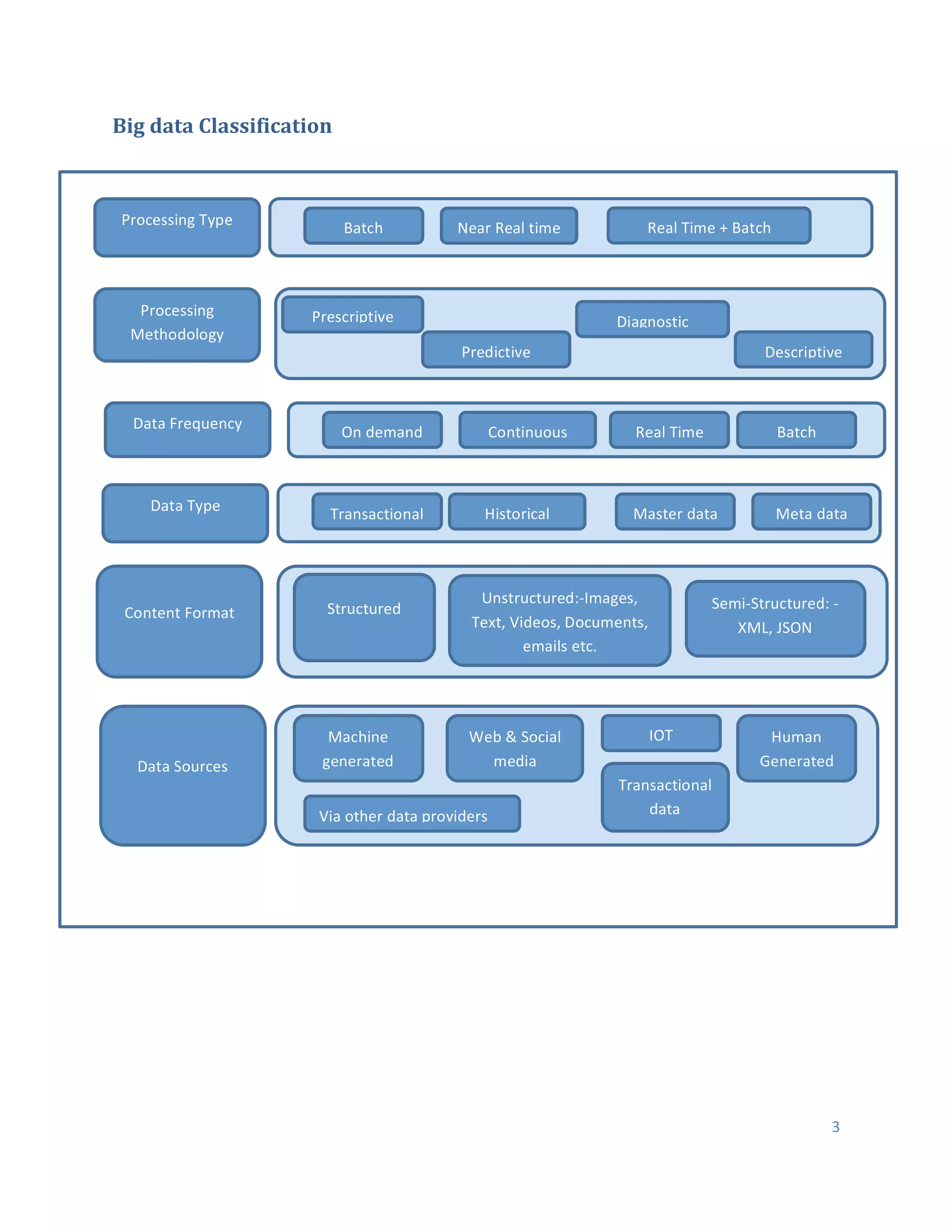
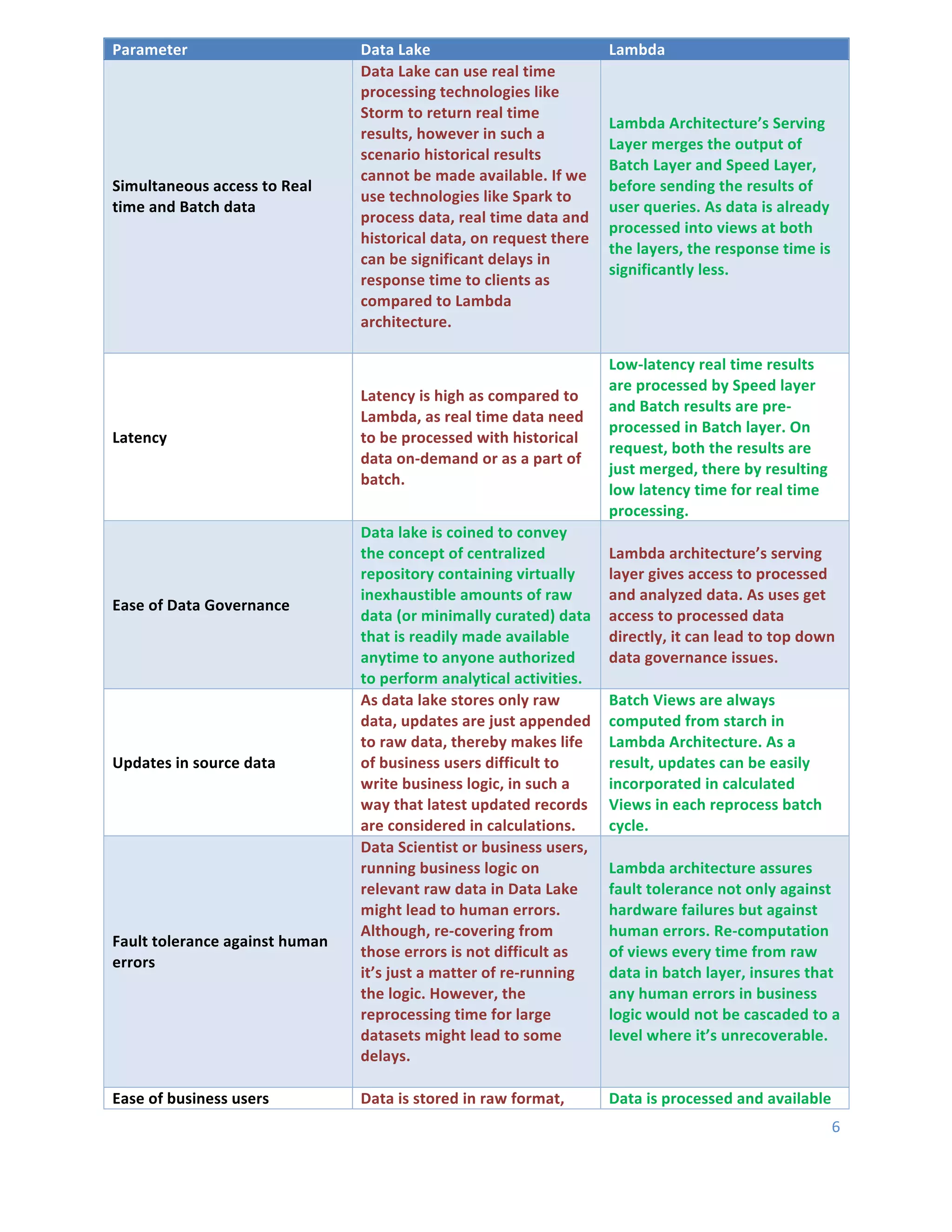
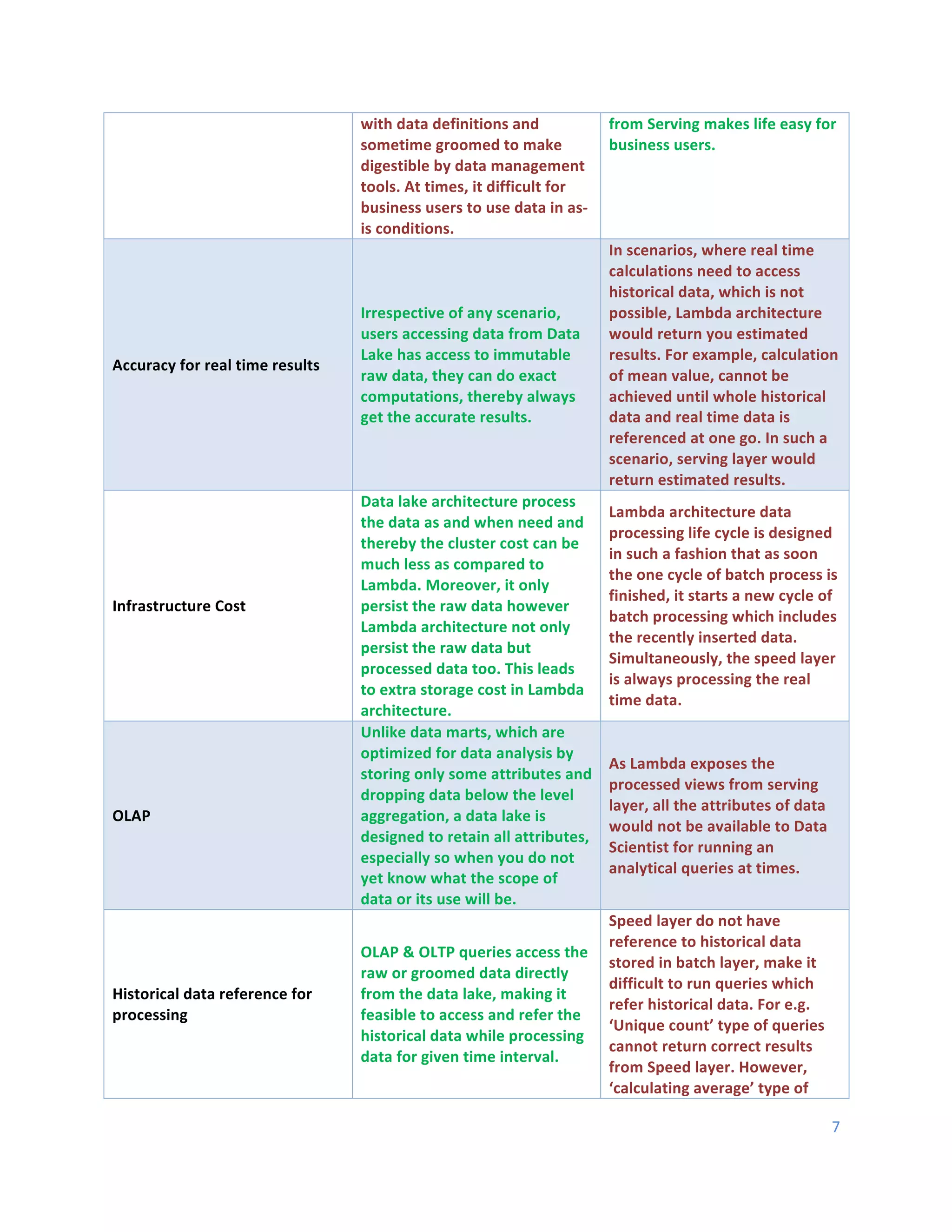
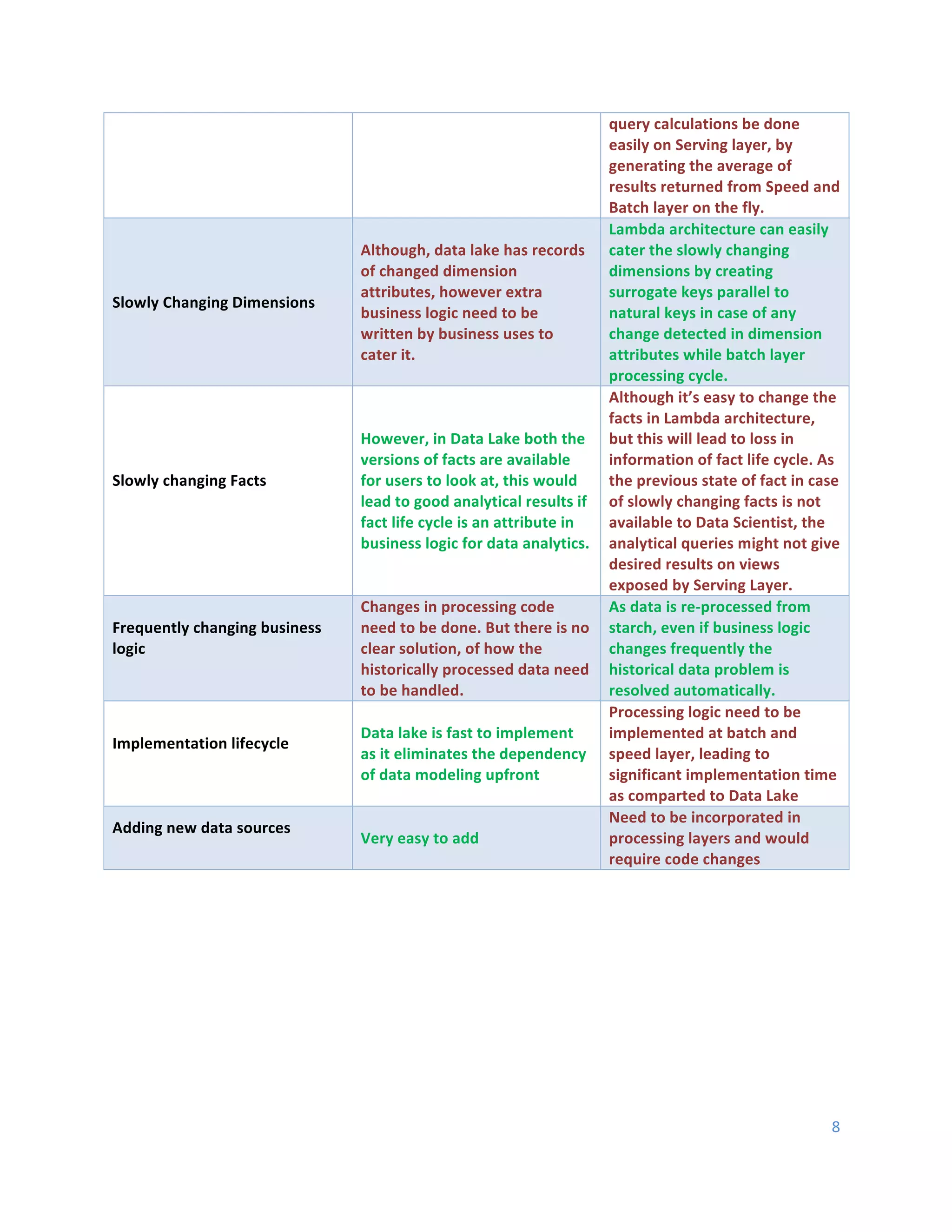
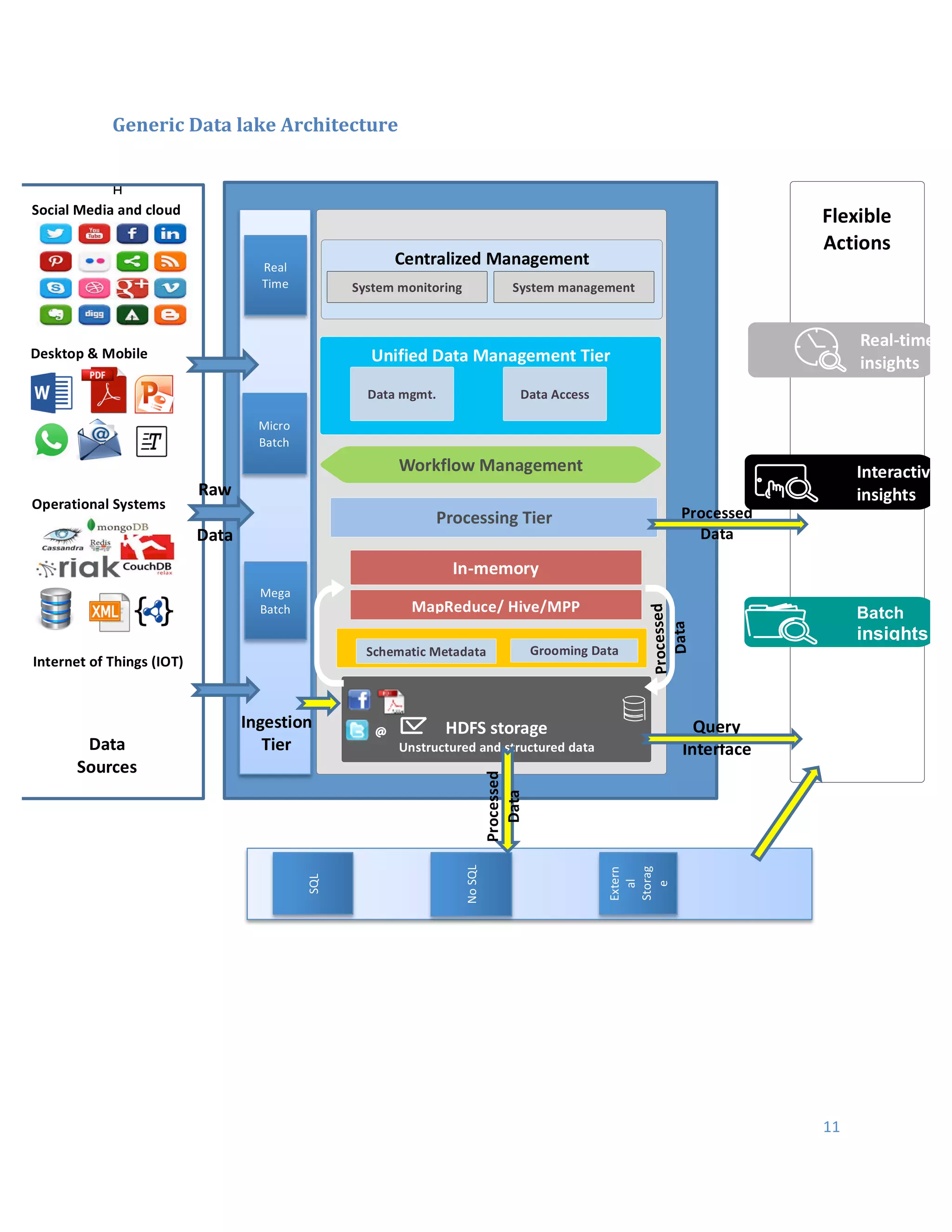
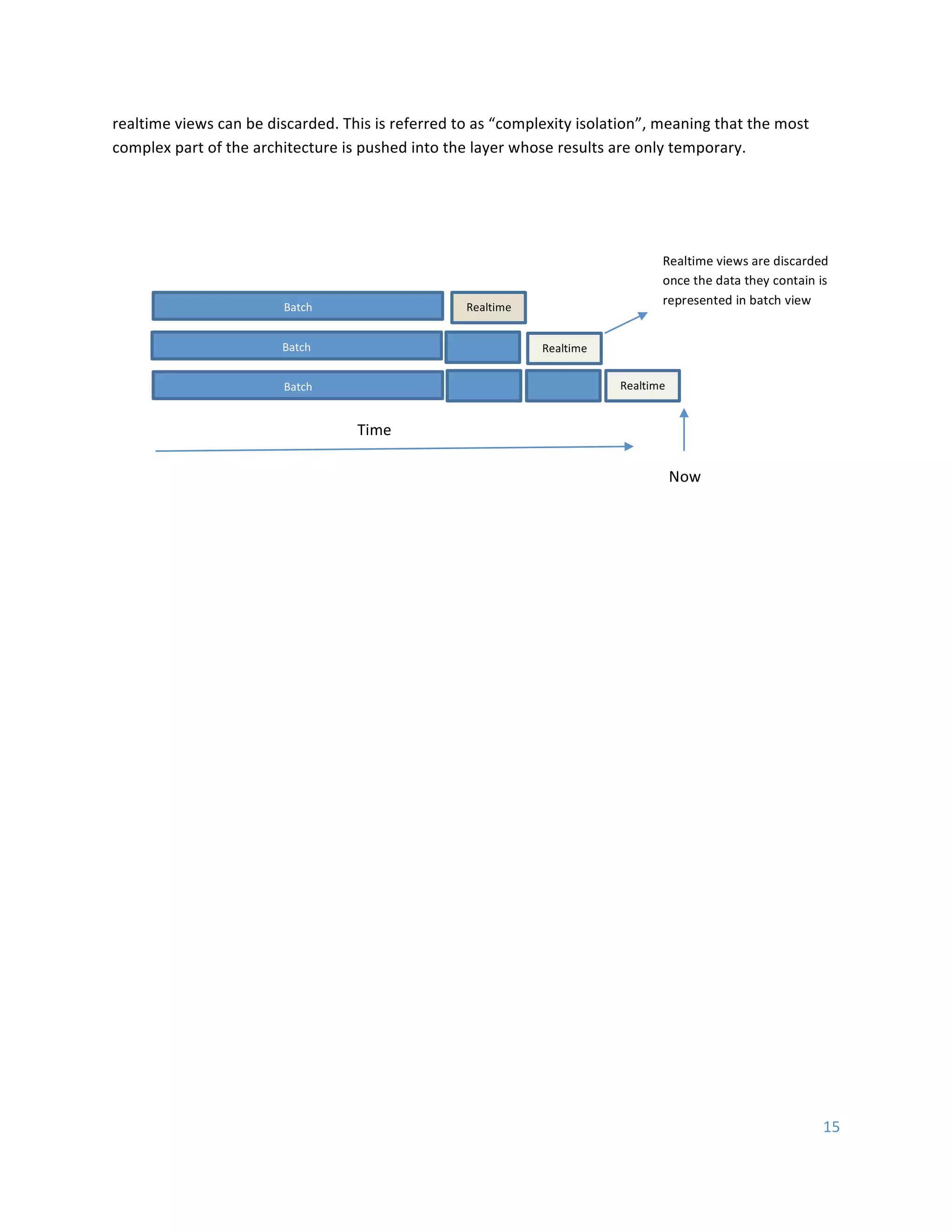
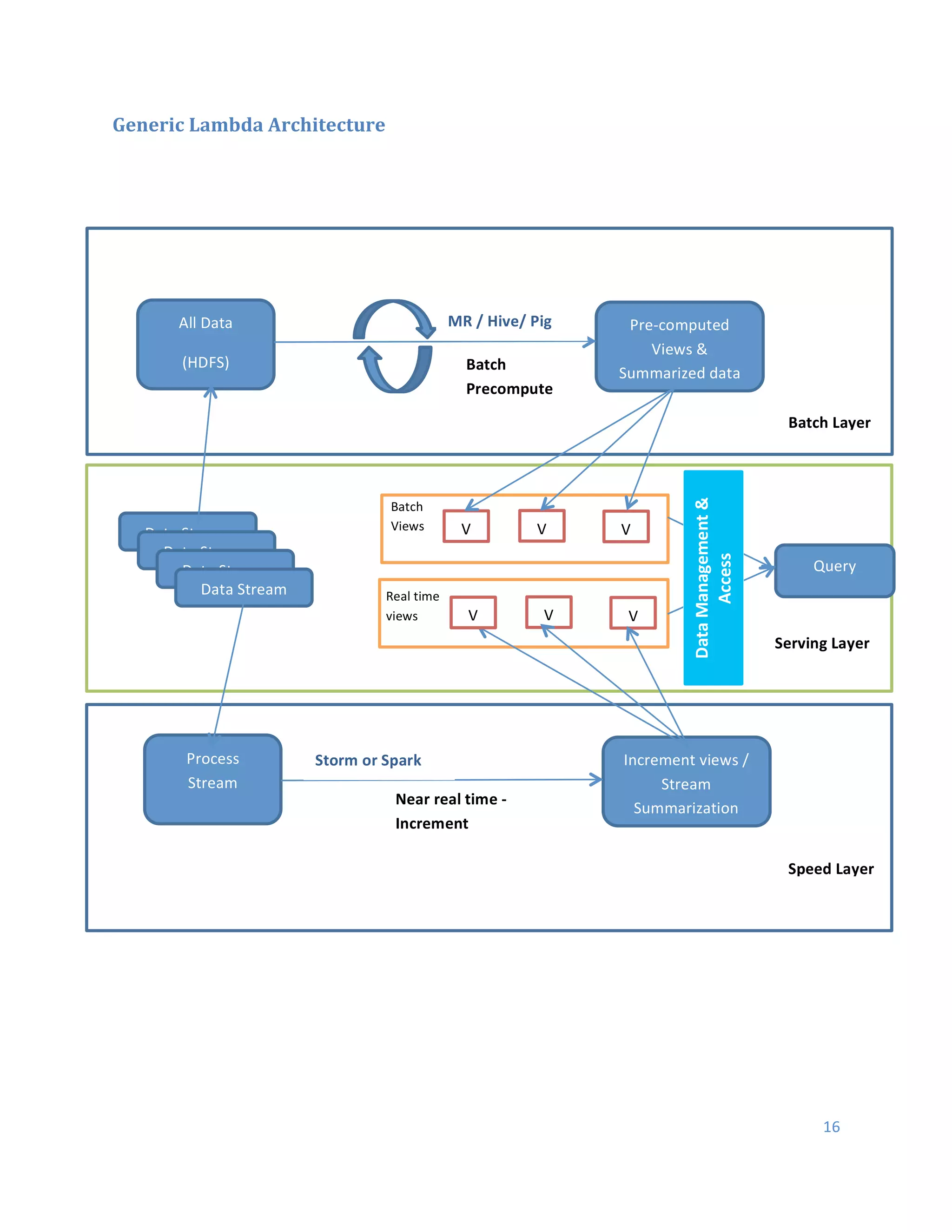
This document discusses Hadoop architecture approaches for big data, specifically data lake architecture and Lambda architecture. It provides an overview of these architectures, including their core components and how they handle batch and real-time processing. A data lake architecture uses Hadoop for flexible storage of all data, while a Lambda architecture combines batch and real-time processing to provide views of both old and new data. The document also covers classifying big data by characteristics like processing type, data sources, and format to determine the appropriate architecture.