Download as PDF, PPTX





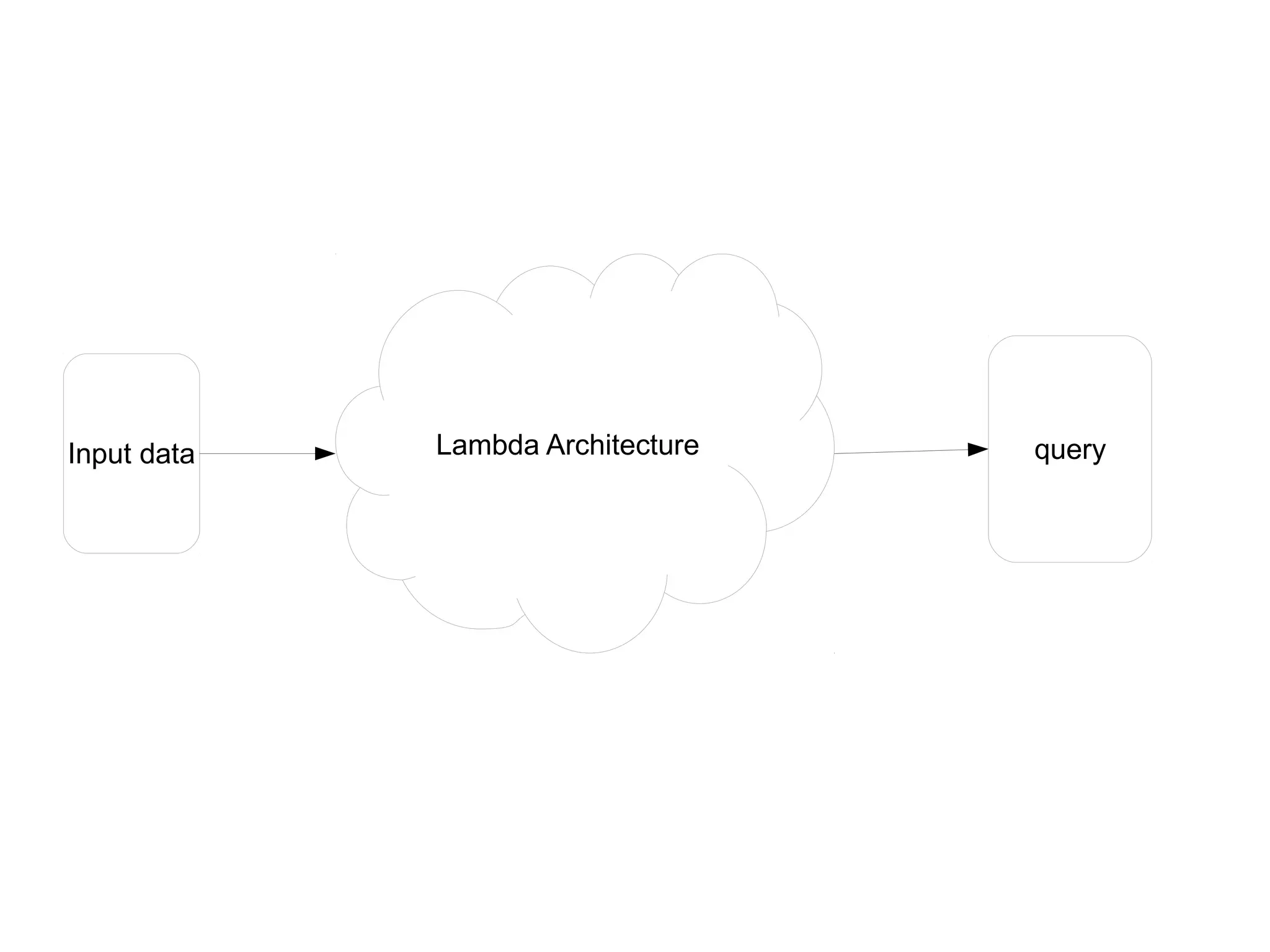
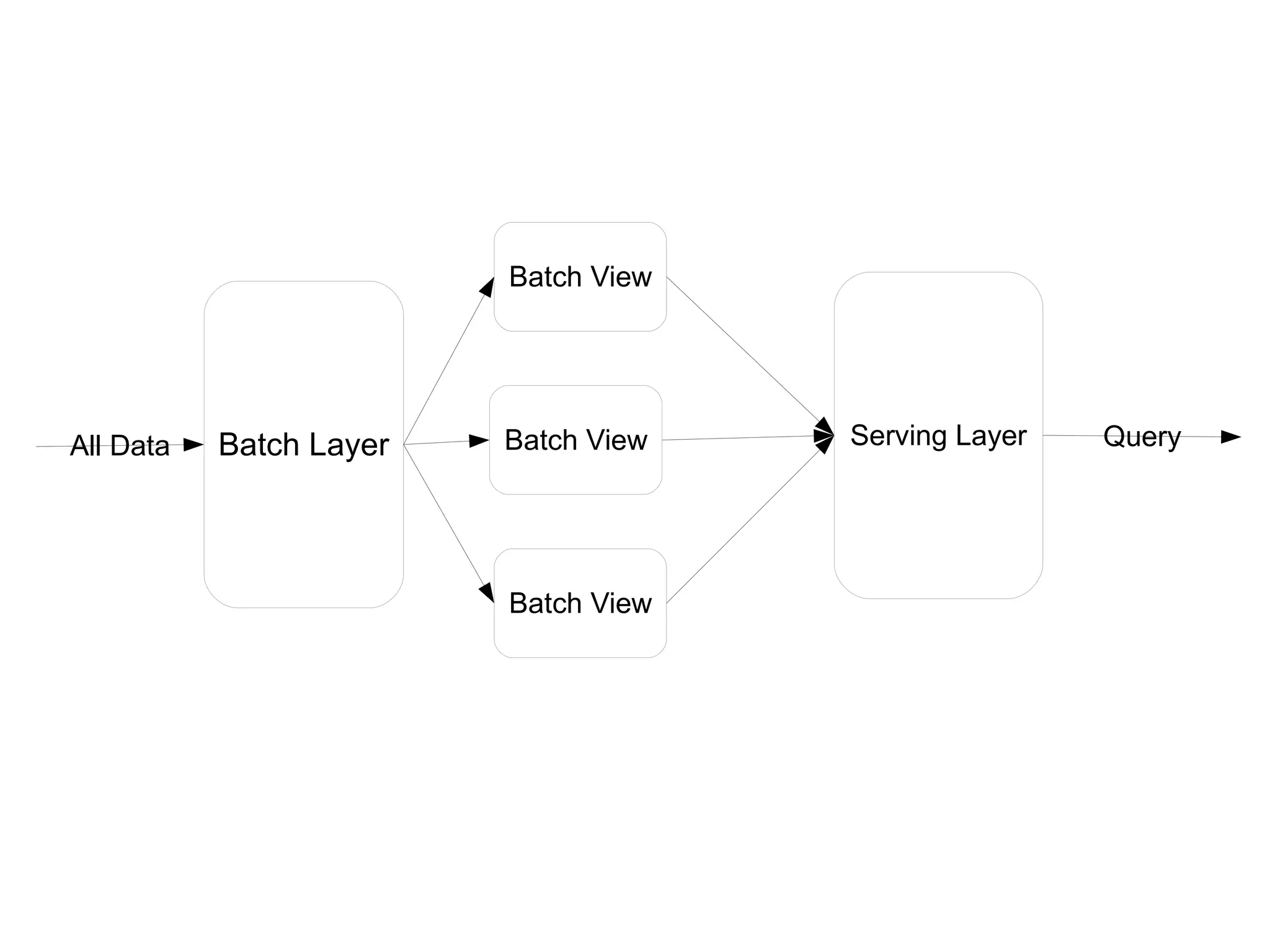




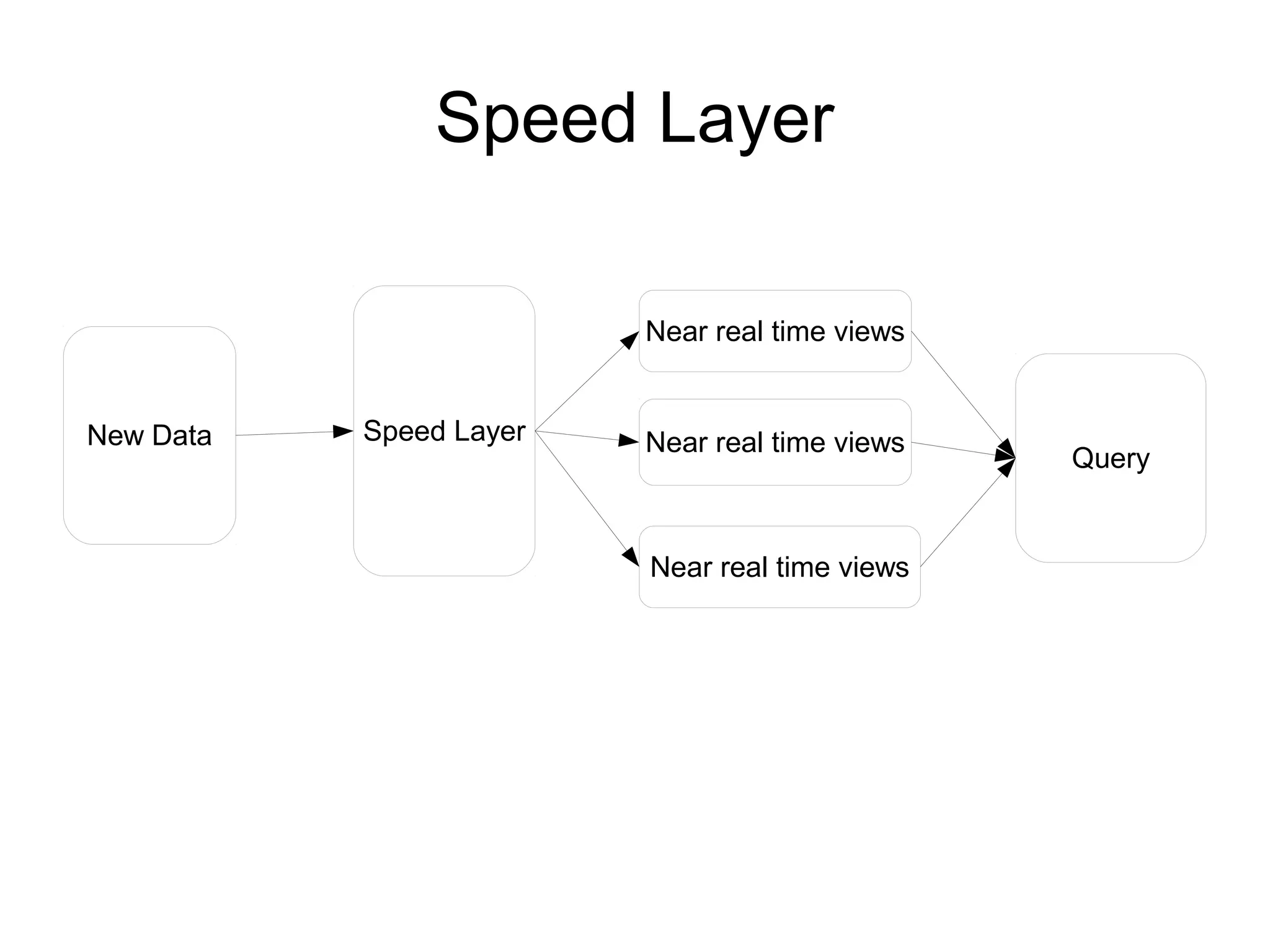
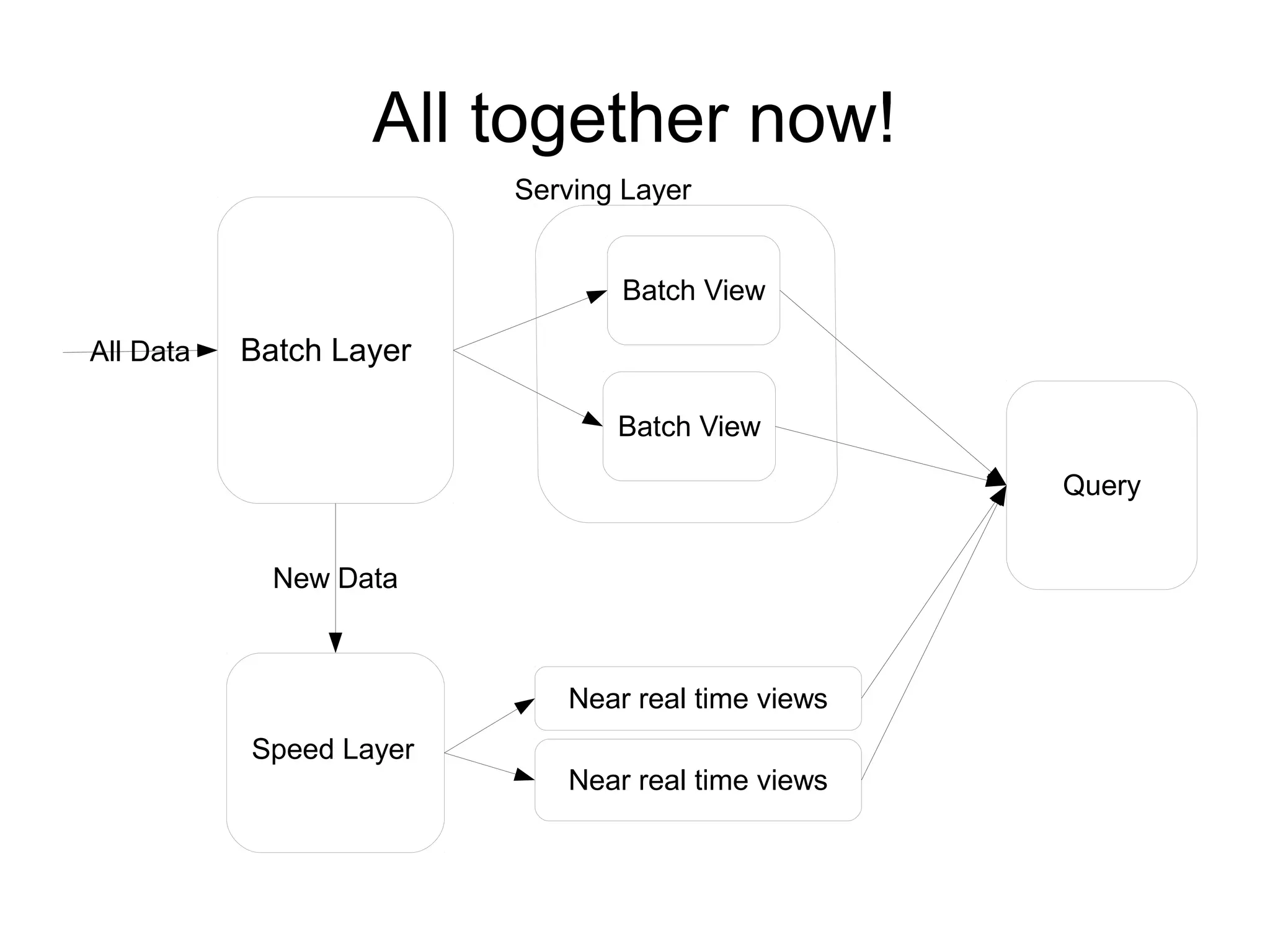







The document discusses the Lambda architecture, a framework for managing big data in systems like Twitter, highlighting its batch and speed layers for processing and querying data. It details components such as batch processing tools (Hadoop, HDFS), serving layer tools (ElephantDB), and speed layer tools (Storm, Apache HBase). The architecture allows for scalable, fault-tolerant, and efficient querying of both real-time and batch data.