Downloaded 16 times





![Log Data Examples Access log: 127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 Error log: [Sun Mar 7 20:58:27 2004] [info] [client 64.242.88.10] (104)Connection reset by peer: client stopped connection before send body completed [Sun Mar 7 21:16:17 2004] [error] [client 24.70.56.49] File does not exist: /home/httpd/twiki/view/Main/WebHome Vmstat procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 305416 260688 29160 2356920 2 2 4 1 0 0 6 1 92 2 0 iostat Linux 2.6.32-100.28.5.el6.x86_64 (dev-db) 07/09/2011 avg-cpu: %user %nice %system %iowait %steal %idle 5.68 0.00 0.52 2.03 0.00 91.76](https://image.slidesharecdn.com/softservelogdataanalysisplatform-150515162643-lva1-app6891/75/Log-Data-Analysis-Platform-7-2048.jpg)






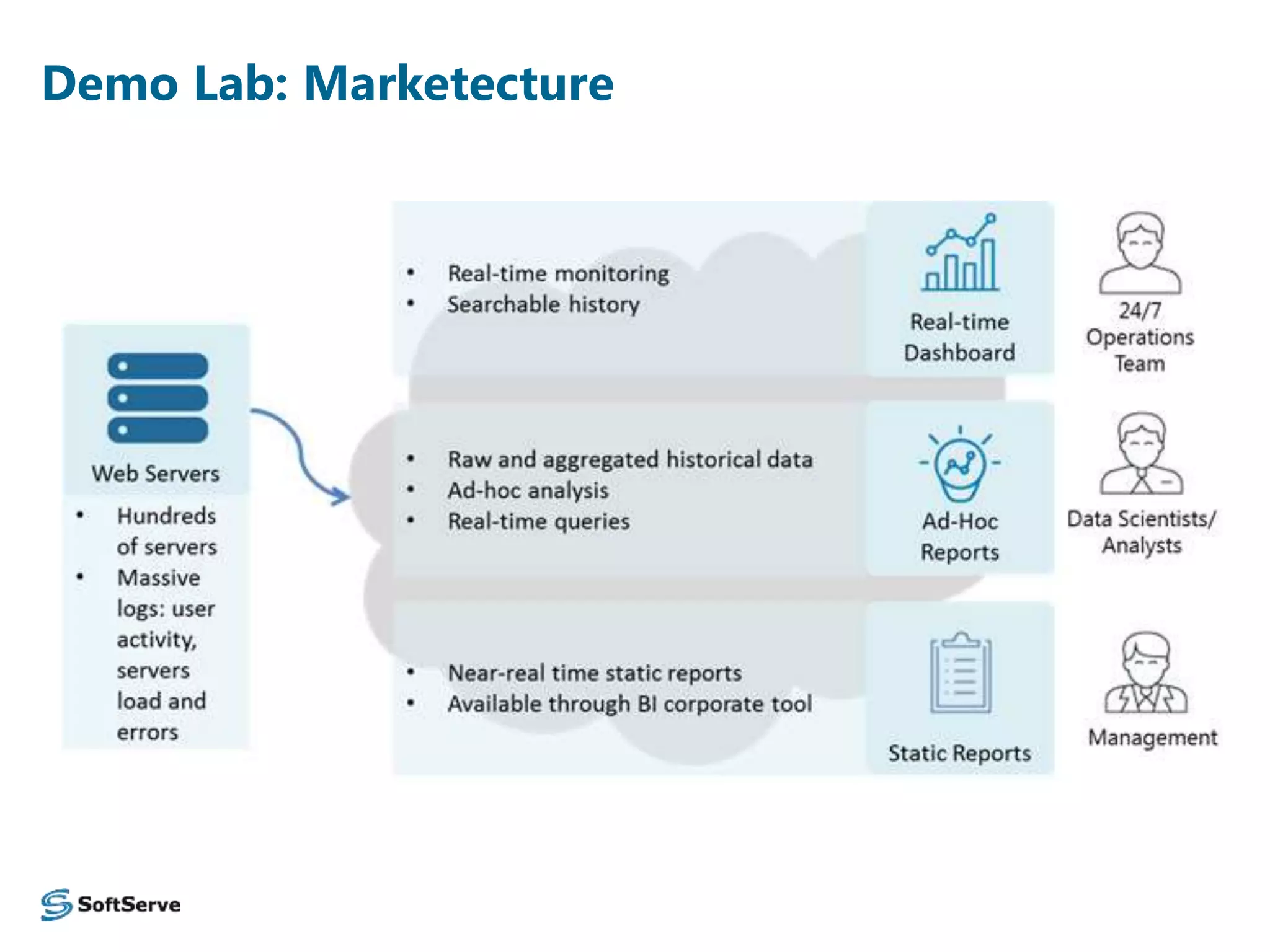

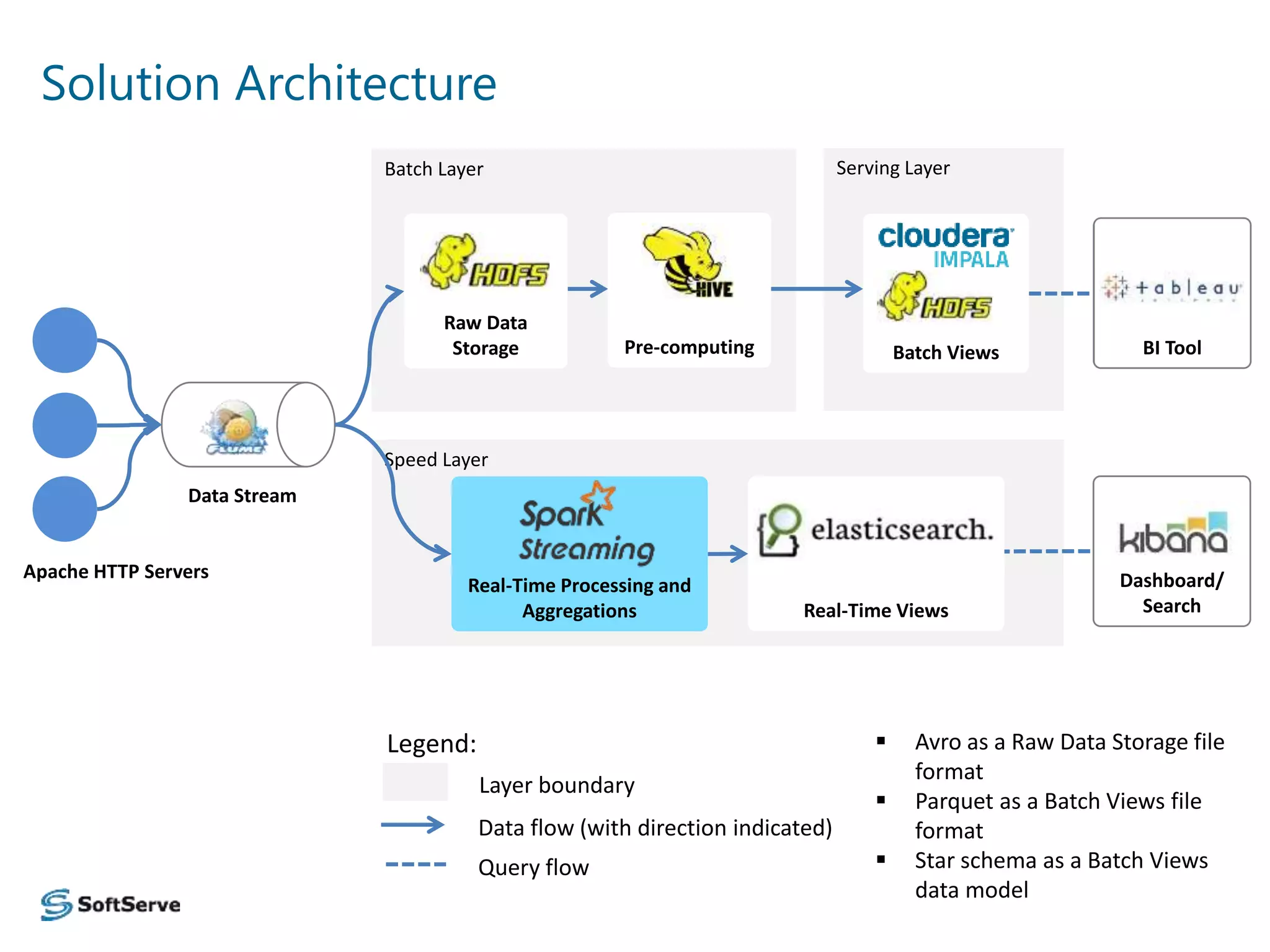
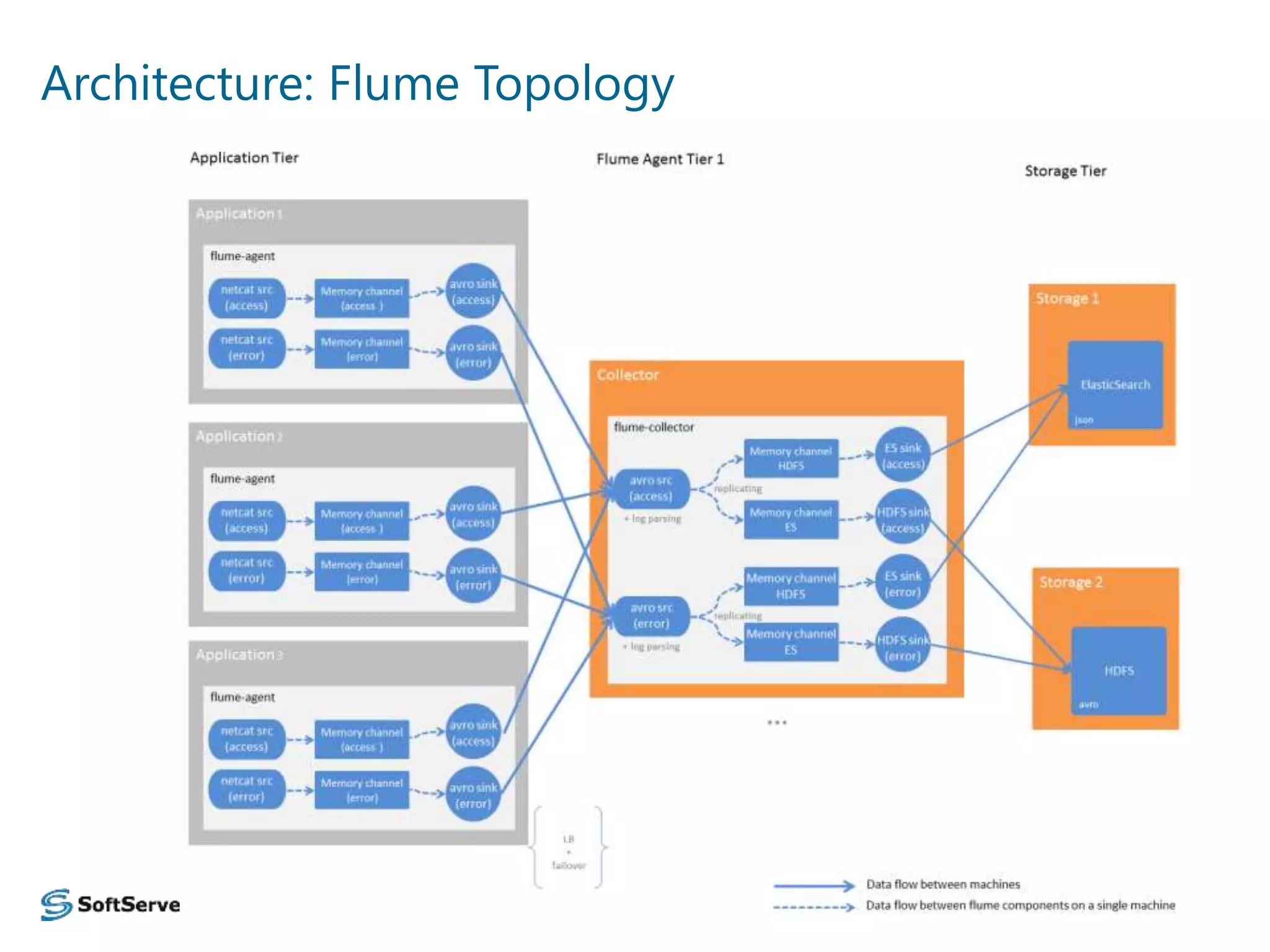
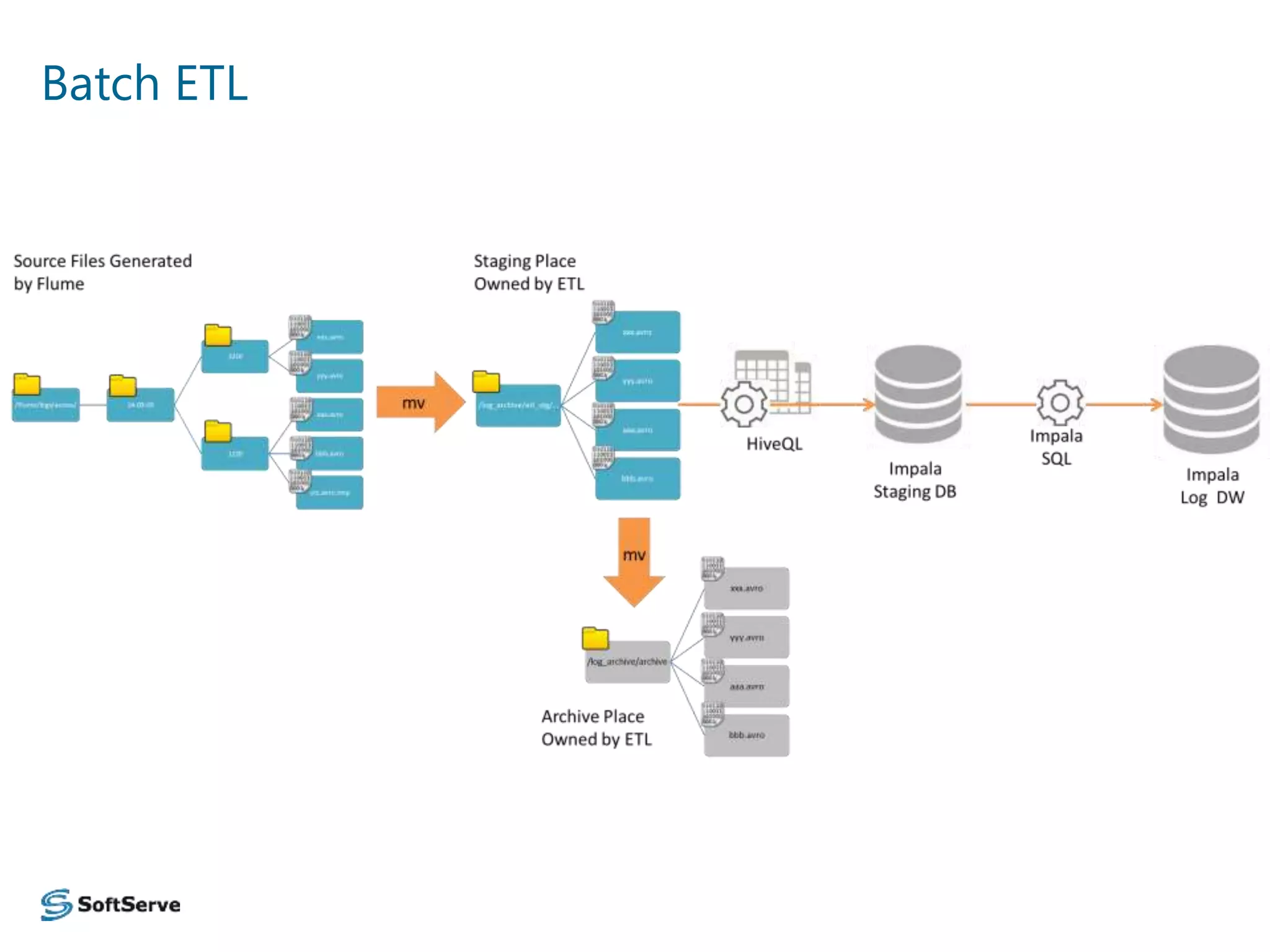




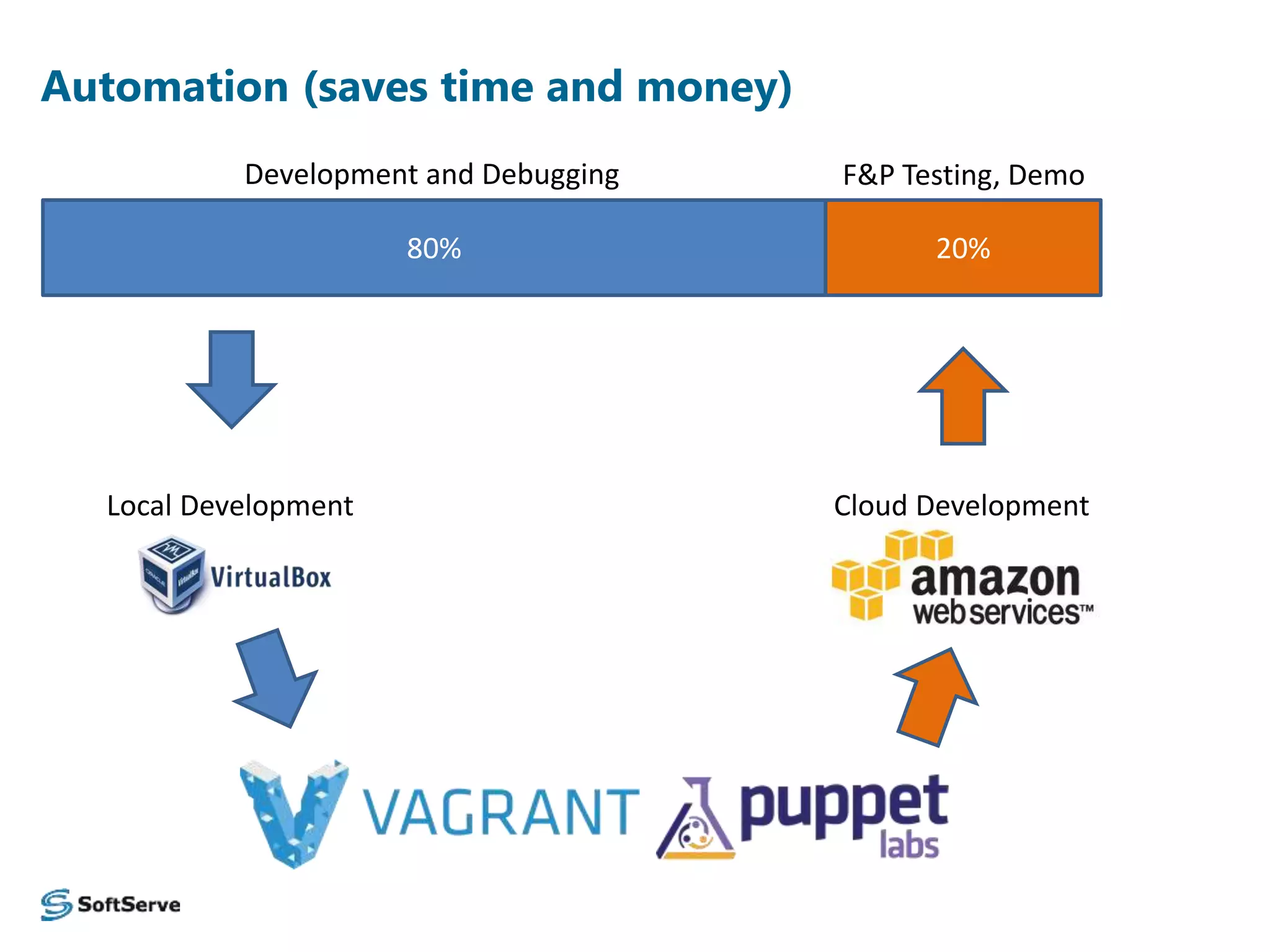



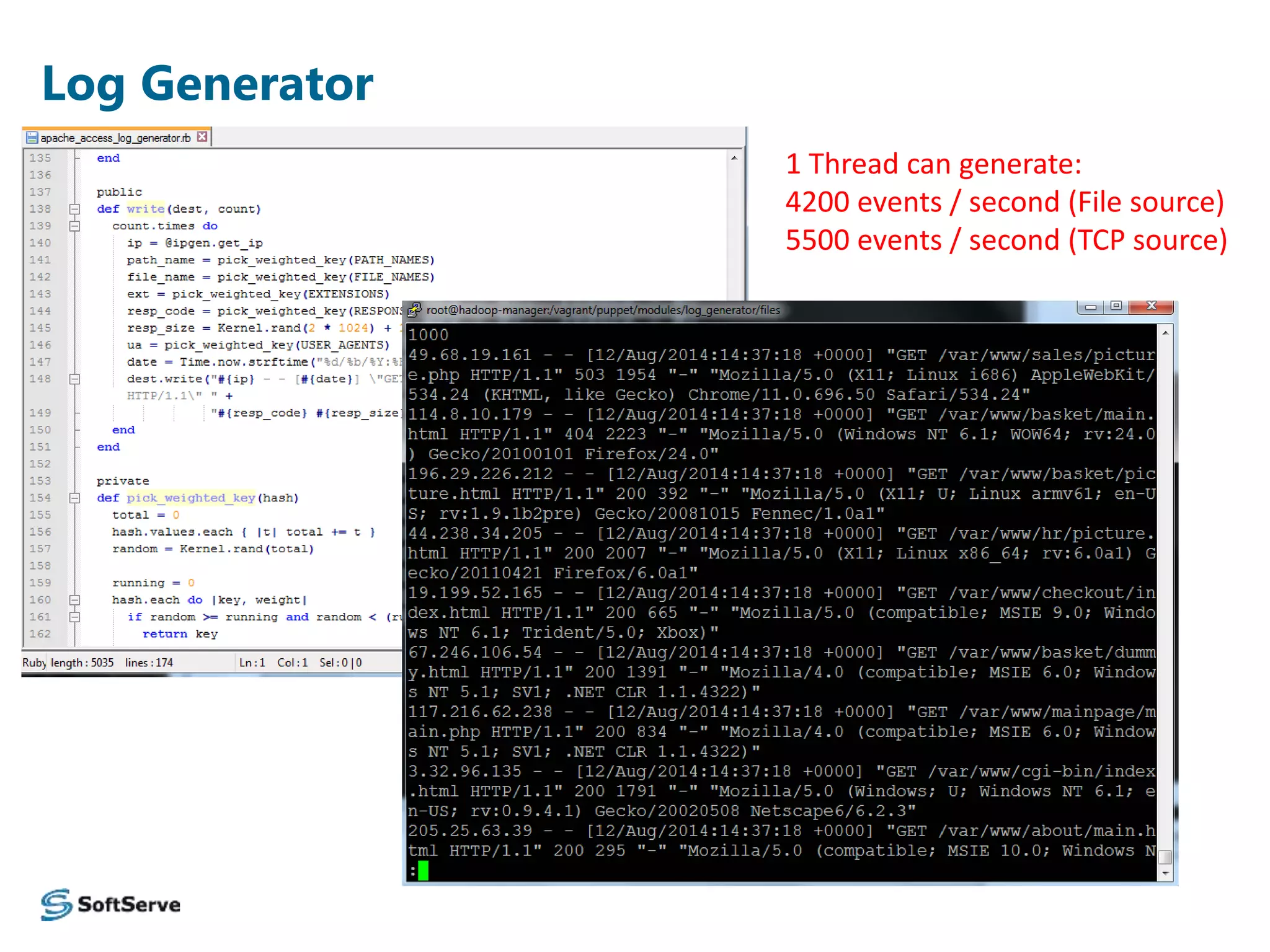
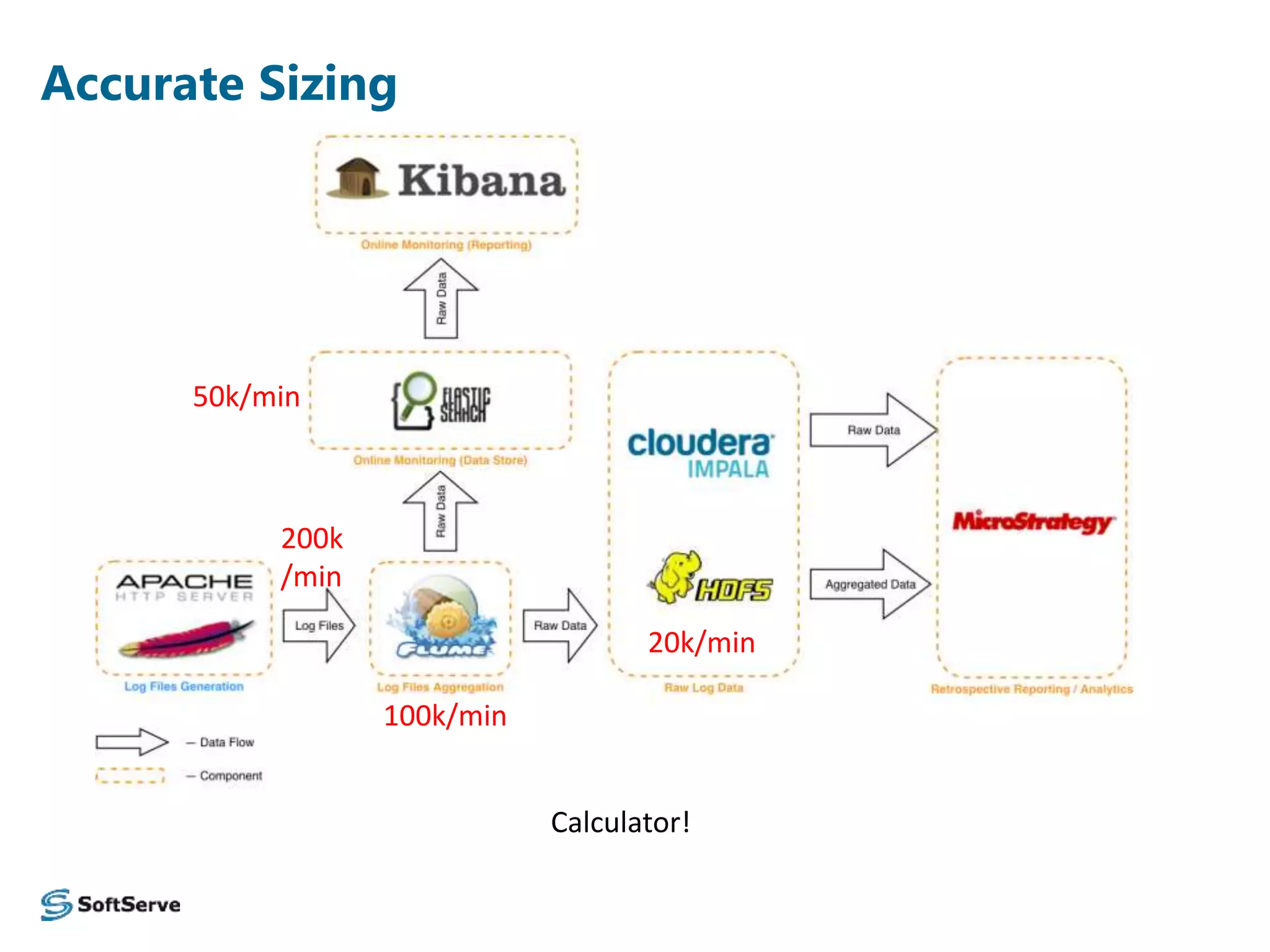




The document presents an overview of a log data analysis platform, detailing its structure, problematic areas, automation benefits, and performance testing results. It outlines the technology stack used, including Hadoop and Elasticsearch, and highlights plans for future enhancements, including open-source support and additional Hadoop distribution compatibility. The project aims to increase internal capabilities, decrease time to market, and acquire new customers.