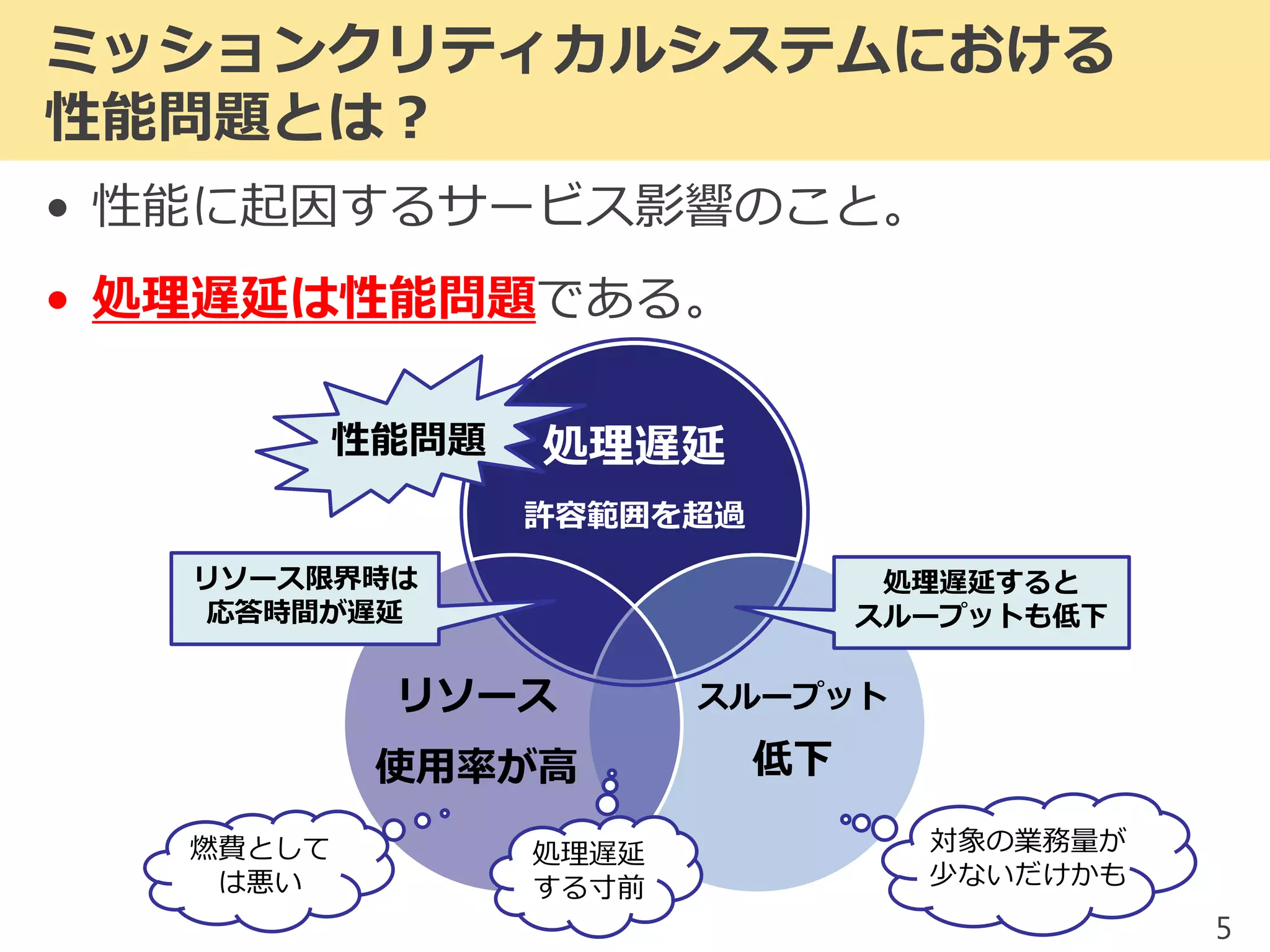
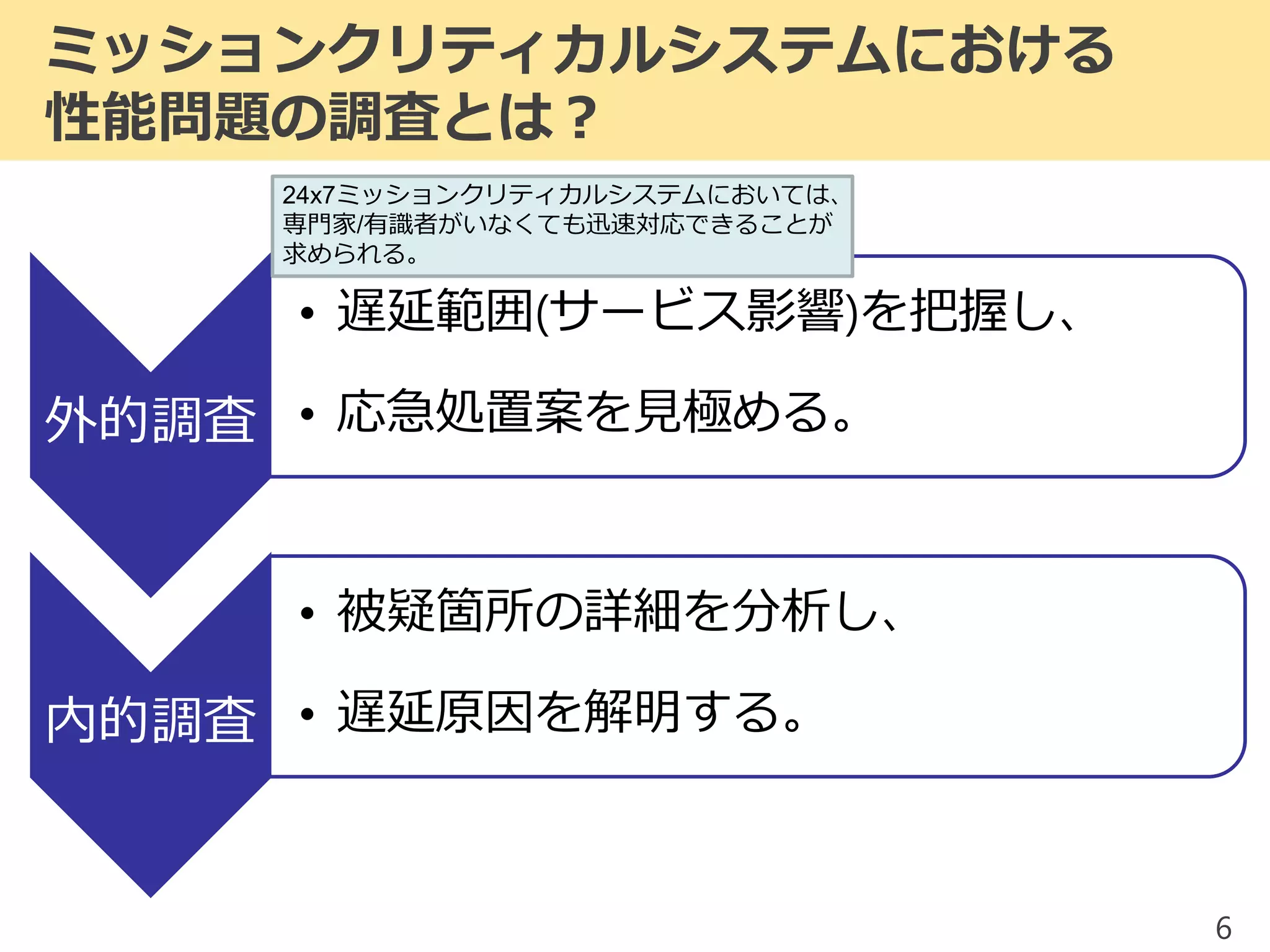
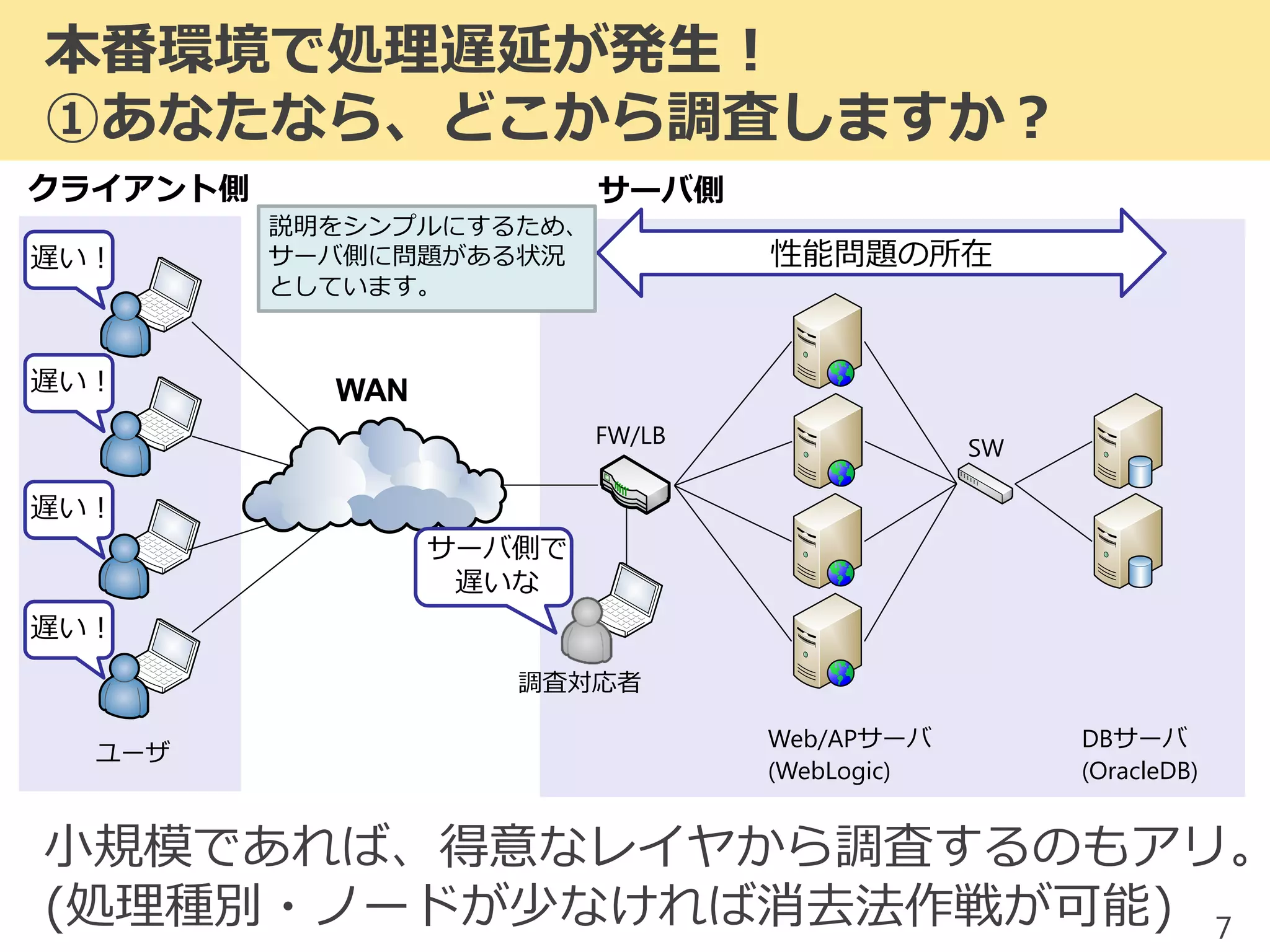
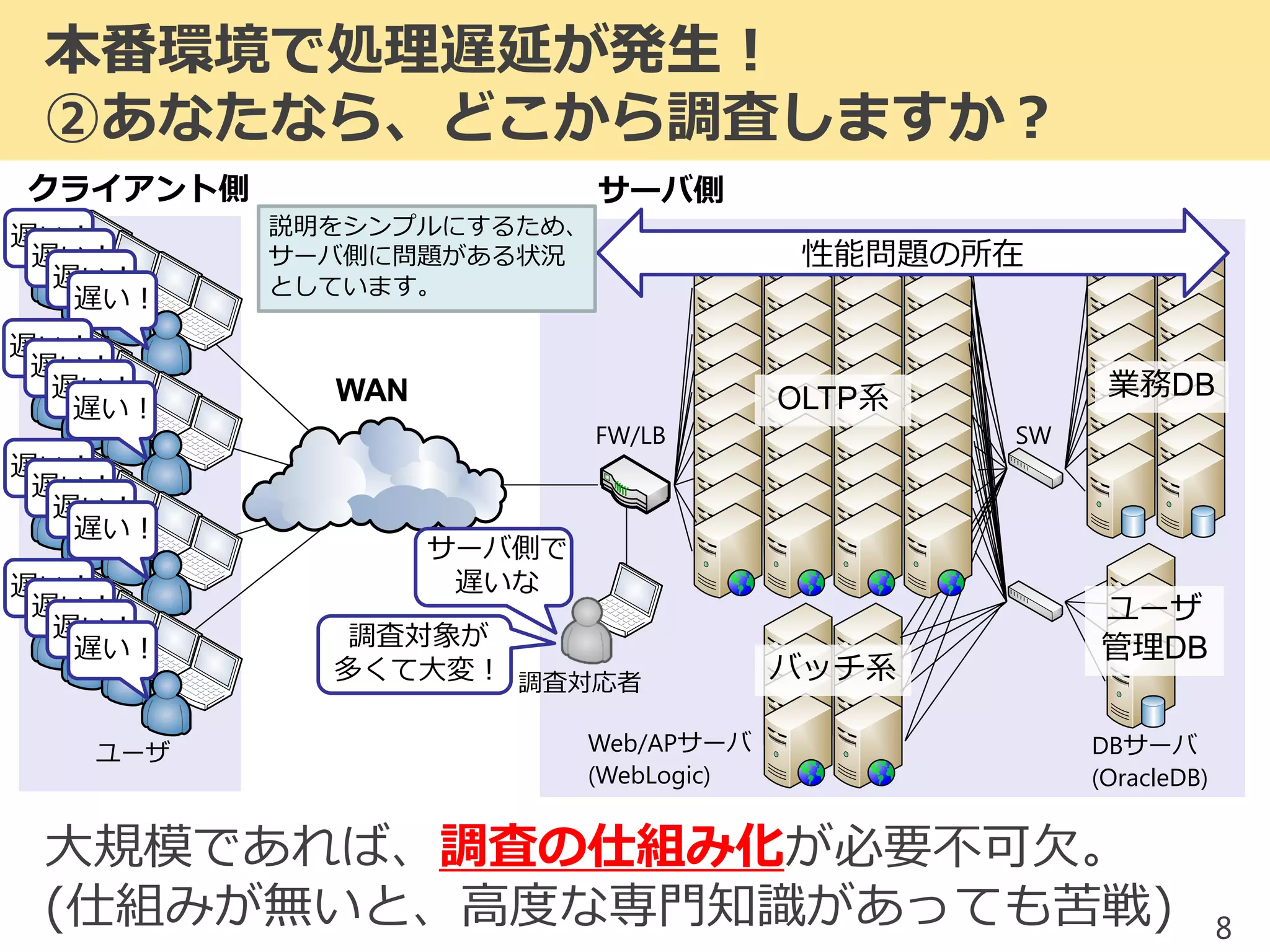
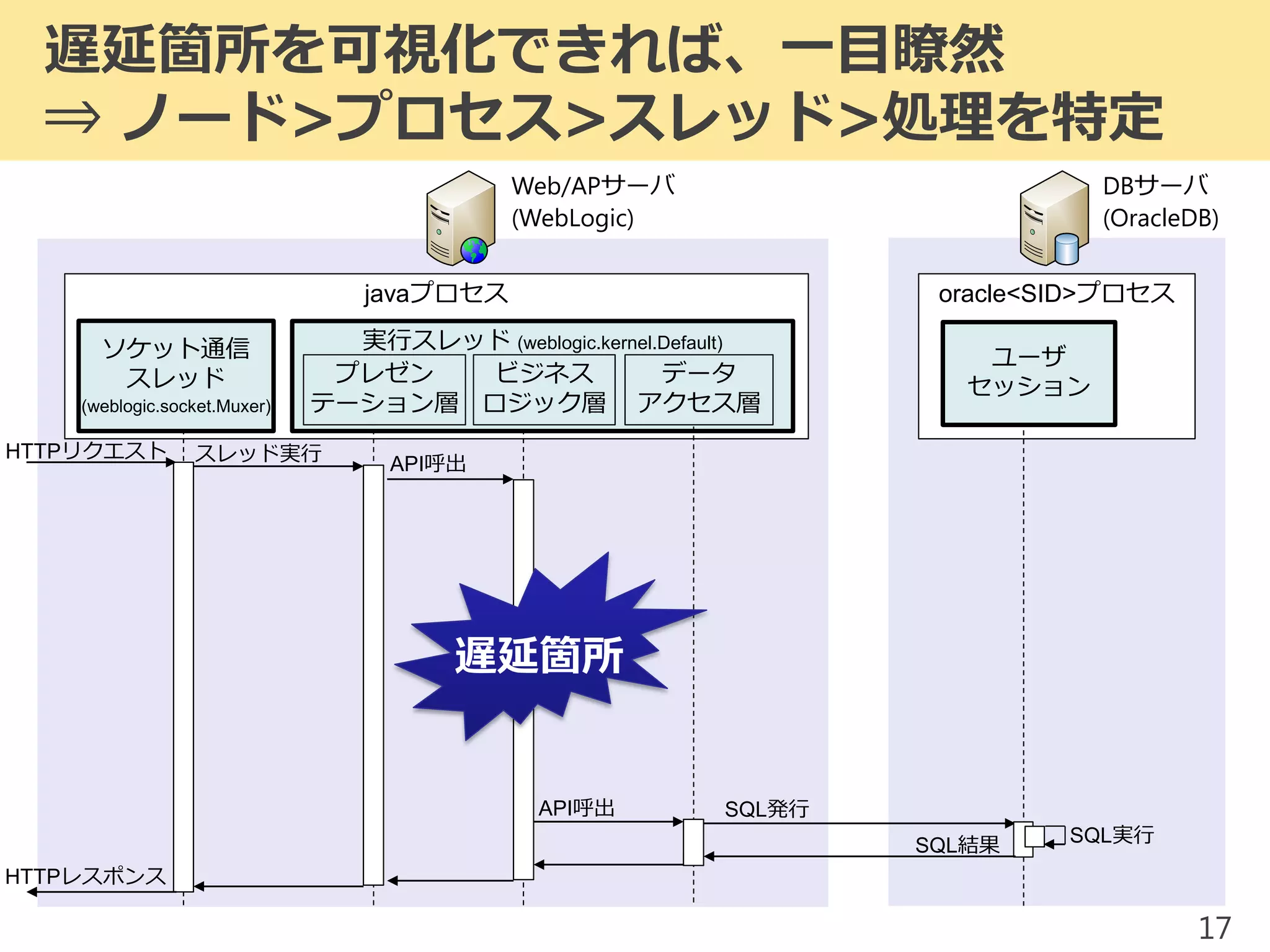
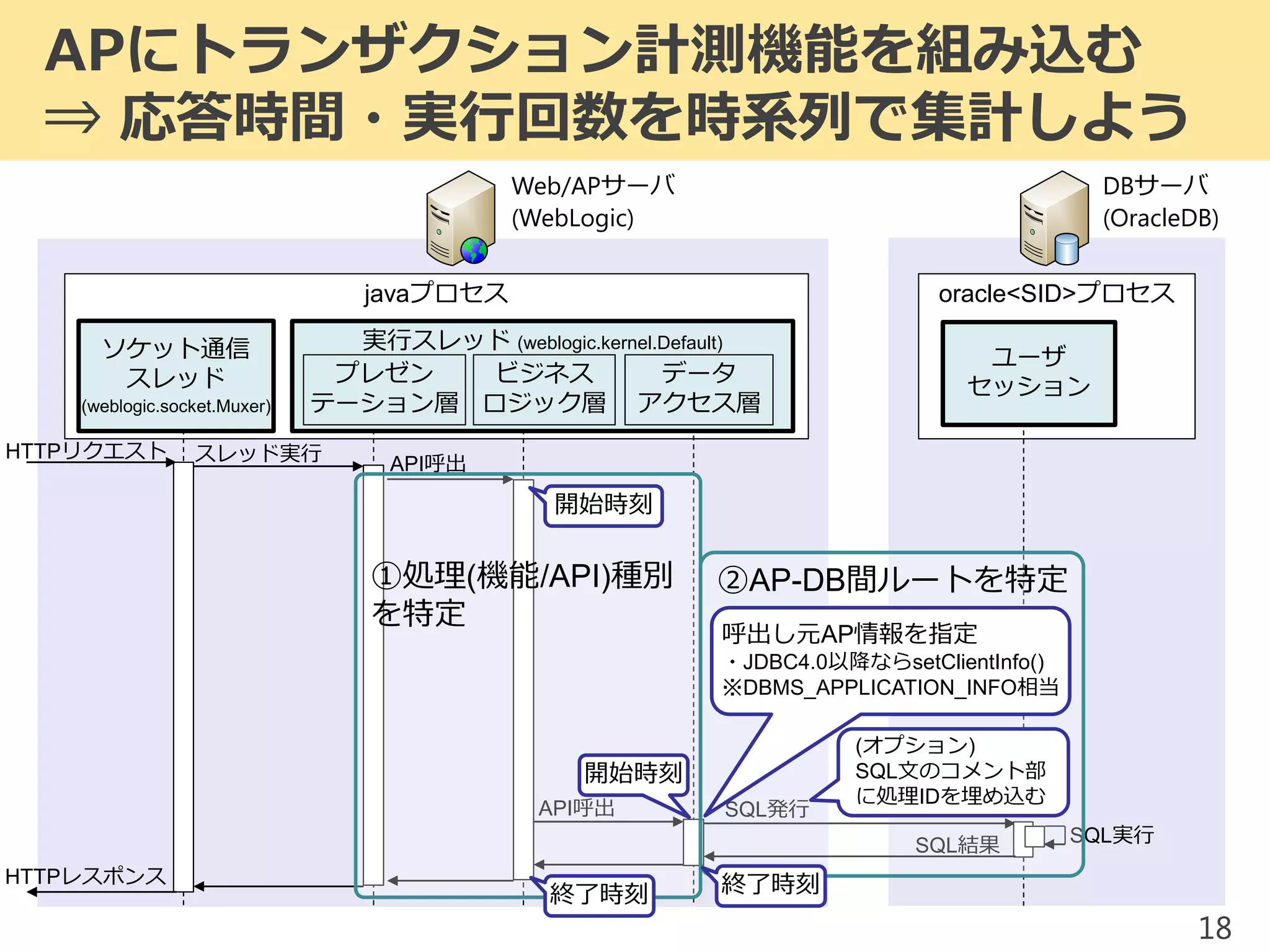
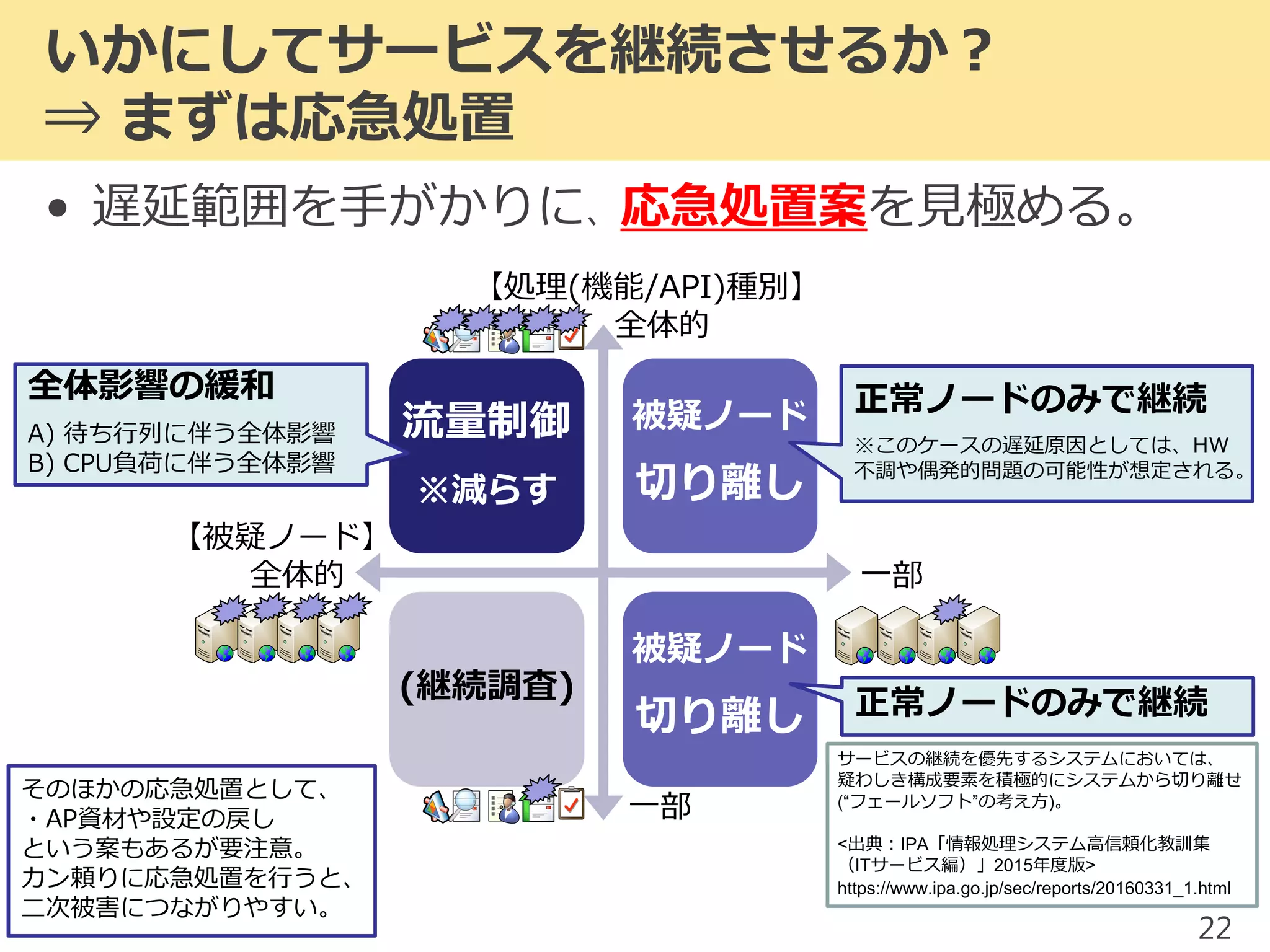
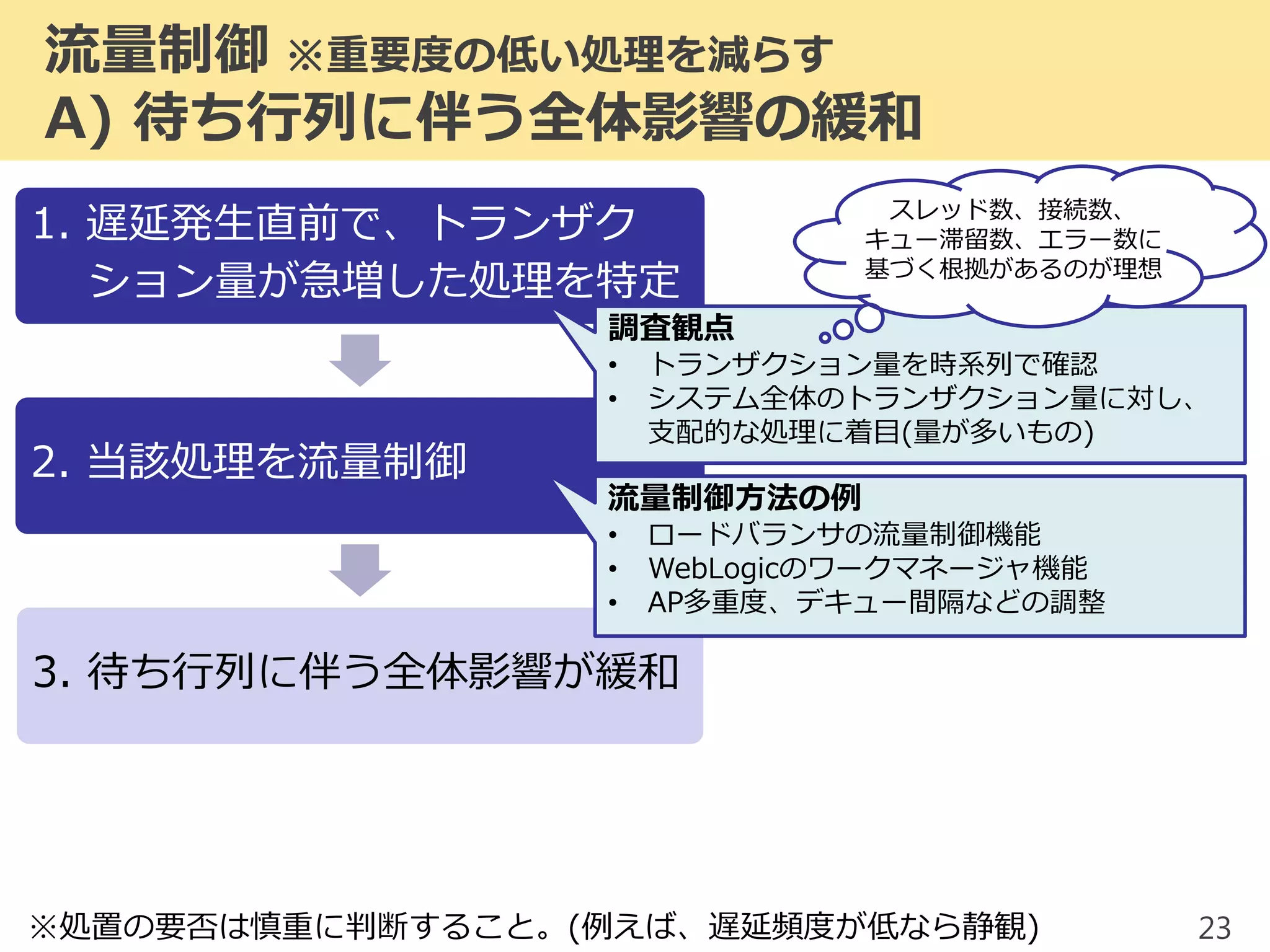
2017/1/17 JPOUG in 15 minutes #3にて発表した内容です。 昨今、システムの大規模(集約)化がトレンドとなっています。そのようなミッションクリティカルシステムにおいて、いかにして性能問題調査を行っていくかを解説します。













![参考: 被疑箇所調査用のOS(Linux)コマンド 27 # CPU負荷の高いプロセスの調査 top -c -d <計測間隔[秒]> # プロセス状態の調査 (メモリ使用量, 累計CPU時間, 実行状態) ps auxfww または ps axww -o user,pid,ppid,stat,rss,etime,cputime,wchan:25,cmd # プロセス内部で、CPU負荷の高い処理の調査 (関数ごとの%CPU, コールグラフ) perf record -F 997 -g -o <出力ファイル名> -p <PID> sleep <計測時間[秒]> perf report -v -n --showcpuutilization --stdio -i <出力したファイル名> # スタックトレース取得(perfのコールグラフ補完) ※SIGSTOPによる一瞬停止を伴うことに留意 gstack <PID> # プロセスの外部(システムコール)で待ちが生じている箇所の調査 lsof -p <PID> strace -f -ff -tt -T -v -x -s 256 -o <出力ファイル名> -p <PID> • 事前に試験環境(同じOS ver.)で動作検証しておく。 • 影響懸念のあるコマンドは極力使用しない。 【調査に役立ったコマンドの紹介】 想定外の挙動となる可能性に備え、 いきなり本番環境での実行は控える](https://image.slidesharecdn.com/oracledatabasejavalinuxpart1-170117172718/75/Oracle-Database-Java-Linux-Part-1-27-2048.jpg)
