















![www.edureka.co/big-data-and-hadoopEDUREKA HADOOP CERTIFICATION TRAINING Pig Data Model – Map and Atom A Map is key-value pairs used to represent data elements. Example of maps− [band#Linkin Park, members#7 ], [band#Metallica, members#8 ] Atoms are basic data types which are used in all the languages like string, int, float, long, double, char[], byte[]](https://image.slidesharecdn.com/pigtutorial-apachepigscriptandcommands-hadooppigtutorial-edureka-170102105712/75/Pig-Tutorial-Twitter-Case-Study-Apache-Pig-Script-and-Commands-Edureka-26-2048.jpg)








The document outlines a training session on Apache Pig, an open-source high-level dataflow system that simplifies data processing tasks in Hadoop without requiring extensive programming knowledge. It compares Apache Pig and MapReduce, highlighting Pig's ease of use, reduced coding effort, and built-in support for common data operations. Additionally, it includes a case study on Twitter's use of Hadoop for data analysis and discusses Pig's architecture, data models, operators, and practical applications in log analysis.
Overview of Edureka's Hadoop Certification Training and the agenda including topics like Apache Pig and its architecture.
Discusses the need for programming skills in MapReduce, addressing concerns for non-programmers with alternative tools in Hadoop Ecosystem.
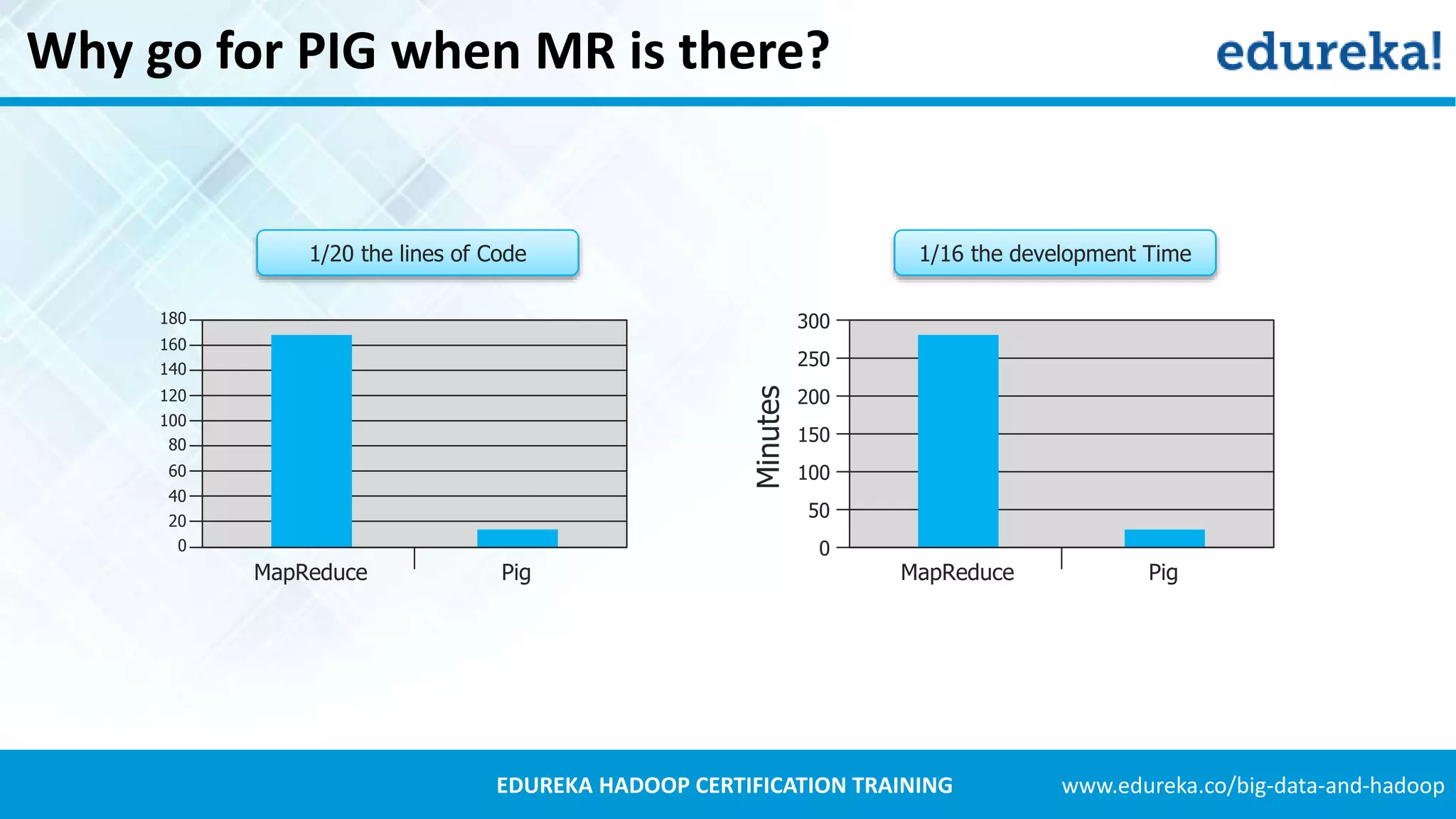
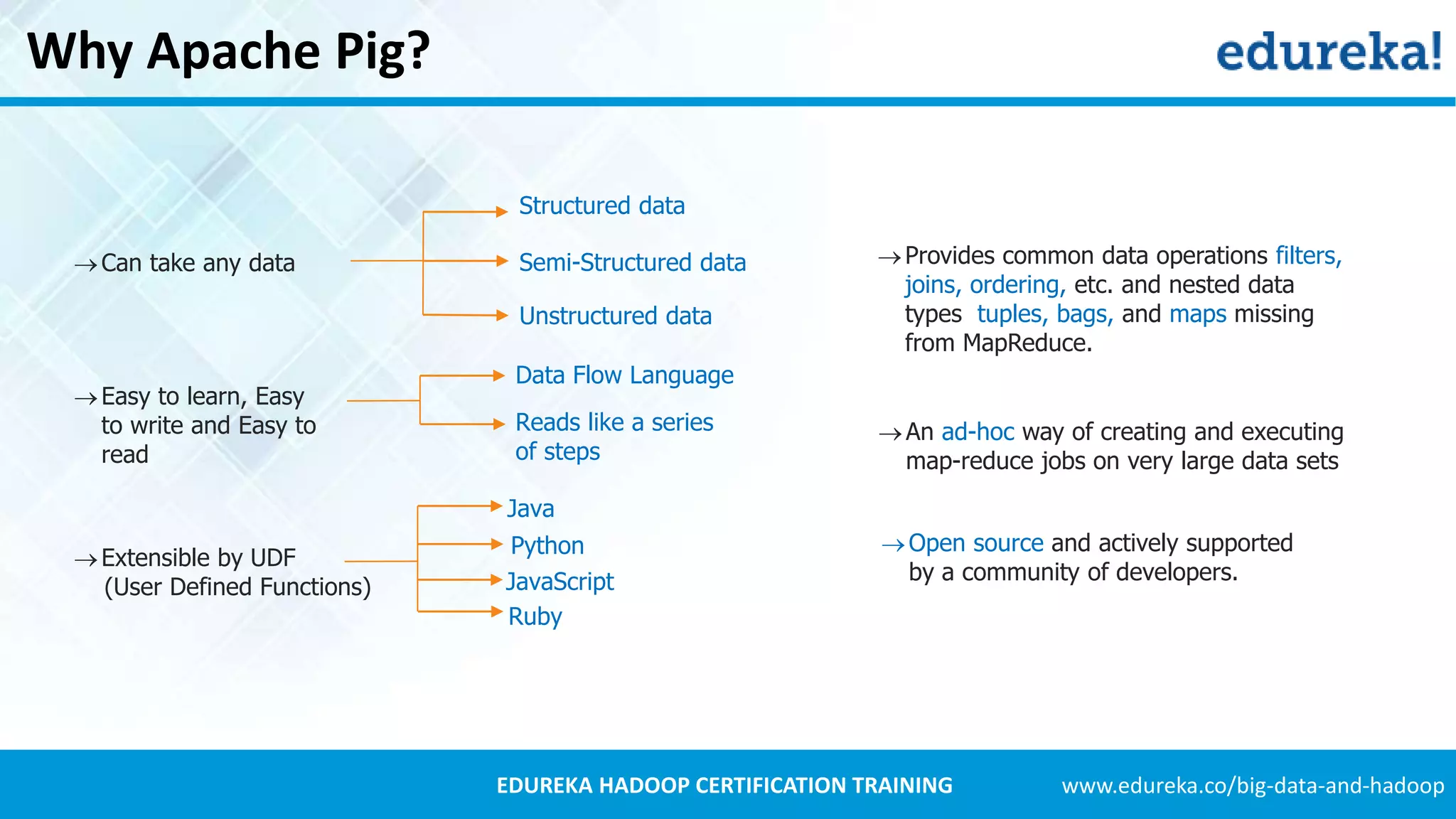
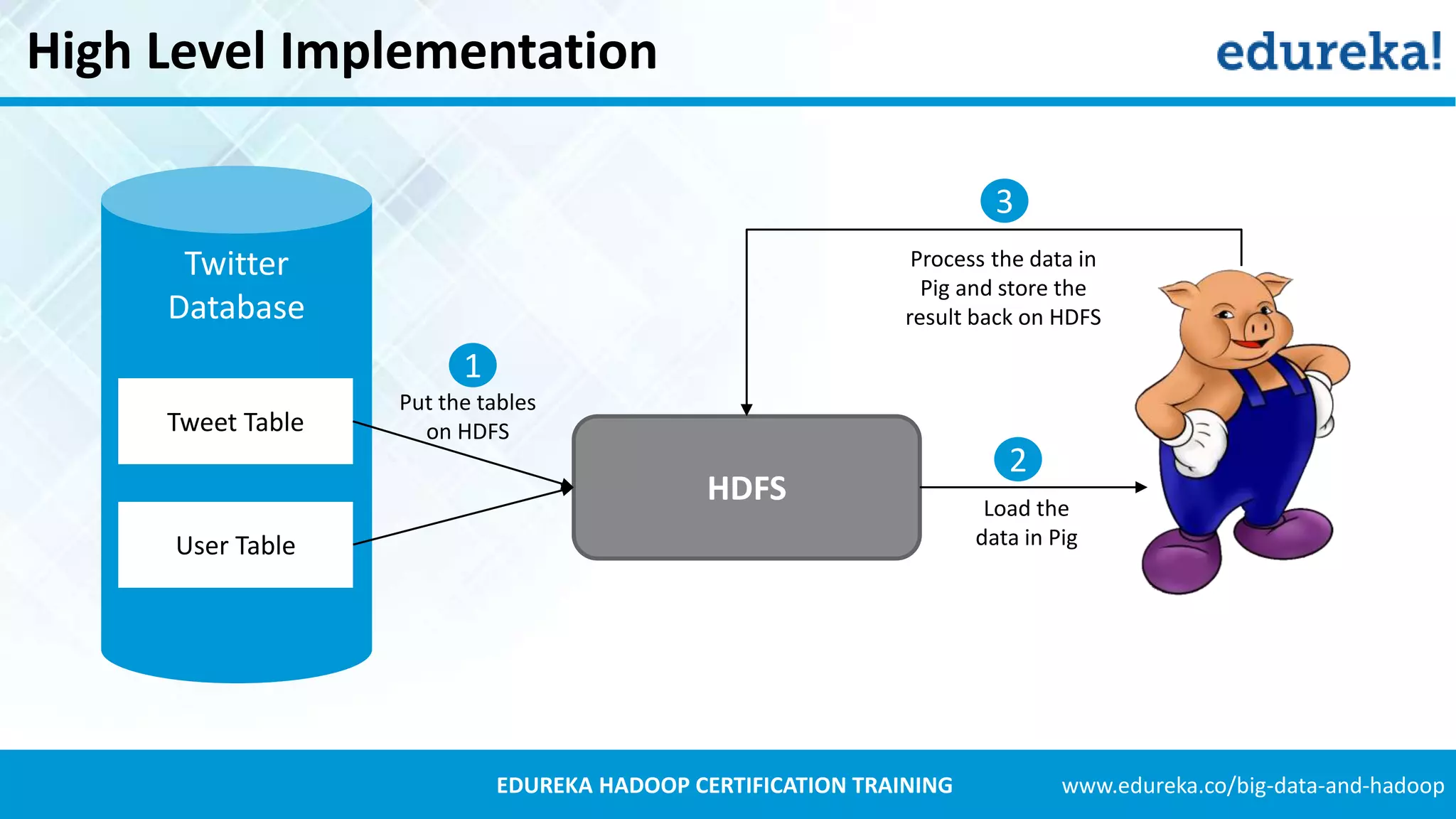
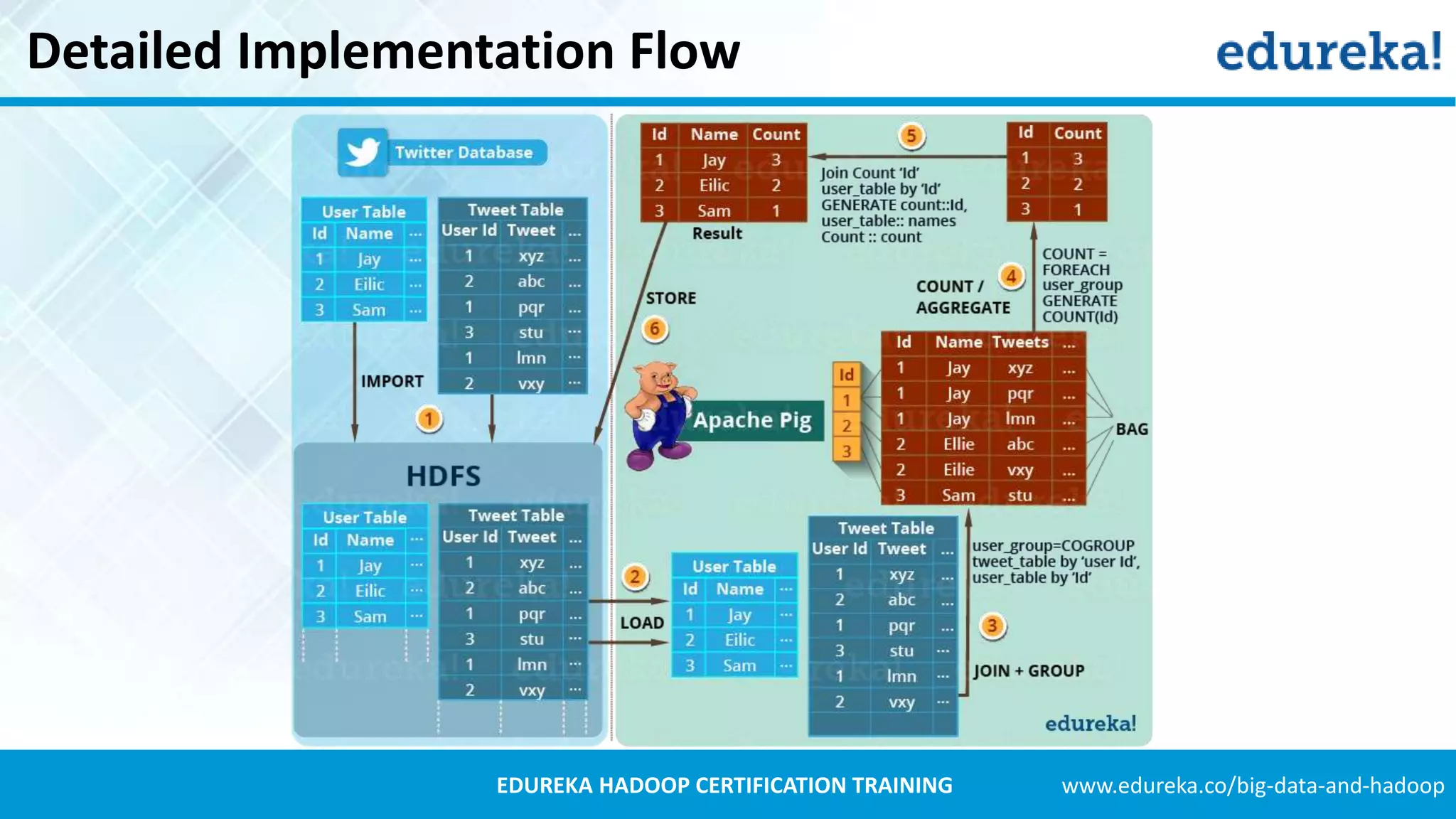
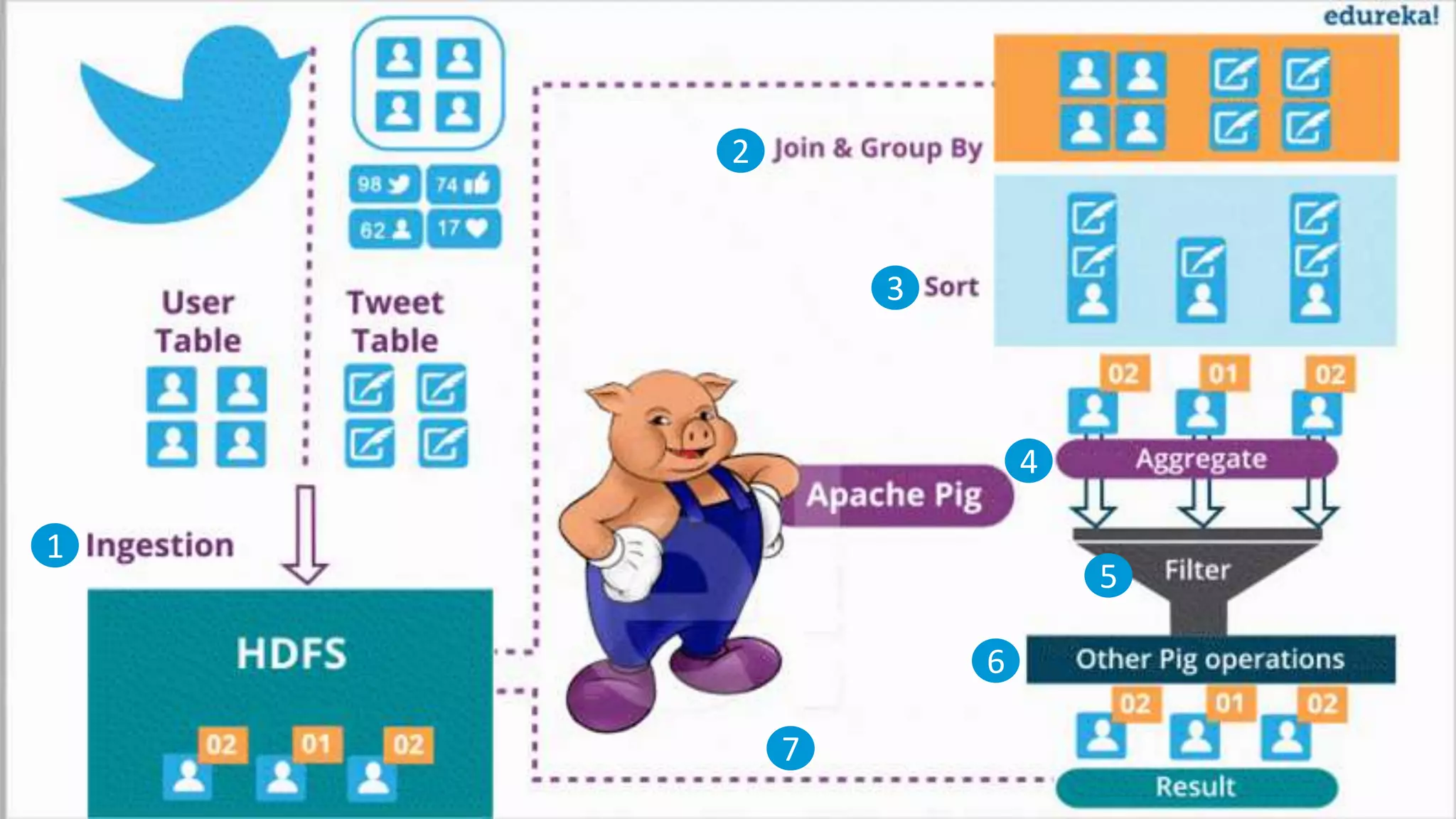
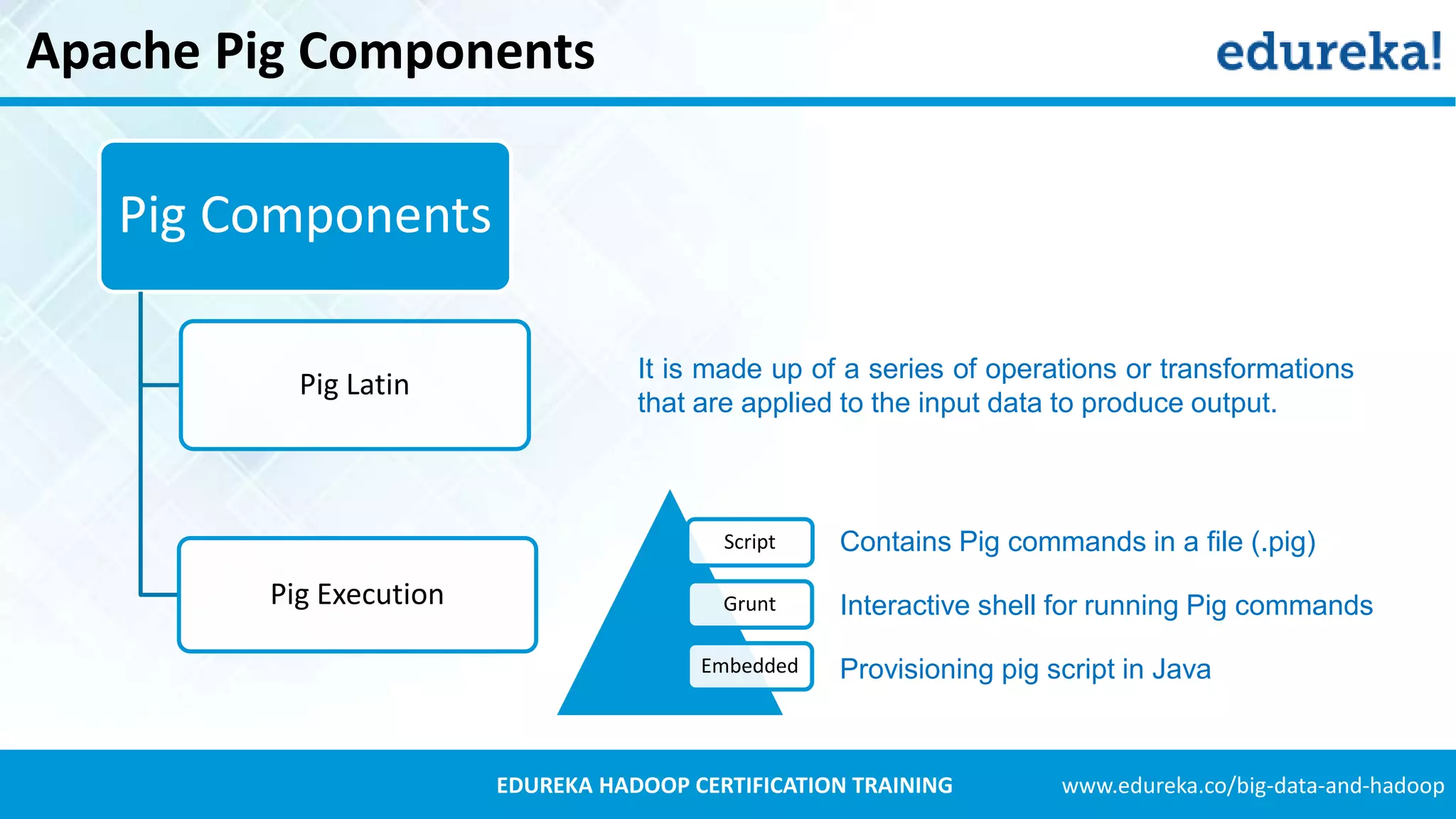
Introduction to Apache Pig, its components like Pig Latin and its advantages over MapReduce, including easy syntax and fewer lines of code.Explains Twitter's data growth, the decision to use Hadoop for data analysis, and the process of archiving tweets in HDFS.
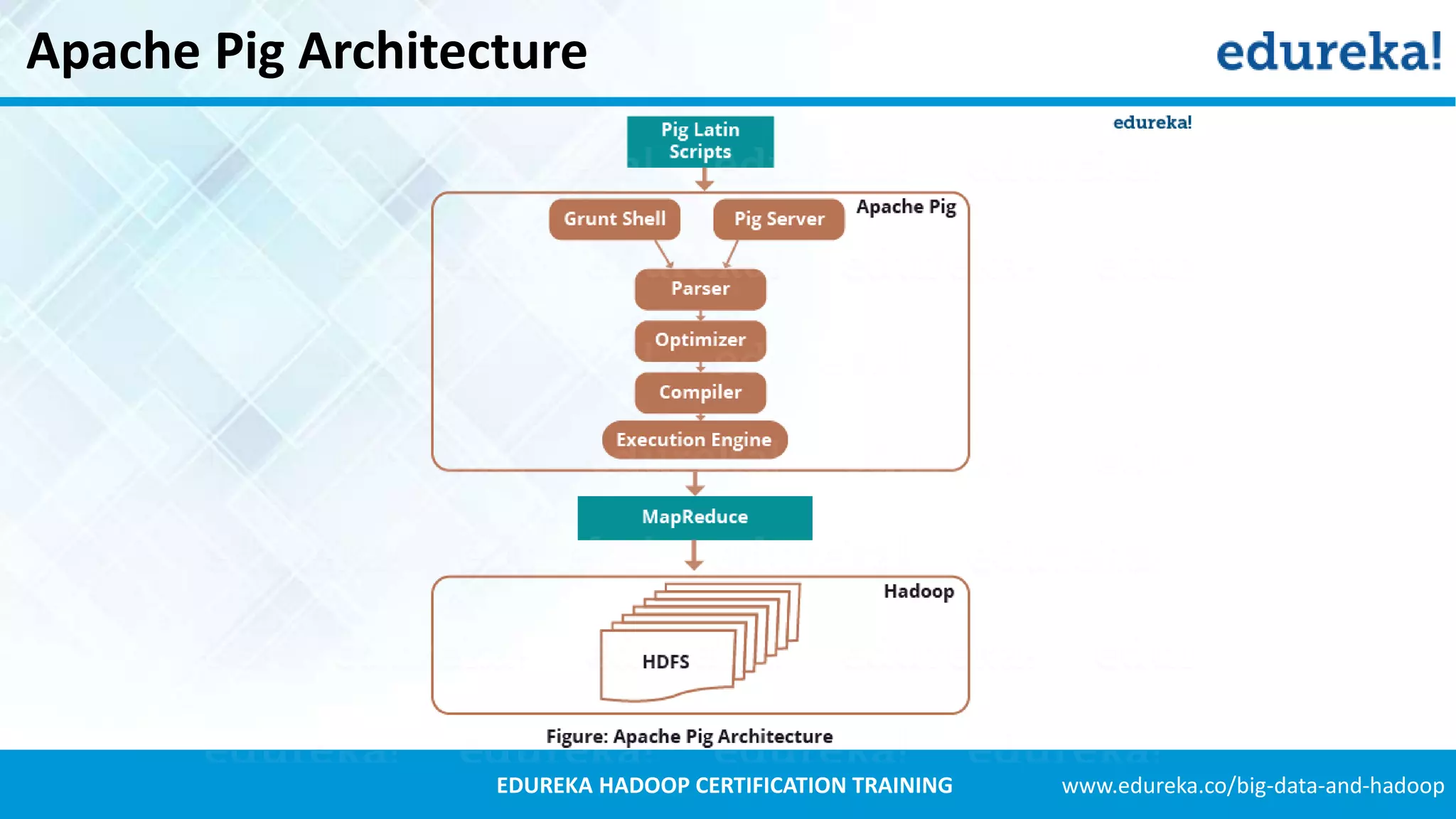
Details about the architecture of Apache Pig and its components including Pig Latin and Pig Execution.
Explains the two modes to run Apache Pig: MapReduce Mode and Local Mode, detailing their operational differences.
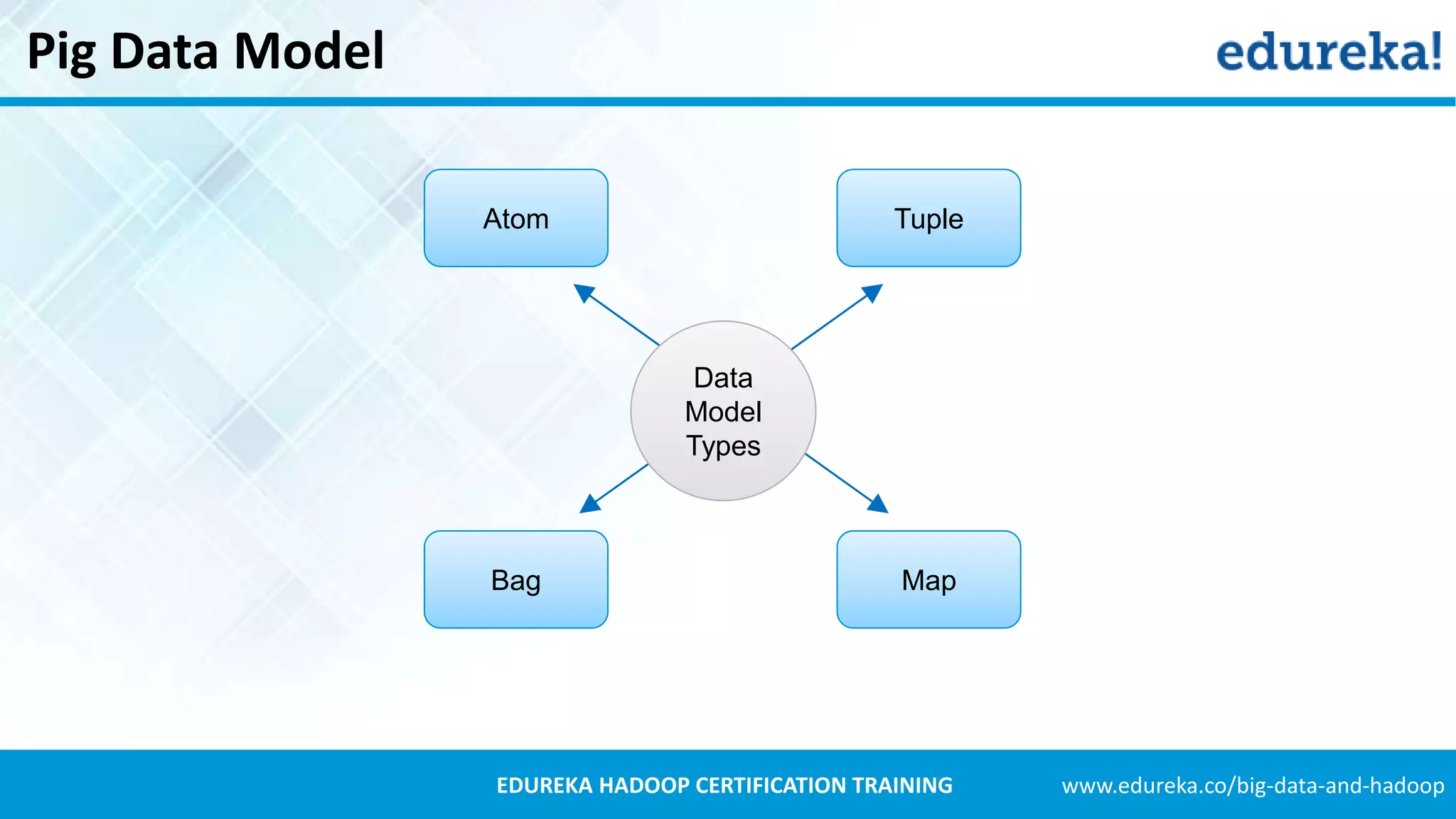
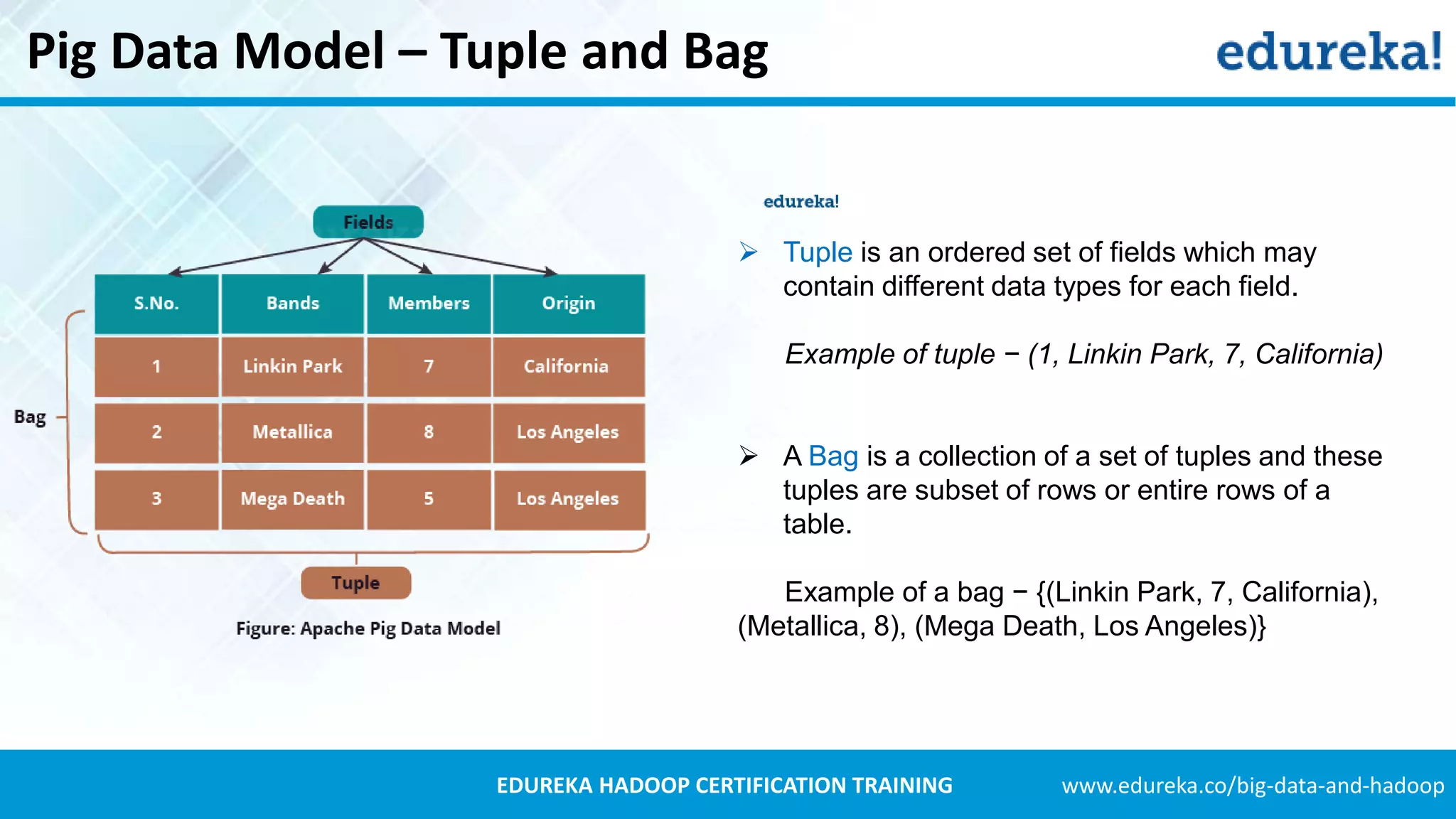
Introduces Pig's data models including Tuples, Bags, and Maps, with examples to illustrate the concepts.
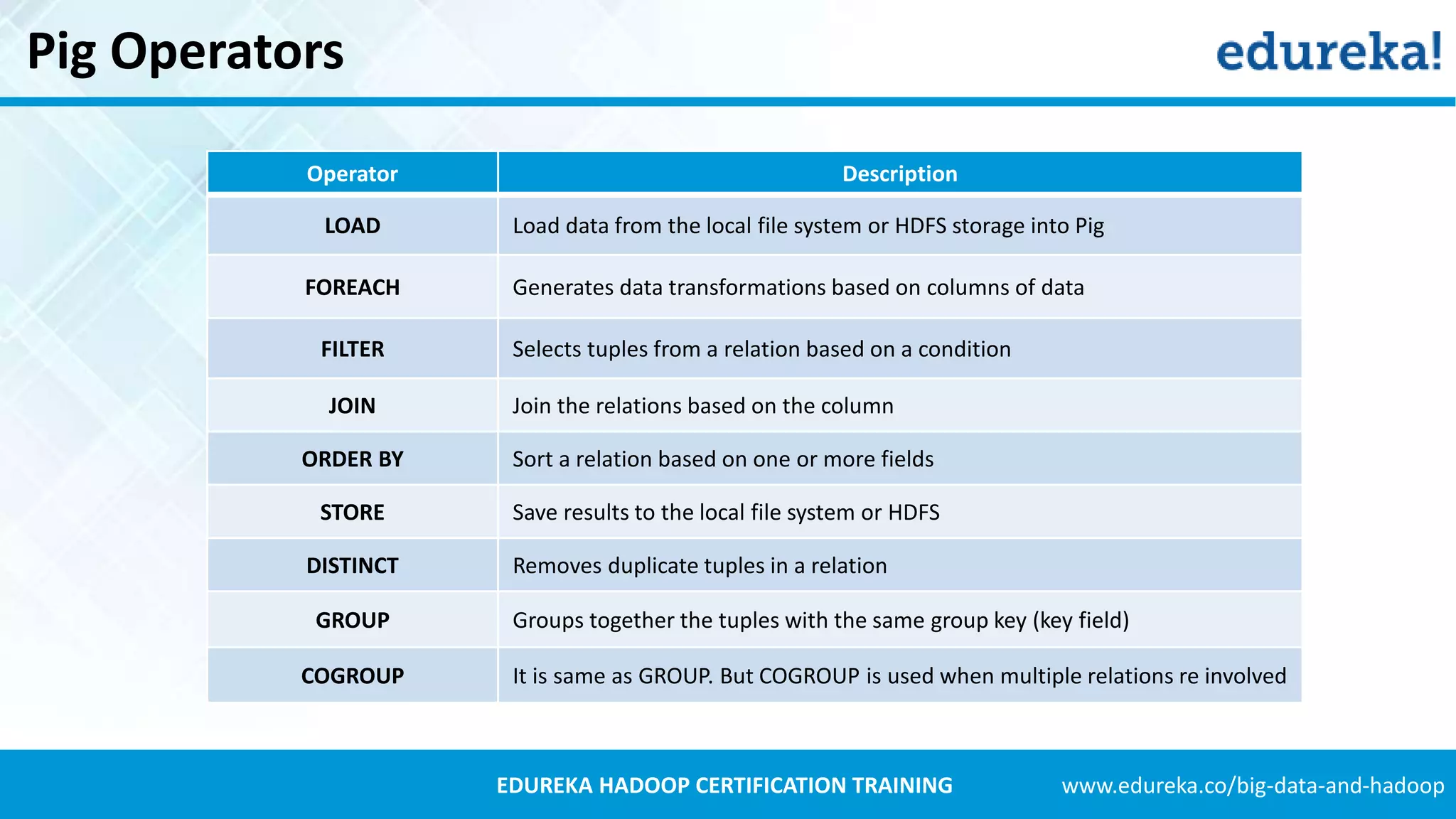
Describes various Pig operators and their functionalities such as LOAD, FILTER, JOIN, and ORDER BY.
Demonstrates executing Pig commands, analyzing log files using Pig, and creating a script to process logs.Provides links to additional learning resources on Hadoop and Pig, followed by a thank you note for queries.