/reorganization. 13
21.
15-721 (Spring 2023) OBSERVATION OLAPqueries almost never access a single column in a table by itself. → At some point during query execution, the DBMS must get other columns and stitch the original tuple back together. But we still need to store data in a columnar format to get the storage + execution benefits. We need columnar scheme that still stores attributes separately but keeps the data for each tuple physically close to each other… 14
22.
15-721 (Spring 2023) PAXSTORAGE MODEL Partition Attributes Across (PAX) is a hybrid storage model that vertically partitions attributes within a database page. → This is what Paraquet and Orc use. The goal is to get the benefit of faster processing on columnar storage while retaining the spatial locality benefits of row storage. 15 DATA PAGE LAYOUTS FOR RELATIONAL DATABASES ON DEEP MEMORY HIERARCHIES VLDB JOURNAL 2002
23.
15-721 (Spring 2023) PAX:PHYSICAL ORGANIZATION Horizontally partition rows into groups. Then vertically partition their attributes into columns. Global header contains directory with the offsets to the file's row groups. → This is stored in the footer if the file is immutable (Parquet, Orc). Each row group contains its own meta-data header about its contents. 16 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header PAX File a0 a1 a2 b0 b1 b2 c0 c1 c2 header Row Group
24.
15-721 (Spring 2023) PAX:PHYSICAL ORGANIZATION Horizontally partition rows into groups. Then vertically partition their attributes into columns. Global header contains directory with the offsets to the file's row groups. → This is stored in the footer if the file is immutable (Parquet, Orc). Each row group contains its own meta-data header about its contents. 16 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header PAX File a0 a1 a2 b0 b1 b2 c0 c1 c2 header Row Group a3 a4 a5 b3 b4 b5 c3 c4 c5 header Row Group
25.
15-721 (Spring 2023) PAX:PHYSICAL ORGANIZATION Horizontally partition rows into groups. Then vertically partition their attributes into columns. Global header contains directory with the offsets to the file's row groups. → This is stored in the footer if the file is immutable (Parquet, Orc). Each row group contains its own meta-data header about its contents. 16 b0 b1 b2 b3 b4 b5 a0 a1 a2 a3 a4 a5 c0 c1 c2 c3 c4 c5 Row #0 Row #1 Row #2 Row #3 Row #4 Row #5 Col A Col B Col C header PAX File a0 a1 a2 b0 b1 b2 c0 c1 c2 header Row Group a3 a4 a5 b3 b4 b5 c3 c4 c5 header Row Group
26.
15-721 (Spring 2023) MEMORYPAGES An OLAP DBMS uses the buffer pool manager methods that we discussed in the intro course. OS maps physical pages to virtual memory pages. The CPU's MMU maintains a TLB that contains the physical address of a virtual memory page. → The TLB resides in the CPU caches. → It cannot obviously store every possible entry for a large memory machine. When you allocate a block of memory, the allocator keeps that it aligned to page boundaries. 18
27.
15-721 (Spring 2023) TRANSPARENTHUGE PAGES (THP) Instead of always allocating memory in 4 KB pages, Linux supports creating larger pages (2MB to 1GB) → Each page must be a contiguous blocks of memory. → Greatly reduces the # of TLB entries With THP, the OS reorganizes pages in the background to keep things compact. → Split larger pages into smaller pages. → Combine smaller pages into larger pages. → Can cause the DBMS process to stall on memory access. 19 Source: Alexandr Nikitin
28.
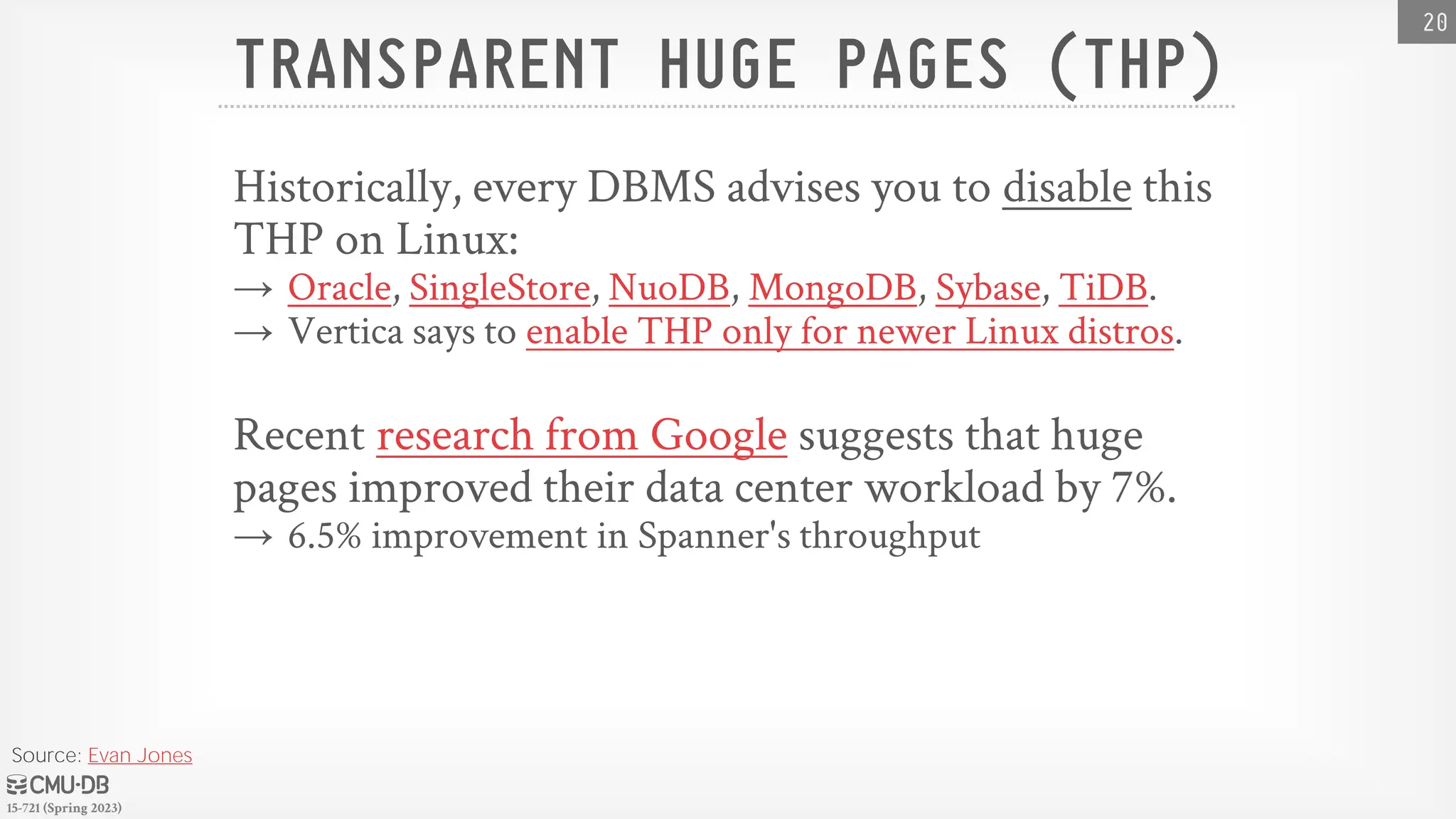
15-721 (Spring 2023) TRANSPARENTHUGE PAGES (THP) Historically, every DBMS advises you to disable this THP on Linux: → Oracle, SingleStore, NuoDB, MongoDB, Sybase, TiDB. → Vertica says to enable THP only for newer Linux distros. Recent research from Google suggests that huge pages improved their data center workload by 7%. → 6.5% improvement in Spanner's throughput 20 Source: Evan Jones
29.
15-721 (Spring 2023) TRANSPARENTHUGE PAGES (THP) Historically, every DBMS advises you to disable this THP on Linux: → Oracle, SingleStore, NuoDB, MongoDB, Sybase, TiDB. → Vertica says to enable THP only for newer Linux distros. Recent research from Google suggests that huge pages improved their data center workload by 7%. → 6.5% improvement in Spanner's throughput 20 Source: Evan Jones
30.
15-721 (Spring 2023) DATAREPRESENTATION INTEGER/BIGINT/SMALLINT/TINYINT → C/C++ Representation FLOAT/REAL vs. NUMERIC/DECIMAL → IEEE-754 Standard / Fixed-point Decimals TIME/DATE/TIMESTAMP → 32/64-bit int of (micro/milli)seconds since Unix epoch VARCHAR/VARBINARY/TEXT/BLOB → Pointer to other location if type is ≥64-bits → Header with length and address to next location (if segmented), followed by data bytes. → Most DBMSs use dictionary compression for these. 21
31.
15-721 (Spring 2023) VARIABLEPRECISION NUMBERS Inexact, variable-precision numeric type that uses the "native" C/C++ types. Store directly as specified by IEEE-754. → Example: FLOAT, REAL/DOUBLE These types are typically faster than fixed precision numbers because CPU ISA's (Xeon, Arm) have instructions / registers to support them. But they do not guarantee exact values… 22
32.
15-721 (Spring 2023) VARIABLEPRECISION NUMBERS 23 #include <stdio.h> int main(int argc, char* argv[]) { float x = 0.1; float y = 0.2; printf("x+y = %fn", x+y); printf("0.3 = %fn", 0.3); } Rounding Example x+y = 0.300000 0.3 = 0.300000 Output
15-721 (Spring 2023) FIXEDPRECISION NUMBERS Numeric data types with (potentially) arbitrary precision and scale. Used when rounding errors are unacceptable. → Example: NUMERIC, DECIMAL Many different implementations. → Example: Store in an exact, variable-length binary representation with additional meta-data. → Can be less expensive if the DBMS does not provide arbitrary precision (e.g., decimal point can be in a different position per value). 24
35.
15-721 (Spring 2023) FIXEDPRECISION NUMBERS Numeric data types with (potentially) arbitrary precision and scale. Used when rounding errors are unacceptable. → Example: NUMERIC, DECIMAL Many different implementations. → Example: Store in an exact, variable-length binary representation with additional meta-data. → Can be less expensive if the DBMS does not provide arbitrary precision (e.g., decimal point can be in a different position per value). 24
36.
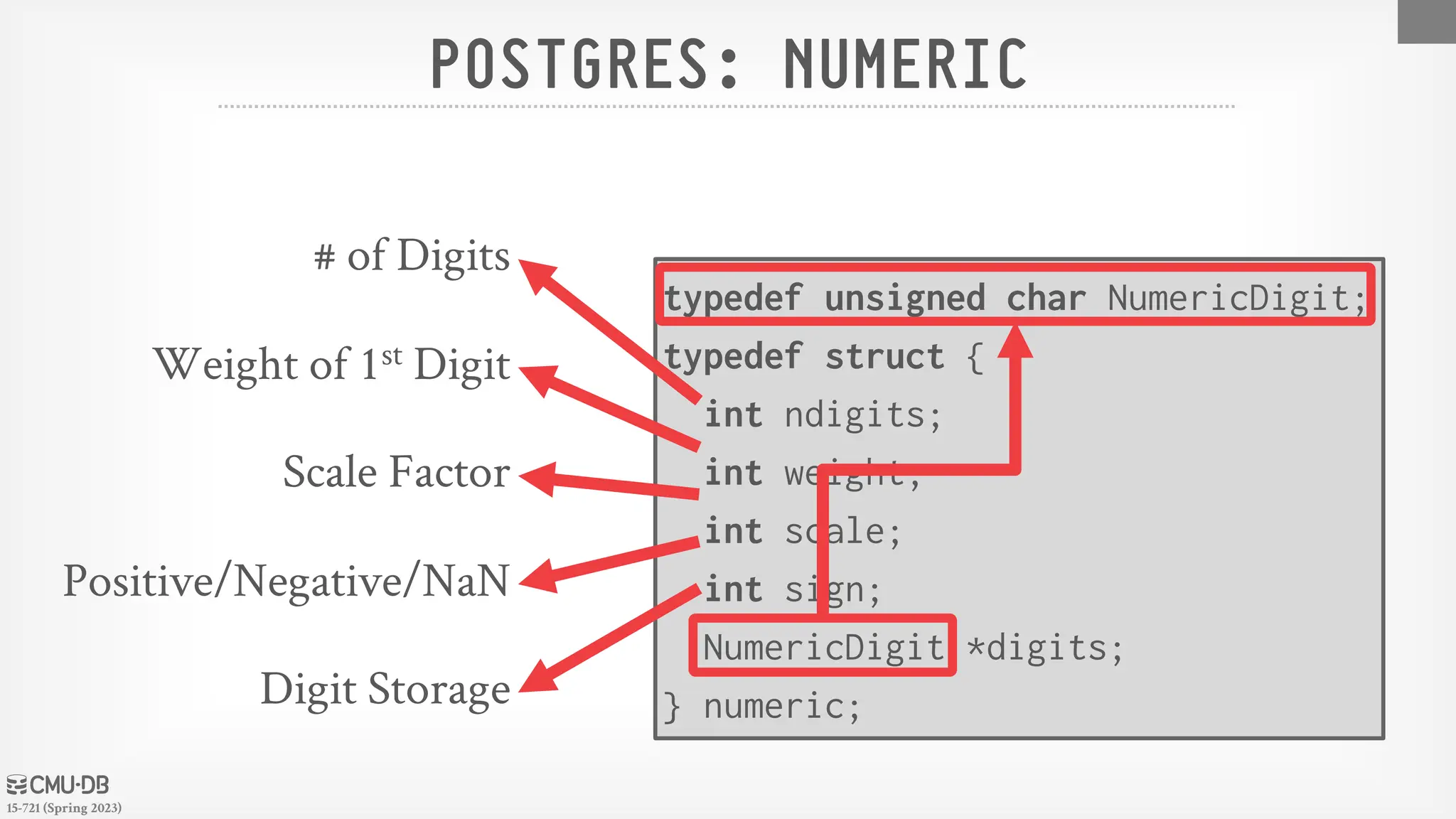
15-721 (Spring 2023) POSTGRES:NUMERIC 25 typedef unsigned char NumericDigit; typedef struct { int ndigits; int weight; int scale; int sign; NumericDigit *digits; } numeric; # of Digits Weight of 1st Digit Scale Factor Positive/Negative/NaN Digit Storage
37.
15-721 (Spring 2023) POSTGRES:NUMERIC 25 typedef unsigned char NumericDigit; typedef struct { int ndigits; int weight; int scale; int sign; NumericDigit *digits; } numeric; # of Digits Weight of 1st Digit Scale Factor Positive/Negative/NaN Digit Storage
38.
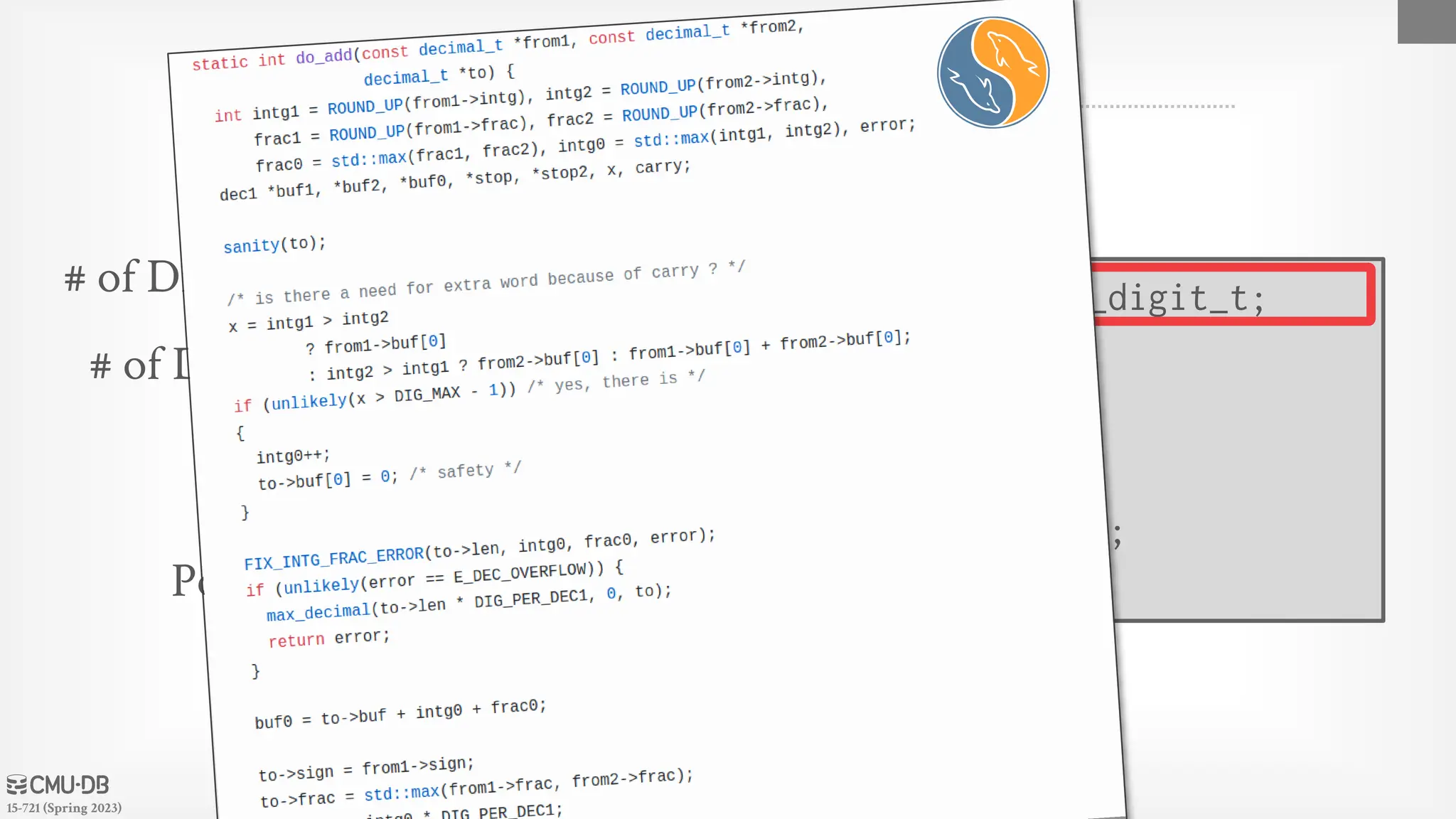
15-721 (Spring 2023) MYSQL:NUMERIC 26 typedef int32 decimal_digit_t; struct decimal_t { int intg, frac, len; bool sign; decimal_digit_t *buf; }; # of Digits Before Point # of Digits After Point Length (Bytes) Positive/Negative Digit Storage
39.
15-721 (Spring 2023) MYSQL:NUMERIC 26 typedef int32 decimal_digit_t; struct decimal_t { int intg, frac, len; bool sign; decimal_digit_t *buf; }; # of Digits Before Point # of Digits After Point Length (Bytes) Positive/Negative Digit Storage
40.
15-721 (Spring 2023) NULLDATA TYPES Choice #1: Special Values → Designate a value to represent NULL for a data type (e.g., INT32_MIN). Choice #2: Null Column Bitmap Header → Store a bitmap in a centralized header that specifies what attributes are null. Choice #3: Per Attribute Null Flag → Store a flag that marks that a value is null. → Must use more space than just a single bit because this messes up with word alignment. 27
41.
15-721 (Spring 2023) NULLDATA TYPES Choice #1: Special Values → Designate a value to represent NULL for a data type (e.g., INT32_MIN). Choice #2: Null Column Bitmap Header → Store a bitmap in a centralized header that specifies what attributes are null. Choice #3: Per Attribute Null Flag → Store a flag that marks that a value is null. → Must use more space than just a single bit because this messes up with word alignment. 27
42.
15-721 (Spring 2023) OBSERVATION Datais "hot" when it enters the database → A newly inserted tuple is more likely to be updated again the near future. As a tuple ages, it is updated less frequently. → At some point, a tuple is only accessed in read-only queries along with other tuples. 28
43.
15-721 (Spring 2023) HYBRIDSTORAGE MODEL Use separate execution engines that are optimized for either NSM or DSM databases. → Store new data in NSM for fast OLTP. → Migrate data to DSM for more efficient OLAP. → Combine query results from both engines to appear as a single logical database to the application. Choice #1: Fractured Mirrors → Examples: Oracle, IBM DB2 Blu, Microsoft SQL Server Choice #2: Delta Store → Examples: SAP HANA, Vertica, SingleStore, Databricks, Google Napa 29
44.
15-721 (Spring 2023) FRACTUREDMIRRORS Store a second copy of the database in a DSM layout that is automatically updated. → All updates are first entered in NSM then eventually copied into DSM mirror. → If the DBMS supports updates, it must invalidate tuples in the DSM mirror. 30 A CASE FOR FRACTURED MIRRORS VLDB 2002 NSM (Primary) DSM (Mirror) Transactions Analytical Queries
45.
15-721 (Spring 2023) DELTASTORE Stage updates to the database in an NSM table. A background thread migrates updates from delta store and applies them to DSM data. → Batch large chunks and then write them out as a PAX file. 31 NSM Delta Store DSM Historical Data Transactions
46.
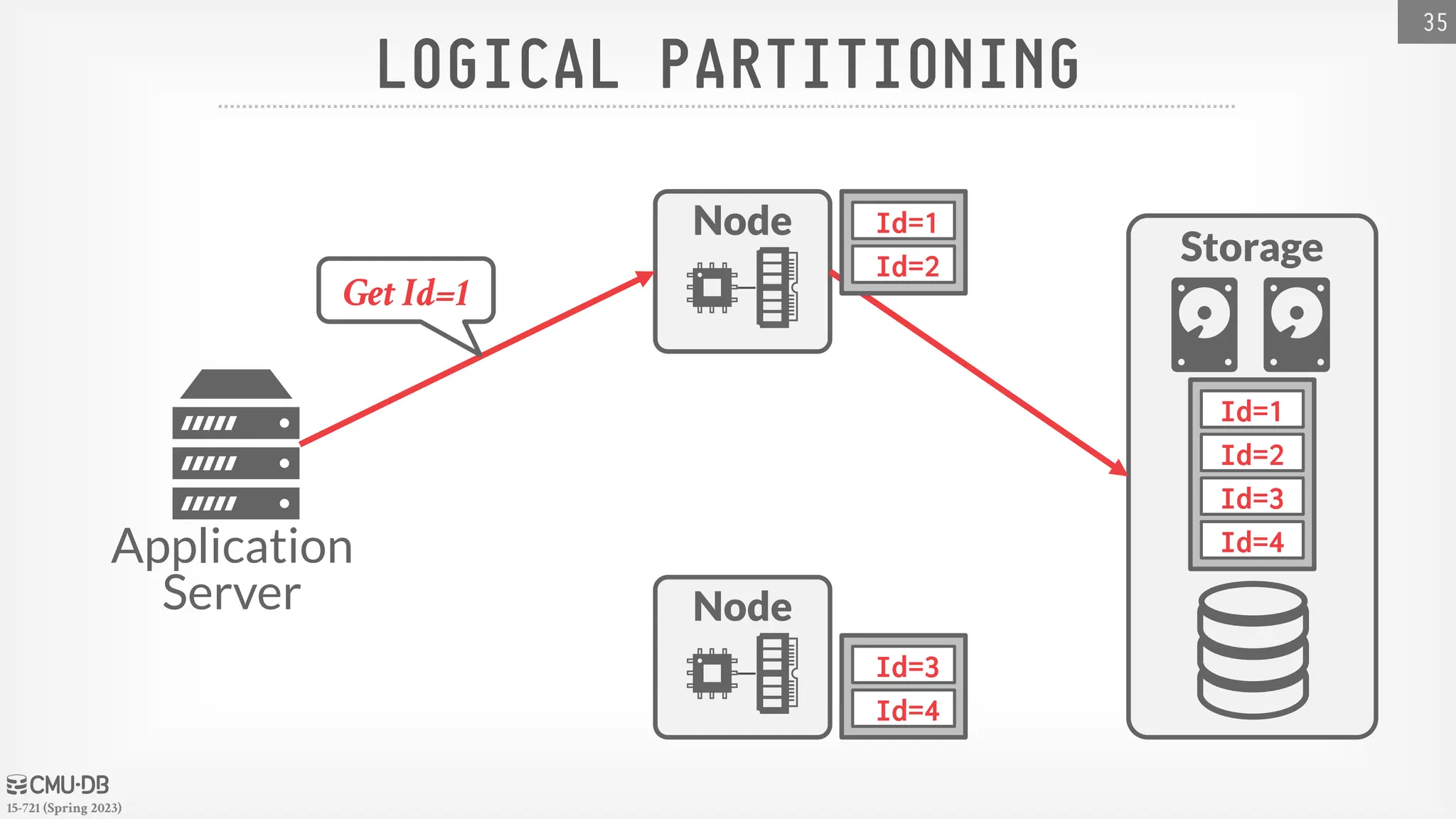
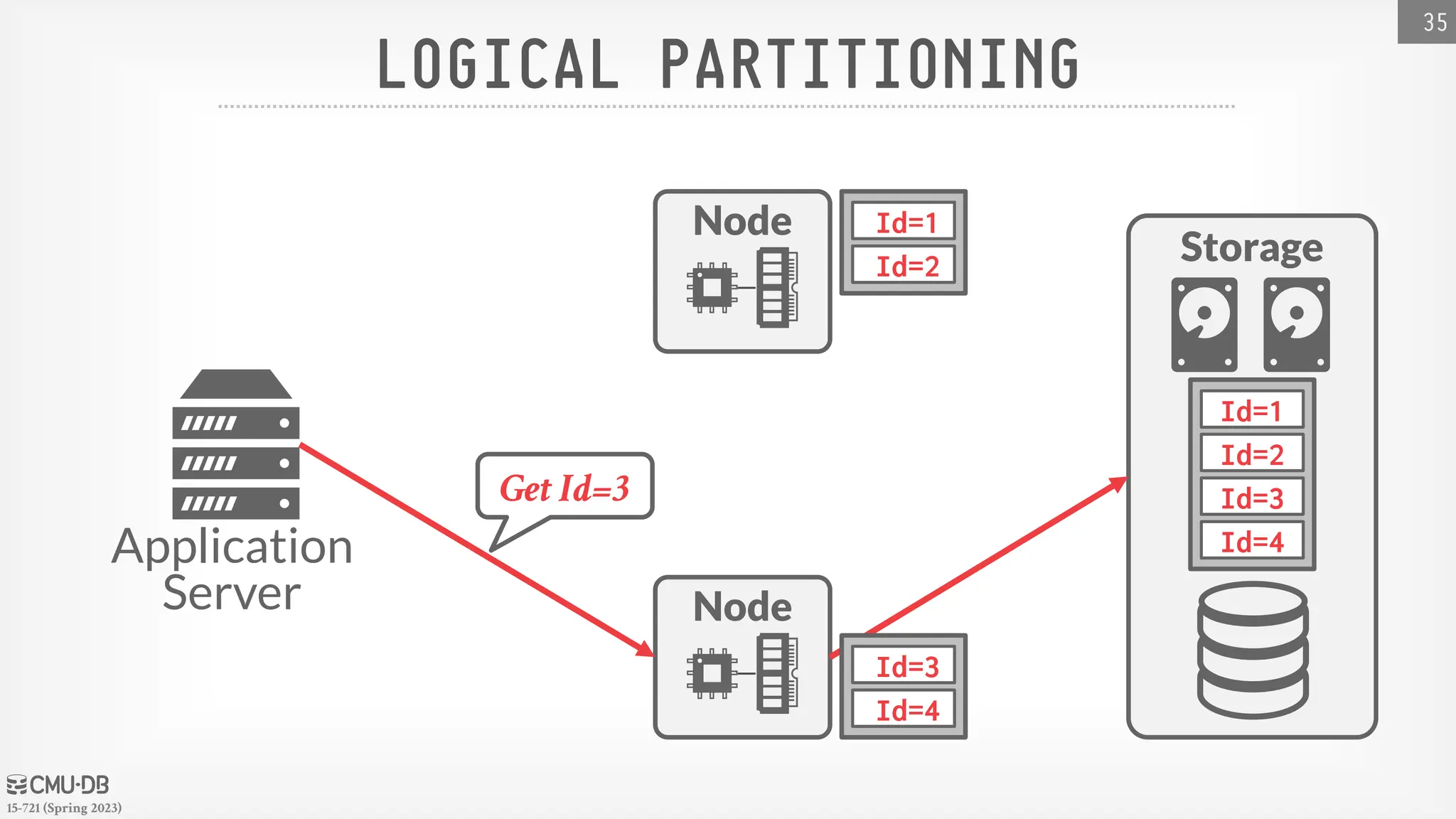
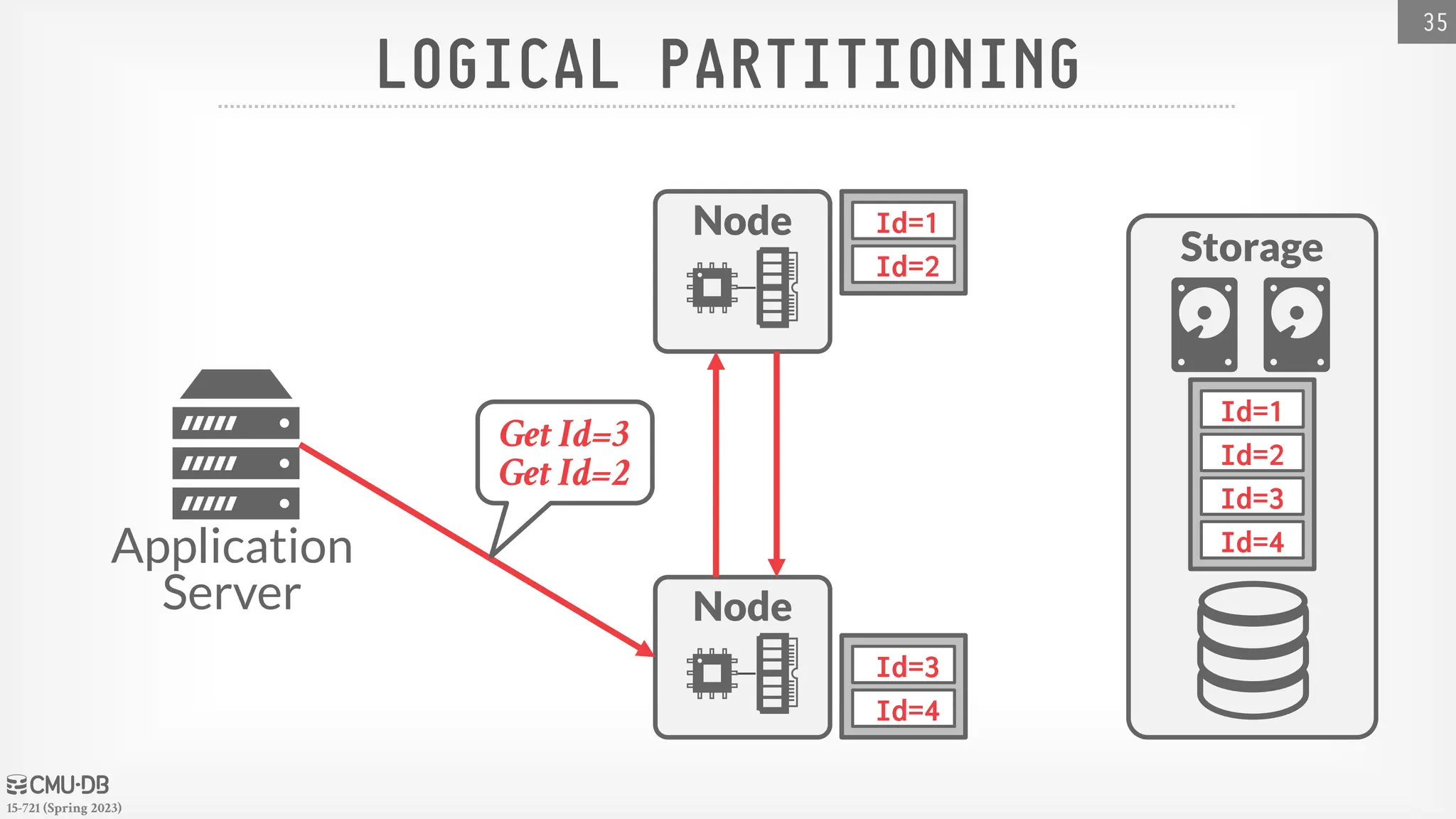
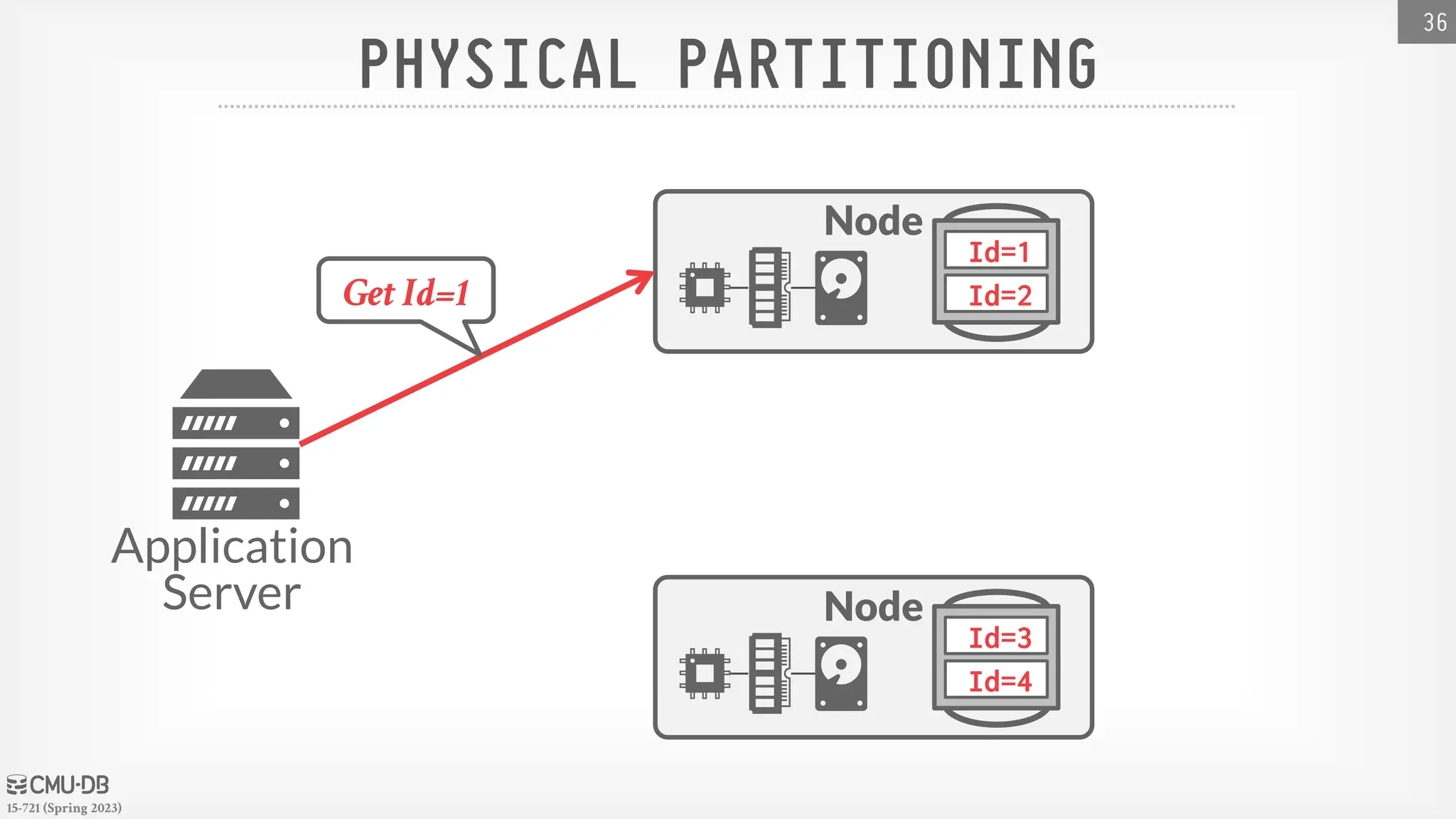
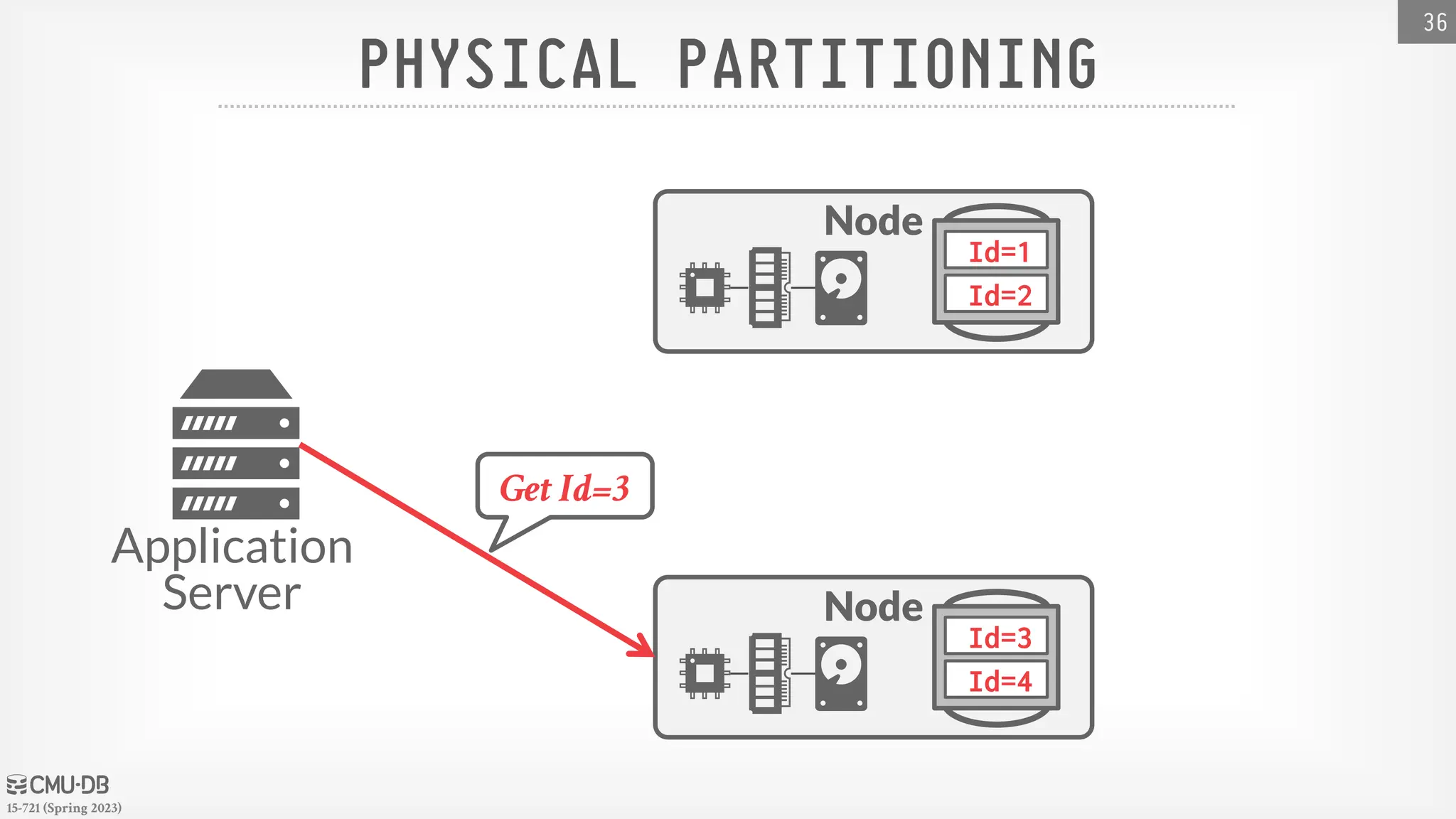
15-721 (Spring 2023) DATABASEPARTITIONING Split database across multiple resources: → Disks, nodes, processors. → Often called "sharding" in NoSQL systems. The DBMS executes query fragments on each partition and then combines the results to produce a single answer. The DBMS can partition a database physically (shared nothing) or logically (shared disk). 32
47.
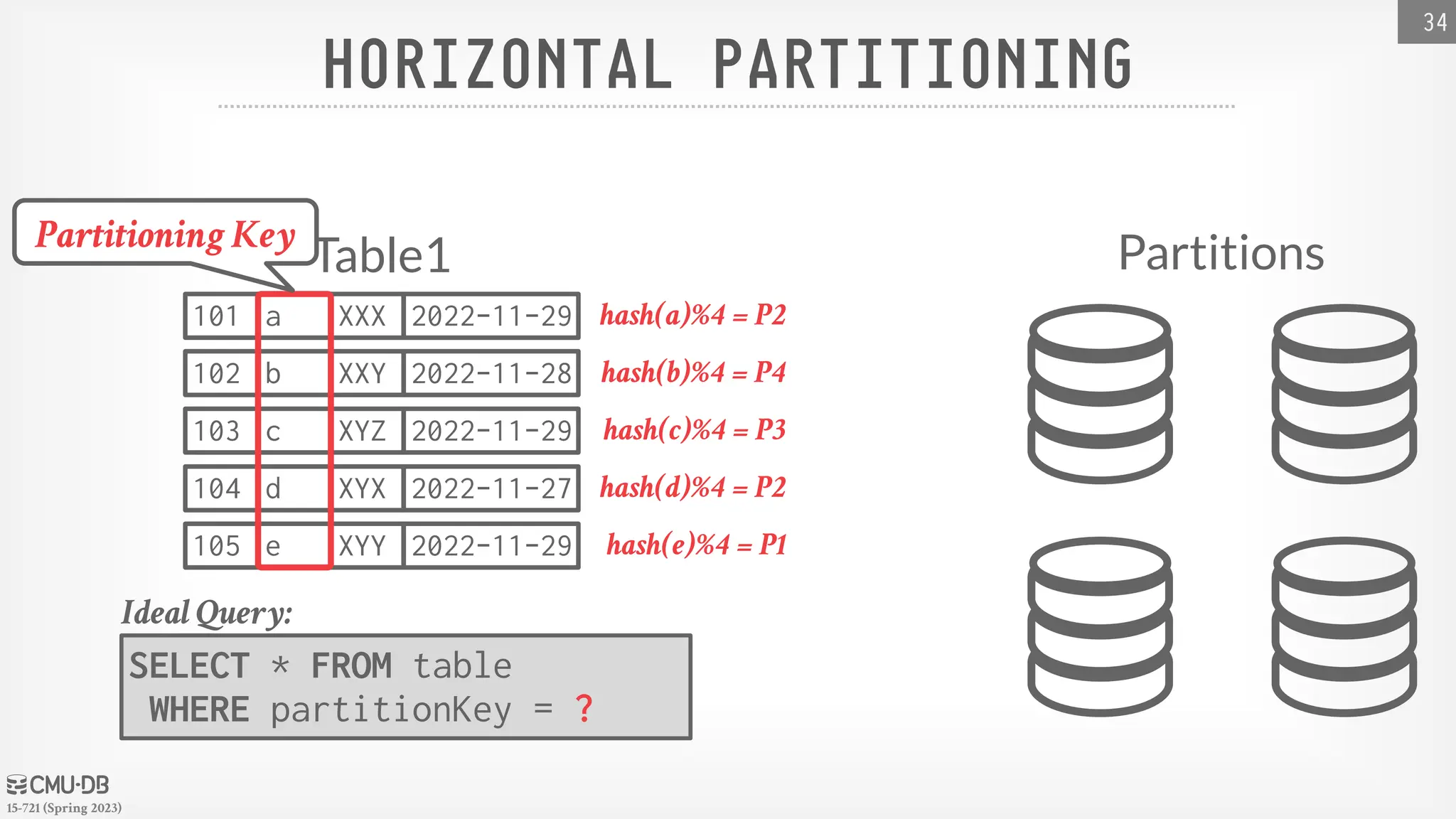
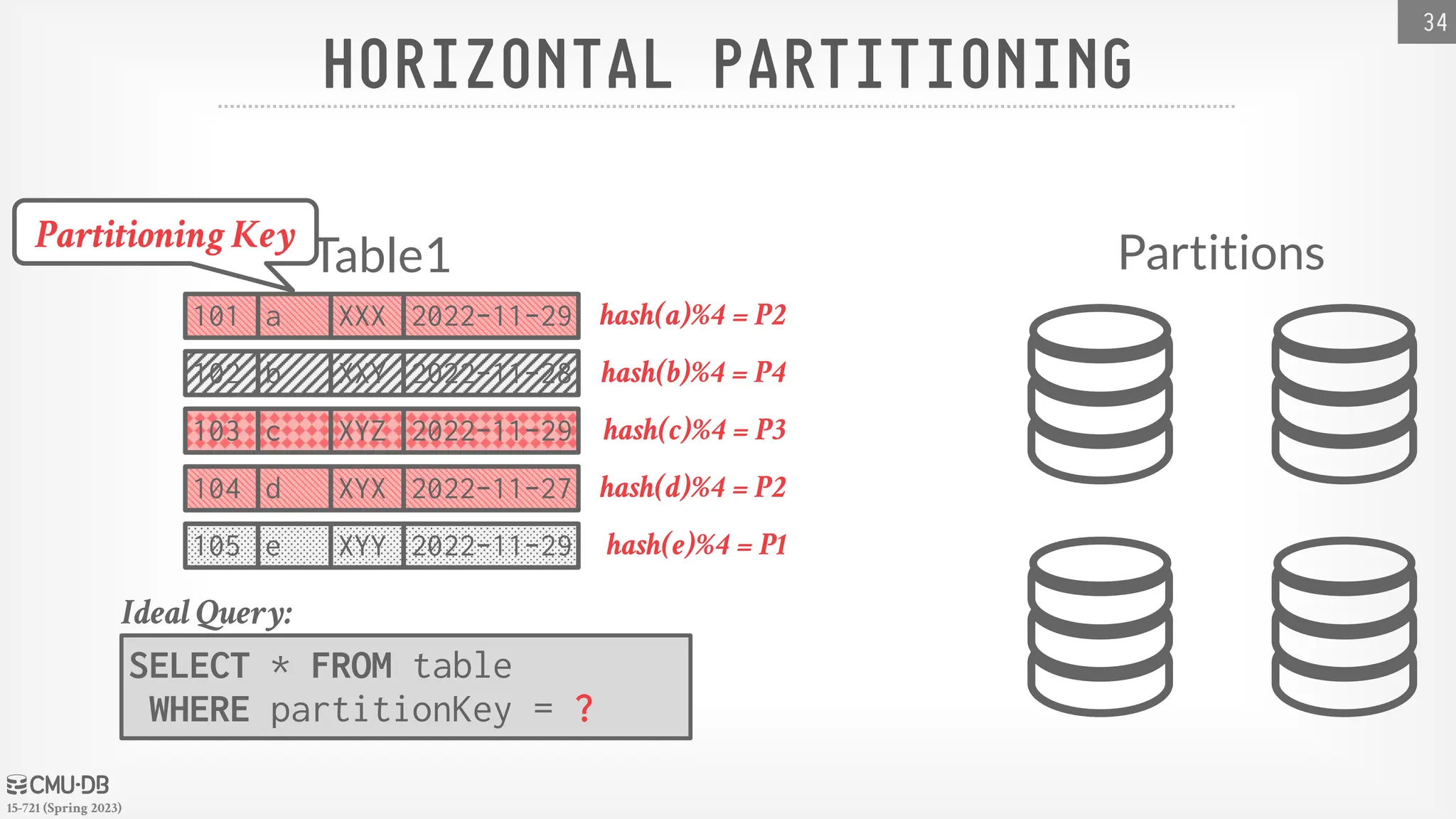
15-721 (Spring 2023) HORIZONTALPARTITIONING Split a table's tuples into disjoint subsets based on some partitioning key and scheme. → Choose column(s) that divides the database equally in terms of size, load, or usage. Partitioning Schemes: → Hashing → Ranges → Predicates 33
48.
15-721 (Spring 2023) HORIZONTALPARTITIONING 34 SELECT * FROM table WHERE partitionKey = ? Ideal Query: Partitions Table1 101 a XXX 2022-11-29 102 b XXY 2022-11-28 103 c XYZ 2022-11-29 104 d XYX 2022-11-27 105 e XYY 2022-11-29 hash(a)%4 = P2 hash(b)%4 = P4 hash(c)%4 = P3 hash(d)%4 = P2 hash(e)%4 = P1 Partitioning Key
49.
15-721 (Spring 2023) HORIZONTALPARTITIONING 34 SELECT * FROM table WHERE partitionKey = ? Ideal Query: Partitions Table1 101 a XXX 2022-11-29 102 b XXY 2022-11-28 103 c XYZ 2022-11-29 104 d XYX 2022-11-27 105 e XYY 2022-11-29 hash(a)%4 = P2 hash(b)%4 = P4 hash(c)%4 = P3 hash(d)%4 = P2 hash(e)%4 = P1 Partitioning Key
50.
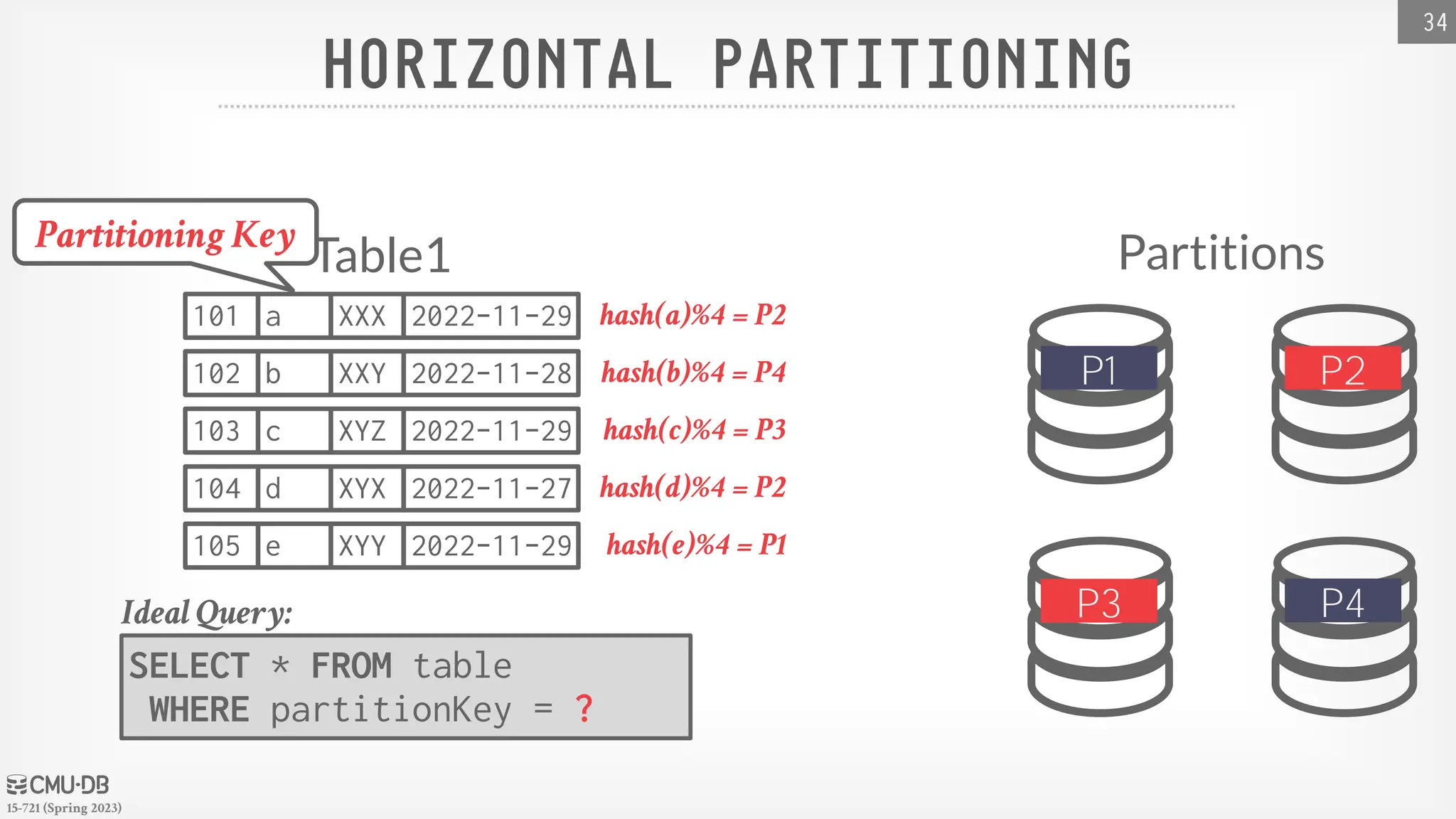
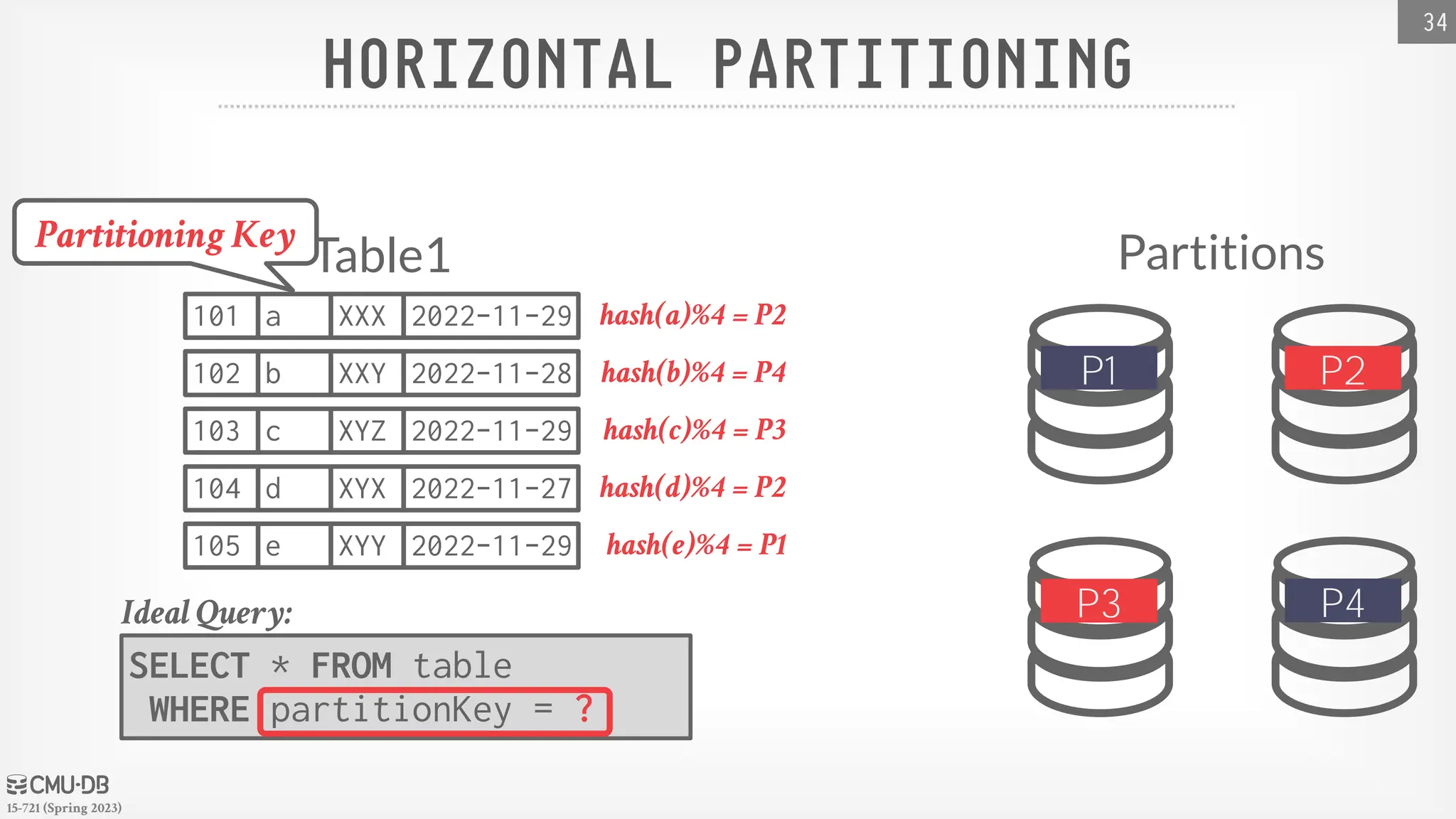
15-721 (Spring 2023) HORIZONTALPARTITIONING 34 SELECT * FROM table WHERE partitionKey = ? Ideal Query: Partitions Table1 101 a XXX 2022-11-29 102 b XXY 2022-11-28 103 c XYZ 2022-11-29 104 d XYX 2022-11-27 105 e XYY 2022-11-29 P3 P4 P1 P2 hash(a)%4 = P2 hash(b)%4 = P4 hash(c)%4 = P3 hash(d)%4 = P2 hash(e)%4 = P1 Partitioning Key
51.
15-721 (Spring 2023) HORIZONTALPARTITIONING 34 SELECT * FROM table WHERE partitionKey = ? Ideal Query: Partitions Table1 101 a XXX 2022-11-29 102 b XXY 2022-11-28 103 c XYZ 2022-11-29 104 d XYX 2022-11-27 105 e XYY 2022-11-29 P3 P4 P1 P2 hash(a)%4 = P2 hash(b)%4 = P4 hash(c)%4 = P3 hash(d)%4 = P2 hash(e)%4 = P1 Partitioning Key
15-721 (Spring 2023) PARTINGTHOUGHTS Every modern OLAP system is using some variant of PAX storage. The key idea is that all data must be fixed-length. Real-world tables contain mostly numeric attributes (int/float), but their occupied storage is mostly comprised of string data. Modern columnar systems are so fast that most people do not denormalize data warehouse schemas. 37
58.
15-721 (Spring 2023) NEXTCLASS How to accelerate OLAP queries on columnar data with auxiliary data structures. → Zone Maps → Bitmap Indexes → Sketches We will also discuss Project #1. 38






























![15-721 (Spring 2023) VARIABLE PRECISION NUMBERS 23 #include <stdio.h> int main(int argc, char* argv[]) { float x = 0.1; float y = 0.2; printf("x+y = %fn", x+y); printf("0.3 = %fn", 0.3); } Rounding Example x+y = 0.300000 0.3 = 0.300000 Output](https://image.slidesharecdn.com/03-storage-250408070525-fd22f6ac/75/Storage-Systems-and-Data-Layout-CMU-Advanced-Databases-32-2048.jpg)
![15-721 (Spring 2023) VARIABLE PRECISION NUMBERS 23 #include <stdio.h> int main(int argc, char* argv[]) { float x = 0.1; float y = 0.2; printf("x+y = %fn", x+y); printf("0.3 = %fn", 0.3); } Rounding Example x+y = 0.300000 0.3 = 0.300000 Output #include <stdio.h> int main(int argc, char* argv[]) { float x = 0.1; float y = 0.2; printf("x+y = %.20fn", x+y); printf("0.3 = %.20fn", 0.3); } x+y = 0.30000001192092895508 0.3 = 0.29999999999999998890](https://image.slidesharecdn.com/03-storage-250408070525-fd22f6ac/75/Storage-Systems-and-Data-Layout-CMU-Advanced-Databases-33-2048.jpg)