






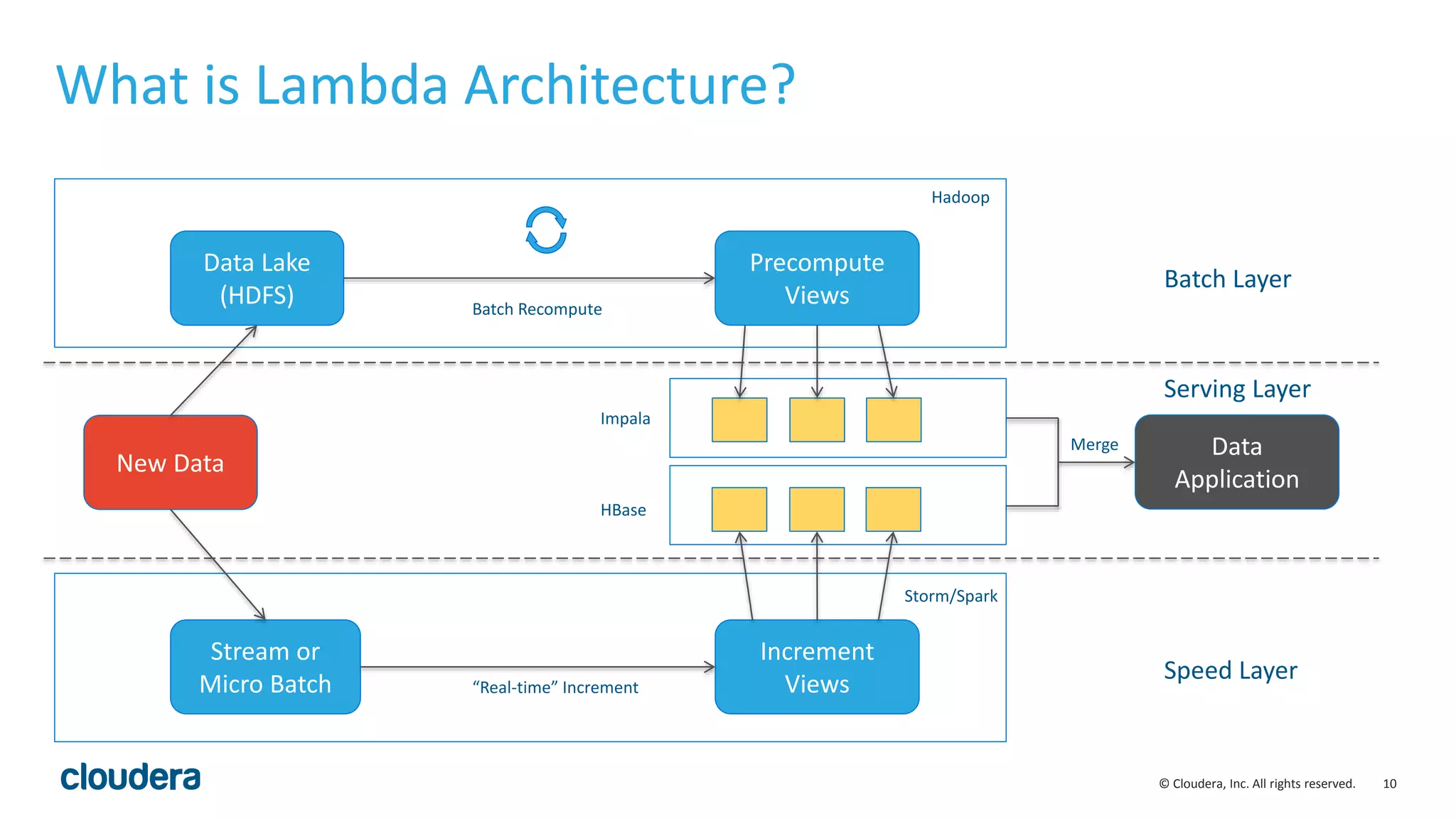



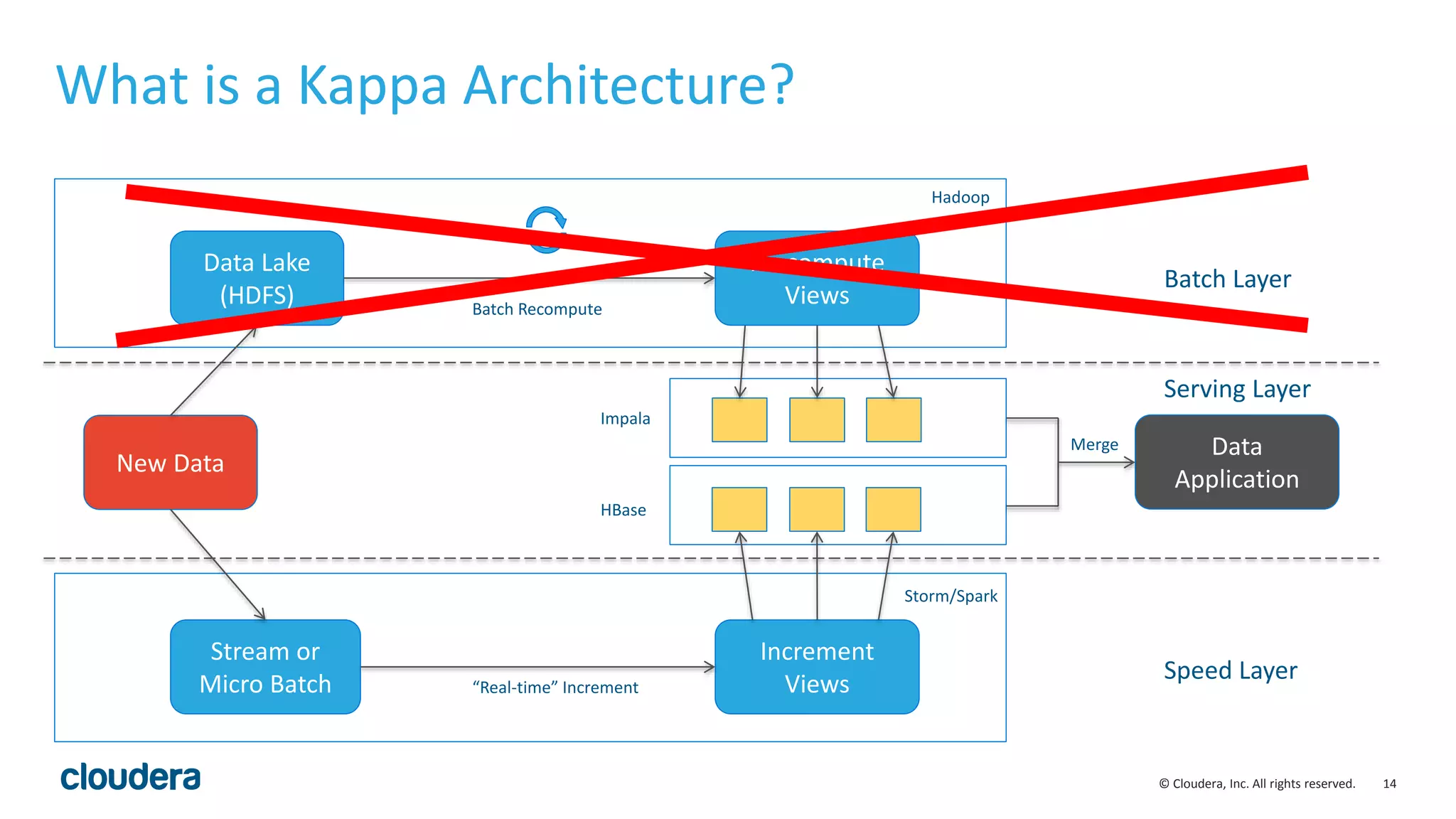
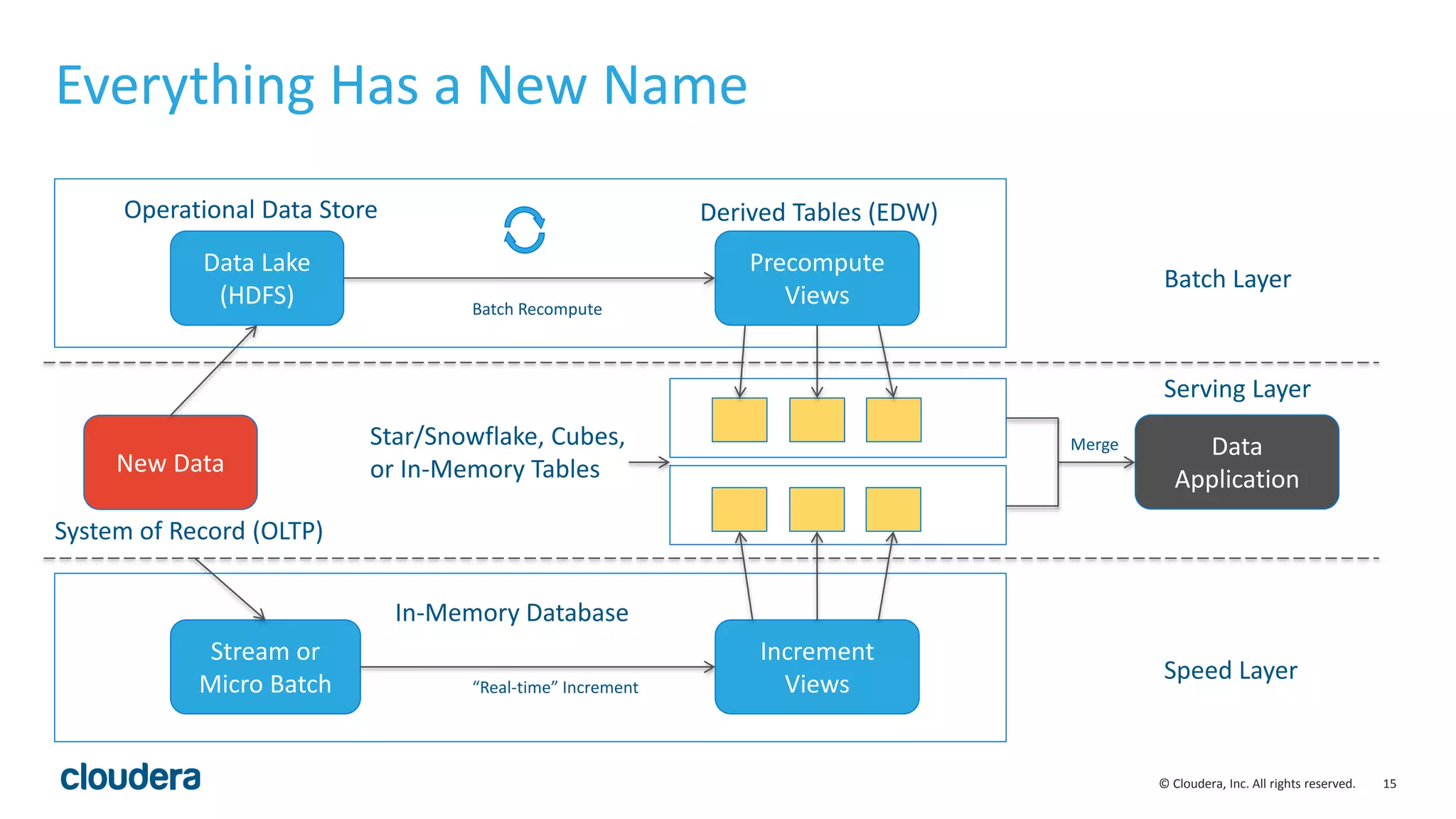
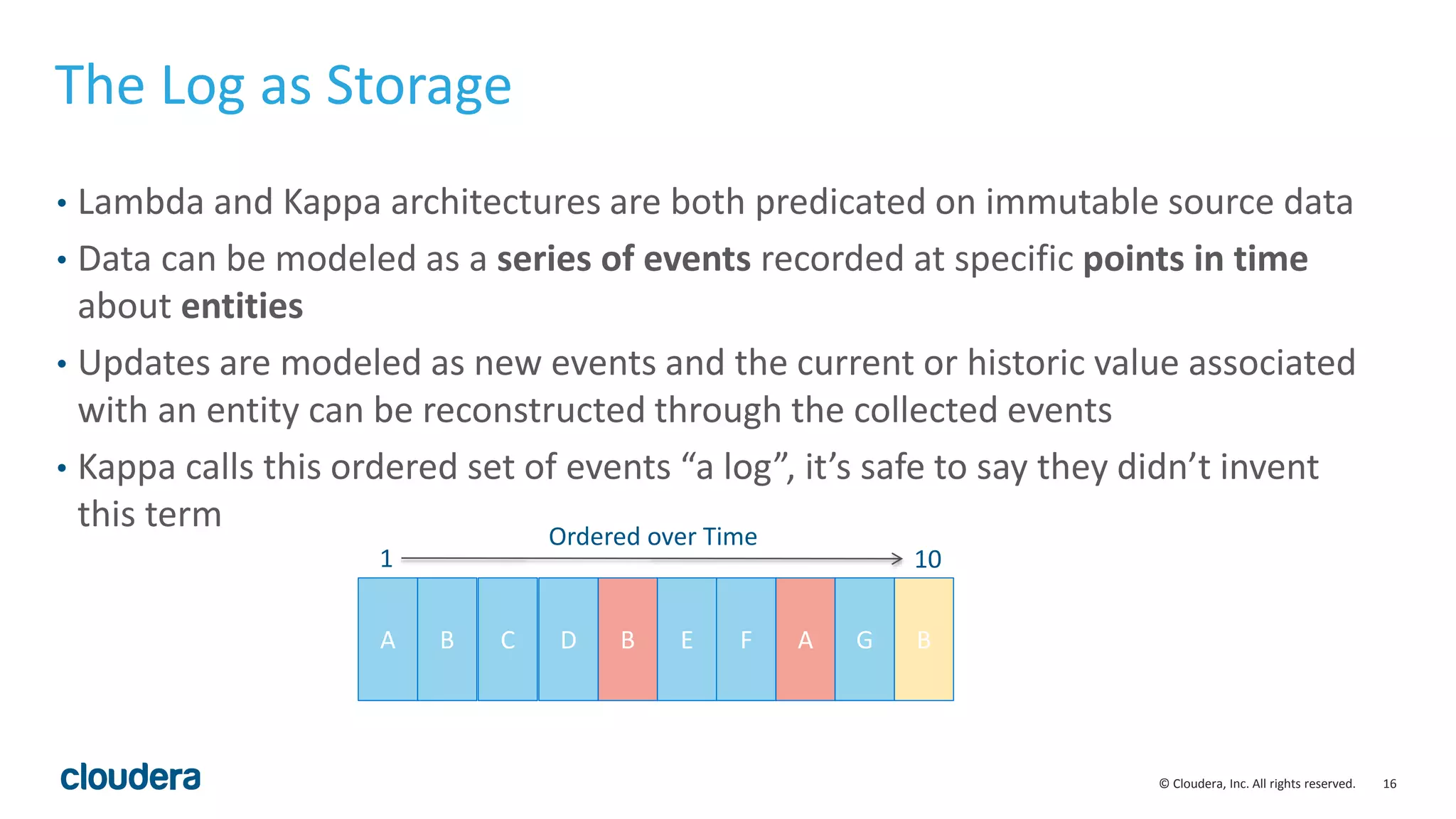


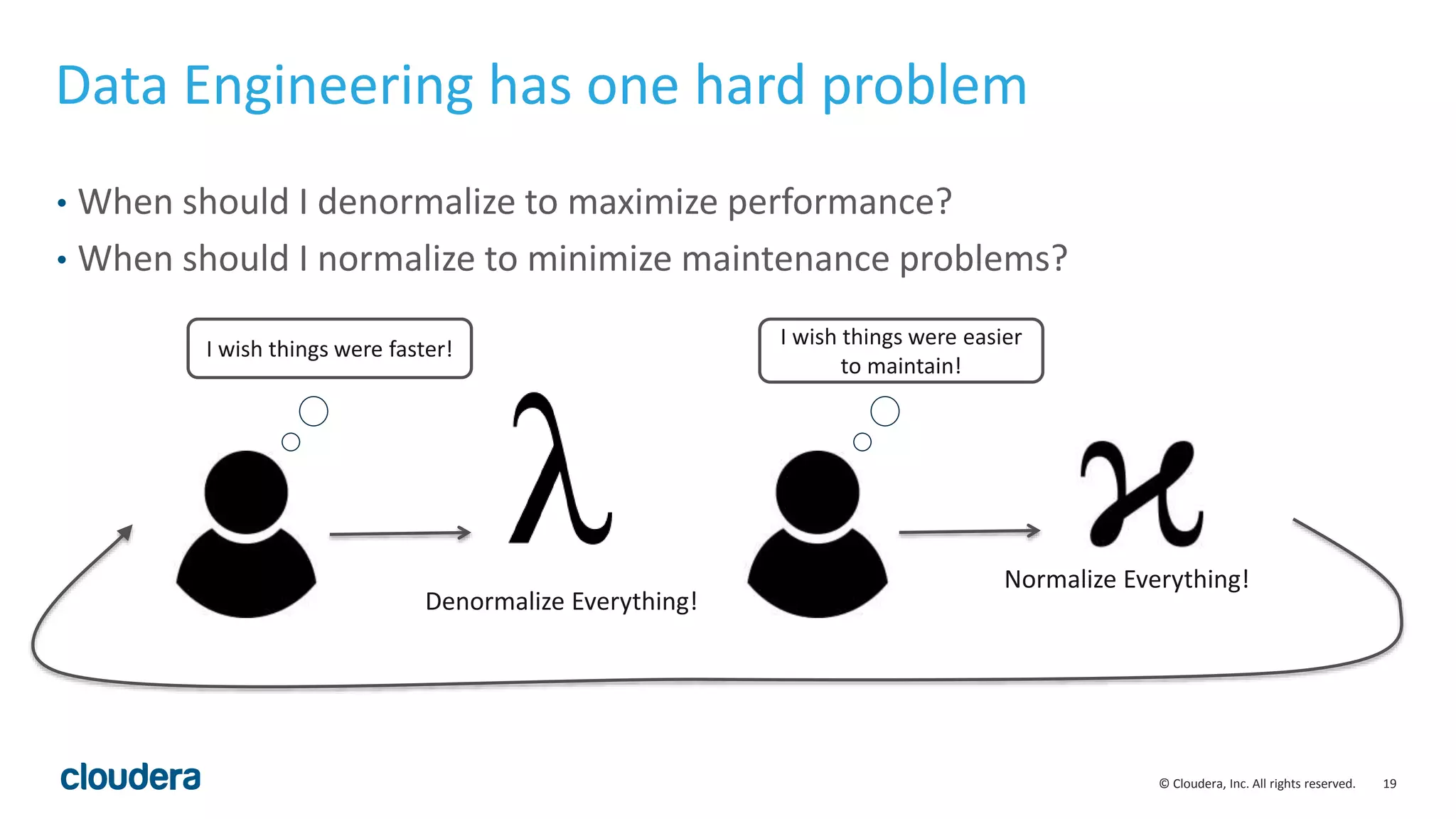



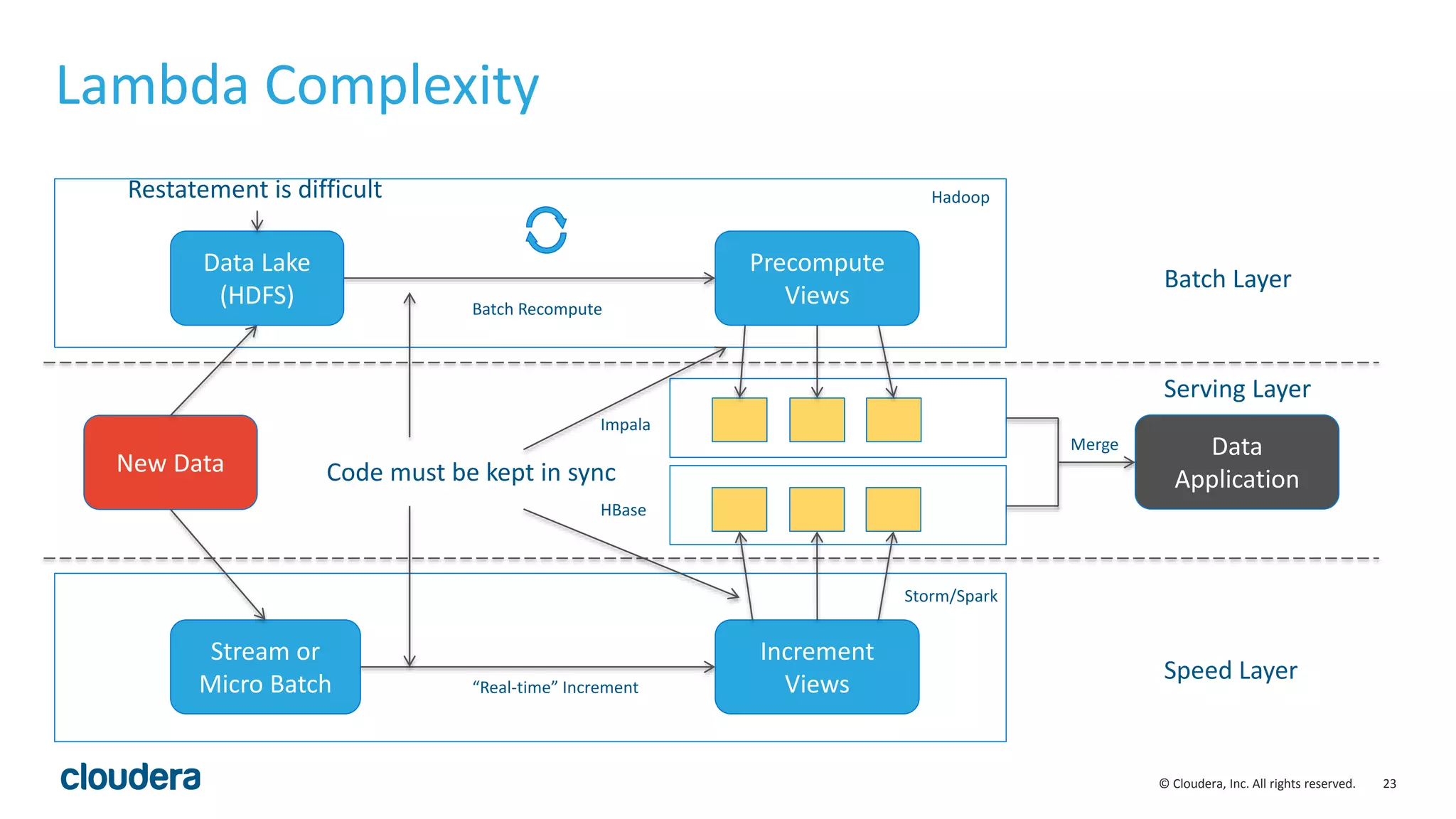
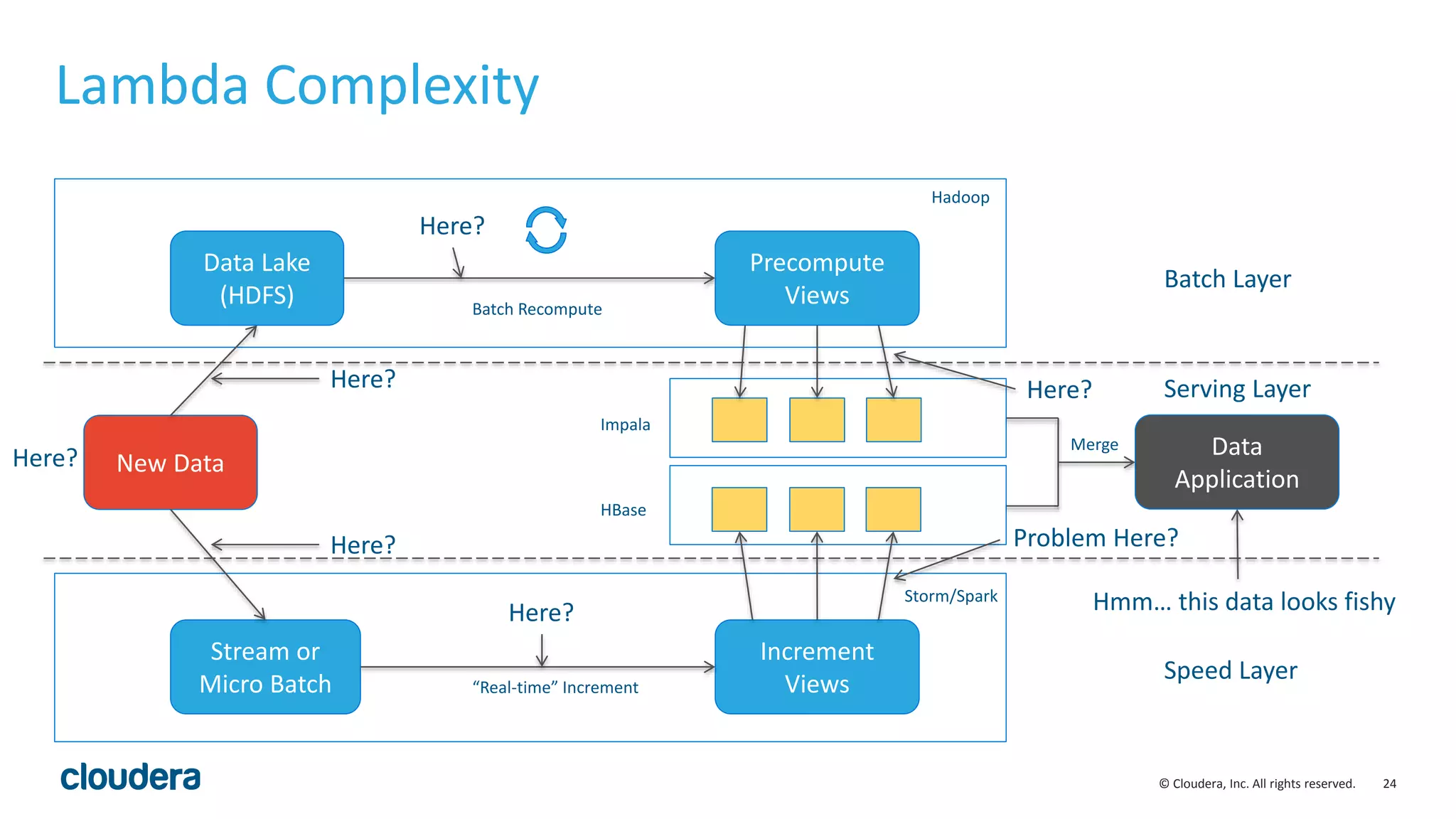



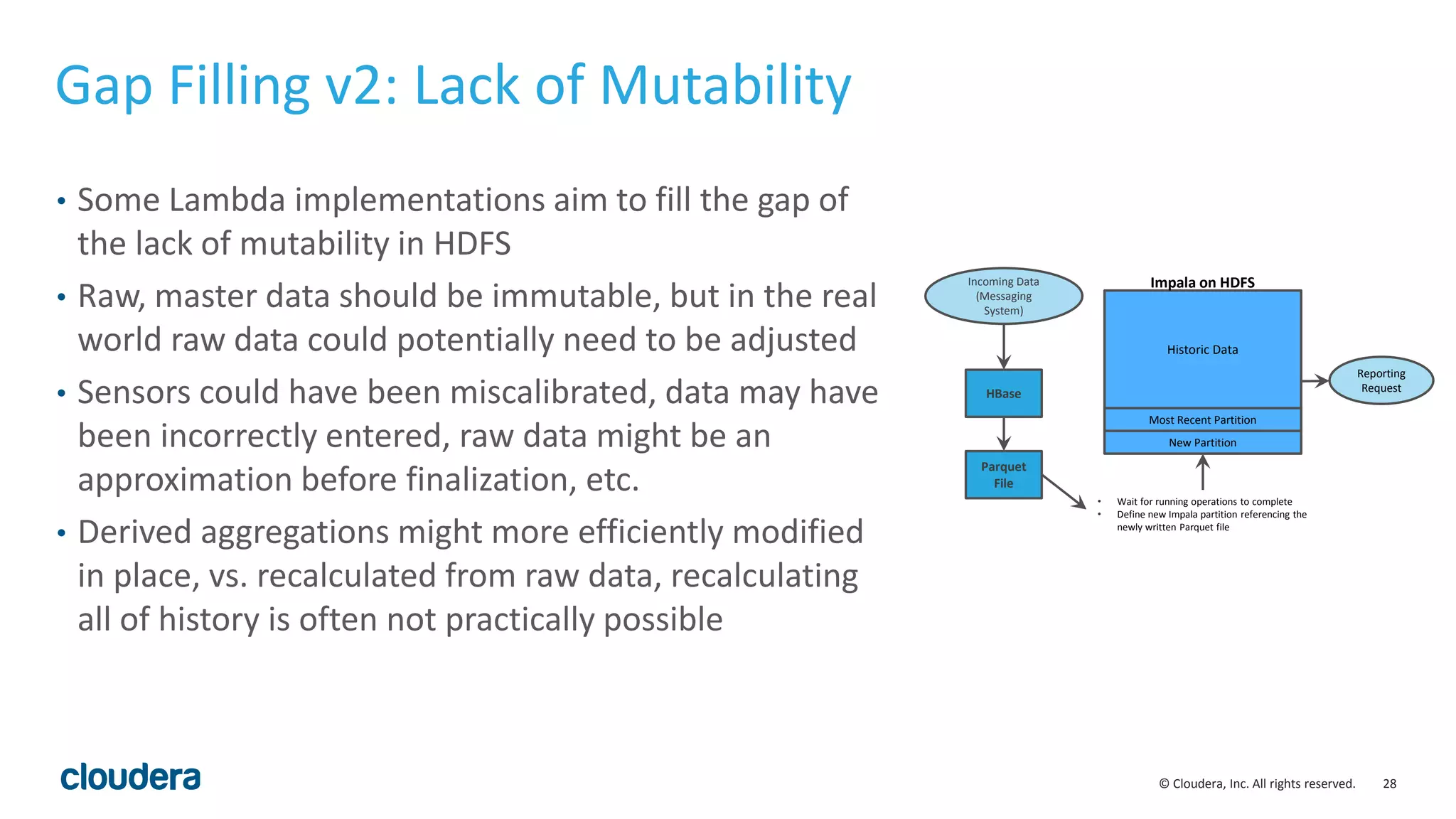

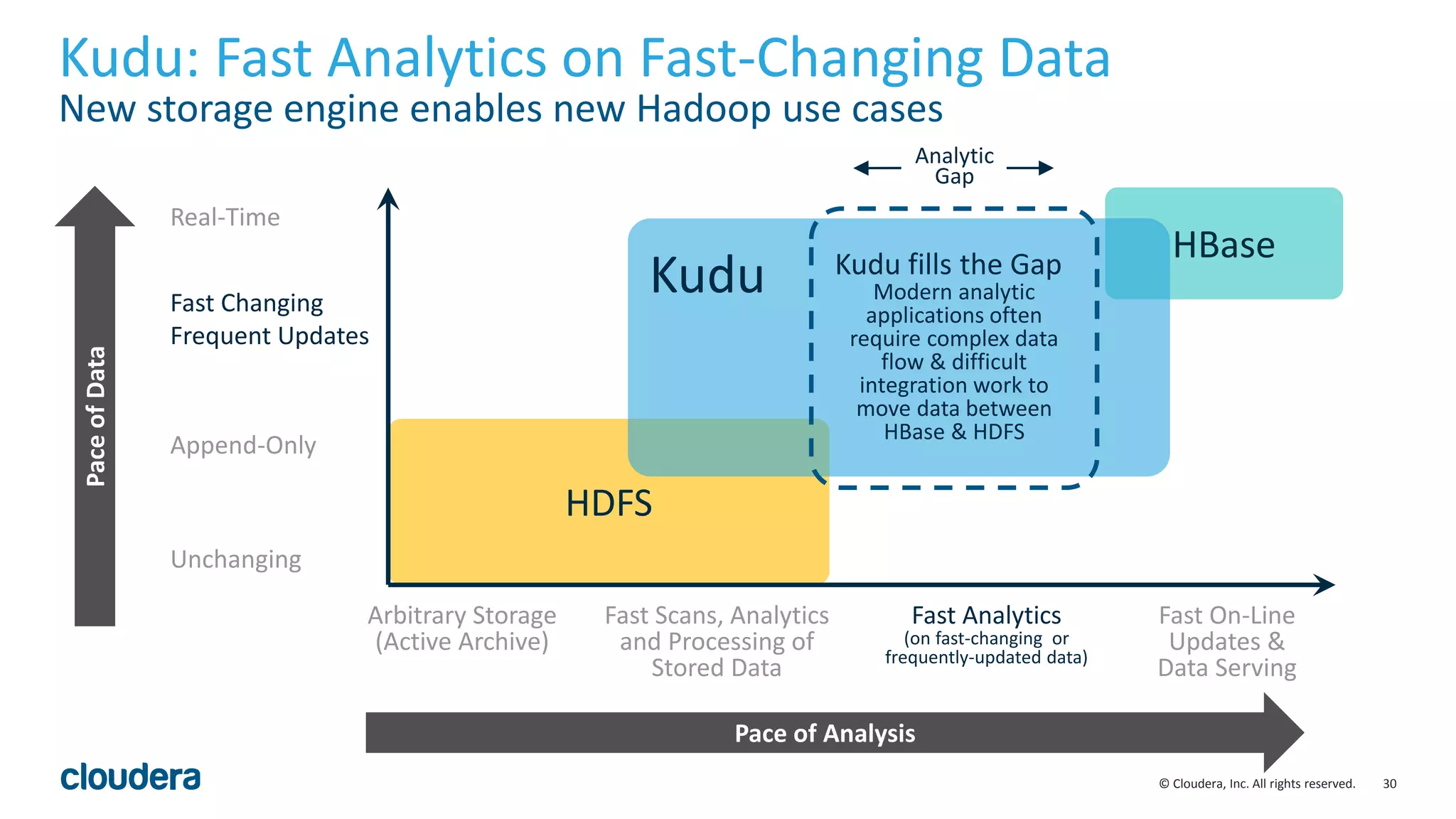



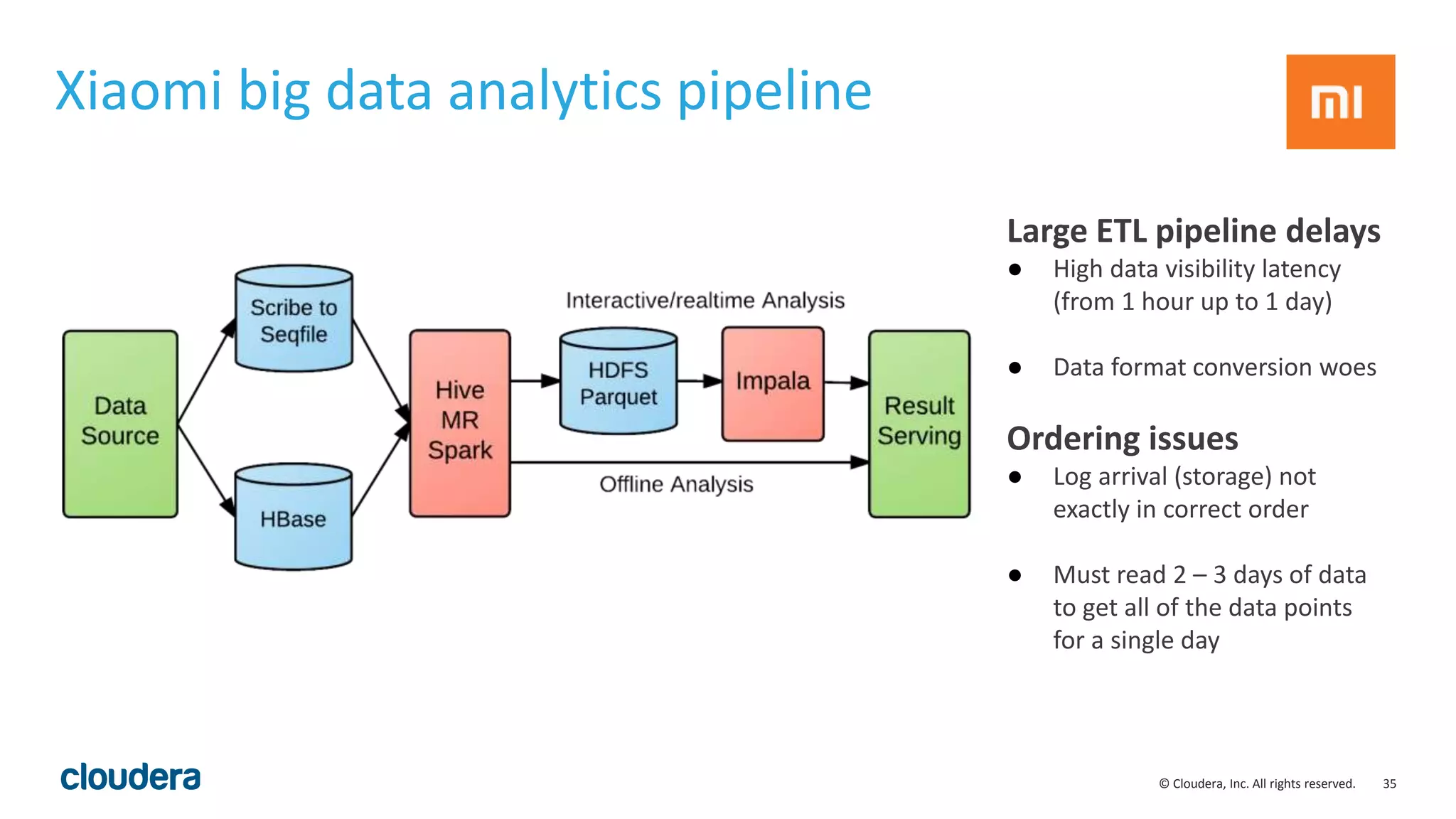
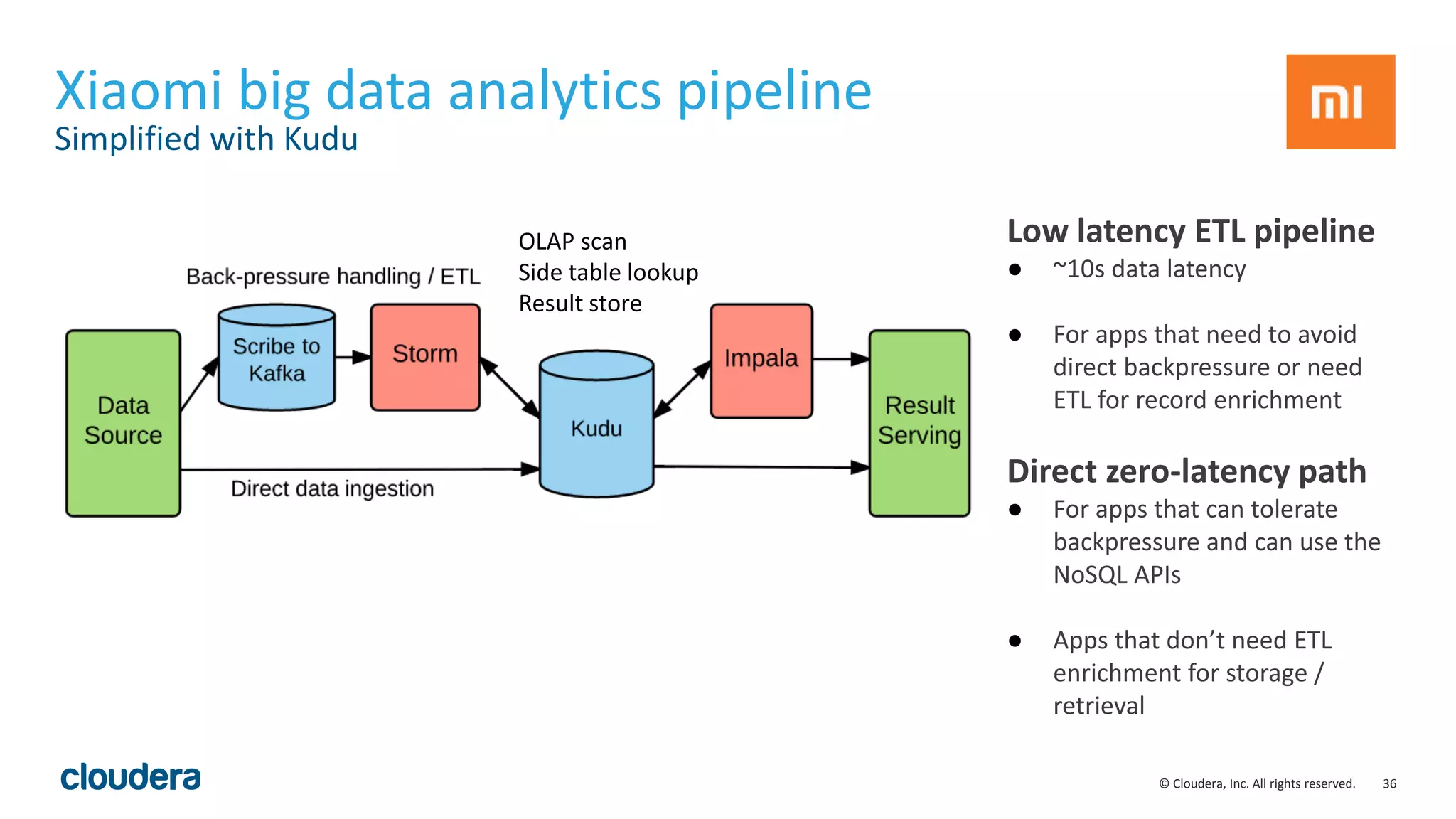


The document discusses the Lambda architecture, its advantages and disadvantages, and how Kudu can serve as an alternative. The Lambda architecture marries batch and real-time processing by using separate batch, speed, and serving layers. While it provides scalability, maintaining two code bases is complex. Kudu can fill the gap by enabling both fast analytics on frequently updated data through its ability to support updates, scans and lookups simultaneously. Examples of how Kudu has been used by Xiaomi to simplify their analytics pipeline and reduce latency are provided. The document cautions against premature optimization and advocates optimizing only as needed.