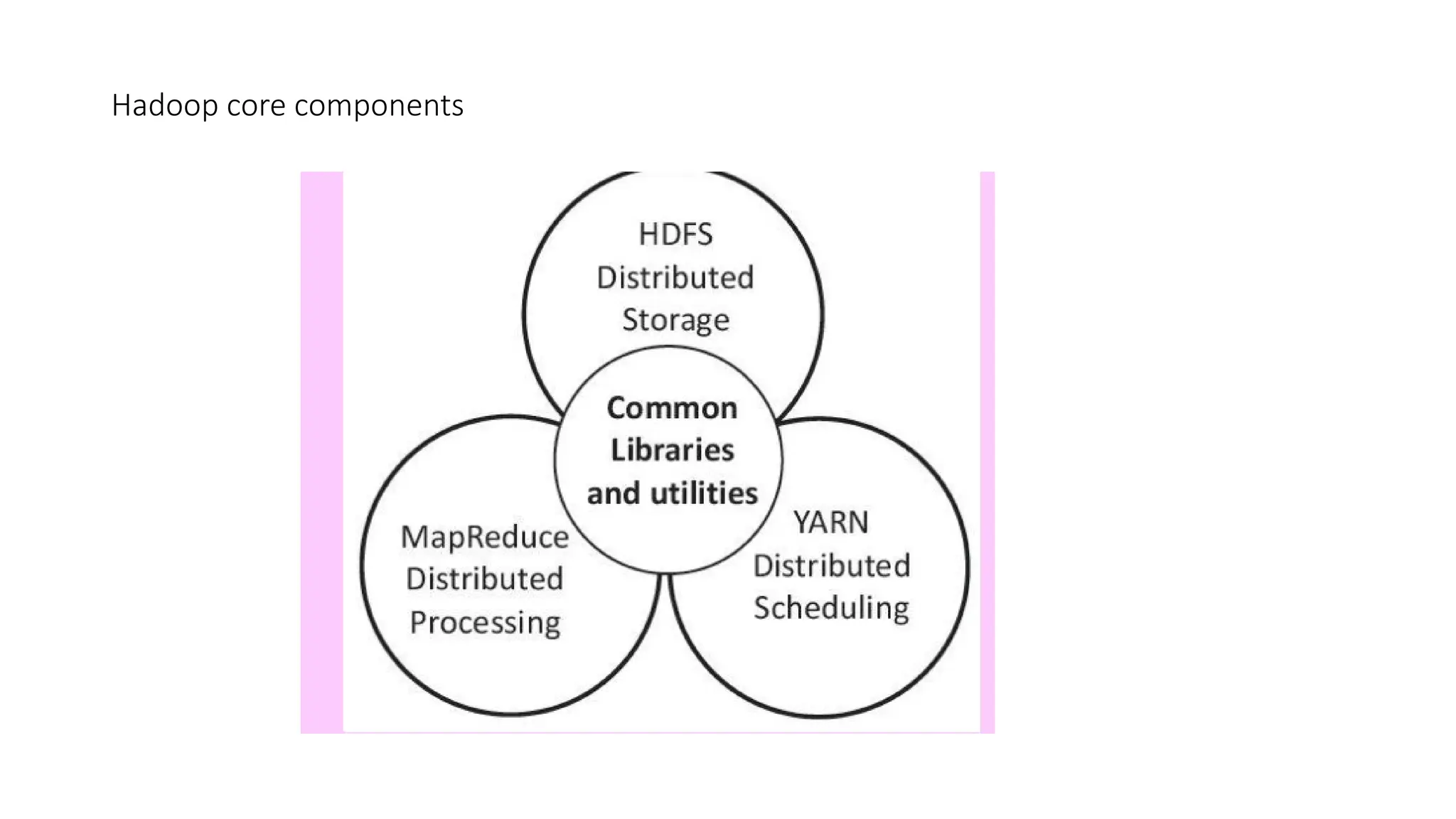
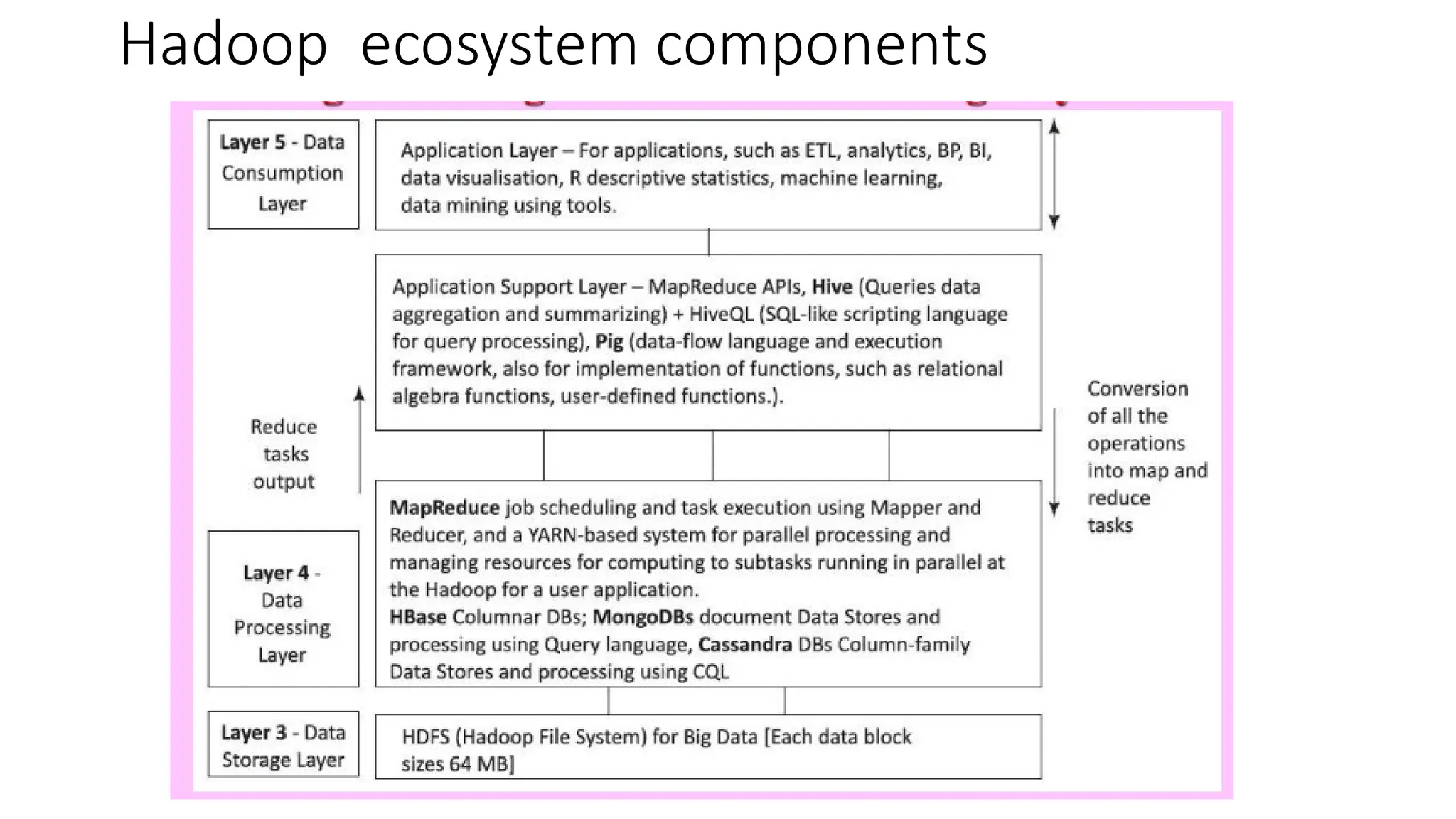
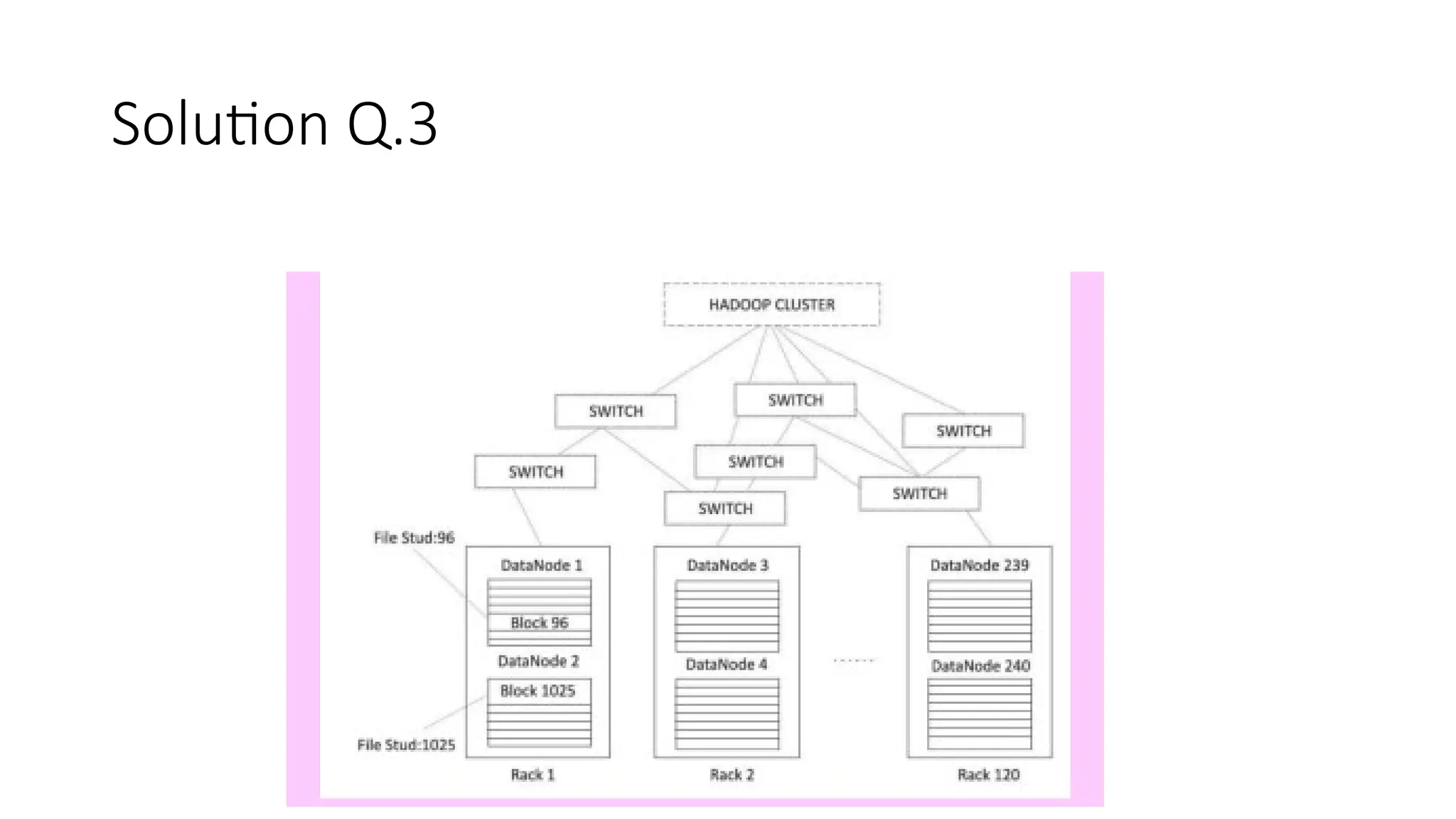
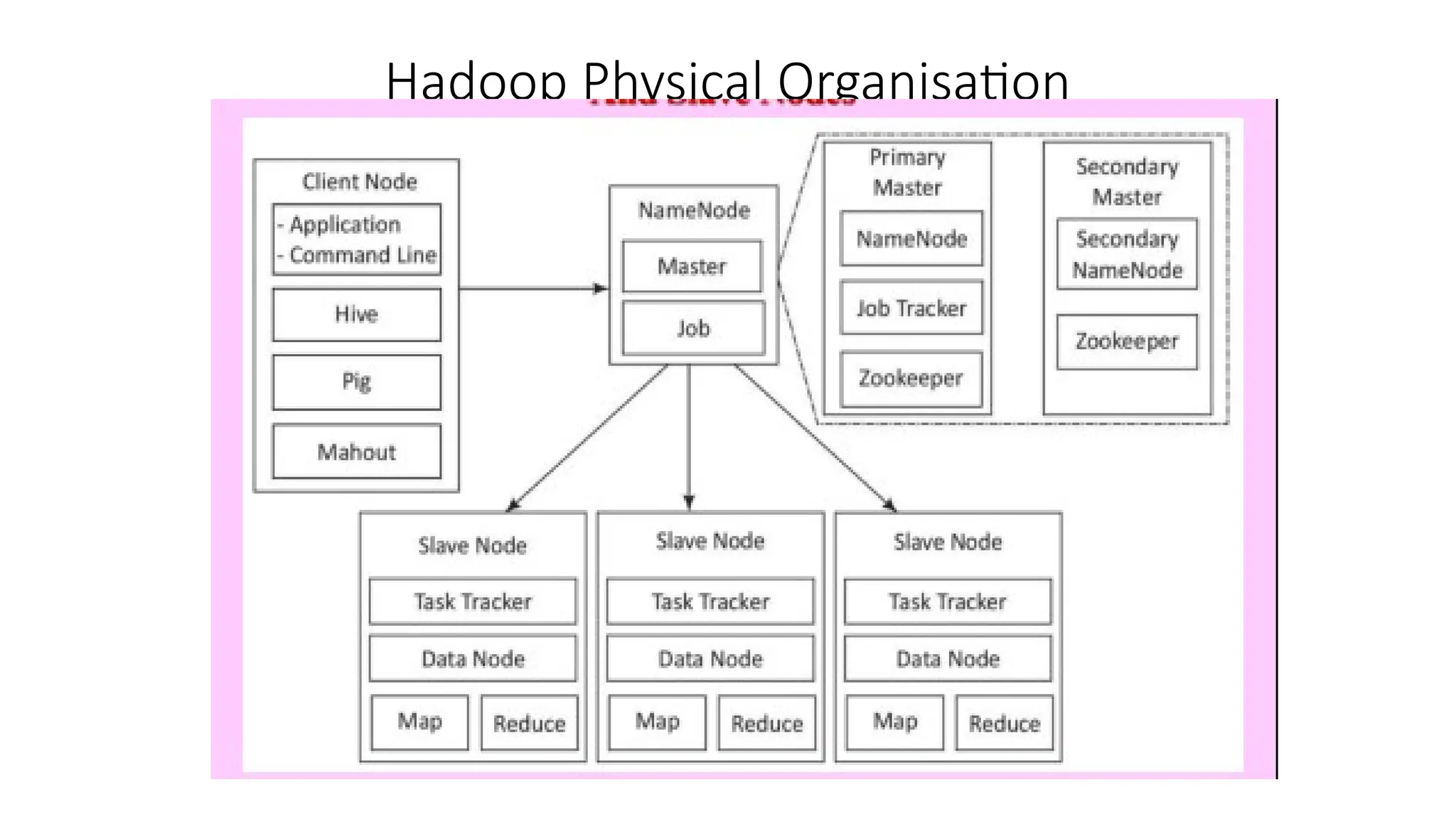
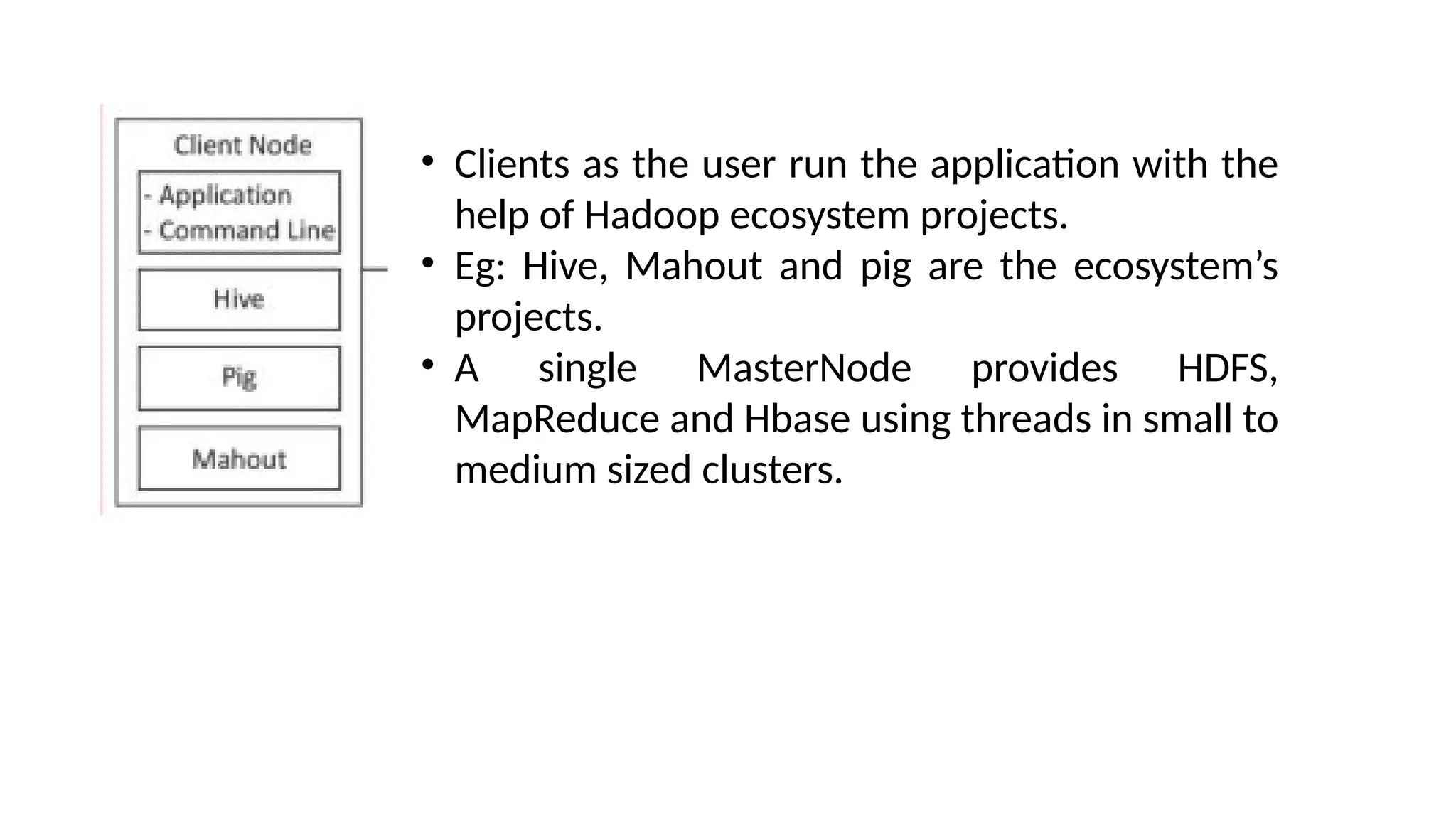
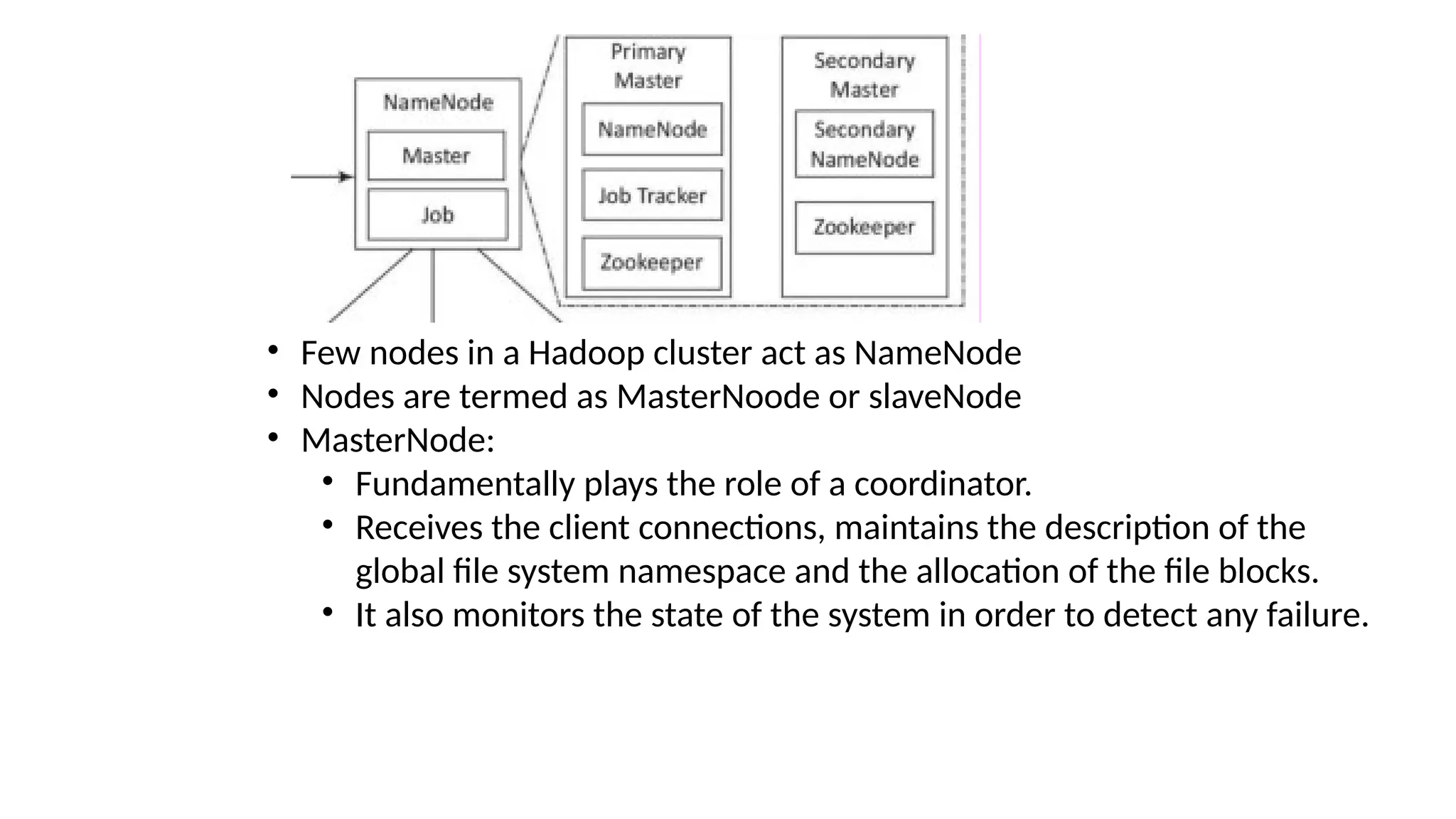
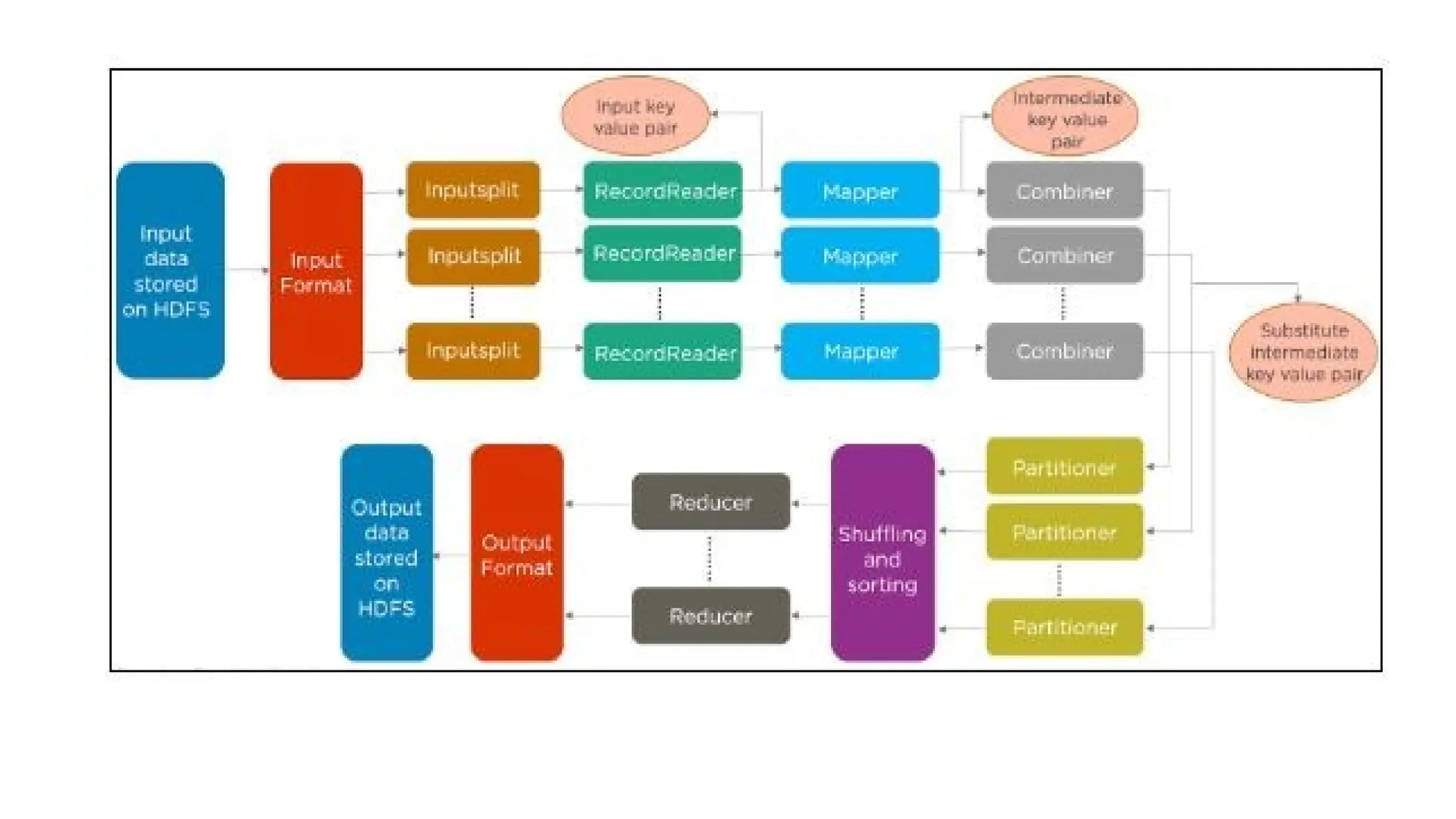
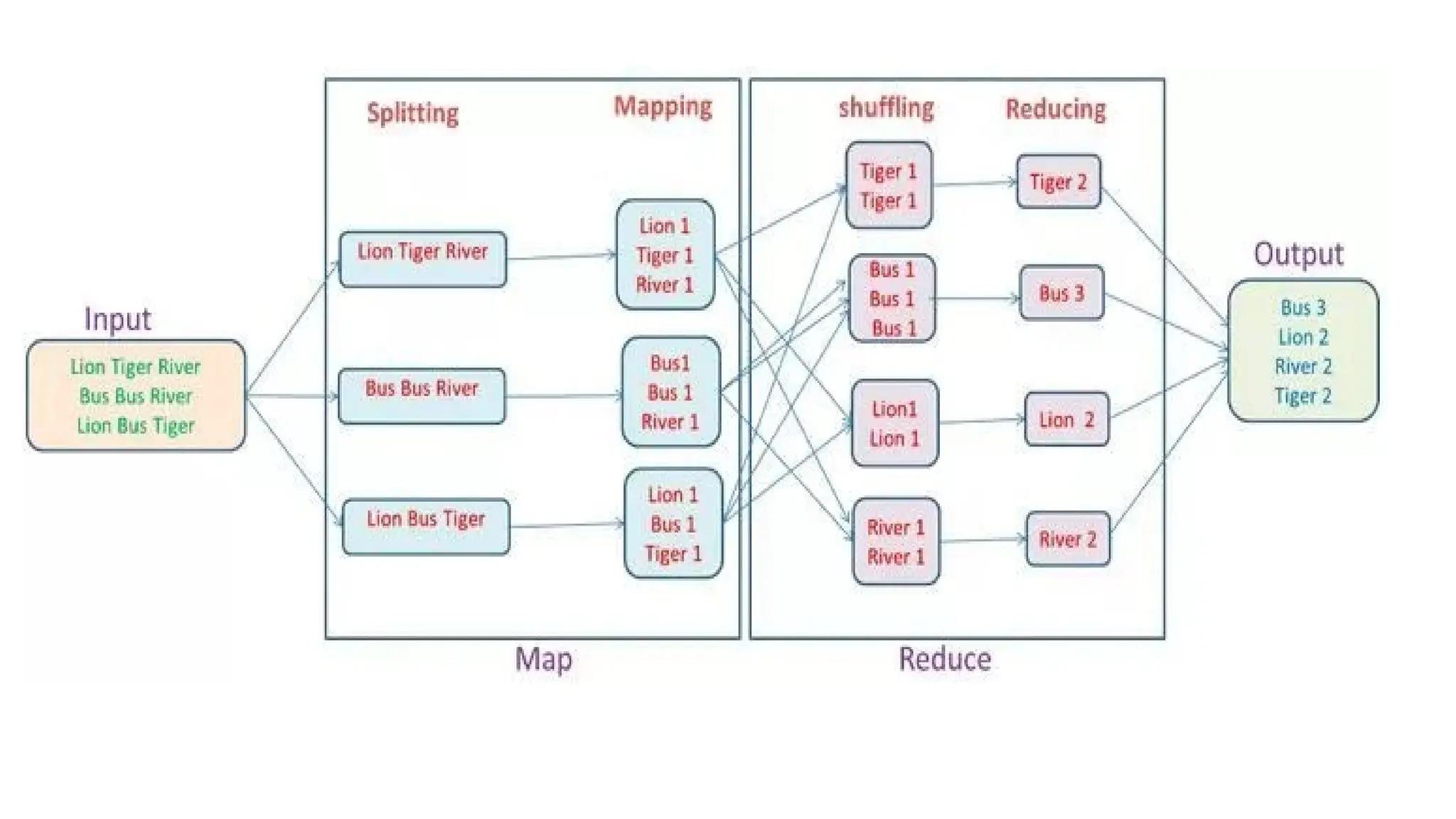
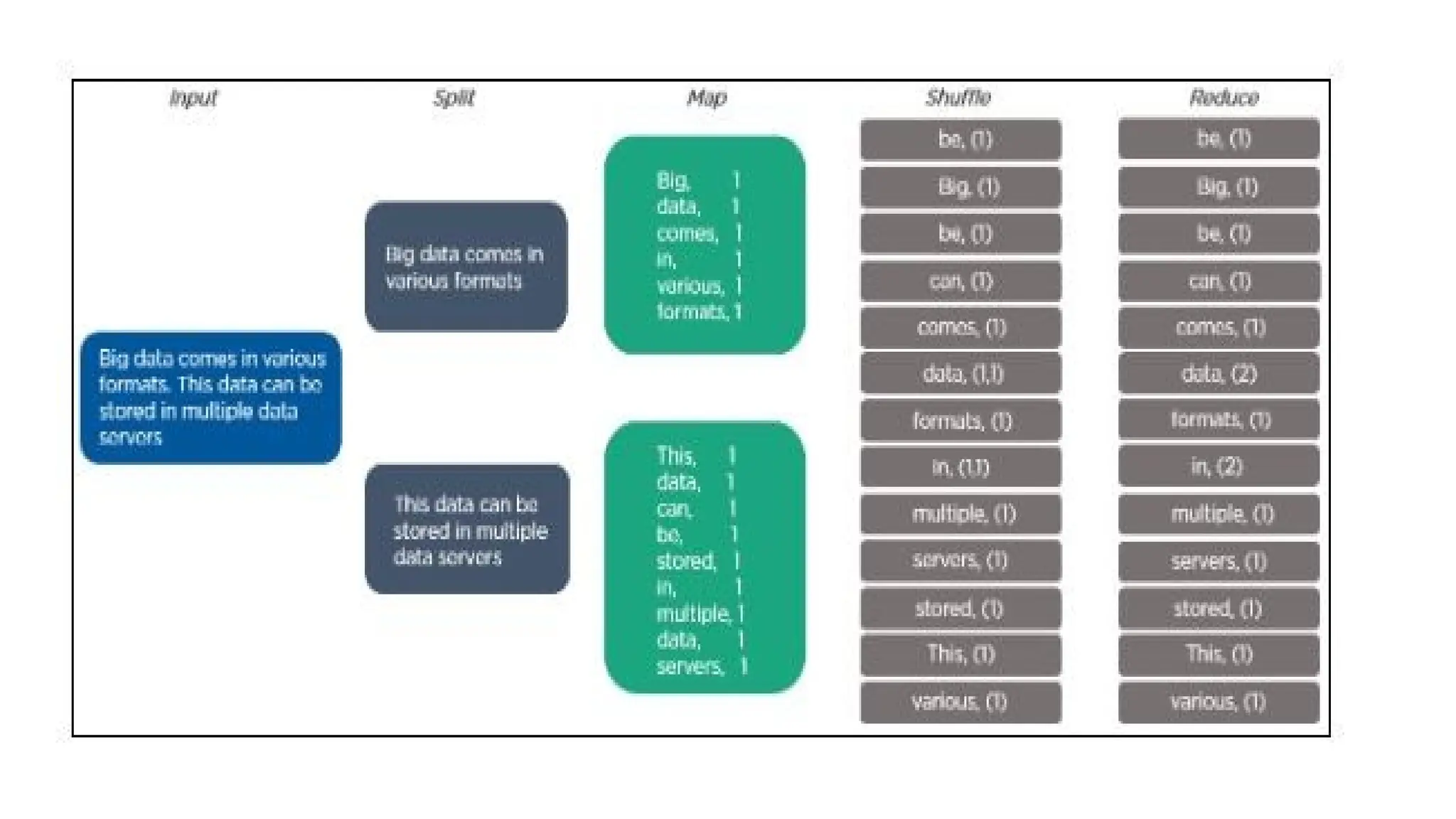
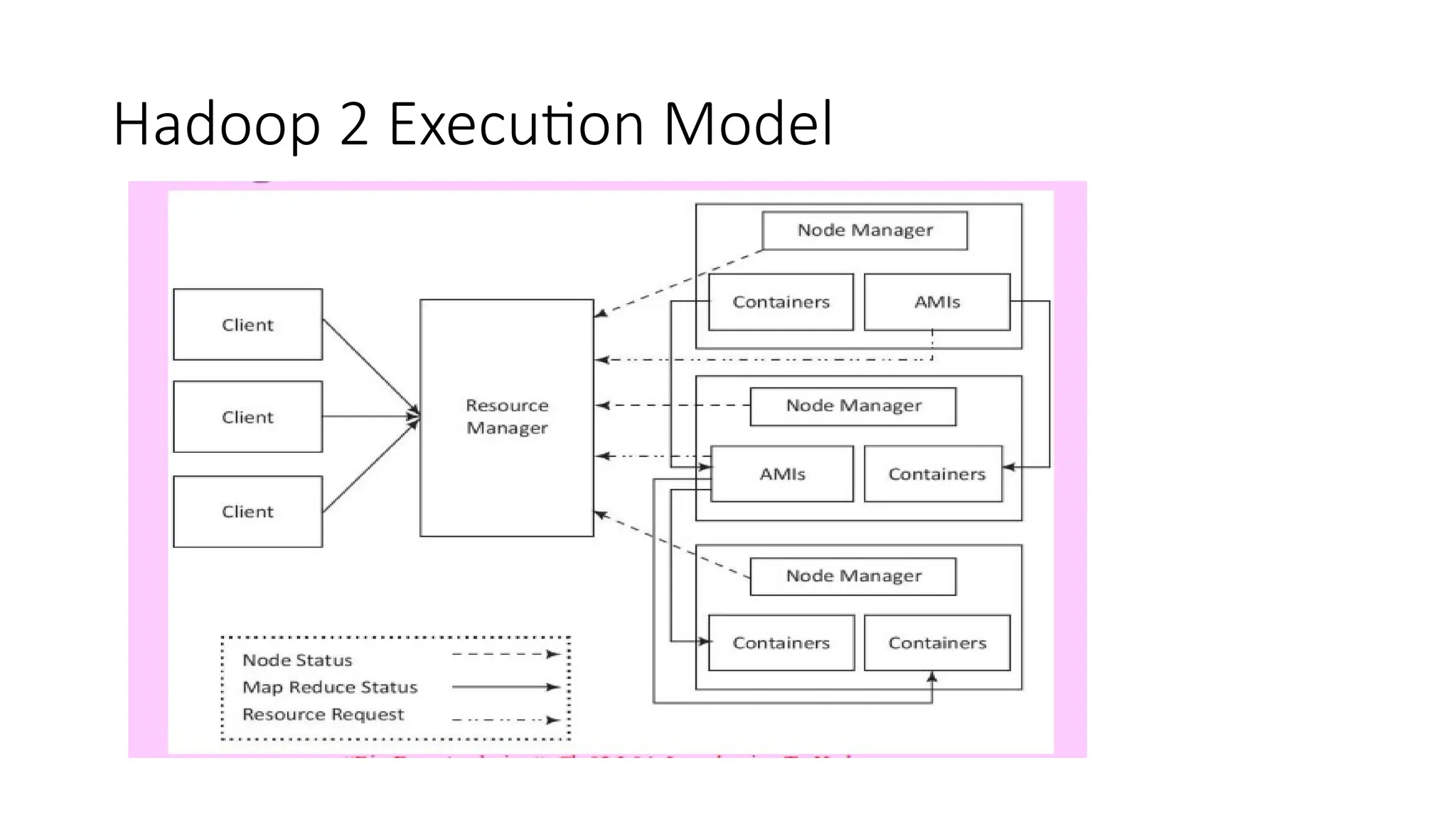
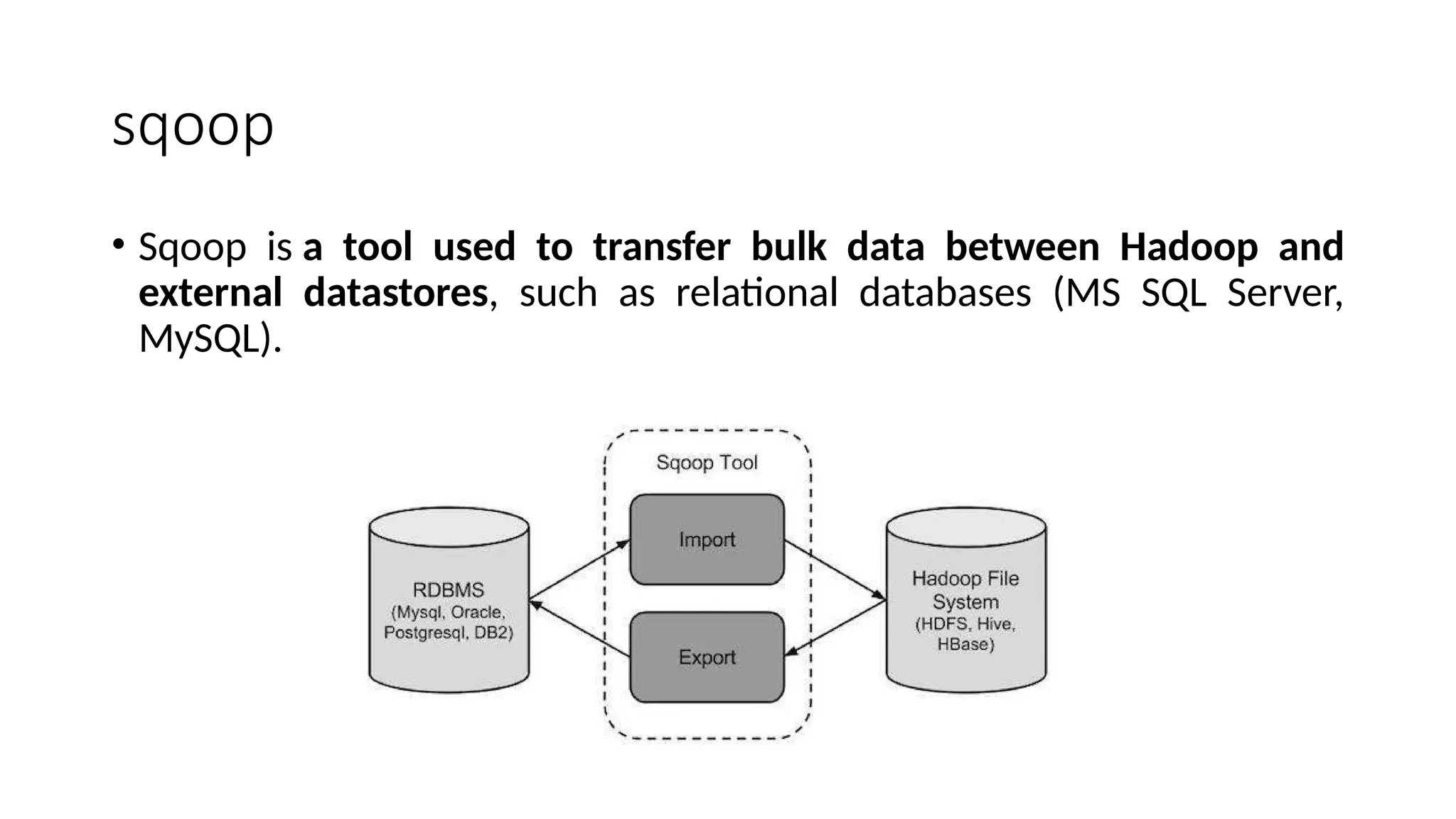
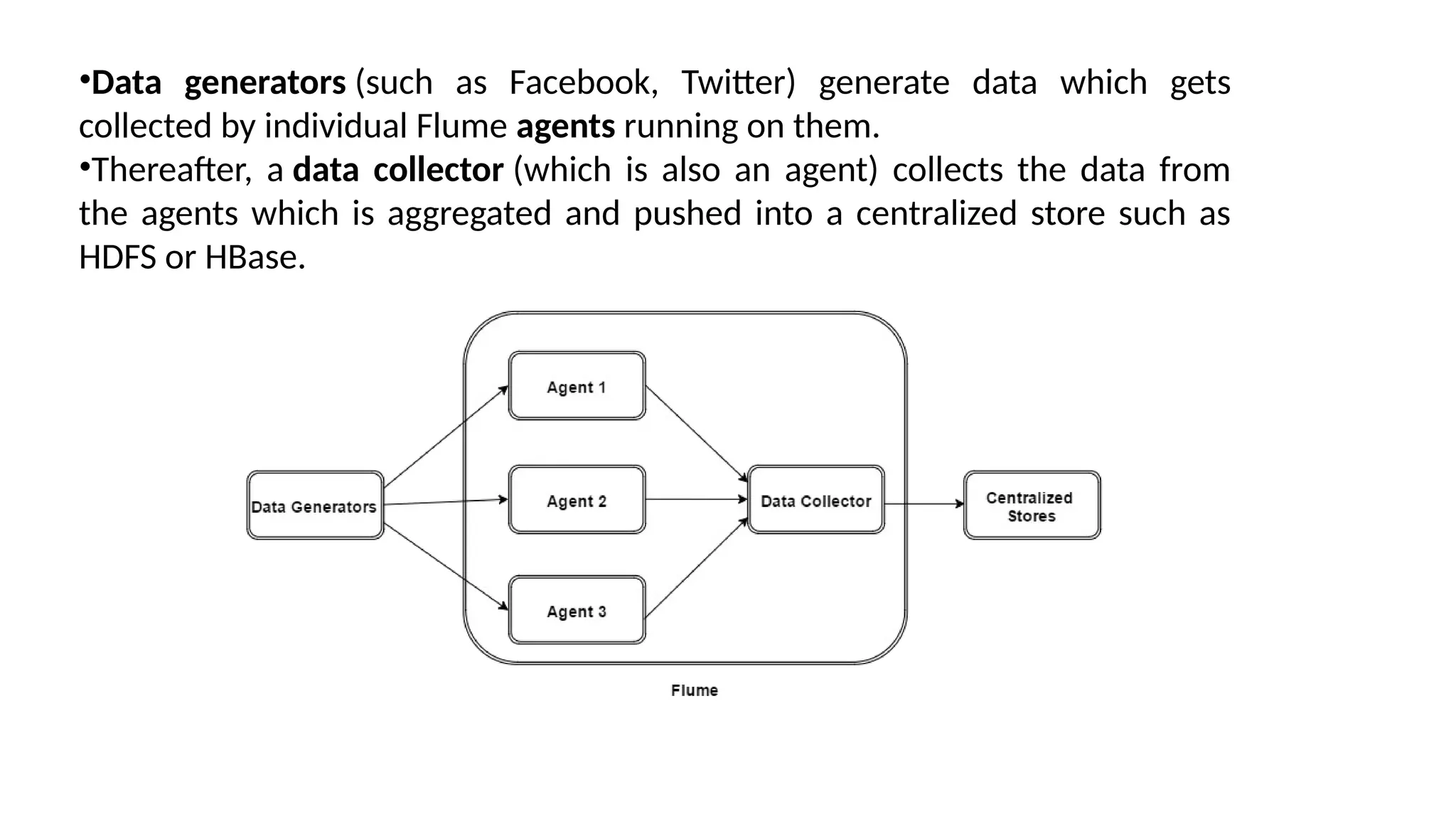
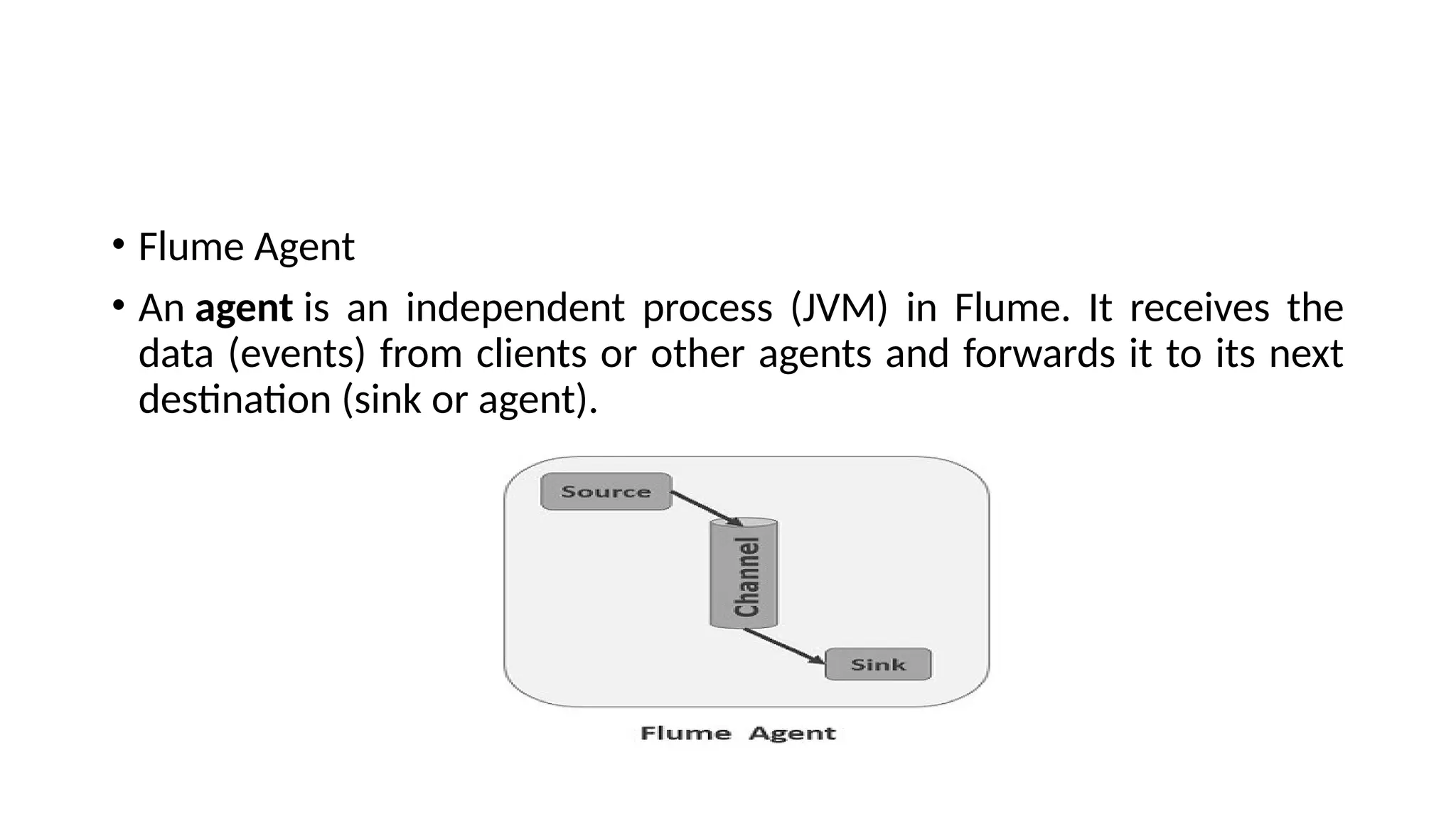
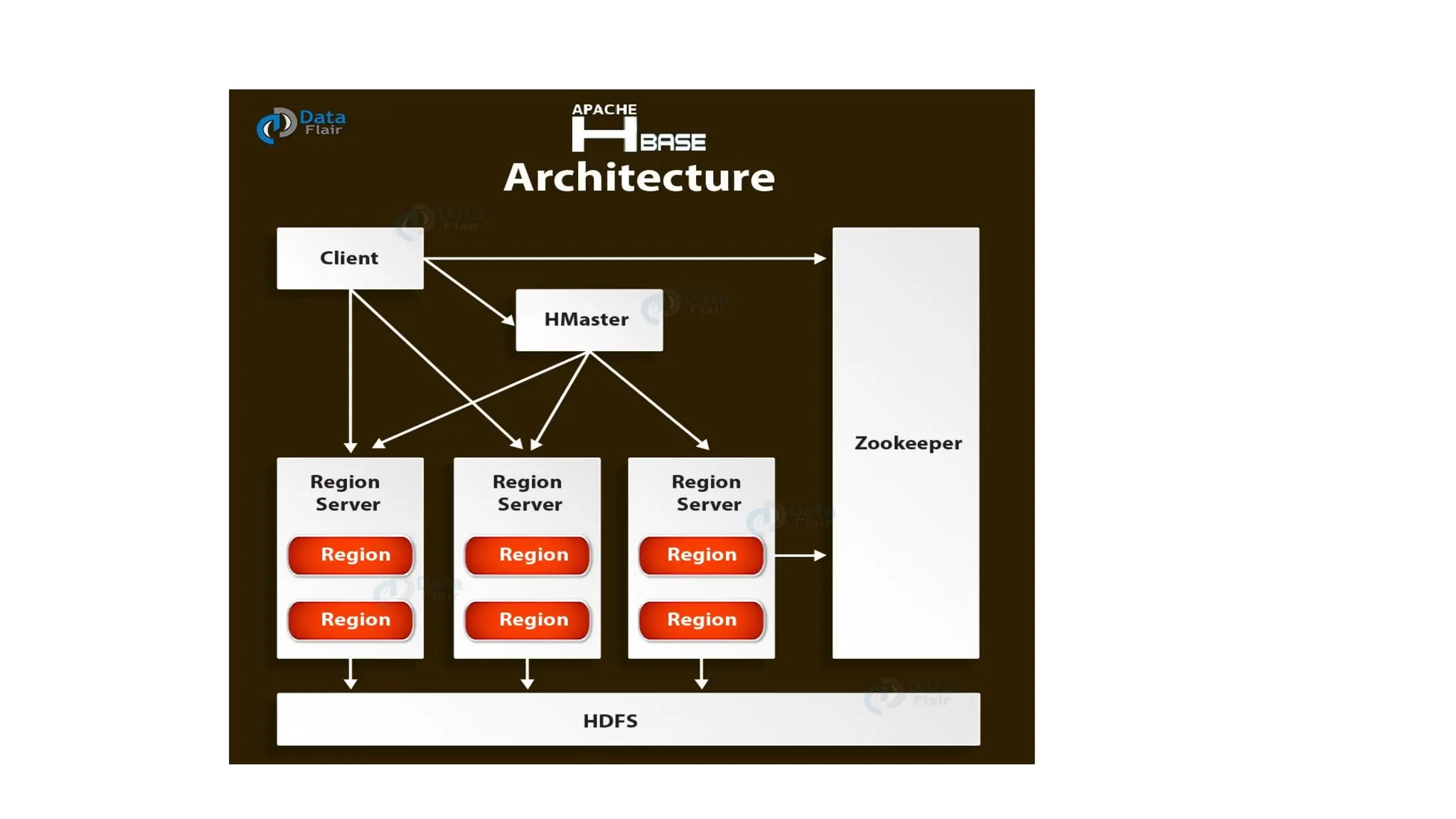
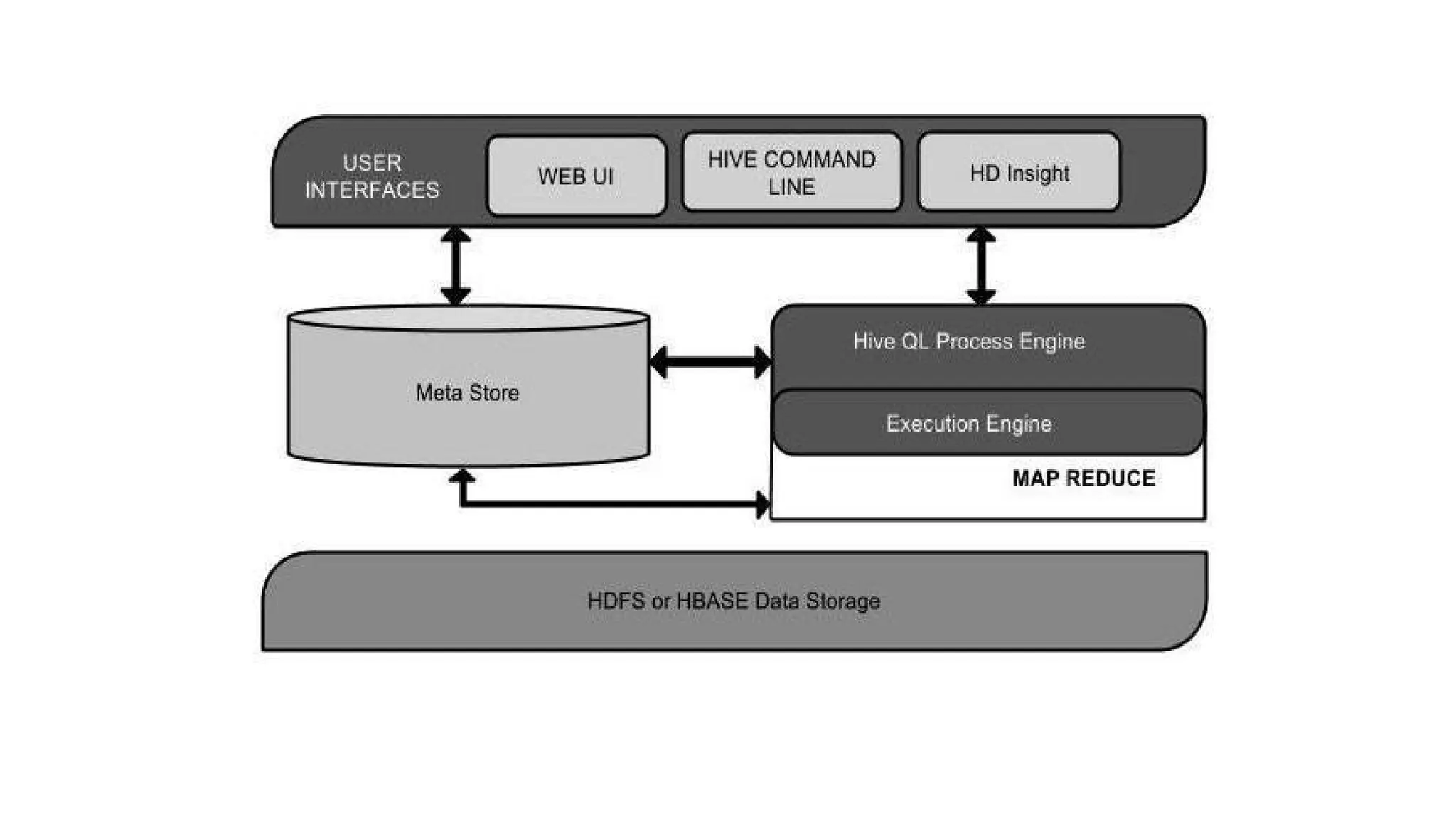
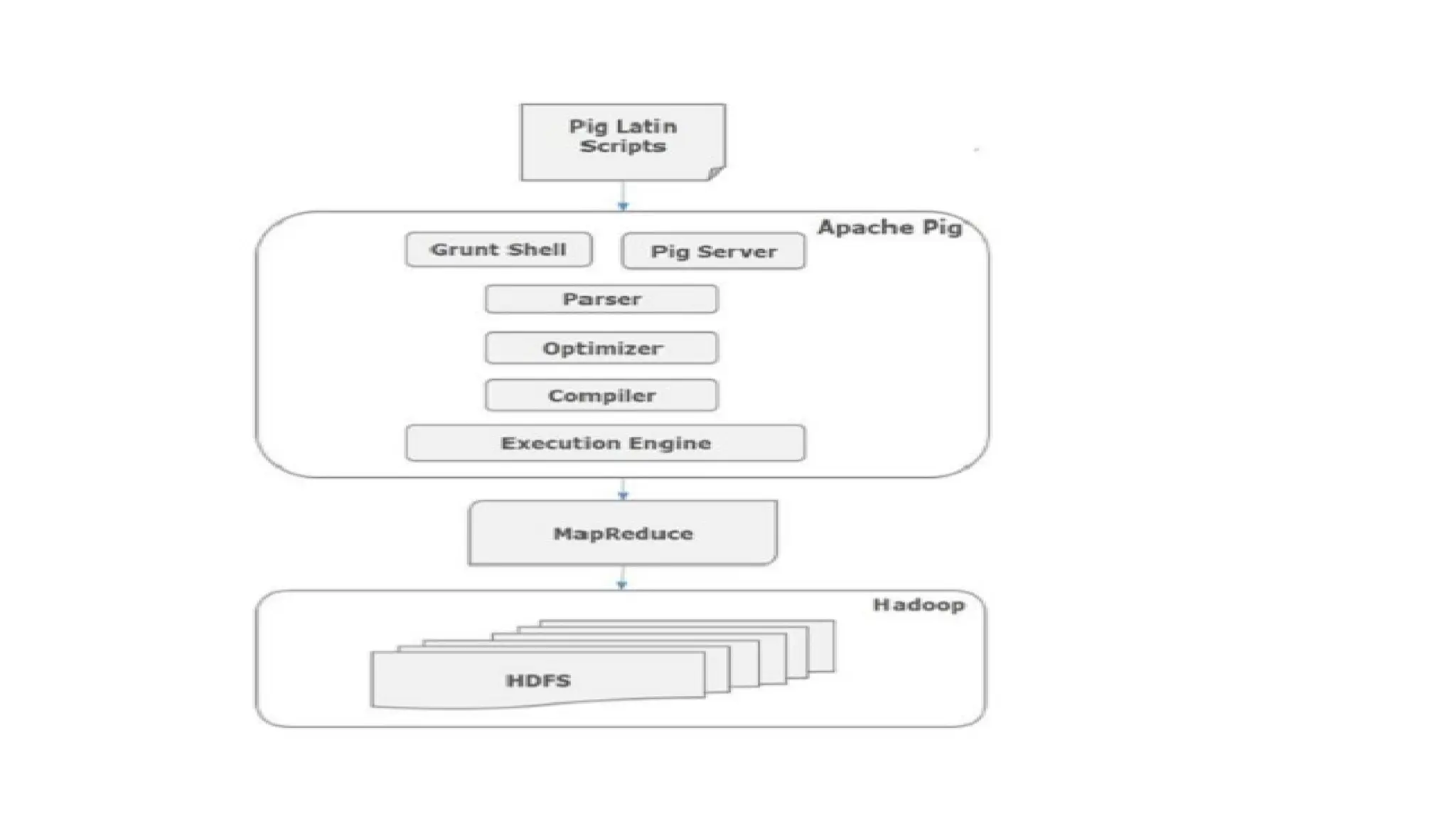
Hadoop components are written in Java with part of native code in c. The command line utilities are written in shell scripts. Hadoop is a computing environment in which input data stores, processes and store the results. The complete system consists of a scalable distributed set of clusters. Infrastructure consists of cloud for clusters. Hadoop platform provides a low cost Big data platform, which is open source and uses cloud services.