Download as PDF, PPTX







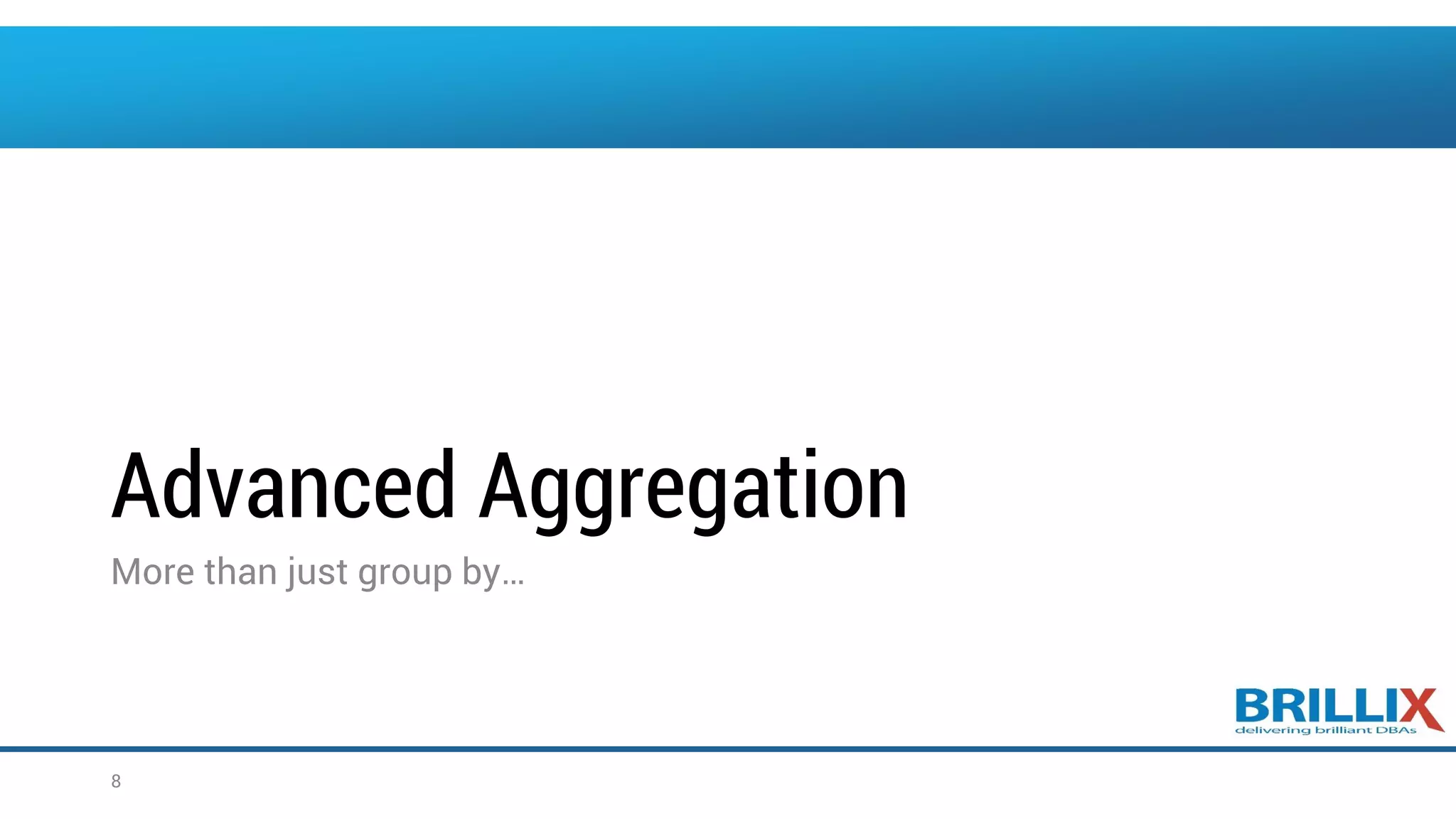


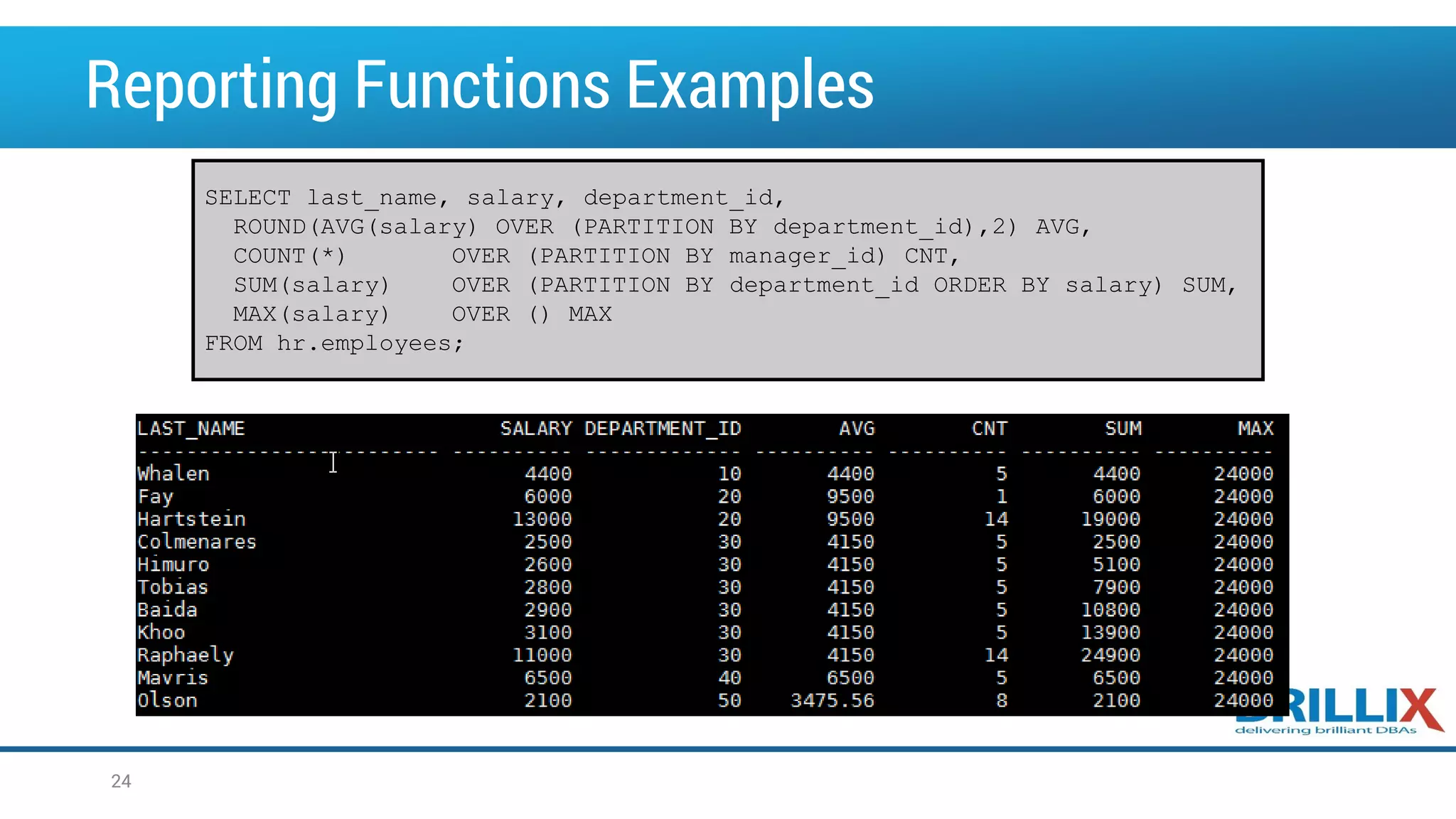
![The ROLLUP Operator • ROLLUP is an extension of the GROUP BY clause • Use the ROLLUP operation to produce cumulative aggregates, such as subtotals SELECT [column,] group_function(column). . . FROM table [WHERE condition] [GROUP BY [ROLLUP] group_by_expression] [HAVING having_expression]; [ORDER BY column]; ` 11](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-11-2048.jpg)
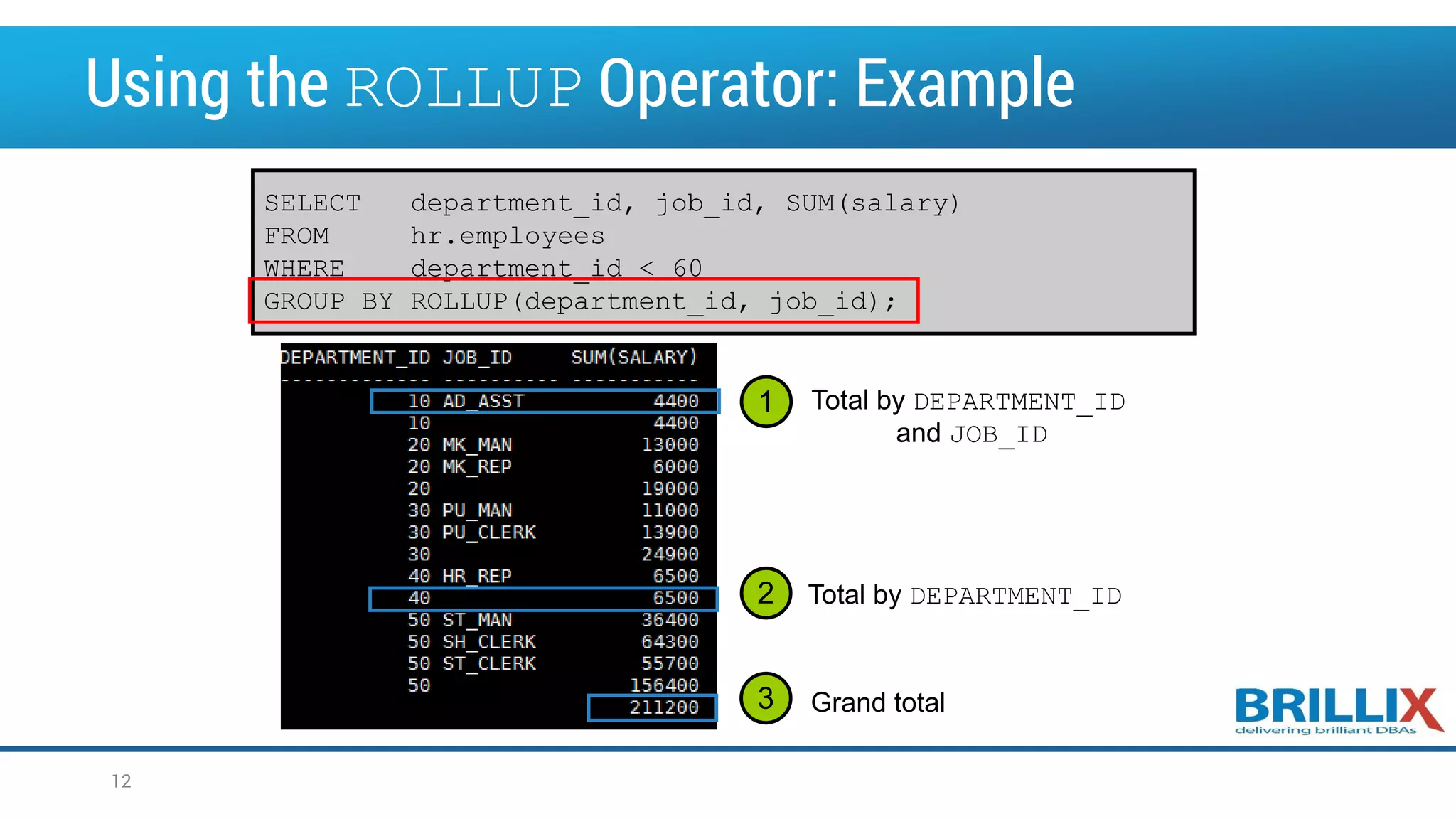
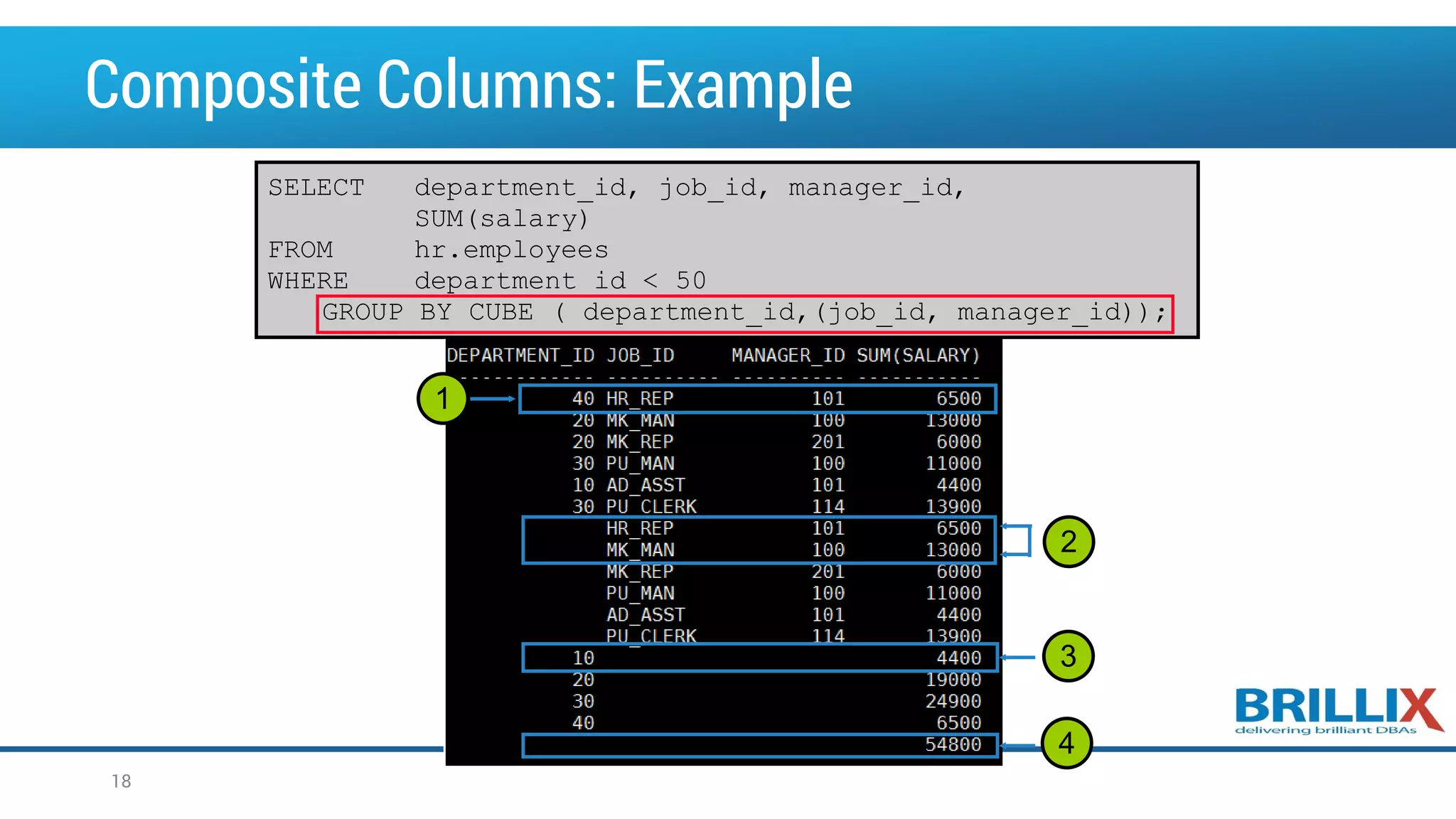
![The CUBE Operator • CUBE is an extension of the GROUP BY clause • You can use the CUBE operator to produce cross-tabulation values with a single SELECT statement SELECT [column,] group_function(column)... FROM table [WHERE condition] [GROUP BY [CUBE] group_by_expression] [HAVING having_expression] [ORDER BY column]; 13](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-13-2048.jpg)









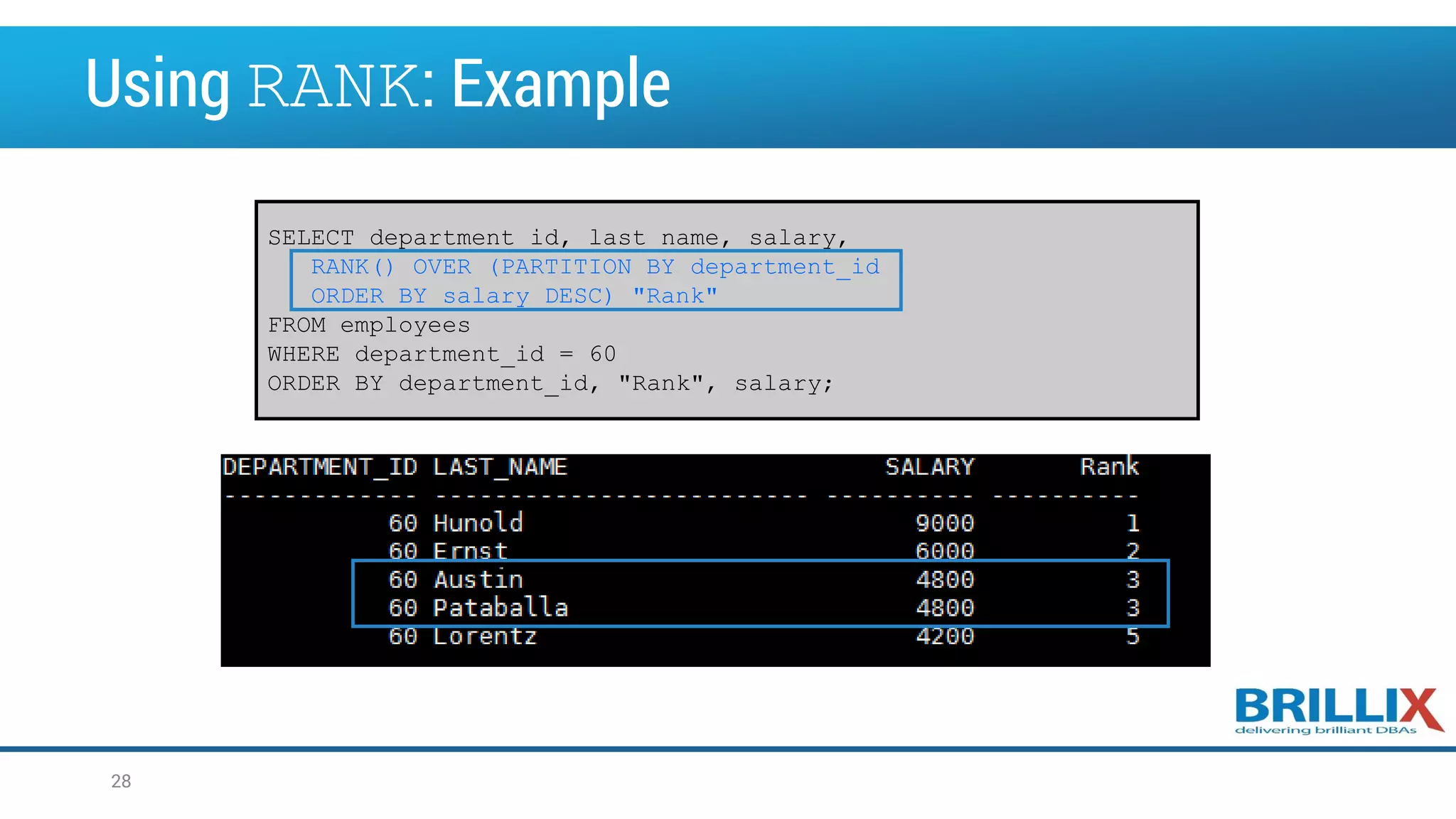
![Working with the RANK Function • The RANK function calculates the rank of a value in a group of values, which is useful for top-N and bottom-N reporting. • When using the RANK function, ascending is the default sort order, which you can change to descending. • Rows with equal values for the ranking criteria receive the same rank. • Oracle Database then adds the number of tied rows to the tied rank to calculate the next rank. RANK ( ) OVER ( [query_partition_clause] order_by_clause ) 27](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-27-2048.jpg)
![RANK and DENSE_RANK: Example SELECT department_id, last_name, salary, RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) "Rank", DENSE_RANK() over (partition by department_id ORDER BY salary DESC) "Drank" FROM employees WHERE department_id = 60 ORDER BY department_id, salary DESC, "Rank" DESC; DENSE_RANK ( ) OVER ([query_partition_clause] order_by_clause) 29](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-29-2048.jpg)
![Working with the ROW_NUMBER Function • The ROW_NUMBER function calculates a sequential number of a value in a group of values. • When using the ROW_NUMBER function, ascending is the default sort order, which you can change to descending. • Rows with equal values in the ranking criteria might receive different values across executions. ROW_NUMBER ( ) OVER ( [query_partition_clause] order_by_clause ) 30](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-30-2048.jpg)

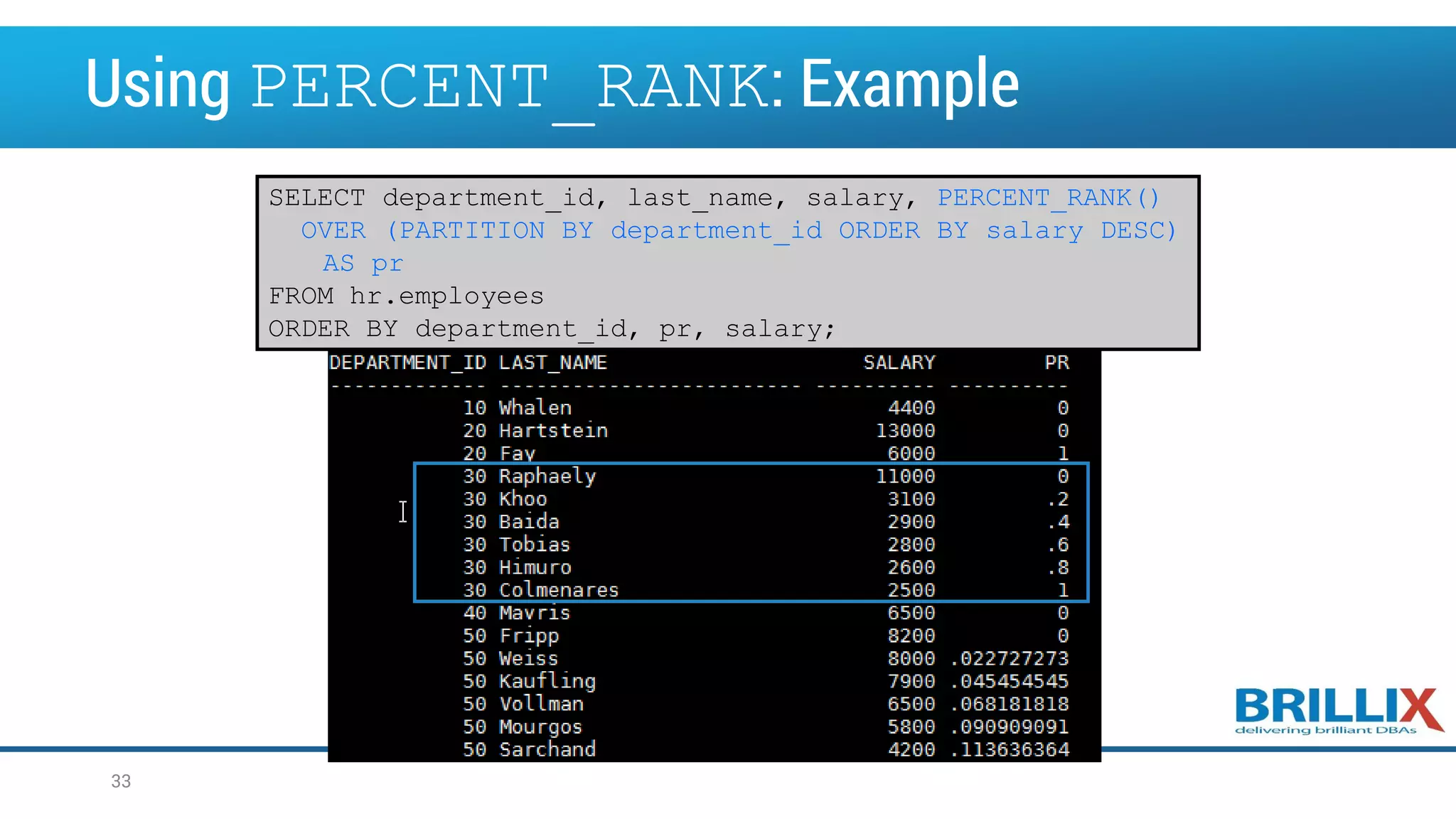
![Using the PERCENT_RANK Function • Uses rank values in its numerator and returns the percent rank of a value relative to a group of values • PERCENT_RANK of a row is calculated as follows: • The range of values returned by PERCENT_RANK is 0 to 1, inclusive. The first row in any set has a PERCENT_RANK of 0. The return value is NUMBER. Its syntax is: (rank of row in its partition - 1) / (number of rows in the partition - 1) PERCENT_RANK () OVER ([query_partition_clause] order_by_clause) 32](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-32-2048.jpg)
![Working with the NTILE Function • Not really a ranking function • Divides an ordered data set into a number of buckets indicated by expr, and assigns the appropriate bucket number to each row • The buckets are numbered 1 through expr NTILE ( expr ) OVER ([query_partition_clause] order_by_clause) 34](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-34-2048.jpg)
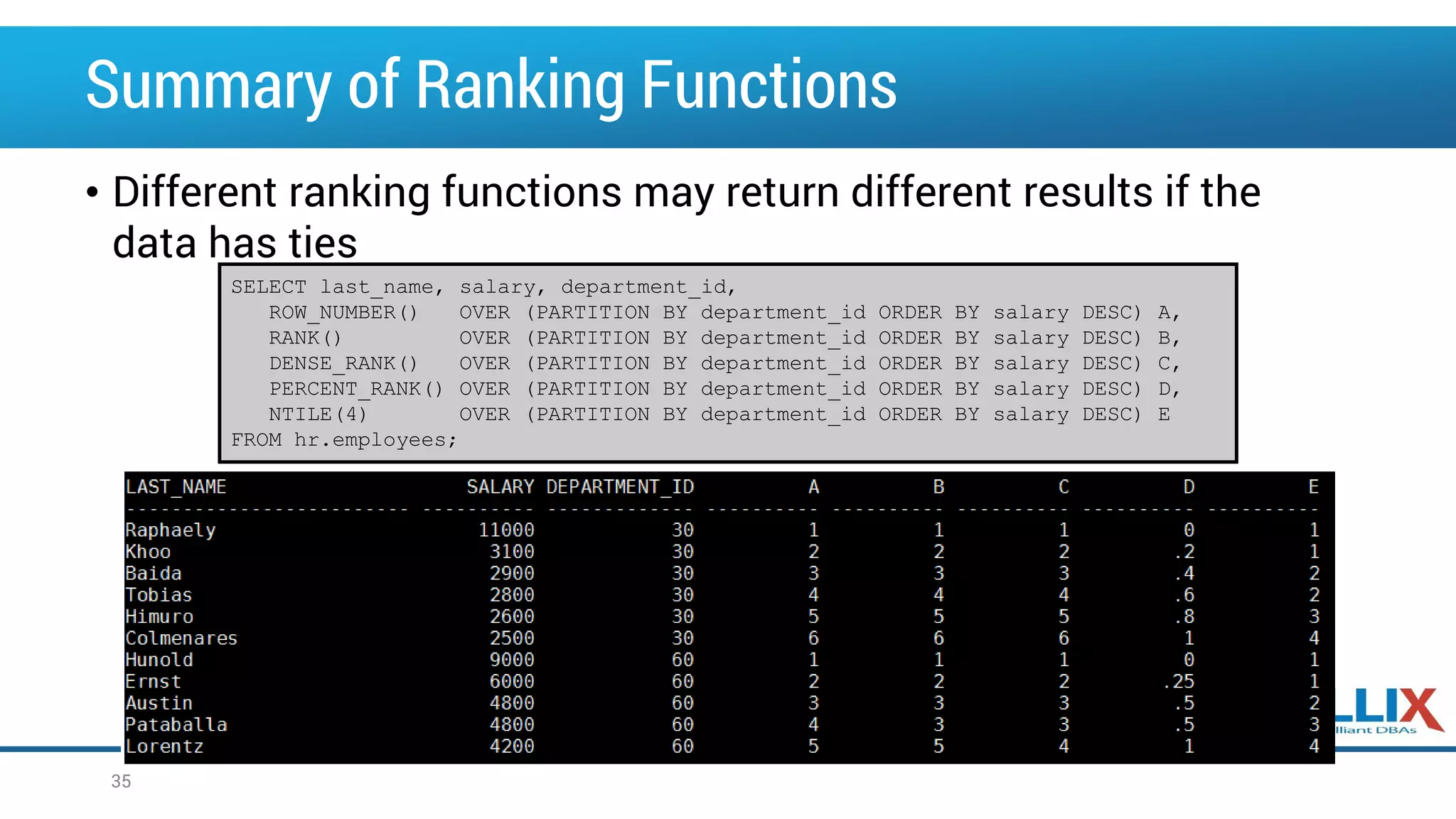

![Using the LAG and LEAD Analytic Functions • LAG provides access to more than one row of a table at the same time without a self-join. • Given a series of rows returned from a query and a position of the cursor, LAG provides access to a row at a given physical offset before that position. • If you do not specify the offset, its default is 1. • If the offset goes beyond the scope of the window, the optional default value is returned. If you do not specify the default, its value is NULL. {LAG | LEAD}(value_expr [, offset ] [, default ]) OVER ([ query_partition_clause ] order_by_clause) 37](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-37-2048.jpg)
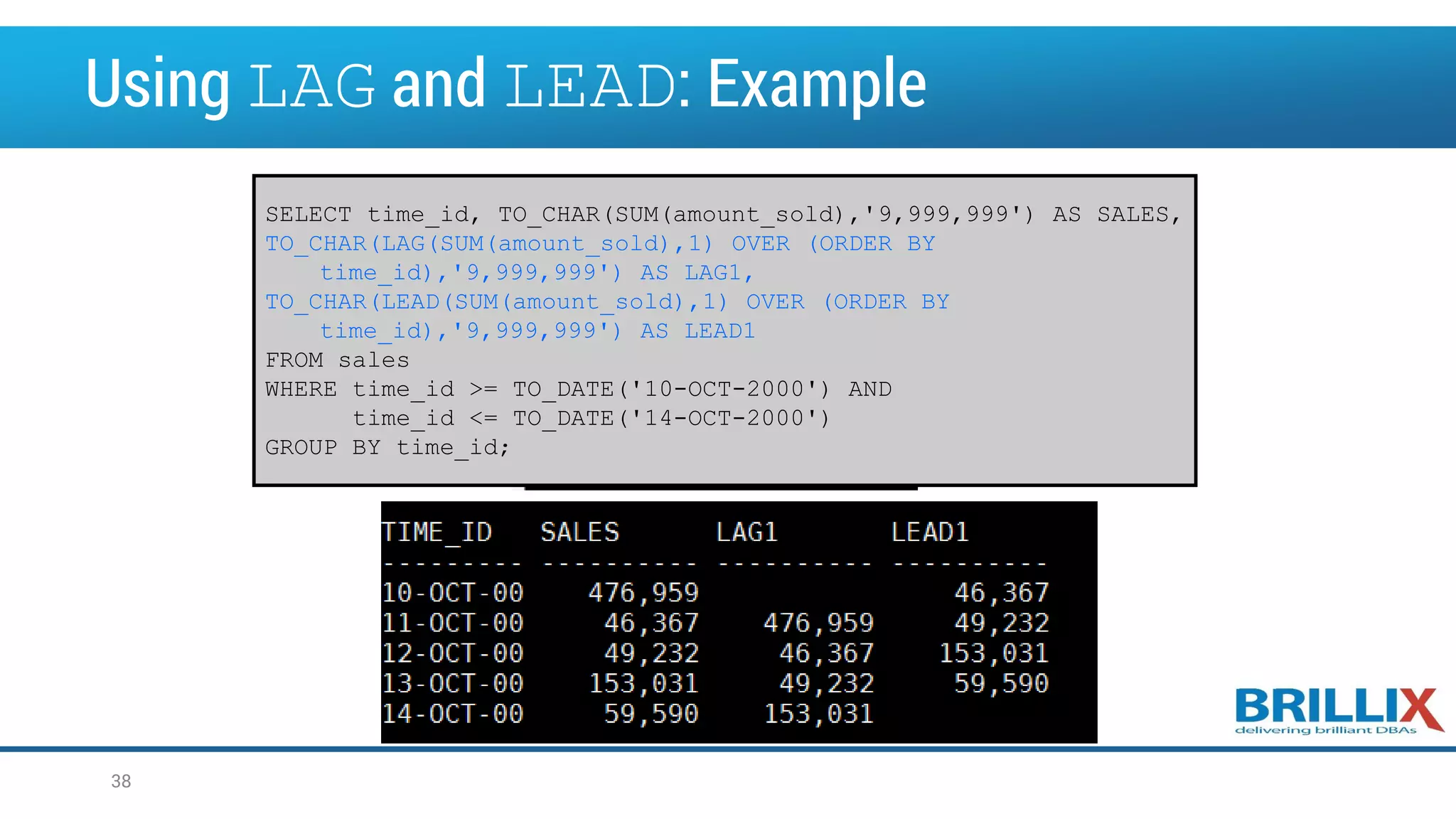
![Using FIRST_VALUE/LAST_VALUE • Returns the first/last value in an ordered set of values • If the first value in the set is null, then the function returns NULL unless you specify IGNORE NULLS. This setting is useful for data densification. 39 FIRST_VALUE (expr [ IGNORE NULLS ]) OVER (analytic_clause) LAST_VALUE (expr [ IGNORE NULLS ]) OVER (analytic_clause)](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-39-2048.jpg)
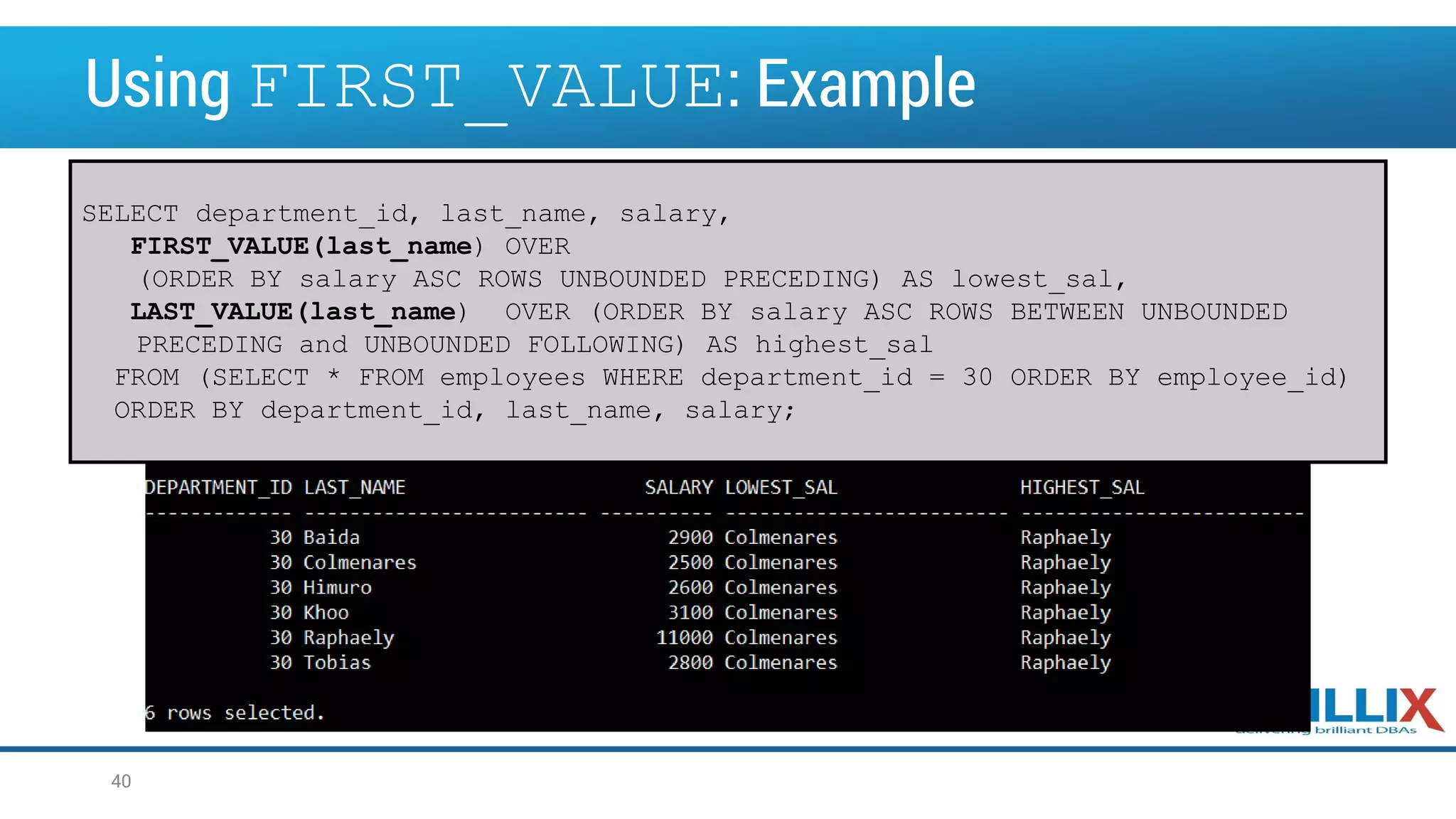
![Using NTH_VALUE Analytic Function • Returns the N-th values in an ordered set of values • Different default window: RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 41 NTH_VALUE (measure_expr, n) [ FROM { FIRST | LAST } ][ { RESPECT | IGNORE } NULLS ] OVER (analytic_clause)](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-41-2048.jpg)
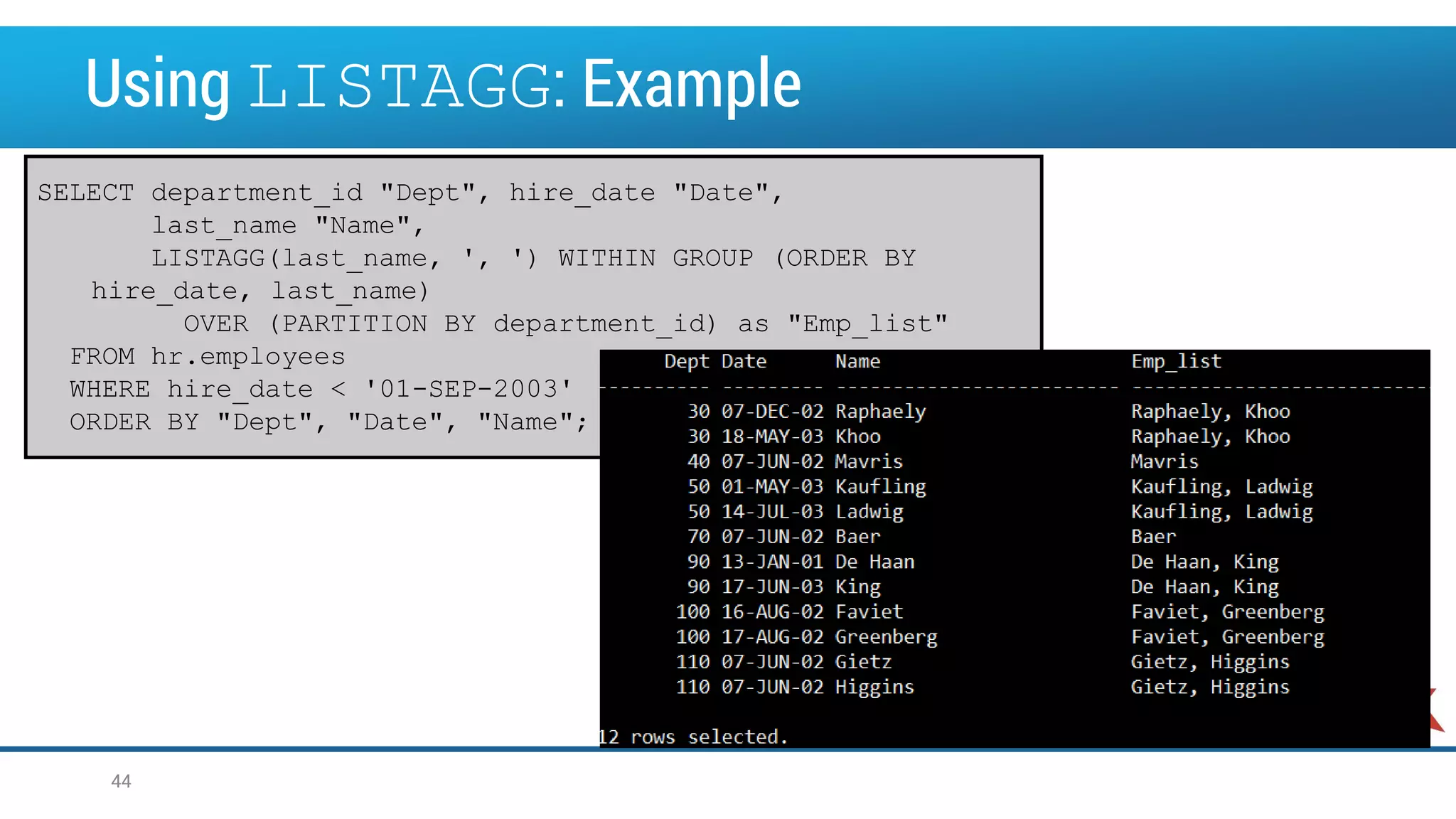
![Using the LISTAGG Function • For a specified measure, LISTAGG orders data within each group specified in the ORDER BY clause and then concatenates the values of the measure column • WARNING: Limited to output of 4000 chars (else, error message in runtime) 43 LISTAGG(measure_expr [, 'delimiter']) WITHIN GROUP (order_by_clause) [OVER query_partition_clause]](https://image.slidesharecdn.com/oow2016oracleadvancedsqlandanalyticfunctionsfinal-160919152345/75/OOW2016-Exploring-Advanced-SQL-Techniques-Using-Analytic-Functions-43-2048.jpg)














The document is a presentation by Zohar Elkayam, CTO at Brillix, discussing advanced SQL techniques, focusing on analytic functions, aggregation methods like rollup and cube, and features of Oracle 12c. It provides detailed explanations and examples of various SQL functionalities including reporting, ranking, inter-row functions, and pattern matching. The agenda includes enhancing query performance and efficiency using advanced SQL features for analysis and reporting.