Pyspark training | Introduction to PySpark DataFrames
Boost your career with AccentFuture's PySpark Training! Enroll in the best PySpark course online and master Apache PySpark with expert-led PySpark online classes. Join the top PySpark training program for hands-on learning and real-world projects.
What is PySpark? PySparkis the Python API for Apache Spark, a powerful distributed computing engine. Used for big data processing with Python. Handles large-scale data with speed and scalability.
3.
What is aDataFrame in PySpark? A DataFrame is a distributed collection of data organized into named columns, like a table in a database. Similar to pandas DataFrames but optimized for big data.
4.
Why Use PySparkDataFrames? Can process terabytes of data across multiple machines. SQL-like operations on large datasets. Integrated with many big data tools (e.g., Hadoop, Hive).
Writing Data toFiles Can also write to JSON, Parquet, or Hive tables.
10.
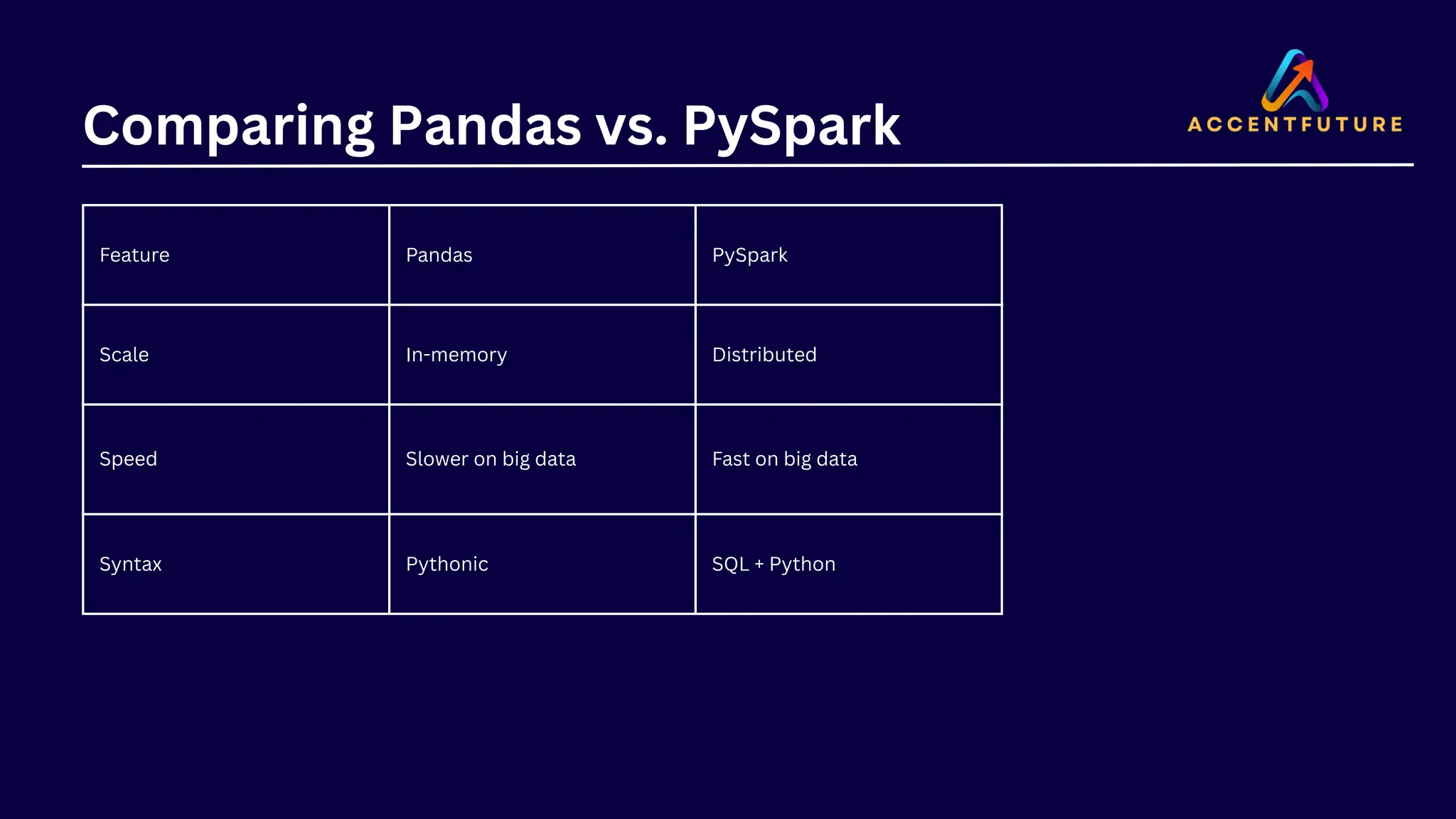
Feature Pandas PySpark ScaleIn-memory Distributed Speed Slower on big data Fast on big data Syntax Pythonic SQL + Python Comparing Pandas vs. PySpark
11.
Summary & NextSteps PySpark DataFrames make big data processing easy and efficient. Supports SQL-like operations on massive datasets. Next topics: Spark SQL, Transformations, Actions, and Joins.
12.
Contact & OnlineTraining 📢We Provide Online Training on Databricks and Big Data Technologies! ✅Hands-on Training with Real-World Use Cases ✅Live Sessions with Industry Experts ✅Job Assistance ✅Certification Guidance 🌐Visit our website: https://www.accentfuture.com/ 📩For inquiries, contact us at: contact@accentfuture.com, 📞+91-96400 01789 (Call/WhatsApp)