Download as PDF, PPTX




















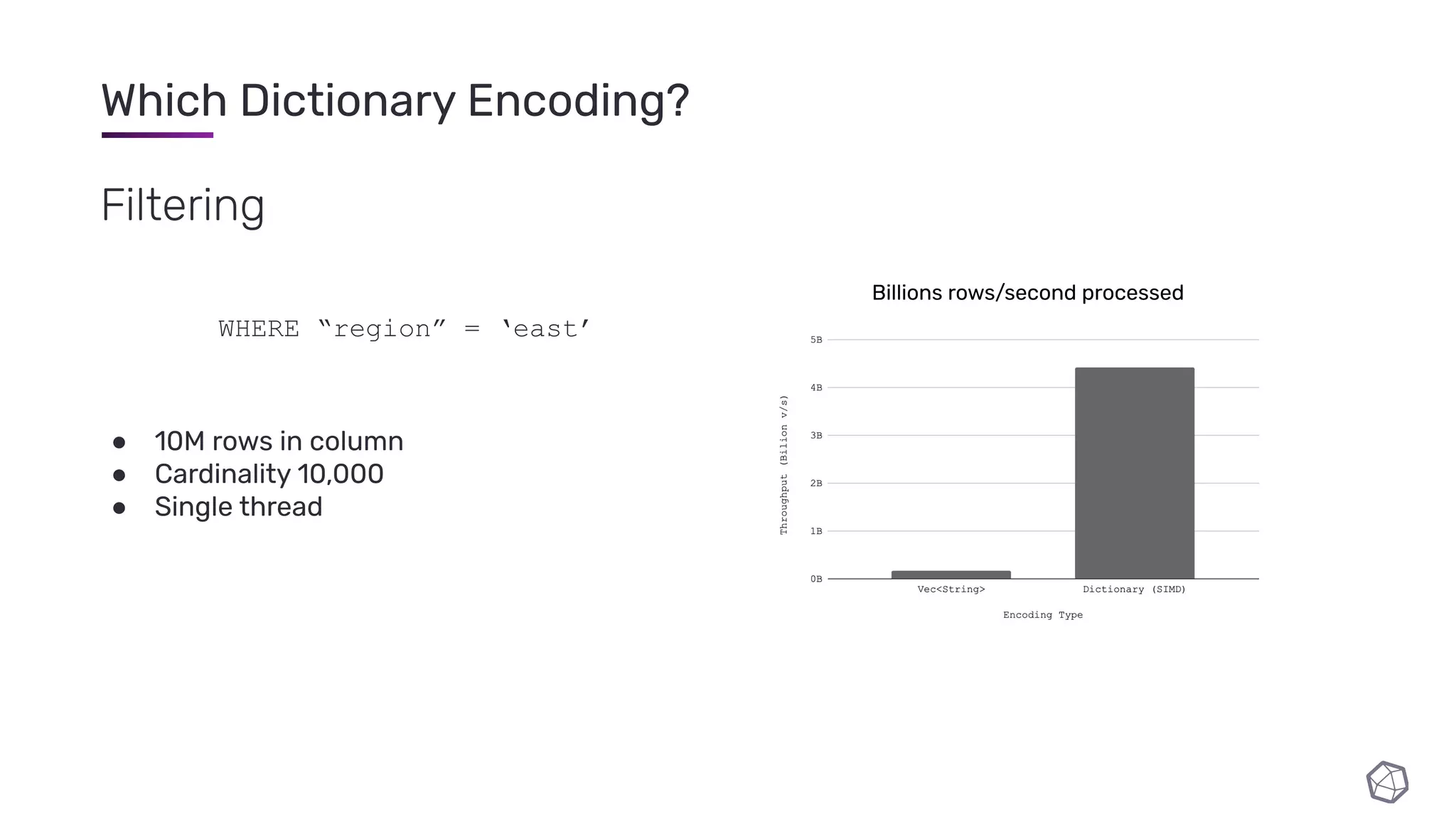
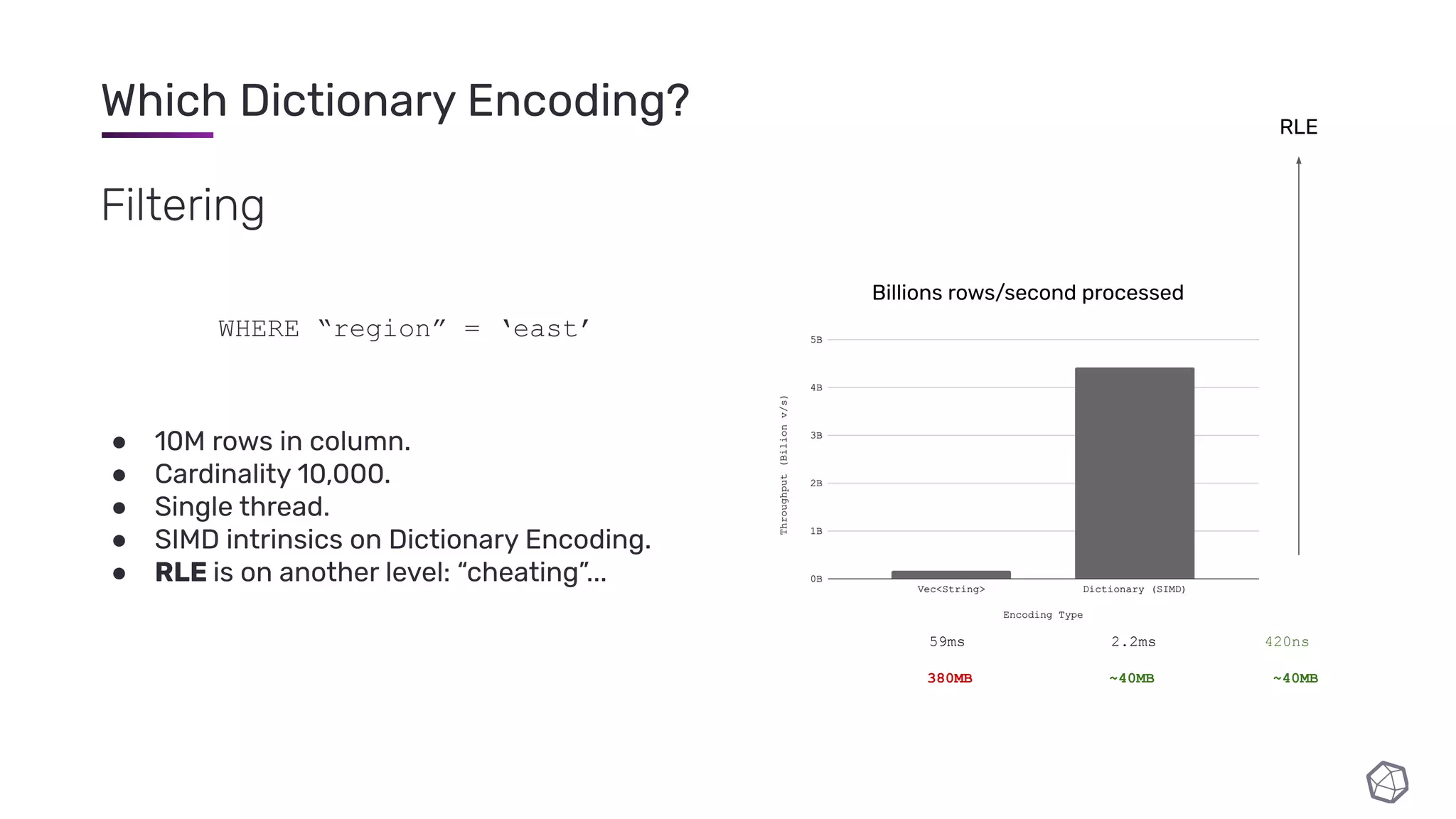
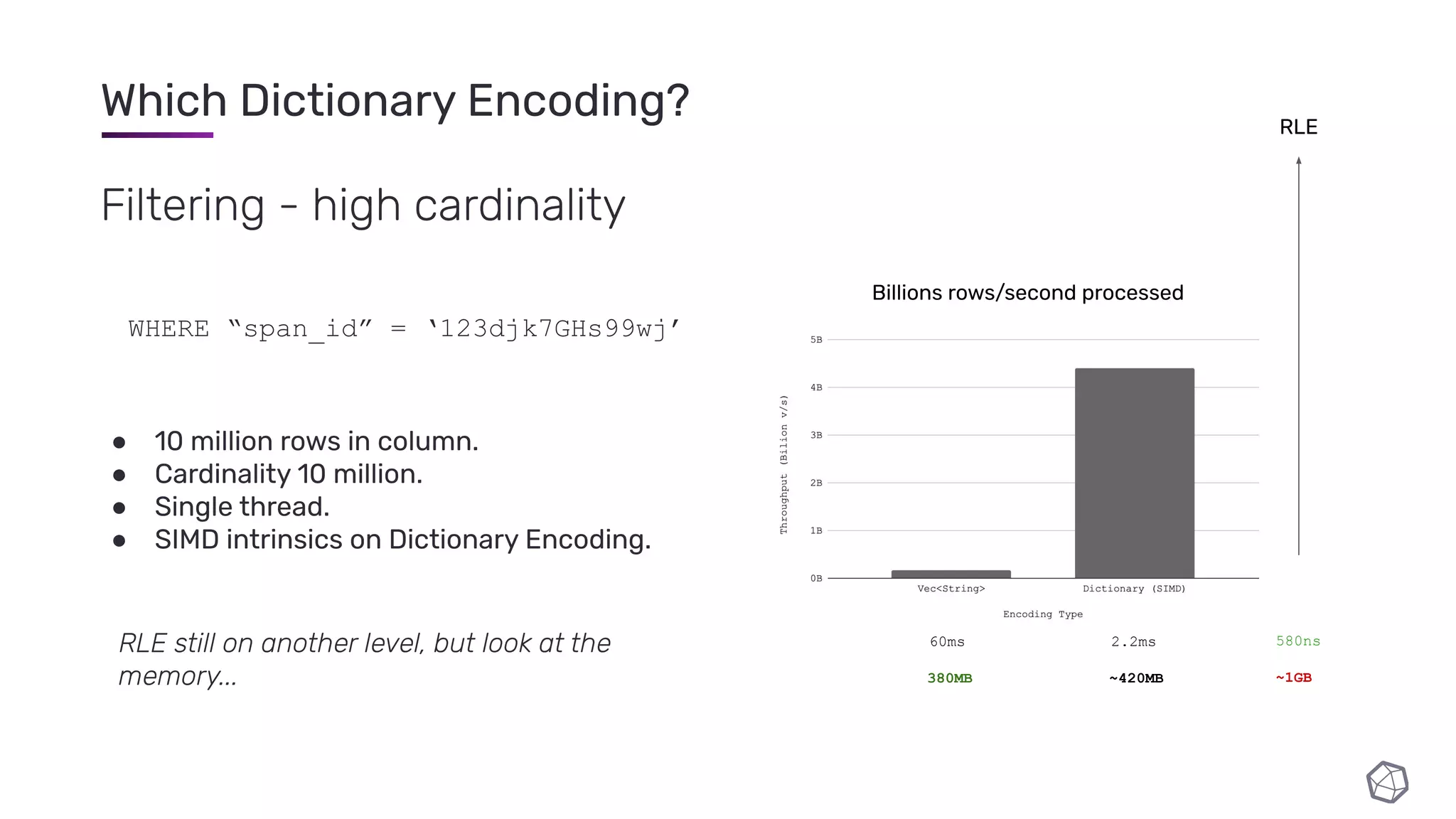
![Which Dictionary Encoding? “I need rows [2, 33, 55, 111, 3343]” 10,000,000 row column Encoding Cardinality 10K (materialise 1000 rows near end) Cardinality 10M (materialise 1 row near end) Vec<String> Dictionary μ RLE μ](https://image.slidesharecdn.com/slides-210210182208/75/InfluxDB-IOx-Tech-Talks-Intro-to-the-InfluxDB-IOx-Read-Buffer-A-Read-Optimized-In-Memory-Query-Execution-Engine-44-2048.jpg)

![Numerical Column Encodings Supported Logical types: i64, u64, f64 {u8, i8,.., u64, i64}* &[i64]: (48 B) [123, 198, 1, 33, 133, 224] ➠ &[u8]: (6 B) [..] &[i64]: (48 B) [-18, 2, 0, 220, 2, 26] ➠ &[i16]: (12 B) [..]](https://image.slidesharecdn.com/slides-210210182208/75/InfluxDB-IOx-Tech-Talks-Intro-to-the-InfluxDB-IOx-Read-Buffer-A-Read-Optimized-In-Memory-Query-Execution-Engine-46-2048.jpg)


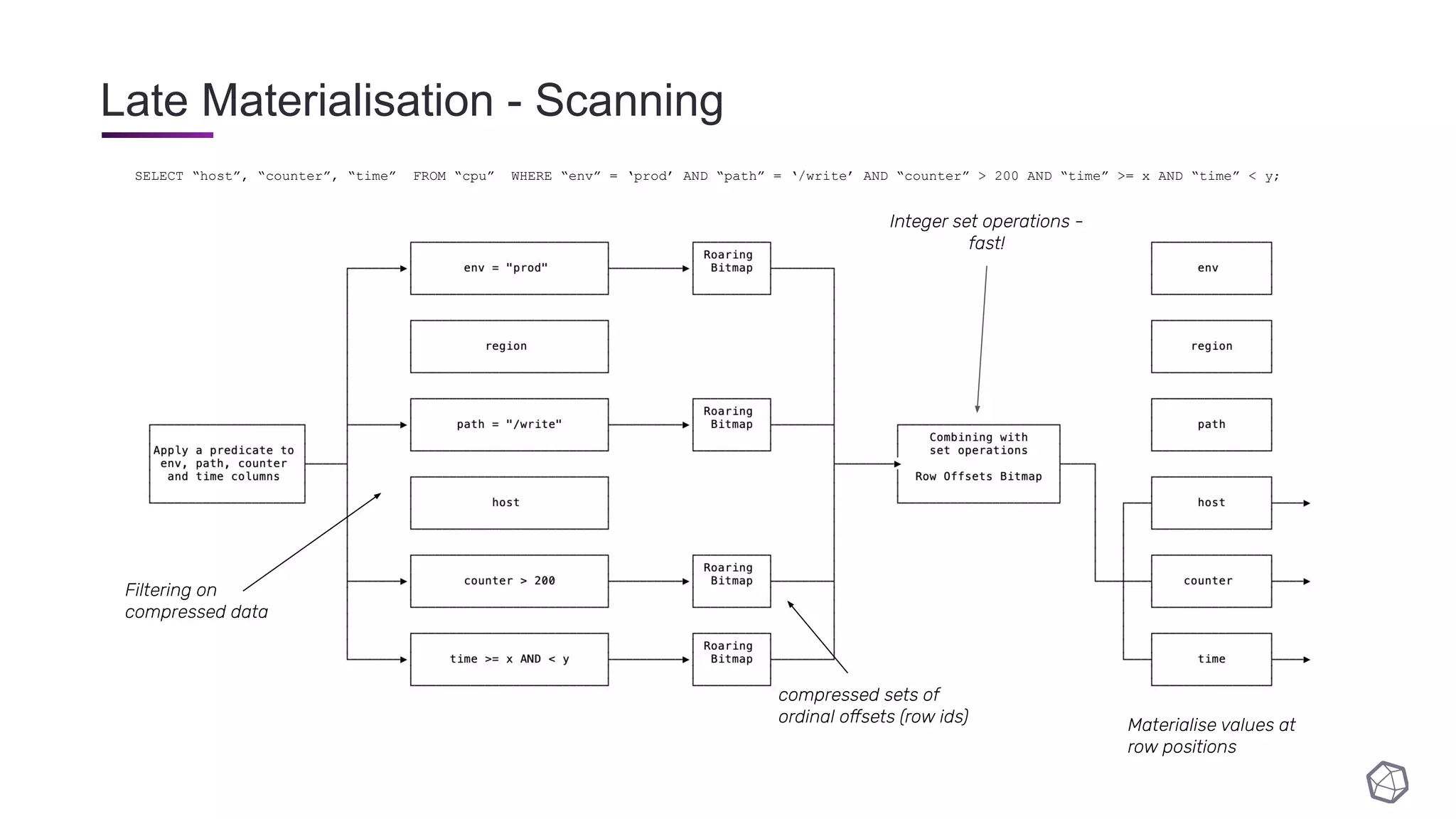
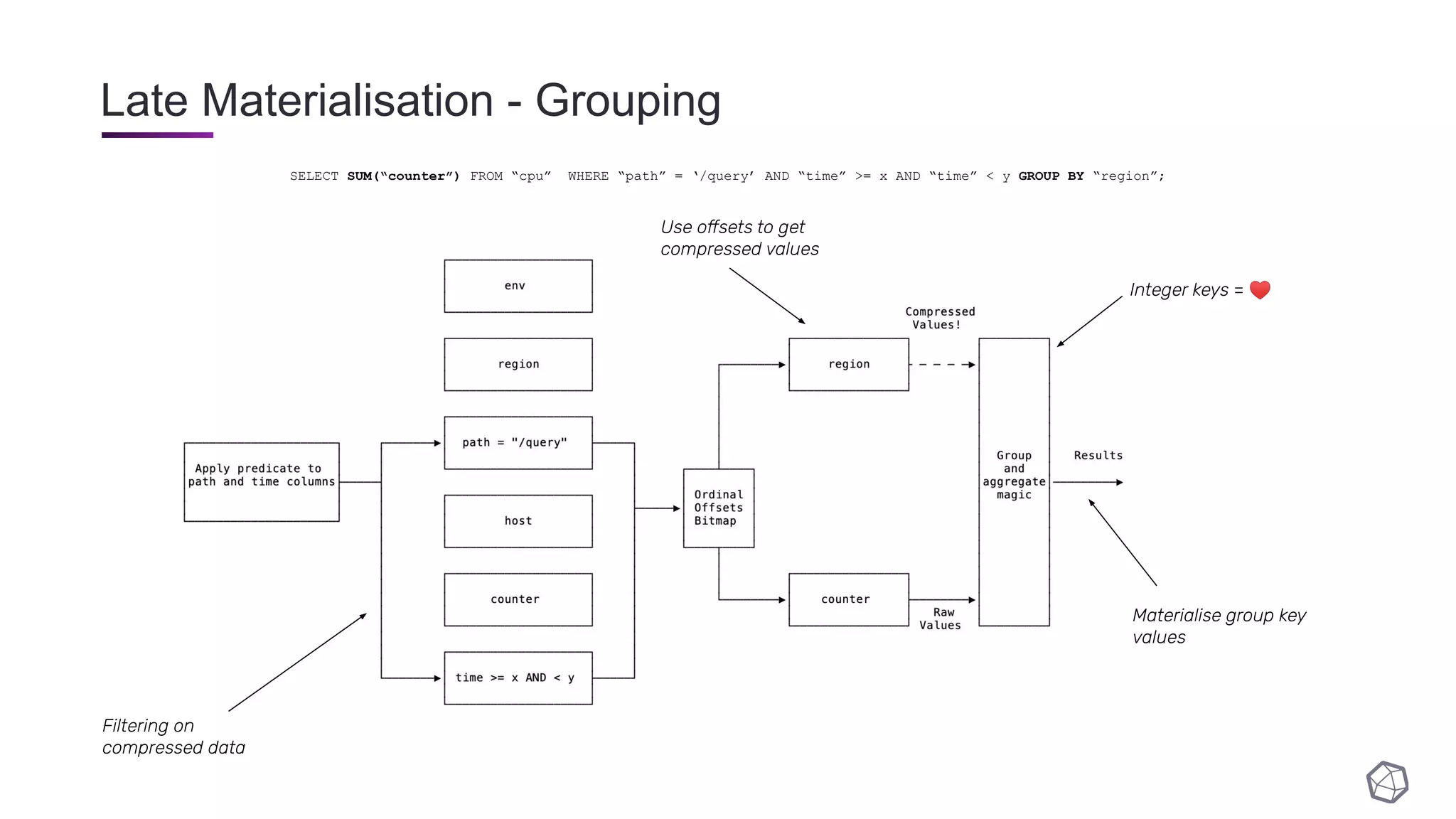


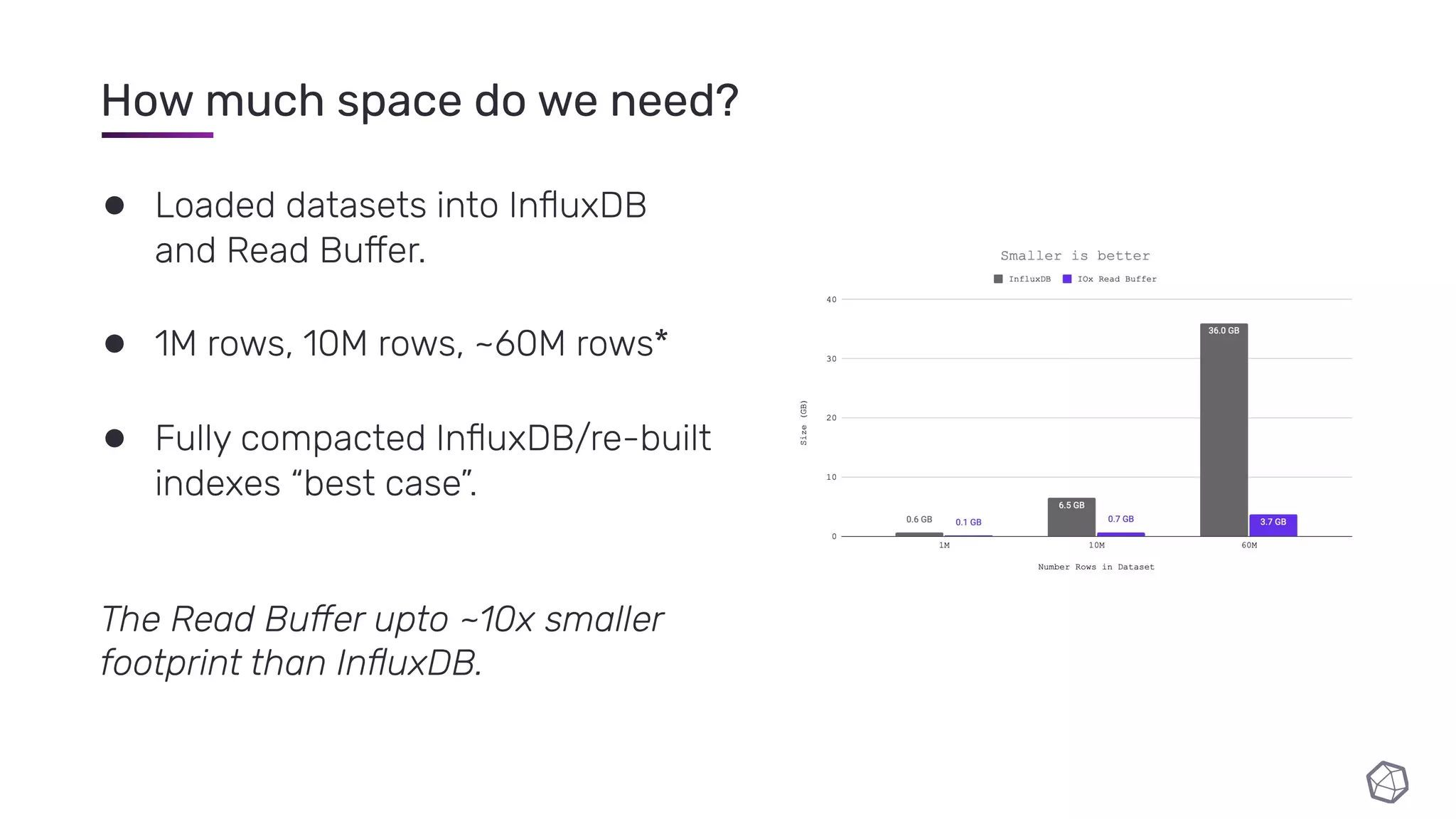


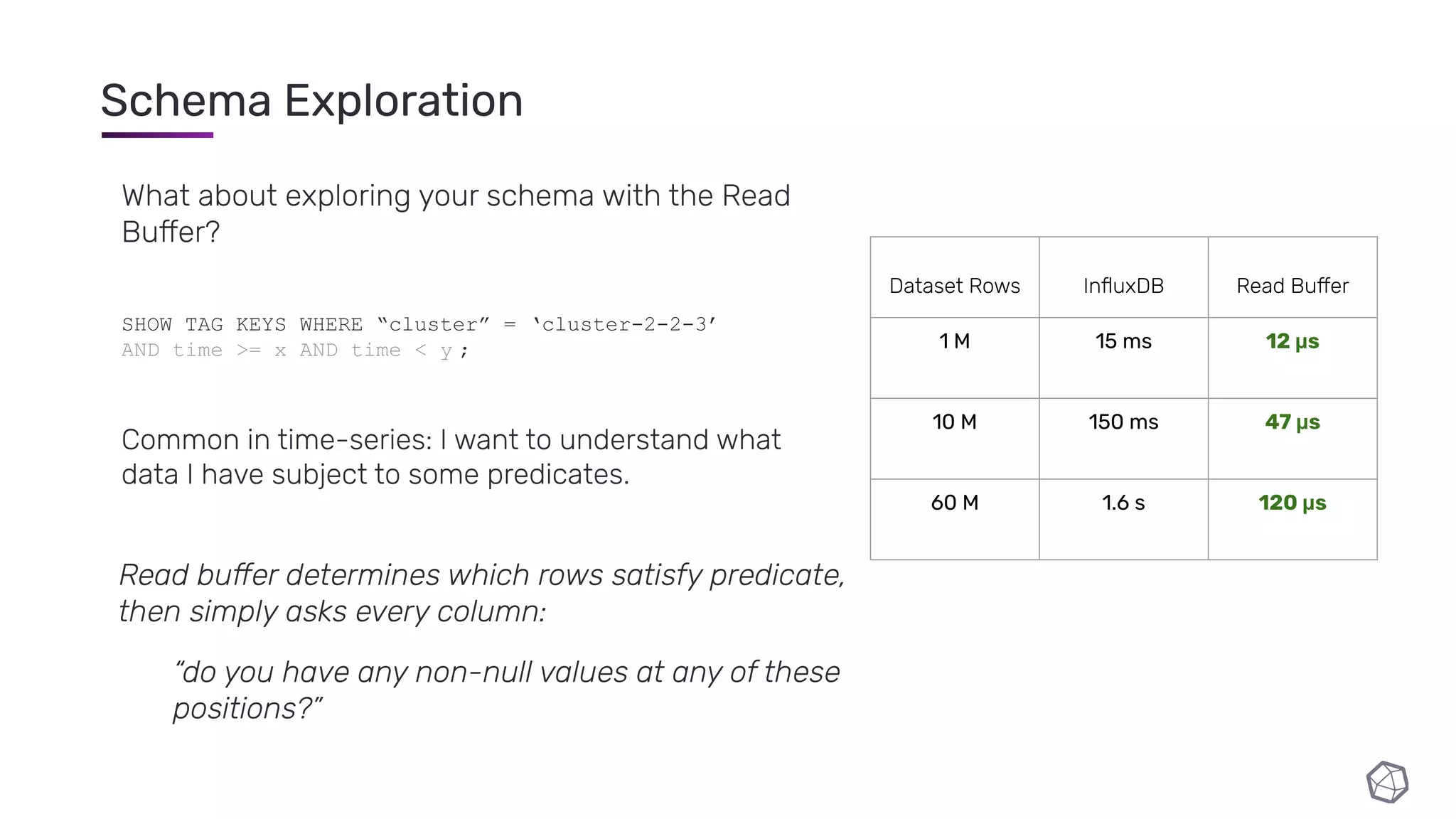











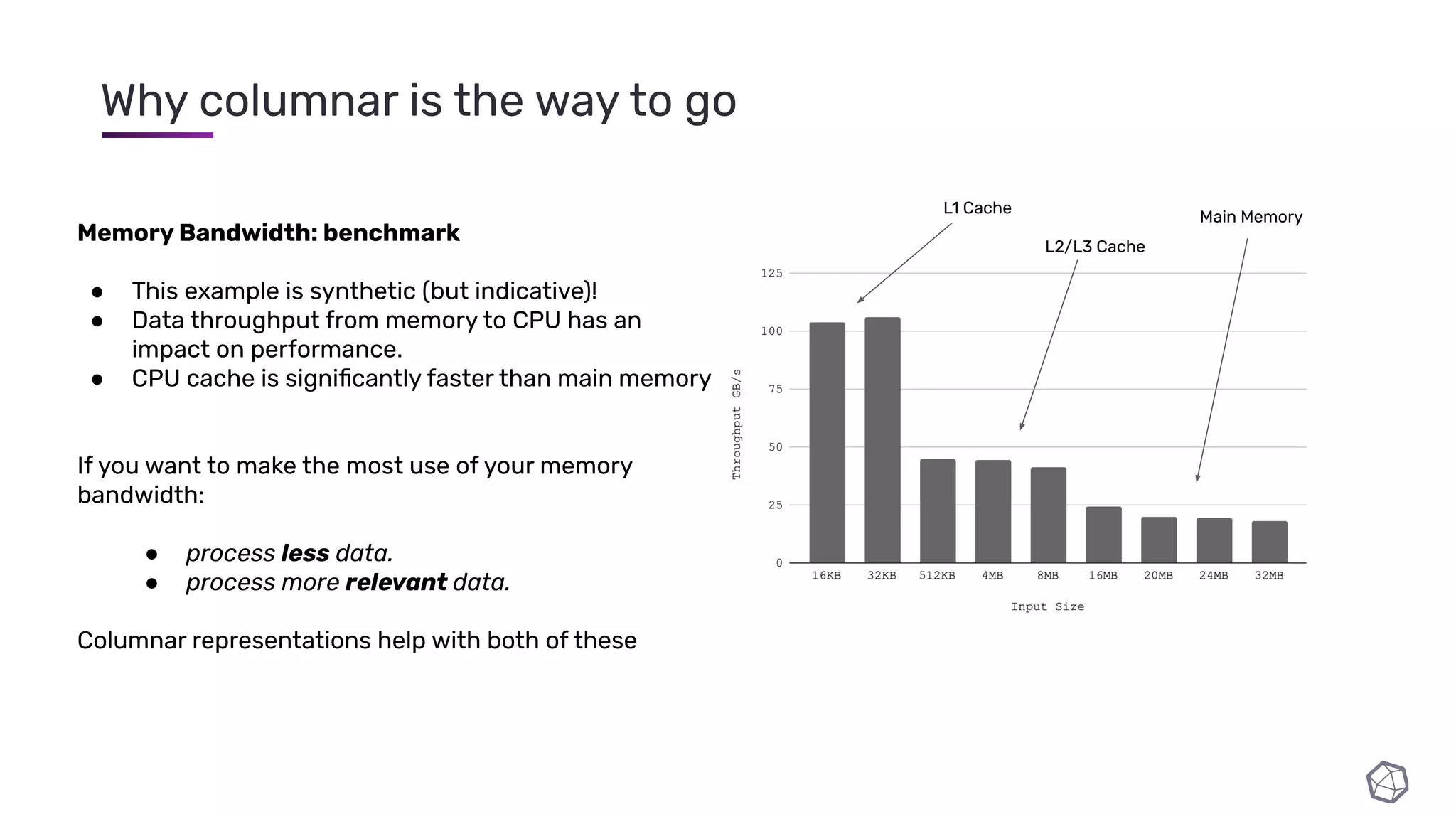
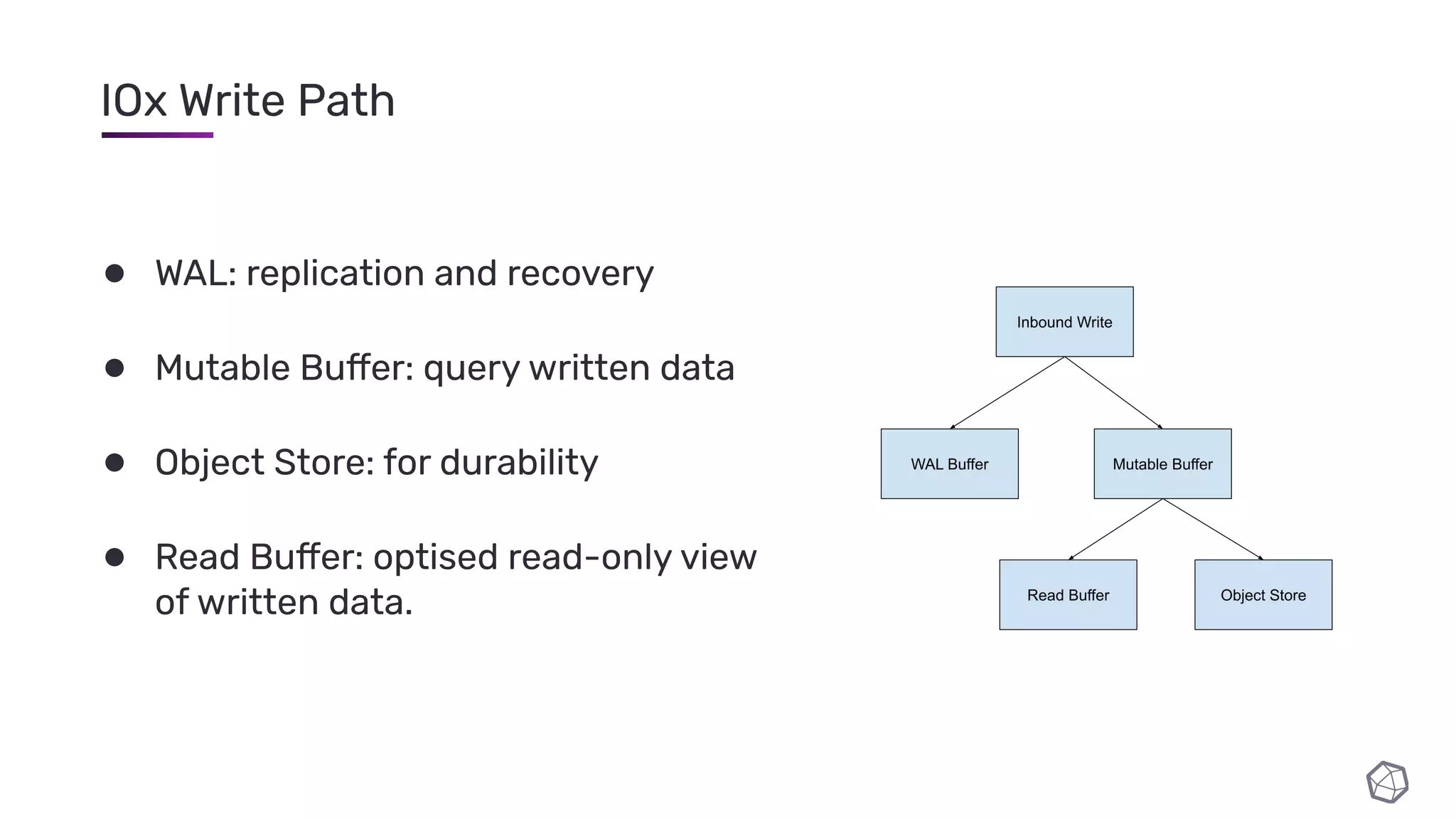
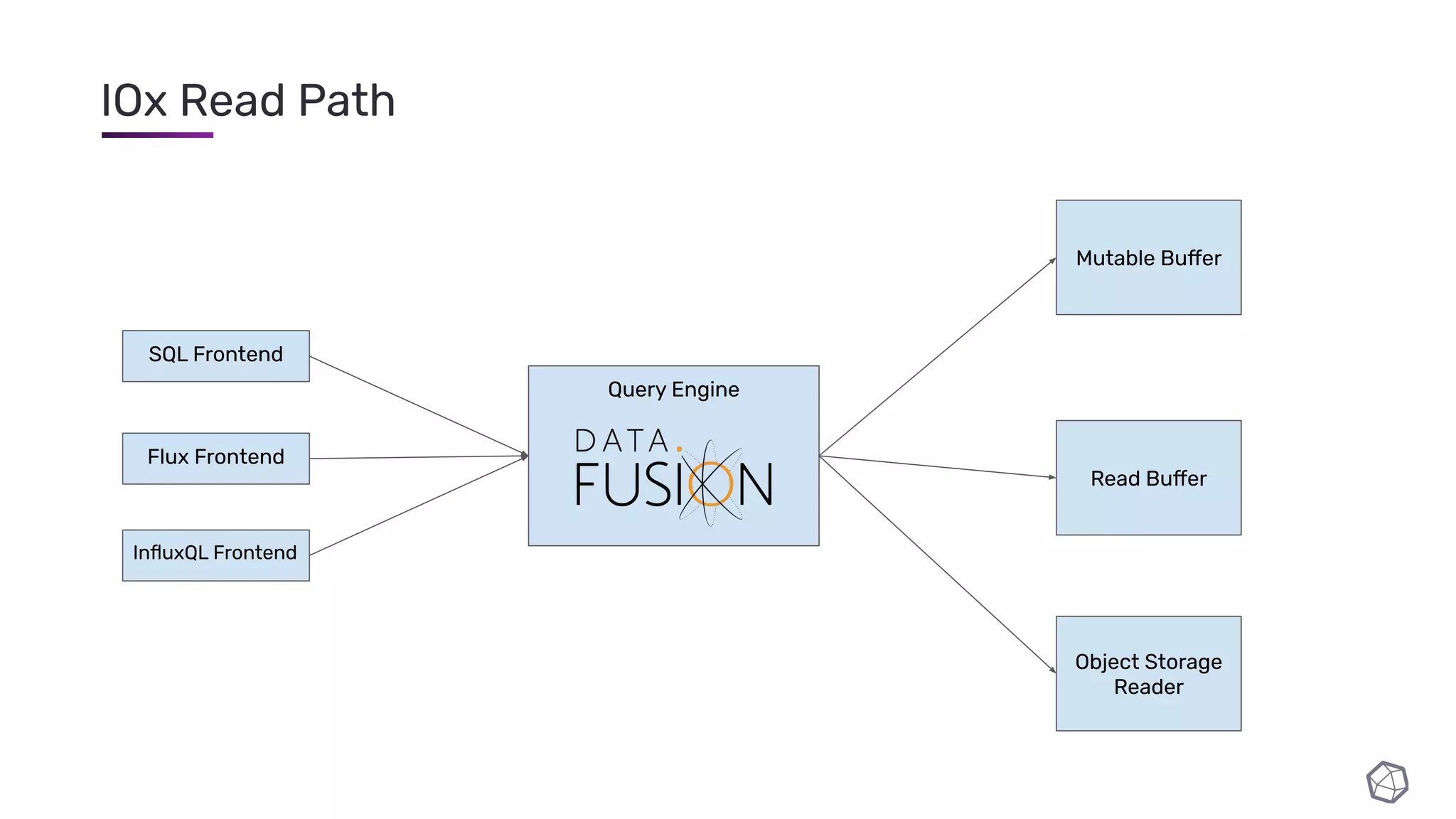
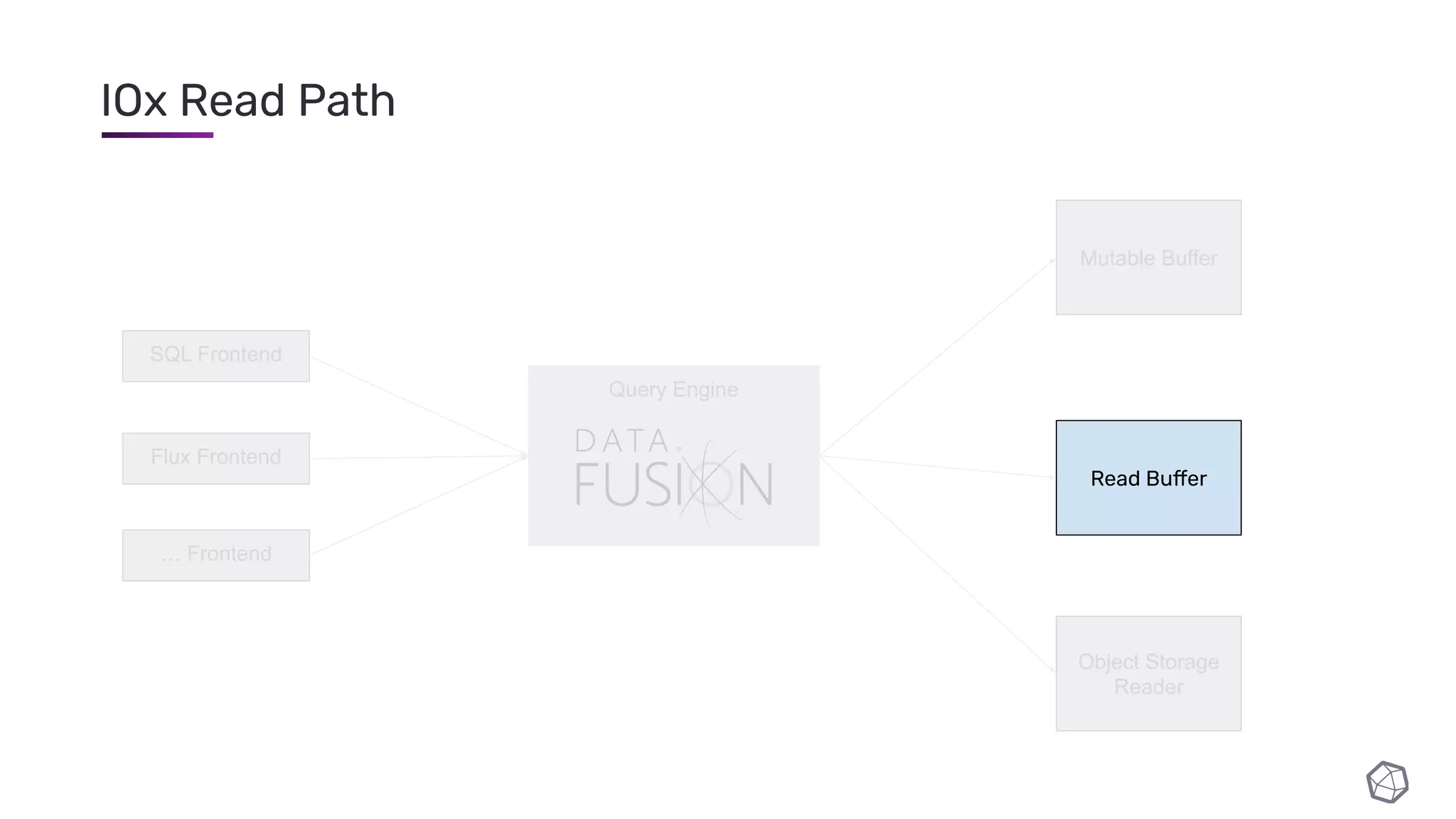
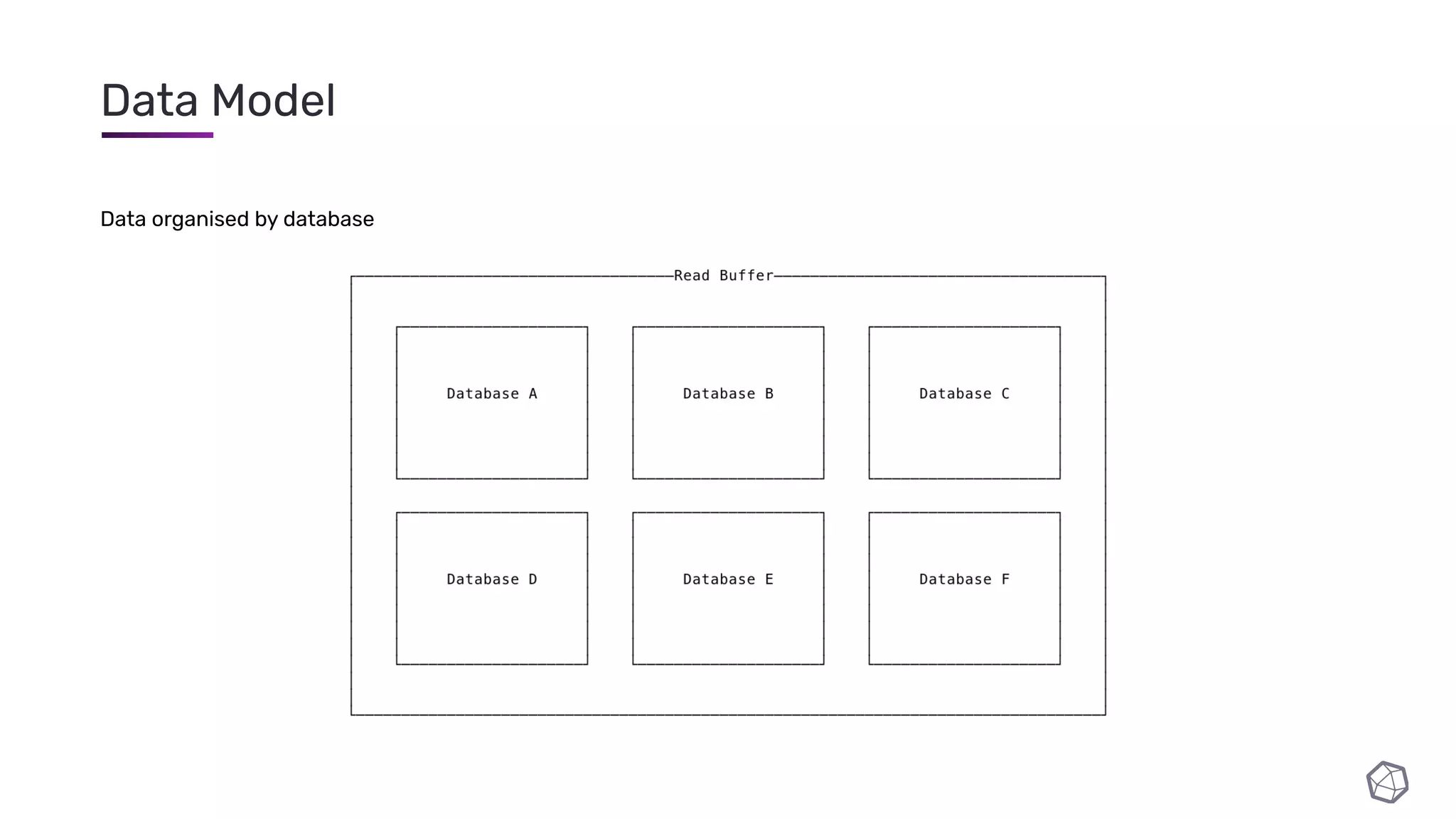
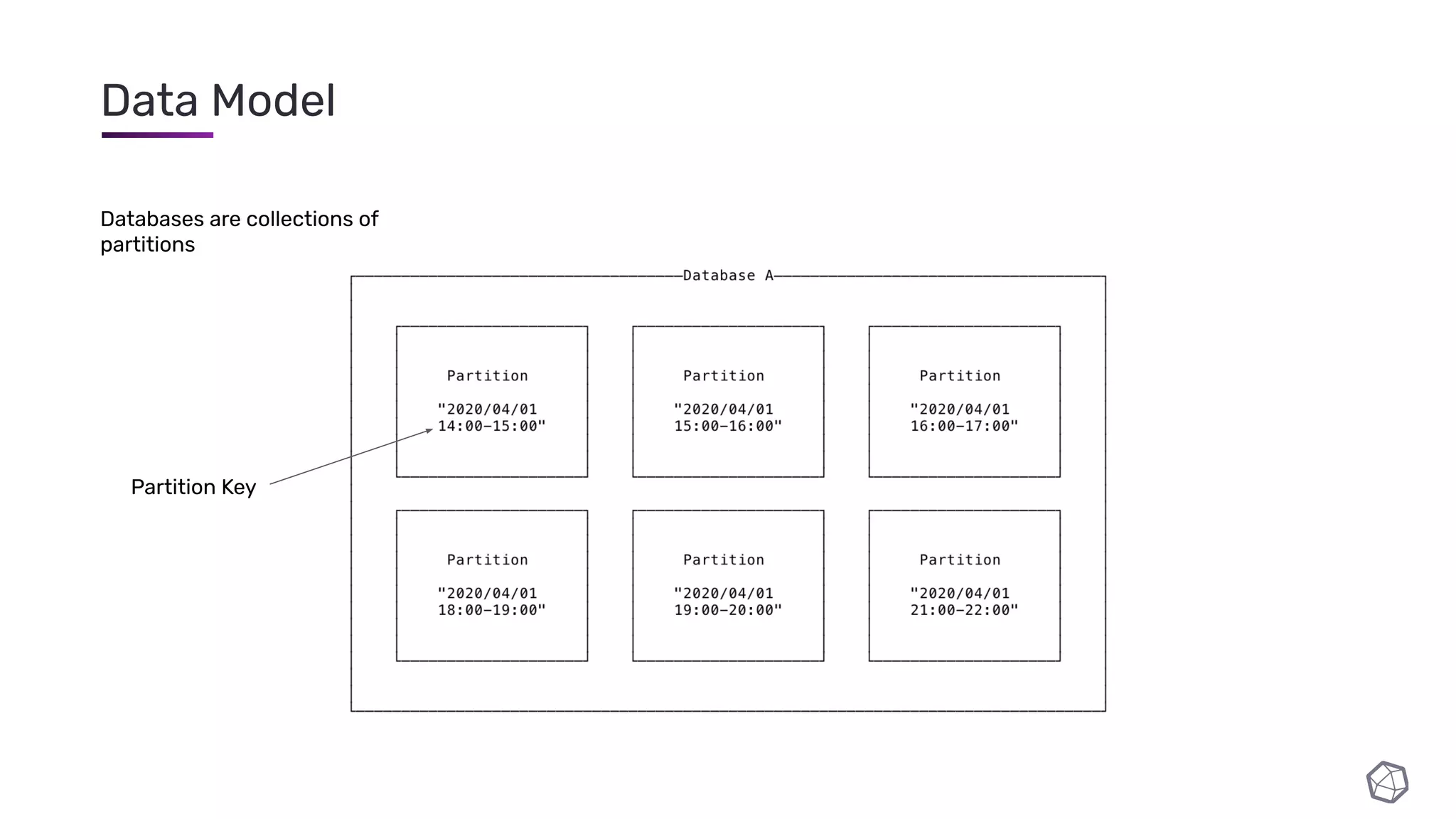
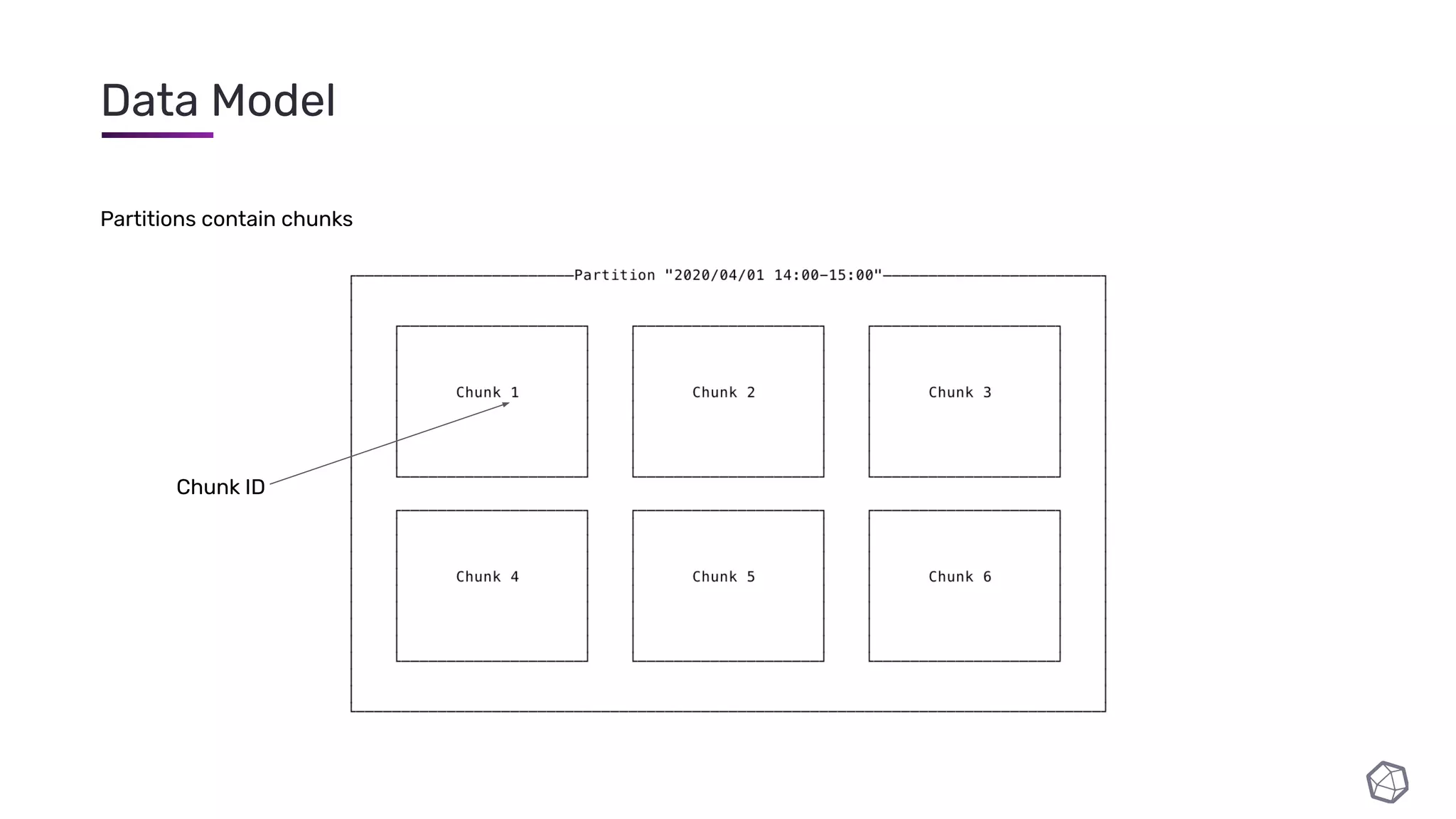
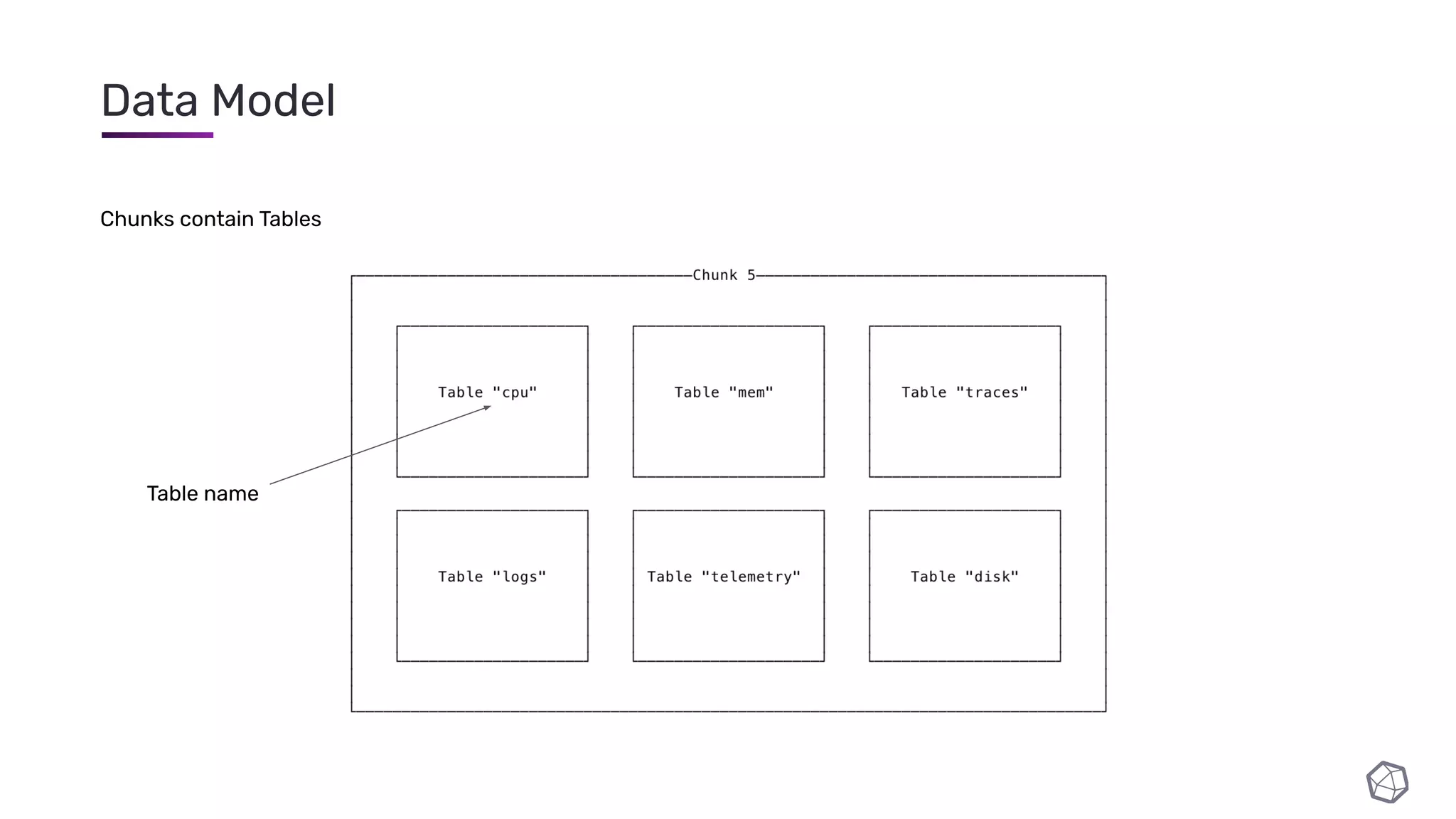
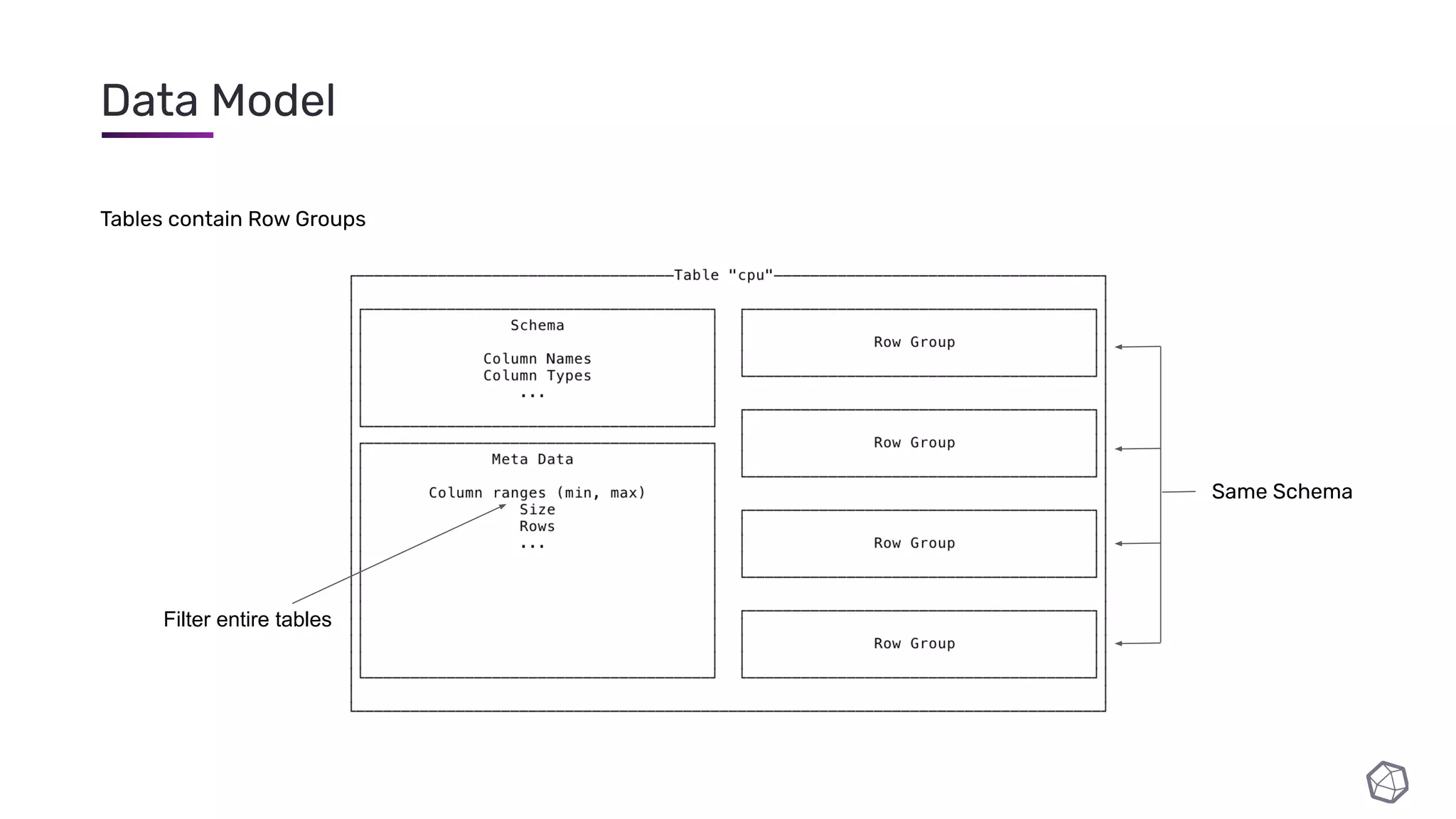
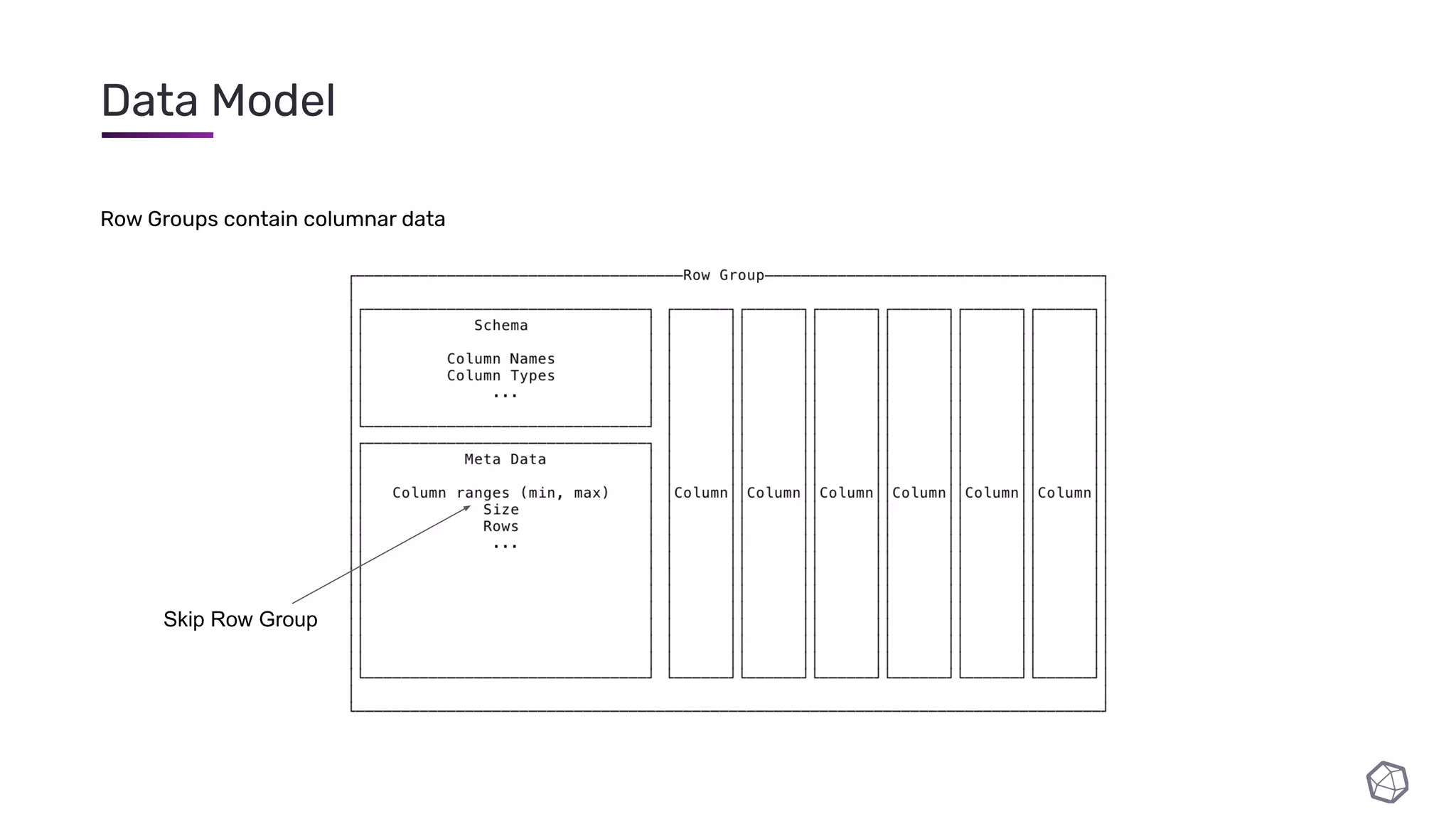
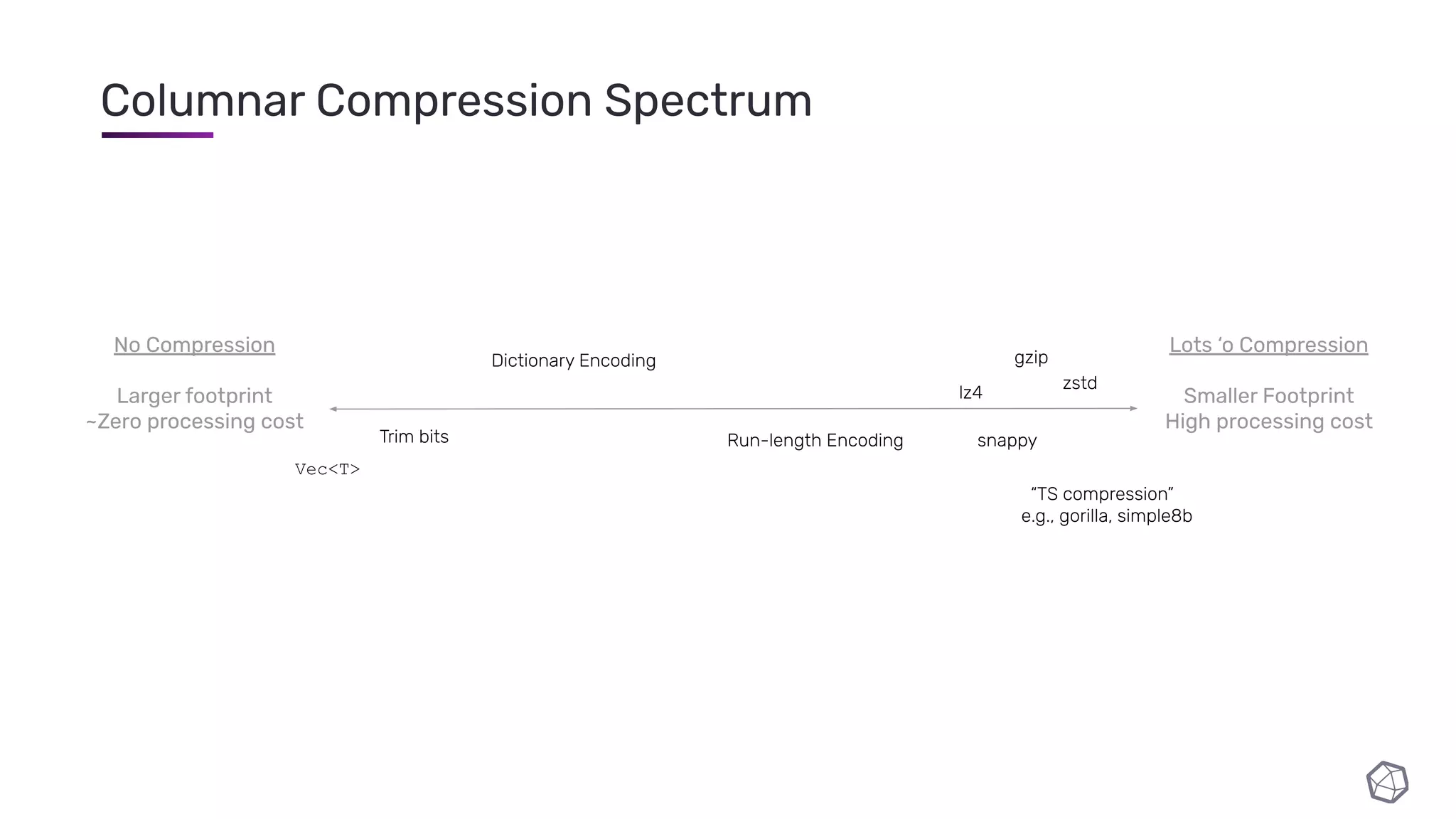
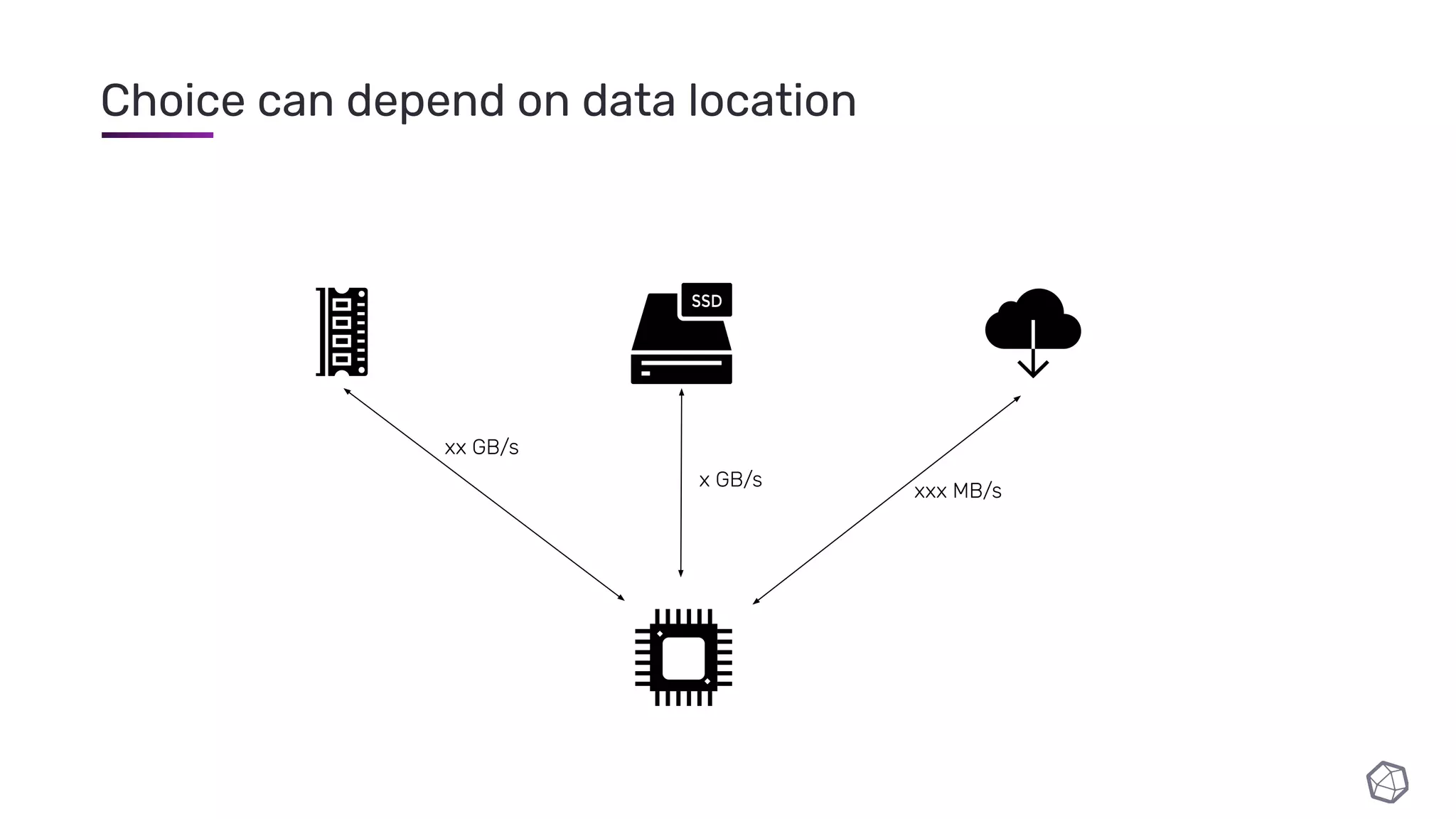
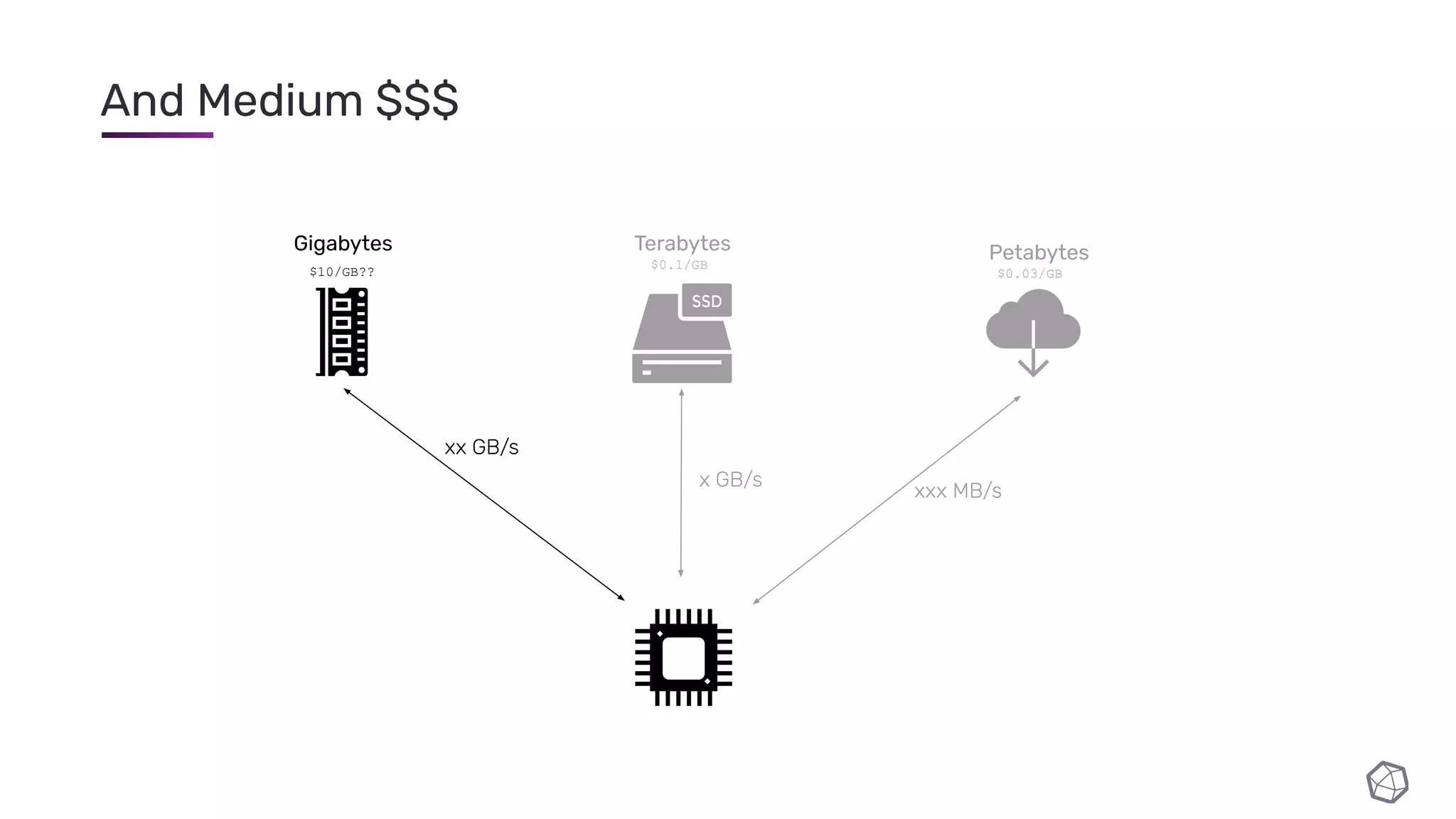
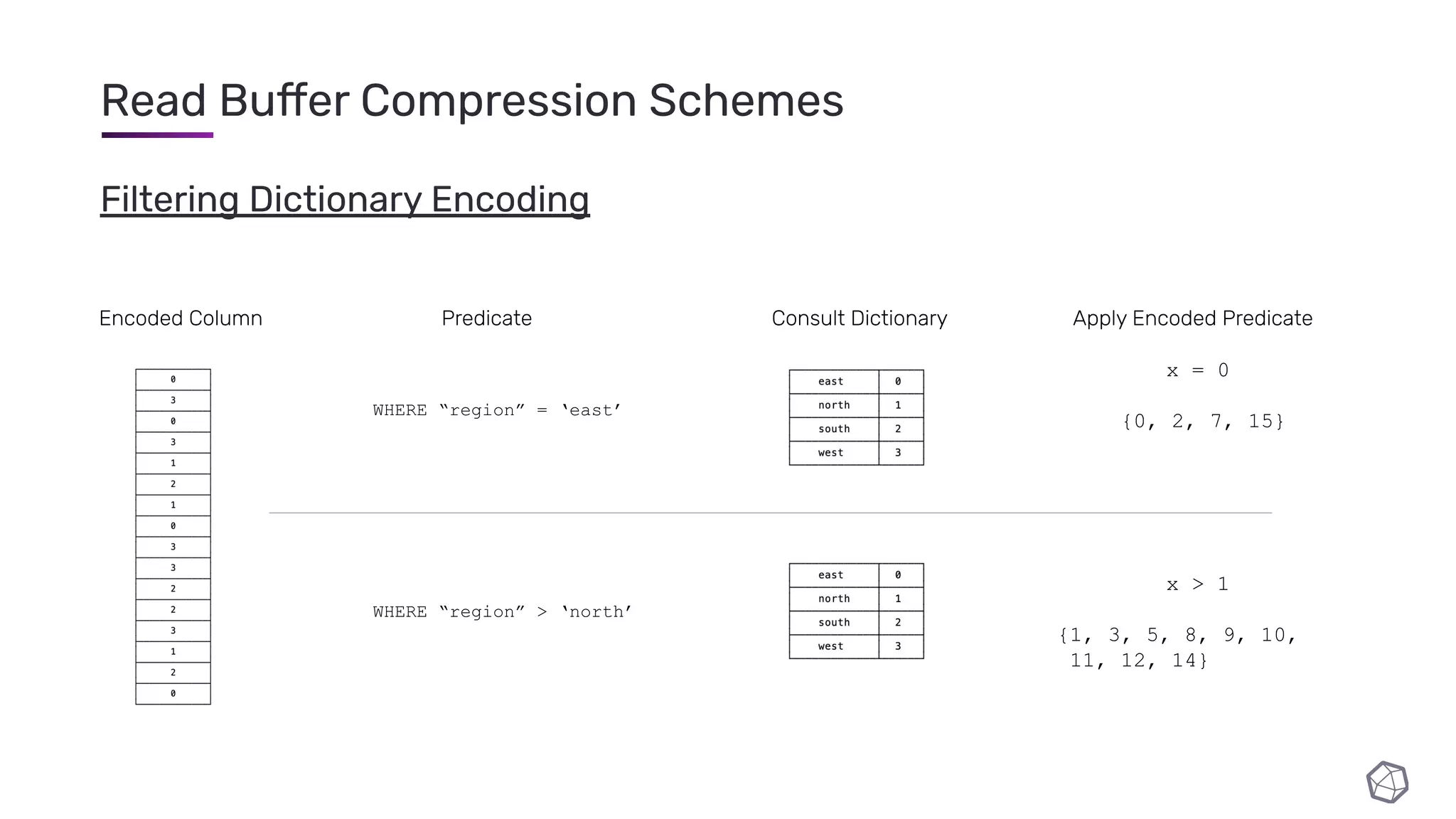
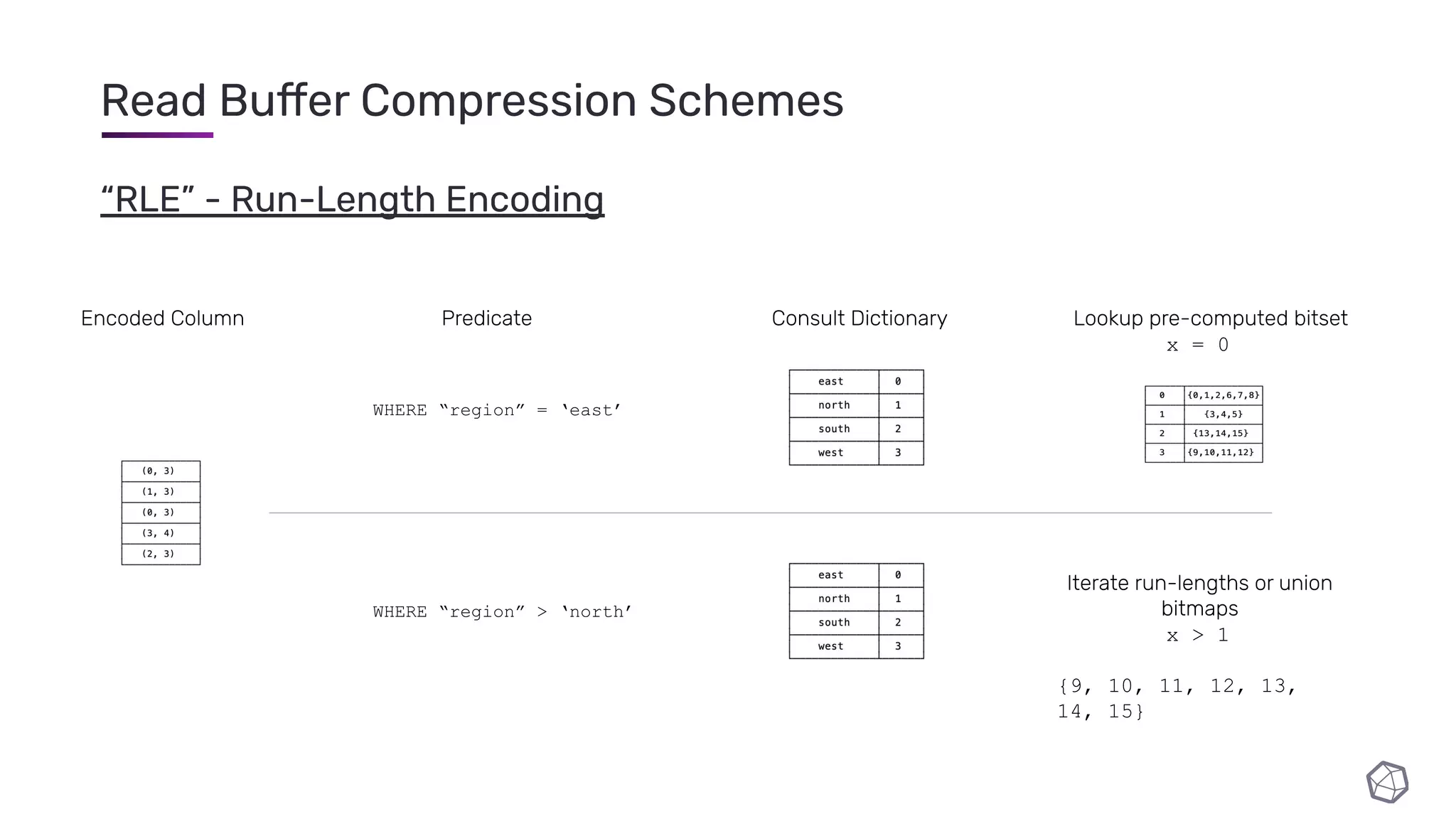
The document discusses updates and progress on InfluxDB IOx, a new columnar time series database, highlighting developments like a read buffer, management API, and future capabilities such as parquet persistence and replication. It emphasizes the importance of columnar data layout for analytical workloads and details various data organization and compression techniques in IOx. The presentation outlines the architecture, data models, and future enhancements aimed at improving performance and data handling for time-series use cases.