Downloaded 66 times














































The document discusses relation extraction in language technology, focusing on the formal definition of relations and the importance of extracting structured information from unstructured text. It outlines methods for building relation extractors, such as supervised learning, bootstrapping, and unsupervised techniques, and explains summarization techniques for single and multiple documents, as well as query-focused summaries. Additionally, it touches on the evaluation of summarization through metrics like ROUGE, emphasizing the creation of concise, informative summaries for various applications.
Introduction to the presentation on semantic analysis in language technology with details about the speaker and university.
Explains what relation extraction is, its significance, and examples of binary relations like 'father-of' or 'located-in'.
Describes various approaches to build relation extractors, including supervised, semi-supervised, and bootstrapping methods.
Provides examples of practical activities in relation extraction, focusing on extracting author-book pairs using seed patterns.
Introduces various summarization types, including news and book summaries, and discusses human summarization and extractive vs. abstractive methods.
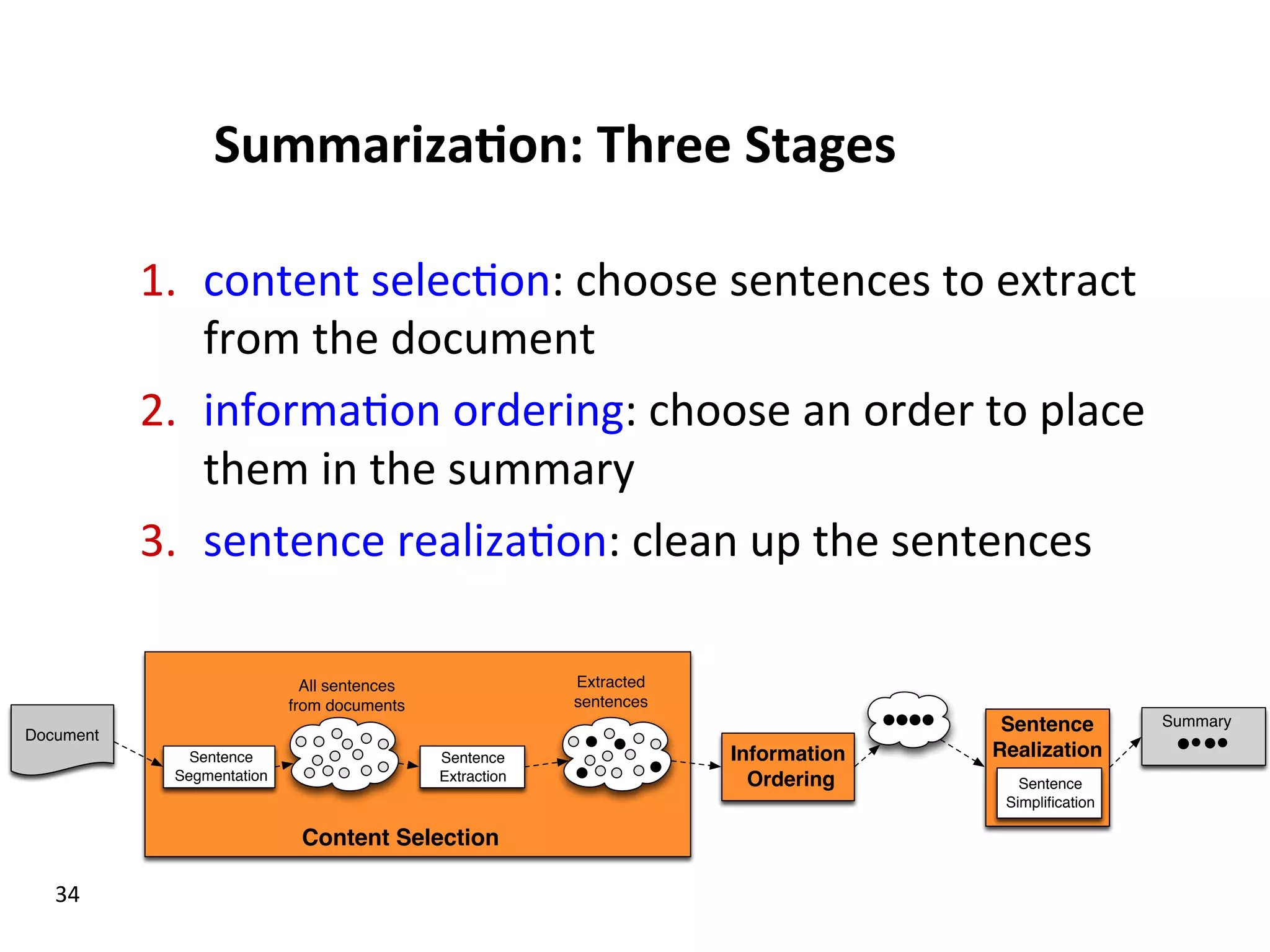
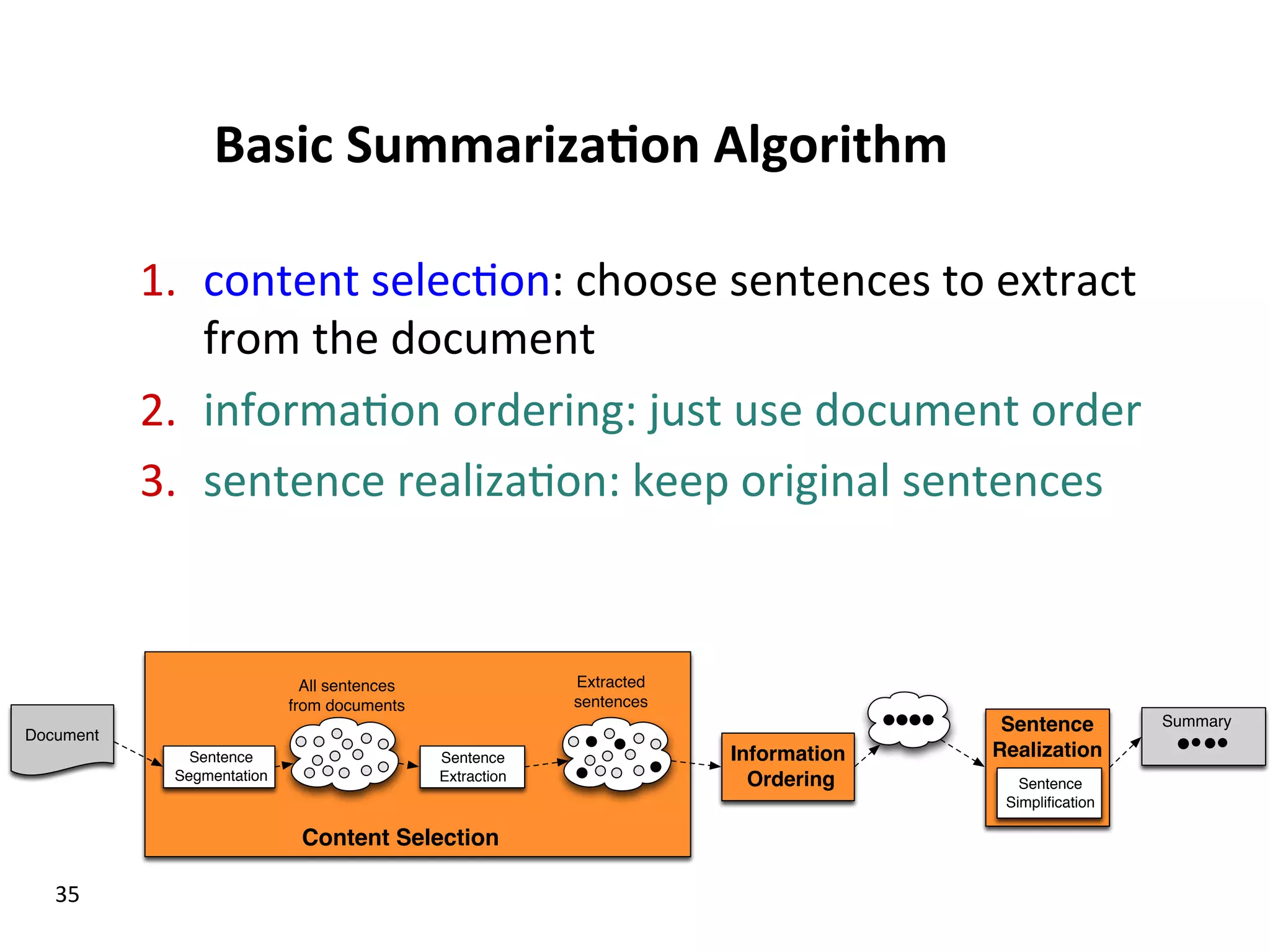
Examines stages of summarization, types including extractive and abstractive summarization, and various summarization algorithms.
Focuses on methods for content selection during summarization, including supervised and unsupervised techniques, and metrics for evaluation like ROUGE.
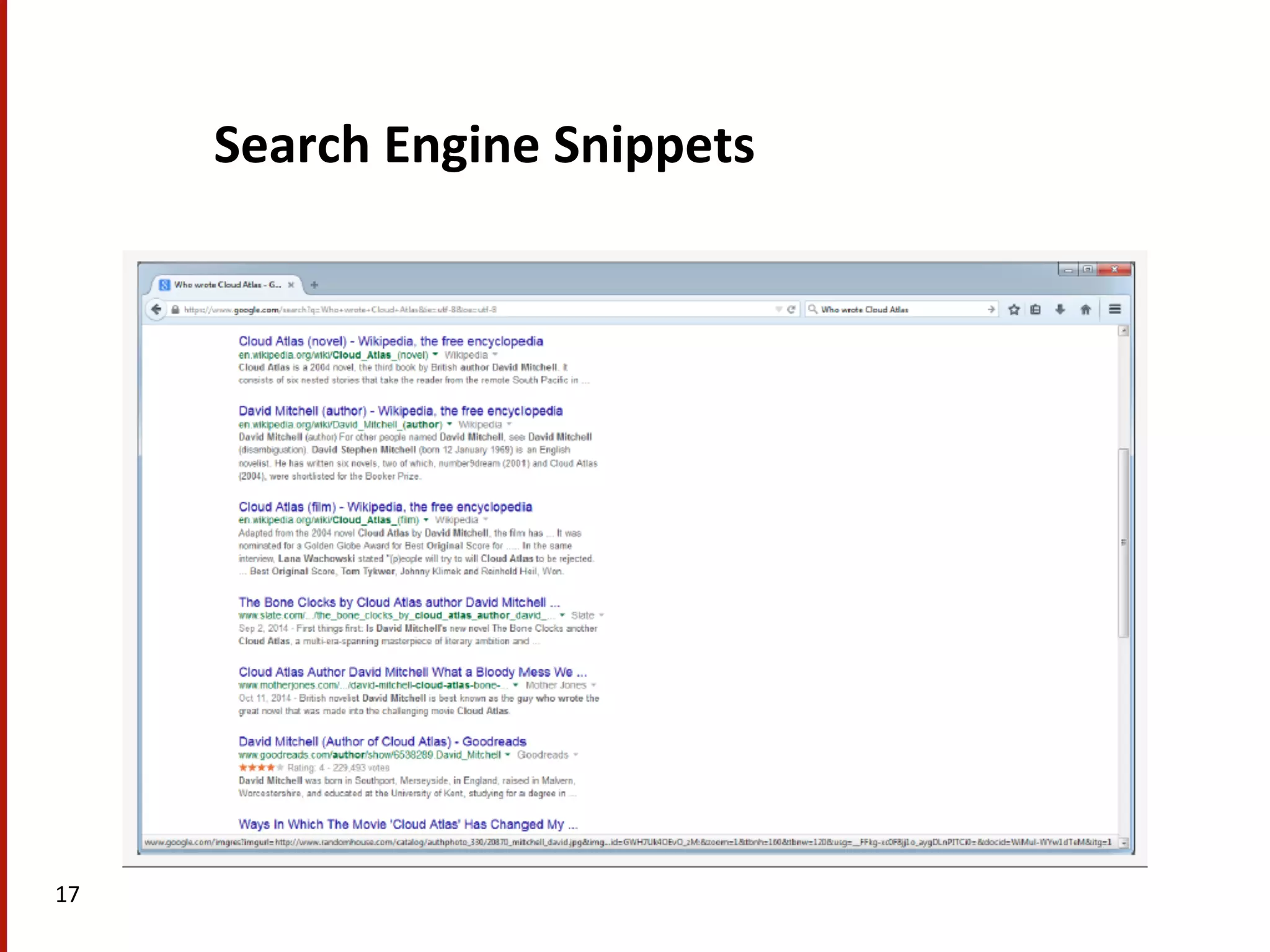
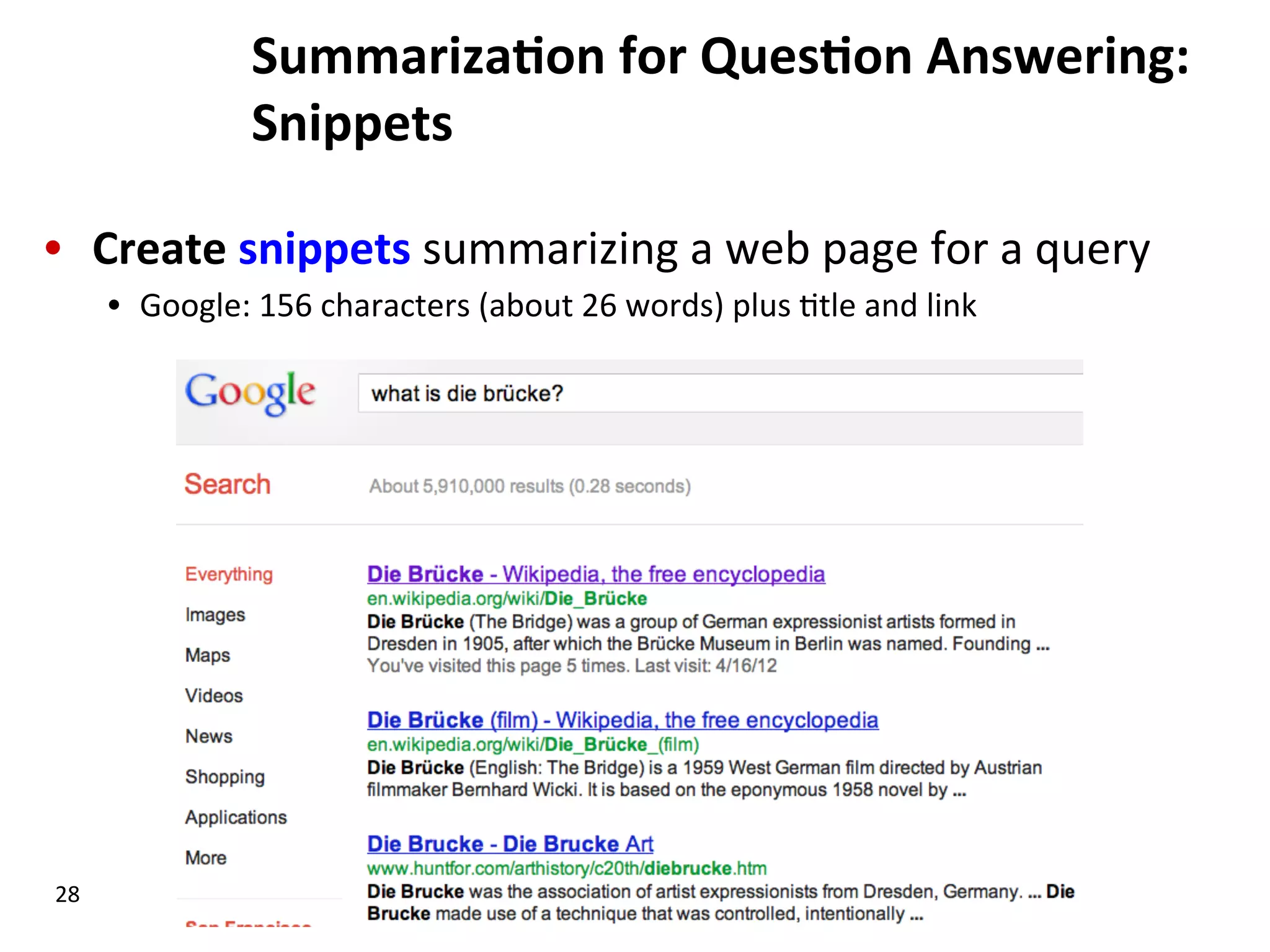
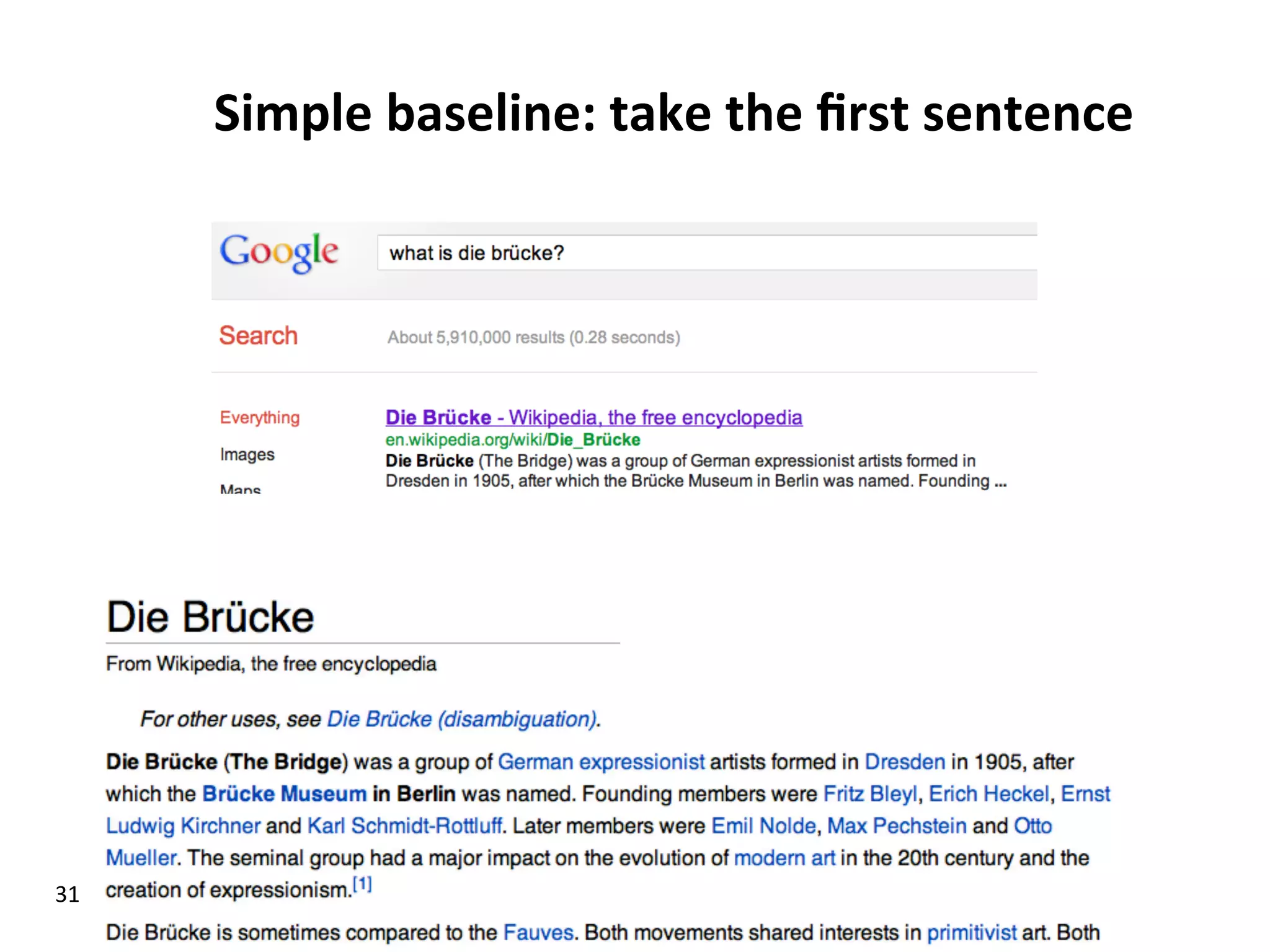
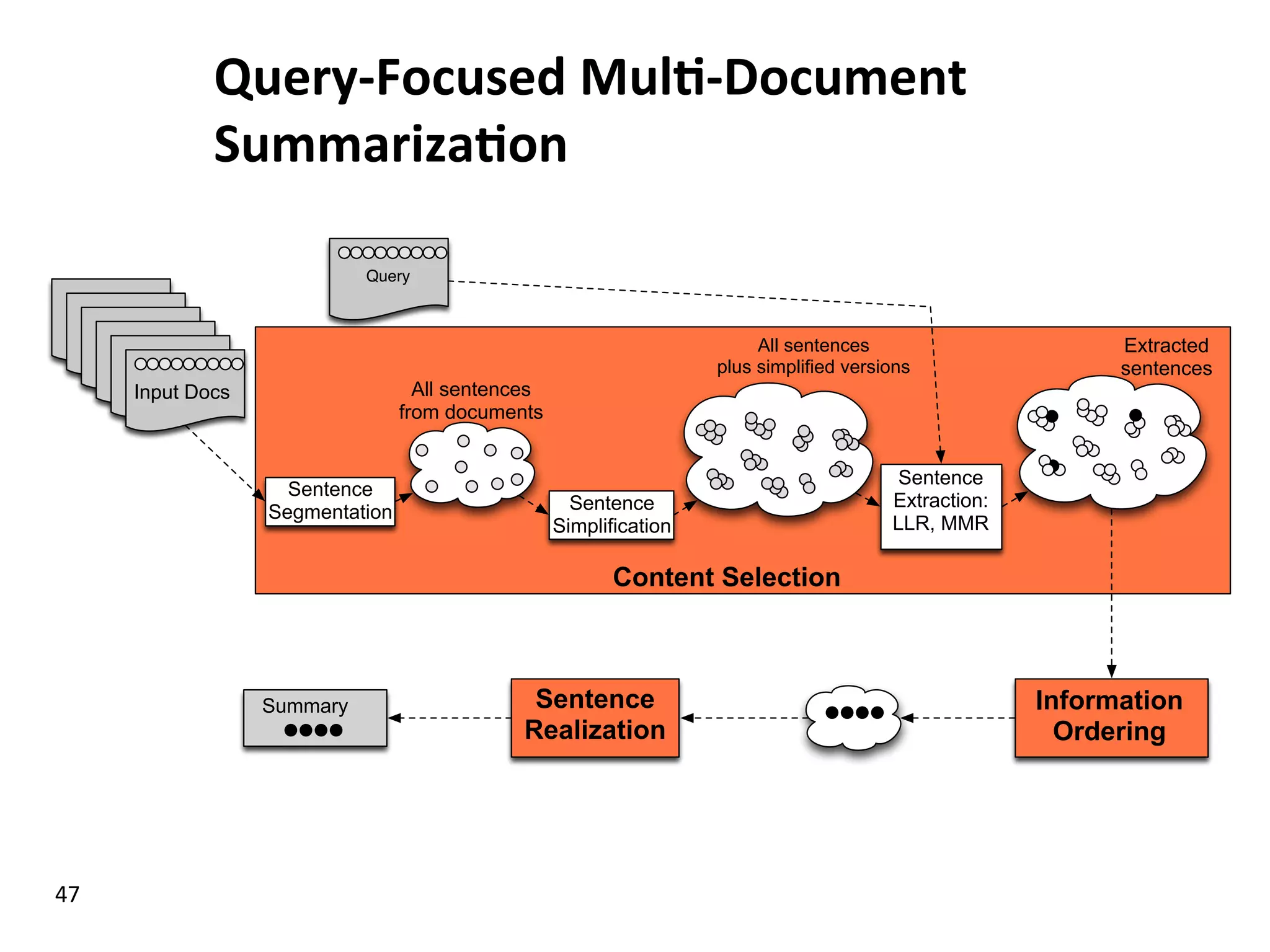
Discusses complex question answering techniques, query-focused multi-document summarization, and domain-specific answering strategies.
Concludes the presentation with a final note.