Downloaded 49 times


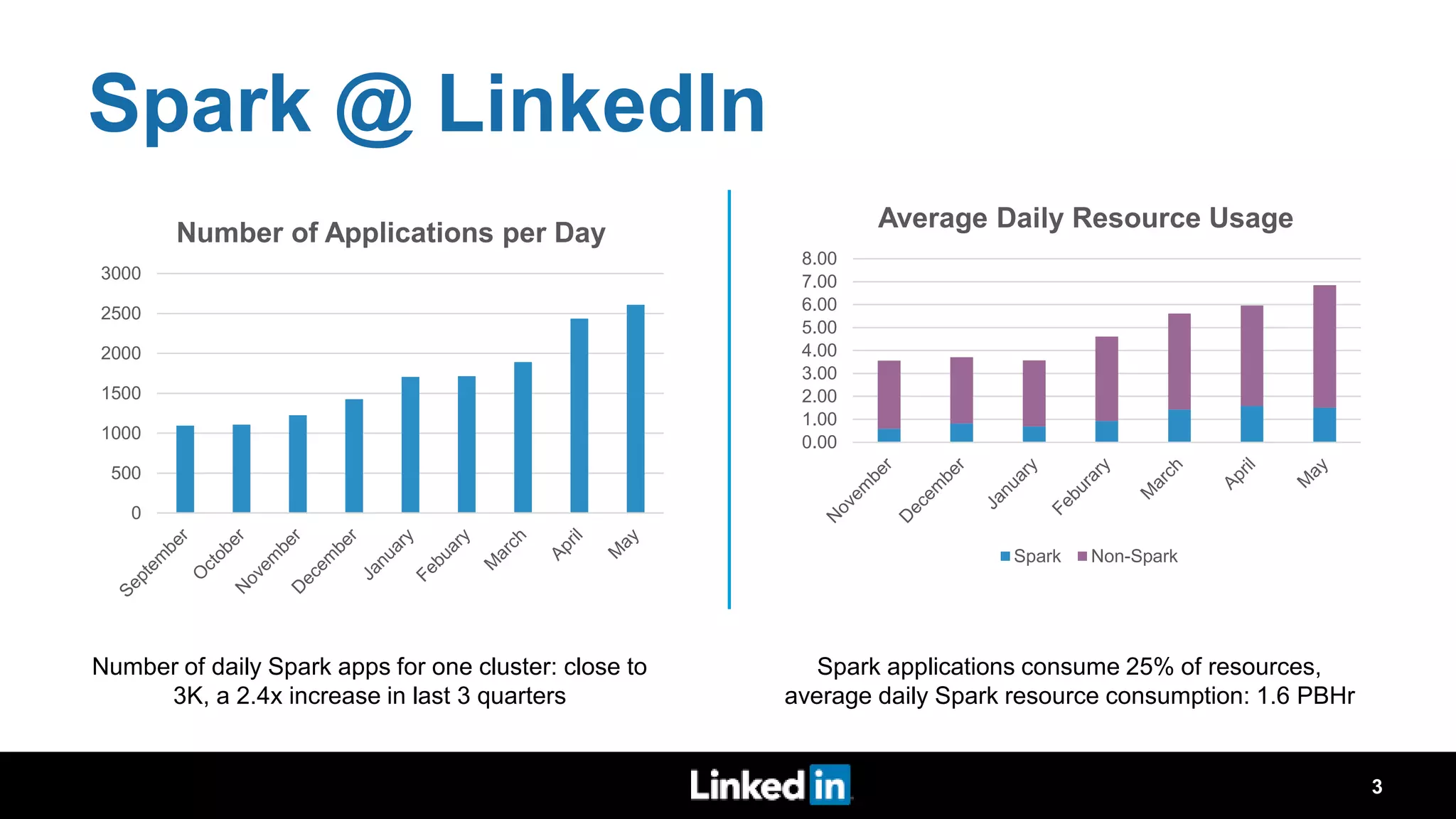




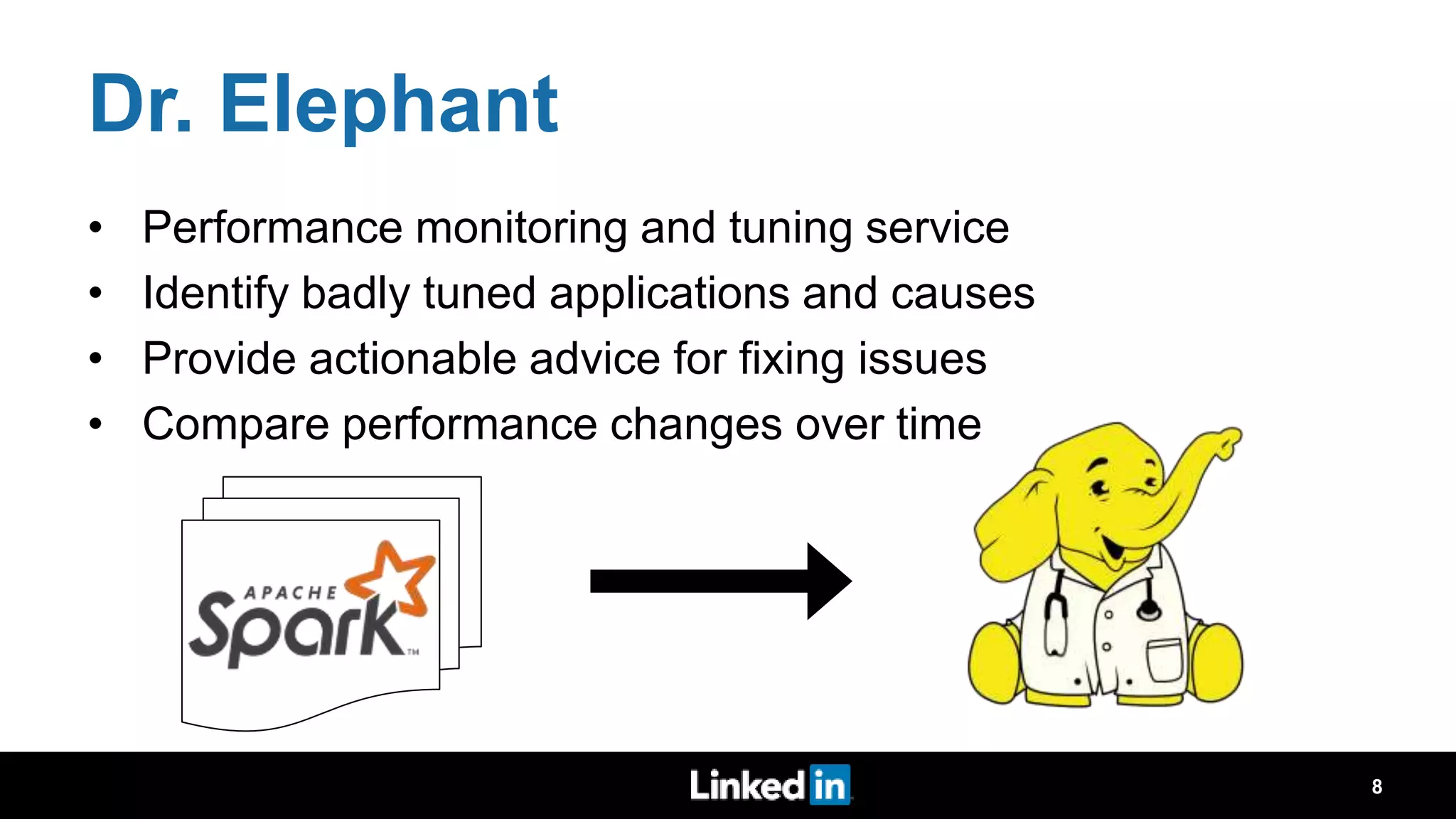
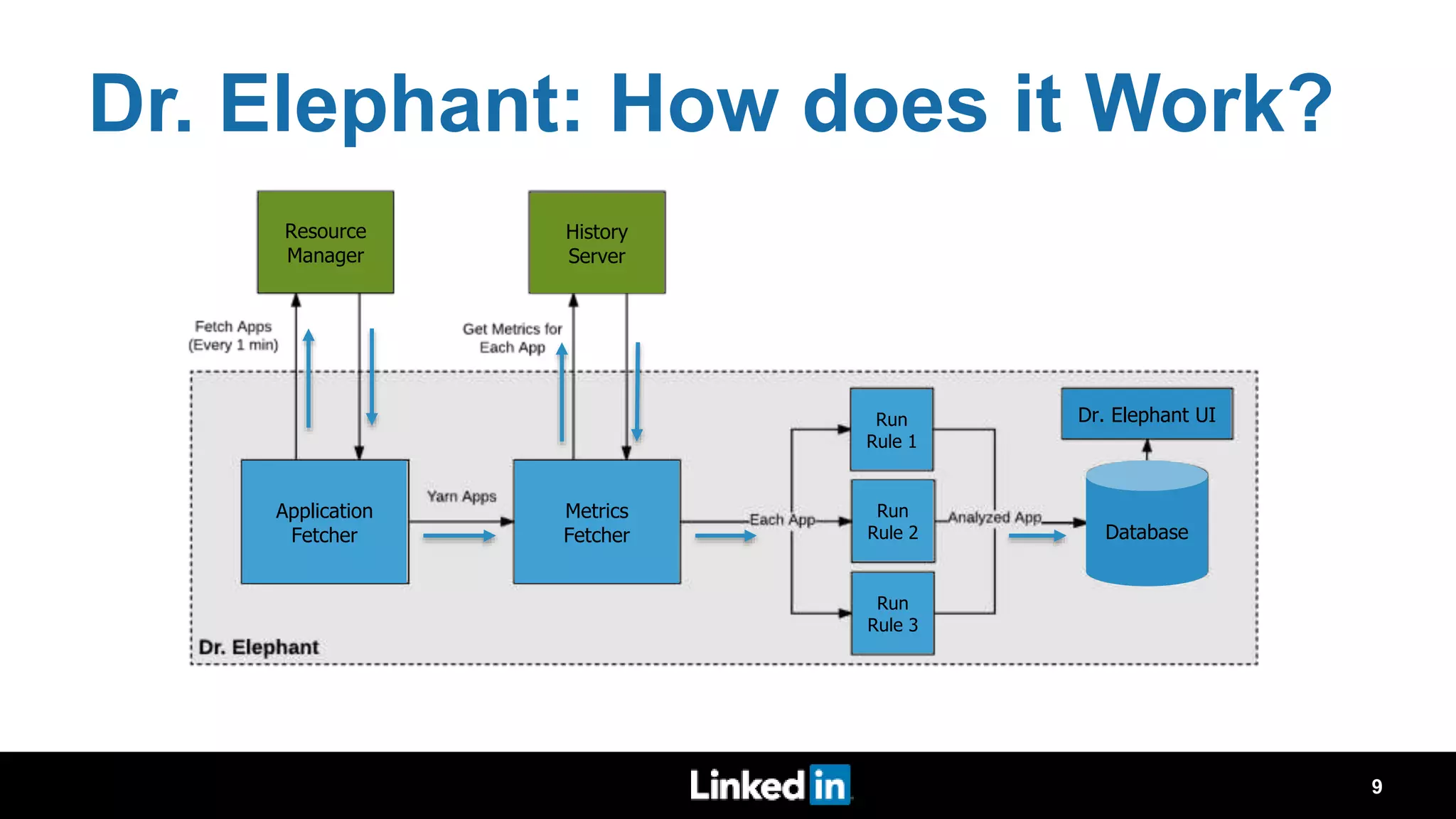

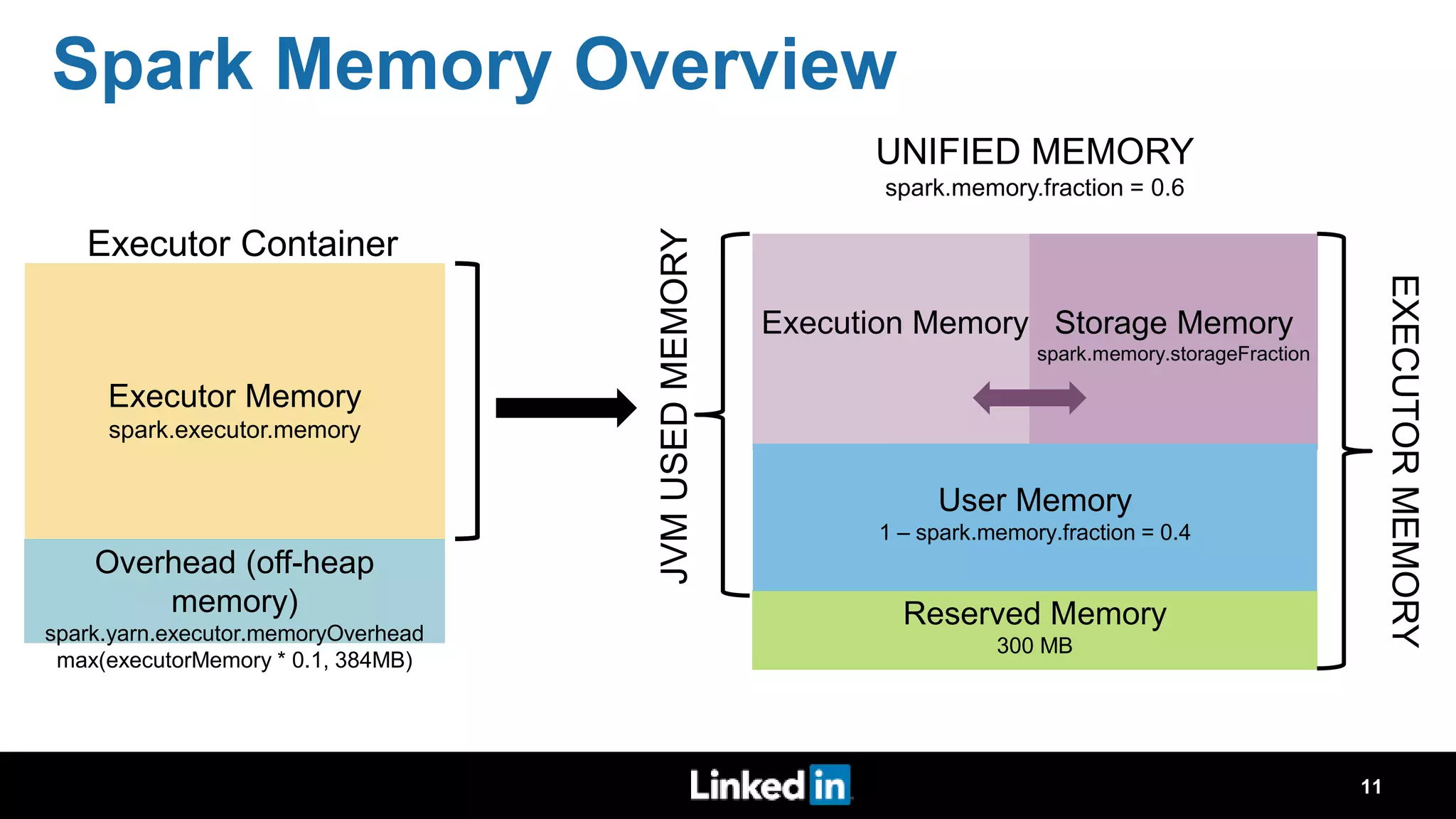
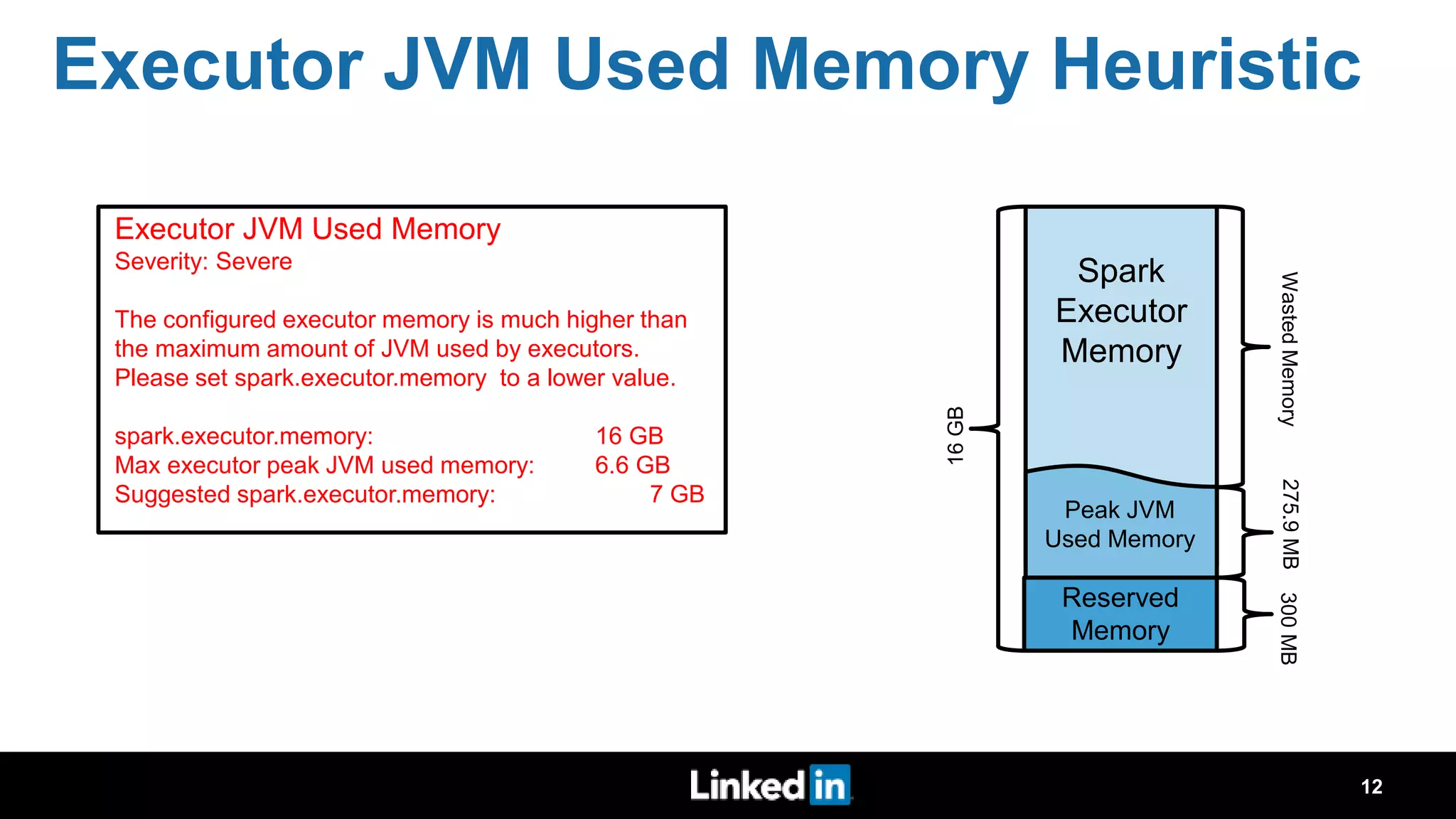
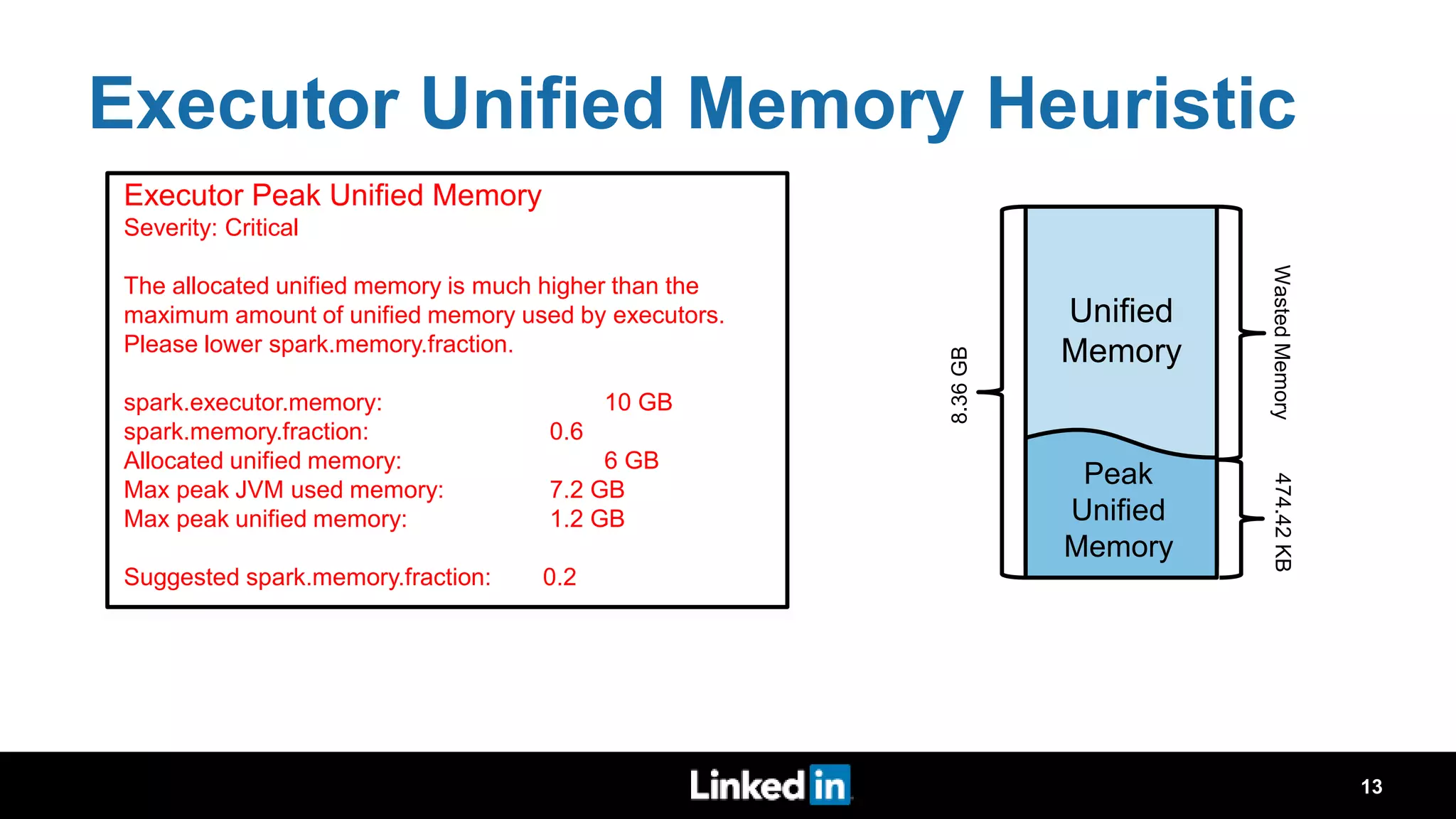
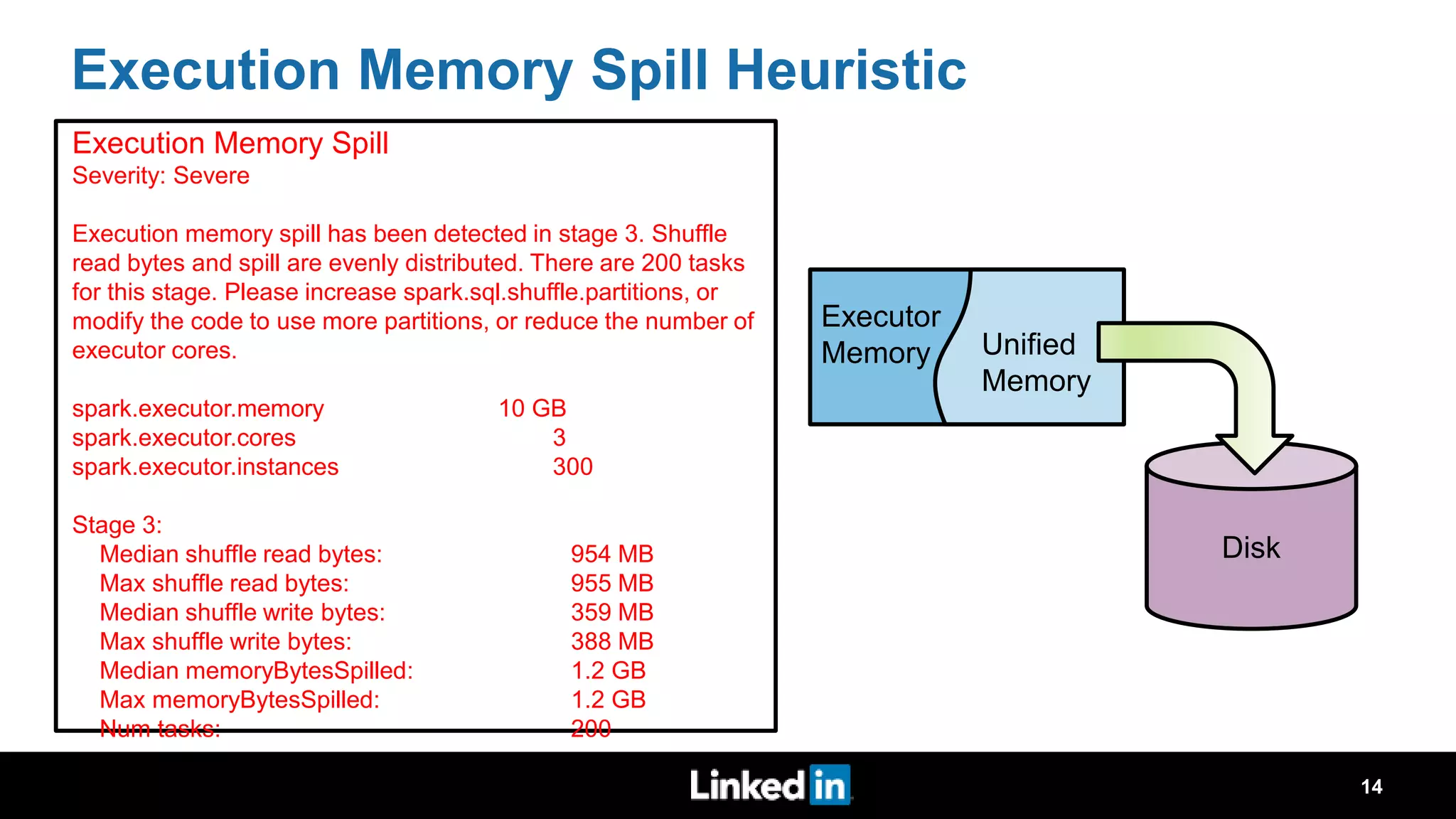

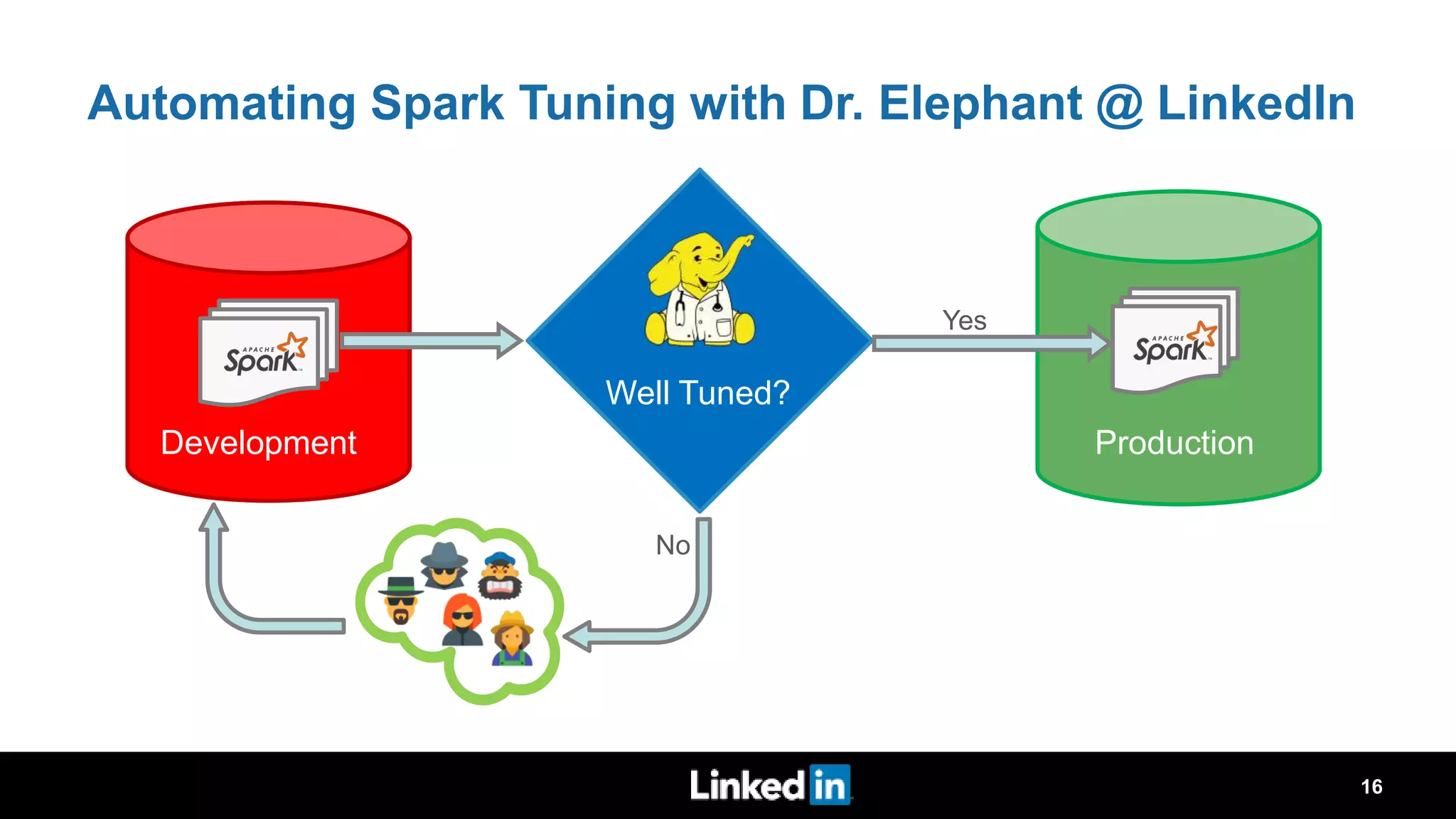
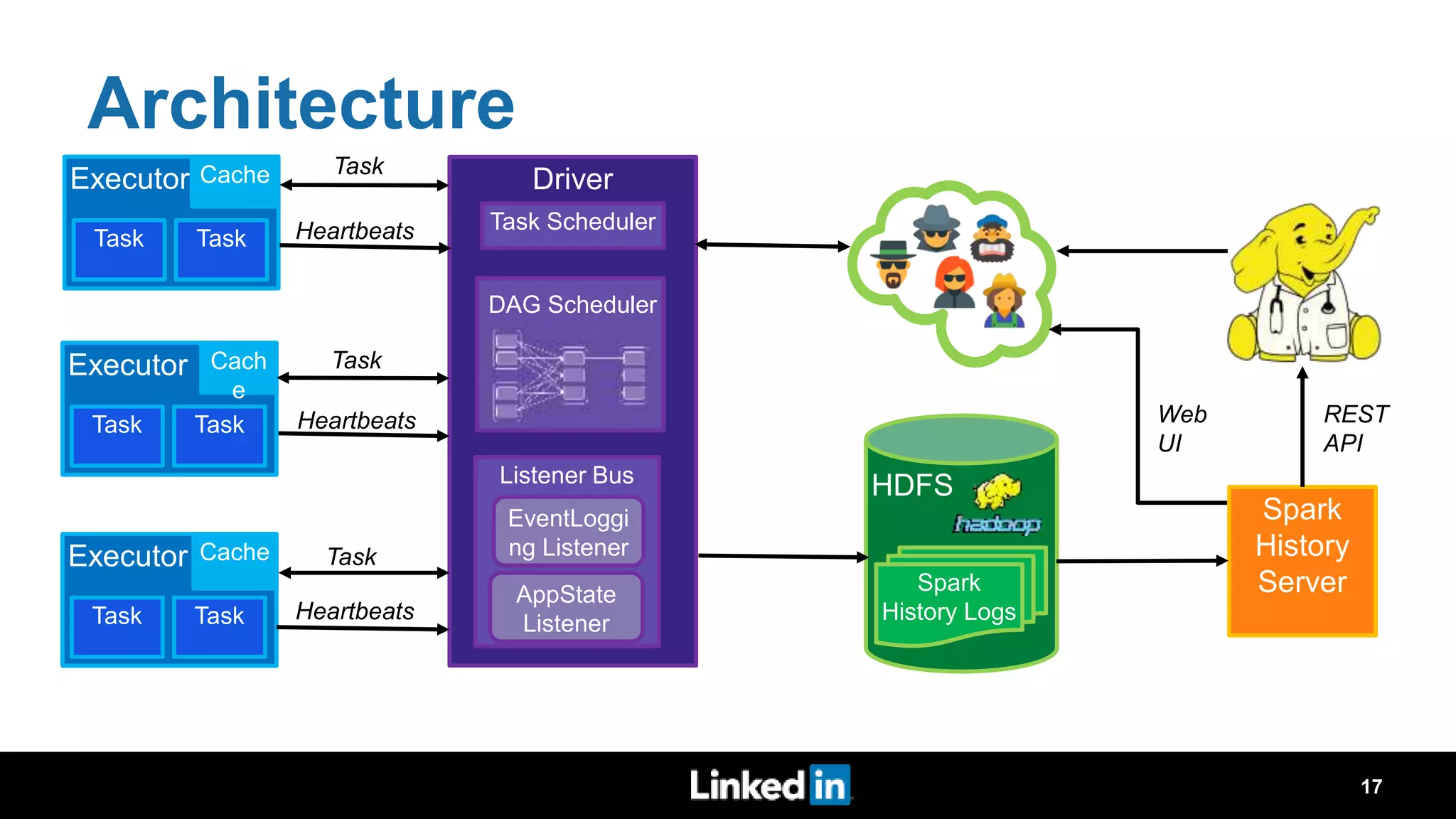

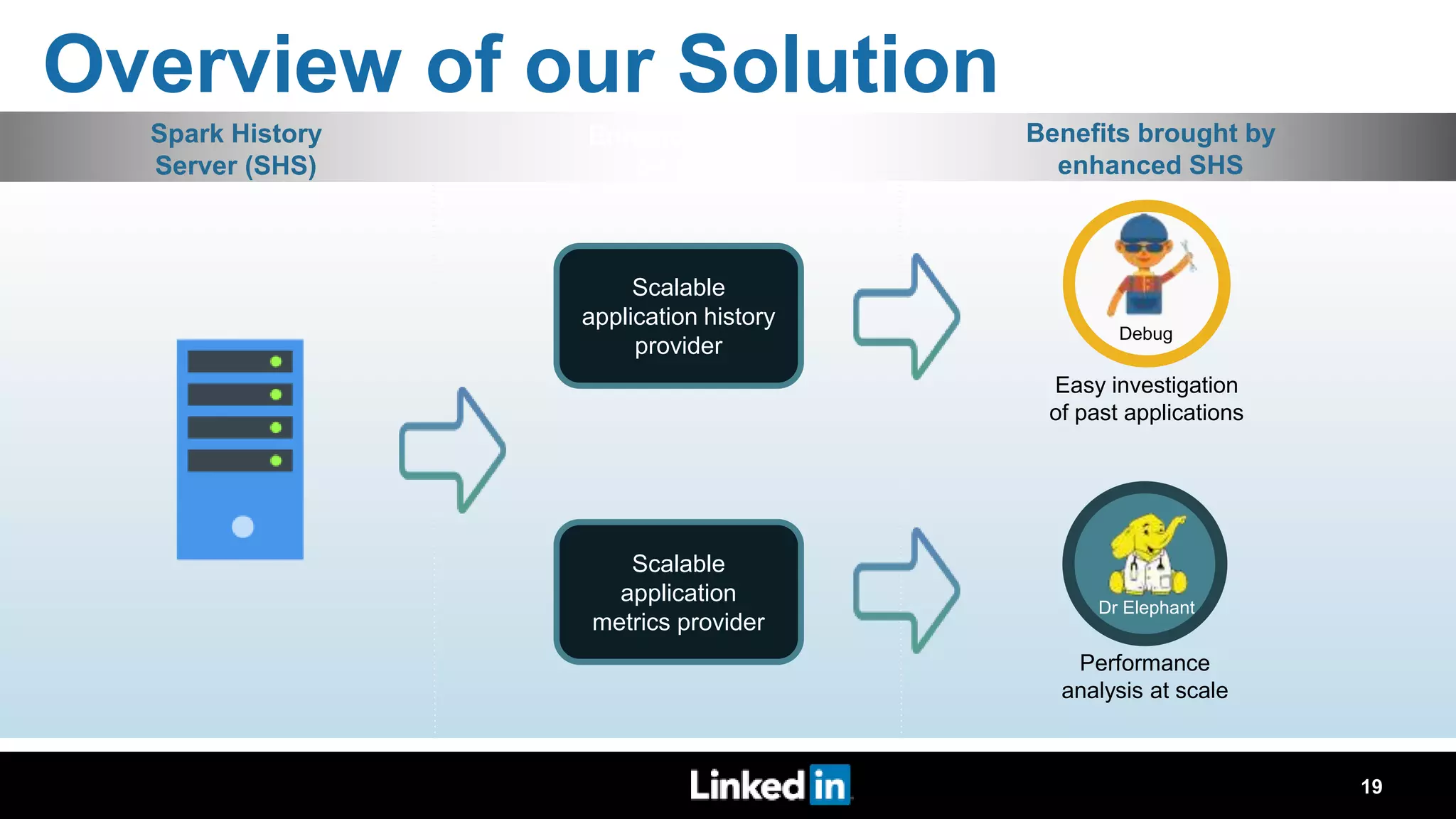
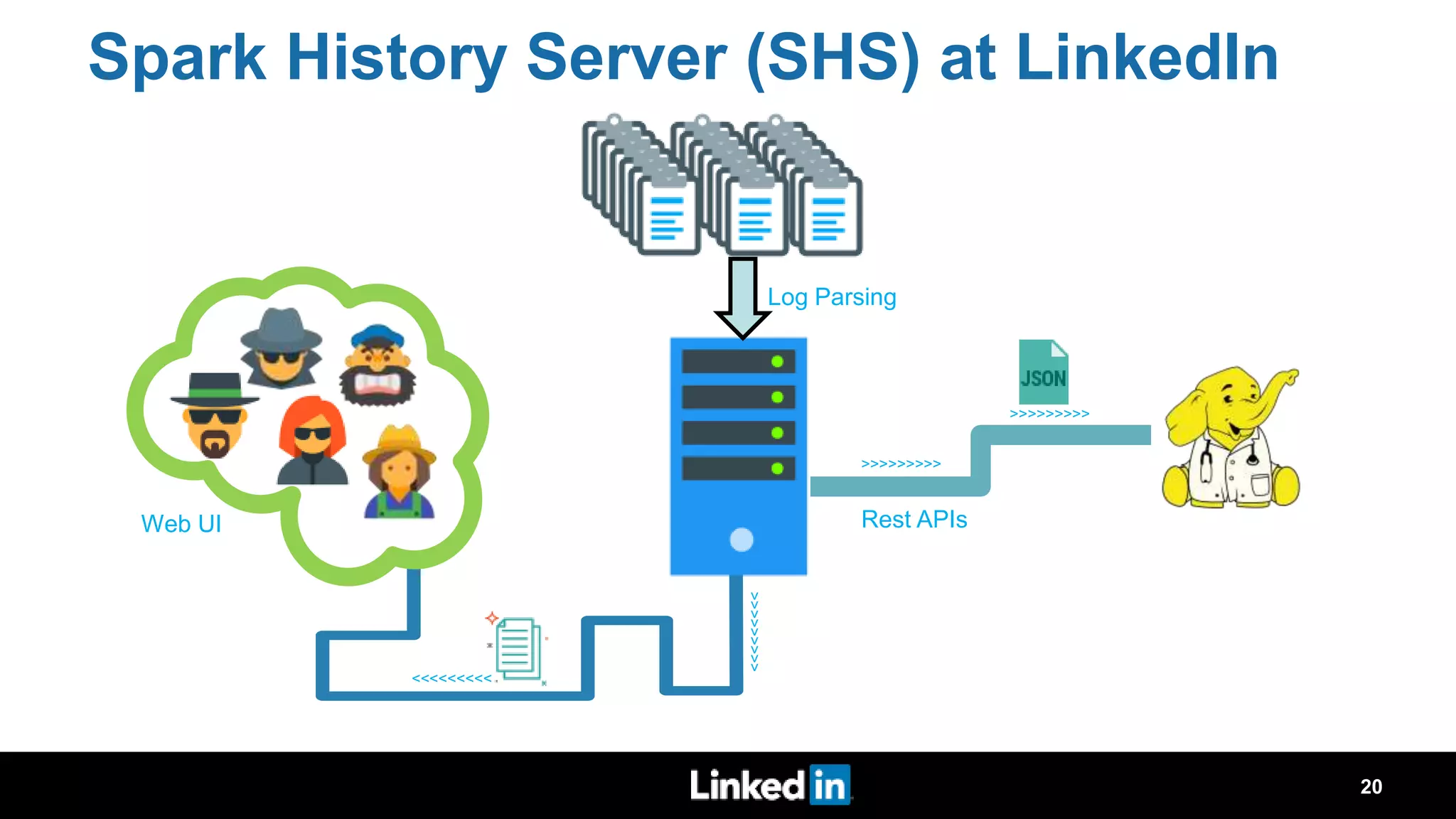
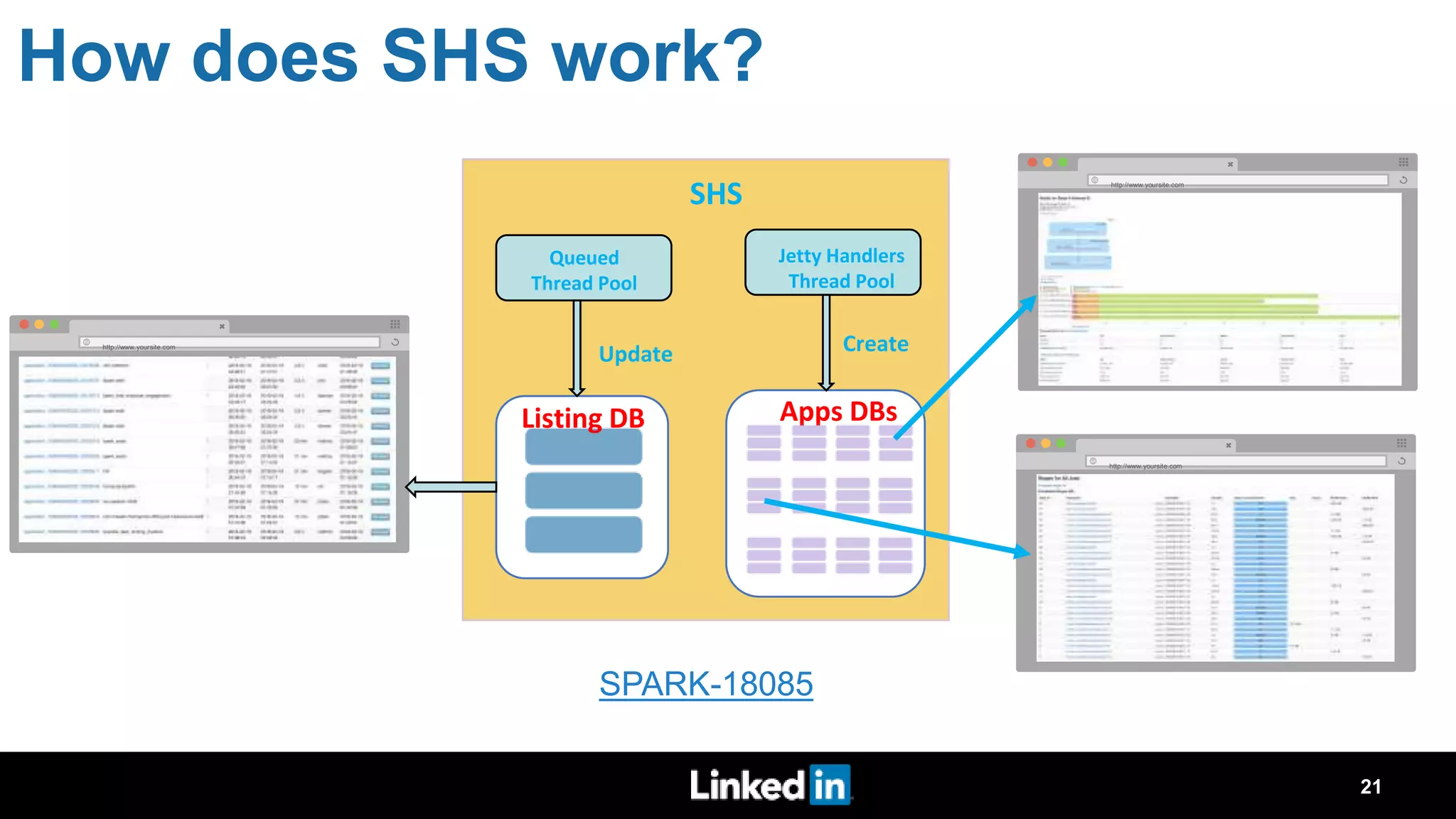
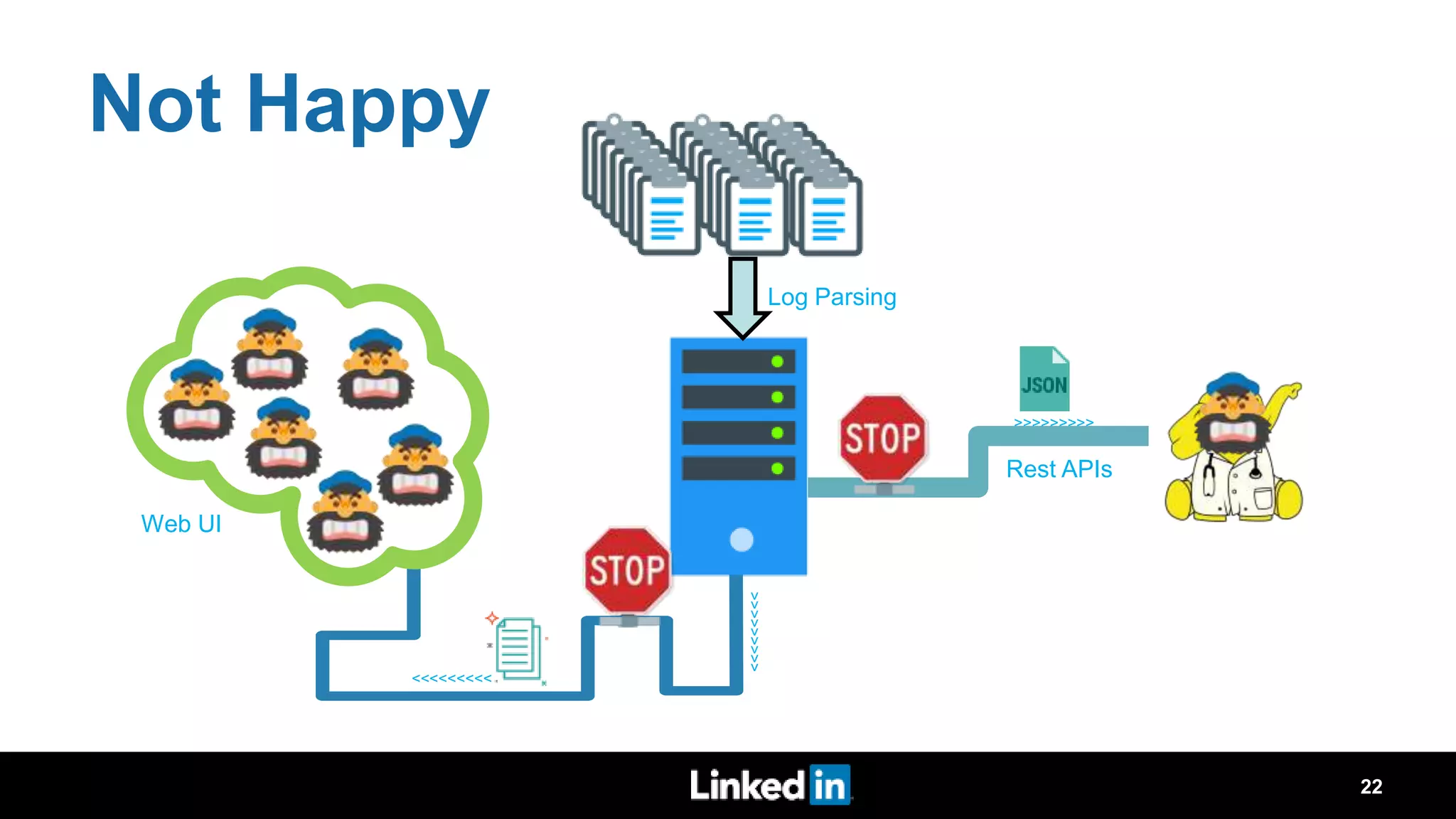

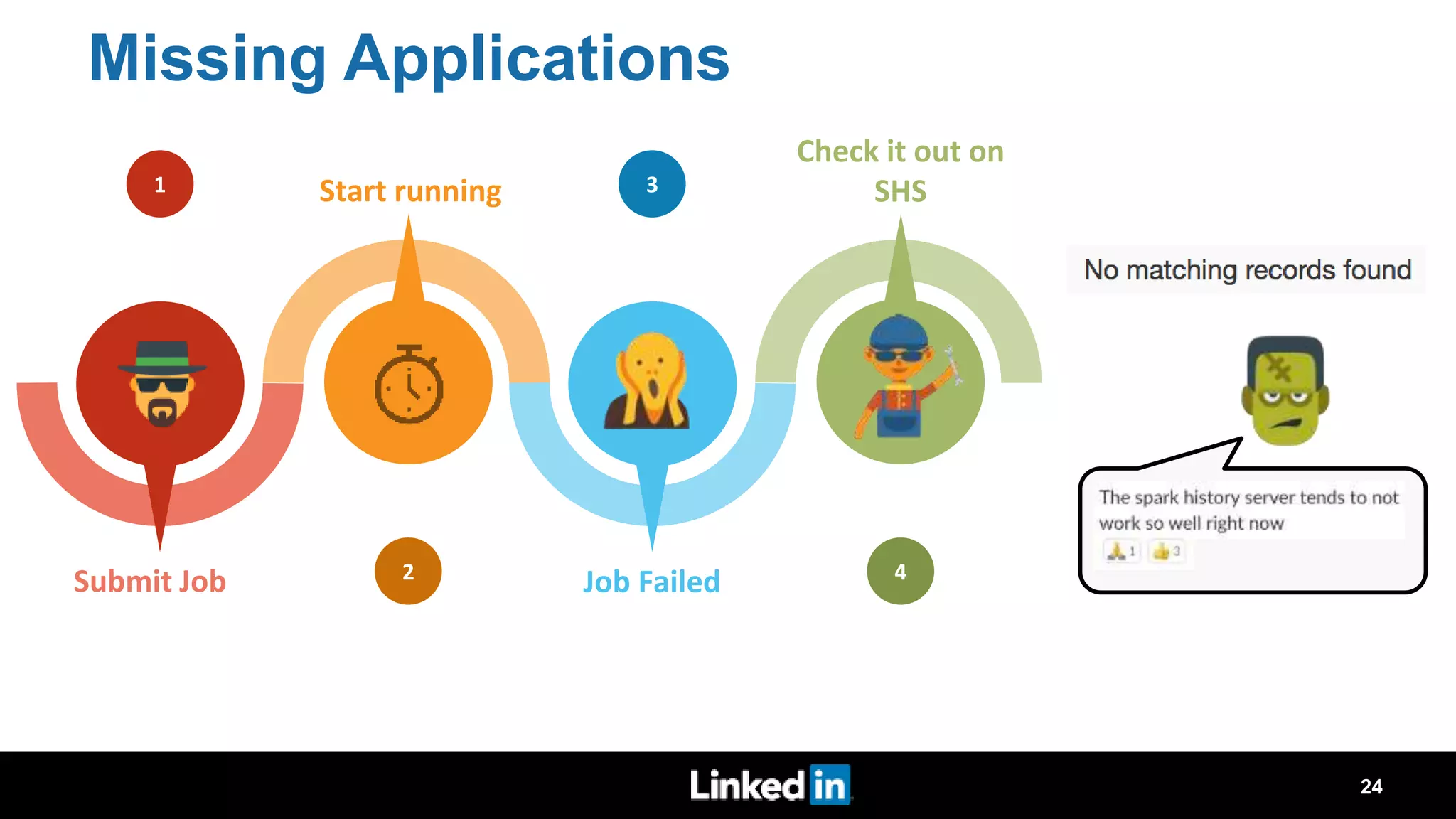

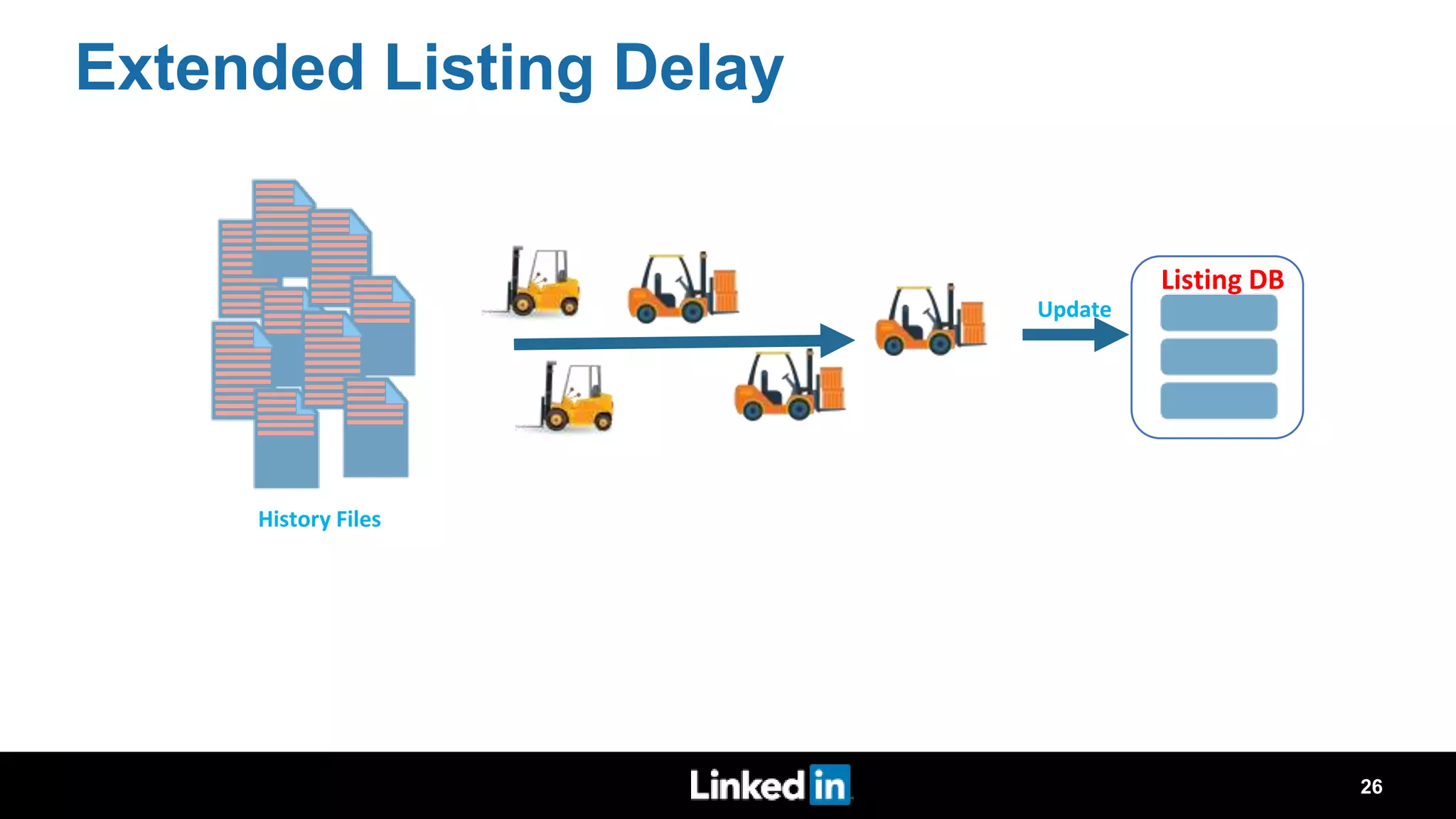
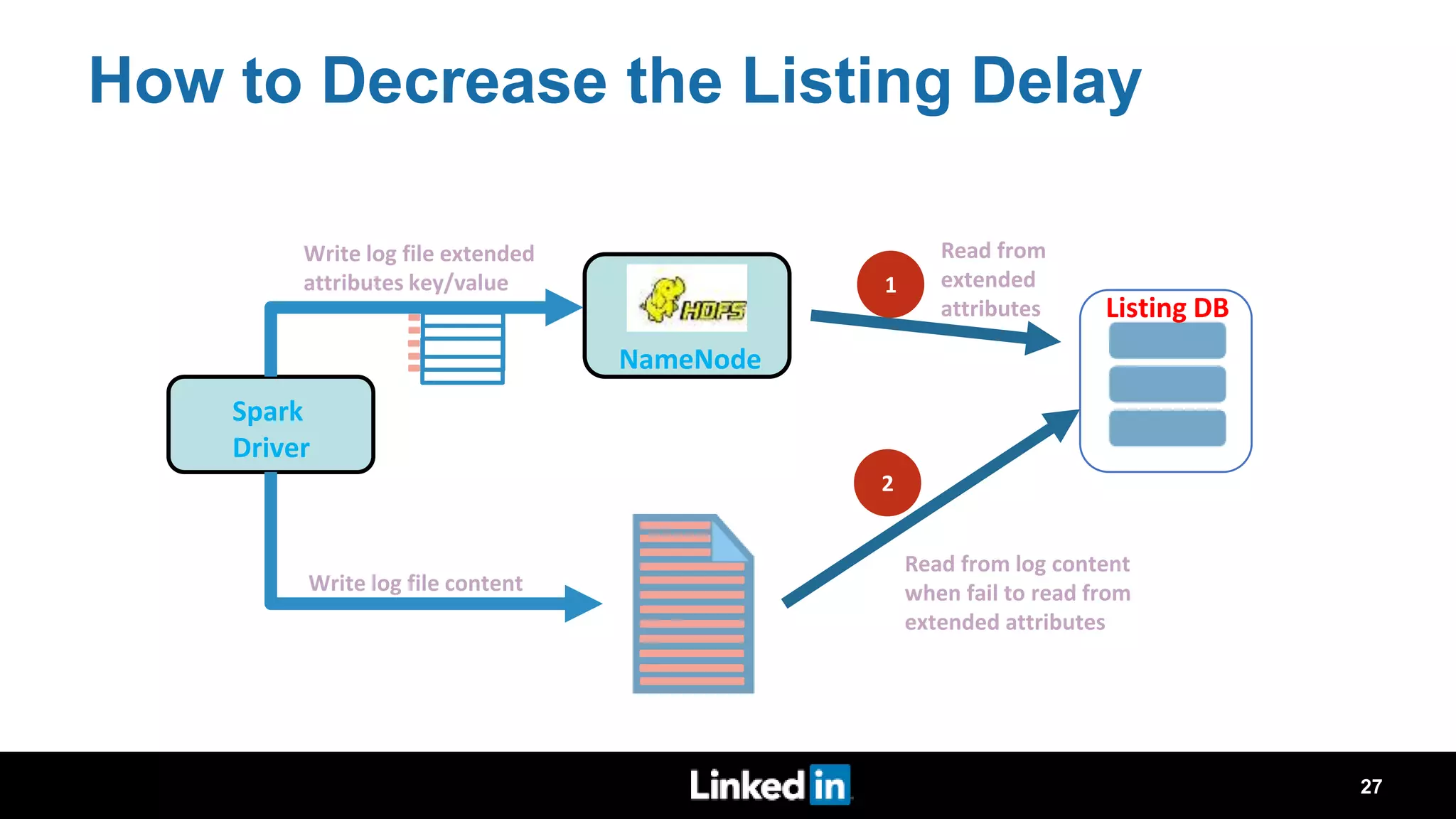
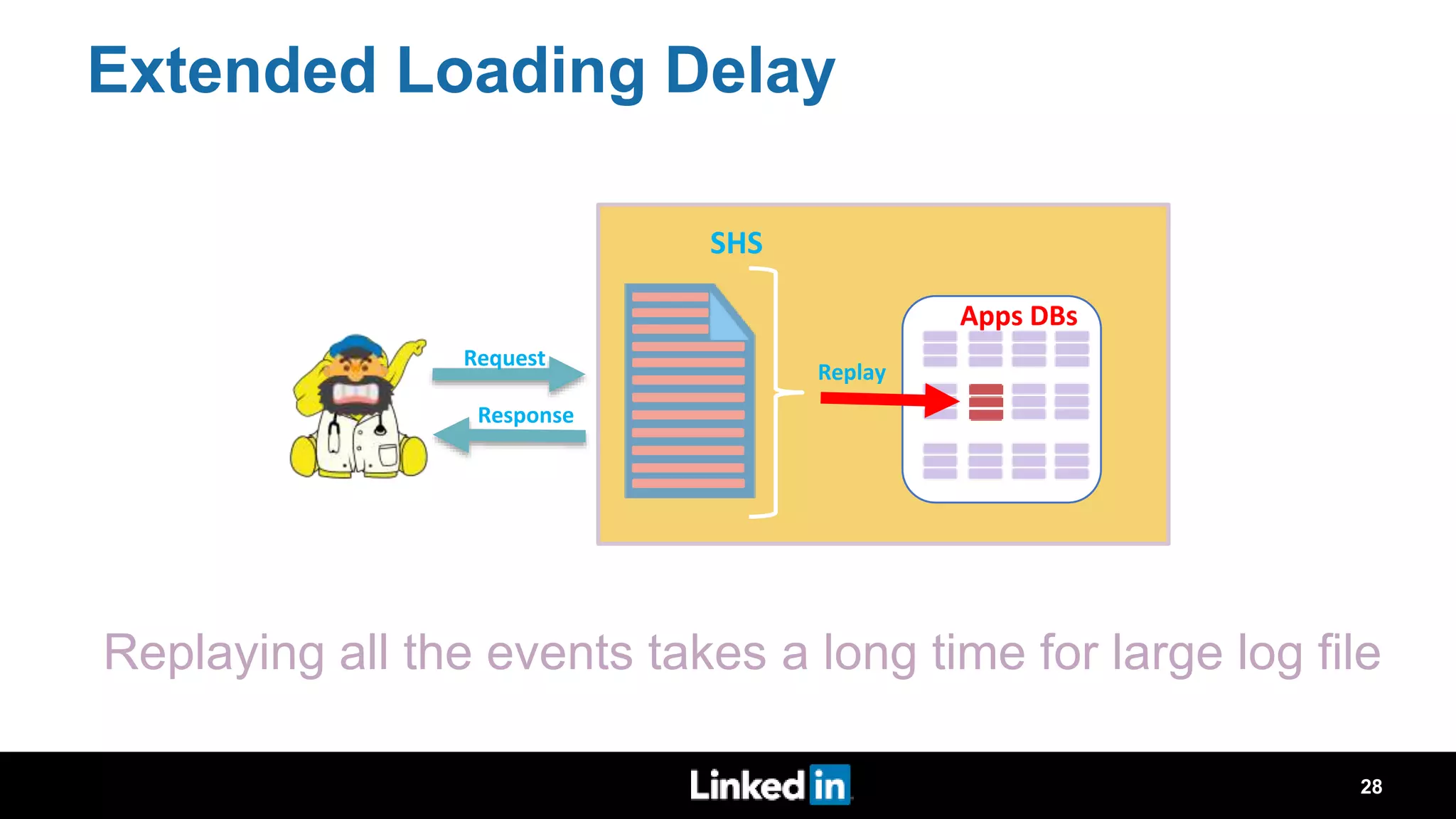
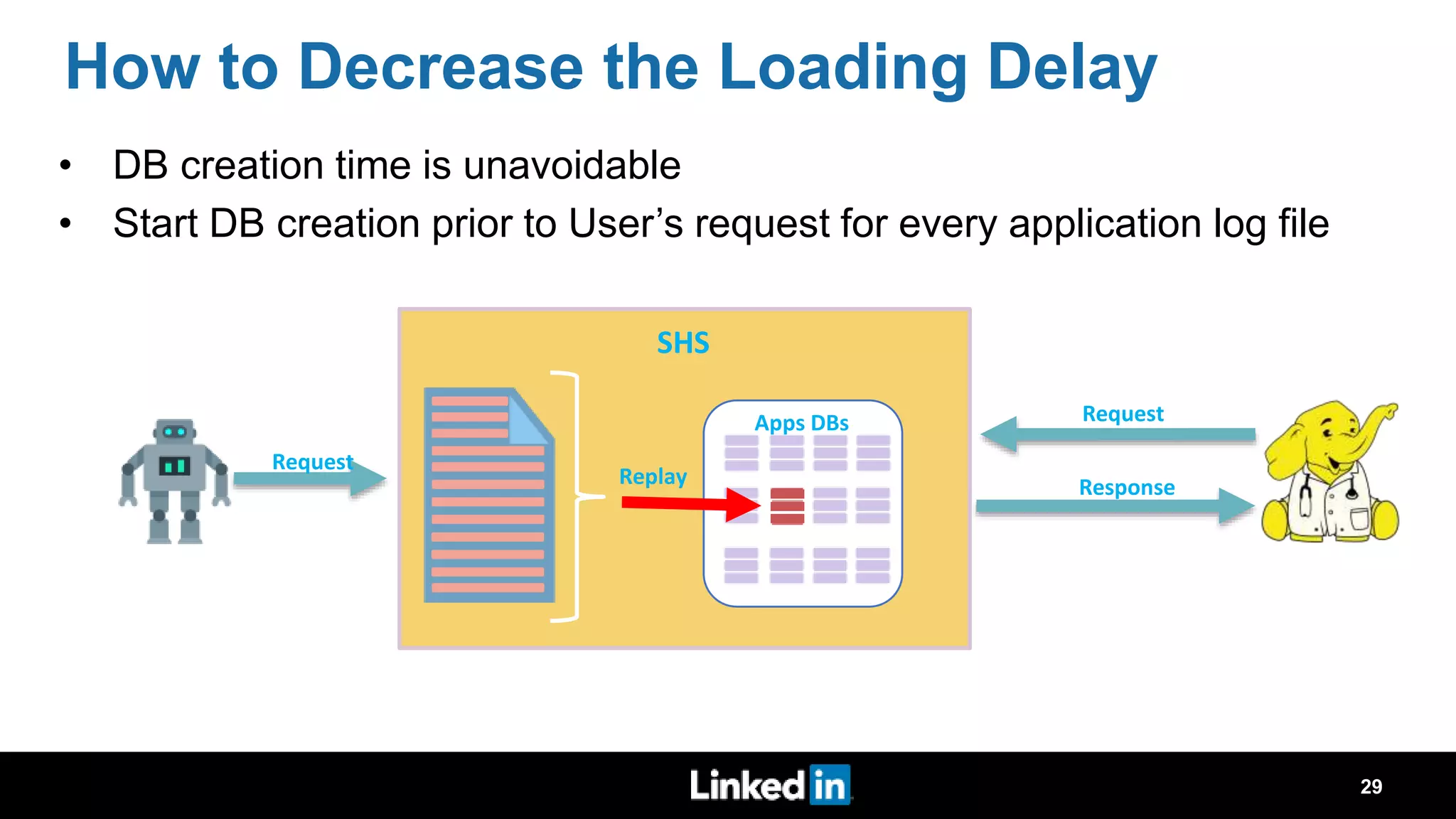

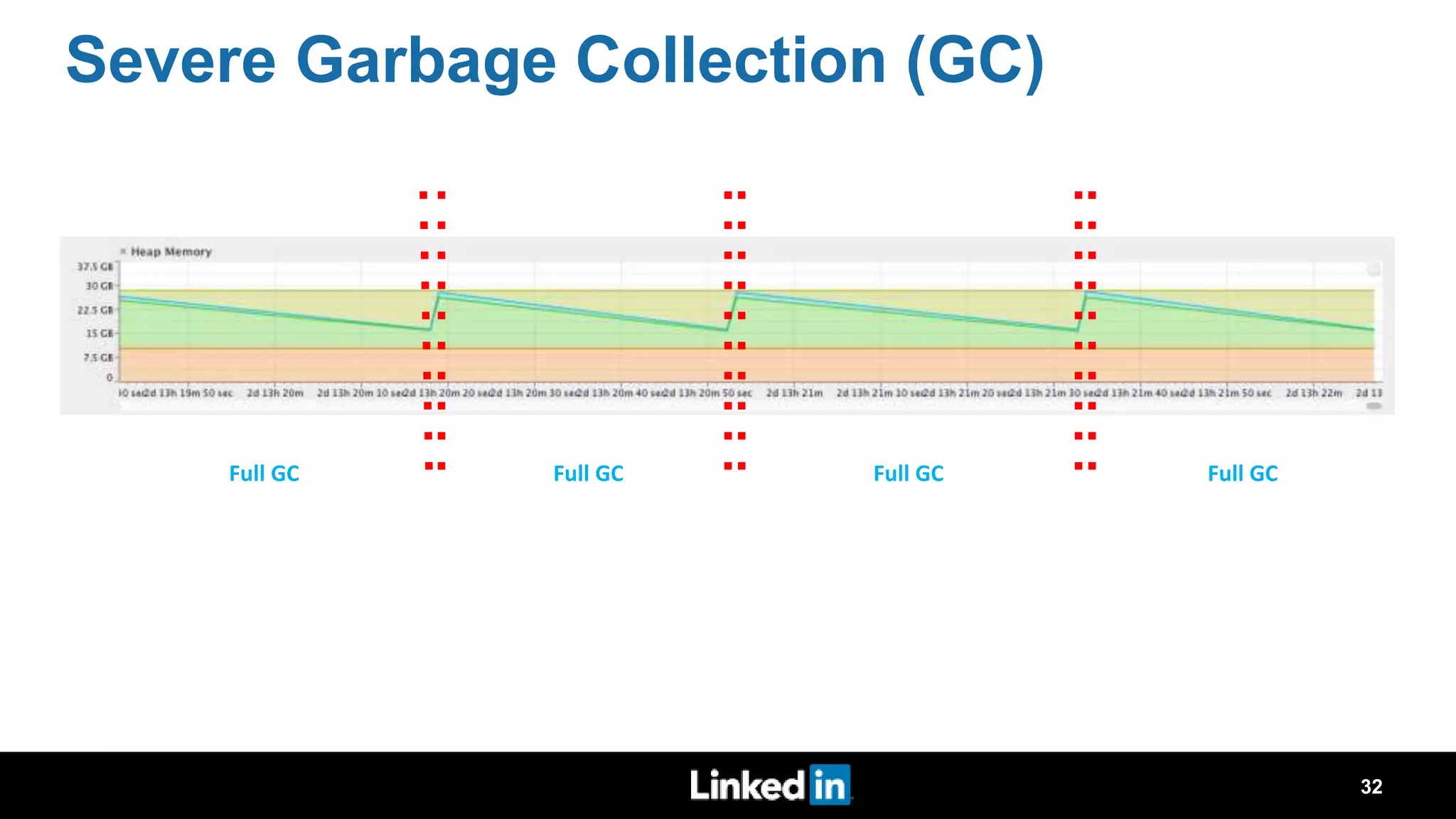
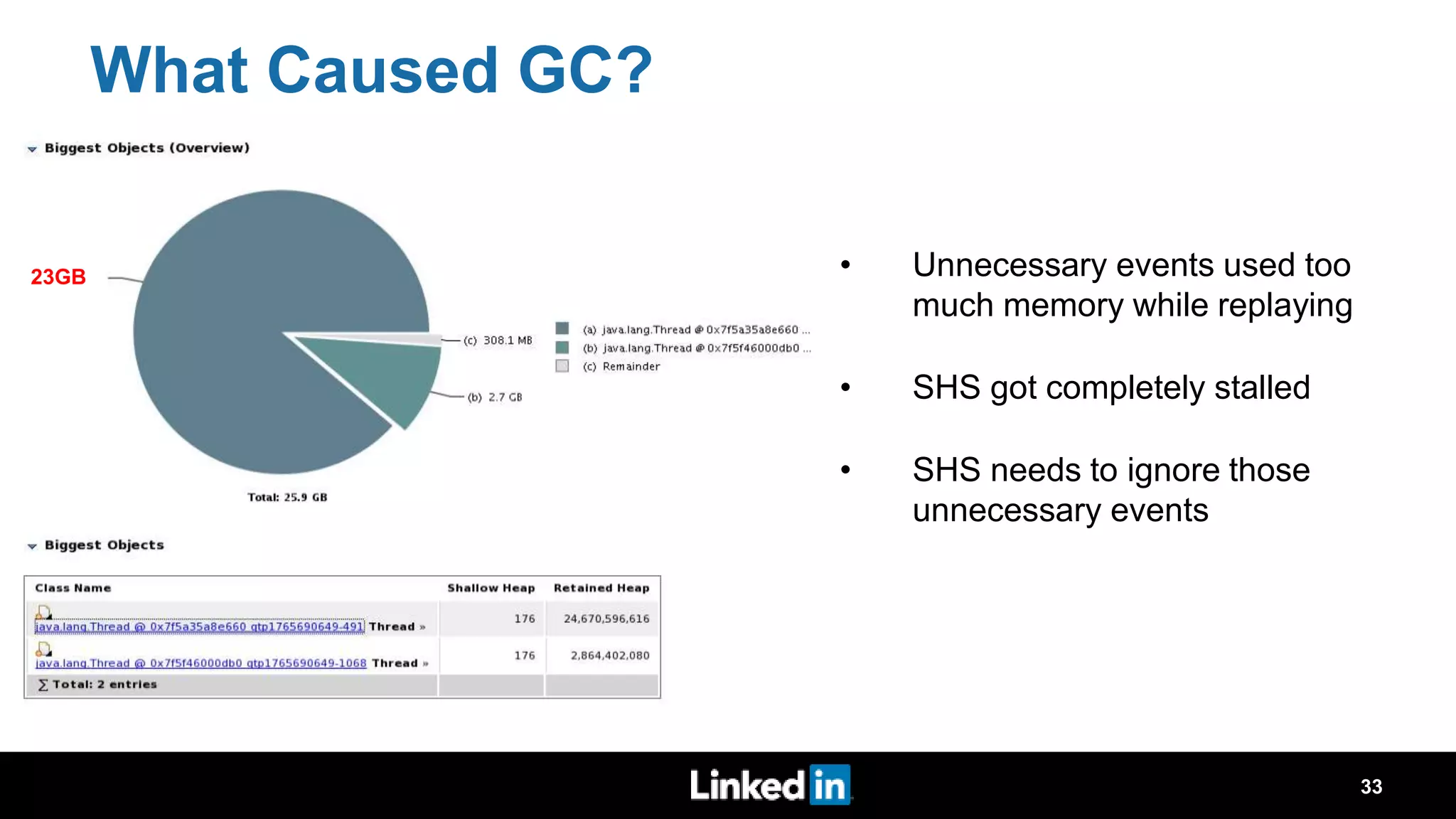
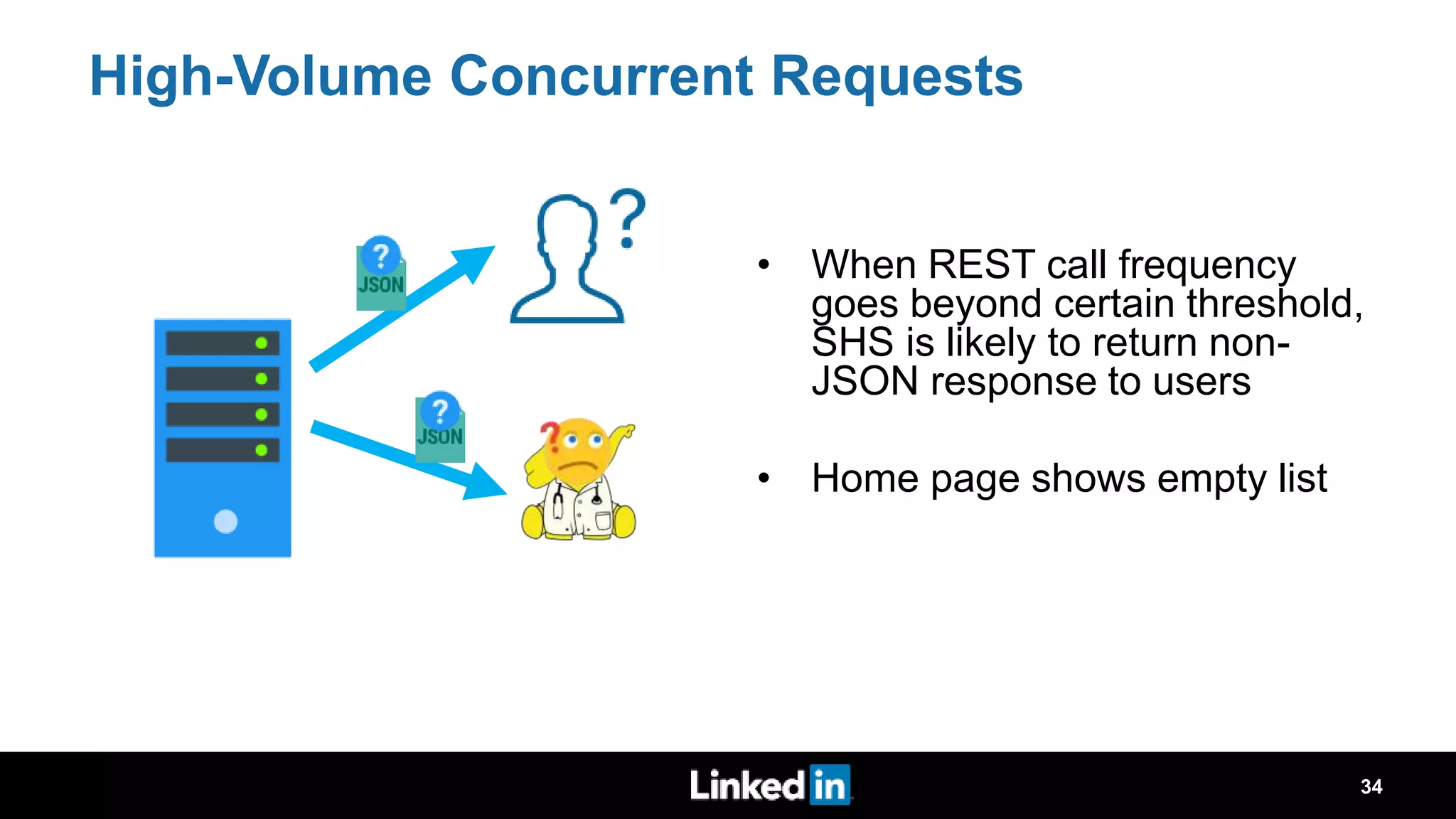





The document discusses metrics-driven tuning of Apache Spark at LinkedIn, where resource consumption has significantly increased, leading to 34% of allocated memory being unused. It highlights the development of 'Dr. Elephant,' a performance monitoring and tuning service designed to identify poorly tuned applications and provide actionable advice for optimization. Additionally, improvements in the Spark History Server (SHS) are described, addressing scalability issues and enhancing user experience by minimizing application loading times.