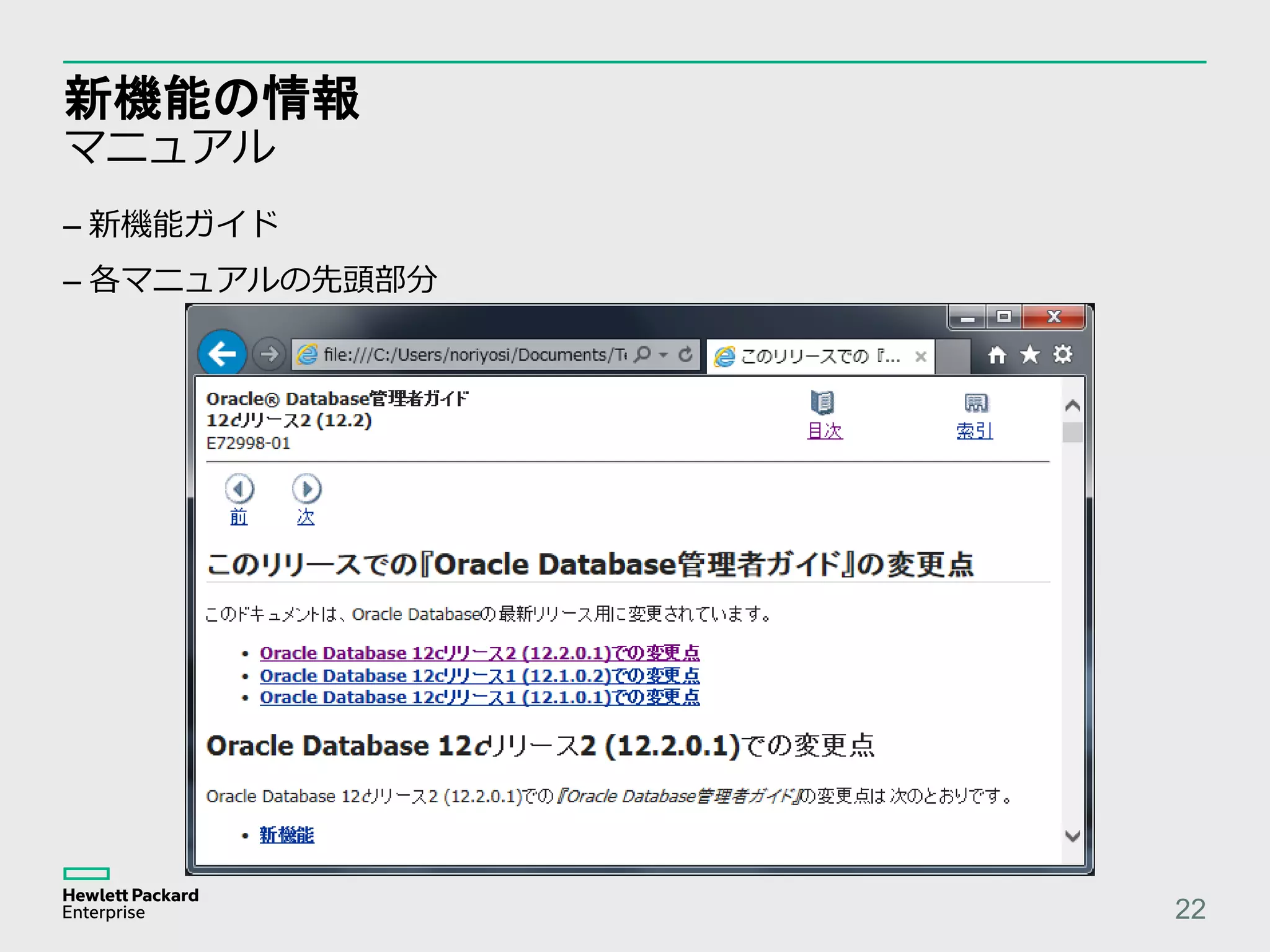
Oracle Database 12c新機能 FETCHn ROWS 9 RDBMS 最初の 10 レコード取得 MySQL LIMIT 10 PostgreSQL FETCH FIRST 10 ROWS ONLY DB2 FETCH FIRST 10 ROWS ONLY SQL Server TOP 10 FETCH FIRST 10 ROWS ONLY Vertica LIMIT 10 SELECT first_name, last_name, salary FROM ( SELECT first_name, last_name, salary, ROW_NUMBER() OVER (ORDER BY salary DESC) ranking FROM employees) WHERE ranking <= 10 – Oracle Database 11g の記述
10.
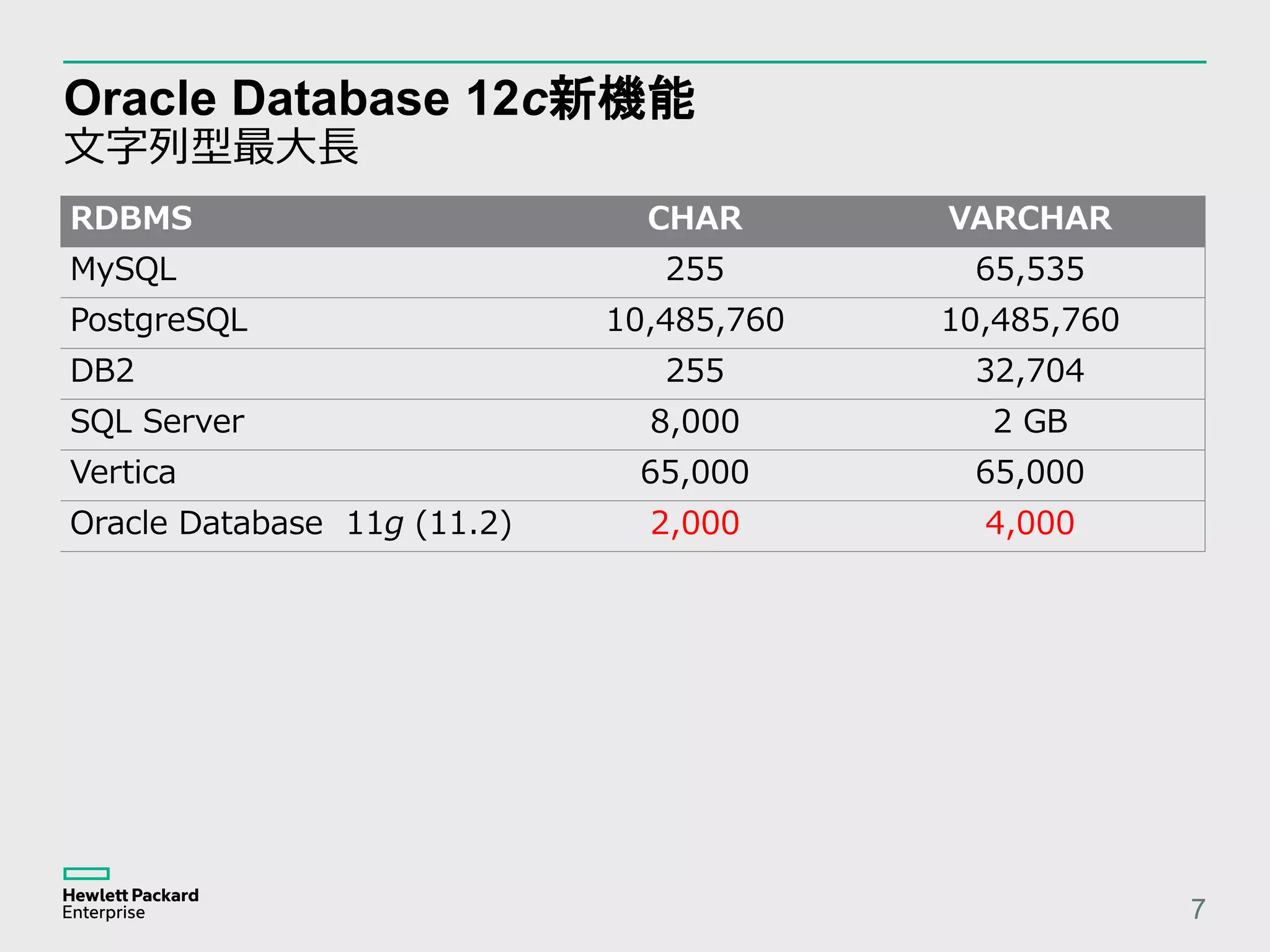
Oracle Database 12c新機能 FETCHn ROWS 10 – Oracle Database 12c (12.1) から OFFSET n ROWS FETCH FIRST m ROWS ONLY 構文が利用可能 SQL> SELECT first_name, last_name, salary FROM employees ORDER BY salary DESC FETCH FIRST 10 ROWS ONLY ; – OFFSET n ROWS 句を指定して途中を抜き出すこともできる – 実行計画を確認すると内部的には ROW_NUMBER 関数を使っている 1 - filter("from$_subquery$_002"."rowlimit_$$_rownumber"<=10) 2 - filter(ROW_NUMBER() OVER ( ORDER BY "EMPLOYEES".“SALARY" )<=10)











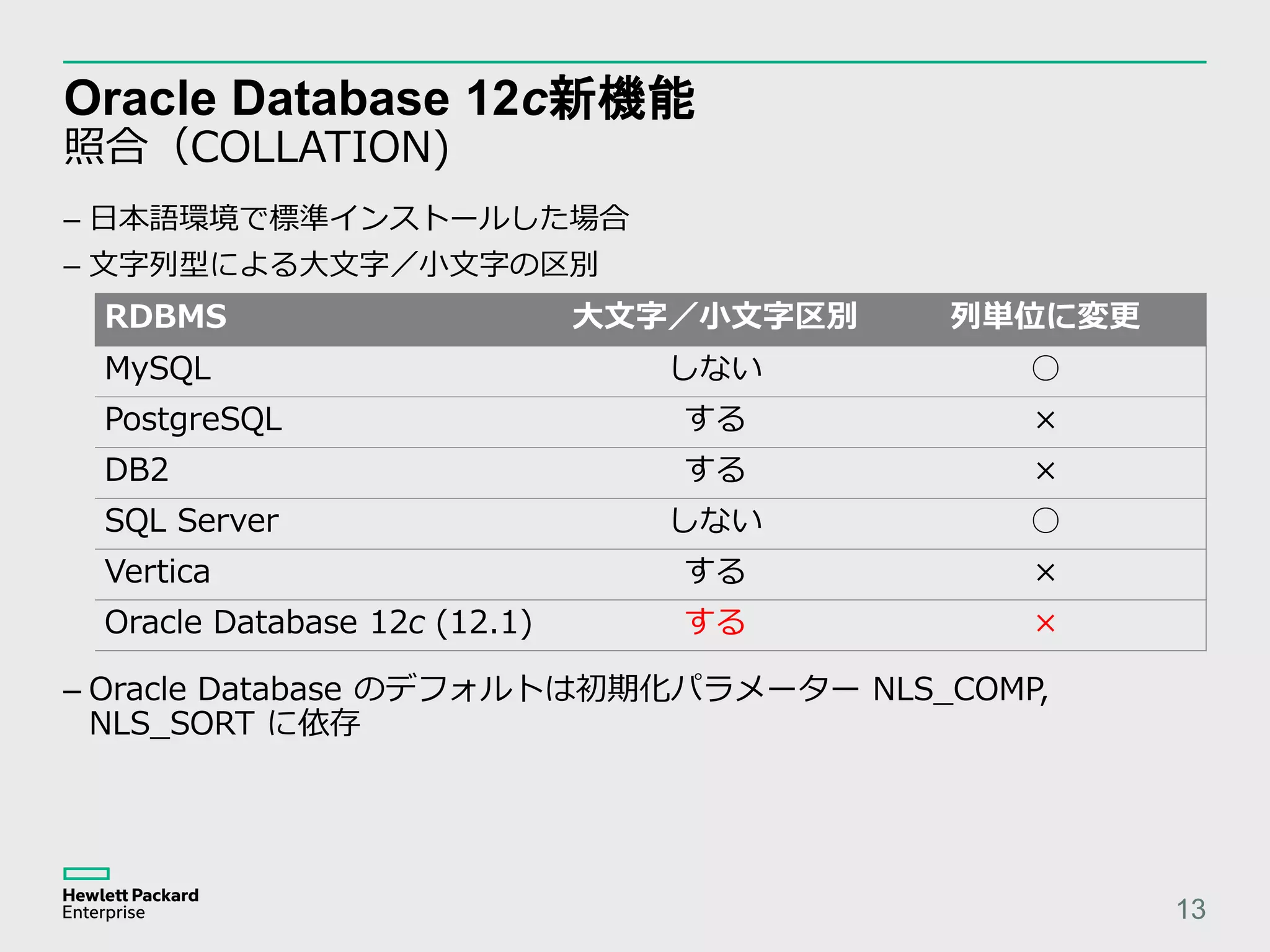






![Oracle Database 12c新機能 JSONデータ対応 20 SQL> SELECT JSON_ARRAY ( 2 JSON_OBJECT('Percentage' VALUE .30), 3 JSON_ARRAY('A', 'B', 'C') 4 ) FROM DUAL ; JSON_ARRAY(JSON_OBJECT('PERCENTAGE'VALUE.30),JSON_ARRAY('A ','B','C')) -------------------------------------------------------------------------------- [{"Percentage":0.3},["A","B","C"]] SQL> – JSON データ生成関数が追加(12.2)](https://image.slidesharecdn.com/oracledatabaseconnect2017jpoug120170307-1-170307124608/75/Oracle-Database-Connect-2017-JPOUG-1-20-2048.jpg)