





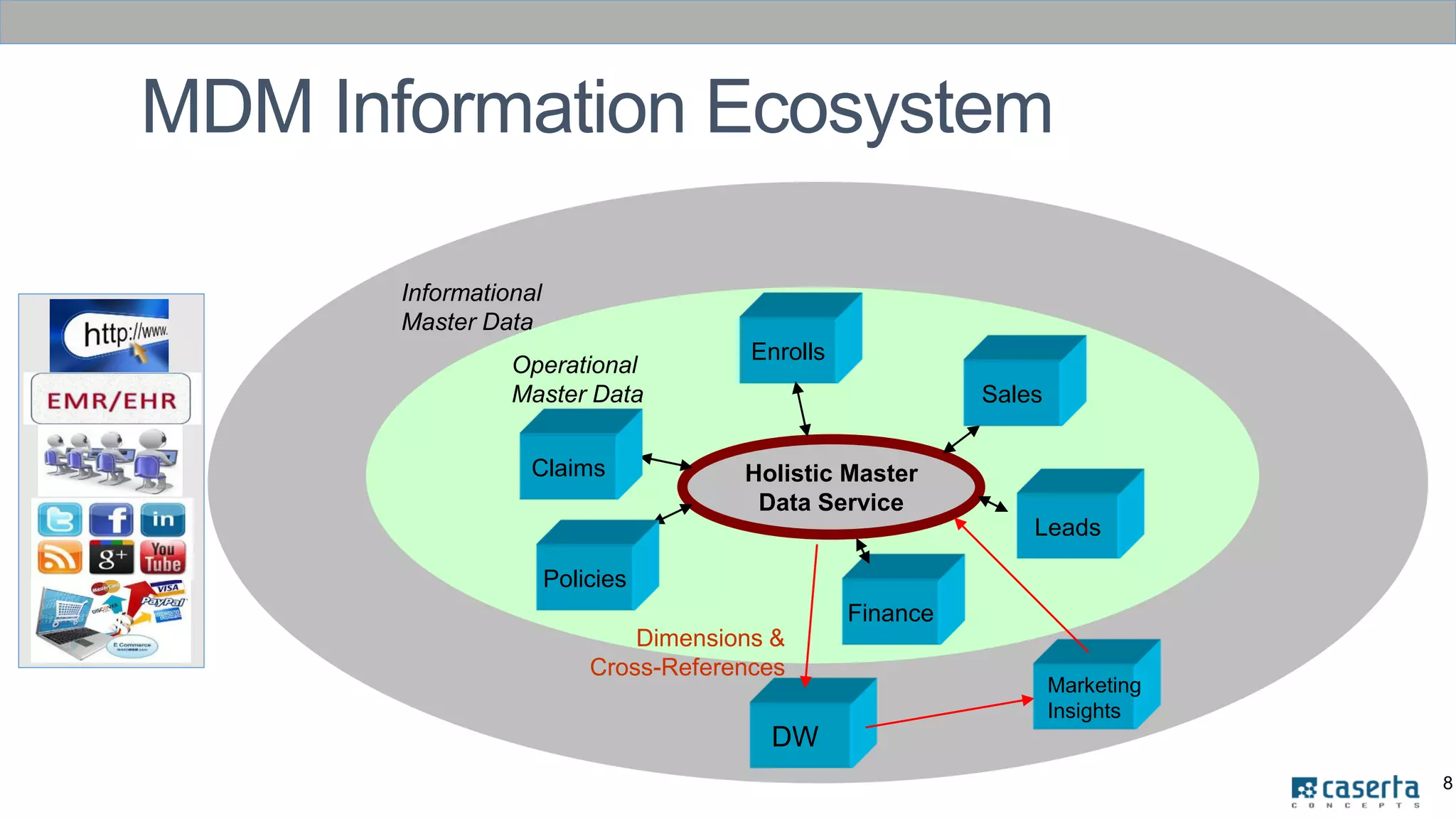

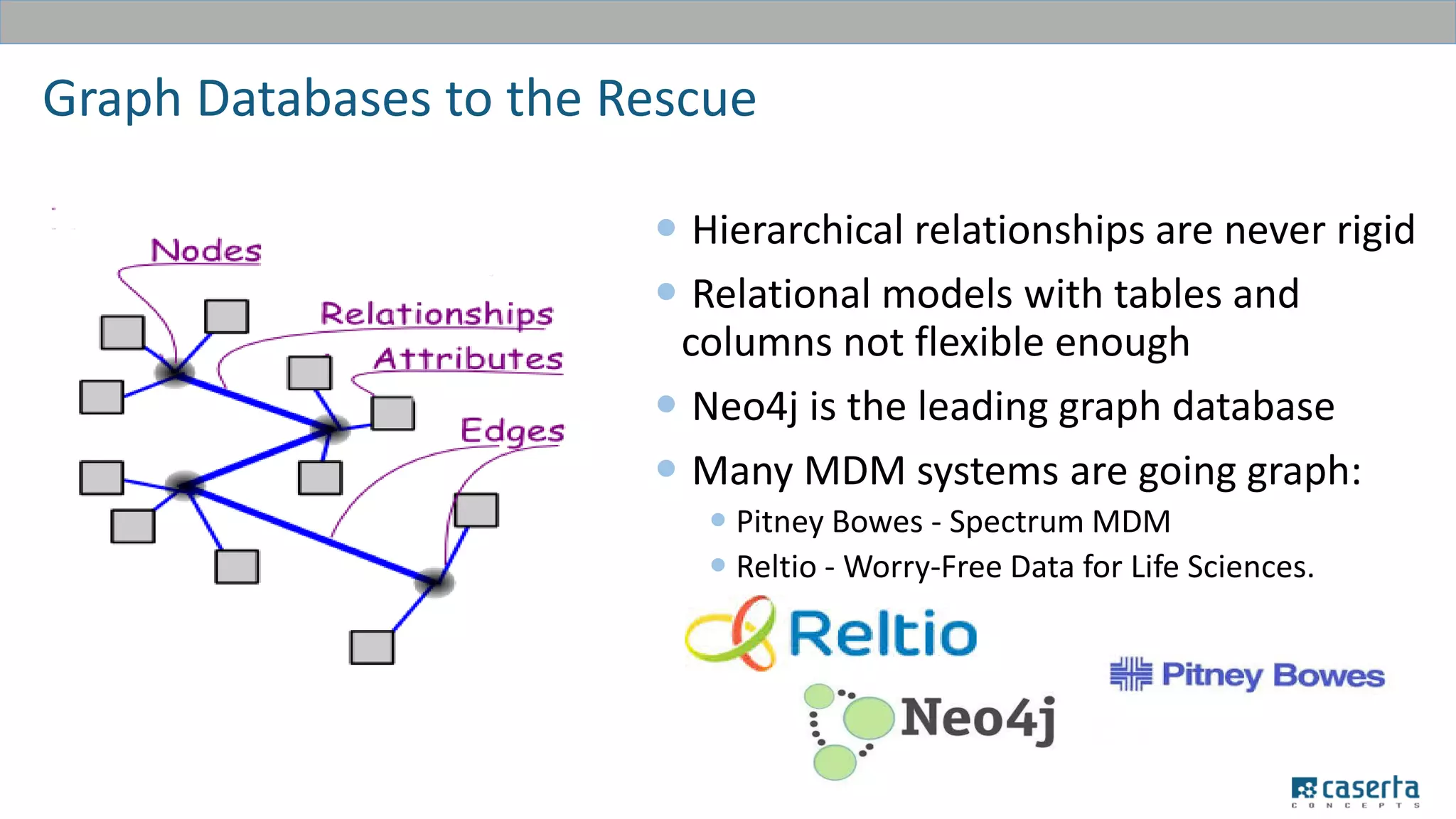

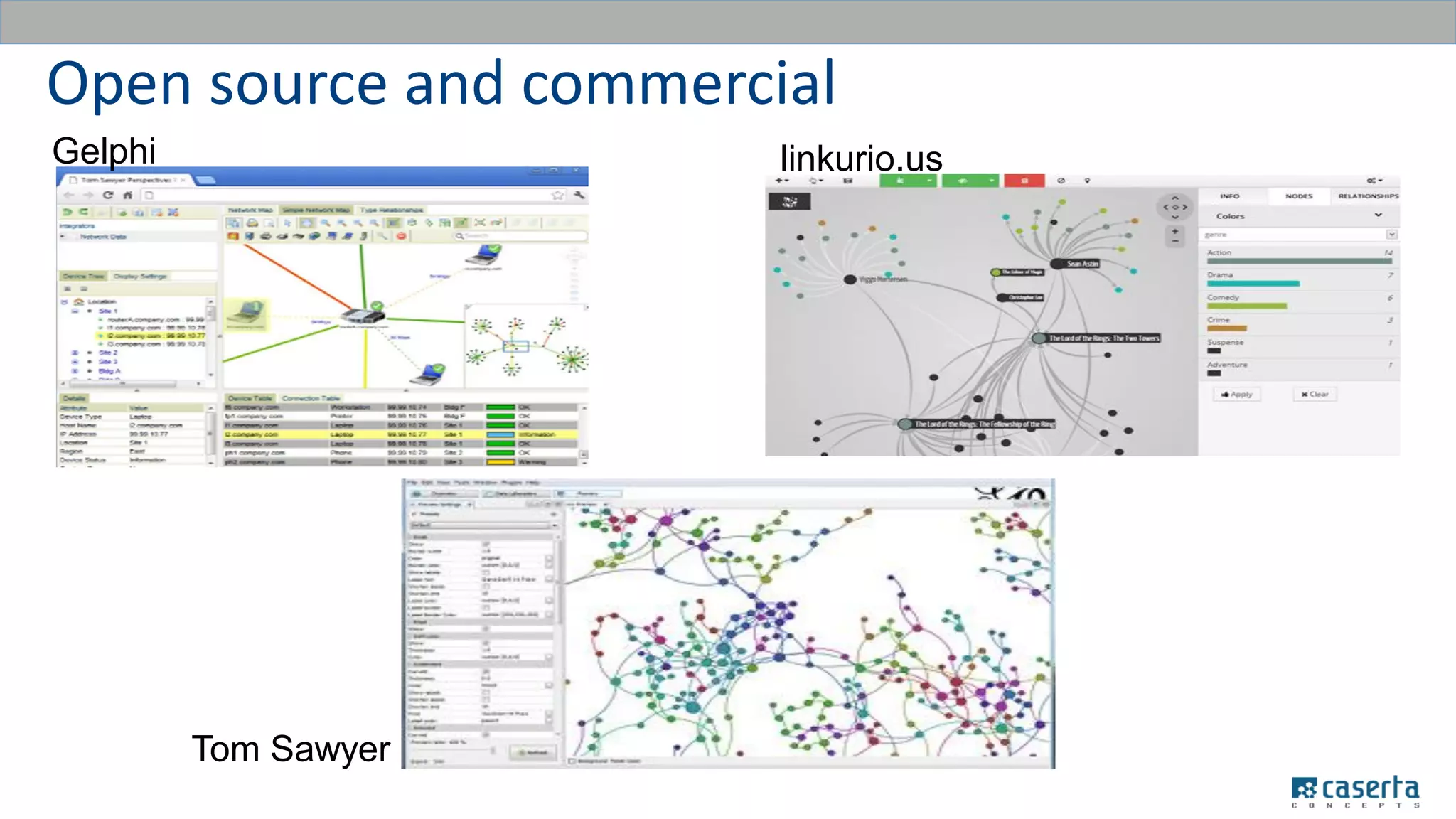



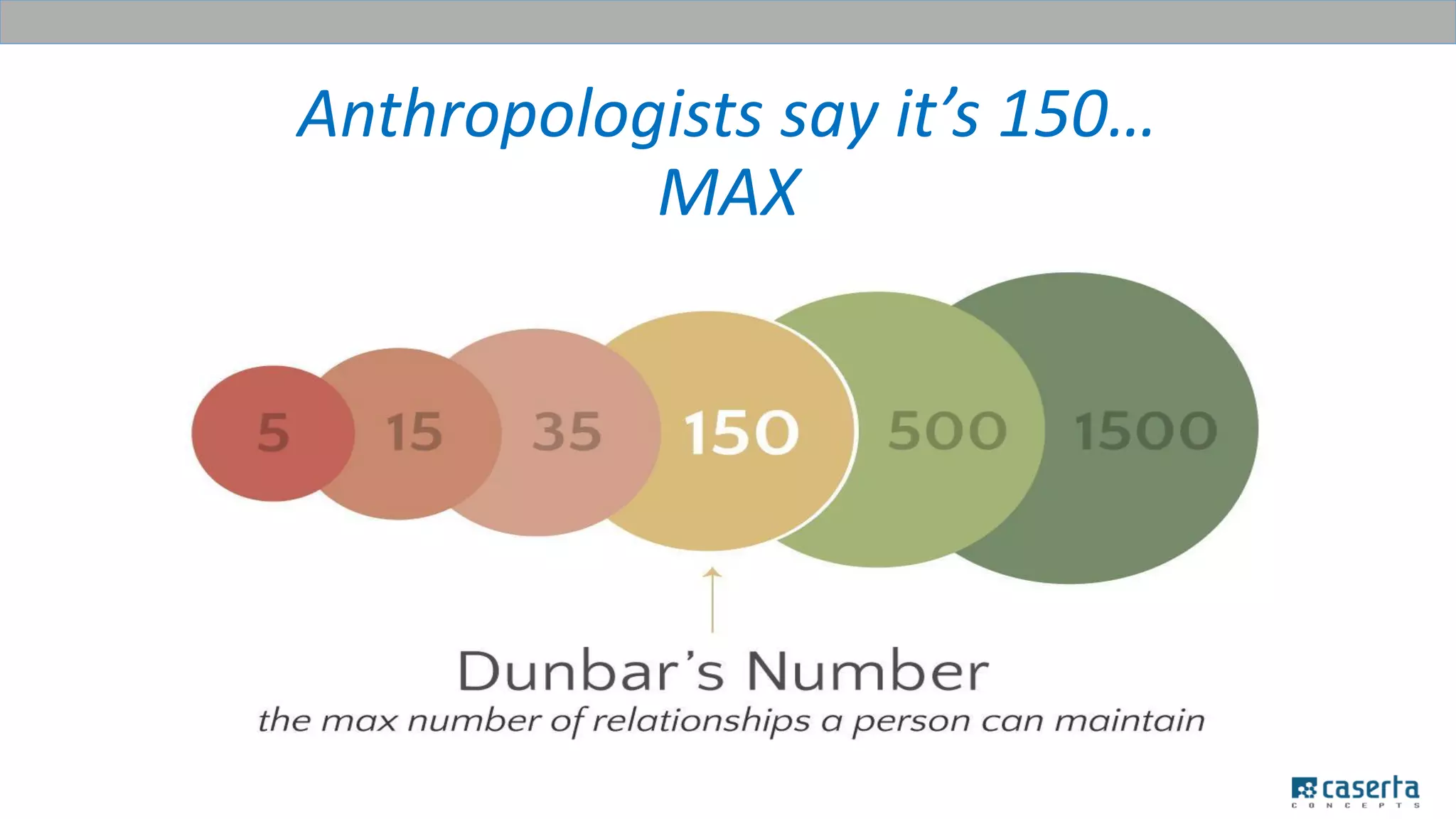
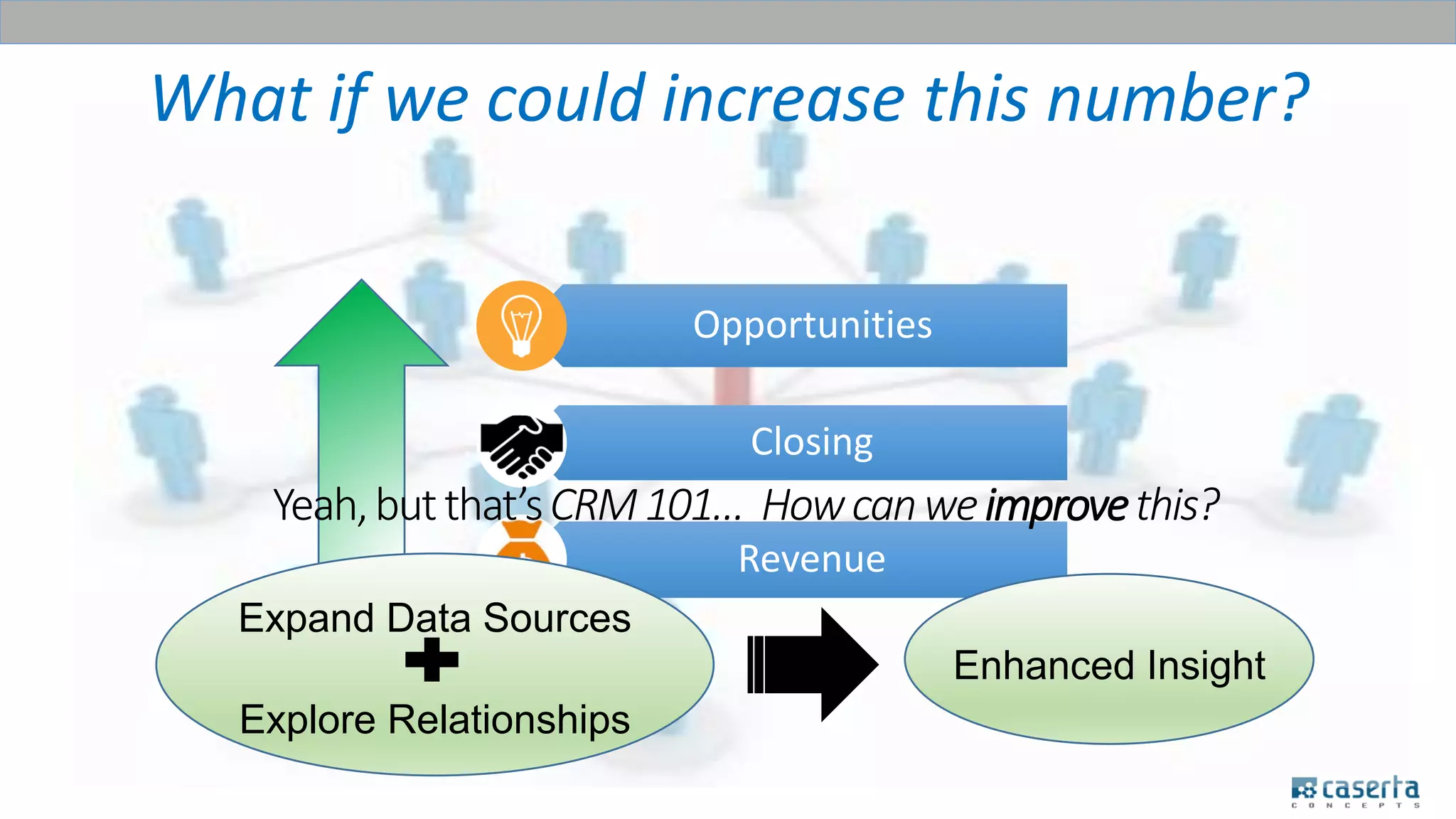
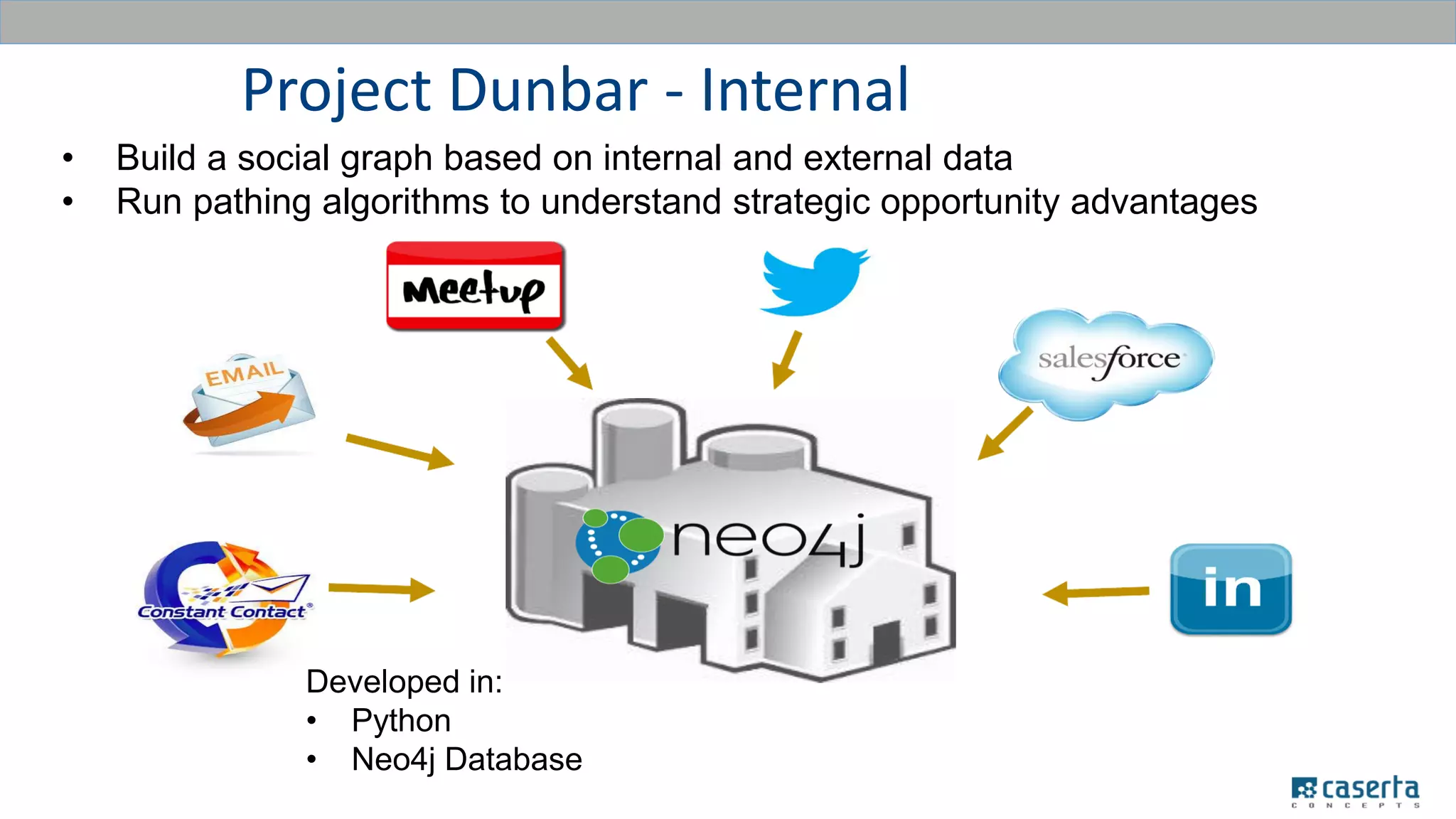

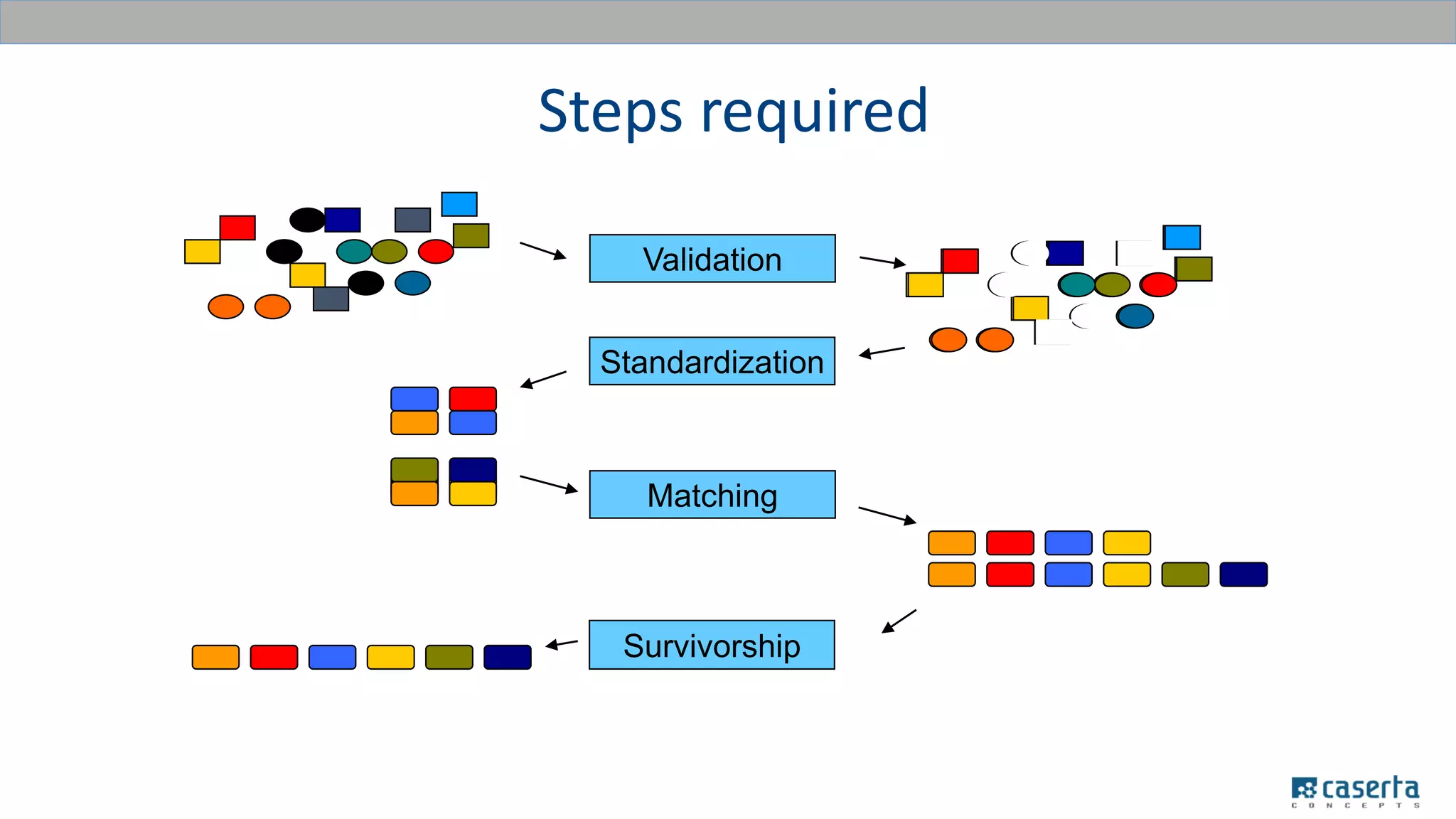
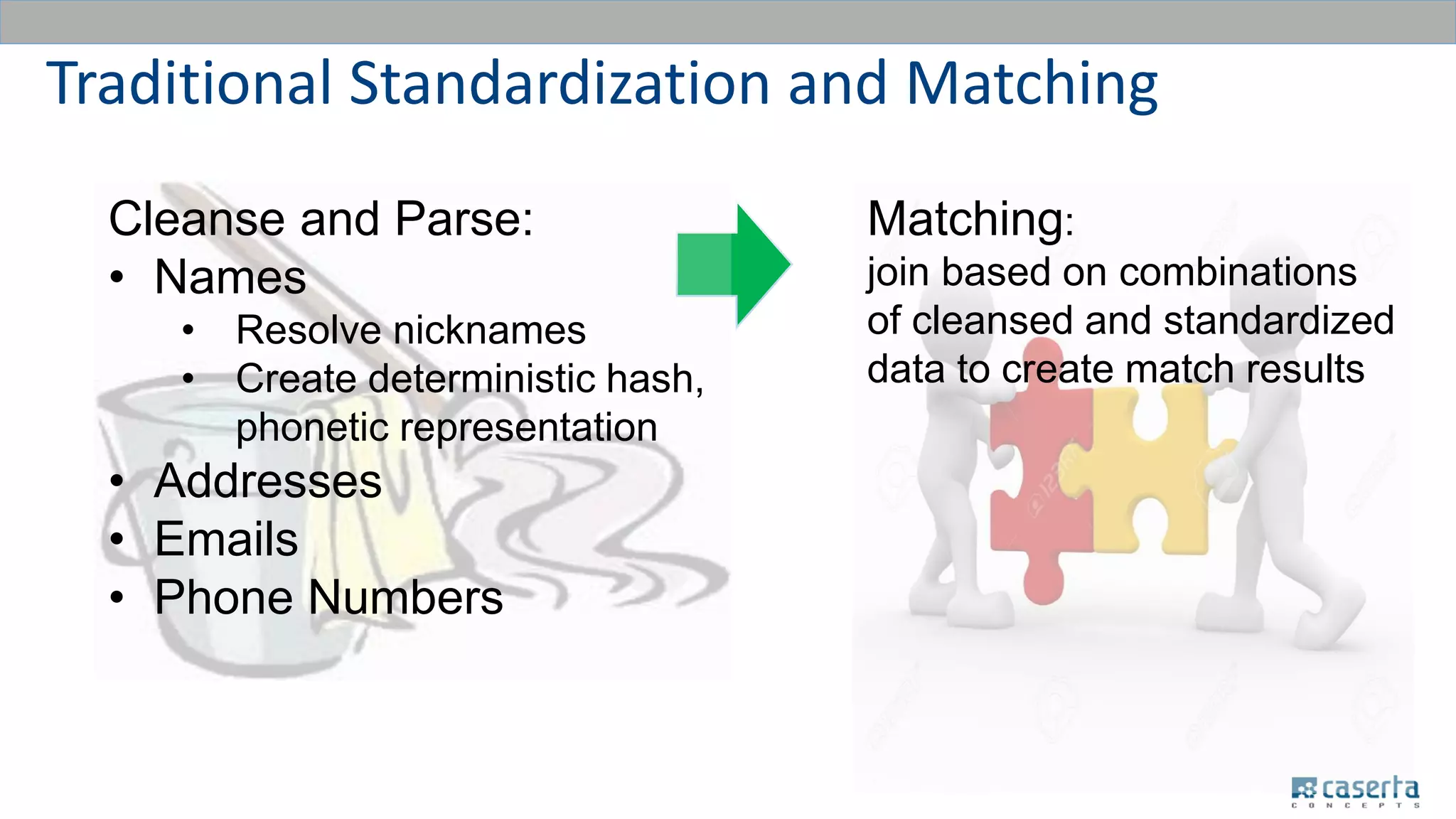






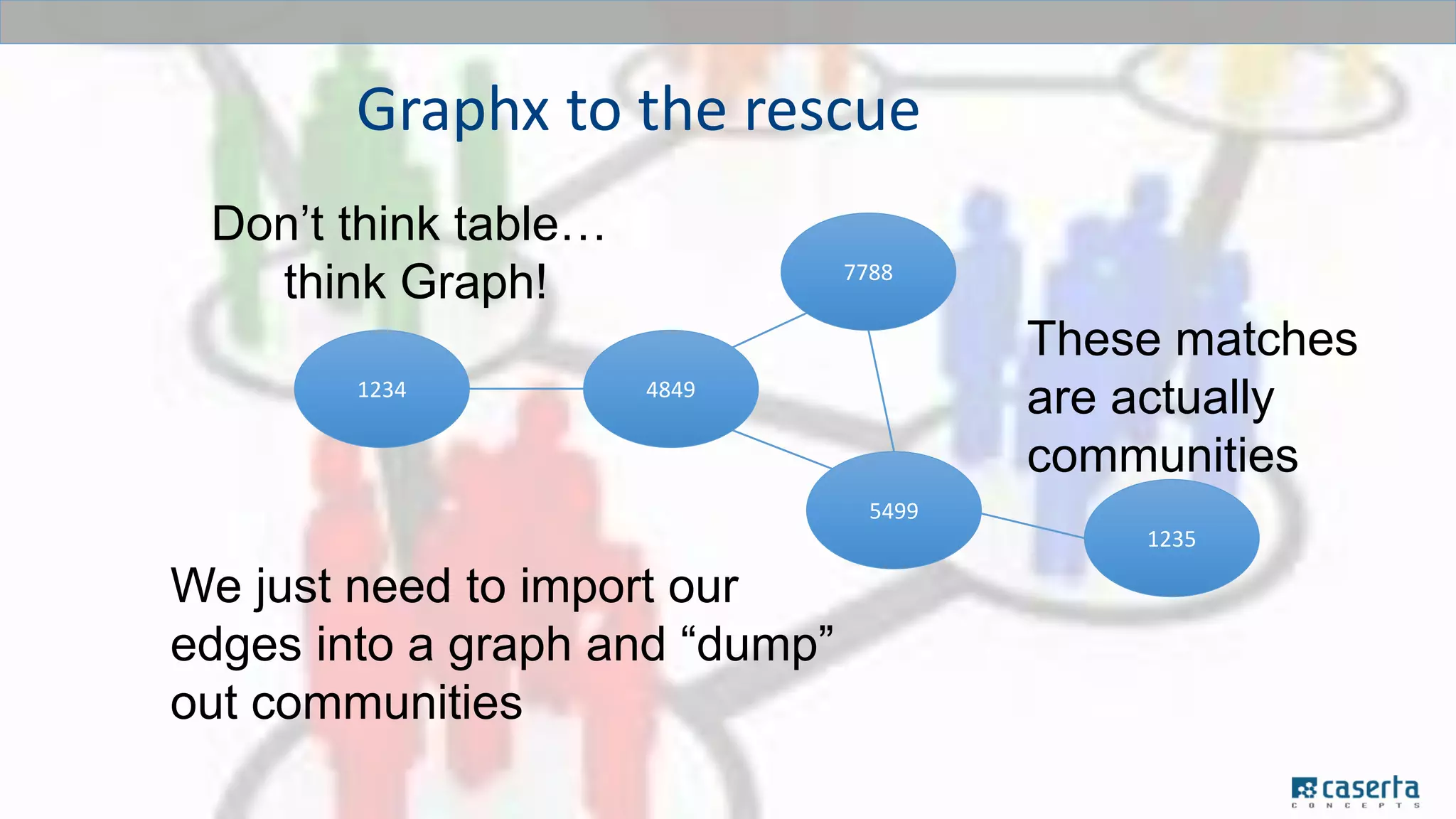



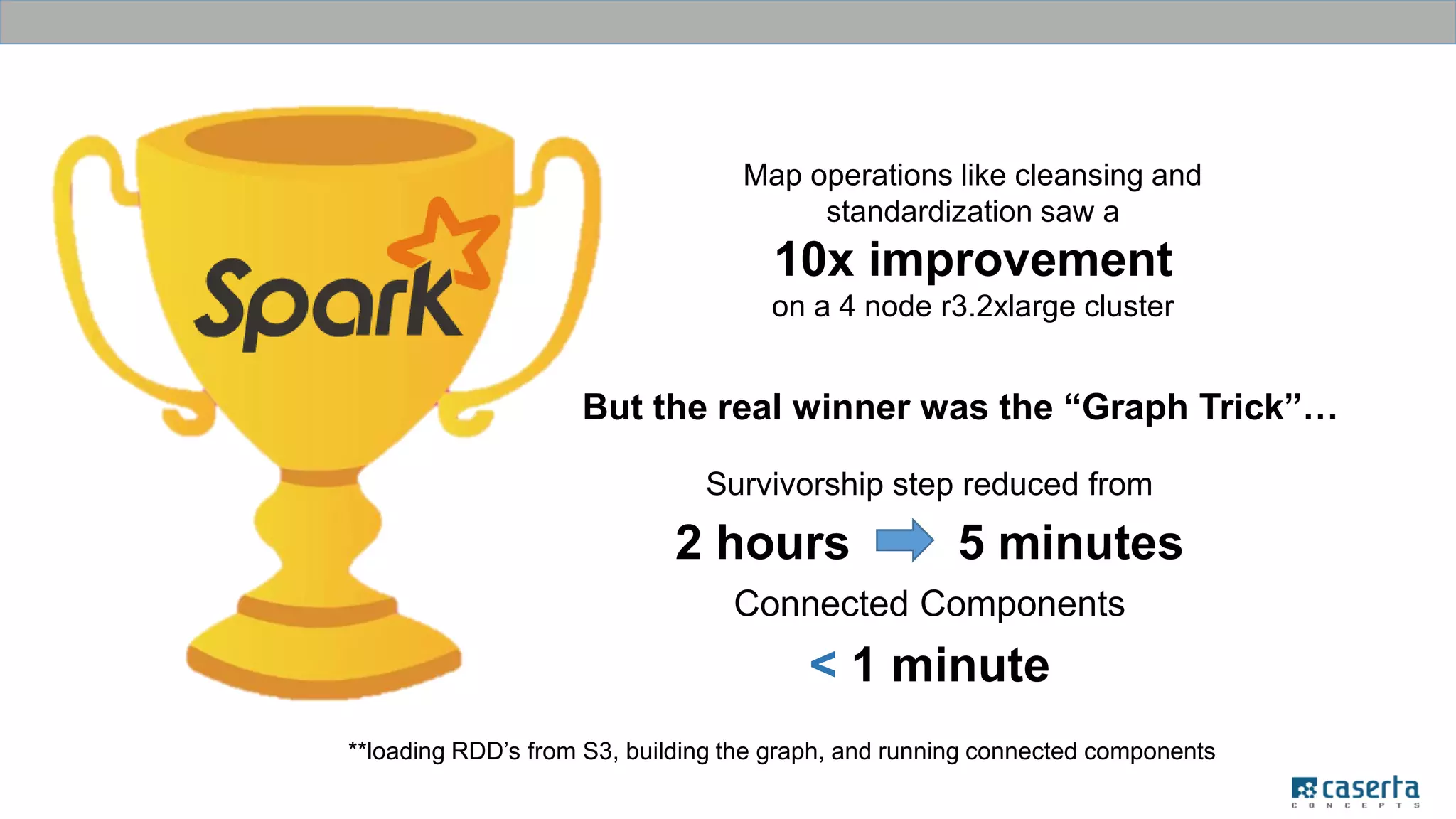



The document outlines a meetup focused on mastering customer data using Apache Spark and graph databases, featuring presentations from industry experts discussing the integration of customer data and the benefits of graph databases for Master Data Management (MDM). Key highlights include challenges with traditional MDM approaches, the advantages of using Spark for processing large datasets, and insights from a case study involving a customer engagement project. The event emphasizes the importance of effective data governance and innovative techniques for managing complex customer information.