Download as PDF, PPTX

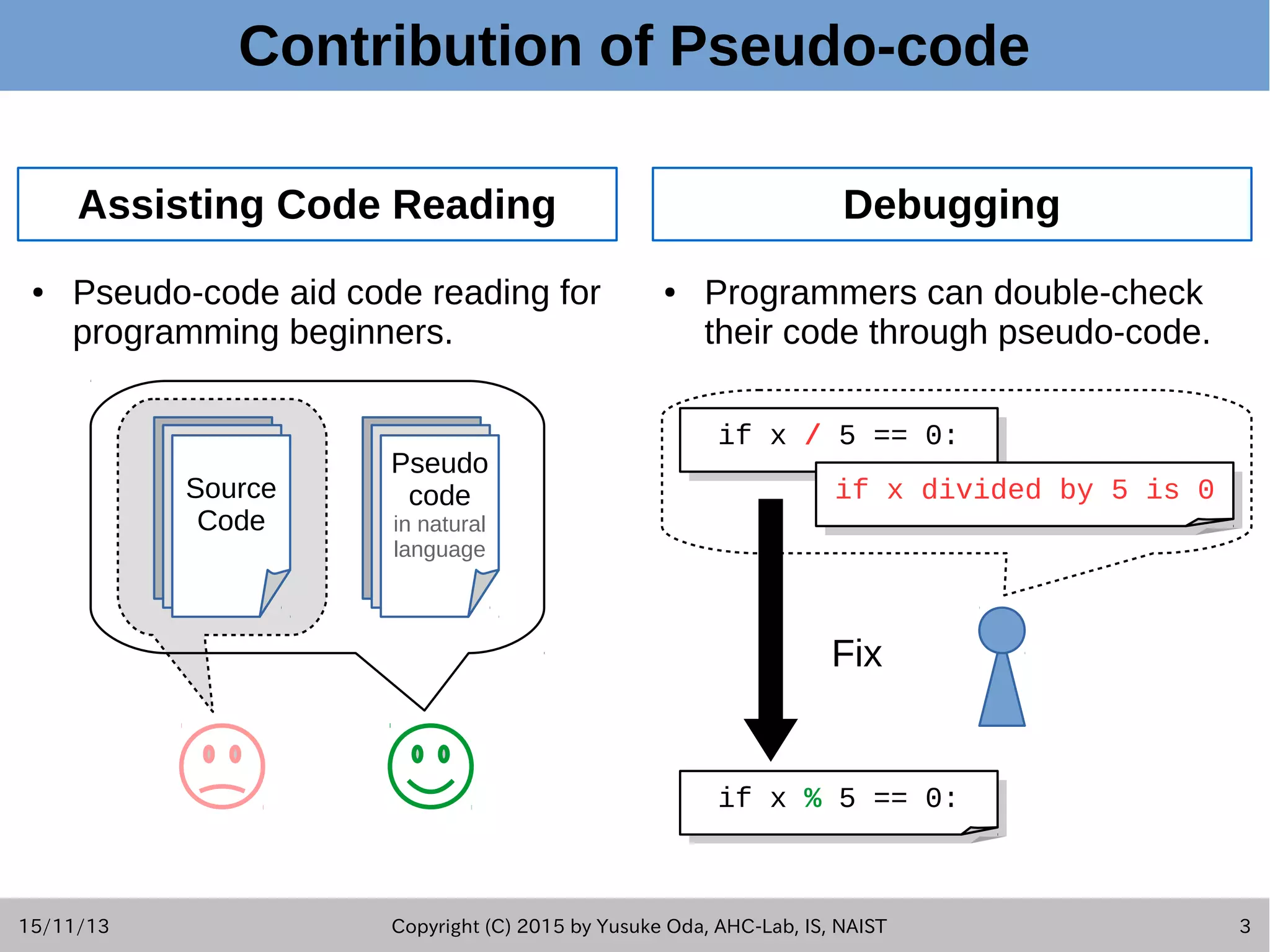
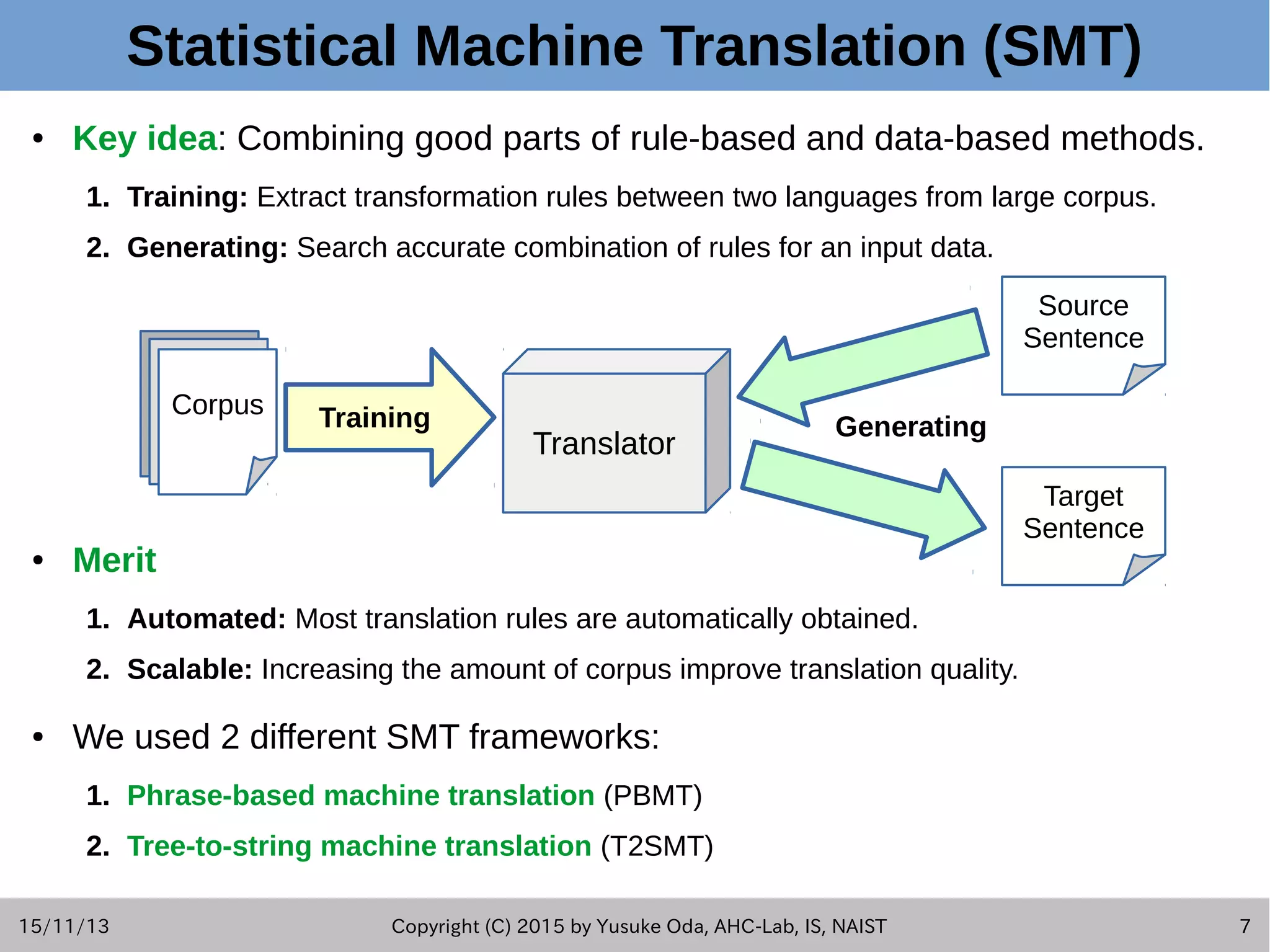
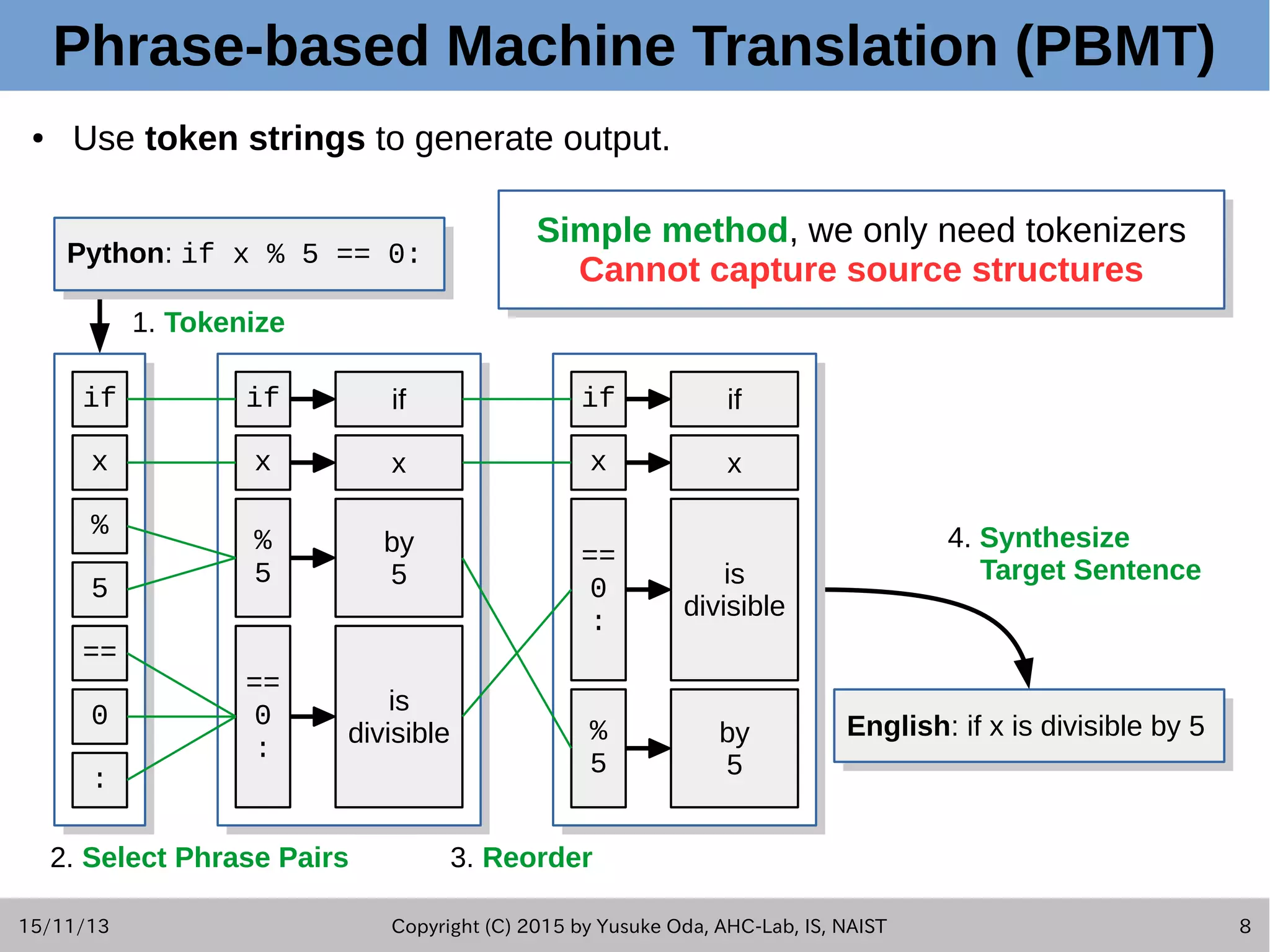
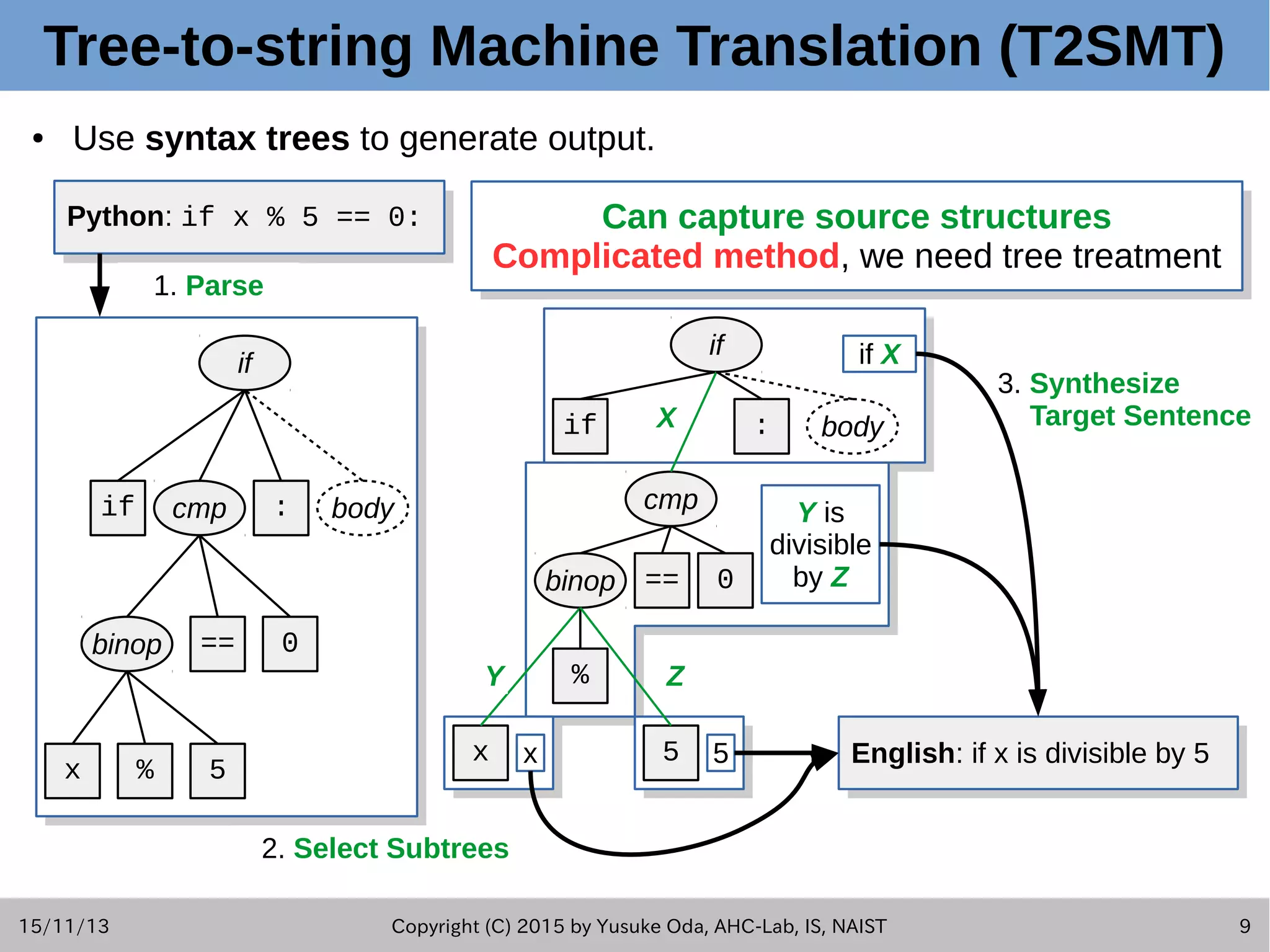
![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 2 Summary of This Study ● This presentation introduces summaries of key techniques used in Pseudogen tool. [Fudaba+2015] ● Goal: – Generating natural language sentences which describe the behavior of each statement in source code. – We call these output sentences "pseudo-code." ● Approach: – Used 2 different frameworks of statistical machine translation (SMT).](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-2-2048.jpg)

![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 5 Related Work for Sentence Generation ● Rule-based methods e.g. [Buse+ '08], [Sridhara+ '10], [Sridhara+ '11], [Moreno+ '13] – Can use detailed information, however requires high cost maintainance. os.print(・) → print ・ to output streamos.print(・) → print ・ to output stream msg → messagemsg → message print message to output system Search on rule table Combine print message to output system Search on KB Propose Knowledge Base Knowledge Base os.print(msg) print message to output system os.print(msg) print message to output system os.print(msg) os.print(msg) ● Data(IR)-based methods e.g. [Haiduc+ '10], [Eddy+ '13], [Wong+ '13], [Rodeghero+ '14] – Can use large corpora from real wold, however sometimes occurs search error.](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-5-2048.jpg)





![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 16 Problem of AST • Problem: Mismatching of token nodes. If Compare BinOp Name %Loadx Num 5 == Num 0 Body id ctx left op right left ops[0] comparators[0] n n test body if x is divisible by 5 ? English – There are redundant nodes. – Some words in natural language are aligned to inner nodes in AST. Our approach Applying simple transformation rules to avoid token mismatching](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-16-2048.jpg)
![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 17 Parse-like Tree (1): Head Insertion 1. Insert HEAD leaves (= label of each nodes). If Compare BinOp Name %Loadx Num 5 == Num 0 Body NumNumNameBinOpCompareIf id ctx left op right left ops[0] comparators[0] n n test body HEAD HEAD HEAD HEAD HEAD HEAD](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-17-2048.jpg)
![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 18 Parse-like Tree (2): Pruning 1. Insert HEAD leaves (= label of each nodes). 2. Delete redundant nodes. If Compare BinOp Name %Loadx Num 5 == Num 0 Body NumNumNameBinOpCompareIf id ctx left op right left ops[0] comparators[0] n n test body HEAD HEAD HEAD HEAD HEAD HEAD](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-18-2048.jpg)
![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 19 Parse-like Tree (3): Simplification 1. Insert HEAD leaves (= label of each nodes). 2. Delete redundant nodes. 3. Integrate some nodes. If Compare BinOp Name %x Num 5 == Num 0NumNumNameIf id left op right left ops[0] comparators[0] n n test HEAD HEAD HEAD HEAD x 5 0](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-19-2048.jpg)
![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 20 Parse-like Tree (4): Final Tree • Finally, we obtain the parse-like tree below. If Compare BinOp % ==If left op right left ops[0] comparators[0] test HEAD x 5 0 if x is divisible by 5English](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-20-2048.jpg)


![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 25 Results: Intrinsic Evaluation ● BLEU and Acceptability has the same tendencies: Modified-T2SMT > Raw-T2SMT > PBMT ● Modified-T2SMT method has the best performance in all settings. – 72% of test samples achieve the highest Acceptability (= gramatically correct & fluent) Genaerator BLEU% English Japanese PBMT 25.71 51.67 Raw-T2SMT 49.74 55.66 Modified-T2SMT 54.08 62.88 PBMT Raw-T2SMT Reduced-T2SMT 0% 20% 40% 60% 80% 100% 5 4 3 2 1 CumulativeAcceptability Human Evaluation: Acceptability [Goto et al. 2013] (Python-Japanese) 50% 63% 72% (do not compare scores between English and Japanese) Automatic Evaluation: BLEU [Papineni et al. 2002]](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-25-2048.jpg)
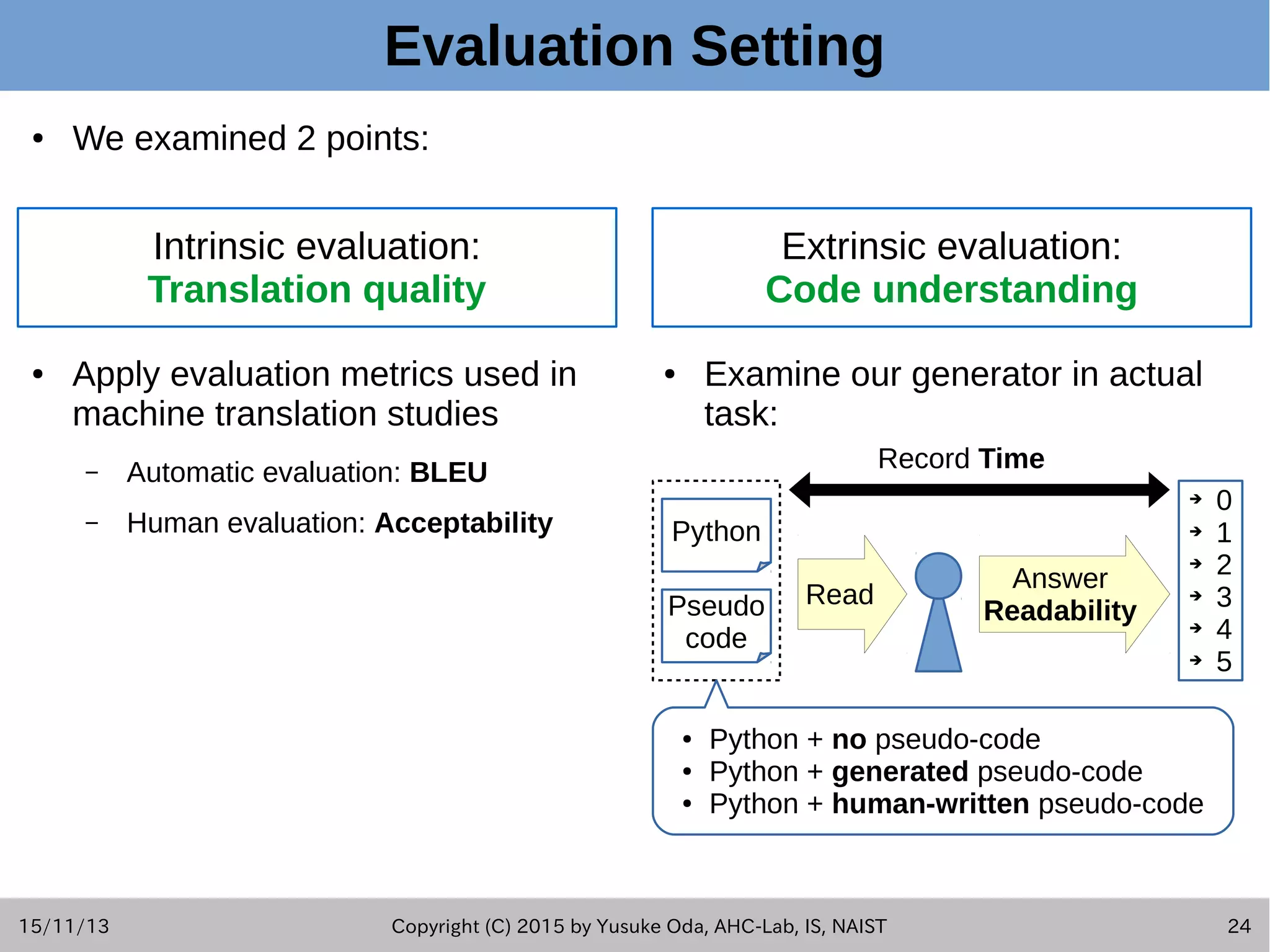
![15/11/13 Copyright (C) 2015 by Yusuke Oda, AHC-Lab, IS, NAIST 26 Results: Code Understanding ● Generated pseudo-code can improve code readability compared with no pseudo-code. ● But reading time increases. – This comes from generation error (oracle pseudo-code decreases reading time). Group Pseudo-code Readability (6-grade Likert) Mean Reading Time [s] Experienced (8 people) No 2.55 41.37 Generated 2.71 46.48 Human-written 3.05 35.65 Inexperienced (6 people) No 1.32 24.99 Generated 1.81 39.52 Human-written 2.10 24.97 Code Readability and Reading Time (Python-Japanese, Modified-T2SMT)](https://image.slidesharecdn.com/oda201511aseslides-151113151044-lva1-app6892/75/Learning-to-Generate-Pseudo-code-from-Source-Code-using-Statistical-Machine-Translation-26-2048.jpg)


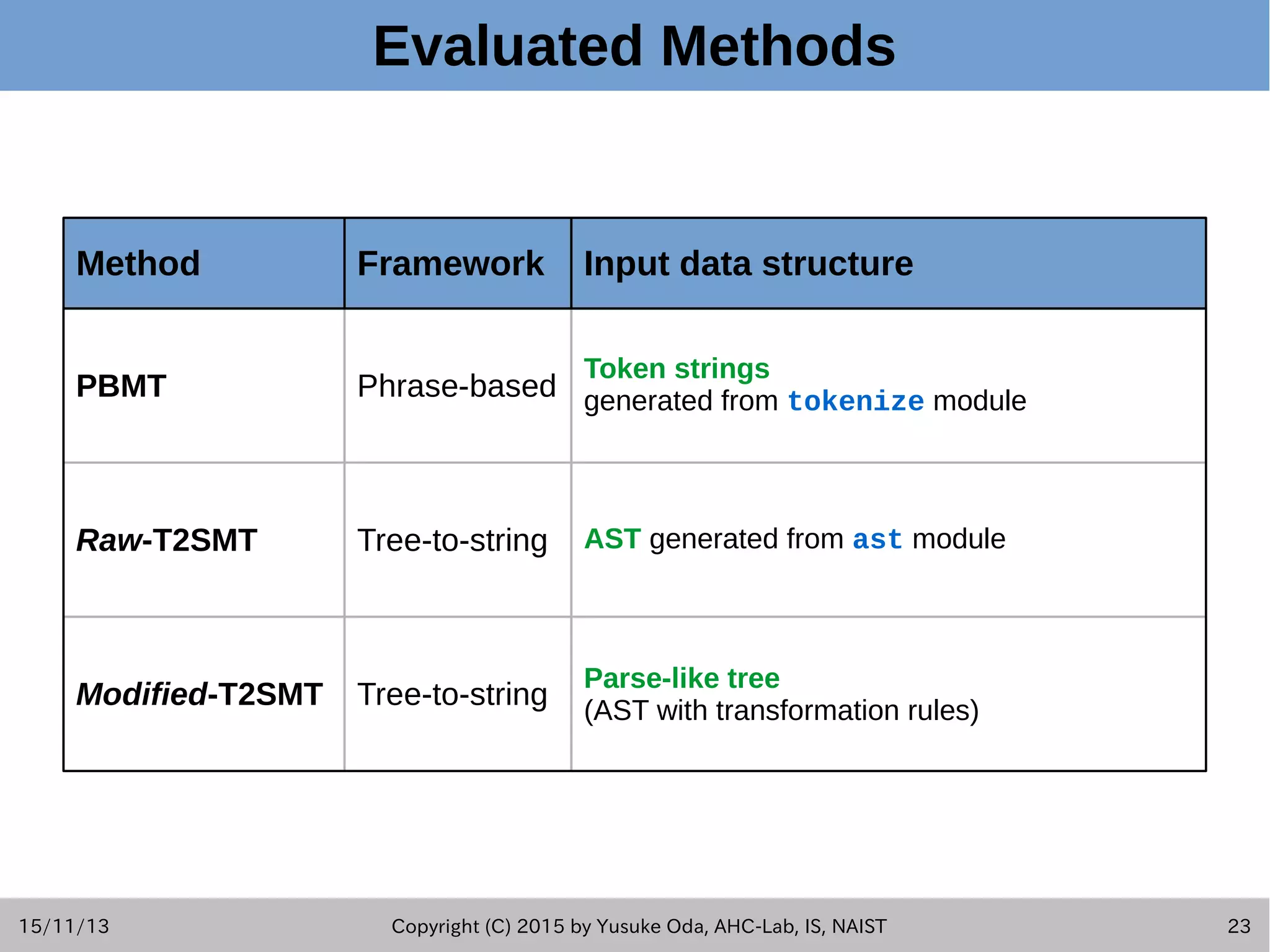
This document summarizes a study on generating pseudo-code from source code using statistical machine translation techniques. The researchers introduced two frameworks: phrase-based machine translation and tree-to-string machine translation. Experiments were conducted on two corpora, with the tree-to-string approach modified to address issues with abstract syntax trees generating the best pseudo-code based on automatic and human evaluations. Generated pseudo-code was shown to help with code understanding tasks compared to source code alone.