Download to read offline



![6 Progress Meeting 12-12-14 Which Scale-out Framework ? [Picture Courtesy: Amir H. Payberah] ● Tuning of Spark internal Parameters ● Tuning of JVM Parameters (Heap size etc..) ● Micro-architecture Level Analysis using Hardware Performance Counters.](https://image.slidesharecdn.com/bdcloudaja2016-161010163224/75/Micro-architectural-Characterization-of-Apache-Spark-on-Batch-and-Stream-Processing-Workloads-6-2048.jpg)
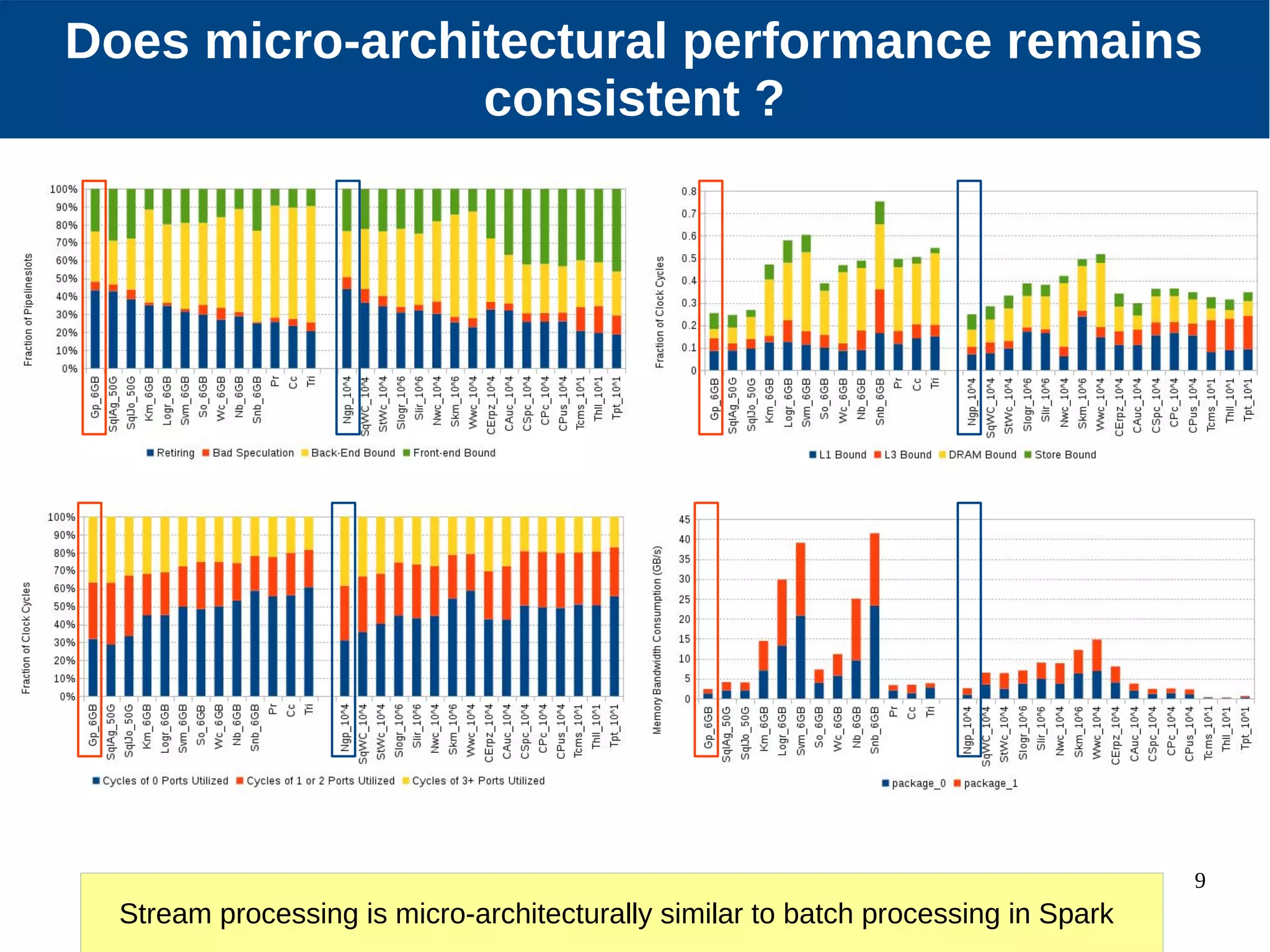
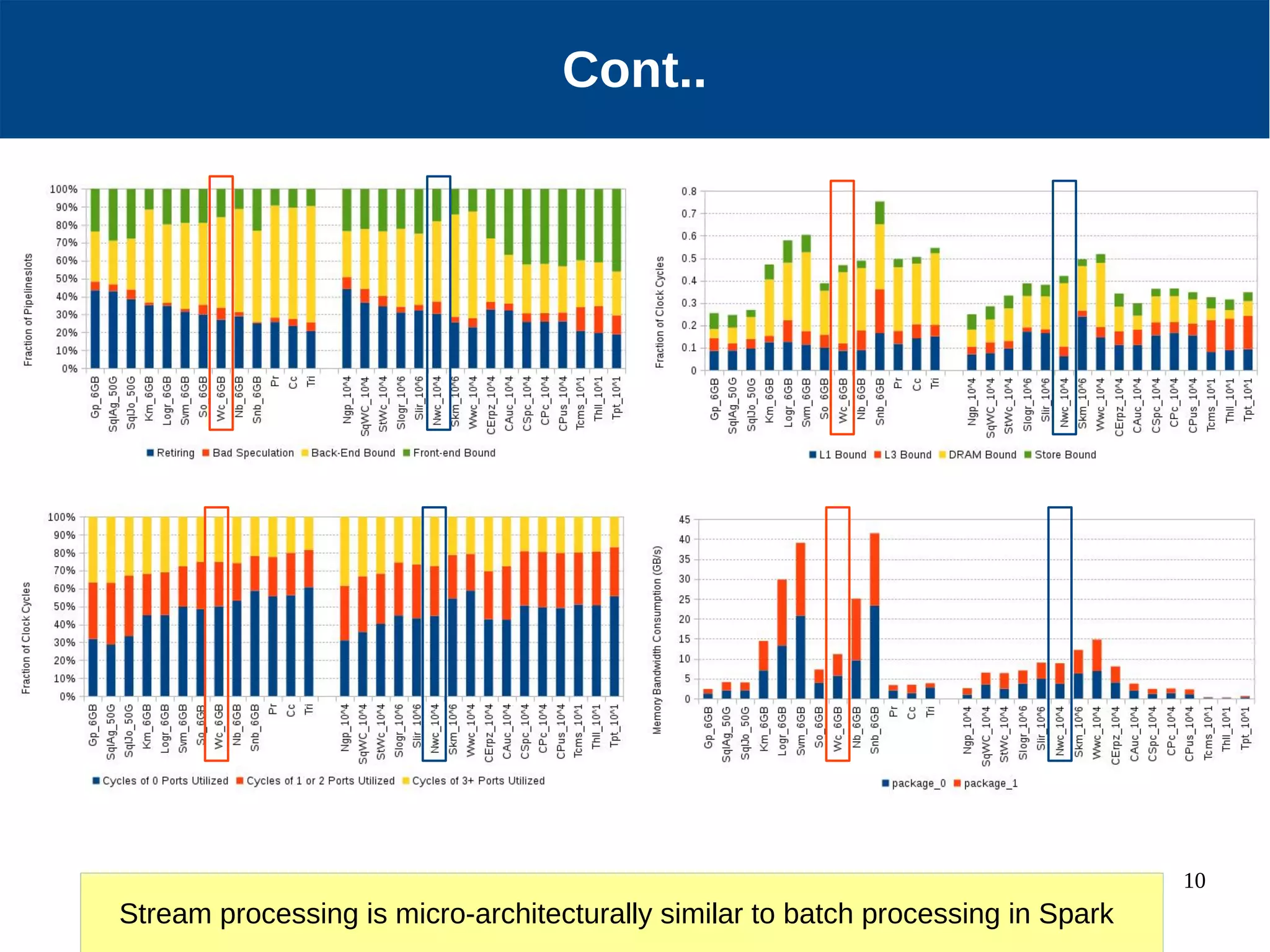
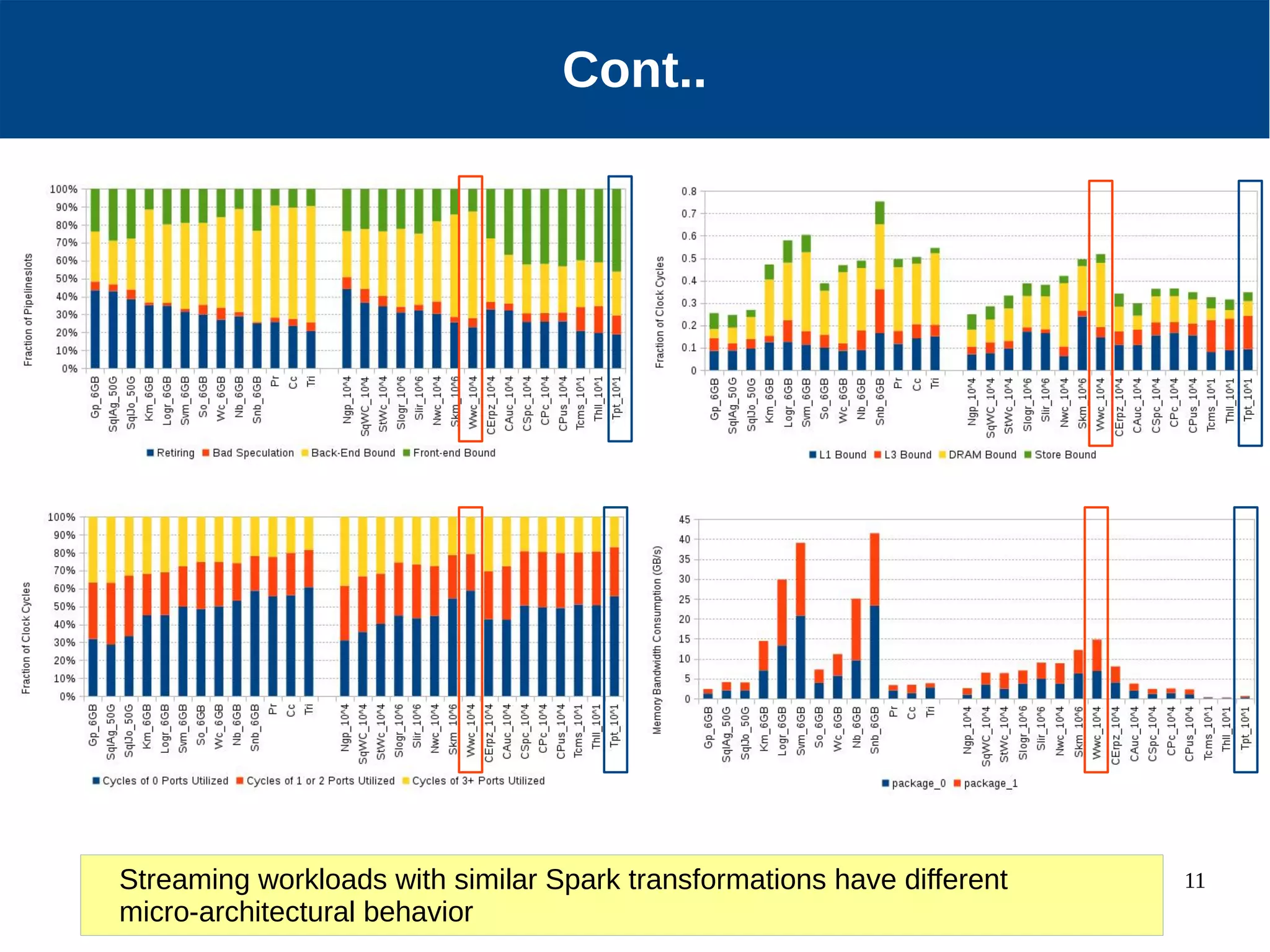
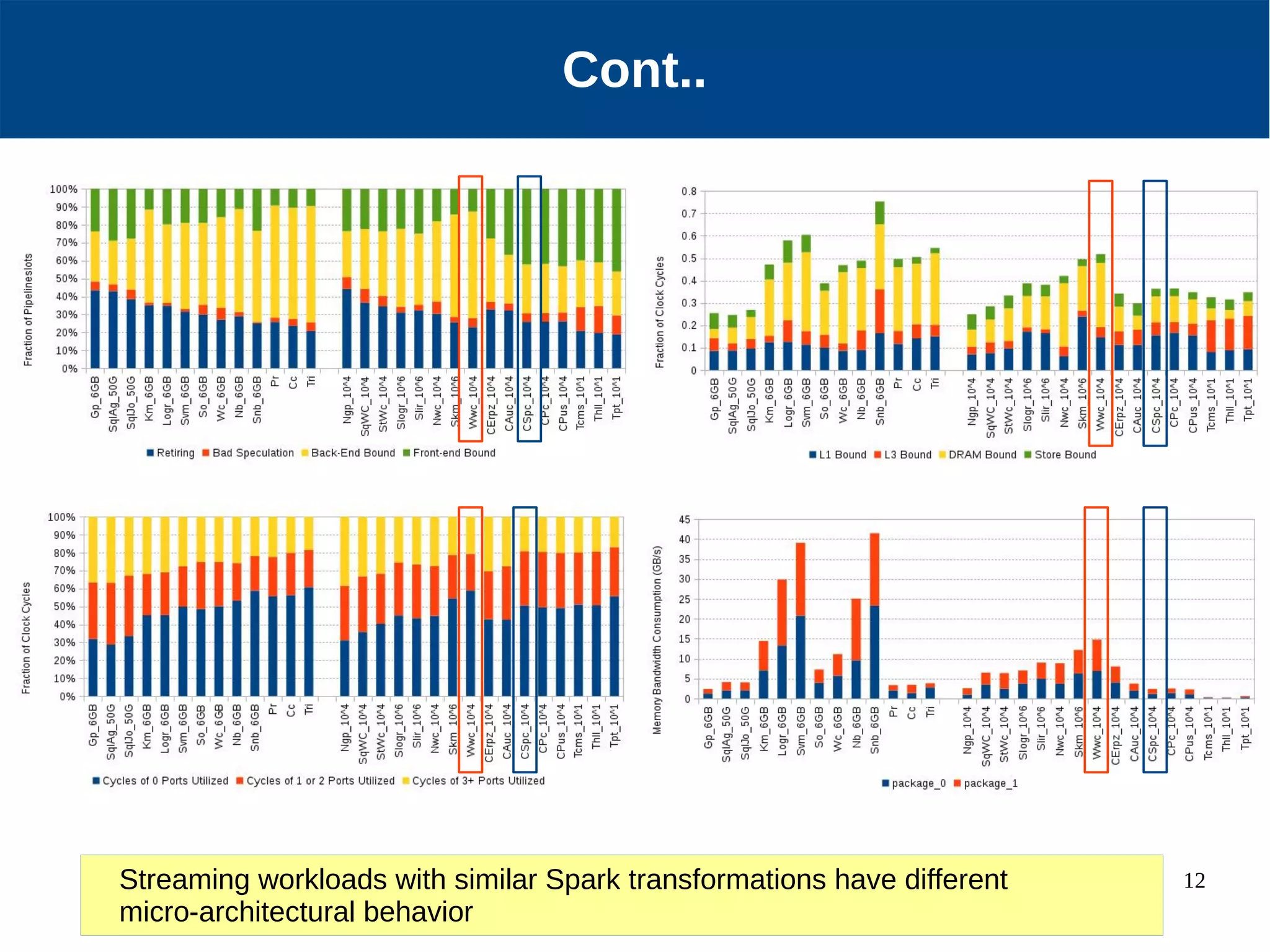
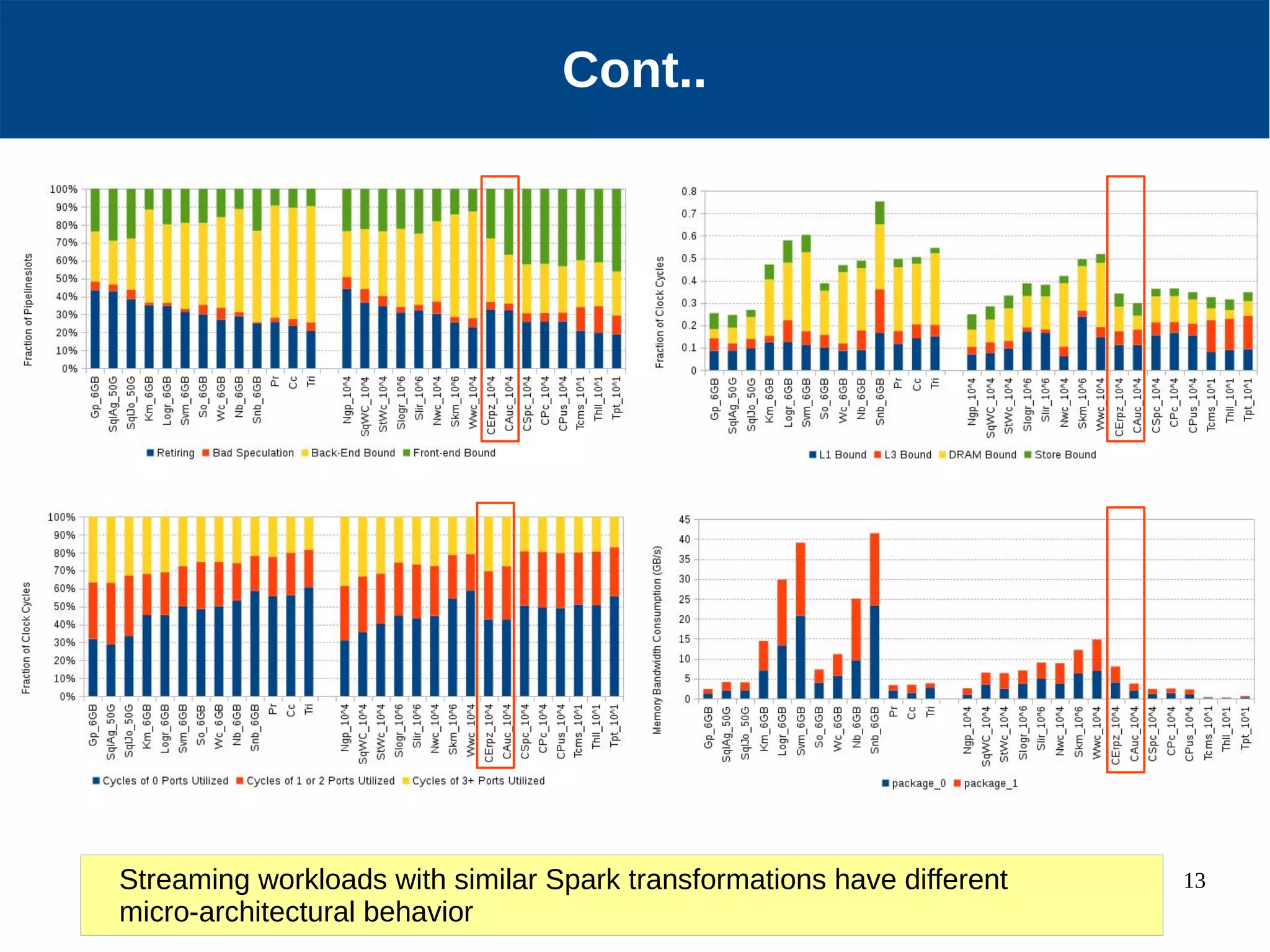
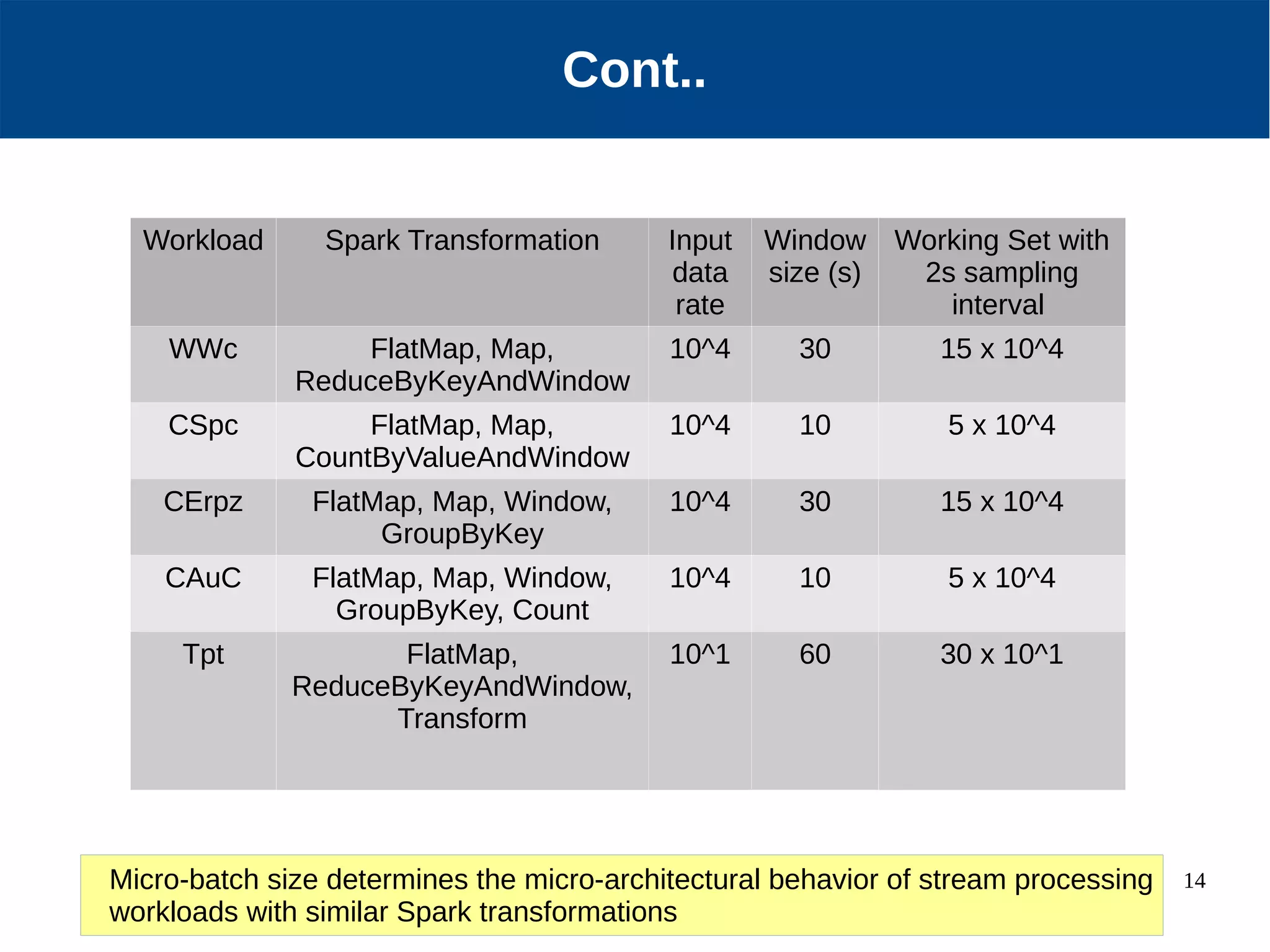
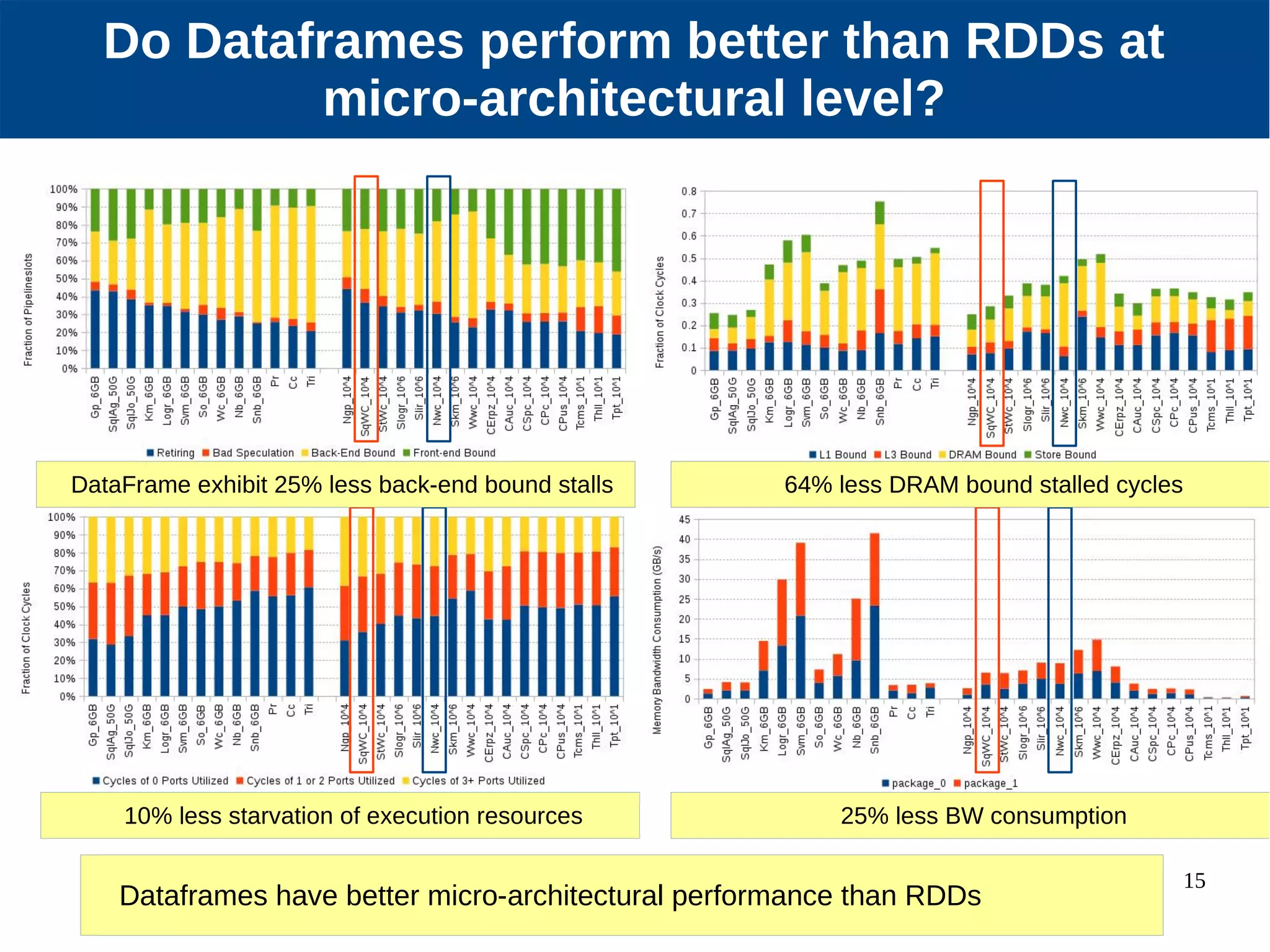
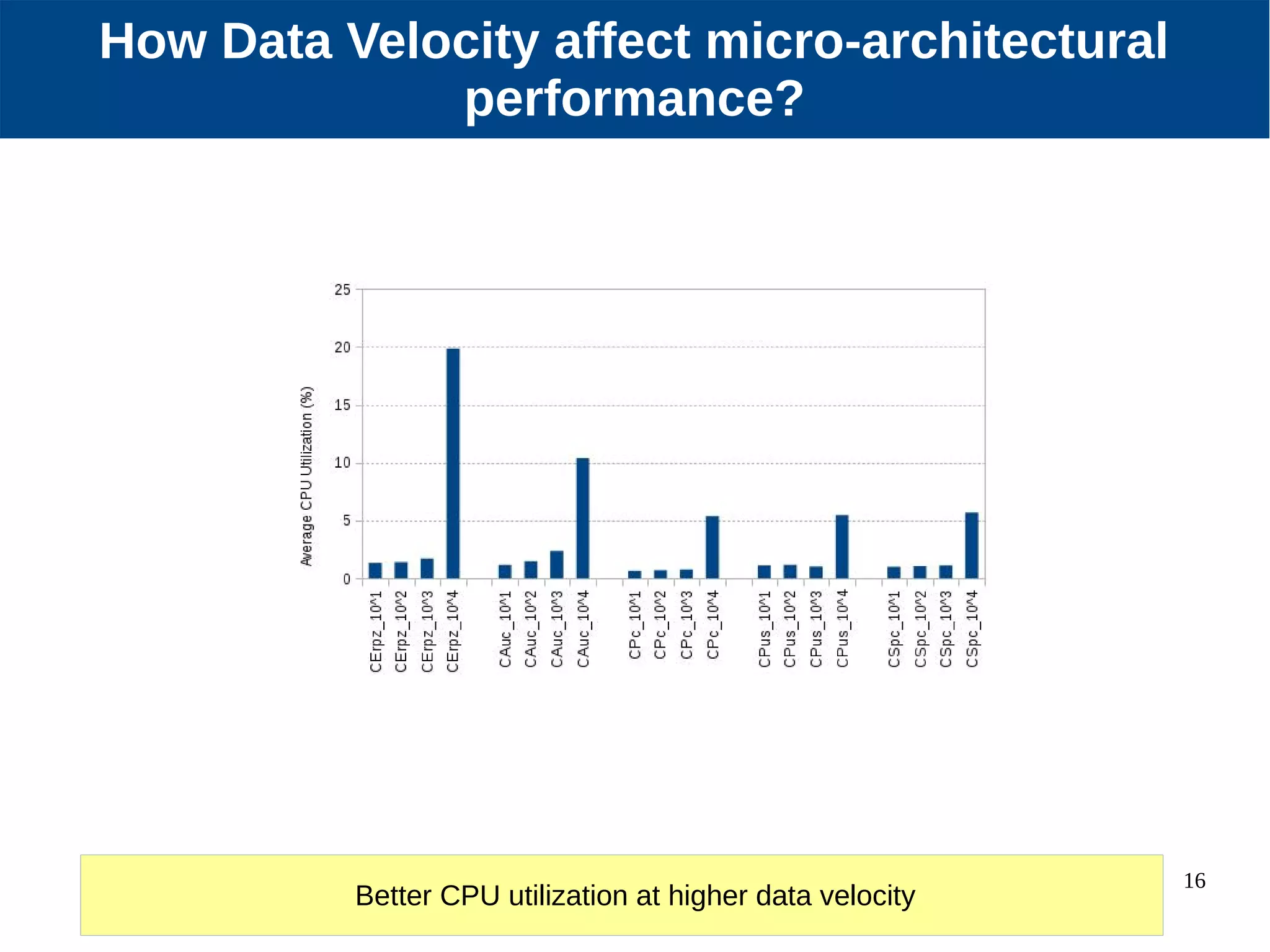
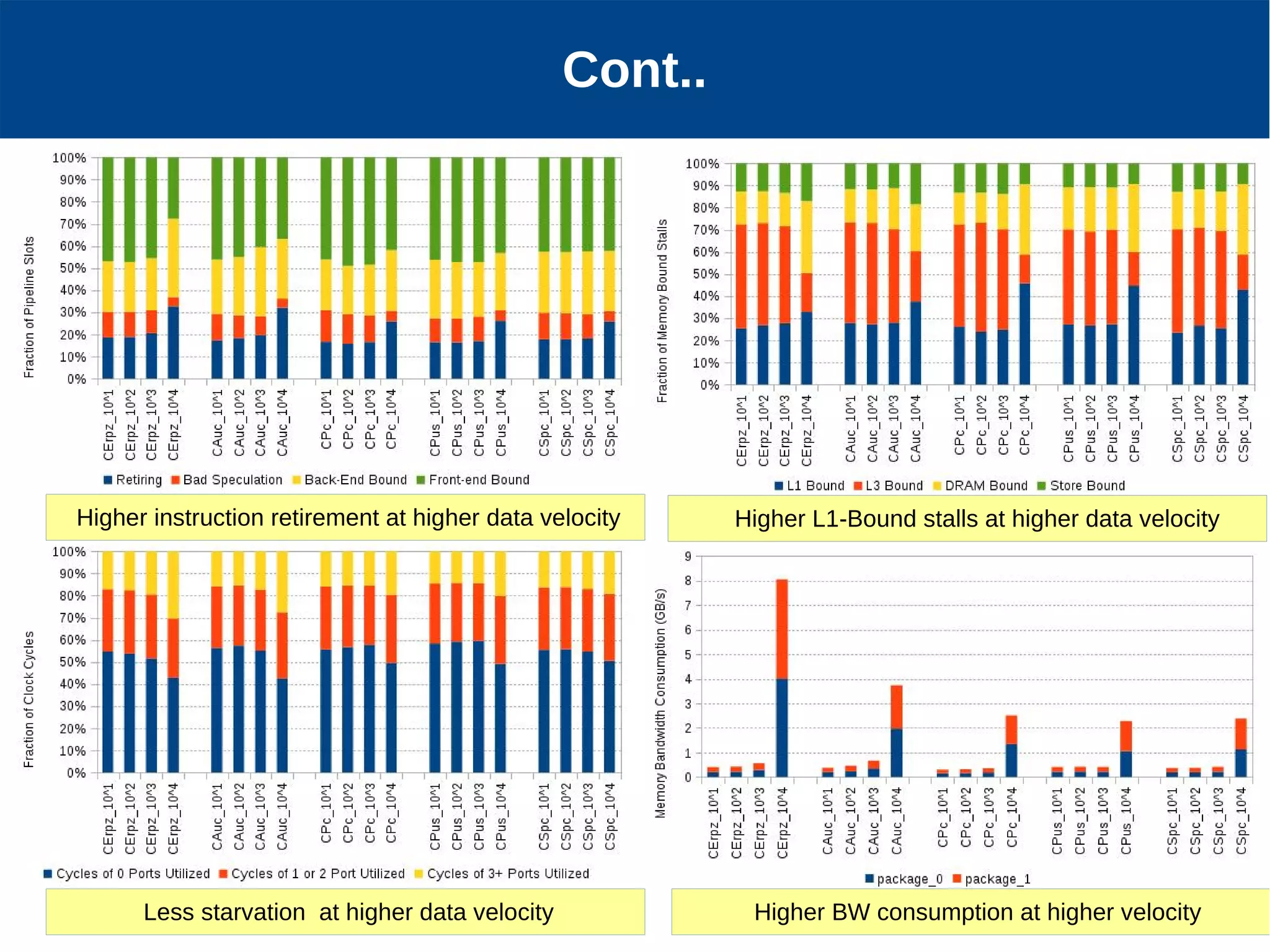




Micro-architectural performance is generally consistent between batch and stream processing workloads in Spark if they only differ in micro-batching. DataFrames show improved instruction retirement and reduced stalls compared to RDDs. Higher data velocities can improve CPU utilization and reduce stalls, while increasing bandwidth consumption and instruction retirement. The size of micro-batches in stream workloads determines their micro-architectural behavior.