Download to read offline







![9 Which Scale-out Framework ? 9 [Picture Courtesy: Amir H. Payberah]](https://image.slidesharecdn.com/phddefenseaja2017v2-171218095157/75/Performance-Characterization-and-Optimization-of-In-Memory-Data-Analytics-on-a-Scale-up-Server-9-2048.jpg)
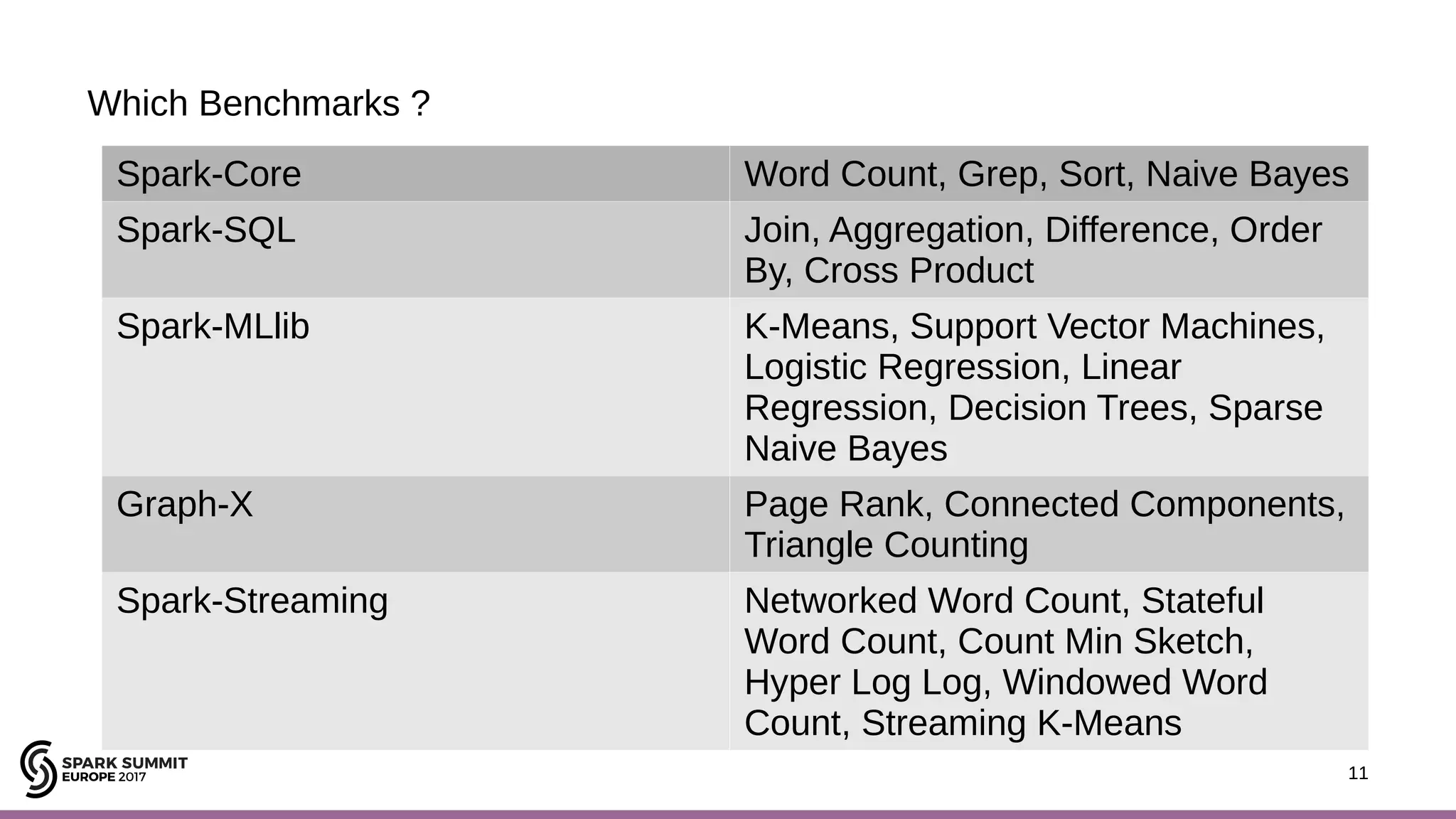
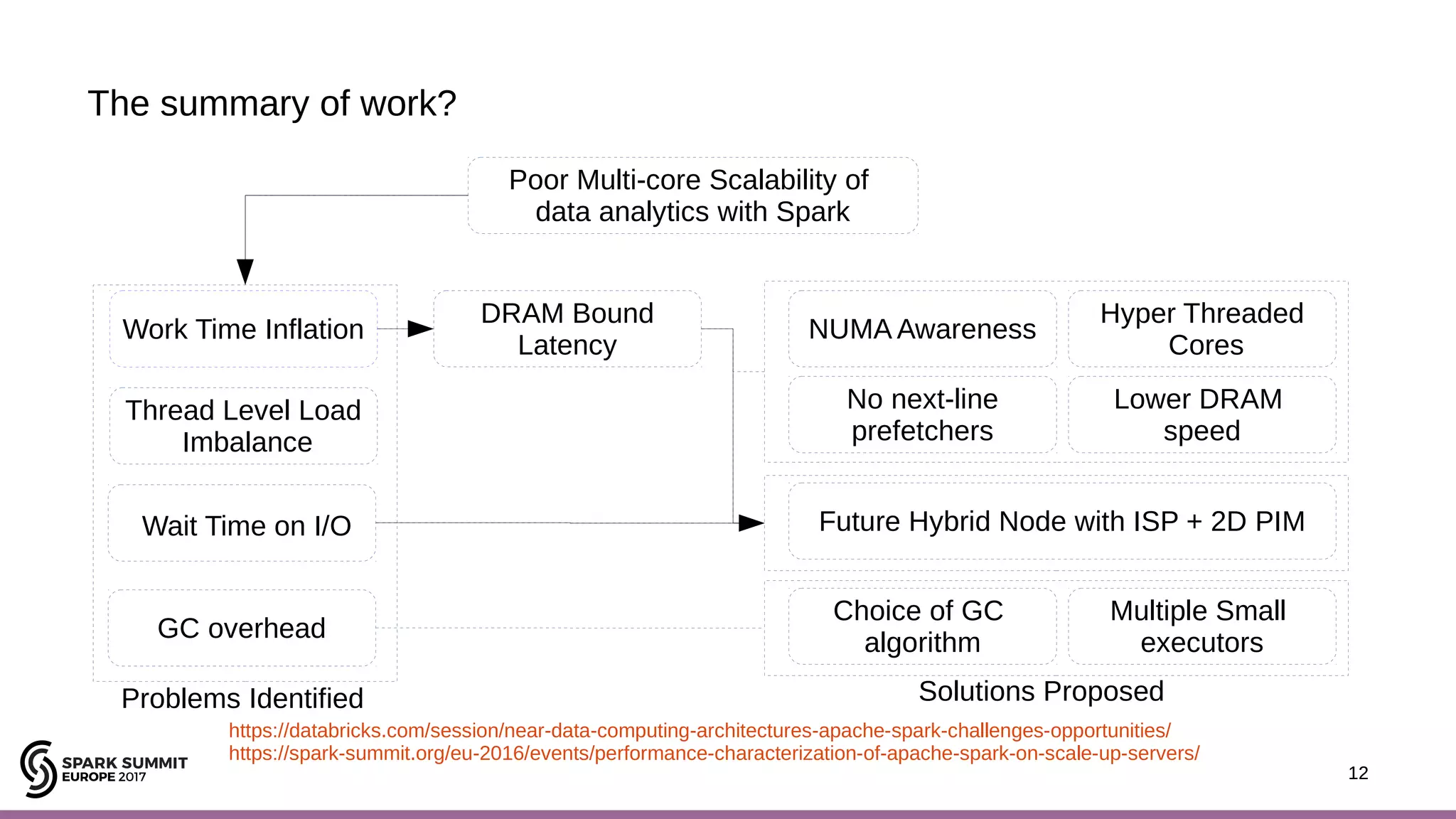
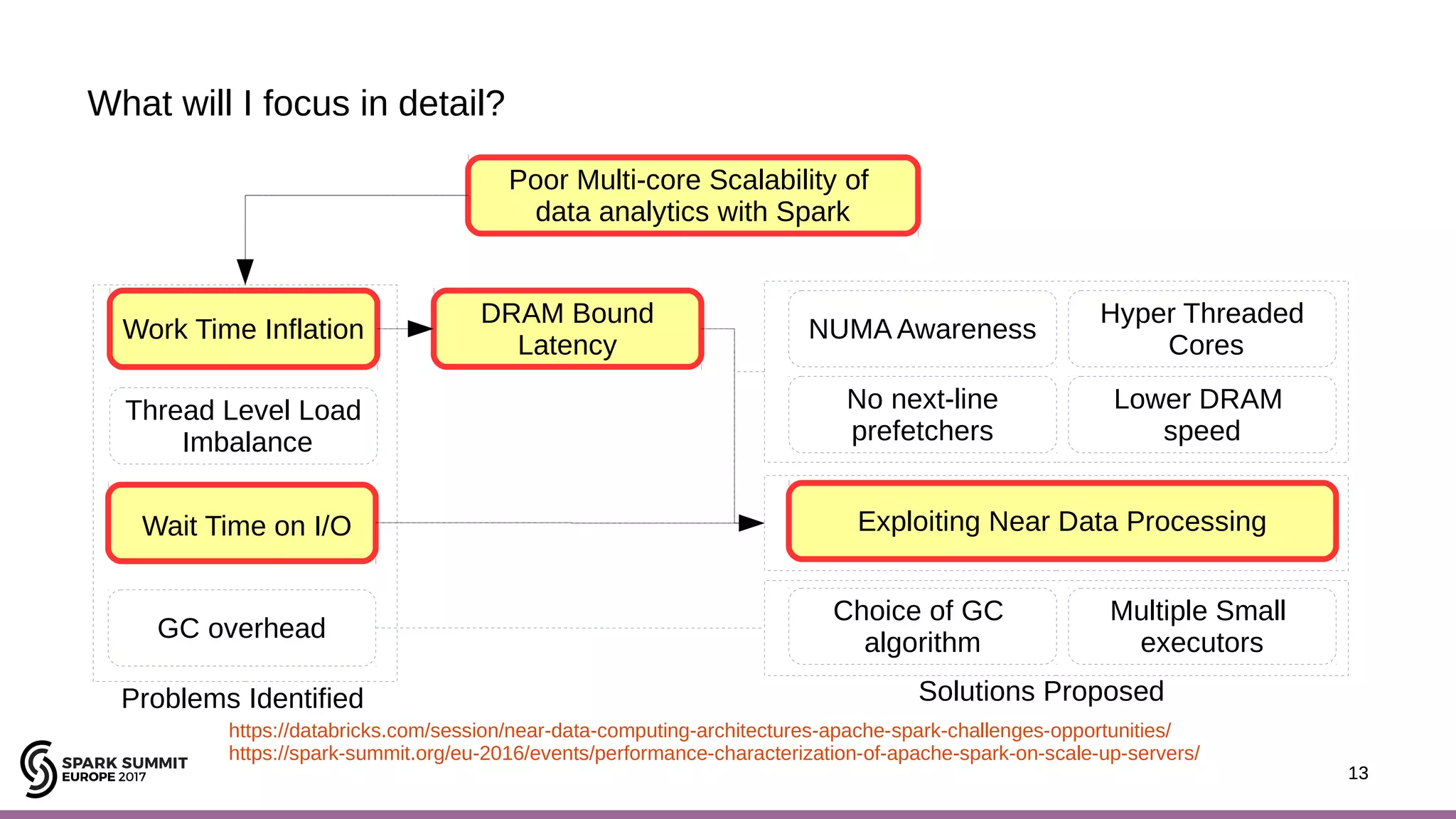
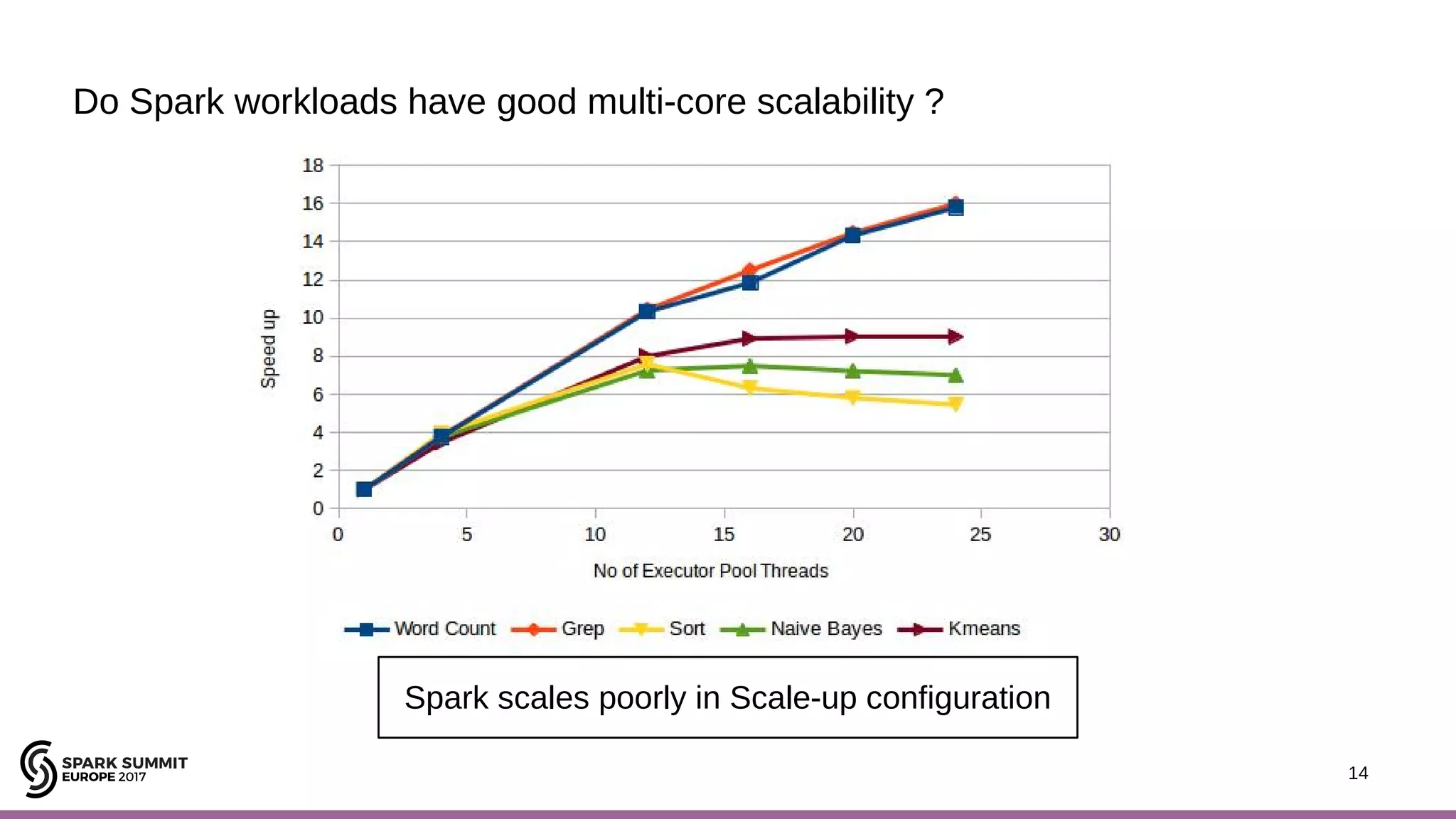
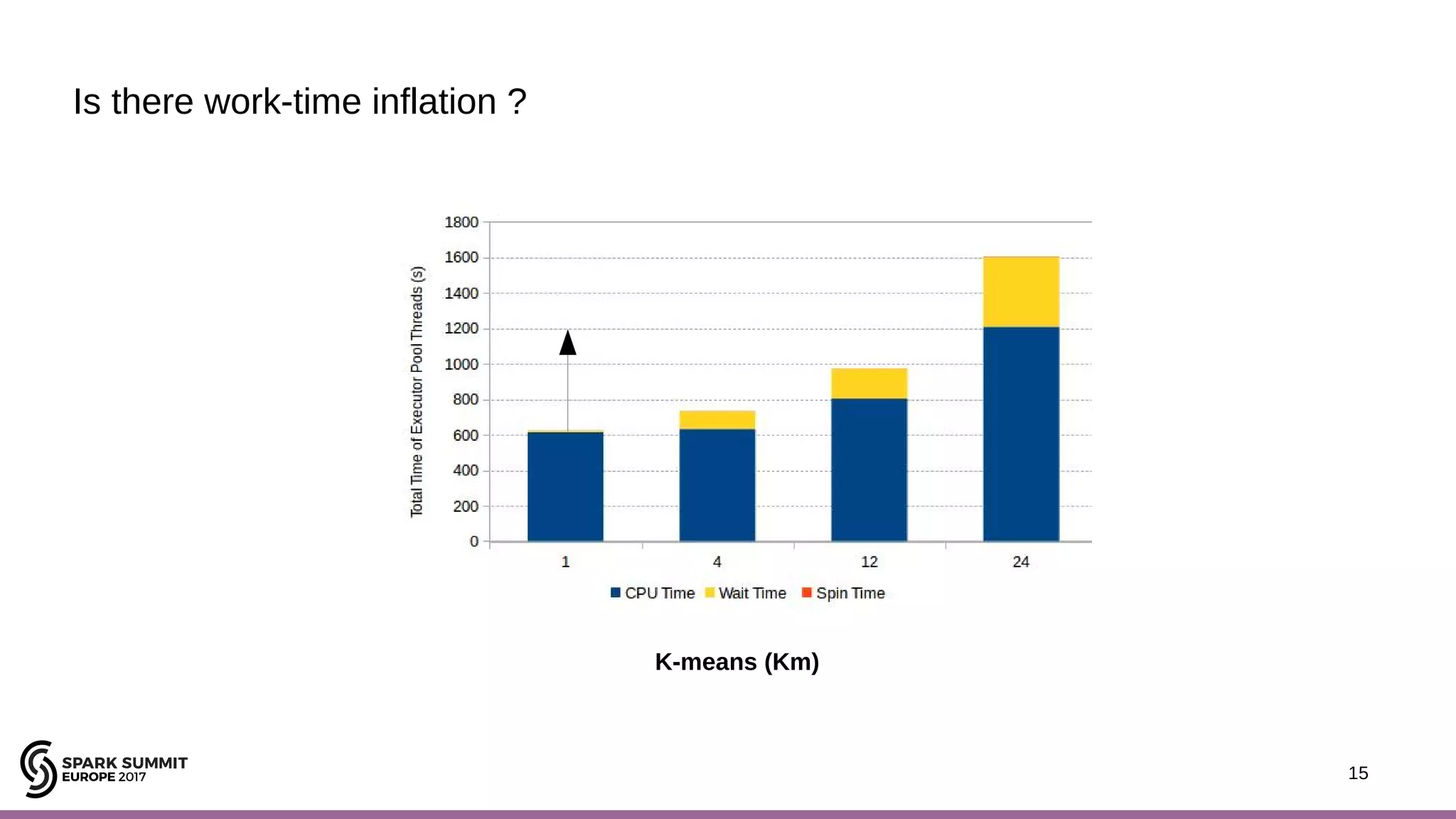
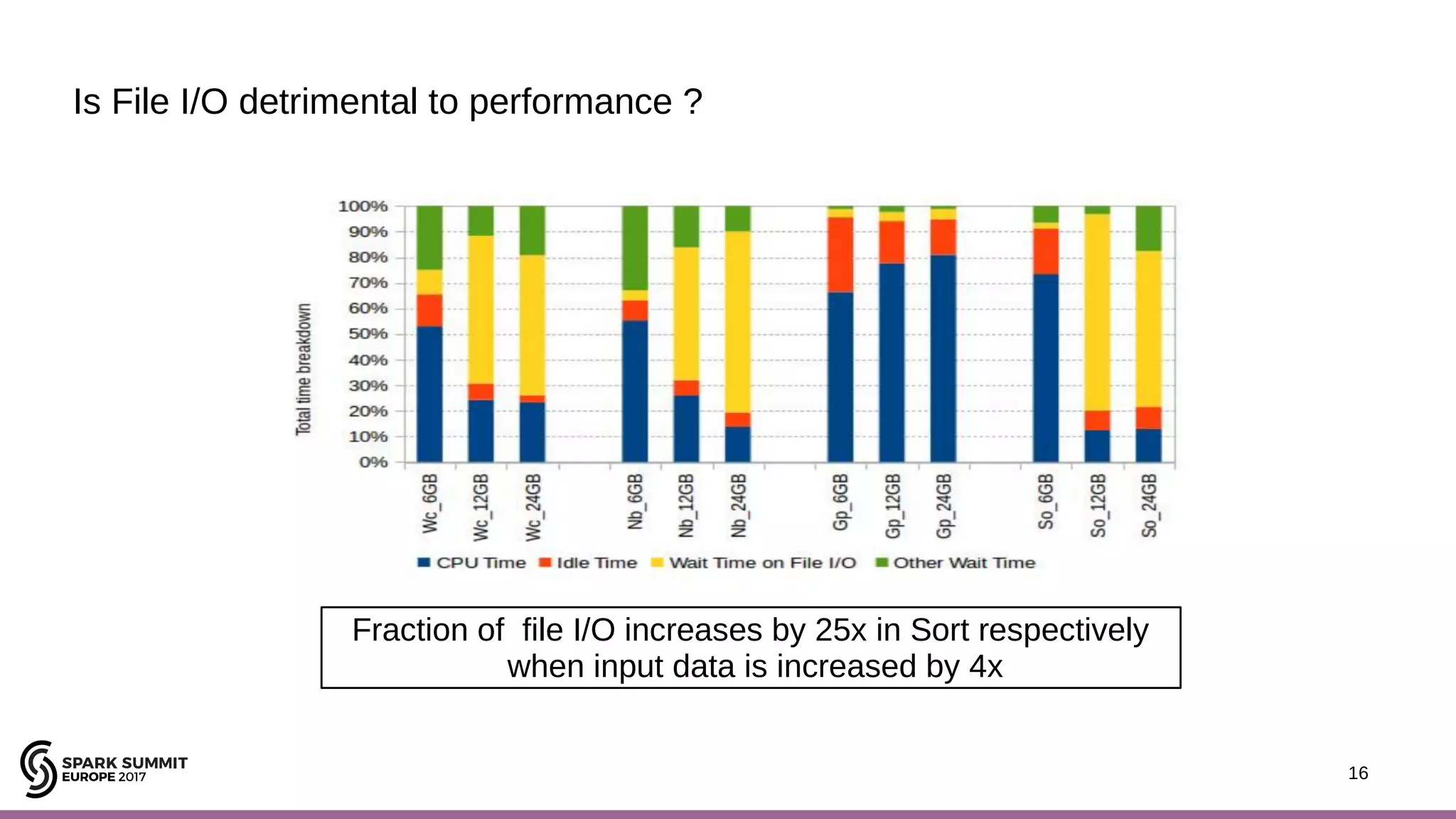
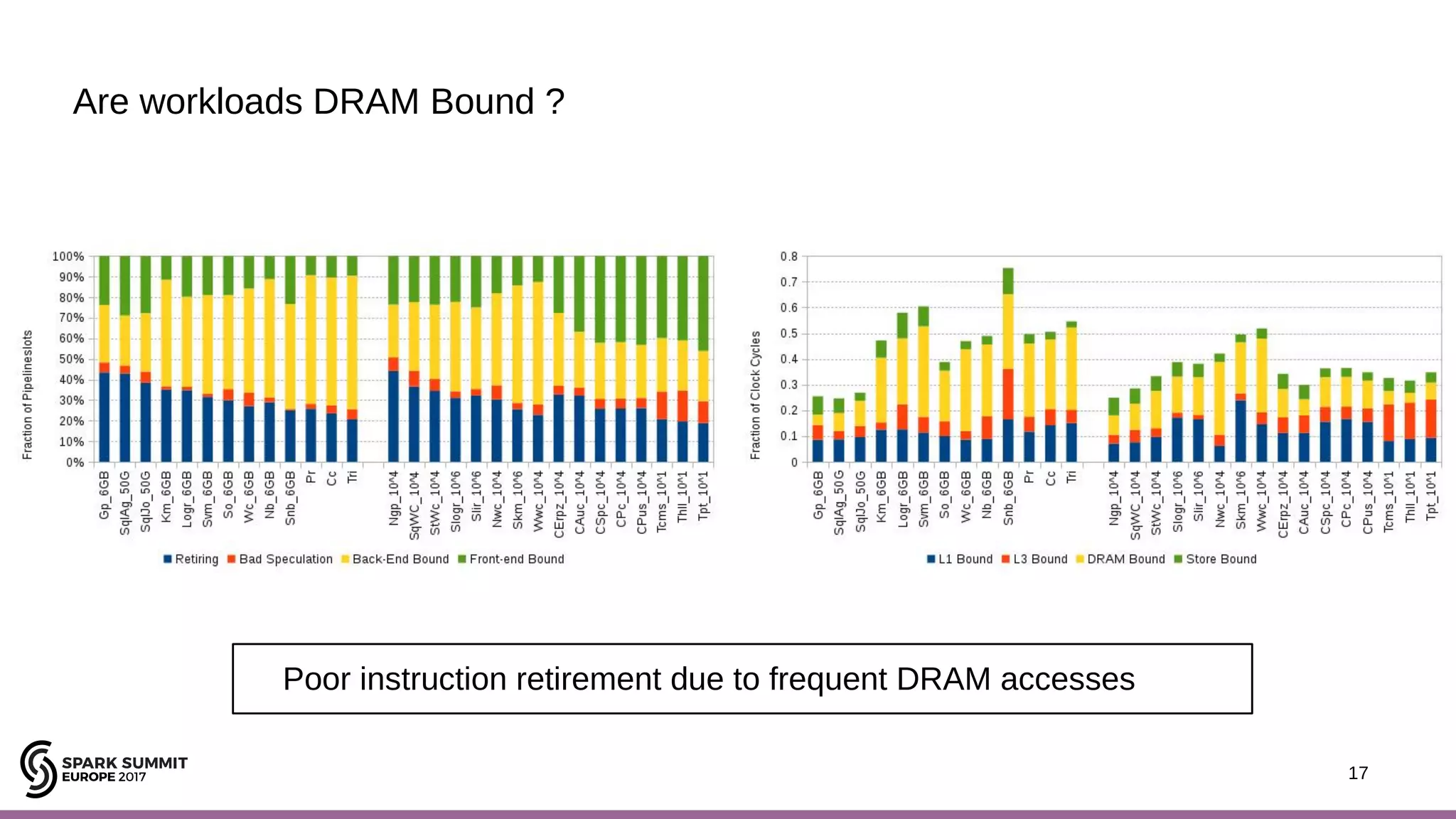
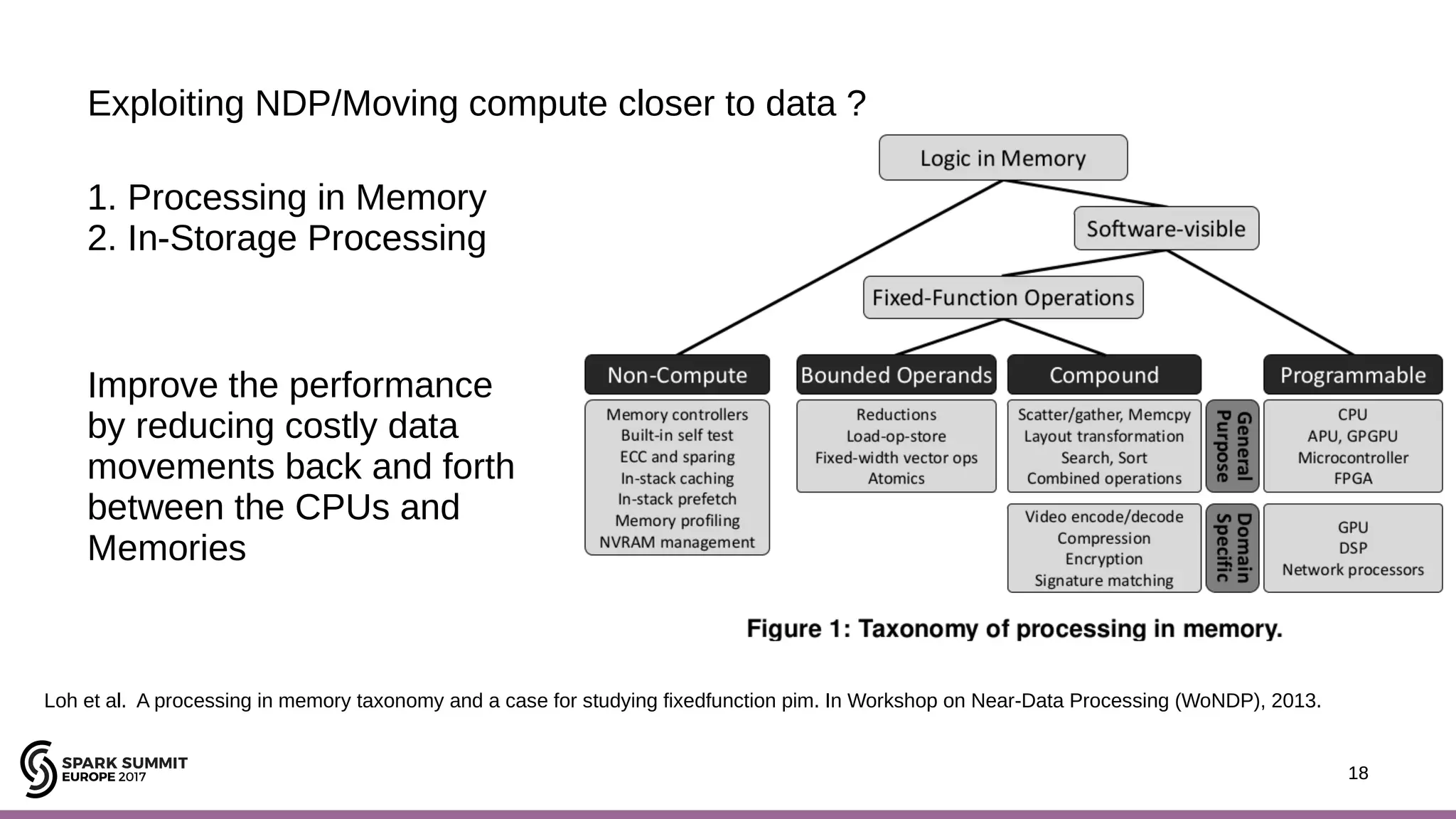
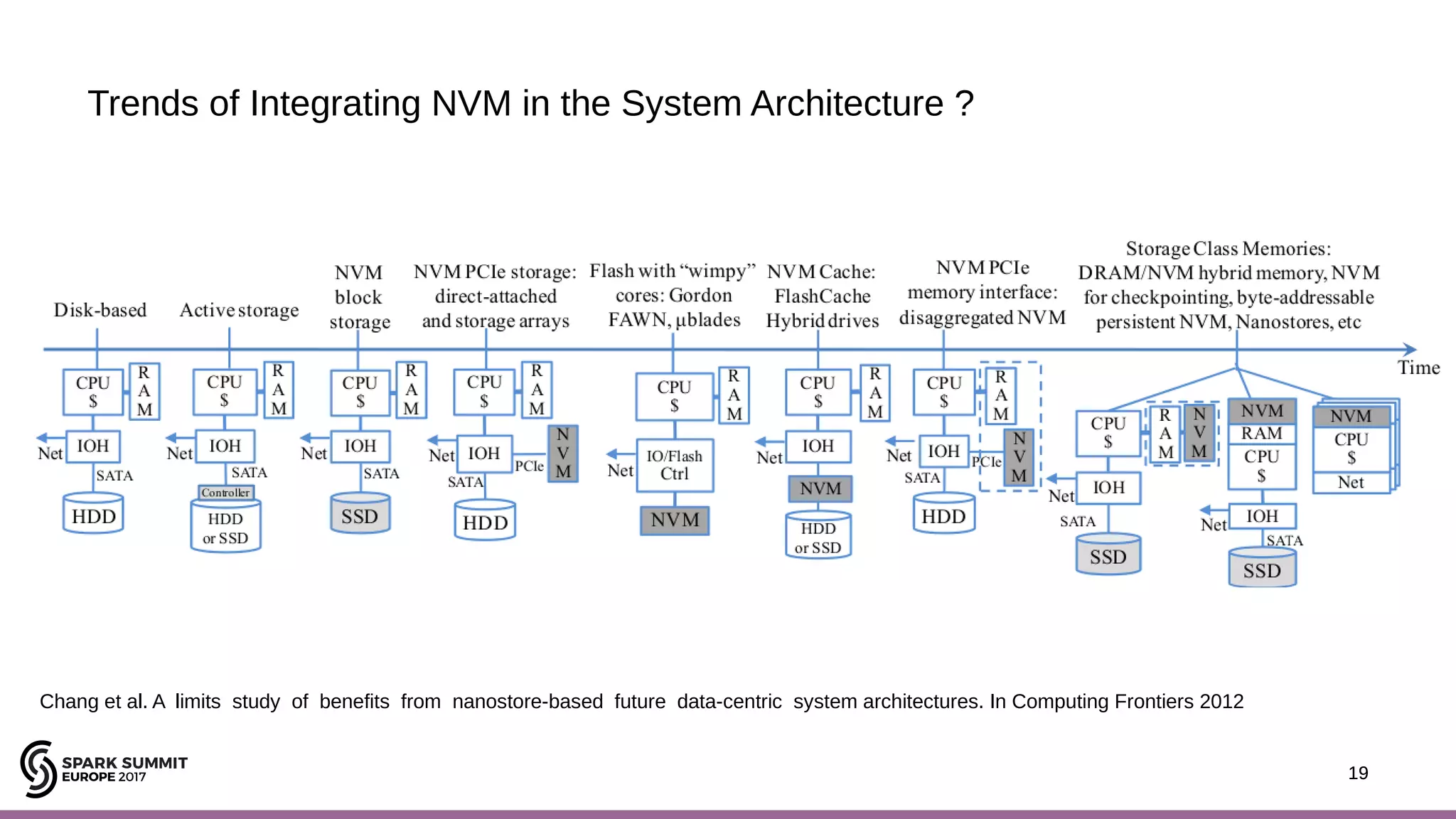
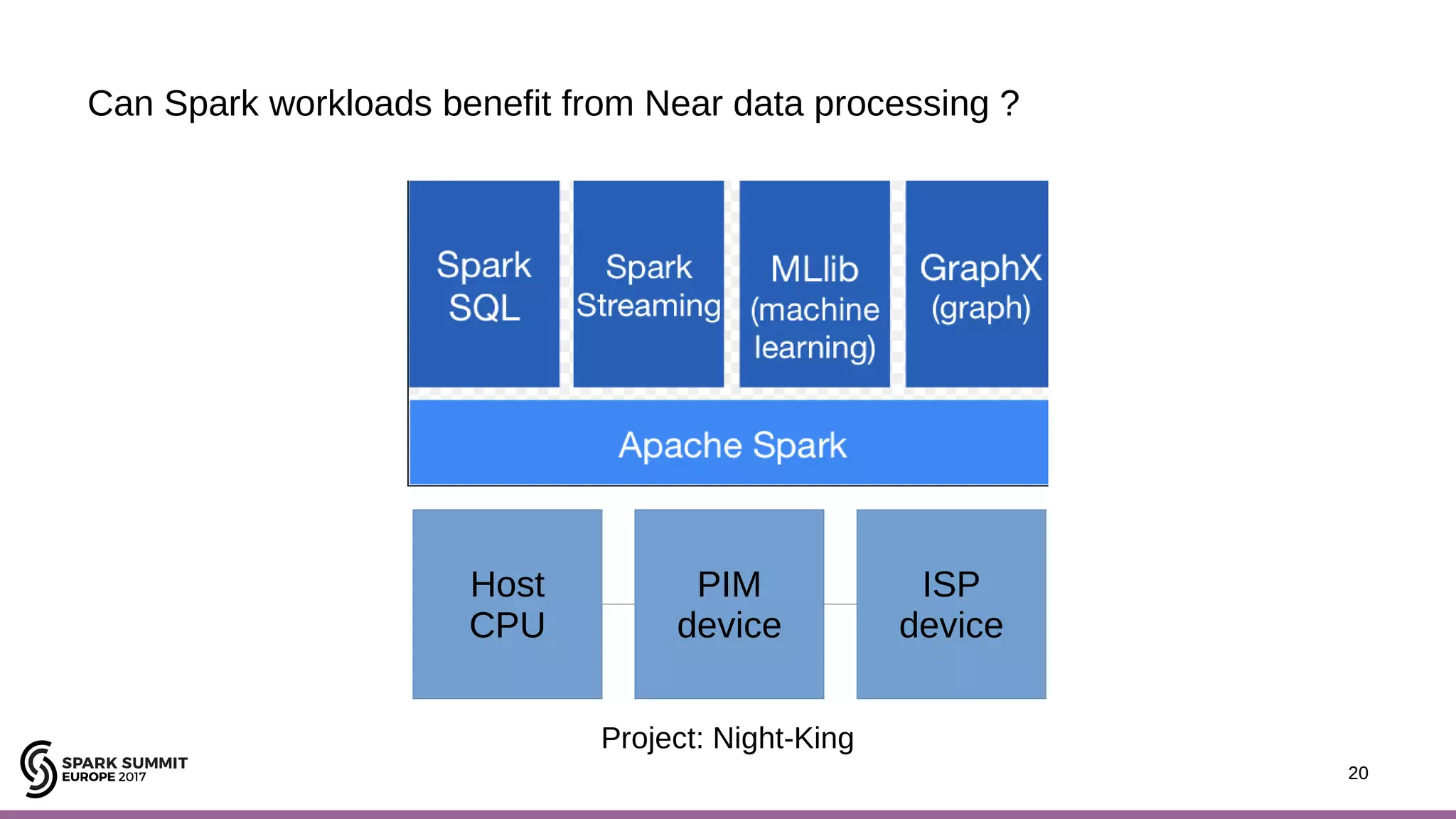



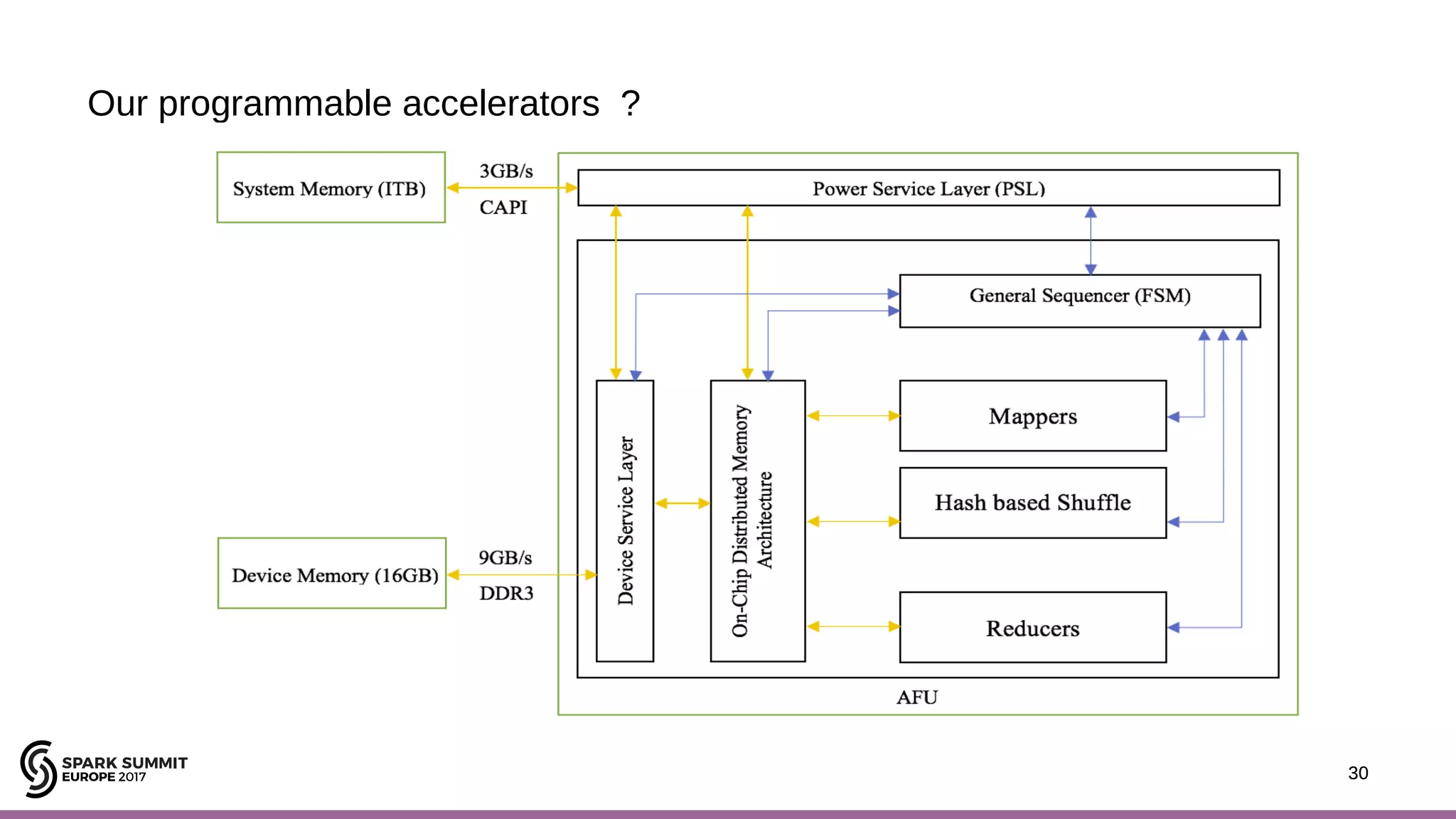

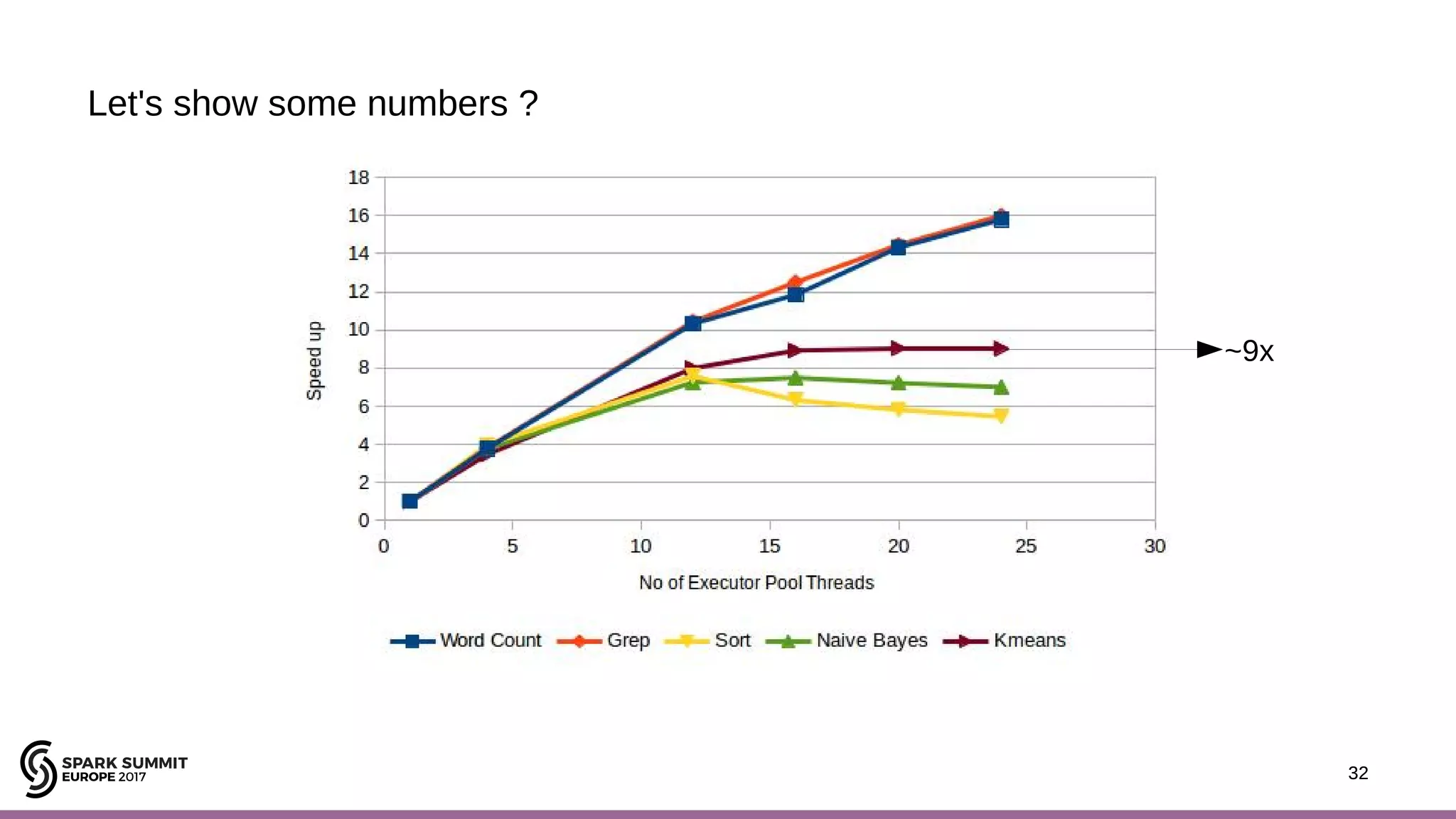




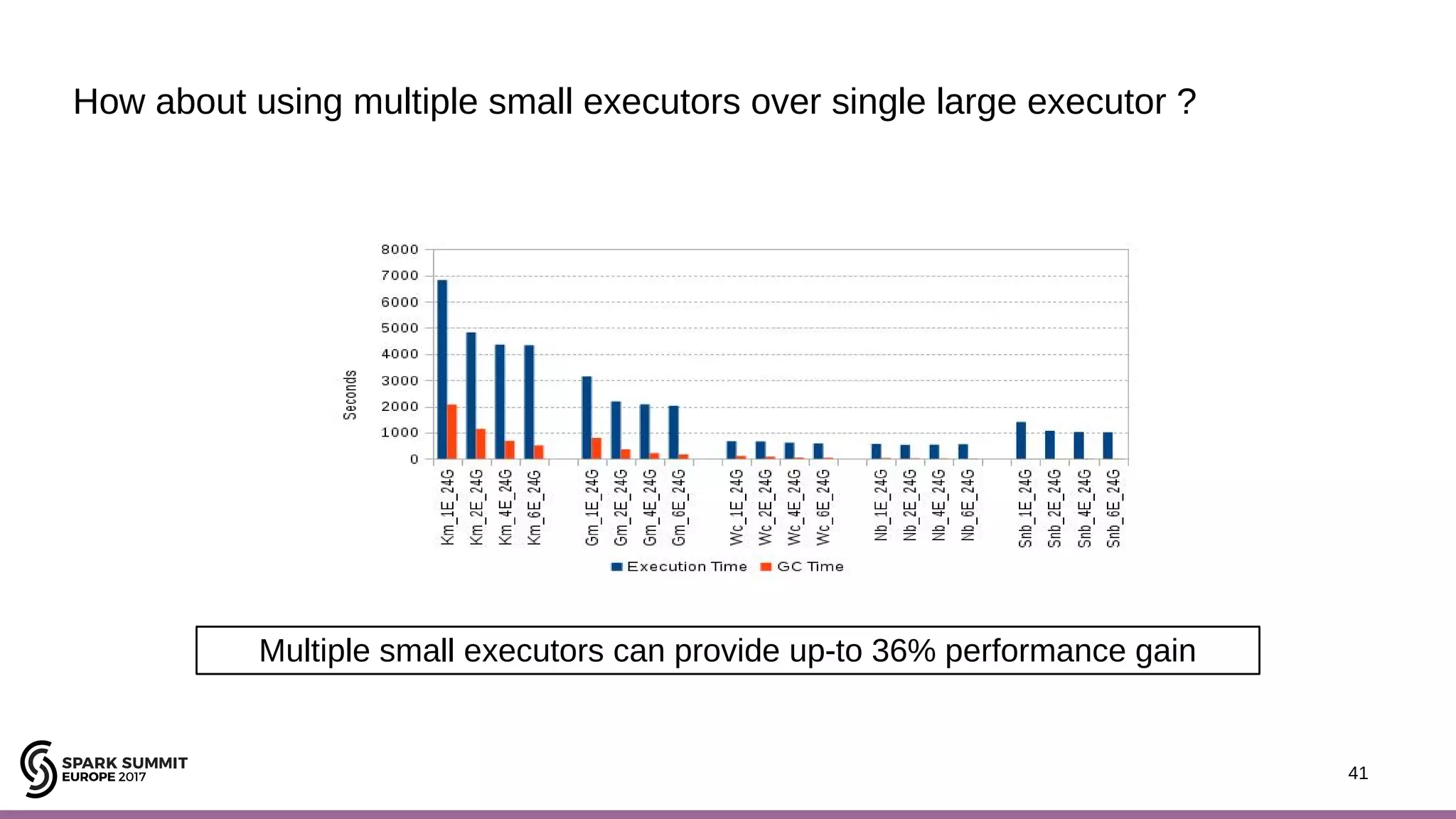
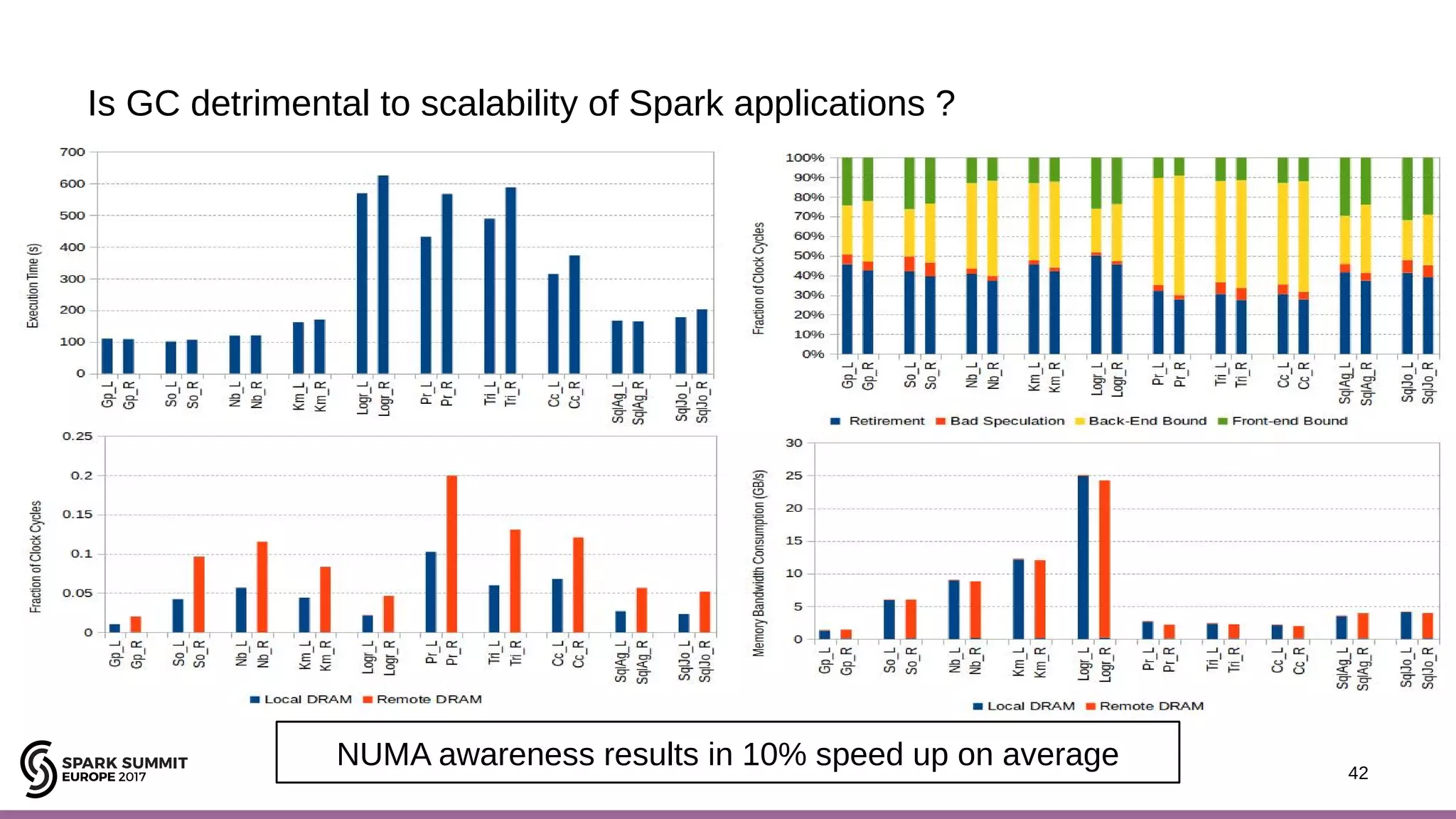
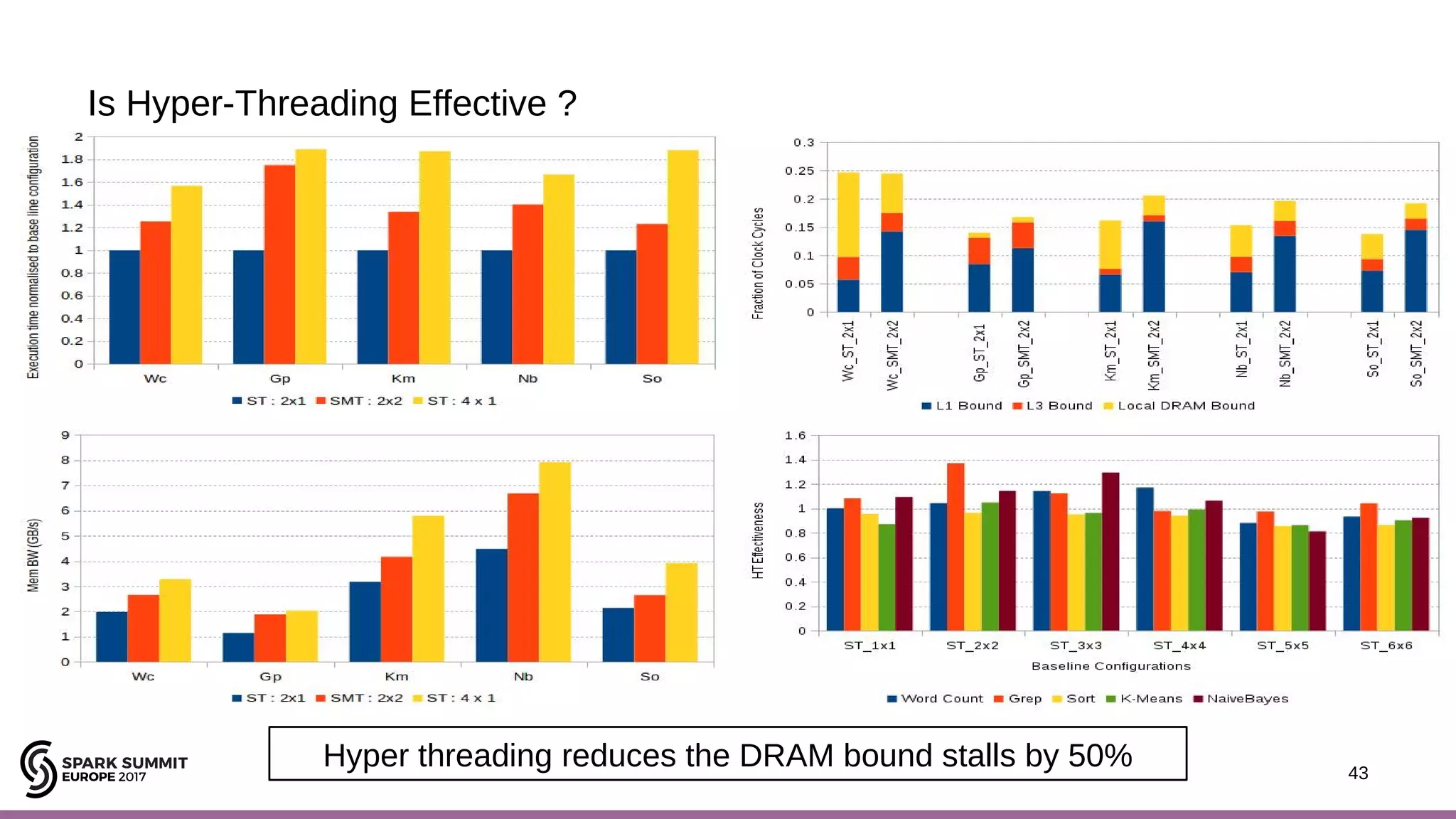
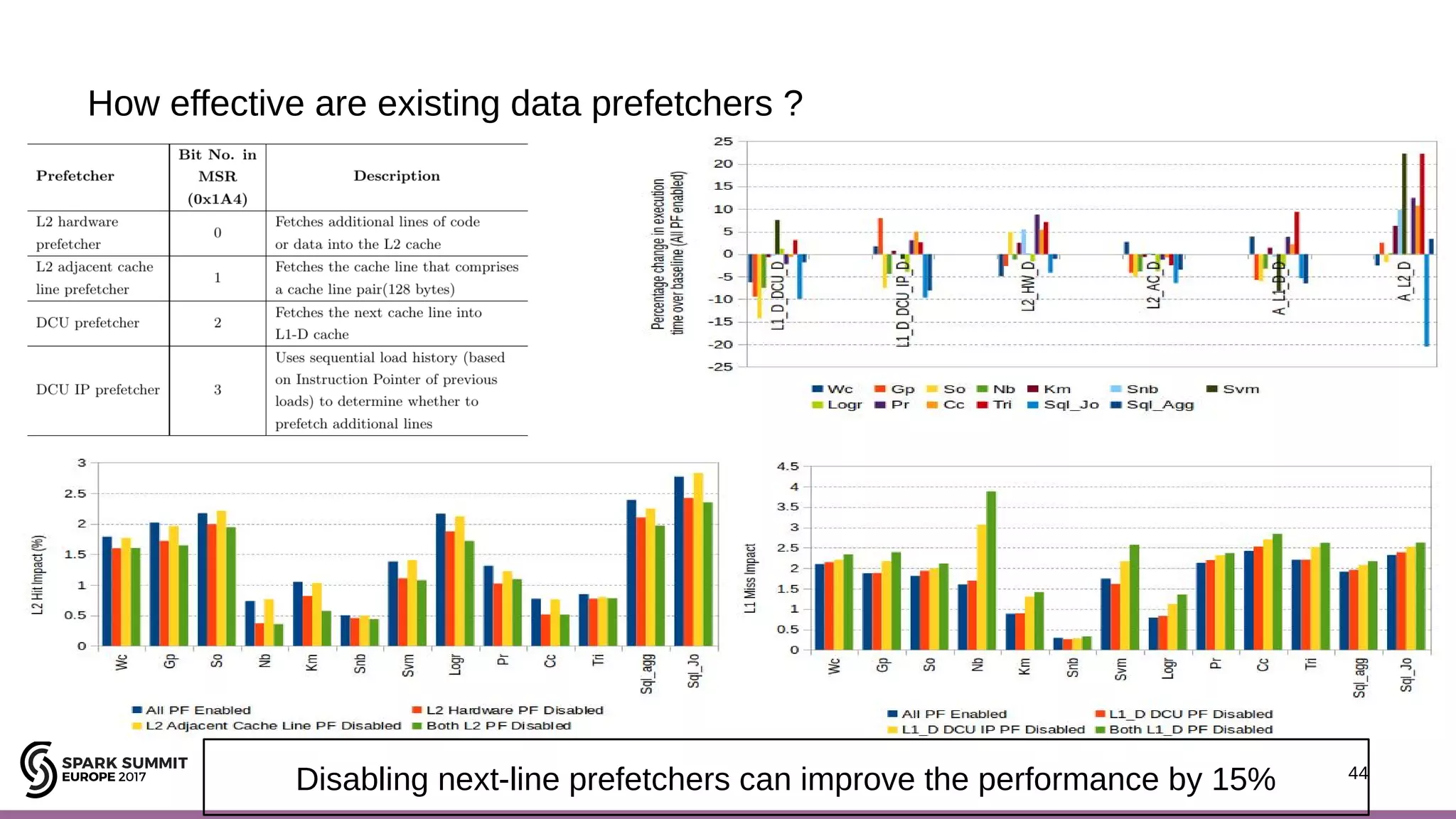

The document discusses performance optimization of Apache Spark on scale-up servers through near-data processing. It finds that Spark workloads have poor multi-core scalability and high I/O wait times on scale-up servers. It proposes exploiting near-data processing through in-storage processing and 2D-integrated processing-in-memory to reduce data movements and latency. The author evaluates these techniques through modeling and a programmable FPGA accelerator to improve the performance of Spark MLlib workloads by up to 9x. Challenges in hybrid CPU-FPGA design and attaining peak performance are also discussed.